爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>
爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>-CSDN博客
爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>-CSDN博客
前言:
之前提到过,很多scrapy写出来之后,不知不觉就会造成整体scrapy速度越来越慢的情况,且大部分都是内存泄漏问题(前面讲了如何诊断,各人往上看链接); `通药`也就是最普遍,快捷的办法便是调整几个数值(在医病篇里);但是,最根本的原因,还是在scrapy的设计上,出现了大范围堵塞造成的! 那么,现在(诊断)完之后,针对 request和item的堆积问题,进行`根上`的解决以及指正一下scrapy玩家,在设计自己的爬虫时,要规避的一些隐患和高效方法!
正文:
1.requests堆积的问题:
-
1.设计一个HTML页面装载一个item:
- 在Scrapy中设计爬虫时,最好将爬取的数据存储为Scrapy的Item对象,然后在解析页面时将数据填充到Item中。(备注:最好一个html,装一个尽量不要回传,哪怕用meta装载到回调函数里,尽快将item丢出去!!!!)
-
2.在收到响应后的处理:
- - 有效响应: 如果收到有效响应,则立即解析出数据,将数据传递给Item,并将Item传递给管道进行后续处理。(先验证是否有数据,要存数据才实例化item(),否则别创建!!!容易造成item的堆积,增加item的量)
- - 无效响应或无有效数据:如果响应为空或者没有有效数据,直接返回一个空列表`[]`。这有助于及时从请求队列中移除对应的request,避免请求堆积。(不返回或者返回None,还会进行后续处理,最直接的就是返回一个[],直接把这个请求给他抹掉;也就是释放得干净!!)
案例:
import scrapy
from scrapy.item import Item, Fieldclass MyItem(Item):data = Field()class MySpider(scrapy.Spider):name = 'my_spider'start_urls = ['http://example.com']def parse(self, response):# 1. 设计一个HTML页面装载一个itemmy_item_1 = MyItem()# 假设爬取的第一个数据在HTML页面中的某个CSS选择器下data_1 = response.css('div.data1::text').get()# 2. 在收到响应后的处理if data_1:# 有效响应:解析出数据,将数据传递给Item,并将Item传递给管道进行后续处理my_item_1['data'] = data_1# 先验证是否有数据,要存数据才实例化item()yield my_item_1else:# 无效响应或无有效数据:返回一个空列表`[]`,从请求队列中移除对应的request,避免请求堆积yield []# 或者直接把请求给抹掉,释放得干净# return# 重复上述过程,设计第二个HTML页面装载另一个itemmy_item_2 = MyItem()data_2 = response.css('div.data2::text').get()if data_2:my_item_2['data'] = data_2yield my_item_2else:yield []# 在这里可以继续处理其他逻辑,或者进行下一步请求# ...创建了两个 MyItem 对象,分别为 my_item_1 和 my_item_2,通过不同的 CSS 选择器提取数据,然后通过 yield 分别返回这两个 MyItem;
我们刚刚已经把item进行了分化,他可能已经从最开始的1个item,变成了X个;(这样能解决你的request问题,但是会加大你的item问题)
2.item堆积的问题:
在Scrapy中,pipelines是串行处理的。当我们直接将一个包含全部数据的Item传递给pipelines时,整个流程从处理Item数据到存储数据都在为这一个Item服务。为了提高效率,我们可以采用一种巧妙的方式,通过处理多个分化的小Item,从而`间接`实现了并行处理的效果。
为了实现这个思路,我们可以将分化的X个Item,通过(X+1)个pipelines分别进行存储到不同的数据库。这里的(X+1)中的1代表一个专门用于接收Item并快速分发到不同管道的特殊管道。这个设计的目的是减小每个存储管道的负担,降低串行处理的风险,提高整体性能。
举个例子:
-
假设有一个Item,存了5条数据,将它直接丢给一个管道,整个流程需要0.5秒。
-
如果有5个Item(也是存了5条数据),分别将它们丢给一个专门的“分管的管道A”,那么这个管道最多只需要花费0.05秒便能处理完一条Item的简单分管任务!对于5个Item,总时间为0.25秒。已知每条数据存入数据库的速度是0.1秒(合并了上面的0.5秒,分析+存储),整个流程的时间就是0.25+0.1=0.35秒完成全部5个Item。
同样的存入5条数据,第二种方式是不是更小而轻便地完成了?而且节省了0.15秒的时间。如果是1000个这样的数据存储,我们就节省了150秒;1W个就是25分钟,10W个就是4个多小时!
案例:
import pymongo
import pymysql
from itemadapter import ItemAdapterclass DistributePipeline:def process_item(self, item, spider):# 在这里可以根据实际情况将Item分发到不同的存储管道# 这里简单示例将Item直接返回,实际可根据需要分发到多个不同的管道return itemclass DatabaseAPipeline:def __init__(self, database_uri, collection_name):self.database_uri = database_uriself.collection_name = collection_nameself.client = Noneself.db = None@classmethoddef from_crawler(cls, crawler):settings = crawler.settingsdatabase_uri = settings.get('DATABASE_A_URI')collection_name = settings.get('COLLECTION_NAME_A')return cls(database_uri, collection_name)def open_spider(self, spider):self.client = pymongo.MongoClient(self.database_uri)self.db = self.client.get_database()def close_spider(self, spider):self.client.close()def process_item(self, item, spider):adapter = ItemAdapter(item)data_to_store = adapter.asdict()# 在这里可以根据实际情况将数据存储到不同的数据库self.db[self.collection_name].insert_one(data_to_store)return itemclass DatabaseBPipeline:def __init__(self, database_host, database_user, database_password, database_name):self.database_host = database_hostself.database_user = database_userself.database_password = database_passwordself.database_name = database_nameself.connection = Noneself.cursor = None@classmethoddef from_crawler(cls, crawler):settings = crawler.settingsdatabase_host = settings.get('DATABASE_B_HOST')database_user = settings.get('DATABASE_B_USER')database_password = settings.get('DATABASE_B_PASSWORD')database_name = settings.get('DATABASE_B_NAME')return cls(database_host, database_user, database_password, database_name)def open_spider(self, spider):self.connection = pymysql.connect(host=self.database_host,user=self.database_user,password=self.database_password,database=self.database_name,charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor)self.cursor = self.connection.cursor()def close_spider(self, spider):self.connection.close()def process_item(self, item, spider):adapter = ItemAdapter(item)data_to_store = adapter.asdict()# 在这里可以根据实际情况将数据存储到不同的数据库表sql = "INSERT INTO table_b (field1, field2) VALUES (%s, %s)"self.cursor.execute(sql, (data_to_store['field1'], data_to_store['field2']))self.connection.commit()return item
一个DistributePipeline用于接收Item并快速分发到不同管道,还有两个数据库存储的管道:DatabaseAPipeline和DatabaseBPipeline。根据实际情况调整数据库连接的配置和字段映射!
这种方式的优势在于解决了存储的高并发问题,特别是通过合理使用连接池可以进一步提高数据库操作的效率。
需要注意的是,作为爬虫的主要任务是存储,因此我们可以专注于优化存储的高并发处理(模块化分流)。后续的清洗和分析工作可以通过脚本进行,确保整个爬虫系统高效运行才是王道!!!
总结:
scrapy,就是尽量把每个环节拆开,拆得尽量轻~ 然后,能用并行解决的,坚决不要串行!! 串行绕不过去的,也要想办法把他拆成接近并行!!! 最重要一点,用完就丢(释放!!!!----->关于item释放,我前面文章有Dropitem的说明!)
最后,你们可以通过今天看到的;对你们的scrapy代码进行重新拆分~ 然后,再用telnet工具检查一下!!
------有收益的,请点赞告诉我!
相关文章:
>)
爬虫工作量由小到大的思维转变---<第二十五章 Scrapy开始很快,越来越慢(追溯篇)>
爬虫工作量由小到大的思维转变---<第二十二章 Scrapy开始很快,越来越慢(诊断篇)>-CSDN博客 爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>-CSDN博客 前言: 之前提到过,很多scrapy写出来之后,不…...
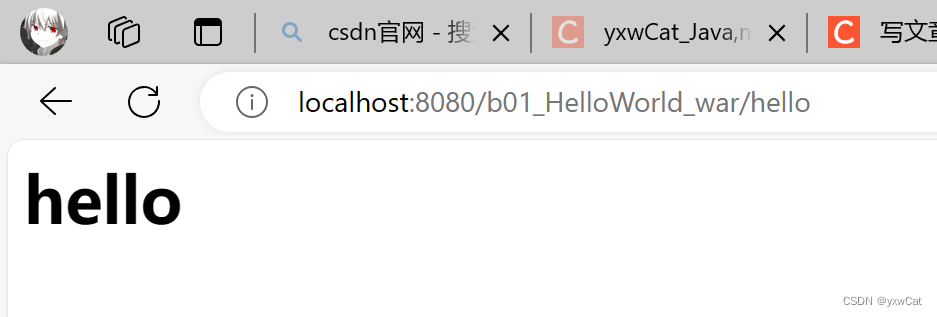
Servlet入门
目录 1.Servlet介绍 1.1什么是Servlet 1.2Servlet的使用方法 1.3Servlet接口的继承结构 2.Servlet快速入门 2.1创建javaweb项目 2.1.1创建maven工程 2.1.2添加webapp目录 2.2添加依赖 2.3创建servlet实例 2.4配置servlet 2.5设置打包方式 2.6部署web项目 3.servl…...

【C#与Redis】--高级主题--Redis 哨兵
一、简介 1.1 哨兵的概述 哨兵(Sentinel)是 Redis 分布式系统中用于监控和管理多个 Redis 服务器的组件。它的主要目标是确保 Redis 系统的高可用性,通过实时监测主节点和从节点的状态,及时发现并自动处理故障,保证系…...

linux安装python
文章目录 前言一、下载安装包二、安装1.安装依赖2.解压3.安装4.软链接5.验证 总结 前言 本篇文章介绍linux环境下安装python。 一、下载安装包 下载地址:官方网站 我们以最新的标准版为例 二、安装 1.安装依赖 yum -y install openssl-devel ncurses-devel li…...

【如何破坏单例模式(详解)】
✅如何破坏单例模式 💡典型解析✅拓展知识仓✅反射破坏单例✅反序列化破坏单例✅ObjectlnputStream ✅总结✅如何避免单例被破坏✅ 避免反射破坏单例✅ 避免反序列化破坏单例 💡典型解析 单例模式主要是通过把一个类的构造方法私有化,来避免重…...

什么是 SPI,它有什么用?
文章目录 什么是 SPI,它有什么用? 什么是 SPI,它有什么用? SPI 全称是 Service Provider Interface ,它是 JDK 内置的一种动态扩展点的实现。 简单来说,就是我们可以定义一个标准的接口,然后第三…...

FolkMQ 新的消息中间件,v1.0.25
简介 采用 “多路复用” “内存运行” “快照持久化” “Broker 集群模式”(可选)基于 Socket.D 网络应用协议 开发。全新设计,自主架构! 角色功能生产端发布消息(Qos0、Qos1)、发布定时消息ÿ…...
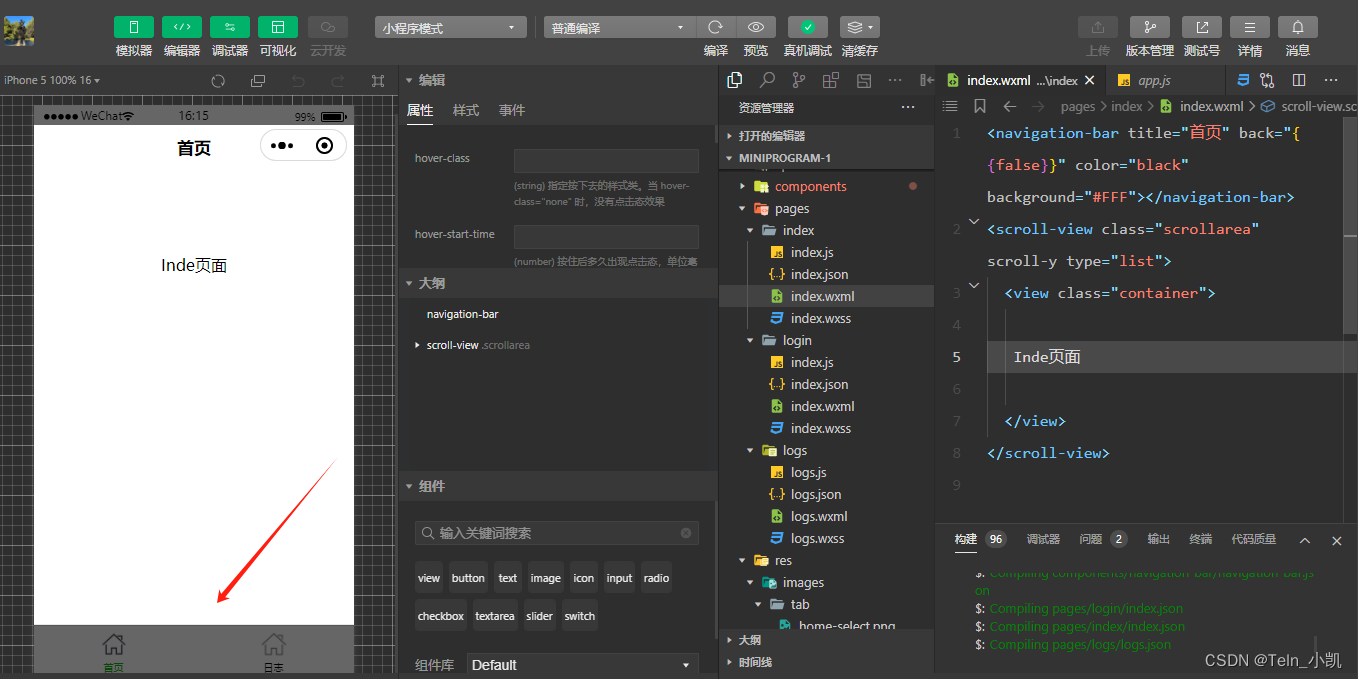
小程序入门-登录+首页
正常新建一个登录页面 创建首页和TatBar,实现登录后底部出现两个按钮 代码 "pages": ["pages/login/index","pages/index/index","pages/logs/logs" ],"tabBar": {"list": [{"pagePath"…...

React快速入门之组件
目录 组件JSX在标签使用{}嵌入JS表达式使用组件组件嵌套以🌲树的方式管理组件间的关系组件纯粹原则 组件 文件:Profile.js export default function Profile({isPacked true,head,stlyeTmp,src,size 80}) {if (isPacked) {head head &q…...
.NET Conf 2023 回顾 – 庆祝社区、创新和 .NET 8 的发布
作者: Jon Galloway - Principal Program Manager, .NET Community Team Mehul Harry - Product Marketing Manager, .NET, Azure Marketing 排版:Alan Wang .NET Conf 2023 是有史以来规模最大的 .NET 会议,来自全球各地的演讲者进行了 100 …...
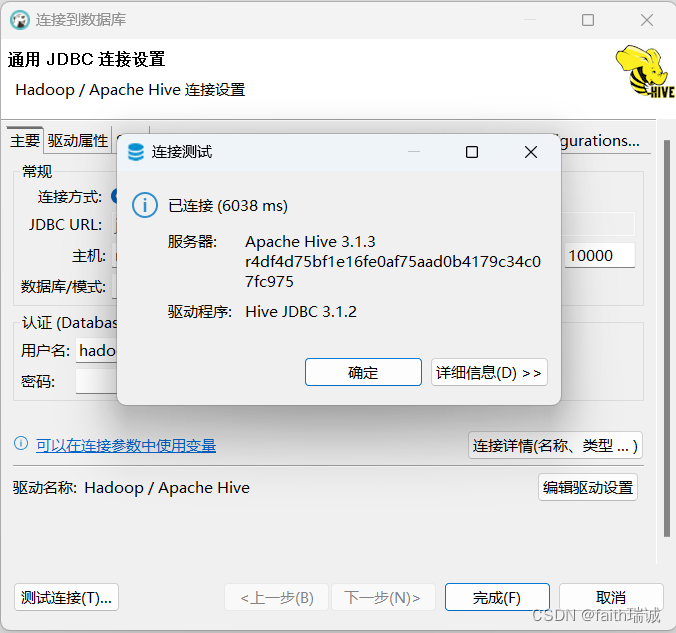
Hadoop入门学习笔记——六、连接到Hive
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 六、连接到Hive6.1. 使用Hive的Shell客户端6.2. 使用Beel…...
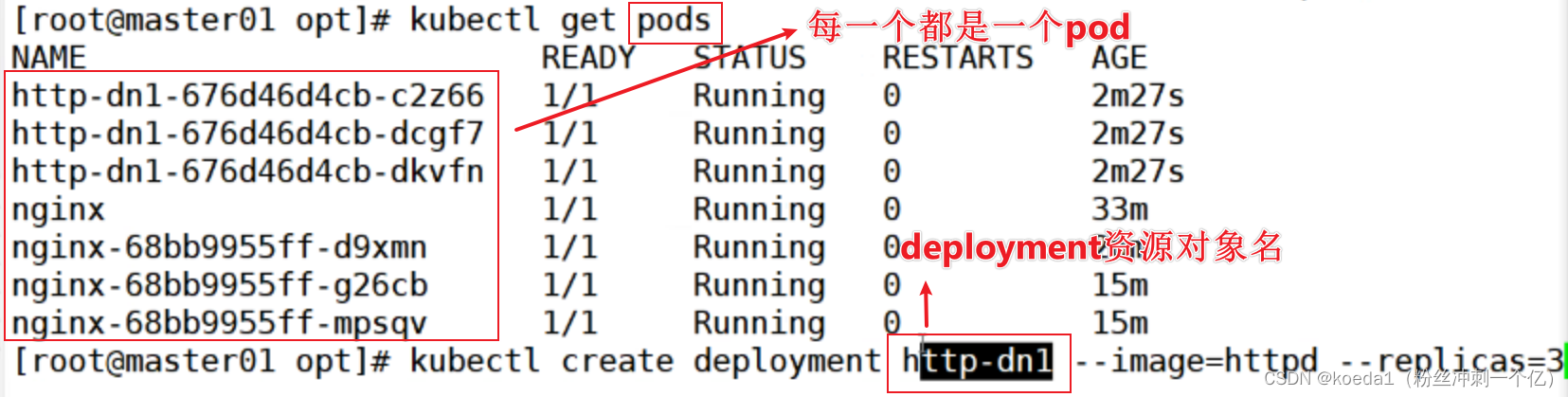
【K8S 基本概念】Kurbernetes的架构和核心概念
目录 一、Kurbernetes 1.1 简介 1.2、K8S的特性: 1.3、docker和K8S: 1.4、K8S的作用: 1.5、K8S的特性: 二、K8S集群架构与组件: 三、K8S的核心组件: 一、master组件: 1、kube-apiserve…...

WPS复选框里打对号,显示小太阳或粗黑圆圈的问题解决方法
问题描述 WPS是时下最流行的字处理软件之一,是目前唯一可以和微软office办公套件相抗衡的国产软件。然而,在使用WPS的过程中也会出现一些莫名其妙的错误,如利用WPS打开docx文件时,如果文件包含复选框,经常会出…...

对“企业数据资源相关会计处理暂行规定“的个人理解
附:2023年数据资源入表白皮书下载: 关注WX公众号: commindtech77, 获得数据资产相关白皮书下载地址 1. 回复关键字:数据资源入表白皮书 下载 《2023数据资源入表白皮书》 2. 回复关键字:光大银行 下载 光…...

JavaScript:函数隐含对象arguments/剩余参数. . .c/解构赋值
除了this,在函数内部还存在着一个隐含的参数arguments arguments 是一个类数组对象(伪数组) 调用函数时传递的所有实参,都被存储在arguments中 arguments[0] 表示的是第一个实参 arguments[1] 表示的是第二个实参 以此类推..…...

MFC窗体背景颜色的设置、控件白色背景问题、控件文本显示重叠问题、被父窗体背景覆盖的问题
文章目录 设置mfc窗体背景颜色窗体设置背景颜色后解决控件白色背景解决重复修改控件文本后重叠的问题自绘控件被父窗体背景覆盖的问题 设置mfc窗体背景颜色 设置窗体的背景颜色非常简单,只需要在窗体的OnEraseBkgnd里面填充窗体背景就可以了,甚至直接画…...

c++简易AI
今天小编一时雅兴大发,做了一个c的简易AI,还是很垃圾的! 题外话(每期都会有):我的蛋仔名叫酷影kuying,大家能加我好友吗? 上代码咯! #include<bits/stdc.h> #in…...

java获取两个List集合之间的交集、差集、并集
文章目录 方式一、jdk8 Stream求交集、并集、差集方式二、求交集方式三、collections4.CollectionUtils求交集、差集、并集 本文总结一下java中获取两个List之间的交集、补集、并集的几种方式。 最常用的通过for循环遍历两个集合的方式在这里就不整理了,主要整理一些…...
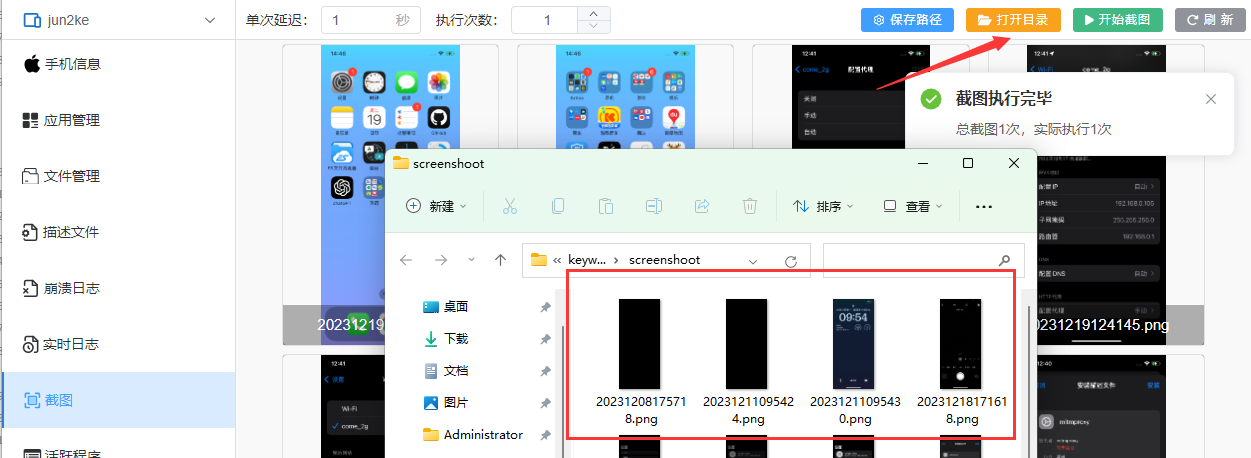
轻松实现iphone截图传电脑
目录 摘要 引言 用户登录工具和连接设备 生成截图 摘要 本篇博文介绍了克魔助手这款工具,解决了iPhone与Windows系统下图片传输的烦恼。通过连接同一Wi-Fi,使用克魔助手轻松实现了iPhone截图传输到电脑上的便捷操作。用户只需简单地下载并安装克魔助…...
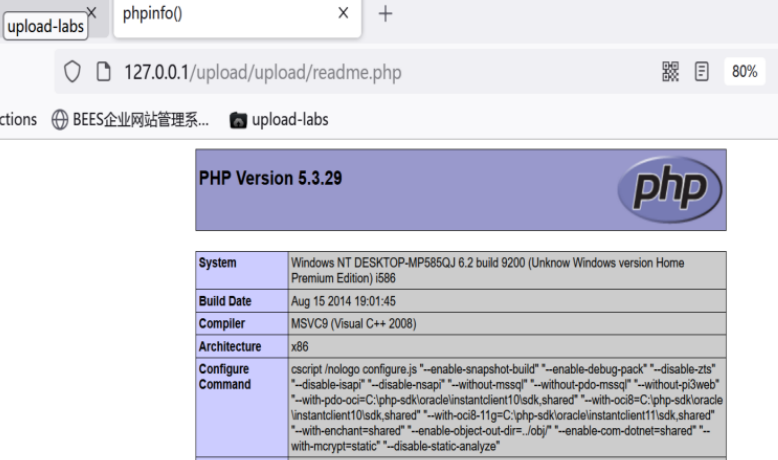
【网络安全】upload靶场pass1-10思路
目录 Pass-1 Pass-2 Pass-3 Pass-4 Pass-5 Pass-6 Pass-7 Pass-8 Pass-9 Pass-10 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN…...

DOM Node:深入解析与高效使用
DOM Node:深入解析与高效使用 引言 DOM(Document Object Model)是现代网页开发的核心技术之一,它允许开发者以程序化的方式操作HTML文档。DOM Node是DOM的核心概念之一,理解并熟练使用DOM Node对于提高网页开发效率至关重要。本文将深入解析DOM Node的概念、类型、属性和…...

如何快速集成Draw.io Mermaid插件:提升图表绘制效率的终极指南
如何快速集成Draw.io Mermaid插件:提升图表绘制效率的终极指南 【免费下载链接】drawio_mermaid_plugin Mermaid plugin for drawio desktop 项目地址: https://gitcode.com/gh_mirrors/dr/drawio_mermaid_plugin 还在为绘制复杂的流程图、时序图而烦恼吗&am…...

5分钟Git指南
Git——一个版本控制系统 了解Git当你建立了一个Git版本库,那么存放.git(也就是版本库)的文件夹就被称为工作区,.git内部有一个暂存区,一个叫做master的分支,一个HEAD指针能够指向分支中不同版本的文件&…...

clawdocker:基于Shell脚本的Docker实例管理器,简化OpenClaw多实例部署
1. 项目概述与核心价值 如果你正在折腾OpenClaw,或者任何需要部署多个独立实例的Docker化应用,那么你大概率经历过这样的场景:每次新建一个实例,都要手动执行一长串的 docker run 命令,记住各种端口映射、卷挂载和环…...

基于GitHub Actions的AI智能体部署指南:exoclaw-github实战解析
1. 项目概述:在GitHub里养一只会看代码的“螃蟹”如果你在GitHub上维护过开源项目,肯定遇到过这样的场景:新开的Issue描述不清,得来回问好几轮才能定位问题;PR提交上来,你得逐行审阅代码,既费时…...

OpenManus-RL:基于强化学习优化大语言模型智能体决策的完整框架
1. 项目概述与核心价值如果你正在关注大语言模型智能体领域,尤其是如何让模型从“会聊天”进化到“会做事”,那么OpenManus-RL这个项目绝对值得你投入时间研究。它不是一个简单的工具库,而是一个由UIUC-Ulab和MetaGPT团队联合发起的、以直播形…...

Kubernetes配置管理神器Monokle:可视化IDE提升YAML开发效率
1. 项目概述:一个被低估的Kubernetes配置管理神器如果你和我一样,每天都在和成堆的YAML文件、复杂的Kubernetes资源关系以及让人头疼的配置漂移问题打交道,那你一定理解那种在终端、IDE和Dashboard之间反复横跳的疲惫感。几年前,当…...

IP2366至为芯支持C口双向快充的140W多串锂电池充放电SOC芯片
英集芯IP2366是一款应用于移动电源、电动工具、智能家居、储能电源等方案的多串锂电池充电SOC芯片。支持高达140W的双向同步升降压充放电,充电电流可达5A。支持2至6节锂电池/磷酸铁锂电池串联,集成PD3.1、QC3.0等多种快充协议。内置14bit ADC,…...

基于大语言模型的银行对账单自动化分析与财务预测实战
1. 项目概述:当大语言模型遇上个人财务分析最近在GitHub上看到一个挺有意思的项目,叫“AI银行对账单文档自动化与个人财务分析预测”。光看这个标题,就能感觉到一股浓浓的“技术赋能生活”的味道。简单来说,这个项目想干的事儿&am…...

量子噪声对机器学习模型的影响与缓解策略
1. 量子噪声与机器学习模型的复杂关系量子计算领域近年来最令人兴奋的进展之一,就是量子机器学习(QML)的兴起。作为一名长期跟踪量子计算发展的从业者,我亲眼见证了量子算法在机器学习任务中展现出的惊人潜力。然而,在…...