DAY 45 超大力王爱学Python
知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
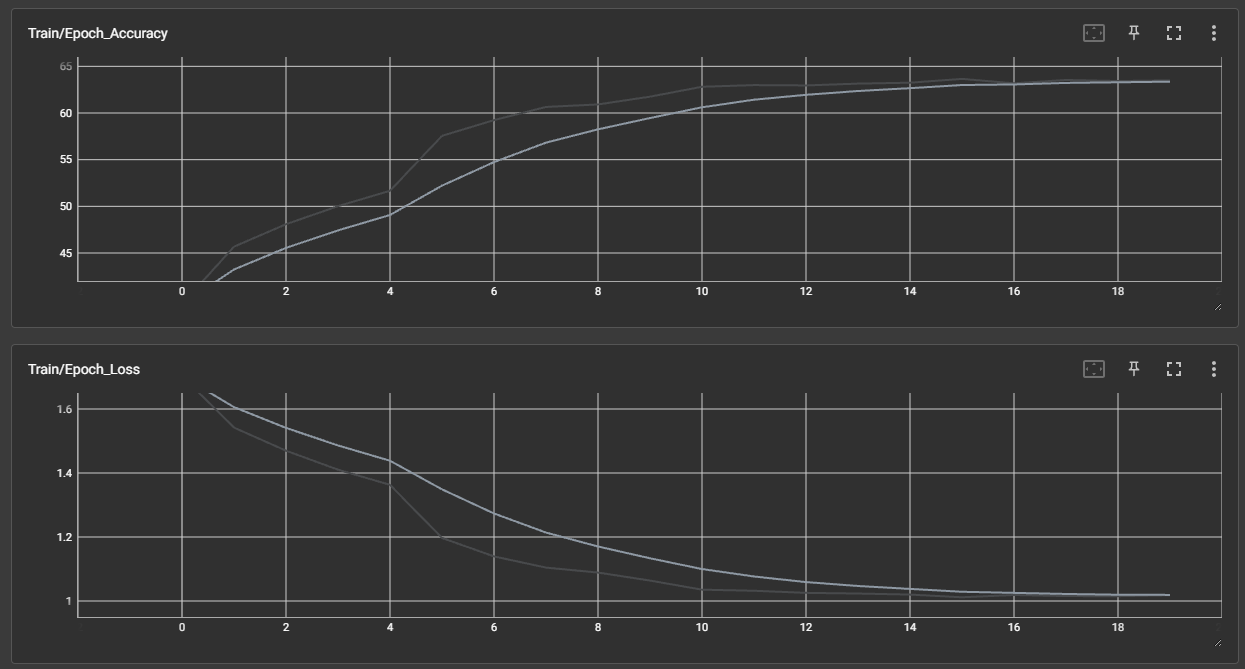
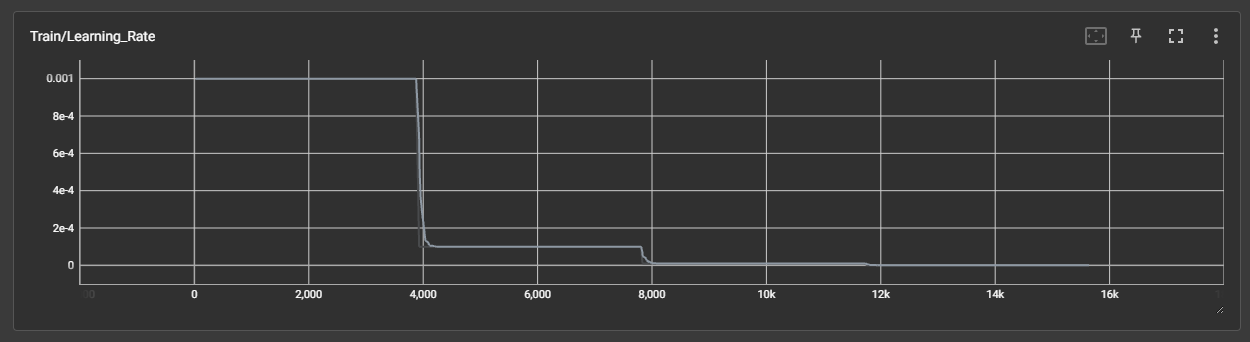
效果展示如下,很适合拿去组会汇报撑页数:
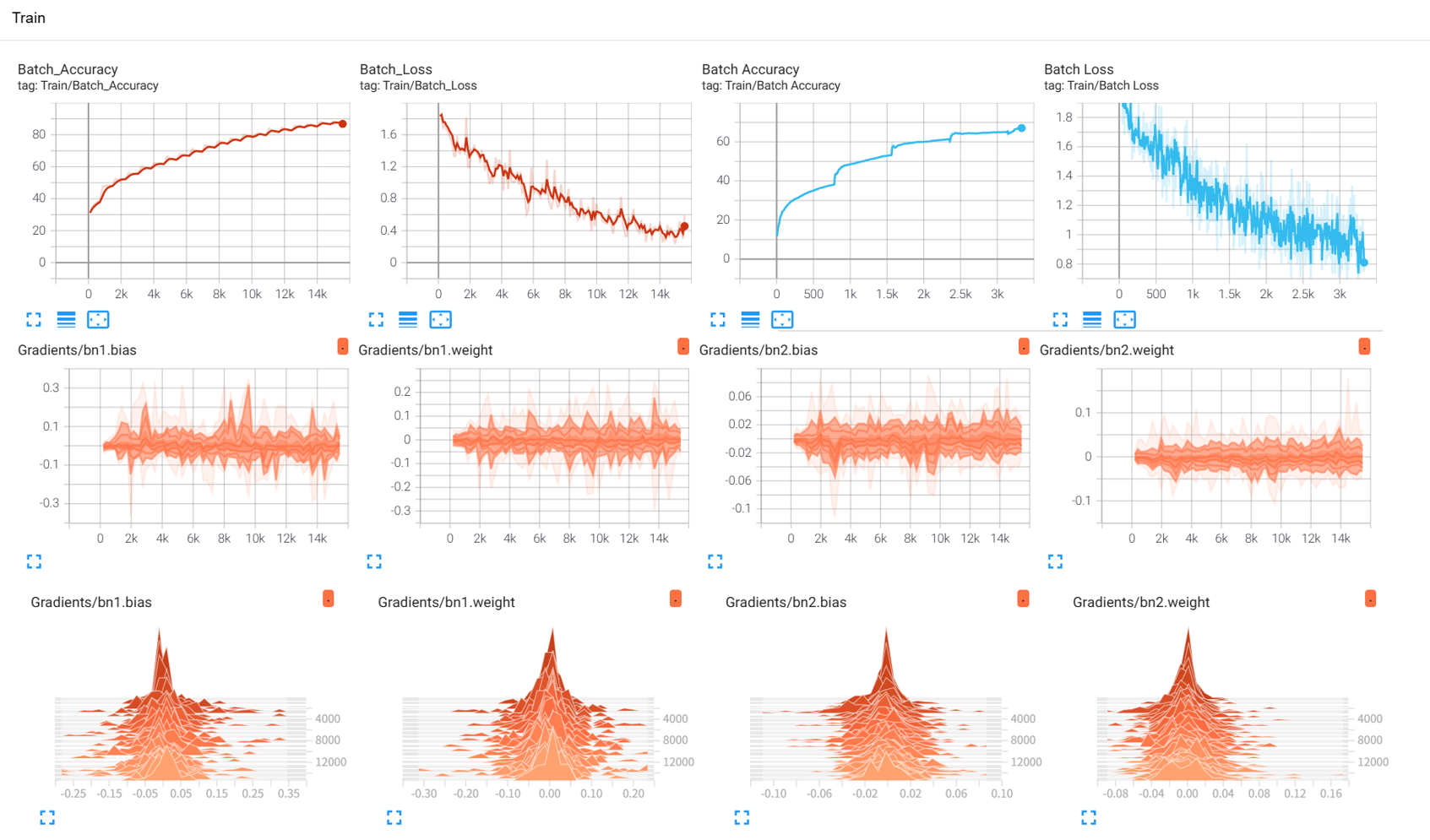
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten()self.layer1 = nn.Linear(3072, 512)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2)self.layer2 = nn.Linear(512, 256)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10)def forward(self, x):x = self.flatten(x)x = self.layer1(x)x = self.relu1(x)x = self.dropout1(x)x = self.layer2(x)x = self.relu2(x)x = self.dropout2(x)x = self.layer3(x)return x# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 初始化模型
model = MLP()
model = model.to(device)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)# 创建TensorBoard的SummaryWriter
log_dir = 'runs/cifar10_mlp_experiment'
# 自动生成唯一目录(避免覆盖)
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"# 创建日志目录并验证
os.makedirs(log_dir, exist_ok=True)
print(f"TensorBoard日志将保存在: {log_dir}")# 检查目录是否创建成功
if not os.path.exists(log_dir):raise FileNotFoundError(f"无法创建日志目录: {log_dir}")writer = SummaryWriter(log_dir)# 模型保存路径
model_save_dir = 'saved_models'
os.makedirs(model_save_dir, exist_ok=True)
best_model_path = os.path.join(model_save_dir, 'best_model.pth')
final_model_path = os.path.join(model_save_dir, 'final_model.pth')# 5. 训练模型(优化TensorBoard日志写入)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()best_accuracy = 0.0global_step = 0# 可视化模型结构(添加错误处理和调试打印)try:dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images)print(f"✅ 已记录模型图至TensorBoard")print(f"成功获取训练数据批次,图像尺寸: {images.shape}") # 调试打印except Exception as e:print(f"⚠️ 模型图记录失败: {e}")return 0.0 # 训练失败时提前返回# 可视化原始图像样本(添加调试打印)img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid, global_step=0)print(f"✅ 已记录原始图像至TensorBoard")for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每批次都记录日志(简化调试)writer.add_scalar('Train/Batch_Loss', loss.item(), global_step)writer.add_scalar('Train/Batch_Accuracy', 100. * correct / total, global_step)writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每100个批次打印一次信息if (batch_idx + 1) % 100 == 0:batch_loss = loss.item()print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 更新学习率scheduler.step()# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练指标writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0# 限制错误样本数量max_wrong_samples = 100wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0 and len(wrong_images) < max_wrong_samples:num_add = min(max_wrong_samples - len(wrong_images), wrong_mask.sum())wrong_batch_images = data[wrong_mask][:num_add].cpu()wrong_batch_labels = target[wrong_mask][:num_add].cpu()wrong_batch_preds = predicted[wrong_mask][:num_add].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试指标writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 保存最佳模型if epoch_test_acc > best_accuracy:best_accuracy = epoch_test_acctorch.save(model.state_dict(), best_model_path)print(f"✅ 保存最佳模型(准确率: {best_accuracy:.2f}%)")# 可视化错误预测样本(每个epoch都记录,便于观察)if len(wrong_images) > 0:display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid, global_step=epoch)writer.add_text('错误预测标签', '\n'.join(wrong_text), global_step=epoch)model.train() # 切回训练模式# 保存最终模型torch.save(model.state_dict(), final_model_path)print(f"模型已保存至 {final_model_path}")# 刷新并关闭TensorBoard写入器writer.flush()writer.close()return best_accuracy# Windows环境下的多进程兼容处理
if __name__ == "__main__":import torch.multiprocessing as mpmp.set_start_method('spawn') # 关键修改:解决Windows多进程问题epochs = 20print("开始训练模型...")print(f"TensorBoard日志保存在: {log_dir}")print("训练完成后,使用命令 `tensorboard --logdir={log_dir}` 启动TensorBoard")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}%")
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定义MLP模型
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten()self.layer1 = nn.Linear(3072, 512)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2)self.layer2 = nn.Linear(512, 256)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10)def forward(self, x):x = self.flatten(x)x = self.layer1(x)x = self.relu1(x)x = self.dropout1(x)x = self.layer2(x)x = self.relu2(x)x = self.dropout2(x)x = self.layer3(x)return x# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 初始化模型
model = MLP()
model = model.to(device)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)# 创建TensorBoard的SummaryWriter
log_dir = 'runs/cifar10_mlp_experiment'
# 自动生成唯一目录(避免覆盖)
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"# 创建日志目录并验证
os.makedirs(log_dir, exist_ok=True)
print(f"TensorBoard日志将保存在: {log_dir}")# 检查目录是否创建成功
if not os.path.exists(log_dir):raise FileNotFoundError(f"无法创建日志目录: {log_dir}")writer = SummaryWriter(log_dir)# 模型保存路径
model_save_dir = 'saved_models'
os.makedirs(model_save_dir, exist_ok=True)
best_model_path = os.path.join(model_save_dir, 'best_model.pth')
final_model_path = os.path.join(model_save_dir, 'final_model.pth')# 5. 训练模型(优化TensorBoard日志写入)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):model.train()best_accuracy = 0.0global_step = 0# 可视化模型结构(添加错误处理和调试打印)try:dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images)print(f"✅ 已记录模型图至TensorBoard")print(f"成功获取训练数据批次,图像尺寸: {images.shape}") # 调试打印except Exception as e:print(f"⚠️ 模型图记录失败: {e}")return 0.0 # 训练失败时提前返回# 可视化原始图像样本(添加调试打印)img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像', img_grid, global_step=0)print(f"✅ 已记录原始图像至TensorBoard")for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 统计准确率和损失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每批次都记录日志(简化调试)writer.add_scalar('Train/Batch_Loss', loss.item(), global_step)writer.add_scalar('Train/Batch_Accuracy', 100. * correct / total, global_step)writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每100个批次打印一次信息if (batch_idx + 1) % 100 == 0:batch_loss = loss.item()print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| Batch损失: {batch_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 更新学习率scheduler.step()# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 记录每个epoch的训练指标writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0# 限制错误样本数量max_wrong_samples = 100wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误样本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0 and len(wrong_images) < max_wrong_samples:num_add = min(max_wrong_samples - len(wrong_images), wrong_mask.sum())wrong_batch_images = data[wrong_mask][:num_add].cpu()wrong_batch_labels = target[wrong_mask][:num_add].cpu()wrong_batch_preds = predicted[wrong_mask][:num_add].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录每个epoch的测试指标writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 保存最佳模型if epoch_test_acc > best_accuracy:best_accuracy = epoch_test_acctorch.save(model.state_dict(), best_model_path)print(f"✅ 保存最佳模型(准确率: {best_accuracy:.2f}%)")# 可视化错误预测样本(每个epoch都记录,便于观察)if len(wrong_images) > 0:display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('错误预测样本', wrong_img_grid, global_step=epoch)writer.add_text('错误预测标签', '\n'.join(wrong_text), global_step=epoch)model.train() # 切回训练模式# 保存最终模型torch.save(model.state_dict(), final_model_path)print(f"模型已保存至 {final_model_path}")# 刷新并关闭TensorBoard写入器writer.flush()writer.close()return best_accuracy# Windows环境下的多进程兼容处理
if __name__ == "__main__":import torch.multiprocessing as mpmp.set_start_method('spawn') # 关键修改:解决Windows多进程问题epochs = 20print("开始训练模型...")print(f"TensorBoard日志保存在: {log_dir}")print("训练完成后,使用命令 `tensorboard --logdir={log_dir}` 启动TensorBoard")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}%")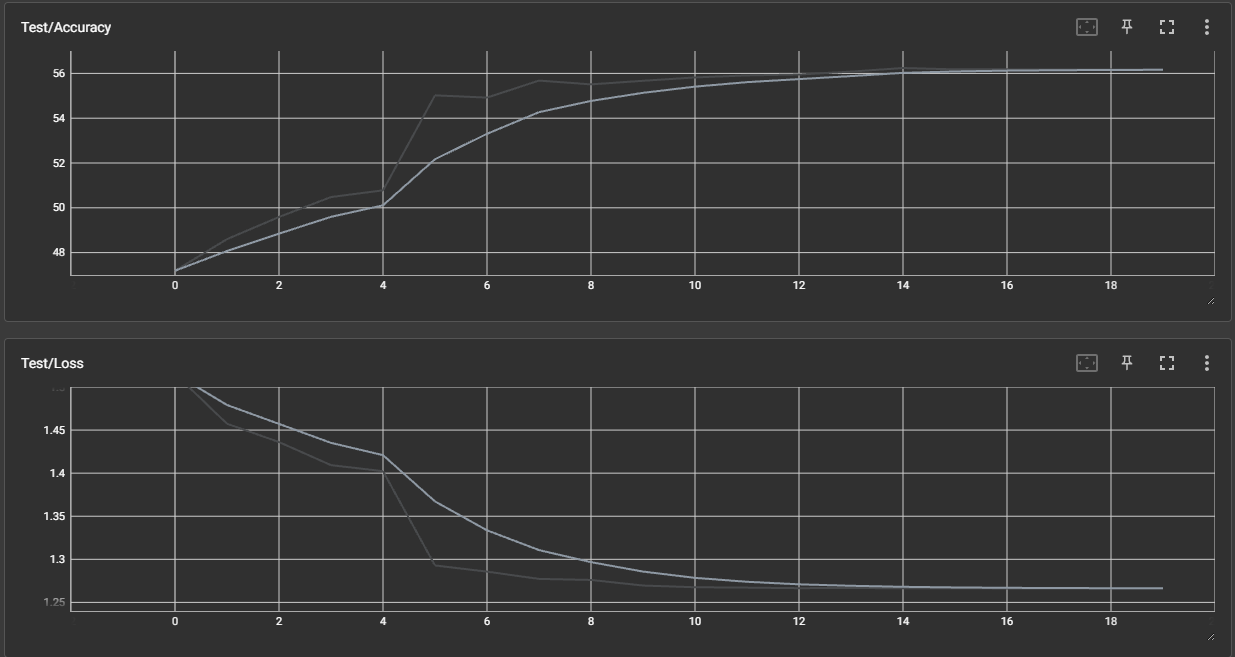

@浙大疏锦行
相关文章:
DAY 45 超大力王爱学Python
来自超大力王的友情提示:在用tensordoard的时候一定一定要用绝对位置,例如:tensorboard --logdir"D:\代码\archive (1)\runs\cifar10_mlp_experiment_2" 不然读取不了数据 知识点回顾: tensorboard的发展历史和原理tens…...

UE5 音效系统
一.音效管理 音乐一般都是WAV,创建一个背景音乐类SoudClass,一个音效类SoundClass。所有的音乐都分为这两个类。再创建一个总音乐类,将上述两个作为它的子类。 接着我们创建一个音乐混合类SoundMix,将上述三个类翻入其中,通过它管理每个音乐…...
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...
Linux基础开发工具——vim工具
文章目录 vim工具什么是vimvim的多模式和使用vim的基础模式vim的三种基础模式三种模式的初步了解 常用模式的详细讲解插入模式命令模式模式转化光标的移动文本的编辑 底行模式替换模式视图模式总结 使用vim的小技巧vim的配置(了解) vim工具 本文章仍然是继续讲解Linux系统下的…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...
echarts使用graphic强行给图增加一个边框(边框根据自己的图形大小设置)- 适用于无法使用dom的样式
pdf-lib https://blog.csdn.net/Shi_haoliu/article/details/148157624?spm1001.2014.3001.5501 为了完成在pdf中导出echarts图,如果边框加在dom上面,pdf-lib导出svg的时候并不会导出边框,所以只能在echarts图上面加边框 grid的边框是在图里…...
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...
麒麟系统使用-进行.NET开发
文章目录 前言一、搭建dotnet环境1.获取相关资源2.配置dotnet 二、使用dotnet三、其他说明总结 前言 麒麟系统的内核是基于linux的,如果需要进行.NET开发,则需要安装特定的应用。由于NET Framework 是仅适用于 Windows 版本的 .NET,所以要进…...

游戏开发中常见的战斗数值英文缩写对照表
游戏开发中常见的战斗数值英文缩写对照表 基础属性(Basic Attributes) 缩写英文全称中文释义常见使用场景HPHit Points / Health Points生命值角色生存状态MPMana Points / Magic Points魔法值技能释放资源SPStamina Points体力值动作消耗资源APAction…...
GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比Grap…...

Canal环境搭建并实现和ES数据同步
作者:田超凡 日期:2025年6月7日 Canal安装,启动端口11111、8082: 安装canal-deployer服务端: https://github.com/alibaba/canal/releases/1.1.7/canal.deployer-1.1.7.tar.gz cd /opt/homebrew/etc mkdir canal…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...

HTTPS证书一年多少钱?
HTTPS证书作为保障网站数据传输安全的重要工具,成为众多网站运营者的必备选择。然而,面对市场上种类繁多的HTTPS证书,其一年费用究竟是多少,又受哪些因素影响呢? 首先,HTTPS证书通常在PinTrust这样的专业平…...
Python环境安装与虚拟环境配置详解
本文档旨在为Python开发者提供一站式的环境安装与虚拟环境配置指南,适用于Windows、macOS和Linux系统。无论你是初学者还是有经验的开发者,都能在此找到适合自己的环境搭建方法和常见问题的解决方案。 快速开始 一分钟快速安装与虚拟环境配置 # macOS/…...
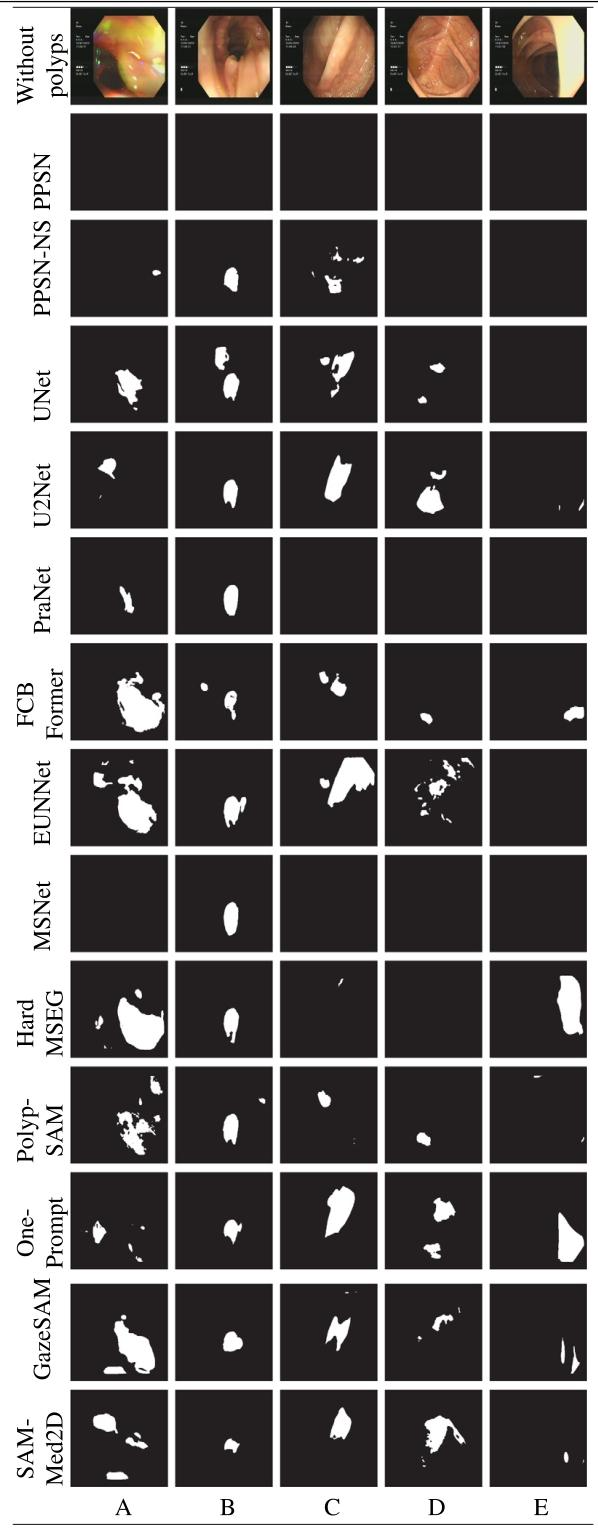
内窥镜检查中基于提示的息肉分割|文献速递-深度学习医疗AI最新文献
Title 题目 Prompt-based polyp segmentation during endoscopy 内窥镜检查中基于提示的息肉分割 01 文献速递介绍 以下是对这段英文内容的中文翻译: ### 胃肠道癌症的发病率呈上升趋势,且有年轻化倾向(Bray等人,2018&#x…...
结构化文件管理实战:实现目录自动创建与归类
手动操作容易因疲劳或疏忽导致命名错误、路径混乱等问题,进而引发后续程序异常。使用工具进行标准化操作,能有效降低出错概率。 需要快速整理大量文件的技术用户而言,这款工具提供了一种轻便高效的解决方案。程序体积仅有 156KB,…...
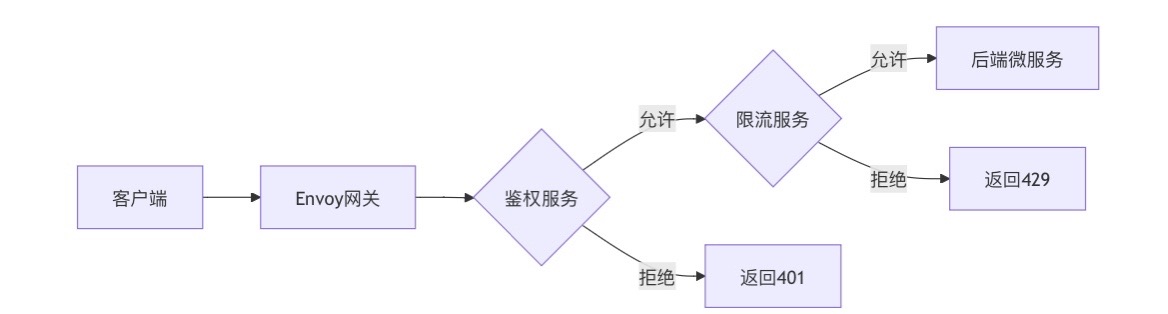
云原生安全实战:API网关Envoy的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关 作为微服务架构的统一入口,负责路由转发、安全控制、流量管理等核心功能。 2. Envoy 由Lyft开源的高性能云原生…...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...

Django RBAC项目后端实战 - 03 DRF权限控制实现
项目背景 在上一篇文章中,我们完成了JWT认证系统的集成。本篇文章将实现基于Redis的RBAC权限控制系统,为系统提供细粒度的权限控制。 开发目标 实现基于Redis的权限缓存机制开发DRF权限控制类实现权限管理API配置权限白名单 前置配置 在开始开发权限…...
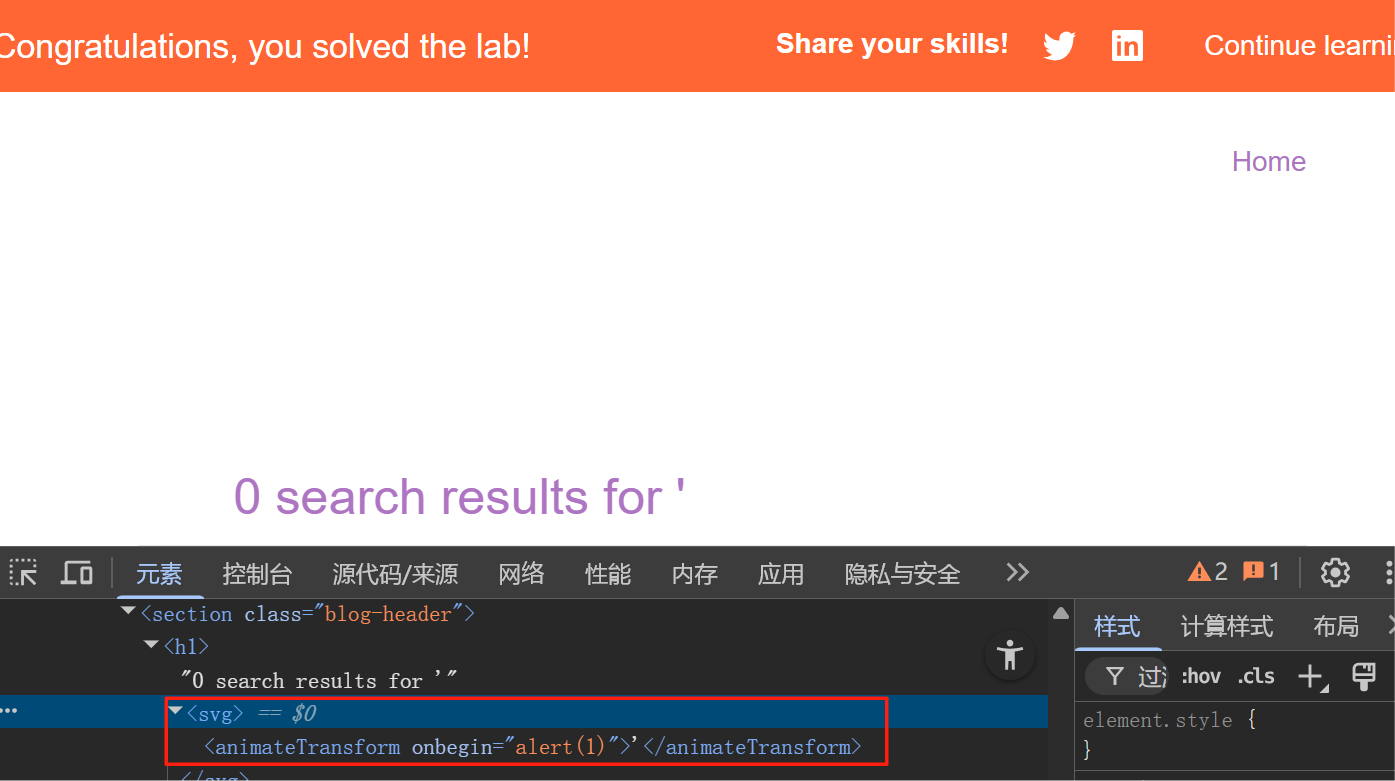
渗透实战PortSwigger Labs指南:自定义标签XSS和SVG XSS利用
阻止除自定义标签之外的所有标签 先输入一些标签测试,说是全部标签都被禁了 除了自定义的 自定义<my-tag onmouseoveralert(xss)> <my-tag idx onfocusalert(document.cookie) tabindex1> onfocus 当元素获得焦点时(如通过点击或键盘导航&…...
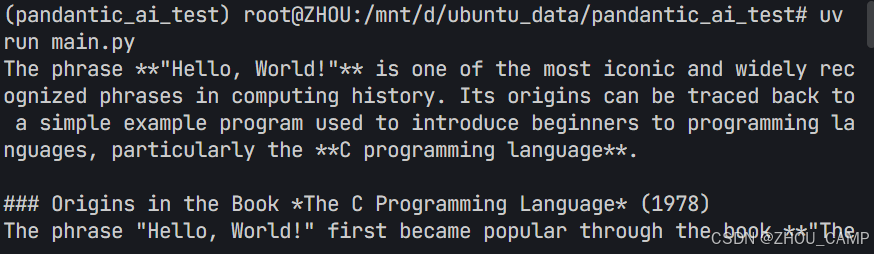
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...

GAN模式奔溃的探讨论文综述(一)
简介 简介:今天带来一篇关于GAN的,对于模式奔溃的一个探讨的一个问题,帮助大家更好的解决训练中遇到的一个难题。 论文题目:An in-depth review and analysis of mode collapse in GAN 期刊:Machine Learning 链接:...

数据分析六部曲?
引言 上一章我们说到了数据分析六部曲,何谓六部曲呢? 其实啊,数据分析没那么难,只要掌握了下面这六个步骤,也就是数据分析六部曲,就算你是个啥都不懂的小白,也能慢慢上手做数据分析啦。 第一…...
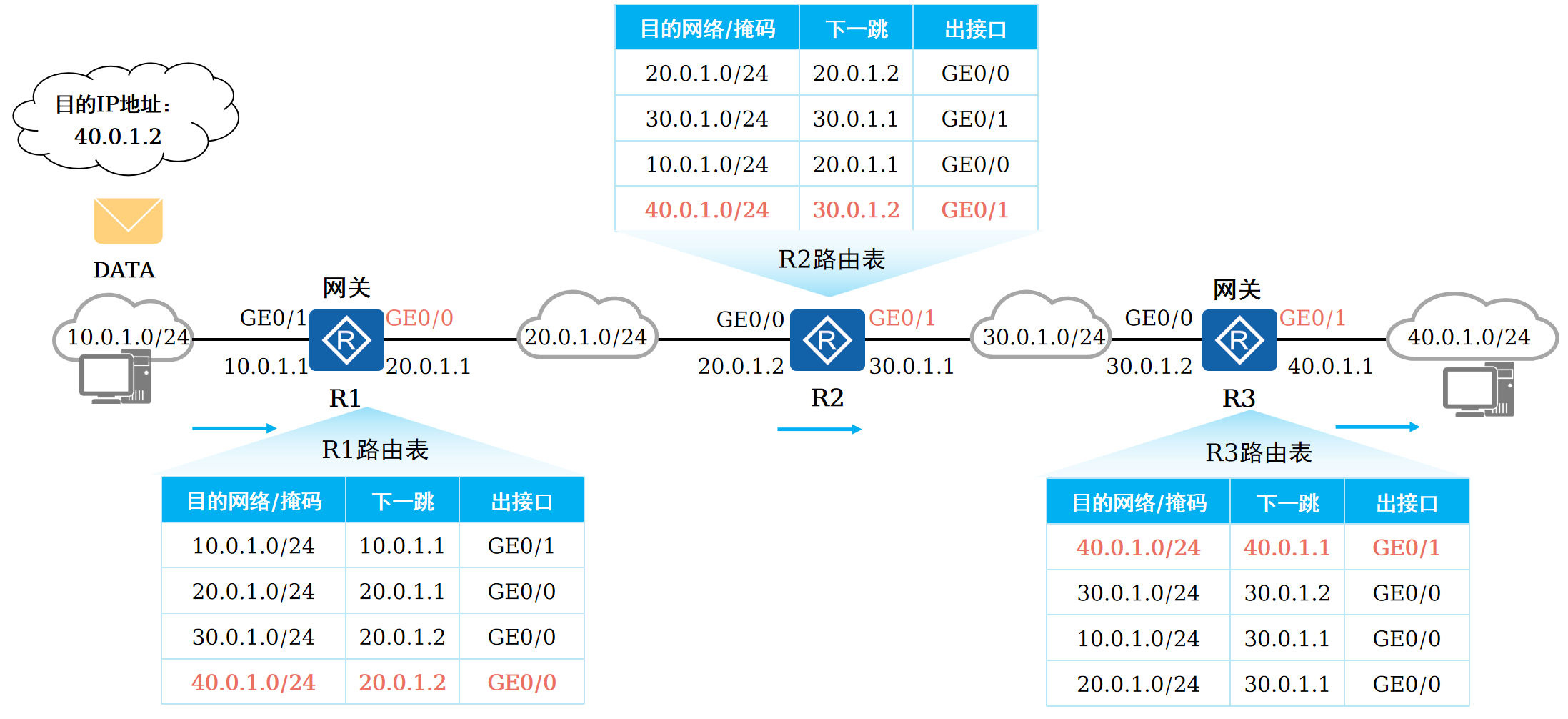
路由基础-路由表
本篇将会向读者介绍路由的基本概念。 前言 在一个典型的数据通信网络中,往往存在多个不同的IP网段,数据在不同的IP网段之间交互是需要借助三层设备的,这些设备具备路由能力,能够实现数据的跨网段转发。 路由是数据通信网络中最基…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...

React父子组件通信:Props怎么用?如何从父组件向子组件传递数据?
系列回顾: 在上一篇《React核心概念:State是什么?》中,我们学习了如何使用useState让一个组件拥有自己的内部数据(State),并通过一个计数器案例,实现了组件的自我更新。这很棒&#…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...

LangChain【6】之输出解析器:结构化LLM响应的关键工具
文章目录 一 LangChain输出解析器概述1.1 什么是输出解析器?1.2 主要功能与工作原理1.3 常用解析器类型 二 主要输出解析器类型2.1 Pydantic/Json输出解析器2.2 结构化输出解析器2.3 列表解析器2.4 日期解析器2.5 Json输出解析器2.6 xml输出解析器 三 高级使用技巧3…...

【深尚想】TPS54618CQRTERQ1汽车级同步降压转换器电源芯片全面解析
1. 元器件定义与技术特点 TPS54618CQRTERQ1 是德州仪器(TI)推出的一款 汽车级同步降压转换器(DC-DC开关稳压器),属于高性能电源管理芯片。核心特性包括: 输入电压范围:2.95V–6V,输…...