Spark编程实验四:Spark Streaming编程
目录
一、目的与要求
二、实验内容
三、实验步骤
1、利用Spark Streaming对三种类型的基本数据源的数据进行处理
2、利用Spark Streaming对Kafka高级数据源的数据进行处理
3、完成DStream的两种有状态转换操作
4、把DStream的数据输出保存到文本文件或MySQL数据库中
四、结果分析与实验体会
一、目的与要求
1、通过实验掌握Spark Streaming的基本编程方法;
2、熟悉利用Spark Streaming处理来自不同数据源的数据。
3、熟悉DStream的各种转换操作。
4、熟悉把DStream的数据输出保存到文本文件或MySQL数据库中。
二、实验内容
1、参照教材示例,利用Spark Streaming对三种类型的基本数据源的数据进行处理。
2、参照教材示例,完成kafka集群的配置,利用Spark Streaming对Kafka高级数据源的数据进行处理,注意topic为你的姓名全拼。
3、参照教材示例,完成DStream的两种有状态转换操作。
4、参照教材示例,完成把DStream的数据输出保存到文本文件或MySQL数据库中。
三、实验步骤
1、利用Spark Streaming对三种类型的基本数据源的数据进行处理
(1)文件流
首先打开第一个终端作为数据流终端,创建一个logfile目录:
[root@bigdata zhc]# cd /home/zhc/mycode/sparkstreaming
[root@bigdata sparkstreaming]# mkdir logfile
[root@bigdata sparkstreaming]# cd logfile
然后打开第二个终端作为流计算终端,在“/logfile/”目录下面新建一个py程序:
[root@bigdata logfile]# vim FileStreaming.py输入如下代码:
#/home/zhc/mycode/sparkstreaming/logfile/FileStreaming.pyfrom pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContextconf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream('file:///home/zhc/mycode/sparkstreaming/logfile')
words = lines.flatMap(lambda line: line.split(' '))
wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
保存该文件并执行如下命令:
[root@bigdata logfile]# spark-submit FileStreaming.py 然后我们进入数据流终端,在logfile目录下新建一个log2.txt文件,然后往里面输入一些英文语句后保存退出,再次切换到流计算终端,就可以看见打印出单词统计信息了。
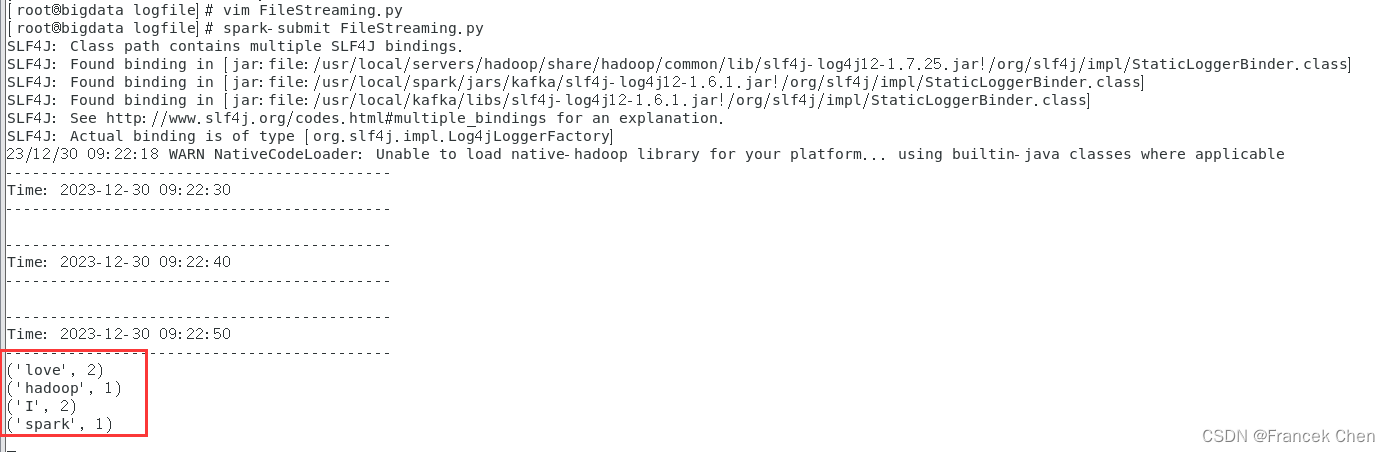
(2)套接字流
1)使用套接字流作为数据源
继续在流计算端的sparkstreaming目录下创建一个socket目录,然后在该目录下创建一个NetworkWordCount.py程序:
[root@bigdata sparkstreaming]# mkdir socket
[root@bigdata sparkstreaming]# cd socket
[root@bigdata socket]# vim NetworkWordCount.py
输入如下代码:
#/home/zhc/mycode/sparkstreaming/socket/NetworkWordCount.pyfrom __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContextif __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingNetworkWordCount")ssc = StreamingContext(sc, 5)lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b)counts.pprint()ssc.start()ssc.awaitTermination()
再在数据流终端启动Socket服务器端:
[root@bigdata logfile]# nc -lk 9999
然后再进入流计算终端,执行如下代码启动流计算:
[root@bigdata socket]# spark-submit NetworkWordCount.py localhost 9999
然后在数据流终端内手动输入一行英文句子后回车,多输入几次,流计算终端就会不断执行词频统计并打印出信息。

2)使用Socket编程实现自定义数据源
下面我们再前进一步,把数据源头的产生方式修改一下,不要使用nc程序,而是采用自己编写的程序产生Socket数据源。在数据流终端执行以下命令,编写DataSourceSocket.py文件:
[root@bigdata logfile]# cd /home/zhc/mycode/sparkstreaming/socket
[root@bigdata socket]# vim DataSourceSocket.py
输入如下代码:
#/home/zhc/mycode/sparkstreaming/socket/DataSourceSocket.py
import socket
# 生成socket对象
server = socket.socket()
# 绑定ip和端口
server.bind(('localhost', 9999))
# 监听绑定的端口
server.listen(1)
while 1:# 为了方便识别,打印一个“我在等待”print("I'm waiting the connect...")# 这里用两个值接受,因为连接上之后使用的是客户端发来请求的这个实例# 所以下面的传输要使用conn实例操作conn,addr = server.accept()# 打印连接成功print("Connect success! Connection is from %s " % addr[0])# 打印正在发送数据print('Sending data...')conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())conn.close()print('Connection is broken.')
继续在数据流终端执行如下命令启动Socket服务端:
[root@bigdata socket]# spark-submit DataSourceSocket.py
再进入流计算终端,执行如下代码启动流计算:
[root@bigdata socket]# spark-submit NetworkWordCount.py localhost 9999

(3)RDD队列流
继续在sparkstreaming目录下新建rddqueue目录并在该目录下创建RDDQueueStream.py程序:
[root@bigdata sparkstreaming]# mkdir rddqueue
[root@bigdata sparkstreaming]# cd rddqueue
[root@bigdata rddqueue]# vim RDDQueueStream.py
输入如下代码:
#/home/zhc/mycode/sparkstreaming/rddqueue/RDDQueueStreaming.py
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":sc = SparkContext(appName="PythonStreamingQueueStream")ssc = StreamingContext(sc, 2)#创建一个队列,通过该队列可以把RDD推给一个RDD队列流rddQueue = []for i in range(5):rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]time.sleep(1)#创建一个RDD队列流inputStream = ssc.queueStream(rddQueue)mappedStream = inputStream.map(lambda x: (x % 10, 1))reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)reducedStream.pprint()ssc.start()ssc.stop(stopSparkContext=True, stopGraceFully=True)
保存退出后,进入流计算终端再执行如下命令:
[root@bigdata rddqueue]# spark-submit RDDQueueStream.py
2、利用Spark Streaming对Kafka高级数据源的数据进行处理
此过程可以参照这篇博客的第四、五部分内容:
【数据采集与预处理】数据接入工具Kafka-CSDN博客![]() https://blog.csdn.net/Morse_Chen/article/details/135273370?spm=1001.2014.3001.5501
https://blog.csdn.net/Morse_Chen/article/details/135273370?spm=1001.2014.3001.5501
3、完成DStream的两种有状态转换操作
说明:上面的词频统计程序NetworkWordCount.py采取了无状态转换操作。
(1)滑动窗口转换操作
在socket目录下创建WindowedNetworkWordCount.py程序并输入如下代码:
#/home/zhc/mycode/sparkstreaming/socket/WindowedNetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: WindowedNetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingWindowedNetworkWordCount")ssc = StreamingContext(sc, 10)ssc.checkpoint("file:///home/zhc/mycode/sparkstreaming/socket/checkpoint")lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)counts.pprint()ssc.start()ssc.awaitTermination()
然后在数据流终端执执行如下命令运行nc程序:
[root@bigdata sparkstreaming]# cd /home/zhc/mycode/sparkstreaming/socket
[root@bigdata socket]# nc -lk 9999

然后再在流计算终端运行WindowedNetworkWordCount.py代码:
[root@bigdata socket]# spark-submit WindowedNetworkWordCount.py localhost 9999
这时,可以查看流计算终端内显示的词频动态统计结果,可以看到,随着时间的流逝,词频统计结果会发生动态变化。
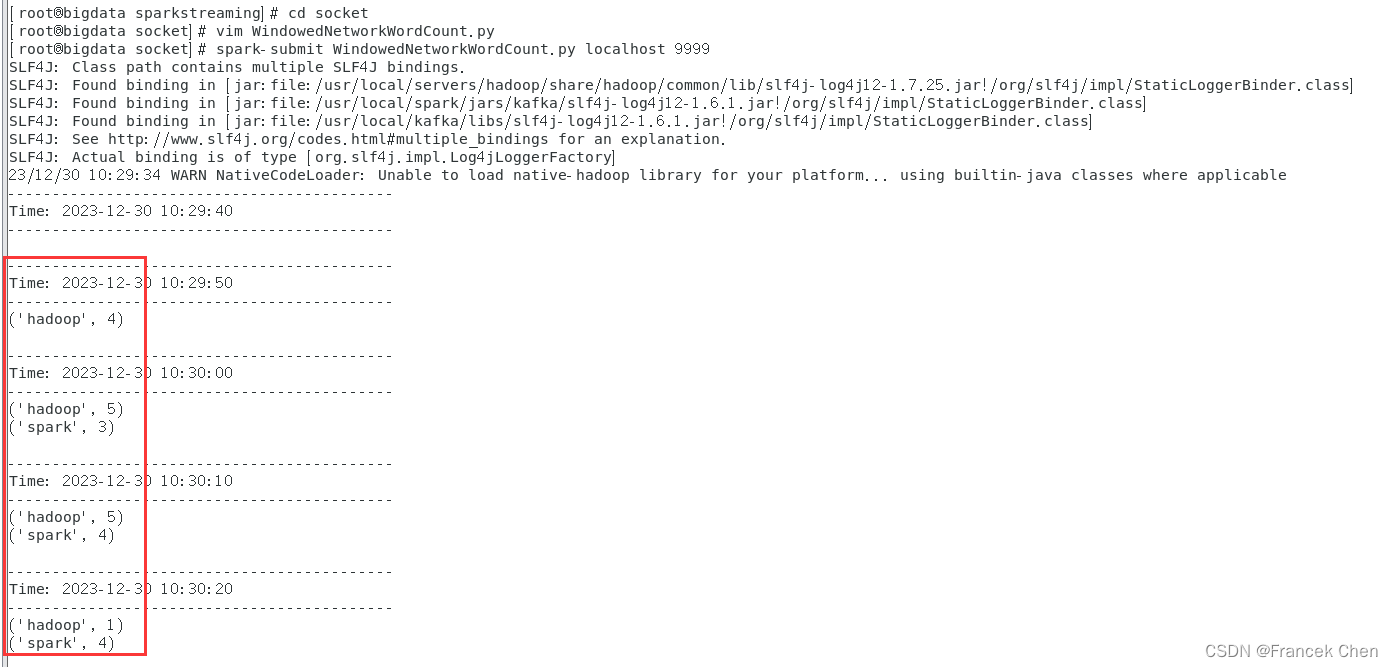
(2)updateStateByKey操作
在“/home/zhc/mycode/sparkstreaming/”路径下新建目录“/stateful”,并在该目录下新建代码文件NetworkWordCountStateful.py。
[root@bigdata sparkstreaming]# mkdir stateful
[root@bigdata sparkstreaming]# cd stateful
[root@bigdata stateful]# vim NetworkWordCountStateful.py
输入如下代码:
#/home/zhc/mycode/sparkstreaming/stateful/NetworkWordCountStateful.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")ssc = StreamingContext(sc, 1)ssc.checkpoint("file:///home/zhc/mycode/sparkstreaming/stateful/") # RDD with initial state (key, value) pairsinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD) running_counts.pprint()ssc.start()ssc.awaitTermination()
在“数据源终端”,执行如下命令启动nc程序:
[root@bigdata stateful]# nc -lk 9999
在“流计算终端”,执行如下命令提交运行程序:
[root@bigdata stateful]# spark-submit NetworkWordCountStateful.py localhost 9999
在数据源终端内手动输入一些单词并回车,再切换到流计算终端,可以看到已经输出了类似如下的词频统计信息:


4、把DStream的数据输出保存到文本文件或MySQL数据库中
(1)把DStream输出到文本文件中
在stateful目录下新建NetworkWordCountStatefulText.py文件:
[root@bigdata stateful]# vim NetworkWordCountStatefulText.py输入如下代码:
#/home/zhc/mycode/sparkstreaming/stateful/NetworkWordCountStatefulText.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")ssc = StreamingContext(sc, 1)ssc.checkpoint("file:///home/zhc/mycode/sparkstreaming/stateful/statefultext")# RDD with initial state (key, value) pairsinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD)running_counts.saveAsTextFiles("file:///home/zhc/mycode/sparkstreaming/stateful/statefultext/output")running_counts.pprint()ssc.start()ssc.awaitTermination()
在“数据源终端”,执行如下命令启动nc程序:
[root@bigdata stateful]# nc -lk 9999
在“流计算终端”,执行如下命令提交运行程序:
[root@bigdata stateful]# spark-submit NetworkWordCountStatefulText.py localhost 9999
在数据源终端内手动输入一些单词并回车,再切换到流计算终端,可以看到已经输出了类似如下的词频统计信息:


在“/home/zhc/mycode/sparkstreaming/stateful/statefultext”目录下便可查看到如下输出目录结果:

进入某个目录下,就可以看到类似part-00000的文件,里面包含了流计算过程的输出结果。

(2)把DStream写入到MySQL数据库中
首先启动MySQL数据库:
[root@bigdata stateful]# systemctl start mysqld.service
[root@bigdata stateful]# mysql -u root -p
然后创建spark数据库和wordcount表:
mysql> use spark;
mysql> create table wordcount (word char(20), count int(4));
然后再在终端安装python连接MySQL的模块:
[root@bigdata stateful]# pip3 install PyMySQL
在stateful目录并在该目录下创建NetworkWordCountStatefulDB.py文件:
[root@bigdata stateful]# vim NetworkWordCountStatefulDB.py输入如下代码:
#/home/zhc/mycode/sparkstreaming/stateful/NetworkWordCountStatefulDB.py
from __future__ import print_function
import sys
import pymysql
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: NetworkWordCountStateful <hostname> <port>", file=sys.stderr)exit(-1)sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")ssc = StreamingContext(sc, 1)ssc.checkpoint("file:///home/zhc/mycode/sparkstreaming/stateful/statefuldb") # RDD with initial state (key, value) pairsinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD) running_counts.pprint() def dbfunc(records):db = pymysql.connect(host="localhost",user="root",password="MYsql123!",database="spark")cursor = db.cursor() def doinsert(p):sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1]))try:cursor.execute(sql)db.commit()except:db.rollback()for item in records:doinsert(item) def func(rdd):repartitionedRDD = rdd.repartition(3)repartitionedRDD.foreachPartition(dbfunc)running_counts.foreachRDD(func)ssc.start()ssc.awaitTermination()
在“数据源终端”,执行如下命令启动nc程序:
[root@bigdata stateful]# nc -lk 9999
在“流计算终端”,执行如下命令提交运行程序:
[root@bigdata stateful]# spark-submit NetworkWordCountStatefulDB.py localhost 9999
在数据源终端内手动输入一些单词并回车,再切换到流计算终端,可以看到已经输出了类似如下的词频统计信息:


到MySQL终端便可以查看wordcount表中的内容:
mysql> select * from wordcount; .......
.......
四、结果分析与实验体会
Spark Streaming是一个用于实时数据处理的流式计算框架,它基于 Apache Spark 平台,提供了高可靠性、高吞吐量和容错性强等特点。在进行 Spark Streaming 编程的实验中,掌握了Spark Streaming的基本编程方法;能够利用Spark Streaming处理来自不同数据源的数据以及DStream的各种转换操作;把DStream的数据输出保存到文本文件或MySQL数据库中。
理解DStream:DStream 是 Spark Streaming 的核心概念,代表连续的数据流。在编程时,我们可以通过输入源(比如 Kafka、Flume、HDFS)创建一个 DStream 对象,并对其进行转换和操作。需要注意的是,DStream 是以时间片为单位组织数据的,因此在编写代码时要考虑时间窗口的大小和滑动间隔。
适当设置批处理时间间隔:批处理时间间隔决定了 Spark Streaming 处理数据的粒度,过小的时间间隔可能导致频繁的任务调度和资源开销,而过大的时间间隔则可能造成数据处理延迟。因此,在实验中需要根据具体场景和需求来选择合适的时间间隔。
使用合适的转换操作:Spark Streaming 提供了丰富的转换操作,如 map、flatMap、filter、reduceByKey 等,可以实现对数据流的转换和处理。在实验中,需要根据具体业务逻辑和需求选择合适的转换操作,并合理组合这些操作,以获取期望的结果。
考虑容错性和数据丢失:Spark Streaming 具备很好的容错性,可以通过记录数据流的偏移量来保证数据不会丢失。在实验中,需要注意配置合适的容错机制,确保数据处理过程中的异常情况能够被恢复,并尽量避免数据丢失。
优化性能和资源利用:对于大规模的实时数据处理任务,性能和资源利用是非常重要的。在实验中,可以通过调整并行度、合理设置缓存策略、使用广播变量等手段来提高性能和资源利用效率。
总的来说,Spark Streaming 是一个功能强大且易用的流式计算框架,通过合理使用其提供的特性和操作,可以实现各种实时数据处理需求。在实验中,需要深入理解其原理和机制,并根据具体需求进行合理配置和优化,以获得良好的性能和结果。
相关文章:
Spark编程实验四:Spark Streaming编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、利用Spark Streaming对三种类型的基本数据源的数据进行处理 2、利用Spark Streaming对Kafka高级数据源的数据进行处理 3、完成DStream的两种有状态转换操作 4、把DStream的数据输出保存到文本文件或MySQL数据库中 四…...

Flink去重计数统计用户数
1.数据 订单表,分别是店铺id、用户id和支付金额 "店铺id,用户id,支付金额", "shop-1,user-1,1", "shop-1,user-2,1", "shop-1,user-2,1", "shop-1,user-3,1", "shop-1,user-3,1", "shop-1,user…...
力扣:62. 不同路径(动态规划,附python二维数组的定义)
题目: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径&…...
2022年全球运维大会(GOPS深圳站)-核心PPT资料下载
一、峰会简介 GOPS 主要面向运维行业的中高端技术人员,包括运维、开发、测试、架构师等群体。目的在于帮助IT技术从业者系统学习了解相关知识体系,让创新技术推动社会进步。您将会看到国内外知名企业的相关技术案例,也能与国内顶尖的技术专家…...

8868体育助力意甲罗马俱乐部 迪巴拉有望付出
8868体育助力意甲罗马俱乐部 迪巴拉有望付出 意甲罗马俱乐部是8868体育合作球队之一,本赛季,在意甲第14轮的比赛中,罗马客场2-1战胜萨索洛,积分上升到意甲第4位。 有报道称,迪巴拉在对阵佛罗伦萨的比赛中受伤ÿ…...

java设计模式实战【策略模式+观察者模式+命令模式+组合模式,混合模式在支付系统中的应用】
引言 在代码开发的世界里,理论知识的重要性毋庸置疑,但实战经验往往才是知识的真正试金石。正所谓,“读万卷书不如行万里路”,理论的学习需要通过实践来验证和深化。设计模式作为软件开发中的重要理论,其真正的价值在…...

小程序wx:if 和hidden的区别?
在小程序中,wx:if 和 hidden 是用于条件渲染的两种不同方式。 选择使用哪种方式取决于具体情况。如果条件变化频繁或节点包含复杂的子节点,可以考虑使用 wx:if 进行条件渲染;如果条件变化较少且节点结构简单,可以使用 hidden 控制…...
自动驾驶学习笔记(二十三)——车辆控制模型
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo开放平台9.0专项技术公开课》免费报名—>传送门 文章目录 前言 运动学模型 动力学模型 总结…...

Linux Shell 015-文本双向覆盖重定向工具tee
Linux Shell 015-文本双向覆盖重定向工具tee 本节关键字:Linux、Bash Shell、文本双向覆盖重定向工具 相关指令:tee、echo、cat tee介绍 tee工具是从标准输入读取并写入到标准输出和文件,即:双向覆盖重定向(屏幕输出…...

【PyQt】(自定义类)QIcon派生,更易用的纯色Icon
嫌Qt自带的icon太丑,自己写了一个,主要用于纯色图标的自由改色。 当然,图标素材得网上找。 Qt原生图标与现代图标对比: 没有对比就没有伤害 Qt图标 网络素材图标 自定义类XJQ_Icon: from PyQt5.QtGui import QIc…...

【mysql】数据处理格式化、转换、判断
数据处理 判断是否超时,时间是否大于当前时间计算分钟数时间格式化处理如果数值类型进行转换字符类型字符拼接case-when代替if-else判断数据空(特殊:含空数据、空字符处理) select /*判断是否超时,时间是否大于当前…...

深入探索Java中的UDP网络通信机制
在网络通信中,UDP(User Datagram Protocol,用户数据报协议)是一种无连接的协议,它在某些情况下比TCP更适合,尤其是在要求速度快、对数据准确性要求相对较低的场景下。本文将介绍如何使用Java进行UDP网络通信…...

List常见方法和遍历操作
List集合的特点 有序: 存和取的元素顺序一致有索引:可以通过索引操作元素可重复:存储的元素可以重复 List集合的特有方法 Collection的方法List都继承了List集合因为有索引,所以有了很多操作索引的方法 ublic static void main…...
【基础篇】一、认识JVM
文章目录 1、虚拟机2、Java虚拟机3、JVM的整体结构4、Java代码的执行流程5、JVM的三大功能6、JVM的分类7、JVM的生命周期 1、虚拟机 虚拟机,Virtual Machine,一台虚拟的计算机,用来执行虚拟计算机指令。分为: 系统虚拟机&#x…...
DrGraph原理示教 - OpenCV 4 功能 - 颜色空间
前言 前段时间,甲方提出明确需求,让把软件国产化。稍微研究了一下,那就转QT开发,顺便把以前的功能代码重写一遍。 至于在Ubuntu下折腾QT、OpenCV安装事宜,网上文章很多,照猫画虎即可。 这个过程࿰…...

听GPT 讲Rust源代码--src/tools(36)
File: rust/src/tools/clippy/clippy_lints/src/loops/empty_loop.rs 在Rust源代码中,empty_loop.rs文件位于src/tools/clippy/clippy_lints/src/loops/目录下,它的作用是实现并提供一个名为EMPTY_LOOP的Lint规则。Clippy是一个Rust的静态分析工具&#…...
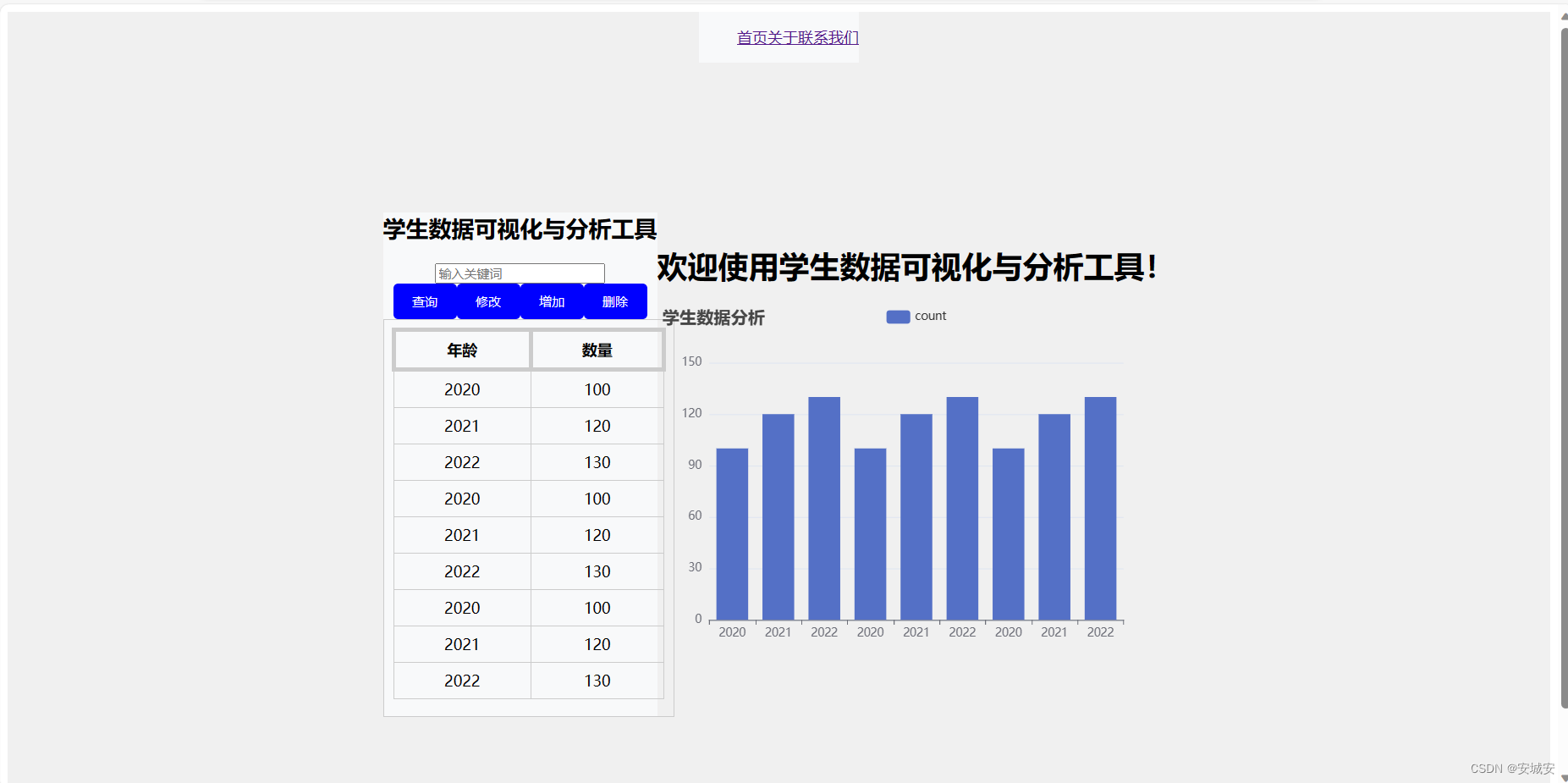
学生数据可视化与分析工具 vue3+flask实现
目录 一、技术栈亮点 二、功能特点 三、应用场景 四、结语 学生数据可视化与分析工具介绍 在当今的教育领域,数据驱动的决策正变得越来越重要。为了满足学校、教师和学生对于数据深度洞察的需求,我们推出了一款基于Vue3和Flask编写的学生数据可视化…...
uni-app condition启动模式配置
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...
网大为卸任腾讯CXO;Midjourney 1 月训练视频模型;2023年马斯克赚了7700亿
投融资 • 2023 年大型科技公司在生成式 AI 初创企业上的投资远超风险投资集团• 恒信东方与无锡政府合作成立布局 MR/XR 技术及 3D 数字资产 AIGC 产业投资基金• 新公司法完善注册资本认缴登记制度• 网大为卸任腾讯CXO,曾促成南非MIH的投资• 宁波蔚孚科技完成数…...

据报道,微软的下一代 Surface 笔记本电脑将是其首款真正的“人工智能 PC”
明年,微软计划推出 Surface Laptop 6和 Surface Pro 10,这两款设备将提供 Arm 和 Intel 两种处理器选项。不愿意透露姓名的不透露姓名人士透露,这些新设备将引入先进的人工智能功能,包括配备下一代神经处理单元 (NPU)。据悉&#…...

开源OmenSuperHub:解决惠普OMEN笔记本性能限制的完整技术方案
开源OmenSuperHub:解决惠普OMEN笔记本性能限制的完整技术方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 第一部分:技术挑战分…...

抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频
抖音无水印下载神器:douyin-downloader完整指南,轻松保存高清视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...
MySQL 大小管理 ——东方仙盟金丹期)
数据库优化(八)MySQL 大小管理 ——东方仙盟金丹期
1查询整个mysql下数据库大小SELECTtable_schema AS db_name,ROUND(SUM(data_length index_length)/1024/1024,2) AS size_mb FROM information_schema.tables GROUP BY table_schema ORDER BY size_mb DESC;| db_name | size_mb | -------------------------…...

告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来
告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

实战指南:如何通过Vosk API实现95%+准确率的离线语音识别系统
实战指南:如何通过Vosk API实现95%准确率的离线语音识别系统 【免费下载链接】vosk-api Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node 项目地址: https://gitcode.com/GitHub_Trending/vo/vosk-ap…...

基于EVE ESI API与AI Agent的自动化游戏监控与数据分析实践
1. 项目概述:为AI助手注入EVE宇宙的灵魂 如果你是一名《EVE Online》的玩家,同时又对AI自动化工具感兴趣,那么你很可能和我一样,长期被一个矛盾所困扰:一方面,EVE这个沙盒宇宙充满了需要监控和管理的日常事…...

IC场景XR全息通信_CSDN
6G IC场景XR/全息通信技术深度分析 摘要: 6G时代的沉浸式通信(Immersive Communication, IC)是实现"存在感"传输的核心场景,其中XR与全息通信技术对网络提出了Tbps级速率和亚毫秒级延迟的极限需求。本文从技术需求量化、…...

Jentic Mini:为AI智能体构建安全的API执行层与凭据管理方案
1. 项目概述:为AI智能体构建安全的API执行层 如果你正在开发AI智能体,并且希望它能帮你操作Notion、Slack、GitHub这些真实世界的服务,那你一定遇到过这个核心难题:怎么把API密钥安全地交给它?直接把密钥塞进提示词里&…...

制造业财务场景AI自动化方案,主流厂商横向对比 —— 2026企业级智能体选型全景盘点
进入2026年,全球制造业正处于从“自动化”向“智能共生”跨越的关键节点。 财务部门作为企业的数据中枢,其AI自动化方案已不再局限于早期的OCR识别或简单的流程脚本。 随着大模型(LLM)与智能体(Agent)技术的…...

C# 图像清晰度“核武器”:8个PictureBox永不模糊的硬核实战技巧
在 Windows Forms 开发中,PictureBox 是我们展示视觉效果的窗口。然而,你是否曾因为图片在缩放或背景色不匹配时变得模糊、锯齿横生,甚至出现难看的“黑边”而感到抓狂?这不仅影响用户体验,更是对完美主义开发者的一种…...