WeNet语音识别分词制作词云图
在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错
介绍
本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代码示例中的不同部分,并解释其如何实现音频处理、语音识别和文本可视化等功能。
代码概览
首先,让我们来看一下这个应用的主要功能和组成部分:
-
导入必要的库和模型加载
import streamlit as st import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from pydub import AudioSegment from noisereduce import reduce_noise import wenet import base64 import os在这一部分,我们导入了必要的 Python 库,包括 Streamlit、jieba(用于中文分词)、WordCloud(用于生成词云)、matplotlib(用于图表绘制)、pydub(用于音频处理)等。同时,我们还加载了 wenet 库,该库包含用于中英文语音识别的预训练模型。
-
语音识别的函数定义
def recognition(audio, lang='CN'):# 识别语音内容并返回文本# ...这个函数利用 wenet 库中的预训练模型,根据上传的音频文件进行语音识别。根据用户选择的语言(中文或英文),函数返回识别出的文本。
-
音频处理函数定义
def reduce_noise_and_export(input_file, output_file):# 降噪并导出处理后的音频文件# ...这个函数对上传的音频文件进行降噪处理,并导出处理后的音频文件,以提高语音识别的准确性。
-
关键词提取函数定义
def extract_keywords(result):# 提取识别文本中的关键词# ...此函数使用 jieba 库对识别出的文本进行分词,并返回关键词列表。
-
Base64 编码和下载链接函数定义
def save_base64(uploaded_file):# 将上传文件转换为 Base64 编码# ...def get_base64_link(file_path, link_text):# 生成下载处理后音频的 Base64 链接# ...这两个函数分别用于将上传的音频文件转换为 Base64 编码,并生成可下载处理后音频的链接。
-
主函数
main()def main():# Streamlit 应用的主要部分# ...主函数包含了 Streamlit 应用程序的主要逻辑,包括文件上传、语言选择、按钮触发的操作等。
-
运行主函数
if __name__ == "__main__":main()此部分代码确保主函数在运行时被调用。
应用程序功能
通过上述功能模块的组合,这个应用程序可以完成以下任务:
- 用户上传 WAV 格式的音频文件。
- 选择要进行的语言识别类型(中文或英文)。
- 降噪并处理上传的音频文件,以提高识别准确性。
- 对处理后的音频进行语音识别,返回识别结果。
- 从识别结果中提取关键词,并将其显示为词云图。
- 提供处理后音频的下载链接,方便用户获取处理后的音频文件。
希望这篇博客能够帮助你理解代码示例的每个部分,并激发你探索更多有趣应用的灵感!
streamlit应用程序
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')# 执行语音识别的函数
def recognition(audio, lang='CN'):if audio is None:return "输入错误!请上传音频文件!"if lang == 'CN':ans = chs_model.transcribe(audio)elif lang == 'EN':ans = en_model.transcribe(audio)else:return "错误!请选择语言!"if ans is None:return "错误!没有文本输出!请重试!"txt = ans['text']return txt# 降噪并导出处理后的音频的函数
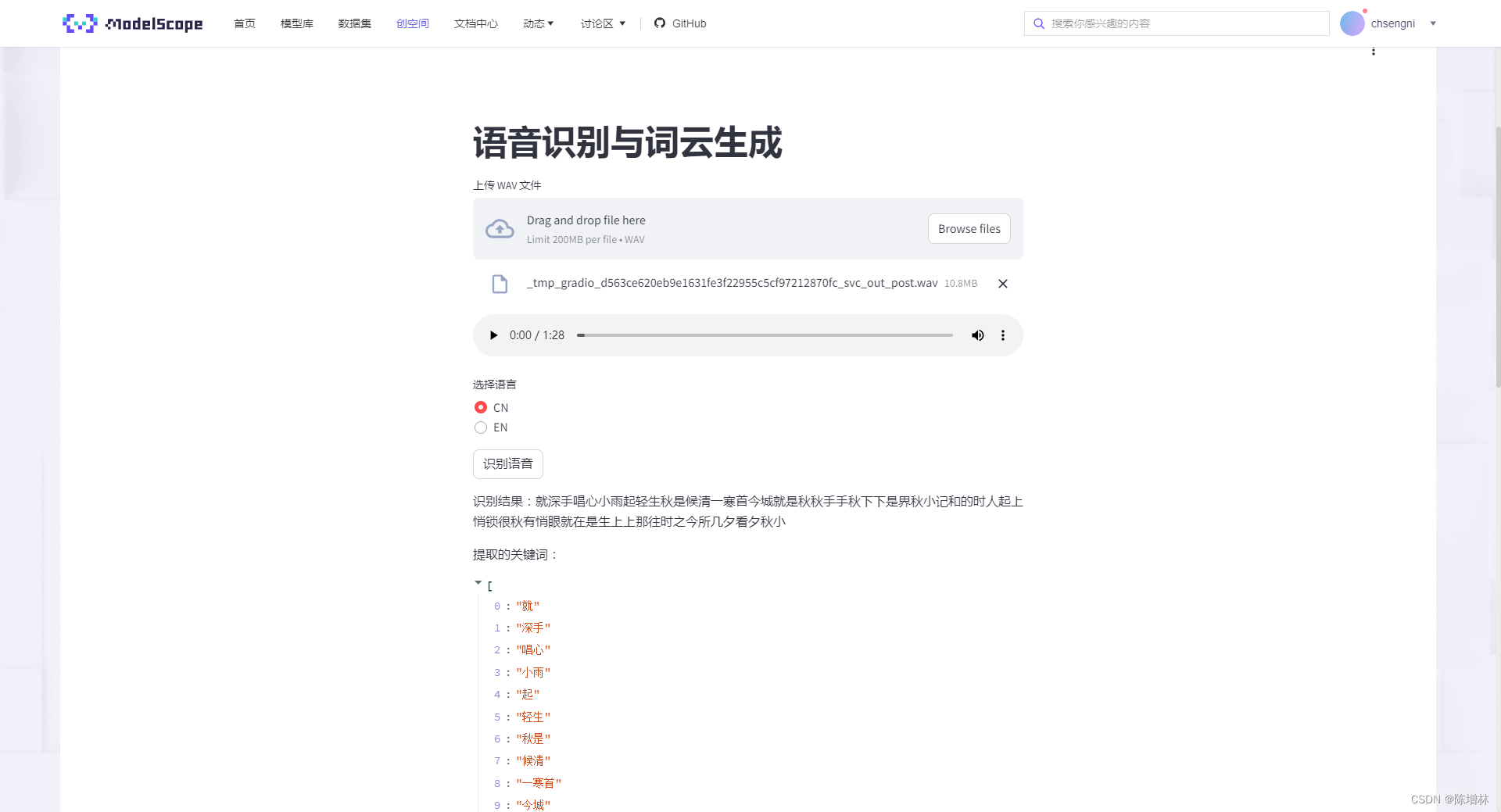
def reduce_noise_and_export(input_file, output_file):try:audio = AudioSegment.from_wav(input_file)audio_array = audio.get_array_of_samples()reduced_noise = reduce_noise(audio_array, audio.frame_rate)reduced_audio = AudioSegment(reduced_noise.tobytes(),frame_rate=audio.frame_rate,sample_width=audio.sample_width,channels=audio.channels)reduced_audio.export(output_file, format="wav")return output_fileexcept Exception as e:return f"发生错误:{str(e)}"def extract_keywords(result):word_list = jieba.lcut(result)return word_listdef save_base64(uploaded_file):with open(uploaded_file, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')return encodeddef main():st.title("语音识别与词云生成")uploaded_file = st.file_uploader("上传 WAV 文件", type="wav")if uploaded_file:st.audio(uploaded_file, format='audio/wav')language_choice = st.radio("选择语言", ('CN', 'EN'))bu=st.button("识别语音")if bu:if uploaded_file:output_audio_path = os.path.basename(uploaded_file.name)processed_audio_path = reduce_noise_and_export(uploaded_file, output_audio_path)if not processed_audio_path.startswith("发生错误"):result = recognition(processed_audio_path, language_choice)st.write("识别结果:" + result)keywords = extract_keywords(result)st.write("提取的关键词:", keywords)text = " ".join(keywords)wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())st.image(wc.to_array(), caption='词云')# 提供处理后音频的下载链接st.markdown(get_base64_link(processed_audio_path, '下载降噪音频'), unsafe_allow_html=True) else:st.warning("请上传文件")
def get_base64_link(file_path, link_text):with open(file_path, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'return hrefif __name__ == "__main__":main()
requirements.txt
wenet @ git+https://github.com/wenet-e2e/wenet
streamlit
wordcloud
pydub
jieba
noisereduce

体验链接: 长音频切换识别
import streamlit as st
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from pydub import AudioSegment
from noisereduce import reduce_noise
import wenet
import base64
import os
import numpy as np# 载入模型
chs_model = wenet.load_model('chinese')
en_model = wenet.load_model('english')# 执行语音识别的函数
def recognition(audio, lang='CN'):if audio is None:return "输入错误!请上传音频文件!"if lang == 'CN':ans = chs_model.transcribe(audio)elif lang == 'EN':ans = en_model.transcribe(audio)else:return "错误!请选择语言!"if ans is None:return "错误!没有文本输出!请重试!"txt = ans['text']return txtdef reduce_noise_segmented(input_file,chunk_duration_ms,frame_rate):try:audio = AudioSegment.from_file(input_file,format="wav")# 将双声道音频转换为单声道audio = audio.set_channels(1)# 压缩音频的帧率为 16000audio = audio.set_frame_rate(frame_rate)duration = len(audio)# 分段处理音频chunked_audio = []start = 0while start < duration:end = min(start + chunk_duration_ms, duration)chunk = audio[start:end]chunked_audio.append(chunk)start = endreturn chunked_audioexcept Exception as e:st.error(f"发生错误:{str(e)}")return Nonedef extract_keywords(result):word_list = jieba.lcut(result)return word_listdef get_base64_link(file_path, link_text):with open(file_path, "rb") as file:audio_content = file.read()encoded = base64.b64encode(audio_content).decode('utf-8')href = f'<a href="data:audio/wav;base64,{encoded}" download="processed_audio.wav">{link_text}</a>'return hrefdef main():st.title("语音识别与词云生成")uploaded_file = st.file_uploader("上传音乐文件", type="wav")if uploaded_file:st.audio(uploaded_file, format='audio/wav')segment_duration = st.slider("分段处理时长(毫秒)", min_value=1000, max_value=10000, value=5000, step=1000)frame_rate = st.slider("压缩帧率", min_value=8000, max_value=48000, value=16000, step=1000)language_choice = st.selectbox("选择语言", ('中文', '英文'))bu=st.button("识别语音")if bu:if uploaded_file:st.success("正在识别中,请稍等...")output_audio_path = os.path.basename(uploaded_file.name)chunked_audio = reduce_noise_segmented(uploaded_file, segment_duration, frame_rate)# 计算总的音频段数total_chunks = len(chunked_audio)if total_chunks>0:# 创建进度条progress_bar = st.progress(0)# 对每个音频段进行降噪并合并reduced_noise_chunks = []result_array = []for i, chunk in enumerate(chunked_audio):audio_array = chunk.get_array_of_samples()reduced_noise = reduce_noise(np.array(audio_array), chunk.frame_rate)reduced_chunk = AudioSegment(reduced_noise.tobytes(),frame_rate=chunk.frame_rate,sample_width=chunk.sample_width,channels=chunk.channels)reduced_noise_chunks.append(reduced_chunk)language=""if language_choice=='中文':language="CN"else:language="EN"path="第"+str(i+1)+"段音频.wav"reduced_chunk.export(path,format="wav")while os.path.exists(path):result = recognition(path, language)if result:st.write(f"第{i+1}段音频识别结果:" + result)result_array.append(result)break# 更新进度条的值progress = int((i + 1) / total_chunks * 100)progress_bar.progress(progress)st.write("识别的结果为:","".join(result_array))keywords = extract_keywords("".join(result_array))st.write("提取的关键词:", keywords)text=" ".join(keywords)wc = WordCloud(font_path="SimSun.ttf",collocations=False, width=800, height=400, margin=2, background_color='white').generate(text.lower())st.image(wc.to_array(), caption='词云')# 合并降噪后的音频段reduced_audio = reduced_noise_chunks[0]for i in range(1, len(reduced_noise_chunks)):reduced_audio += reduced_noise_chunks[i]# 导出处理后的音频文件reduced_audio.export(output_audio_path,format="wav")while os.path.exists(output_audio_path):# 提供处理后音频的下载链接st.markdown(get_base64_link(output_audio_path, '下载降噪音频'), unsafe_allow_html=True) breakelse:st.warning("请上传文件")if __name__ == "__main__":main()
相关文章:
WeNet语音识别分词制作词云图
在线体验 ,点击识别语音需要等待一会,文件太大缓存会报错 介绍 本篇博客将介绍如何使用 Streamlit、jieba、wenet 和其他 Python 库,结合语音识别(WeNet)和词云生成,构建一个功能丰富的应用程序。我们将深入了解代码…...
Proxyman:现代本地Web调试代理工具
1. 简介 1.1 什么是Proxyman? Proxyman是一款专为macOS设计的现代本地Web调试代理工具,它不仅支持macOS平台,还能无缝地与iOS和Android设备进行集成。作为一个网络调试工具,Proxyman的设计旨在提供高性能、直观且功能丰富的解决…...

k8s中DaemonSet实战详解
一、DaemonSet介绍 DaemonSet 的主要作用,是在 Kubernetes 集群里,运行一个 Daemon Pod。DaemonSet 只管理 Pod 对象,然后通过 nodeAffinity 和 Toleration 这两个调度器参数的功能,保证了每个节点上有且只有一个 Pod。 二、Daem…...

信号处理设计模式
问题 如何编写信号安全的应用程序? Linux 应用程序安全性讨论 场景一:不需要处理信号 应用程序实现单一功能,不需要关注信号 如:数据处理程序,文件加密程序,科学计算程序 场景二:需要处理信…...
Linux权限的基本理解
一:🚩Linux中的用户 1.1🥦用户的分类 🌟在Linux中用户可以被分为两种用户: 超级用户(root):可以在Linux系统中做各种事情而不被约束普通用户:只能做有限的事情被权限约束 在实际操作时超级用户的命令提示符为#,普通用户的命令提示符为$,可…...

AI人工智能大模型讲师叶梓《基于人工智能的内容生成(AIGC)理论与实践》培训提纲
【课程简介】 本课程介绍了chatGPT相关模型的具体案例实践,通过实操更好的掌握chatGPT的概念与应用场景,可以作为chatGPT领域学习者的入门到进阶级课程。 【课程时长】 1天(6小时/天) 【课程对象】 理工科本科及以上࿰…...

nat地址转换
原理 将内网地址转换成外网地址 方式 掌握动态NAT的配置方法 掌握Easy IP的配置方法 掌握NAT Server的配置方法 实验 r1 r2 是内网 ar1 ip地址 ip add ip地址 掩码 ip route-static 0.0.0.0 0 192.168.1.254 默认网关 吓一跳网关 相等于设置了网关 ar2 …...

第12课 循环综合举例
文章目录 前言一、循环综合举例1. 质数判断问题2. 百人百砖问题3. 猴子吃桃问题4. 质因数分解问题5. 数字统计问题。 二、课后练习2. 末尾3位数问题3. 求自然常数e4. 数据统计问题5. 买苹果问题。6. 找5的倍数问题。 总结 前言 本课使用循环结构,介绍了以下问题的解…...
Tuxera NTFS for Mac2024免费Mac读写软件下载教程
在日常生活中,我们使用Mac时经常会遇到外部设备不能正常使用的情况,如:U盘、硬盘、软盘等等一系列存储设备,而这些设备的格式大多为NTFS,Mac系统对NTFS格式分区存在一定的兼容性问题,不能正常读写。 那么什…...

C++ 具名要求
此页面中列出的具名要求,是 C 标准的规范性文本中使用的具名要求,用于定义标准库的期待。 某些具名要求在 C20 中正在以概念语言特性进行形式化。在那之前,确保以满足这些要求的模板实参实例化标准库模板是程序员的重担。若不这么做…...

大创项目推荐 深度学习二维码识别
文章目录 0 前言2 二维码基础概念2.1 二维码介绍2.2 QRCode2.3 QRCode 特点 3 机器视觉二维码识别技术3.1 二维码的识别流程3.2 二维码定位3.3 常用的扫描方法 4 深度学习二维码识别4.1 部分关键代码 5 测试结果6 最后 0 前言 🔥 优质竞赛项目系列,今天…...
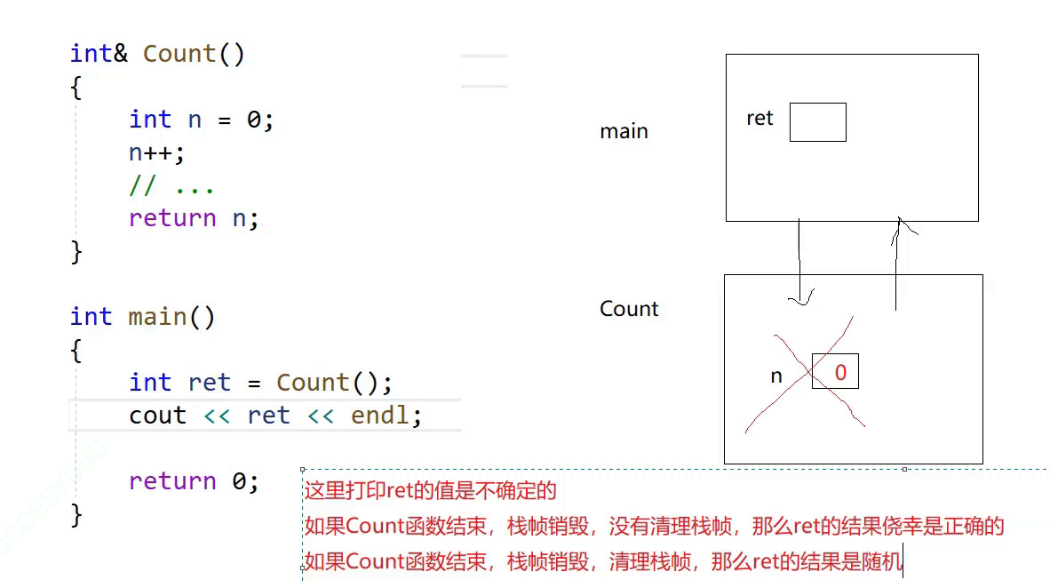
C++初阶——基础知识(函数重载与引用)
目录 1.命名冲突 2.命名空间 3.缺省参数 4.函数重载 1.函数重载的特点包括: 2.函数重载的好处包括: 3.引用 引用的特点包括 引用的主要用途包括 引用和指针 引用 指针 类域 命名空间域 局部域 全局域 第一个关键字 命名冲突 同一个项目之间冲…...
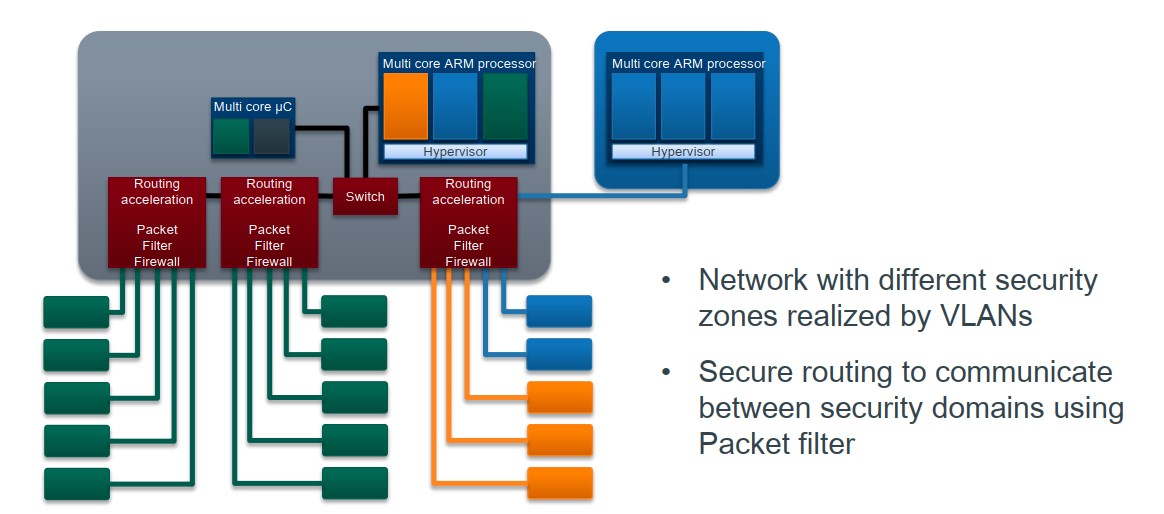
车载电子电器架构 —— 电子电气系统开发角色定义
车载电子电器架构 —— 电子电气系统开发角色定义 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 注:本文12000字,深度思考者进!!! 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的…...
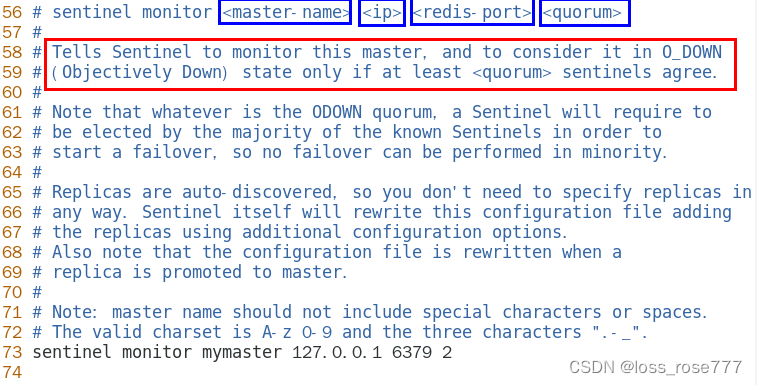
最新Redis7哨兵模式(保姆级教学)
一定一定要把云服务器的防火墙打开一定要!!!!!!!!!否则不成功!!!!!!!!&…...
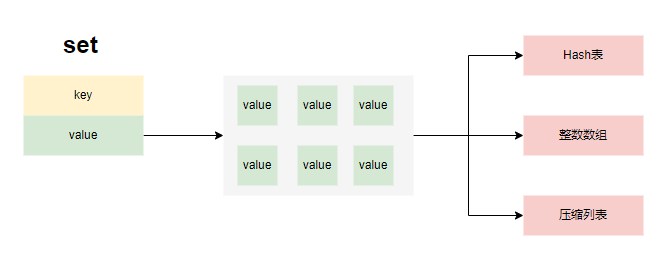
Redis原理及常见问题
高性能之道 单线程模型基于内存操作epoll多路复用模型高效的数据存储结构redis的单线程指的是数据处理使用的单线程,实际上它主要包含 IO线程:处理网络消息收发主线程:处理数据读写操作,包括事务、Lua脚本等持久化线程:执行RDB或AOF时,使用持久化线程处理,避免主线程的阻…...

nvm 的安装及使用 (Node版本管理器)
目录 1、nvm 介绍 2、nvm安装 3、nvm 使用 4、node官网可以查看node和npm对应版本 5、nvm安装指定版本node 6、安装cli脚手架 1、nvm 介绍 NVM 全称 node.js version management ,专门针对 node 版本进行管理的工具,通过它可以安装和切换不同版本的…...

【Yii2】数据库查询方法总结
目录 1.查找单个记录: 2.查找多个记录: 3.条件查询: 4.关联查询: 假设User模型有一个名为orders的多对一关联关系。 5.排序和分组: 6.数据操作: 7.事务处理: 8.命令查询: 9…...

区块链的三难困境是什么,如何解决?
人们需要保持社交、工作和睡眠之间的平衡,并且努力和谐相处。同样的概念也反映在区块链的三难困境中。 区块链三难困境是一个术语,指的是现有区块链的局限性:可扩展性、安全性和去中心化。这是一个存在了几十年的设计问题,其问题的…...
oCPC实践录 | oCPM的秘密
前言 笔者从这几方面介绍oCPM,并一一分析平台侧宣称的oCPM相比oCPC的优势,并解开其中的秘密。 1)什么是oCPM? 2)oCPC与oCPM的异同 3)平台宣称oCPM的优势 4)oCPM真正的秘密 5)oCPM下的点击率与…...

【Linux Shell学习笔记】Linux Shell的位置参数与函数
一、位置参数 位置参数,也被称之为位置变量,通过位置参数,可以在执行程序的时候,向程序传递数据 1.1 shell接收参数的方法 1.2 向shell传递参数的方法 二、函数 2.1 函数基础 2.1.1 函数简介 函数本质上就是一个代码块…...

EdgeDB监控告警:生产环境运维监控体系构建终极指南
EdgeDB监控告警:生产环境运维监控体系构建终极指南 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirrors/ed/edgedb EdgeDB是一…...
5分钟搞懂钢琴音区划分)
别再死记硬背了!用MIDI键盘和DAW软件(如FL Studio/Cubase)5分钟搞懂钢琴音区划分
别再死记硬背了!用MIDI键盘和DAW软件5分钟搞懂钢琴音区划分 第一次打开DAW的钢琴卷帘窗时,那些密密麻麻的C3、C4编号是否让你一头雾水?作为从乐队吉他手转型音乐制作的过来人,我完全理解这种困惑。传统教材里"小字组"&q…...
技术演进与核心论文全景解读)
综述篇 | 2015-2024,情绪识别(Emotion Recognition)技术演进与核心论文全景解读
1. 情绪识别技术演进全景图(2015-2024) 十年前,当研究人员试图通过摄像头分析人脸肌肉变化来判断情绪时,准确率还停留在60%左右。如今,结合多模态数据的情绪识别系统在特定场景下已突破90%准确率。这九年间的技术跃迁可…...

Orama混合搜索实战:从全文检索到向量搜索的轻量级实现
1. 项目概述:从“全文搜索”到“向量搜索”的现代演进如果你做过Web开发,尤其是需要处理大量文本内容的应用,比如博客站、文档中心或者电商平台,那么“搜索”功能绝对是你绕不开的核心需求。传统上,我们可能会直接想到…...

Qt 批量读取Excel数据:从性能瓶颈到优化实践
1. 为什么Qt读取Excel会卡成PPT? 第一次用Qt操作Excel表格时,我兴冲冲写了个循环读取单元格的代码。结果打开包含5000行数据的文件后,进度条像蜗牛爬坡,鼠标指针转成彩色圆圈,程序直接卡成PPT幻灯片模式——这场景估计…...
)
告别手动重命名!Win10下用记事本写个.bat脚本,5分钟搞定图片批量编号(001.jpg到999.jpg)
零基础玩转Windows批量重命名:用记事本5分钟打造专属文件编号神器 每次旅行归来或项目结束,手机相册里堆积如山的照片总让人头疼——"IMG_20230401_123456.jpg"这类毫无规律的命名,既难查找又难管理。专业摄影师和自媒体博主们早就…...
)
从B站视频到跑通代码:手把手复现大疆C板控制M2006电机的完整流程(STM32CubeMX + C610电调)
大疆C板驱动M2006电机全流程解析:从CubeMX配置到CAN通信实战 第一次拿到大疆RoboMaster C板时,看着官方文档和一堆外设确实有点无从下手。特别是当需要控制M2006这种高性能电机时,文档中的信息分散在不同章节,而社区里的完整教程又…...

如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 [特殊字符]
如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 🔥 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mi…...

性价比高可代理的油烟分离油烟机的厂家
最近跟10多个开厨电店的老板喝茶,一半人唉声叹气:去年赚的钱全压库存里了,3个做了十几年的老老板说,再找不到好产品,今年打算把店转了。为啥好好的店做成这样?说白了就是选品选错了,风口变了&am…...

Arm Development Studio 2023.1入门:构建Hello World项目
1. Arm Development Studio 2023.1入门指南:从零开始构建Hello World项目作为一名嵌入式开发工程师,我深知选择正确的开发工具对于项目成功的重要性。Arm Development Studio(简称Arm DS)作为Arm官方推出的集成开发环境࿰…...