【头歌实训】Spark 完全分布式的安装和部署
文章目录
- 第1关: Standalone 分布式集群搭建
- 任务描述
- 相关知识
- 课程视频
- Spark分布式安装模式
- 示例集群信息
- 配置免密登录
- 准备Spark安装包
- 配置环境变量
- 修改 spark-env.sh 配置文件
- 修改 slaves 文件
- 分发安装包
- 启动spark
- 验证安装
- 编程要求
- 测试说明
- 答案代码
- 报错问题
- 基本过程
第1关: Standalone 分布式集群搭建
任务描述
掌握 Standalone 分布式集群搭建。
相关知识
我们已经掌握了 Spark 单机版安装,那么分布式集群怎么搭建呢? 接下来我们学习 Standalone 分布式集群搭建。
课程视频
如果你需要在本地配置 Spark 完全分布式环境,可以通过查看课程视频来学习。
课程视频《克隆虚拟机与配置网络》
课程视频《配置集群免密登录》
课程视频《Spark配置文件设置》
课程视频《Spark完全分布式总结》
Spark分布式安装模式
Spark 分布式环境安装目前有四种模式:
1.Standalone:Spark 自带的简单群资源管理器,安装较为简单,不需要依赖 Hadoop;
2.Hadoop YARN:使用 YARN 作为集群资源管理,安装需要依赖 Hadoop;
3.Apache Mesos:不常用;
4.Kubernetes:不常用。
本地学习测试我们常用 Standalone 模式,生产环境常使用 YARN 模式。
示例集群信息
以下表格为本教程所用示例集群节点信息:
| 节点名称 | 节点角色 |
|---|---|
| master | worker,master |
| slave1 | worker |
| slave2 | worker |
我们准备了三台虚拟服务器,连接方式如下:
| 服务器 | SSH | 密码 | ip |
|---|---|---|---|
| master | ssh 172.18.0.2 | 123456 | 172.18.0.2 |
| slave1 | ssh 172.18.0.3 | 123456 | 172.18.0.3 |
| slave2 | ssh 172.18.0.4 | 123456 | 172.18.0.4 |
第一步我们需要在 evassh 服务器初始化虚拟服务器:
cd /home
wrapdocker
ulimit -f 1024000
docker load -i hbase-ssh2_v1.0.tar
docker-compose up -d
注意:请不要在各个虚拟服务器之间进行 ssh 登录,这种操作会导致无法保存配置数据。正确方法是:在虚拟服务器里执行 exit 后回到 evassh 服务器,再按上述方法登录各虚拟服务器。
配置免密登录
Hadoop 集群在启动脚本时,会去启动各个节点,此过程是通过 SSH 去连接的,为了避免启动过程输入密码,需要配置免密登录。
1、分别在 master、slave1、slave 生成密钥,命令如下:
ssh-keygen -t rsa
2、 在 master 复制 master、slave1、slave2 的公钥。
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh root@slave1 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh root@slave2 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
3、 分别在 slave1、slave2 复制 master 的 authorized_keys 文件。
ssh root@master cat ~/.ssh/authorized_keys>> ~/.ssh/authorized_keys
到此,免密已经成功,可以在各个虚拟服务器之间进行 ssh 登录,而不需要输入密码了。
准备Spark安装包
把 evassh 服务器的 /usr/local 目录下的 spark 安装包通过 SCP 命令上传到 master 虚拟服务器的 /usr/local 目录下。
scp -r /usr/local/spark-2.3.4-bin-hadoop2.7 root@172.18.0.2:/usr/local
密码为:123456。
配置环境变量
我们将 Spark 的安装目录配置到 /etc/profile 中(在文件末尾添加)。
不要忘了 source /etc/profile。
该步骤所有虚拟服务器节点均可执行。
修改 spark-env.sh 配置文件
首先生成一份 spark-env.sh 文件(master节点):
切换目录到:/usr/local/spark-2.3.4-bin-hadoop2.7/conf 执行命令:mv spark-env.sh.template spark-env.sh
修改 spark-env.sh 文件:
执行命令:vi spark-env.sh,添加以下内容:
#指定JAVA安装路径/usr/lib/jvm/jdk1.8.0_111
export JAVA_HOME=java安装路径
#指定SCALA安装位置,非必须配置,可不指定
export SCALA_HOME=scala安装路径
#指定spark master webui 端口,默认是 8080,跟 tomcat 冲突
SPARK_MASTER_WEBUI_PORT=8888
#指定Master节点IP或映射地址
export SPARK_MASTER_IP=master节点IP或映射地址
修改 slaves 文件
首先生成一份 slaves 文件(master节点)。
切换到 Spark 的 conf 目录下, 执行命令: mv slaves.template slaves
修改 slaves 文件, 执行命令: vi slaves 在该文件中加入作为 worker 节点 ip 或映射主机名。
master
slave1
slave2
分发安装包
把 master 节点的 spark 安装包分发到 slave1 节点和 slave2 节点(通过 scp 命令)。
scp -r spark-2.3.4-bin-hadoop2.7/ root@slave1:/usr/local
启动spark
切换到 master 节点安装目录的 /sbin 目录下 执行命令启动 Spark 集群:./start-all.sh
验证安装
输入 jps 命令查看。 master 节点有以下进程:
master
worker
slave1 节点有以下进程:
worker
slave2 节点有以下进程:
worker
编程要求
请按照步骤小心安装,安装完成后点击测评即可。
测试说明
点击测评后,后台会通过curl http://172.18.0.2:8888/ 命令获取页面,并取其中部分内容来判定你是否安装成功。
预期输出:
<li><strong>Alive Workers:</strong> 3</li>
课程视频《 Spark 完全分布式搭建总结》
答案代码
报错问题
docker load -i hbase-ssh2_v1.0.tar 加载的镜像时间较长多等一会;
docker-compose up -d 创建并启动服务器,报错了多试几次(平台的问题),直到 master、slave1、slave2 几个服务器节点都启动,都能 ping 通就行,可以通过 docker ps -n 3 看看容器创建几个了;
如果运气不好创建一半的时候挂了,出现 /master 已经存在但是 master 服务器还没启动的情况,使用 docker rm master 把它删了重新 docker-compose up -d 创建,或者自己启动 docker start master,slave1、slave2 同理;
注意:使用 ssh 更换 educoder、master、slave1、slave2 几个服务器节点,没配置 IP 映射直接用 IP 访问。
避免来回切换,直接开四个命令行,在原来 educoder 的基础上再加三个命令行用于 master、slave1、slave2
# master
ssh 172.18.0.2
# slave1
ssh 172.18.0.3
# slave2
ssh 172.18.0.4
基本过程
- 加载并启动服务器;
- 进入
master、slave1、slave2三个节点配置免密登录; - 进入
educoder节点将Spark文件分发给master节点; - 在
master节点上配置好环境,再将Spark文件分发给slave1、slave2节点; - 运行
Spark
# step 1
cd /home
wrapdocker
ulimit -f 1024000
docker load -i hbase-ssh2_v1.0.tar
docker-compose up -d# step 2
# 172.18.0.2、172.18.0.3、172.18.0.4, password=123456
ssh-keygen -t rsa # Press Enter three times# 172.18.0.2
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh root@172.18.0.3 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh root@172.18.0.4 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys# 172.18.0.3、172.18.0.4
ssh root@172.18.0.2 cat ~/.ssh/authorized_keys>> ~/.ssh/authorized_keys# step 3: educoder
scp -r /usr/local/spark-2.3.4-bin-hadoop2.7 root@172.18.0.2:/usr/local# step 4: 172.18.0.2
vim /etc/profile# add
export SPARK_HOME=/usr/local/spark-2.3.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/binsource /etc/profilecd /usr/local/spark-2.3.4-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh# add
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111
export SPARK_MASTER_WEBUI_PORT=8888
export SPARK_MASTER_IP=172.18.0.2vi slaves# add(delete localhost if exists)
172.18.0.2
172.18.0.3
172.18.0.4# step 4: scp spark to slave1 and slave2
scp -r /usr/local/spark-2.3.4-bin-hadoop2.7/ root@172.18.0.3:/usr/local
scp -r /usr/local/spark-2.3.4-bin-hadoop2.7/ root@172.18.0.4:/usr/local# step 5: start
$SPARK_HOME/sbin/start-all.sh
相关文章:

【头歌实训】Spark 完全分布式的安装和部署
文章目录 第1关: Standalone 分布式集群搭建任务描述相关知识课程视频Spark分布式安装模式示例集群信息配置免密登录准备Spark安装包配置环境变量修改 spark-env.sh 配置文件修改 slaves 文件分发安装包启动spark验证安装 编程要求测试说明答案代码报错问题基本过程…...
Leetcode—86.分隔链表【中等】
2023每日刷题(六十九) Leetcode—86.分隔链表 实现代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* partition(struct ListNode* head, int x) {struct ListNode…...

淘宝/天猫商品API:实时数据获取与安全隐私保护的指南
一、引言 随着电子商务的快速发展,淘宝/天猫等电商平台已成为商家和消费者的重要交易场所。对于电商企业而言,实时掌握店铺商品的销售情况、库存状态等信息至关重要。然而,手动管理和更新商品信息既费时又费力。因此,淘宝/天猫提…...
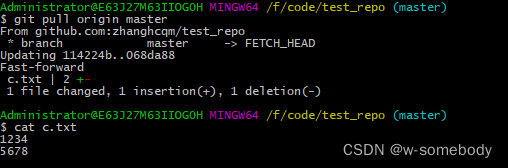
使用 SSH 方式实现 Git 远程连接GitHub
git是目前世界上最先进的分布式版本控制系统,相比于SVN,分布式版本系统的最大好处之一是在本地工作完全不需要考虑远程库的存在,也就是有没有联网都可以正常工作!当有网络的时候,再把本地提交推送一下就完成了同步&…...

Centos7部署Keepalived+lvs服务
IP规划: 服务器IP地址主服务器20.0.0.22/24从服务器20.0.0.24/24Web-120.0.0.26/24Web-220.0.0.27/24 一、主服务器安装部署keepalivedlvs服务 1、调整/proc响应参数 关闭Linux内核的重定向参数,因为LVS负载服务器和两个页面服务器需要共用一个VIP地…...
12/31
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 摘要Abstract文献阅读:用于密集预测的多路径视觉Transformer1、研究背景2、方法提出3、相关方法3.1、Vision Transformers for dense predictions3.2、C…...
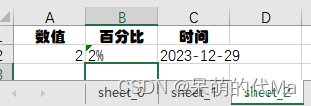
python使用openpyxl为excel模版填充数据,生成多个Sheet页面
目标:希望根据一个给定的excel模版,生成多个Sheet页面,比如模版: 示例程序 import openpyxlexcel_workbook openpyxl.load_workbook("模版.xlsx") for _i in range(3): # 比如填充3个页面# 复制模版sheet页&#x…...
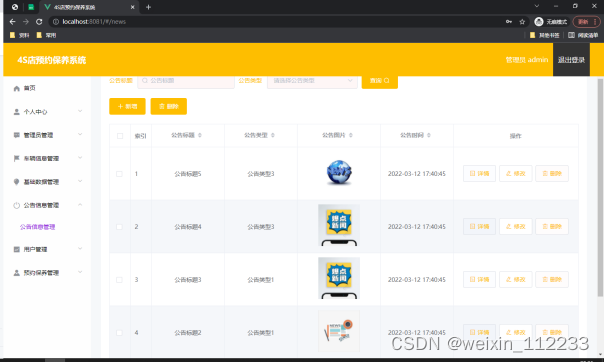
基于ssm的4S店预约保养系统开发+vue论文
目 录 目 录 I 摘 要 III ABSTRACT IV 1 绪论 1 1.1 课题背景 1 1.2 研究现状 1 1.3 研究内容 2 2 系统开发环境 3 2.1 vue技术 3 2.2 JAVA技术 3 2.3 MYSQL数据库 3 2.4 B/S结构 4 2.5 SSM框架技术 4 3 系统分析 5 3.1 可行性分析 5 3.1.1 技术可行性 5 3.1.2 操作可行性 5 3…...
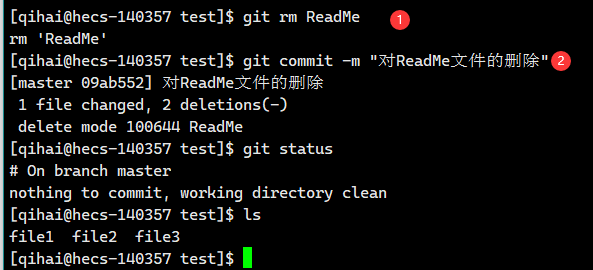
【Git】Git的基本操作
前言 Git是当前最主流的版本管理器,它可以控制电脑上的所有格式的文件。 它对于开发人员,可以管理项目中的源代码文档。(可以记录不同提交的修改细节,并且任意跳转版本) 本篇博客基于最近对Git的学习,简单介…...
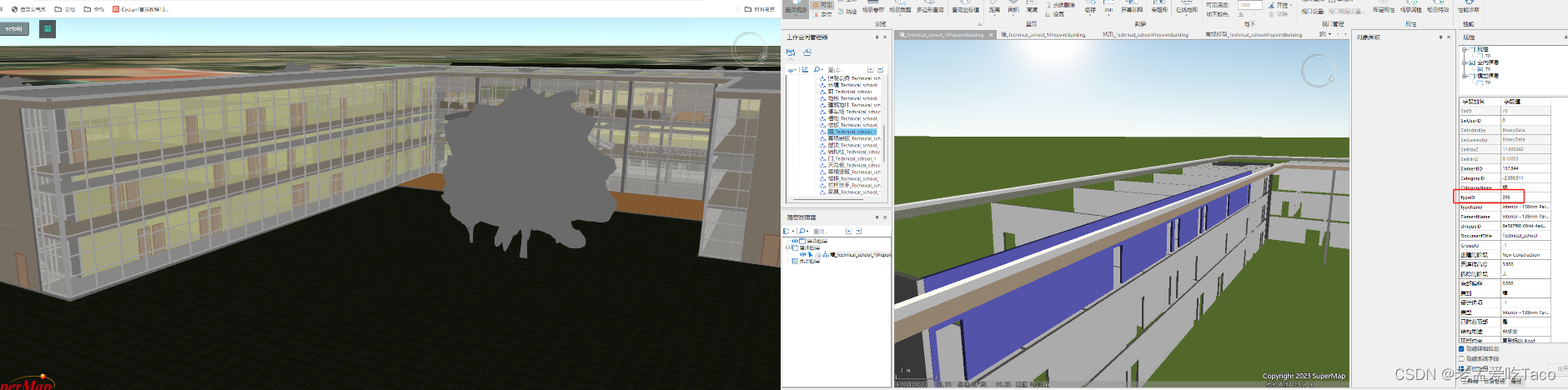
【超图】SuperMap iClient3D for WebGL/WebGPU —— 数据集合并缓存如何控制对象样式
作者:taco 最近在支持的过程中,遇到了一个新问题!之前研究功能的时候竟然没有想到。通常我们控制单个对象的显隐、颜色、偏移的参数都是根据对象所在的图层以及对象单独的id来算的。那么问题来了,合并后的图层。他怎么控制单个对象…...
intellij IDEA开发工具的使用(打开/关闭工程;删除类文件;修改类/包/模块/项目名称;导入/删除模块)
1,打开工程 打开IDEA,会看到如下界面 1栏目里是自己曾经打开过的project(工程),直接点击就好。如果需要打开其他工程,则点击open,会出下以下界面。 选择需要加载的project(工程&…...
抖音详情API:开发环境搭建与工具选择
随着短视频的流行,抖音已经成为了一个备受欢迎的社交媒体平台。对于开发人员而言,利用抖音详情API开发定制化的抖音应用具有巨大的潜力。本文将为你详细介绍开发抖音应用的开发环境搭建与工具选择,帮助你顺利地开始开发工作。 一、开发环境搭…...
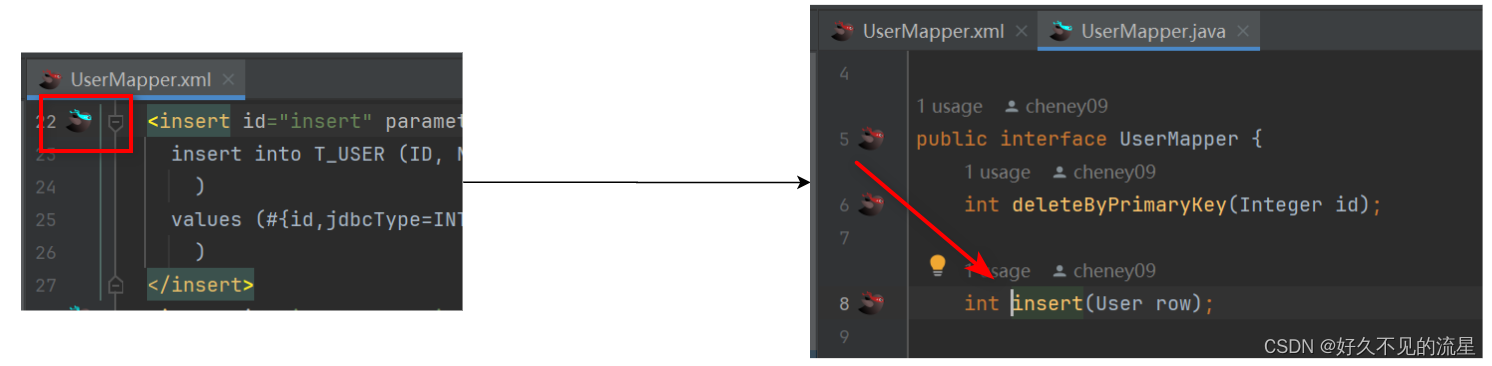
IntelliJ IDEA [插件 MybatisX] mapper和xml间跳转
文章目录 1. 安装插件2. 如何使用3. 主要功能总结 MybatisX 是一款为 IntelliJ IDEA 提供支持的 MyBatis 开发插件 它通过提供丰富的功能集,大大简化了 MyBatis XML 文件的编写、映射关系的可视化查看以及 SQL 语句的调试等操作。本文将介绍如何安装、配置和使用 In…...

Havenask 分布式索引构建服务 --Build Service
Havenask 是阿里巴巴智能引擎事业部自研的开源高性能搜索引擎,深度支持了包括淘宝、天猫、菜鸟、高德、饿了么在内几乎整个阿里的搜索业务。本文针对性介绍了 Havenask 分布式索引构建服务——Build Service,主打稳定、快速、易管理,是在线系…...
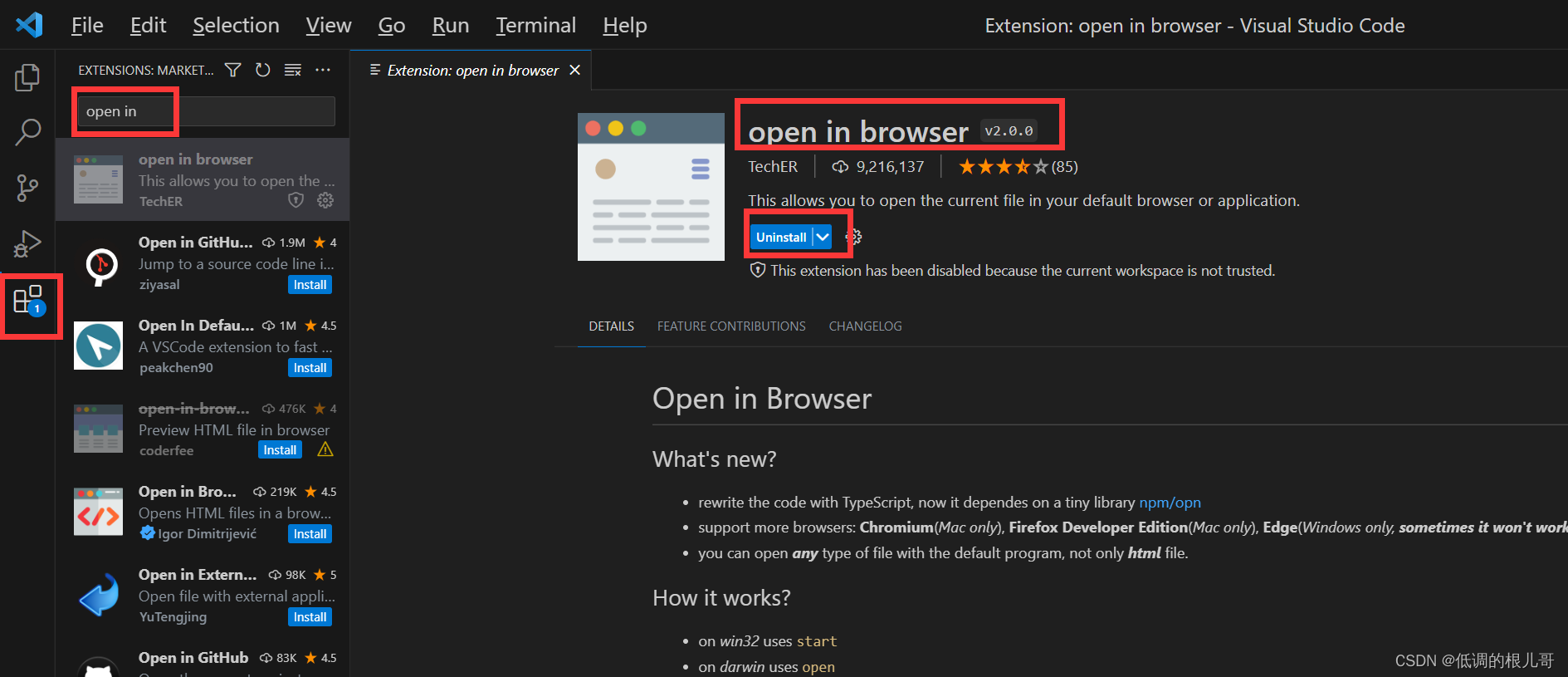
vscode软件安装步骤
目录 一、下载软件安装包 二、运行安装包后 一、下载软件安装包 打开vscode官方网址,找到下载界面 链接如下:Download Visual Studio Code - Mac, Linux, Windows 我是windows电脑,各位小伙伴自己选择合适的版本,点击下载按钮…...

C语言中灵活多变的动态内存,malloc函数 free函数 calloc函数 realloc函数
文章目录 🚀前言🚀管理动态内存的函数✈️malloc函数✈️free函数✈️calloc函数✈️realloc函数 🚀在使用动态内存函数时的常见错误✈️对NULL指针的解引用✈️ 对动态开辟空间的越界访问✈️对非动态开辟内存使用free释放✈️使用free释放一…...

小细节处理
重载运算符:重载<运算符。 bool operator<(const Edge&s)const{return w<s.w;}...

【42页动态规划学习笔记分享】动态规划核心原理详解及27道LeetCode相关经典题目汇总
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…...

Python正则的匹配与替换
import re 查找时的注意事项,要查找的内容左右两边打出来,用真正的字符,不要用.*?,离查找内容远一点,再用.*? a /aksj<a>哈哈哈<a><p>拉阿鲁<p>\.askjp b re.findall(<a>(.*?)<…...
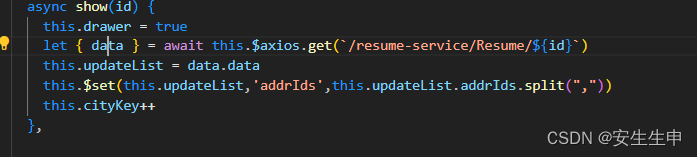
解决ELement-UI懒加载三级联动数据不回显(天坑)
最老是遇到这类问题头有点大,最后也是解决了,为铁铁们总结了一下几点 一.查看数据类型是否一致 未选择下 选择下 二.处理数据时使用this.$set方法来动态地设置实例中的属性,以确保其响应式 三.绑定v-if 确保每次重新加载 四.绑定key 五.完整代码...

ppt模板_0013_66tm黑色--运动
PPT模板分享...

如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 [特殊字符]
如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 🔥 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mi…...

OpencvSharp 算子学习教案之 - Cv2.Sobel
OpencvSharp 算子学习教案之 - Cv2.Sobel 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因此…...

VirtualBox 6.1+ 搭配Win10:除了装系统,这些高效设置让你的虚拟机真正好用起来
VirtualBox 6.1 与Win10深度整合:解锁专业级虚拟化生产力的5个关键策略 当你已经成功在VirtualBox中安装好Windows 10虚拟机,这仅仅是虚拟化旅程的起点。真正的高手懂得如何将这个看似隔离的环境转变为无缝融入日常工作流的生产力引擎。本文将揭示那些鲜…...

三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南
三步彻底解决Zotero中文文献管理的三大难题:茉莉花插件完整指南 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 你是否…...

深度解析开源AI工具库:OpenAI API封装库的设计与实战应用
1. 项目概述:一个开源AI工具库的深度解构最近在GitHub上看到一个名为“anasfik/openai”的项目,这个标题乍一看有点意思。它不像官方SDK那样直接叫“openai”,而是带上了个人或组织的命名空间前缀“anasfik/”。这通常意味着这是一个第三方封…...

10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南
10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏看不懂而烦恼吗?XUnity.AutoTranslator正是你需要的游戏…...

别再瞎写 Prompt 了:2026年最实用的10条LLM提示词技巧
别再瞎写 Prompt 了:2026年最实用的10条LLM提示词技巧强烈推荐收藏!从 OpenAI 官方指南到社区实践精华,每条技巧都附带 ❌ 错误示范 → ✅ 正确示范 → 💡 原理说明。这个问题你肯定遇到过 你打开 ChatGPT,输入&#x…...
)
西门子博图V17变量导入昆仑通态MCGS Pro的保姆级避坑指南(含DB块偏移量设置)
西门子博图V17与MCGS Pro高效数据对接实战指南 在工业自动化系统集成中,西门子TIA Portal(博图)与昆仑通态MCGS Pro触摸屏的数据交互是常见需求。许多工程师在变量导入环节频繁遭遇DB块偏移量异常、变量名截断、数据类型不匹配等"暗坑&q…...

Skill Library:AI智能体技能库的模块化设计与工程实践
1. 项目概述:一个为AI智能体打造的“技能武器库”如果你和我一样,每天都在和Claude、ChatGPT、Cursor这些AI工具打交道,那你肯定也经历过这样的时刻:想让AI帮你写个复杂的SQL查询、设计一个微服务架构,或者起草一份产品…...