【大数据面试知识点】Spark中的累加器
Spark累加器
累加器用来把Executor端变量信息聚合到Driver端,在driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行merge。
累加器一般是放在行动算子中进行操作的。
Spark累加器有哪些特点?
1)累加器在全局唯一的,只增不减,记录全局集群的唯一状态
2)在Executor中修改它,在Driver读取
3)executor级别共享的,广播变量是task级别的共享两个application不可以共享累加器,但是同一个app不同的job可以共享
应用举例
不经过Shuffle实现词频统计
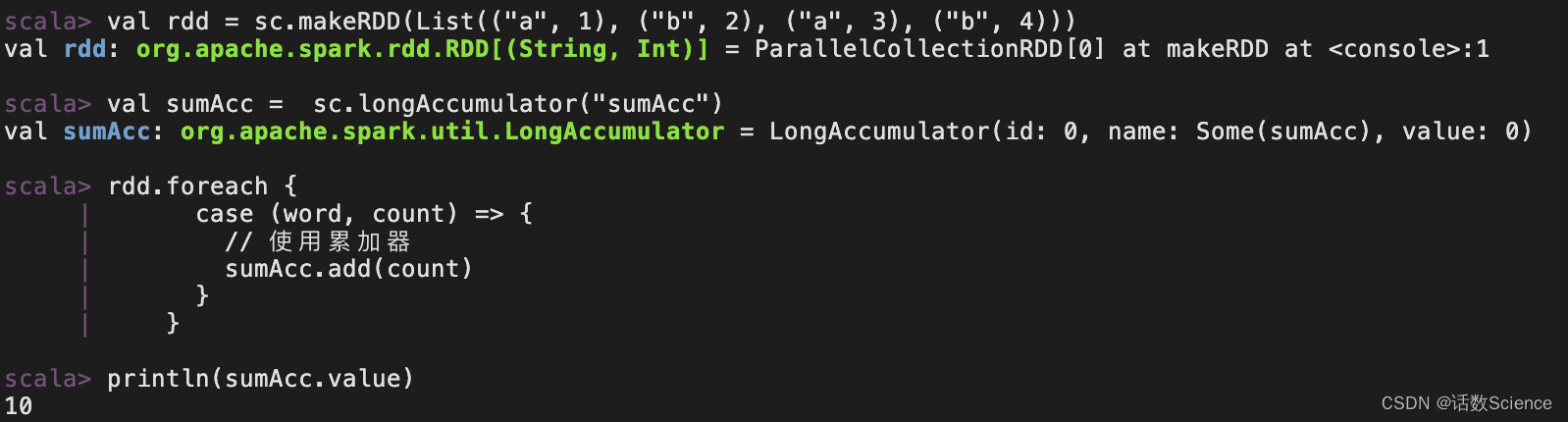
object Spark06_Accumulator {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")val sc = new SparkContext(conf)val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("a", 3), ("b", 4)))// 声明累加器val sumAcc: LongAccumulator = sc.longAccumulator("sumAcc")rdd.foreach {case (word, count) => {// 使用累加器sumAcc.add(count)}}// 累加器的toString方法//println(sumAcc)//取出累加器中的值println(sumAcc.value)sc.stop()}
}
不经过shuffle,计算以H开头的单词出现的次数。
object Spark07_MyAccumulator {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")val sc = new SparkContext(conf)val rdd: RDD[String] = sc.makeRDD(List("Hello", "HaHa", "spark", "scala", "Hi", "Hello", "Hi"))// 创建累加器val myAcc = new MyAccumulator//注册累加器sc.register(myAcc, "MyAcc")rdd.foreach{datas => {// 使用累加器myAcc.add(datas)}}// 获取累加器的结果println(myAcc.value)sc.stop()}
}// 自定义累加器
// 泛型分别为输入类型和输出类型
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Int]] {// 定义输出数据变量var map: mutable.Map[String, Int] = mutable.Map[String, Int]()// 累加器是否为初始状态override def isZero: Boolean = map.isEmpty// 复制累加器override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {val MyAcc = new MyAccumulator// 将此累加器中的数据赋值给新创建的累加器MyAcc.map = this.mapMyAcc}// 重置累加器override def reset(): Unit = {map.clear()}// 累加器添加元素override def add(v: String): Unit = {if (v.startsWith("H")) {// 判断map集合中是否已经存在此元素map(v) = map.getOrElse(v, 0) + 1}}// 合并累加器中的元素override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {val map1: mutable.Map[String, Int] = this.mapval map2: mutable.Map[String, Int] = other.value// 合并两个mapmap = map1.foldLeft(map2) {(m, kv) => {m(kv._1) = m.getOrElse(kv._1, 0) + kv._2m}}}// 获取累加器中的值override def value: mutable.Map[String, Int] = {map}
}
参考:Spark累加器的作用和使用-CSDN博客
相关文章:
【大数据面试知识点】Spark中的累加器
Spark累加器 累加器用来把Executor端变量信息聚合到Driver端,在driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行merge。 累加器一般是放在行动算子…...

深度学习核心技术与实践之深度学习基础篇
非书中全部内容,只是写了些自认为有收获的部分 神经网络 生物神经元的特点 (1)人体各种神经元本身的构成很相似 (2)早期的大脑损伤,其功能可能是以其他部位的神经元来代替实现的 (3&#x…...

Kafka安装及简单使用介绍
🍓 简介:java系列技术分享(👉持续更新中…🔥) 🍓 初衷:一起学习、一起进步、坚持不懈 🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏 🍓 希望这篇文章对你有所帮助,欢…...
20231229在Firefly的AIO-3399J开发板的Android11使用挖掘机的DTS配置单前后摄像头ov13850
20231229在Firefly的AIO-3399J开发板的Android11使用挖掘机的DTS配置单前后摄像头ov13850 2023/12/29 11:10 开发板:Firefly的AIO-3399J【RK3399】 SDK:rk3399-android-11-r20211216.tar.xz【Android11】 Android11.0.tar.bz2.aa【ToyBrick】 Android11.…...

九台虚拟机网站流量分析项目启动步骤
文章目录 零、操作概述一、服务器分配二、9台虚拟机相互免密登录三、Nginx(反向代理服务器)四、Tomcat(Web服务器)五、测试Nginx反向代理是否成功六、Flume集群配置七、修改LogDemo项目八、项目1703FluxStorm九、Hadoop集群十、整个集群的启动十一、部署项目十二、测试项目…...

迅软科技助力高科技防泄密:从华为事件中汲取经验教训
近期,涉及华为芯片技术被窃一事引起广泛关注。据报道,华为海思的两个高管张某、刘某离职后成立尊湃通讯,然后以支付高薪、股权支付等方式,诱导多名海思研发人员跳槽其公司,并指使这些人员在离职前通过摘抄、截屏等方式…...
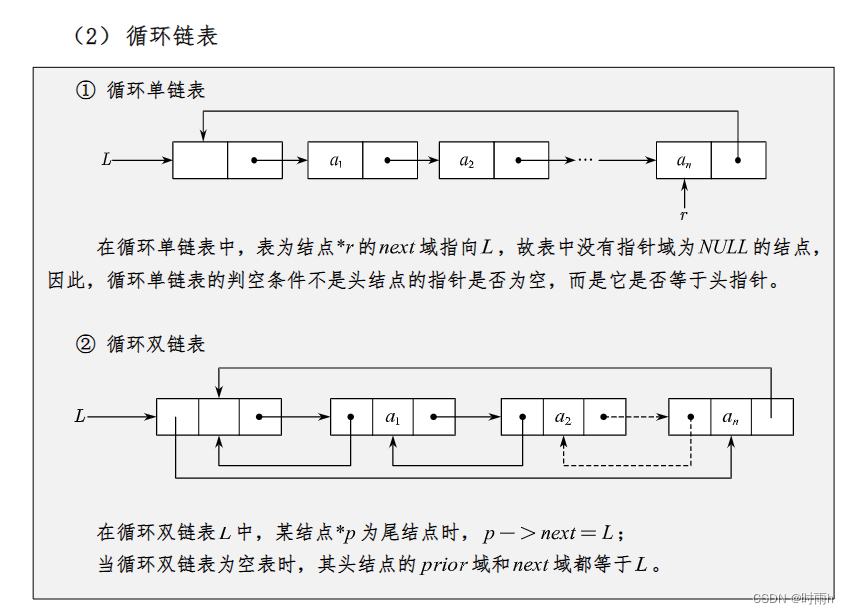
数据结构期末复习(2)链表
链表 链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指…...
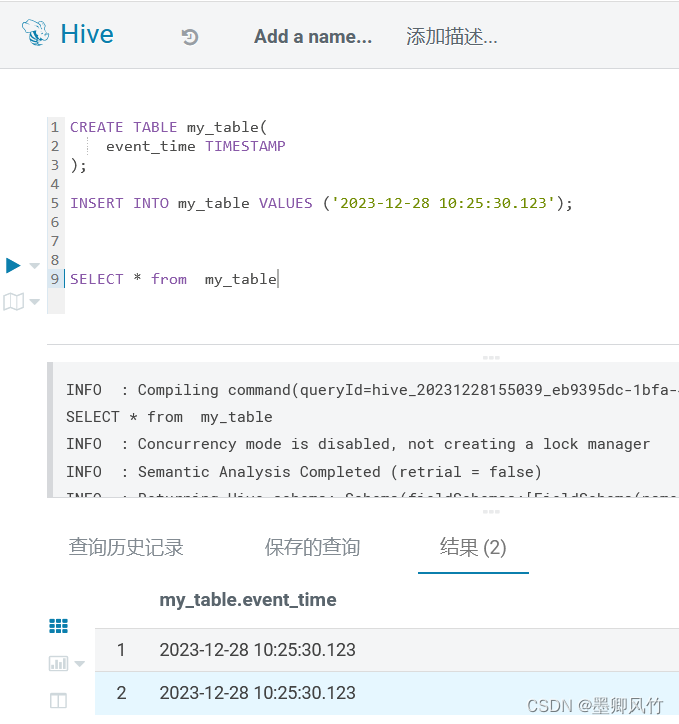
Hive中支持毫秒级别的时间精度
实际上,Hive 在较新的版本中已经支持毫秒级别的时间精度。你可以通过设置 hive.exec.default.serialization.format 和 mapred.output.value.format 属性为 1,启用 Hive 的时间精度为毫秒级。可以使用以下命令进行设置: set hive.exec.defau…...
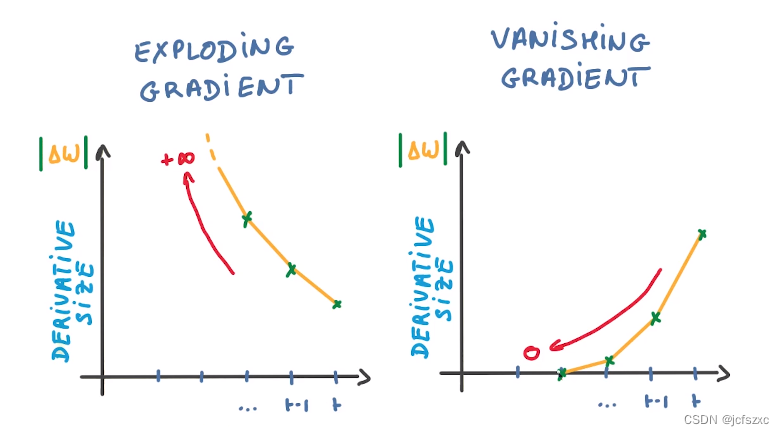
【深度学习:Recurrent Neural Networks】循环神经网络(RNN)的简要概述
【深度学习】循环神经网络(RNN):连接过去与未来的桥梁 循环神经网络简介什么是循环神经网络 (RNN)?传统 RNN 的架构循环神经网络如何工作?常用激活函数RNN的优点和缺点RNN 的优点:RNN 的缺点: 循…...

HTML 基础
文章目录 01-标签语法标签结构 03-HTML骨架04-标签的关系05-注释06-标题标签07-段落标签08-换行和水平线09-文本格式化标签10-图像标签图像属性 11-路径相对路径绝对路径 12-超链接标签13-音频14-视频 01-标签语法 HTML 超文本标记语言——HyperText Markup Language。 超文本…...

大学物理II-作业1【题解】
1.【单选题】——考查高斯定理 下面关于高斯定理描述正确的是(D )。 A.高斯面上的电场强度是由高斯面内的电荷激发的 B.高斯面上的各点电场强度为零时,高斯面内一定没有电荷 C.通过高斯面的电通量为零时,高斯面上各点电场强度…...

Unity引擎有哪些优点
Unity引擎是一款跨平台的游戏引擎,拥有很多的优点,如跨平台支持、强大的工具和编辑器、灵活的脚本支持、丰富的资源库和强大的社区生态系统等,让他成为众多开发者选择的游戏开发引擎。下面我简单的介绍一下Unity引擎的优点。 跨平台支持 跨…...

【华为机试】2023年真题B卷(python)-猴子爬山
一、题目 题目描述: 一天一只顽猴想去从山脚爬到山顶,途中经过一个有个N个台阶的阶梯,但是这猴子有一个习惯: 每一次只能跳1步或跳3步,试问猴子通过这个阶梯有多少种不同的跳跃方式? 二、输入输出 输入描述…...

【Harmony OS - Stage应用模型】
基本概念 大类分为: Ability Module: 功能模块 、Library Module: 共享功能模块 编译时概念: Ability Module在编译时打包生成HAP(Harmony Ability Package),一个应用可能会有多个HAP…...

Java 8 中的 Stream 轻松遍历树形结构!
可能平常会遇到一些需求,比如构建菜单,构建树形结构,数据库一般就使用父id来表示,为了降低数据库的查询压力,我们可以使用Java8中的Stream流一次性把数据查出来,然后通过流式处理,我们一起来看看…...
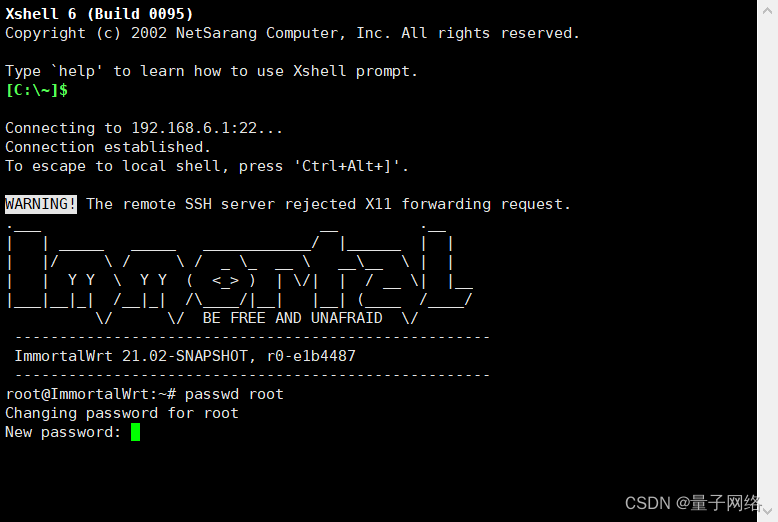
Openwrt修改Dropbear ssh root密码
使用ssh工具连接路由器 输入:passwd root 输入新密码 重复新密码 设置完成 rootImmortalWrt:~# passwd root Changing password for root New password:...

js 对象
js 对象定义 <!DOCTYPE html> <html> <body><h1>JavaScript 对象创建</h1><p id"demo1"></p> <p>new</p> <p id"demo"></p><script> // 创建对象: var persona {fi…...
【SpringBoot】常用注解
RequestBody:自动将请求体中的 json 数据转换为实体类对象。 这个例子凑巧传入的json属性键名和User键名一致,可以直接使用User实体类对象,如果键名不一致则需要用一个Map 类接收参数: PutMapping("/update")public R…...
【模拟电路】软件Circuit JS
一、模拟电路软件Circuit JS 二、Circuit JS软件配置 三、Circuit JS 软件 常见的快捷键 四、Circuit JS软件基础使用 五、Circuit JS软件使用讲解 欧姆定律电阻的串联和并联电容器的充放电过程电感器和实现理想超导的概念电容阻止电压的突变,电感阻止电流的突变LR…...
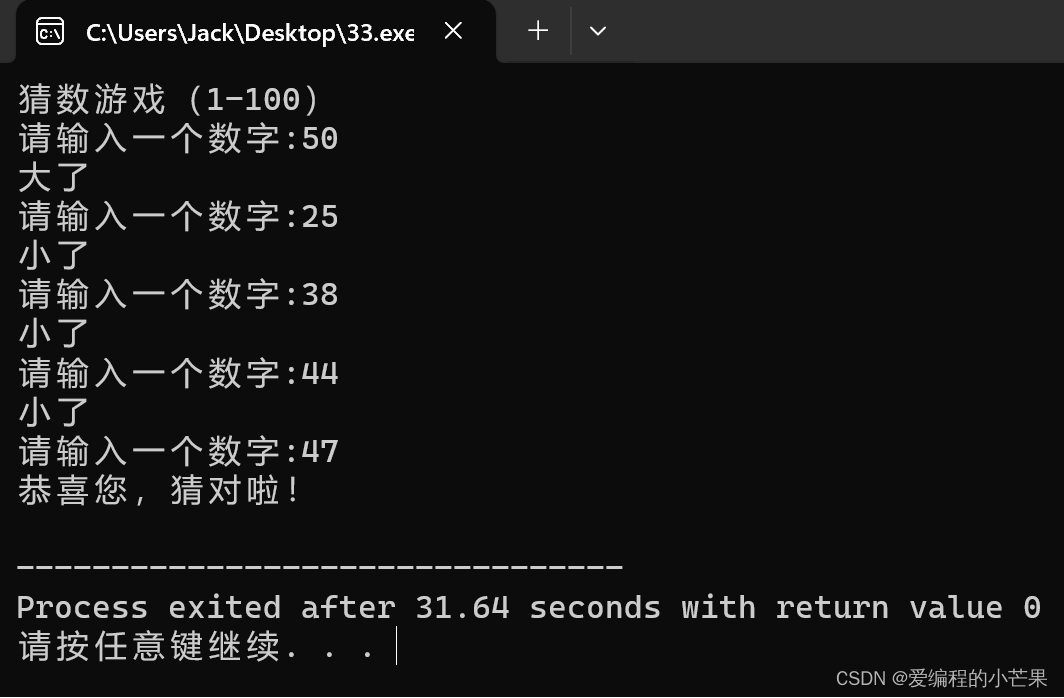
从入门到精通,30天带你学会C++【第十天:猜数游戏】
目录 Everyday English 前言 实战1——猜数游戏 综合指标 游玩方法 代码实现 最终代码 试玩时间 必胜策略 具体演示 结尾 Everyday English All good things come to those who wait. 时间不负有心人 前言 今天是2024年的第一天,新一年,新…...

终极免费离线OCR解决方案:Umi-OCR完整使用指南
终极免费离线OCR解决方案:Umi-OCR完整使用指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...

Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间
Windows驱动清理终极指南:用DriverStore Explorer安全释放数十GB磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你的Windows电脑是否经常提示C盘空间不足ÿ…...

基于轨道模型构建现代化流程编排系统:从概念到实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫s4kuraN4gi/orbit-app。乍一看这个仓库名,可能很多人会有点懵,不知道它具体是做什么的。我花了一些时间深入研究,发现这是一个围绕“轨道”概念构建的现代化应用。这…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...