【基础】【Python网络爬虫】【6.数据持久化】Excel、Json、Csv 数据保存(附大量案例代码)(建议收藏)
Python网络爬虫基础
- 数据持久化(数据保存)
- 1. Excel
- 创建数据表
- 批量数据写入
- 读取表格数据
- 案例 - 豆瓣保存 Excel
- 案例 - 网易新闻Excel保存
- 2. Json
- 数据序列化和反序列化
- 中文指定
- 案例 - 豆瓣保存Json
- 案例 - Json保存
- 3. Csv
- 写入csv列表数据
- 案例 - 豆瓣列表保存Csv
- 写入csv字典数据
- 案例 - 豆瓣字典保存csv
- 读取csv数据
- 案例 - 网易新闻csv
数据持久化(数据保存)
1. Excel
创建数据表
import openpyxl # 第三方模块, pip install openpyxl# 1.创建一个工作簿对象
work_book = openpyxl.Workbook()# 2.创建表对象
sheet1 = work_book.create_sheet('表1')
# 如果使用默认的表操作数据, 需要调用工作簿对象的active属性
sheet1 = work_book.active# 3.操作表中单元格写入数据
sheet1['A1'] = 'A1'
sheet1['B7'] = 'B7'# cell --> 单元格对象, row表示行, column表示列
sheet1.cell(row=1, column=1).value = '111111'
sheet1.cell(row=2, column=2).value = '222222'data1 = (1, 2, 3, 4, 5)
# data2 = '45678'# sheet1.append(序列数据) 整行添加数据到表格中去, 括号内部传递序列数据(列表/元祖)
# 通过数据的第一次和第二次数据提取, 会提取到一条一条的数据
sheet1.append(data1)
# sheet1.append(data2)# 4.保存
work_book.save('实例.xlsx')
批量数据写入
import openpyxlwork = openpyxl.Workbook()
sheet1 = work.activefor i in range(1, 10):for j in range(1, i + 1):print(f'{j} x {i} = {j * i}', end='\t')sheet1.cell(row=i, column=j).value = f'{j} x {i} = {j * i}'print()work.save('实例.xlsx')
读取表格数据
import openpyxlworkbook = openpyxl.load_workbook('实例.xlsx')print(workbook.sheetnames)sheet = workbook['Sheet'] # 指定表读取print(sheet.max_row) # 最大行
print(sheet.max_column) # 最大列# 读取第一行
for i in range(1, sheet.max_column + 1):print(sheet.cell(row=1, column=i).value) # 单元格为空就返回None# 读取第一列
for j in range(1, sheet.max_row + 1):print(sheet.cell(row=j, column=1).value) # 单元格为空就返回Nonefor i in range(1, sheet.max_column + 1):for j in range(1, sheet.max_row + 1):print(sheet.cell(row=i, column=j).value)
案例 - 豆瓣保存 Excel
import parsel
import requests
import openpyxl# 3.操作表中单元格写入数据
# 4.保存# 1.创建一个工作簿对象
work = openpyxl.Workbook()
# 2.创建表对象
sheet1 = work.active
# 写表头? √sheet1.append(['标题', '简介', '评分', '评价人数'])for page in range(0, 226, 25):url = f'https://movie.douban.com/top250?start={page}&filter='headers = {'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; __utmz=30149280.1687782730.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1687782730.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687952054%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DqdlD_RZvrHI0sXUZ08wSSKbkKLAWA_R84aALUkbWwp__yA2hUL-2C_Ej15saTpe7%26wd%3D%26eqid%3Dfdfaeaeb0001b3f60000000664998548%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1169382564.1682168622.1687782730.1687952054.9; __utmb=30149280.0.10.1687952054; __utmc=30149280; __utma=223695111.1640817040.1683638062.1687782730.1687952054.5; __utmb=223695111.0.10.1687952054; __utmc=223695111; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1687952056:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1687952056:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw','Host': 'movie.douban.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}response = requests.get(url=url, headers=headers)html_data = response.text# print(html_data)"""解析数据"""# 转对象selector = parsel.Selector(html_data)# 第一次提取lis = selector.css('.grid_view>li')# 二次提取for li in lis:title = li.css('.hd>a>span:nth-child(1)::text').get()info = li.css('.bd>p:nth-child(1)::text').getall()info = '//'.join([i.strip() for i in info])score = li.css('.rating_num::text').get()follow = li.css('.star>span:nth-child(4)::text').get()print(title, info, score, follow)# 调用append方法写入每一条数据# 写表头? xsheet1.append([title, info, score, follow])print('=' * 100 + '\n')# 写表头? x
work.save('douban.xlsx')# 编码
# office软件中Excel文件使用的编码是gbk
# wps软件使用的编码是 utf-8
案例 - 网易新闻Excel保存
"""
目标站点:https://news.163.com/往下翻有 "要闻" 这个新闻类目, 找不到可以 Ctrl + F 搜索下需求:爬取网易新闻 "要闻" 类目第一页数据,将数据保存为 Excel 表格保存字段需要以下内容titlechannelname docurl imgurl source tlink
"""
import json
import reimport requests
import openpyxlurl = 'https://news.163.com/special/cm_yaowen20200213/?callback=data_callback'
response = requests.get(url=url)
json_data = response.text
# print(json_data)result = re.findall('data_callback\((.*?)\)', json_data, re.S)
# print(result)item_json = json.loads(result[0])
# print(item_json)
# print(type(item_json))work = openpyxl.Workbook()
sheet1 = work.active
sheet1.append(['title', 'channelname', 'docurl', 'imgurl', 'source', 'tlink'])for item in item_json:title = item['title']channelname = item['channelname']docurl = item['docurl']imgurl = item['imgurl']source = item['source']tlink = item['tlink']print(title, channelname, docurl, imgurl, source, tlink, sep=' | ')sheet1.append([title, channelname, docurl, imgurl, source, tlink])work.save('网易新闻.xlsx')
2. Json
数据序列化和反序列化
import json # 内置# [] {}
data = {'name': 'ACME','shares': 100,'price': 542.23
}"""
json序列化: 将对象转化成json字符串
dumps() 序列化json字符串
"""
json_str = json.dumps(data)
print(json_str)
print(type(json_str))"""
json反序列化: 将json字符串转化成对象
dumps() 序列化json字符串
"""
json_obj = json.loads(json_str)
print(json_obj)
print(type(json_obj))
中文指定
import jsondata = {'name': '青灯','shares': 100,'price': 542.23
}
# json字符串默认使用unicode编码, 无法显示中文
# ensure_ascii=False 不适用默认编码json_str = json.dumps(data, ensure_ascii=False)
with open('data.json', mode='w', encoding='utf-8') as f:f.write(json_str)
案例 - 豆瓣保存Json
import jsonimport parsel
import requests
import openpyxldata = [] # 定义一个空列表, 用于收集每一条数据for page in range(0, 226, 25):url = f'https://movie.douban.com/top250?start={page}&filter='headers = {'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; __utmz=30149280.1687782730.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1687782730.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687952054%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DqdlD_RZvrHI0sXUZ08wSSKbkKLAWA_R84aALUkbWwp__yA2hUL-2C_Ej15saTpe7%26wd%3D%26eqid%3Dfdfaeaeb0001b3f60000000664998548%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1169382564.1682168622.1687782730.1687952054.9; __utmb=30149280.0.10.1687952054; __utmc=30149280; __utma=223695111.1640817040.1683638062.1687782730.1687952054.5; __utmb=223695111.0.10.1687952054; __utmc=223695111; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1687952056:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1687952056:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw','Host': 'movie.douban.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}response = requests.get(url=url, headers=headers)html_data = response.text# print(html_data)"""解析数据"""# 转对象selector = parsel.Selector(html_data)# 第一次提取lis = selector.css('.grid_view>li')# 二次提取for li in lis:title = li.css('.hd>a>span:nth-child(1)::text').get()info = li.css('.bd>p:nth-child(1)::text').getall()info = '//'.join([i.strip() for i in info])score = li.css('.rating_num::text').get()follow = li.css('.star>span:nth-child(4)::text').get()# print(title, info, score, follow)d = {'title': title, 'info': info, 'score': score, 'follow': follow}data.append(d)# print('=' * 100 + '\n')print(data)# json数据的序列化
json_str = json.dumps(data, ensure_ascii=False)
with open('douban.json', mode='w', encoding='utf-8') as f:f.write(json_str)# [{}, {}, {}......]
案例 - Json保存
"""目标网址:https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=76请求方式: GET要求:1、请求上述网址的数据2、把获取到的数据保存到json文件中文件命名: data.json需要在文件中看到json字符串请在下方编写代码
"""
import requestsurl = 'https://www.ku6.com/video/feed?pageNo=0&pageSize=40&subjectId=76'
response = requests.get(url=url)
json_data = response.text
print(json_data)with open('data.json', mode='w', encoding='utf-8') as f:f.write(json_data)# json序列化-
3. Csv
写入csv列表数据
"""
csv数据格式:每一行是一条数据每一行中每个数据字段有分隔符号, 默认为逗号
"""
import csv # 内置data = [[1, 2, 3, 4],[1, 2, 3, 4],[5, 6, 7, 8],[5, 6, 7, 8]
]with open('data.csv', mode='a', encoding='utf-8', newline='') as f:# newline='' 指定数据新行是一个空字符串, 不然保存会有数据空行# csv.writer(f) 实例化一个csv数据的写入对象, 括号内部传递文件对象csv_write = csv.writer(f)for i in data:# writerow(i) 把数据一行一行<一条一条>写入, 传入(列表/元组)csv_write.writerow(i)
案例 - 豆瓣列表保存Csv
import csv
import jsonimport parsel
import requests
import openpyxl# 上下文管理器
with open('douban-list.csv', mode='a', encoding='utf-8', newline='') as f:csv_write = csv.writer(f)# csv_write.writerow(['标题', '简介', '平分', '评论人数'])f.write('标题,简介,平分,评论人数\n')for page in range(0, 226, 25):url = f'https://movie.douban.com/top250?start={page}&filter='headers = {'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; __utmz=30149280.1687782730.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1687782730.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687952054%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DqdlD_RZvrHI0sXUZ08wSSKbkKLAWA_R84aALUkbWwp__yA2hUL-2C_Ej15saTpe7%26wd%3D%26eqid%3Dfdfaeaeb0001b3f60000000664998548%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1169382564.1682168622.1687782730.1687952054.9; __utmb=30149280.0.10.1687952054; __utmc=30149280; __utma=223695111.1640817040.1683638062.1687782730.1687952054.5; __utmb=223695111.0.10.1687952054; __utmc=223695111; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1687952056:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1687952056:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw','Host': 'movie.douban.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}response = requests.get(url=url, headers=headers)html_data = response.text# print(html_data)"""解析数据"""# 转对象selector = parsel.Selector(html_data)# 第一次提取lis = selector.css('.grid_view>li')# 二次提取for li in lis:title = li.css('.hd>a>span:nth-child(1)::text').get()info = li.css('.bd>p:nth-child(1)::text').getall()info = '//'.join([i.strip() for i in info])score = li.css('.rating_num::text').get()follow = li.css('.star>span:nth-child(4)::text').get()print(title, info, score, follow)# 循环写入数据csv_write.writerow([title, info, score, follow])print('=' * 100 + '\n')写入csv字典数据
"""
csv数据格式:每一行是一条数据每一行中每个数据字段有分隔符号, 默认为逗号
"""import csv # 内置list_dict = [{'first_name': 'Baked', 'last_name': 'Beans'},{'first_name': 'Lovely'},{'first_name': 'Wonderful', 'last_name': 'Spam'}]with open('data.csv', mode='a', encoding='utf-8', newline='') as f:# 创建一个字典数据写入对象, 第一个参数是文件对象, 第二个参数是字典中的键# fieldnames 指定字典的键, 不能多不能少不能错csv_write = csv.DictWriter(f, fieldnames=['first_name', 'last_name'])# 字典数据会有专门写表头的方法csv_write.writeheader()for i in list_dict:csv_write.writerow(i)
案例 - 豆瓣字典保存csv
import csv
import jsonimport parsel
import requests
import openpyxlwith open('douban-dict.csv', mode='a', encoding='utf-8', newline='') as f:csv_write = csv.DictWriter(f, fieldnames=['title', 'info', 'score', 'follow'])csv_write.writeheader() # 写表头, 只有字典数据有写表头的方法,列表没有方法写表头for page in range(0, 226, 25):url = f'https://movie.douban.com/top250?start={page}&filter='headers = {'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; __utmz=30149280.1687782730.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1687782730.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687952054%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DqdlD_RZvrHI0sXUZ08wSSKbkKLAWA_R84aALUkbWwp__yA2hUL-2C_Ej15saTpe7%26wd%3D%26eqid%3Dfdfaeaeb0001b3f60000000664998548%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1169382564.1682168622.1687782730.1687952054.9; __utmb=30149280.0.10.1687952054; __utmc=30149280; __utma=223695111.1640817040.1683638062.1687782730.1687952054.5; __utmb=223695111.0.10.1687952054; __utmc=223695111; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1687952056:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1687952056:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw','Host': 'movie.douban.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}response = requests.get(url=url, headers=headers)html_data = response.text# print(html_data)"""解析数据"""# 转对象selector = parsel.Selector(html_data)# 第一次提取lis = selector.css('.grid_view>li')# 二次提取for li in lis:title = li.css('.hd>a>span:nth-child(1)::text').get()info = li.css('.bd>p:nth-child(1)::text').getall()info = '//'.join([i.strip() for i in info])score = li.css('.rating_num::text').get()follow = li.css('.star>span:nth-child(4)::text').get()print(title, info, score, follow)d = {'title': title, 'info': info, 'score': score, 'follow': follow}csv_write.writerow(d)print('=' * 100 + '\n')
读取csv数据
import csv"""基于字符串文件类型直接读取"""
# with open('data.csv', mode='r', encoding='utf-8') as f:
# print(f.read())"""读取返回列表"""
# with open('douban-list.csv', mode='r', encoding='utf-8') as f:
# csv_read = csv.reader(f)
# print(csv_read)
# for i in csv_read:
# print(i)"""读取返回字典对象的方法"""
with open('douban-list.csv', mode='r', encoding='utf-8') as f:csv_read = csv.DictReader(f)print(csv_read)for i in csv_read:print(i)
案例 - 网易新闻csv
"""
目标站点:https://news.163.com/
往下翻有 要闻 这个新闻类目需求:爬取网易新闻 要闻 类目第一页数据,将数据保存为csv格式保存字段需要以下内容title channelname docurl imgurl source tlink
"""
import csv
import json
import re
import requests
import openpyxlurl = 'https://news.163.com/special/cm_yaowen20200213/?callback=data_callback'
response = requests.get(url=url)
json_data = response.textresult = re.findall('data_callback\((.*?)\)', json_data, re.S)item_json = json.loads(result[0])with open('网易新闻.csv', mode='a', encoding='utf-8', newline='') as f:write = csv.writer(f)write.writerow(['title', 'channelname', 'docurl', 'imgurl', 'source', 'tlink'])for item in item_json:title = item['title']channelname = item['channelname']docurl = item['docurl']imgurl = item['imgurl']source = item['source']tlink = item['tlink']print(title, channelname, docurl, imgurl, source, tlink, sep=' | ')write.writerow([title, channelname, docurl, imgurl, source, tlink])
相关文章:
(建议收藏))
【基础】【Python网络爬虫】【6.数据持久化】Excel、Json、Csv 数据保存(附大量案例代码)(建议收藏)
Python网络爬虫基础 数据持久化(数据保存)1. Excel创建数据表批量数据写入读取表格数据案例 - 豆瓣保存 Excel案例 - 网易新闻Excel保存 2. Json数据序列化和反序列化中文指定案例 - 豆瓣保存Json案例 - Json保存 3. Csv写入csv列表数据案例 - 豆瓣列表保…...

王道考研计算机网络——应用层
如何为用户提供服务? CS/P2P 提高域名解析的速度:local name server高速缓存:直接地址映射/低级的域名服务器的地址 本机也有告诉缓存:本机开机的时候从本地域名服务器当中下载域名和地址的对应数据库,放到本地的高…...
Android MVVM 写法
前言 Model:负责数据逻辑 View:负责视图逻辑 ViewModel:负责业务逻辑 持有关系: 1、ViewModel 持有 View 2、ViewModel 持有 Model 3、Model 持有 ViewModel 辅助工具:DataBinding 执行流程:View &g…...

LeetCode 热题 100——283. 移动零
283. 移动零 提示 简单 2.3K 相关企业 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12] 输出: [1,…...

neovim调试xv6-riscv过程中索引不到对应头文件问题
大家好,我叫徐锦桐,个人博客地址为www.xujintong.com,github地址为https://github.com/jintongxu。平时记录一下学习计算机过程中获取的知识,还有日常折腾的经验,欢迎大家访问。 和这篇文章neovim调试linux内核过程中索…...

轻量应用服务器与云服务器CVM对比——腾讯云
腾讯云轻量服务器和云服务器CVM该怎么选?不差钱选云服务器CVM,追求性价比选择轻量应用服务器,轻量真优惠呀,活动 https://curl.qcloud.com/oRMoSucP 轻量应用服务器2核2G3M价格62元一年、2核2G4M价格118元一年,540元三…...
-游戏AI控制)
骑砍战团MOD开发(31)-游戏AI控制
一.骑砍单机模式下AI控制 骑砍战团中野外战斗,训练场中小兵和地方小兵的行为统称为场景AI. 骑砍大地图中敌军追踪和遭遇追击统称为大地图AI. 二.骑砍场景AI 骑砍引擎通过header_mission_templates,py定制AI常量控制小兵位置,动作和朝向.可实现自定义阵型和攻击动作。 # Agen…...

flutter学习-day21-使用permission_handler进行系统权限的申请和操作
文章目录 1. 介绍2. 环境准备2-1. Android2-2. iOS 3. 使用 1. 介绍 在大多数操作系统上,权限不是在安装时才授予应用程序的。相反,开发人员必须在应用程序运行时请求用户的许可。在 flutter 开发中,则需要一个跨平台(iOS, Android)的 API 来…...

虹科方案丨L2进阶L3,数据采集如何助力自动驾驶
来源:康谋自动驾驶 虹科方案丨L2进阶L3,数据采集如何助力自动驾驶 原文链接:https://mp.weixin.qq.com/s/qhWy11x_-b5VmBt86r4OdQ 欢迎关注虹科,为您提供最新资讯! 12月14日,宝马集团宣布,搭载…...

Kubernetes 学习总结(42)—— Kubernetes 之 pod 健康检查详解
Kubernetes 入门 回想 2017 年刚开始接触 Kubernetes 时,碰到 Pod一直起不来的情况,就开始抓瞎。后来渐渐地掌握了一些排查方法之后,这种情况才得以缓解。随着时间推移,又碰到了问题。有一天在部署某个 springboot 微服务时&…...
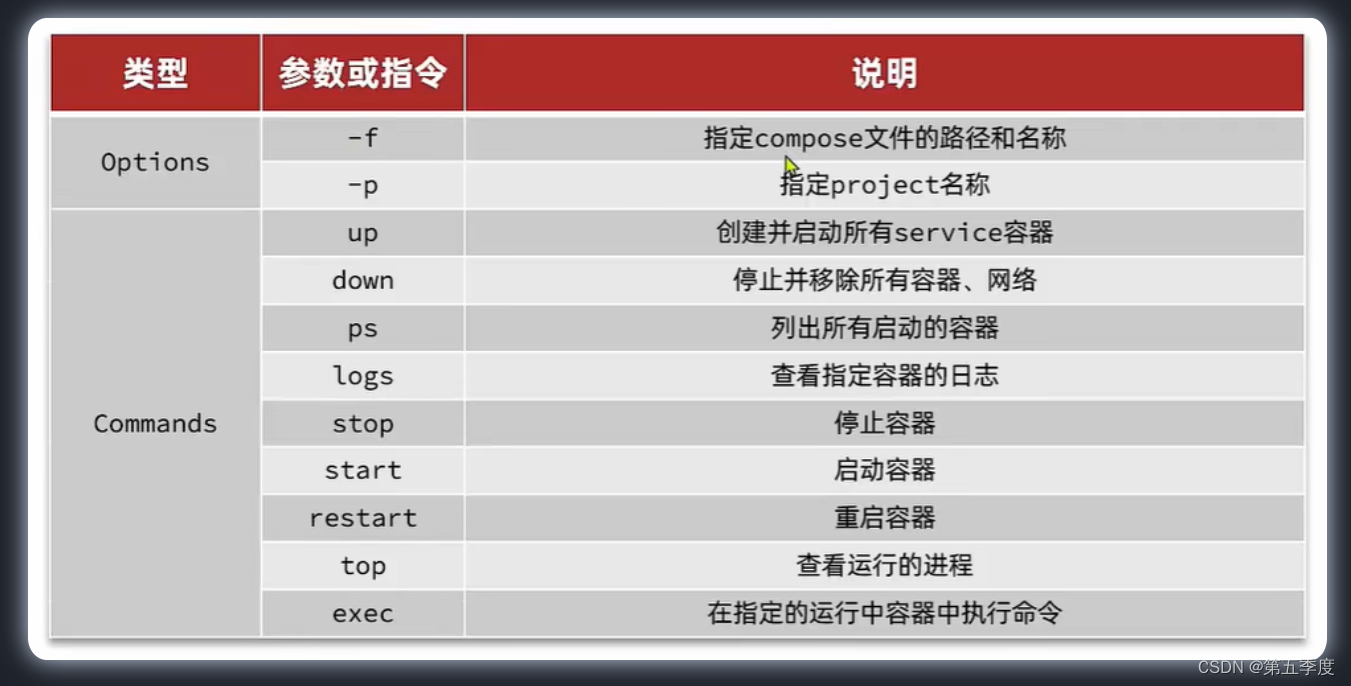
【后端】Docker学习笔记
文章目录 Docker一、Docker安装(Linux)二、Docker概念三、Docker常用命令四、数据卷五、自定义镜像六、网络七、DockerCompose Docker Docker是一个开源平台,主要基于Go语言构建,它使开发者能够将应用程序及其依赖项打包到一个轻…...
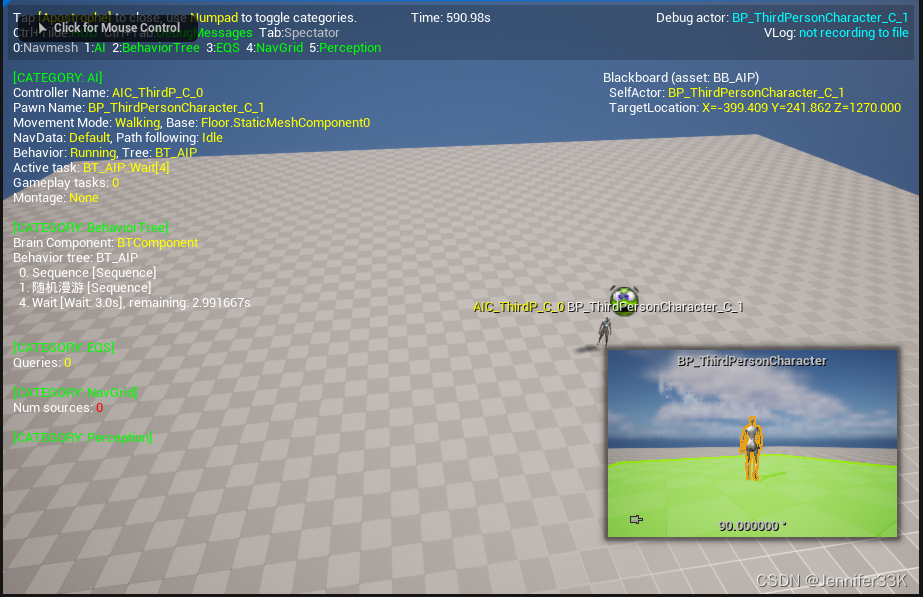
UE5.1_Gameplay Debugger启用
UE5.1_Gameplay Debugger启用 重点问题: Gamplay Debugger启用不知道? Apostrophe、Tilde键不知道是哪个? Gameplay调试程序 | 虚幻引擎文档 (unrealengine.com) Gameplay Debugger...

【论文阅读+复现】SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
SparseCtrl:在文本到视频扩散模型中添加稀疏控制。 (AnimateDiff V3,官方版AnimateDiffControlNet,效果很丝滑) code:GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff. paper:htt…...

速盾cdn:ddos防护手段
速盾CDN采用多种手段来进行DDoS防护,以确保网络和网站的正常运行。以下是速盾CDN可能采用的一些主要DDoS防护手段: 实时监测和分析: 速盾CDN实时监测网络流量,通过分析流量模式来检测异常行为,以迅速发现潜在的DDoS攻击…...
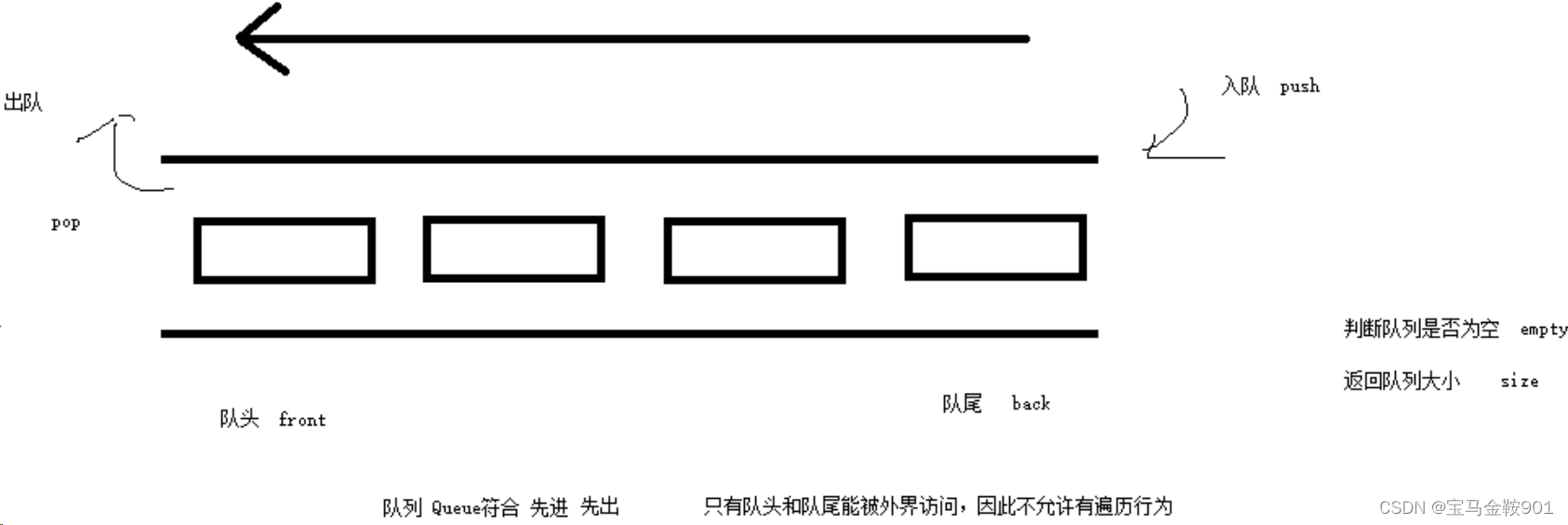
STL——queue容器
1.queue基本概念 概念:queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口。 队列容器允许从一端新增元素,从另一端移除元素。 队列中只有队头和队尾才可以被外界使用,因此队列不允许…...

gitLab页面打tag操作步骤
作者:moical 链接:gitLab页面打tag简单使用 - 掘金 (juejin.cn) 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 ---------------------------------------------------------------------…...
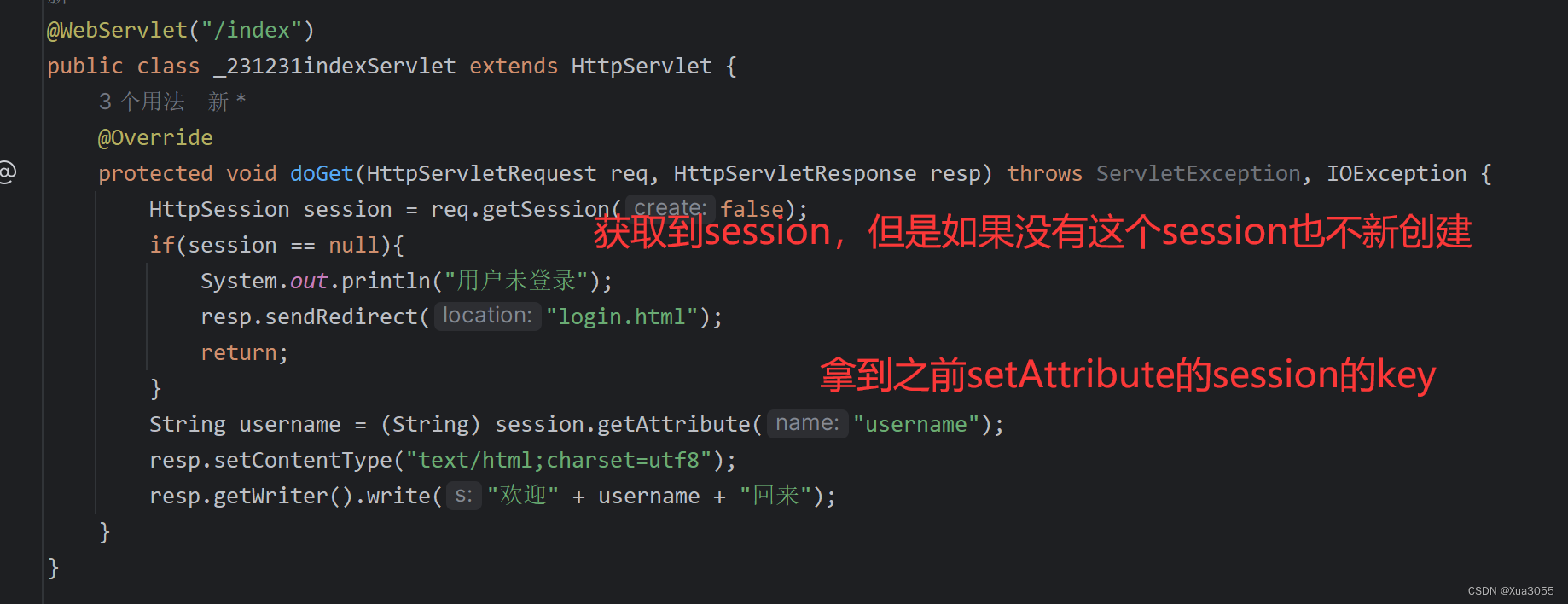
神秘的Cookie和Session
Cookie 1.Cookie是什么? Cookie是浏览器提供的持久化储存数据的方式。 2.从哪里来? Cookie从服务器中来,存储到客户端中。一个客户端就对应着一个浏览器。 服务器代码中决定了什么样的数据会储存到客户端中,通过HTTP相应的Se…...

springboot接口文档
Swagger 在Spring Boot中生成和维护接口文档的一个常用方法是使用Swagger。Swagger是一个开源软件框架,它帮助开发者设计、构建、记录和使用RESTful Web服务。下面是在Spring Boot项目中使用Swagger来创建接口文档的详细步骤:1. 添加Swagger依赖 在你的Spring Boot项目的pom…...
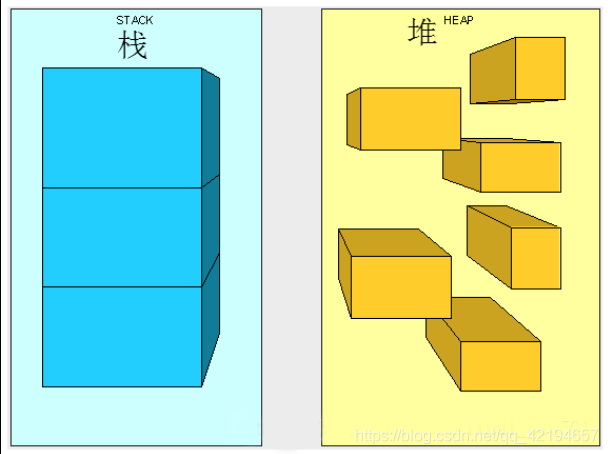
深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈
深入浅出图解C#堆与栈 C# HeapingVS Stacking第一节 理解堆与栈 [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈](https://mp.csdn.net/mdeditor/101021023)[深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节 栈基本工作原理](https://mp.csdn.n…...

Maven的使用和配置
Maven的使用和配置 起源: Apache 软件基金会(非营业的组织,把一些开源软件维护管理起来) maven 是apache的一个开源项目,是一个优秀的项目构建(管理)工具, maven 管理项目中的jar,以及jar与jar之间的依赖 maven 可…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...

基于GitHub Actions的自动化代码质量守护:CodeBuddy实战指南
1. 项目概述与核心价值最近在和一些团队做代码评审和协作时,我经常遇到一个痛点:大家写的代码风格各异,注释要么缺失要么过时,一些潜在的安全漏洞和性能问题在提交前很难被系统性地发现。虽然市面上有各种静态分析工具,…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...

OpenClaw-Subcortex:轻量级自动化任务编排与执行框架详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目叫openclaw-subcortex。乍一看这个名字,可能有点摸不着头脑,又是“爪子”又是“皮层下”的,感觉像是什么生物或者神经科学的东西。但实际上,这是…...

[具身智能-766]:机器人在运动过程中需要实时定位,AMCL 每一次都需要全局撒粒子重搜吗?还是一旦定位后,后续的移动过程中,只需要局部匹配?
直白结论完全不需要每次全局撒粒子重搜定位成功稳定后,机器人全程只做局部小范围匹配,只有丢位置、被挪动时,才会重新全局撒粒子搜索。一、分两种状态1. 正常行走(已定位成功)粒子只聚集在机器人真实位置周边很小一片区…...

RFM69无线通信进阶:从基础收发到可靠数据传输系统构建
1. 项目概述:从点对点收发迈向可靠通信在物联网和嵌入式开发领域,无线通信模块是连接物理世界与数字世界的桥梁。RFM69系列模块,特别是工作在433MHz或915MHz等Sub-GHz频段的RFM69HCW,因其出色的抗干扰能力、较远的传输距离以及相对…...

LoRA模型合并实战指南:多技能融合与vLLM部署
1. 项目概述:LoRA模型合并的“瑞士军刀”最近在折腾大语言模型微调的朋友,估计对LoRA(Low-Rank Adaptation)这个词都不陌生。它就像给预训练好的大模型“打补丁”,用极小的参数量(通常只有原模型的0.1%到1%…...