Pandas教程(四)—— 分层索引及数据联合
1.分层索引
分层索引就是在一个轴上拥有多个(两个及以上)索引级别,能以低维度形式处理高维度数据。

1.1 分层索引的创建
1.1.1 方式一:直接设置
- 1)在创建series、dataframe或读取文件时时,行名或列名输入一个二维的列表;
- 2)使用语句:data.set_index( ) 括号中输入一个含多个列名的列表
set_index会生成一个新的dataframe,使用一个或多个列作为索引
reset_index是它的反函数,分层索引中的索引层级会被移动到列中
import pandas as pd
data = {"城市":["北京","上海","深圳","广州"],"同比":[120.7,127.3,119.4,140.9],"环比":[101.5,101.2,101.3,120.0],"定基":[121.4,127.8,120.0,145.5]}# 法一
data1 = pd.DataFrame(data,index = [["A","A","B","B"],[1,2,1,4]], #第一层中相同的要放在一起columns =["城市","同比","环比","定基"])# 法二
data2 = pd.DataFrame(data,columns =["城市","同比","环比","定基"])
data2 = data2.set_index(['城市','同比'])输出结果如下:

我们得到的就是一个以 MutiIndex 对象 作为索引的 美化视图
print(data.index) #打印dataframe的索引返回结果如下:
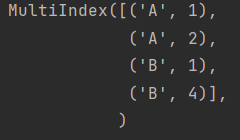
1.1.2 利用方法属性创建
- 以下方法只是创建出多维索引 Mutiindex 对象,还需要在定义时将其赋给Dataframe
创建语法:pd. MutiIndex.下述方法()
| 方法 | 描述 |
|---|---|
| from_arrays | 接收一个多维数组,高维指定高层索引,低维指定底层索引 |
| from_tuples | 接收一个元组的列表,每个元组指定每个对应索引 (高维索引,低维索引) 如上图 |
| from_product | 接收一个可迭代对象的列表,使用笛卡尔积的方式创建 |
- 补充:笛卡尔积
两个集合X和Y的笛卡尔积(X × Y)是指 第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员
例如:A={a, b},B={0, 1, 2},则笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
import pandas as pd
# 利用数组设置
mult1 = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],names = ["x","y"])
print(mult1)# 利用元组设置
mult2 = pd.MultiIndex.from_tuples([('a', 1),('a', 2),('b', 1),('b', 2)],names = ["x","y"])
print(mult2)# 推荐:利用可迭代对象设置
mult3 = pd.MultiIndex.from_product([[2019,2020],[1,2]])
mult3.names = ["年","月"] # 也可以这样设置索引名
print(mult3)# 将mutiindex赋给数据
mult4 = pd.MultiIndex.from_product([["山东","北京"],["土豆","茄子"]],names=['城市', '蔬菜'])
data = pd.DataFrame(np.random.random(size=(4,4)),index = mult3,columns = mult4)
print(data)1.2 分层索引的切片或索引
首先我们先创建一个多层索引的dataframe,并以此为例讲解
(参考了该文章:https://blog.csdn.net/qq_35318838/article/details/102469320)
import pandas as pd
mult3 = pd.MultiIndex.from_product([[2019,2020],[1,2]])
mult3.names = ["年","月"]
mult4 = pd.MultiIndex.from_product([["山东","北京"],["土豆","茄子"]],names=['城市', '蔬菜'])
data = pd.DataFrame(np.random.random(size=(4,4)),index = mult3,columns = mult4)
print(data)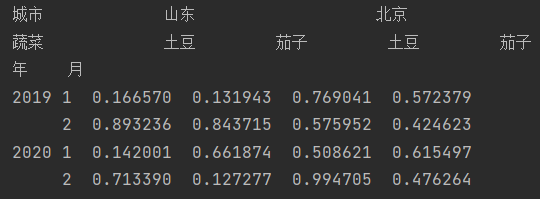
1.2.1 对列标签层次化索引
- 最外层列标签的索引:data [ "外层列名" ]
- 内层列标签的索引: data [ "外层标签","内层标签" ]
print(data["山东"]) # 索引山东列
print("-"*50)
print(data["山东","土豆"]) #索引山东的土豆列1.2.2 对行标签层次化索引
- 最外层行标签的索引:data.loc [ "外层行名" ]
- 内层行标签的索引: data.loc [ "外层标签","内层标签" ]
print(data.loc[2019]) # 索引2019年 行
print("-"*50)
print(data.loc[2019,1]) # 索引2019一月 行1.2.3 使用xs进行索引
pandas 中的 xs 方法在索引时可以直接指定层次化索引中元素和层级
- 语法:data.xs( x , level=, axis=1)
参数说明:
x:标签或标签的元组
level:层级名(本例中行索引层级包括:蔬菜、城市 列索引层级包括:年、月)
axis:哪个轴向上的层级
print(data.xs(1,level="月",axis=0)) # 列切片 月层级上所有1月
print("-"*50)
print(data.xs("土豆",level="蔬菜",axis=1)) # 行切片 蔬菜层级上所有土豆1.2.4 使用loc和slice方法切片
在列索引中,“ :”代表选取全部列,但冒号不能在行索引中使用;
行索引中应该使用slice(None)代表选取所有行
print(data.loc[(slice(None),1),:]) # 选取所有1月
print(data.loc[slice(None),(slice(None),"茄子")]) # 选取所有的茄子1.3 重排序和层级排序
| 方法 | 描述 |
|---|---|
| data.swaplevel(“key1”,“key2”) | 传入两个层级序号或层级名称,互换这两个层级的位置 |
| data.sort_index(level =) | 传入一个层级,使结果按照层级进行字典排序 |
2.联合与合并数据集
- 基础知识:四种连接方式
内连接(inner)、左连接(left)、右连接(right)、全外连接(outer 全部都要)

2.1 Merge函数
merge函数有点类似sql中的join,主要用于将两个Dataframe根据一些共有的列连接起来
- 语法: pd.merge(data1,data2,参数)
常用参数:
how: 数据连接的方式:inner(默认)、left、right、outer(即上面四种)
on: 用来连接的列名,必须是在两边的df中都有的列名;若使用多个键进行合并,
传入一个含多个列名的列表,把多个键看作一个元组数据当作单个键处理即可
suffixes:对于左右表中的重名列,添加后缀进行区分,默认为("_x","_y")
left_on / right_on: 左(右)表中用作连接键的列名
left_index / right_index: 将左(右)表的行索引index用作连接键,布尔值 默认F
2.1.1 根据单个连接键合并
- pd.merge(数据1,数据2,on='姓名',how='inner')
import pandas as pd
数据1= pd.DataFrame({'姓名':['叶问','李小龙','孙兴华','李小龙','叶问','叶问'],'出手次数1':np.arange(6)})
数据2 = pd.DataFrame({'姓名':['黄飞鸿','孙兴华','李小龙'],'出手次数2':[1,2,3]})
数据3 = pd.merge(数据1,数据2,on='姓名',how='inner')
print(数据3)
2.1.2 根据多个连接键合并
- 根据多个键进行合并时,on参数需传入一个含多个列名的列表,把多个键看作一个元组数据当作单个键处理即可
import pandas as pd
数据1 = pd.DataFrame({'姓名': ['张三', '张三', '王五'],'班级': ['1班', '2班', '1班'],'分数': [10,20,30]})
数据2 = pd.DataFrame({'姓名': ['张三', '张三', '王五','王五'],'班级': ['1班', '1班', '1班','2班'],'分数': [40,50,60,70]})数据3 = pd.merge(数据1,数据2,on=['姓名','班级'],how='outer',suffixes=('_left','_right')) # 外连接(并集)的结果
print(数据3)
2.1.3 索引作为键进行合并
- 如果我们希望以df的索引作为合并的键,只需传递参数 left_index / right_index = True 即可
import pandas as pd
import numpy as np
data1 = pd.DataFrame({"key1":["Ohio","Ohio","Ohio","Nevada","Nevada"],"key2":[2000,2001,2002,2001,2002],"data":np.arange(5)})data2 = pd.DataFrame(np.arange(12).reshape(6,2),index = [["Nevada","Nevada","Ohio","Ohio","Ohio","Ohio"],[2001,2000,2000,2000,2001,2002]],columns = ["first","second"])data3 = pd.merge(data1,data2,left_on=["key1","key2"],right_index=True,how="outer")
print(data3)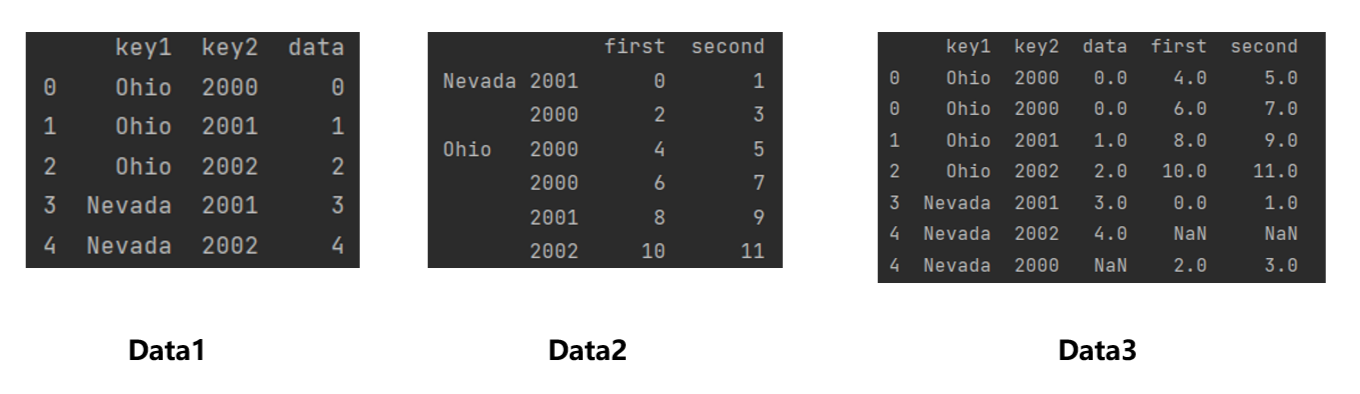
2.2 join函数
join函数可以便捷的进行横向连接,它默认以索引为连接键,且默认左连接
- 语法:left_data . join(right_data,on = None,how = 'left')
- 若要一次组合多个dataframe,只需传入一个列表即可。例如:result = left.join([right, right2])
import pandas as pd
left = pd.DataFrame({'姓名1':['叶问','李小龙','孙兴华'],'年龄1':[127,80,20]})
right = pd.DataFrame({'姓名2':['大刀王五','霍元甲','陈真'],'年龄2':[176,152,128]})print(left.join(right))
2.3 concat函数
contact函数主要负责数据组合中的拼接、绑定或堆叠,也可以总结为沿轴向对数据进行连接
- 语法:contact([ data1,data2... ],axis = ,join = ,keys = ...)
常用参数:
axis :沿哪个轴进行数据连接,默认为0,纵向连接
join :选择连接方式,inner(默认)或outer
join_axes :可以指定根据那个轴来对齐数据,代替join的作用
ignore_index:是否忽略原索引,产生一段新的索引(默认False,不忽略)
keys:输入一个列表,增加一个区分数据组的键,形成分层索引
2.3.1 纵向拼接 / 分层索引
contact函数默认(axis = 0)就是纵向拼接,即首尾相连
此时我们可以通过 添加一个keys或传入字典 来区分拼接后的数据到底来自哪个表
- 语法1:contact([ df1,df2,df3 ],axis = 0,keys=['x', 'y', 'z'])
- 语法2:contact( { 'x': df1, 'y': df2, 'z': df3 },axis = 0)

2.3.2 横向拼接 / 指定拼接键
当axis = 1的时候,concat就是行对齐,即横向合并
我们也可以通过传入join_axes,来指定根据那个轴来对齐数据
- 语法:pd.concat ( [ df1, df4 ] , axis = 1 , join_axes = [df1.index] )

2.3.3 无视原来的index
如果两个表的index都没有实际含义,或拼接后变得混乱,我们可以传入 ignore_index 参数来生成一个新的index
- 语法: pd.concat ( [ df1, df4 ] , axis = 1 , ignore_index = True)

2.4 联合重叠的数据
在数据操作中,我们经常需要去联合一些重叠的数据,进而去填补一些缺失值
- 方法一:np.where(condition,x,y) 等价于 x if condition else y
语法:np.where(pd.isnull(data1),data2,data1)
该语法相当于先判断data1中的数据是否为空值,如果为空就用data2的数据,如果不为空,就用data1的数据
- 方法二:combine_first
语法:data1.combine_first(data2)
改语法是逐列对df做相同的操作,可以认为是根据data2 来修补 data1的缺失值
相关文章:
Pandas教程(四)—— 分层索引及数据联合
1.分层索引 分层索引就是在一个轴上拥有多个(两个及以上)索引级别,能以低维度形式处理高维度数据。 行索引有两层 1.1 分层索引的创建 1.1.1 方式一:直接设置 1)在创建series、dataframe或读取文件时时,行…...
小梅哥Xilinx FPGA学习笔记16——FSM(状态机)的学习
目录 一、 状态机导读 1.1 理论学习 1.2 状态机的表示 1.3 状态机编码 1.4 状态机描述方式 二 、实战演练一(来自野火) 2.1 实验目标 2.2 模块框图 2.3 状态转移图绘制 2.4 设计文件 2.5 仿真测试文件 2.6 仿真结果 三、 实战演练二&…...

vol----学习随记!!!
目录 一、代码生成1.先新建一个功能的对应的代码配置各项解释: 2.后设置配置菜单3.再点保存,生成vue页面,生成model,生成业务类4.再通过菜单设置编写系统菜单 一、代码生成 1.先新建一个功能的对应的代码配置 各项解释ÿ…...

HarmonyOS4.0系统性深入开发10卡片事件能力说明
卡片事件能力说明 ArkTS卡片中提供了postCardAction()接口用于卡片内部和提供方应用间的交互,当前支持router、message和call三种类型的事件,仅在卡片中可以调用。 接口定义:postCardAction(component: Object, action: Object): void 接口…...

openGauss学习笔记-181 openGauss 数据库运维-升级-升级流程
文章目录 openGauss学习笔记-181 openGauss 数据库运维-升级-升级流程 openGauss学习笔记-181 openGauss 数据库运维-升级-升级流程 本章介绍升级到该版本的主要升级过程。 图 1 升级流程图 说明: 本文档中描述的时间仅供参考,实际操作时间以现场情况…...

提前应对威胁
通过新的《2023-2028 年荷兰国际网络安全战略》,荷兰政府在面对国家和犯罪分子持续构成的网络威胁时展现了责任和机构。它渴望将民主、人权和规范放在首位,并寻求维护全球开放、自由和安全的互联网。该战略明确了政府在国内实施打击的意愿和能力…...
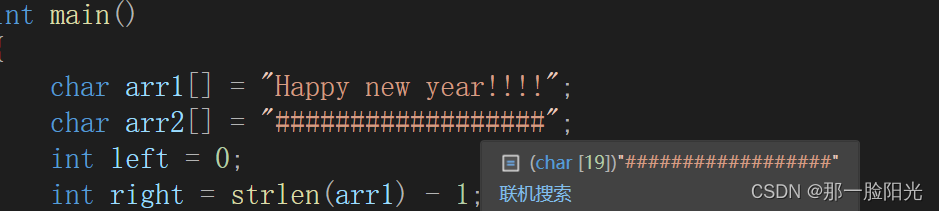
C语言与人生:数组交换和二分查找
少年们,大家好。我是博主那一脸阳光,今天和分享数组交换和二分查找。 前言:探索C语言中的数组交换操作与二分查找算法 在计算机编程领域,特别是以C语言为代表的低级编程语言中,对数据结构的理解和熟练运用是至关重要的…...
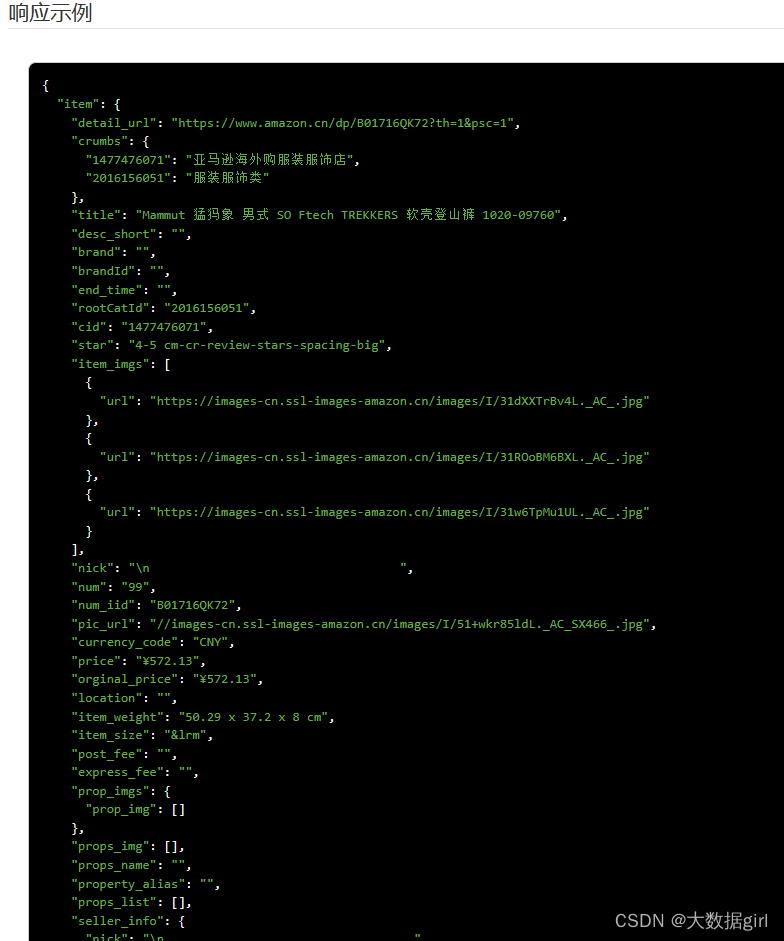
Python实现【亚马逊商品】数据采集
前言 亚马逊公司,是美国最大的一家网络电子商务公司,位于华盛顿州的西雅图 是网络上最早开始经营电子商务的公司之一,亚马逊成立于1994年 今天教大家用Python批量采集亚马逊平台商品数据(完整代码放在文末) 地址&#…...

Git使用教程 gittutorial
该教程对该文章的翻译:https://git-scm.com/docs/gittutorial 本文介绍怎用使用 Git 导入新的工程、修改文件及如何其他人同步开发。 首先, 可以使用以下指令获取文档帮助 git help log笔者注:不建议看这个文档,标准的语法介绍…...
有了向量数据库,我们还需 SQL 数据库吗?
“除了向量数据库外,我是否还需要一个普通的 SQL 数据库?” 这是我们经常被问到的一个问题。如果除了向量数据以外,用户还有其他标量数据信息,那么其业务可能需要在进行语义相似性搜索前先根据某种条件过滤数据,例如&a…...

信息网络协议基础-IPv6协议
文章目录 概述为什么引入IP服务模型IPv4的可扩展性问题解决方法***CIDR(Classless Inter-Domain Routing, 无类别域间寻路)前缀汇聚***前缀最长匹配***NAT(网络地址转换)存在的问题解决方案路由表配置***局限性IPv6协议头标IPv6地址表示前缀类型单播地址链路局部地址(Link-Loca…...

VC++ ado 实现单表CURD
继续修改前文的资产管理源码; 新建一个数据库sds;把代码中的数据库连接改为连接此库; 新建下图一个表; 把之前的资产类别管理对话框改为下图所示;对话框ID也改为下图; 资产类别管理菜单和ID改为下图; 直接修改资产类别管理对话框类不太方便,新建一个对话框类,没有关联…...
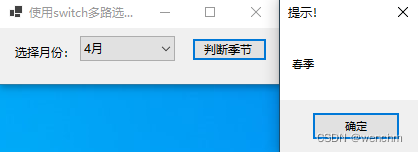
C#使用switch多路选择语句判断何为季节
目录 一、 switch语句 二、示例 三、生成 一、 switch语句 switch语句是多路选择语句,它通过一个表达式的值来使程序从多个分支中选取一个用于执行的分支。 switch表达式的值只可以是整型、字符串、枚举和布尔类型。 switch语句中多个case可以使用一个break。 在…...
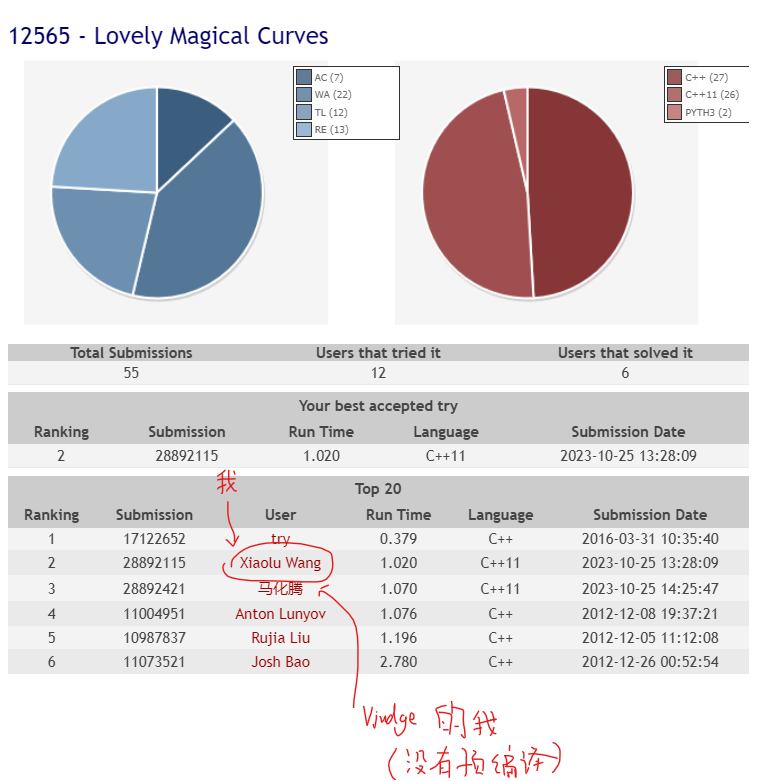
可爱的魔法曲线 Lovely Magical Curves(12年开始只有5个人AC)
一起来交流编程吧!【CSDN app】:http://qm.qq.com/cgi-bin/qm/qr?_wv1027&k3svdDJTlkD76TRRShbxYCYK1zK1c8cyF&authKeyv1pxp6rS8AA4SRy7bflJl9LIwp8d5v0HOudw%2BDxHiWDRqZ1LzjeoBJH1Z1EXnl35&noverify0&group_code546881376 可爱的魔法…...

通过C++程序实现光驱的自动化刻录和读取
文章目录 ISO文件格式光盘的基本概念光盘种类特点DVDR光盘使用windows调用Linux调用Linux平台下用到的C库:读取设备驱动列表向光驱中写文件 数字存储媒体快速发展的今天,光驱的使用已经不像以前那样普及了。但是在数据备份、安装软件和操作系统、旧设备兼容等领域还…...

【电商项目实战】商品详情显示与Redis存储购物车信息
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《电商项目实战》。🎯🎯 &am…...

概率论基础
1.概率论 1.1 随机事件与概率 1.1.1 基本概念 样本点(sample point): 称为试验 S S S的可能结果为样本点,用 ω \omega ω表示。 样本空间(sample space):称试验 S S S的样本点构成的集合为样本空间,用 Ω \Omega Ω表示…...

Mac电脑CMake安装和配置
1.从CMake官网下载dmg文件并且安装 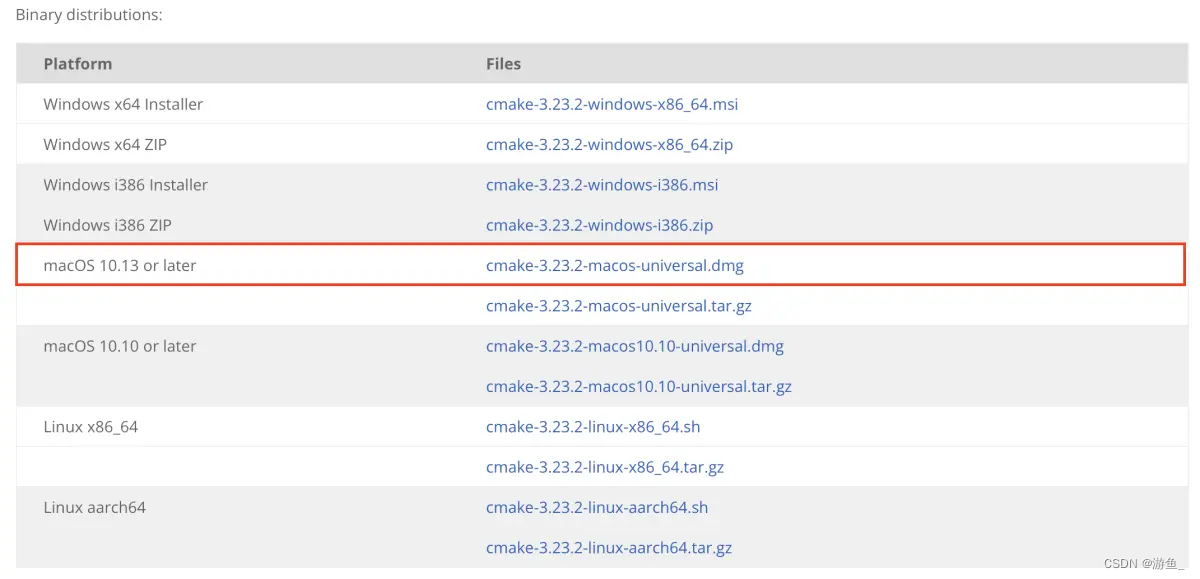...

FormData传送复杂数据
FormData 是一个用于创建表单数据对象的 JavaScript 类。它通常用于通过 JavaScript 发送表单数据,尤其是用于发送 AJAX 请求时非常有用。 使用 FormData 可以方便地构建一个以 multipart/form-data 格式提交的表单数据,这允许你在发送 XMLHttpRequest …...

力扣回溯算法-电话号码的字母组合
力扣第17题,电话号码的字母组合 题目 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 .电话号码的字母组合 示例: 输入:“2…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...

ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台
ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...

从零实现神经网络:前向传播、反向传播与梯度下降原理详解
1. 项目概述:从“黑箱”到“白箱”的探索之旅“人工神经网络”这个词,听起来总带着点科幻和神秘色彩,仿佛一个能自己思考的“黑箱”。很多刚接触的朋友,包括几年前的我,都曾被它吓住——又是矩阵运算,又是梯…...
)
尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表)
更多请点击: https://intelliparadigm.com 第一章:尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表) 尼泊尔语(नेपाली)作为IS…...
)
【实用小程序】超轻量级文件上传下载中心 (File Download Server)
站内源码及jar包下载 一、项目概述 文件下载中心一个基于 Java 内置 HTTP 服务器(com.sun.net.httpserver)构建的轻量级文件管理服务。它零第三方依赖,单 JAR 包即可运行,适合在内网环境或临时场景中快速搭建文件共享站点。 你的团队需要临时共享一批日志文件或交付物,…...

Arm Neoverse CMN-650一致性网格网络架构与配置解析
1. Arm Neoverse CMN-650 一致性网格网络架构解析在现代多核处理器设计中,一致性网格网络(Coherent Mesh Network)已成为解决核心间通信瓶颈的关键技术。Arm Neoverse CMN-650作为第二代一致性互连解决方案,其架构设计体现了三个核…...

基于大语言模型的学术论文AI阅读助手:从PDF解析到智能问答全流程解析
1. 项目概述:一个为学术论文阅读而生的AI助手 如果你经常需要阅读海量的学术论文,尤其是计算机科学、人工智能领域的英文PDF文献,那你一定对那种“打开一篇新论文,面对几十页的陌生术语和复杂公式,不知从何读起”的无…...

ngx_http_read_request_header
1 定义 ngx_http_read_request_header 函数 定义在 ./nginx-1.24.0/src/http/ngx_http_request.cstatic ssize_t ngx_http_read_request_header(ngx_http_request_t *r) {ssize_t n;ngx_event_t *rev;ngx_connection_t *c;ngx_http_…...
如何用二维图像实现三维物体识别?)
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别?
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别? 【免费下载链接】mvcnn_pytorch MVCNN on PyTorch 项目地址: https://gitcode.com/gh_mirrors/mv/mvcnn_pytorch 在计算机视觉领域,三维物体识别一直是一个具有…...