SparkStreaming与Kafka整合
1.3 SparkStreaming与Kafka整合
1.3.1 整合简述
kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。 二者的整合,有主要的两大版本。
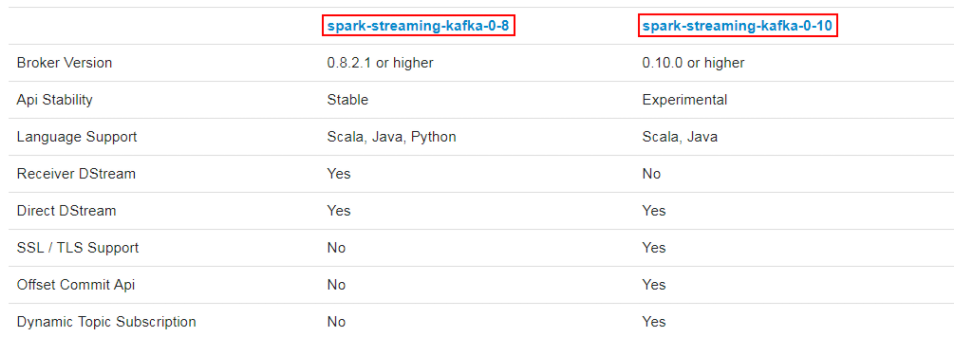
kafka作为一个实时的分布式消息队列,实时的生产和消费消息,在实际开发中Spark Streaming经常会结合Kafka来处理实时数据。Spark Streaming 与 kafka整合需要引入spark-streaming-kafka.jar,该jar根据kafka版本有2个分支,分别是spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10。jar包分支选择原则:
-
0.10.0>kafka版本>=0.8.2.1,选择 08 接口
-
kafka版本>=0.10.0,选择 010 接口
sparkStreaming和Kafka整合一般两种方式:Receiver方式和Direct方式
Receiver方式(介绍)
Receiver方式基于kafka的高级消费者API实现(高级优点:高级API写起来简单;不需要去自行去管理offset,系统通过zookeeper自行管理;不需要管理分区,副本等情况,系统自动管理;消费者断线会自动根据上一次记录在 zookeeper中的offset去接着获取数据;高级缺点:不能自行控制 offset;不能细化控制如分区、副本、zk 等)。Receiver从kafka接收数据,存储在Executor中,Spark Streaming 定时生成任务来处理数据。

默认配置的情况,Receiver失败时有可能丢失数据。如果要保证数据的可靠性,需要开启预写式日志,简称WAL(Write Ahead Logs,Spark1.2引入),只有接收到的数据被持久化之后才会去更新Kafka中的消费位移。接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
还有几个需要注意的点:
-
在Receiver的方式中,Spark中的 partition 和 kafka 中的 partition 并不是相关的,如果加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度;
-
对于不同的 Group 和 Topic 可以使用多个 Receiver 创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream;
-
如果启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是:KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER)
-
WAL将接收的数据备份到HDFS上,保证了数据的安全性。但写HDFS比较消耗性能,另外要在备份完数据之后还要写相关的元数据信息,这样总体上增加job的执行时间,增加了任务执行时间;
-
总体上看 Receiver 方式,不适于生产环境;
1.3.2 Direct的方式
Direct方式从Spark1.3开始引入的,通过 KafkaUtils.createDirectStream 方法创建一个DStream对象,Direct方式的结构如下图所示。
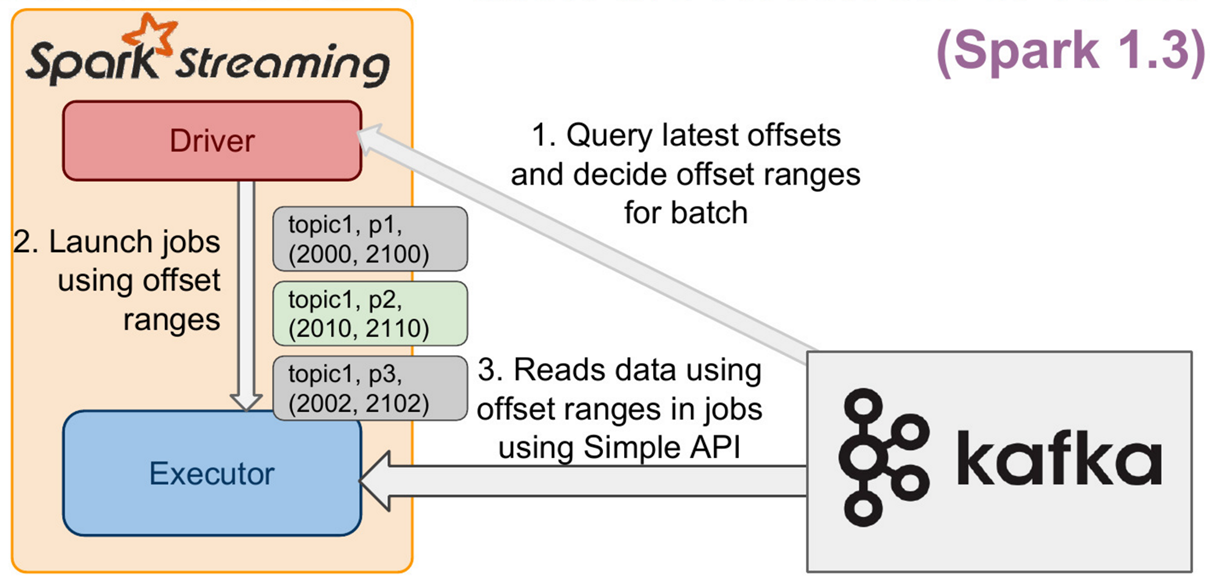
Direct 方式特点如下:
-
对应Kafka的版本 0.8.2.1+
-
Direct 方式
-
Offset 可自定义
-
使用kafka低阶API
-
底层实现为KafkaRDD
该方式中Kafka的一个分区与Spark RDD对应,通过定期扫描所订阅Kafka每个主题的每个分区的最新偏移量以确定当前批处理数据偏移范围。与Receiver方式相比,Direct方式不需要维护一份WAL数据,由Spark Streaming程序自己控制位移的处理,通常通过检查点机制处理消费位移,这样可以保证Kafka中的数据只会被Spark拉取一次。
-
引入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.1.2</version> </dependency>
-
模拟kafka生产数据
package com.qianfeng.sparkstreaming
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
/*** 向kafka中test主题模拟生产数据;;;也可以使用命令行生产:kafka-console-producer.sh --broker-list qianfeng01:9092,hadoop02:9092,hadoop03:9092 -topic test*/
object Demo02_DataLoad2Kafka {def main(args: Array[String]): Unit = {val prop = new Properties()//提供Kafka服务器信息prop.put("bootstrap.servers","qianfeng01:9092")//指定响应的方式prop.put("acks","all")//请求失败重试的次数prop.put("retries","3")//指定key的序列化方式,key是用于存放数据对应的offsetprop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer")//指定value的序列化方式prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer")//创建producer对象val producer = new KafkaProducer[String,String](prop)//提供一个数组,数组中数据val arr = Array("hello tom","hello jerry","hello dabao","hello zhangsan","hello lisi","hello wangwu",)//提供一个随机数,随机获取数组中数据向kafka中进行发送存储val r = new Random()while(true){val message = arr(r.nextInt(arr.length))producer.send(new ProducerRecord[String,String]("test",message))Thread.sleep(r.nextInt(1000)) //休眠1s以内}}
}
-
实时消费kafka数据
package com.qianfeng.sparkstreaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*** sparkStreaming消费Kafka中的数据*/
object Demo03_SparkStreamingWithKafka {def main(args: Array[String]): Unit = {//1.创建SparkConf对象val conf = new SparkConf().setAppName("SparkStreamingToKafka").setMaster("local[*]")//2.提供批次时间val time = Seconds(5)//3.提供StreamingContext对象val sc = new StreamingContext(conf, time)//4.提供Kafka配置参数val kafkaConfig = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "qianfeng01:9092",ConsumerConfig.GROUP_ID_CONFIG -> "qianfeng","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",)//5.读取Kafka中数据信息生成DStreamval value = KafkaUtils.createDirectStream(sc,//本地化策略:将Kafka的分区数据均匀的分配到各个执行Executor中LocationStrategies.PreferConsistent,//表示要从使用kafka进行消费【offset谁来管理,从那个位置开始消费数据】ConsumerStrategies.Subscribe[String, String](Set("test"), kafkaConfig))//6.将每条消息kv获取出来val line: DStream[String] = value.map(record => record.value())//7.开始计算操作line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()//line.count().print() //每隔5s的数据条数//8.开始任务sc.start()sc.awaitTermination()}
}
-
说明
-
简化的并行性:不需要创建多个输入Kafka流并将其合并。 使用directStream,Spark Streaming将创建与使用Kafka分区一样多的RDD分区,这些分区将全部从Kafka并行读取数据。 所以在Kafka和RDD分区之间有一对一的映射关系。
-
效率:在第一种方法中实现零数据丢失需要将数据存储在预写日志中,这会进一步复制数据。这实际上是效率低下的,因为数据被有效地复制了两次:一次是Kafka,另一次是由预先写入日志(WriteAhead Log)复制。这个第二种方法消除了这个问题,因为没有接收器,因此不需要预先写入日志。只要Kafka数据保留时间足够长。
-
正好一次(Exactly-once)的语义:第一种方法使用Kafka的高级API来在Zookeeper中存储消耗的偏移量。传统上这是从Kafka消费数据的方式。虽然这种方法(结合提前写入日志)可以确保零数据丢失(即至少一次语义),但是在某些失败情况下,有一些记录可能会消费两次。发生这种情况是因为Spark Streaming可靠接收到的数据与Zookeeper跟踪的偏移之间的不一致。因此,在第二种方法中,我们使用不使用Zookeeper的简单Kafka API。在其检查点内,Spark Streaming跟踪偏移量。这消除了Spark Streaming和Zookeeper/Kafka之间的不一致,因此Spark Streaming每次记录都会在发生故障的情况下有效地收到一次。为了实现输出结果的一次语义,将数据保存到外部数据存储区的输出操作必须是幂等的,或者是保存结果和偏移量的原子事务。
-
Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客
相关文章:
SparkStreaming与Kafka整合
1.3 SparkStreaming与Kafka整合 1.3.1 整合简述 kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。 二者的整合,有主要的两大版本。 kaf…...

openwrt源码编译
下载openwrt源码 git clone https://github.com/openwrt/chaos_calmer.git // 官方下载地址 当前我们基于15.05版本开发,如果开发者想用最新的OpenWRT系统,可以下载 https://github.com/openwrt/openwrt.git git clone https://github.com/Ying-Yun/o…...

【Leetcode Sheet】Weekly Practice 22
Leetcode Test 1349 参加考试的最大学生数(12.26) 给你一个 m * n 的矩阵 seats 表示教室中的座位分布。如果座位是坏的(不可用),就用 # 表示;否则,用 . 表示。 学生可以看到左侧、右侧、左上、右上这四个方向上紧邻…...

ROS TF坐标变换 - 静态坐标变换
目录 一、静态坐标变换(C实现)二、静态坐标变换(Python实现) 如前文所属,ROS通过广播的形式告知各模块的位姿关系,接下来详述这一机制的代码实现。 模块间的位置关系有两种类型,一种是相对固定…...

香橙派5plus从ssd启动Ubuntu
官方接口图 我实际会用到的就几个接口,背面的话就一个M.2固态的位置: 其中WIFI模块的接口应该也可以插2230的固态,不过是pcie2.0的速度,背面的接口则是pcie3.0*4的速度,差距还是挺大的。 开始安装系统 准备工作 一张…...

JWT+Redis 实现接口 Token 校验
1、业务逻辑 有一些接口,需要用户登录以后才能访问,用户没有登录则无法访问。 因此,对于一些限制用户访问的接口,可以在请求头中增加一个校验参数,用于判断接口对应的用户是否登录。 而对于一些不需要登录即可访问的接…...
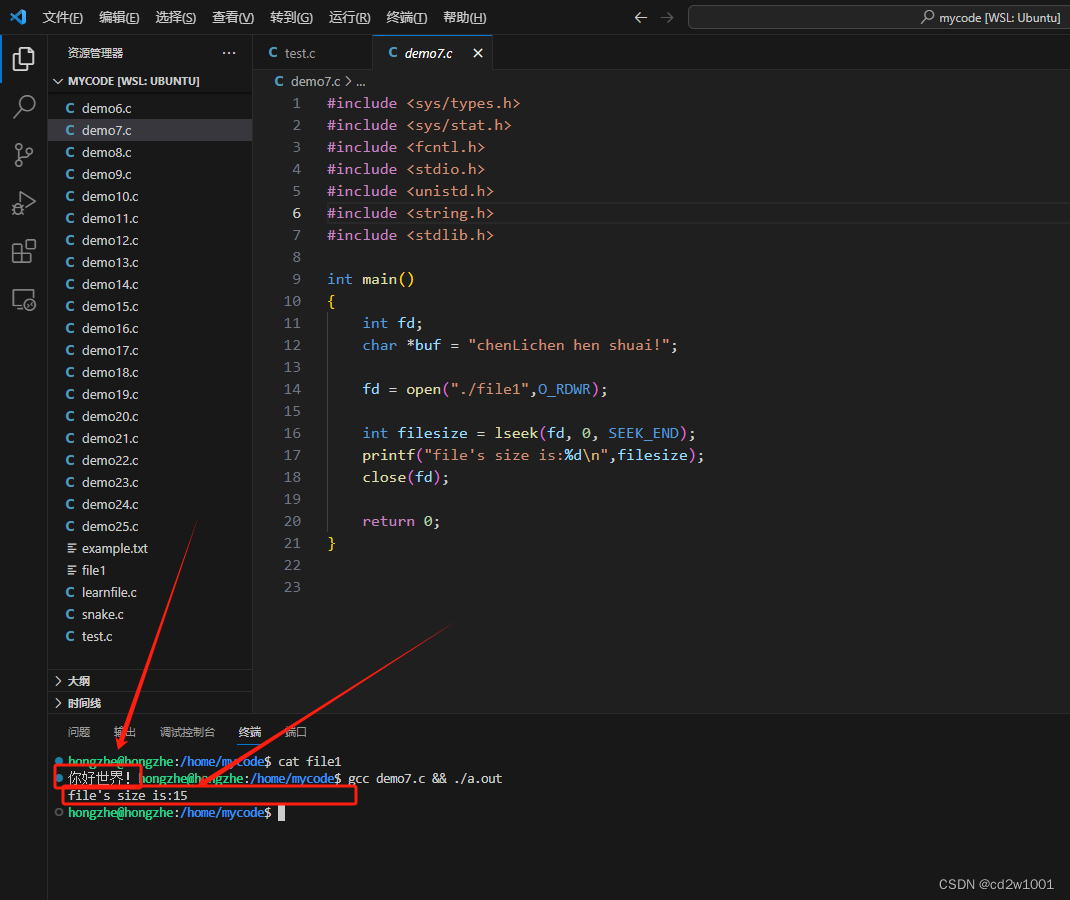
C语言 linux文件操作(二)
文章目录 一、获取文件长度二、追加写入三、覆盖写入四、文件创建函数creat 一、获取文件长度 通过lseek函数,除了操作定位文件指针,还可以获取到文件大小,注意这里是文件大小,单位是字节。例如在file1文件中事先写入"你好世…...
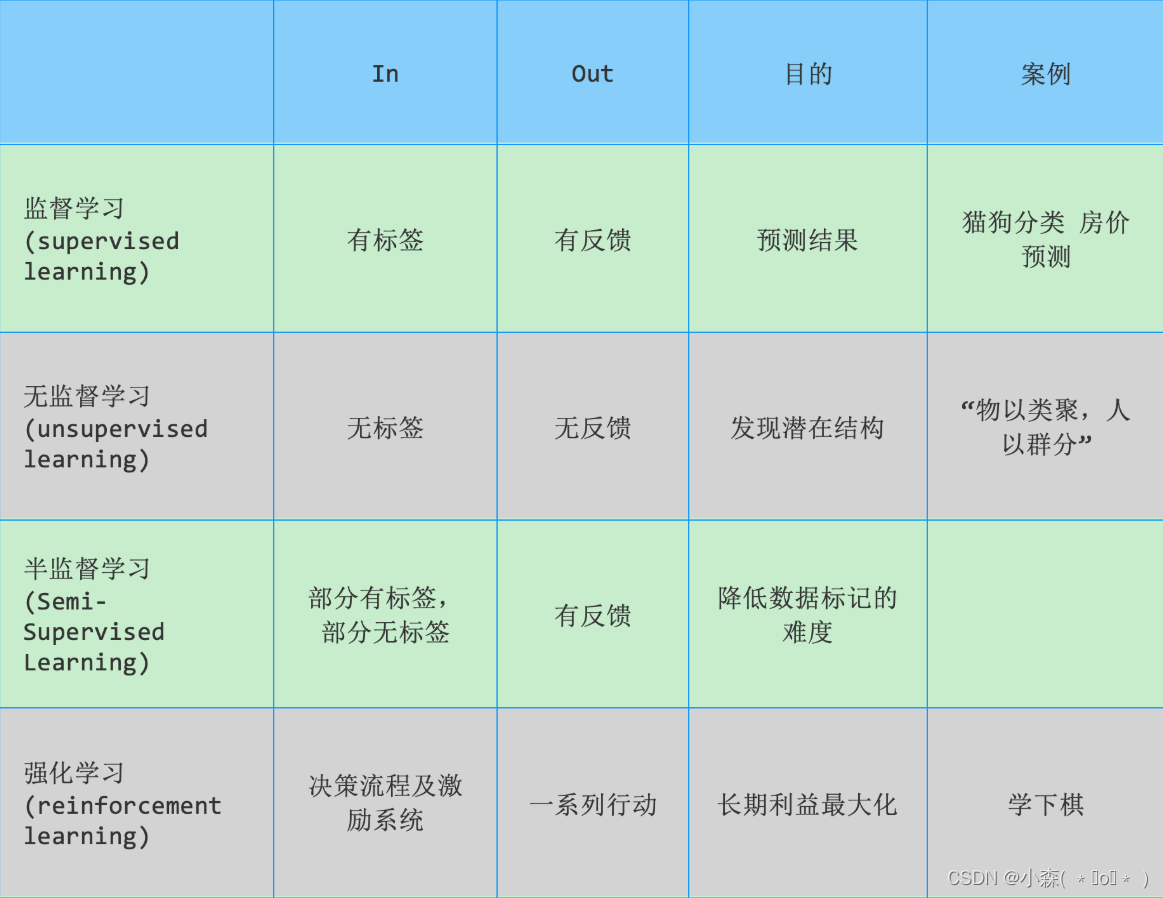
机器学习分类
1. 监督学习 监督学习指的是人们给机器一大堆标记好的数据,比如: 一大堆照片,标记出哪些是猫的照片,哪些是狗的照片 让机器自己学习归纳出算法或模型 使用该算法或模型判断出其他没有标记的照片是否是猫或狗 上述流程如下图所…...

CSS之元素转换
我想大家在写代码时有一个疑问,块级元素可以转换成其他元素吗? 让我为大家介绍一下元素转换 1.display:block(转换成块元素) display:block可以把我们的行内元素或者行内块元素转换成块元素 接下来让我为大家演示一下: <!DO…...
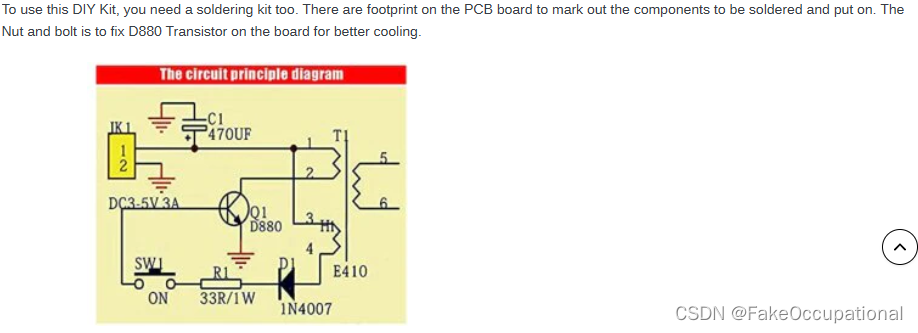
自激振荡电路笔记 电弧打火机
三极管相关 三极管的形象描述 二极管 简单求解(理想) 优先导通(理想) 恒压降 稳压管(二极管plus) 基础工作模块 理想稳压管的工作特性 晶体管之三极管(“两个二极管的组合” ) 电弧打火机电路 1.闭合开…...

Linux su 命令
Linux su(英文全拼:switch user)命令用于变更为其他使用者的身份,除 root 外,需要键入该使用者的密码。 使用权限:所有使用者。 语法 su [-fmp] [-c command] [-s shell] [--help] [--version] [-] [USE…...
论文阅读: AAAI 2022行人重识别方向论文-PFD_Net
本篇博客用于记录一篇行人重识别方向的论文所提出的优化方法《Pose-Guided Feature Disentangling for Occluded Person Re-identification Based on Transformer》,论文中提出的PDF_Net模型的backbone是采用《TransReID: Transformer-based Object Re-Identificati…...

蓝牙物联网灯控设计方案
蓝牙技术是当前应用最广泛的无线通信技术之一,工作在全球通用的 2.4GHZ 的ISM 频段。蓝牙的工作距离约为 100 米,具有一定的穿透性,没有方向限制。具有低成本、抗干扰能力强、传输质量高、低功耗等特点。蓝牙技术组网比较简单,无需…...

Codeforces Round 900 (Div. 3)(A-F)
比赛链接 : Dashboard - Codeforces Round 900 (Div. 3) - Codeforces A. How Much Does Daytona Cost? 题面 : 思路 : 在序列中只要找到k,就返回true ; 代码 : #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0)…...

vue大屏-列表自动滚动vue-seamless-scroll
vue大屏-列表自动滚动vue-seamless-scroll vue-seamless-scroll的官方文档地址:https://chenxuan0000.github.io/vue-seamless-scroll/zh/guide/ 具体效果可到官方文档那里查看。 1、下载依赖 npm install vue-seamless-scroll --save2、使用例子 <template…...
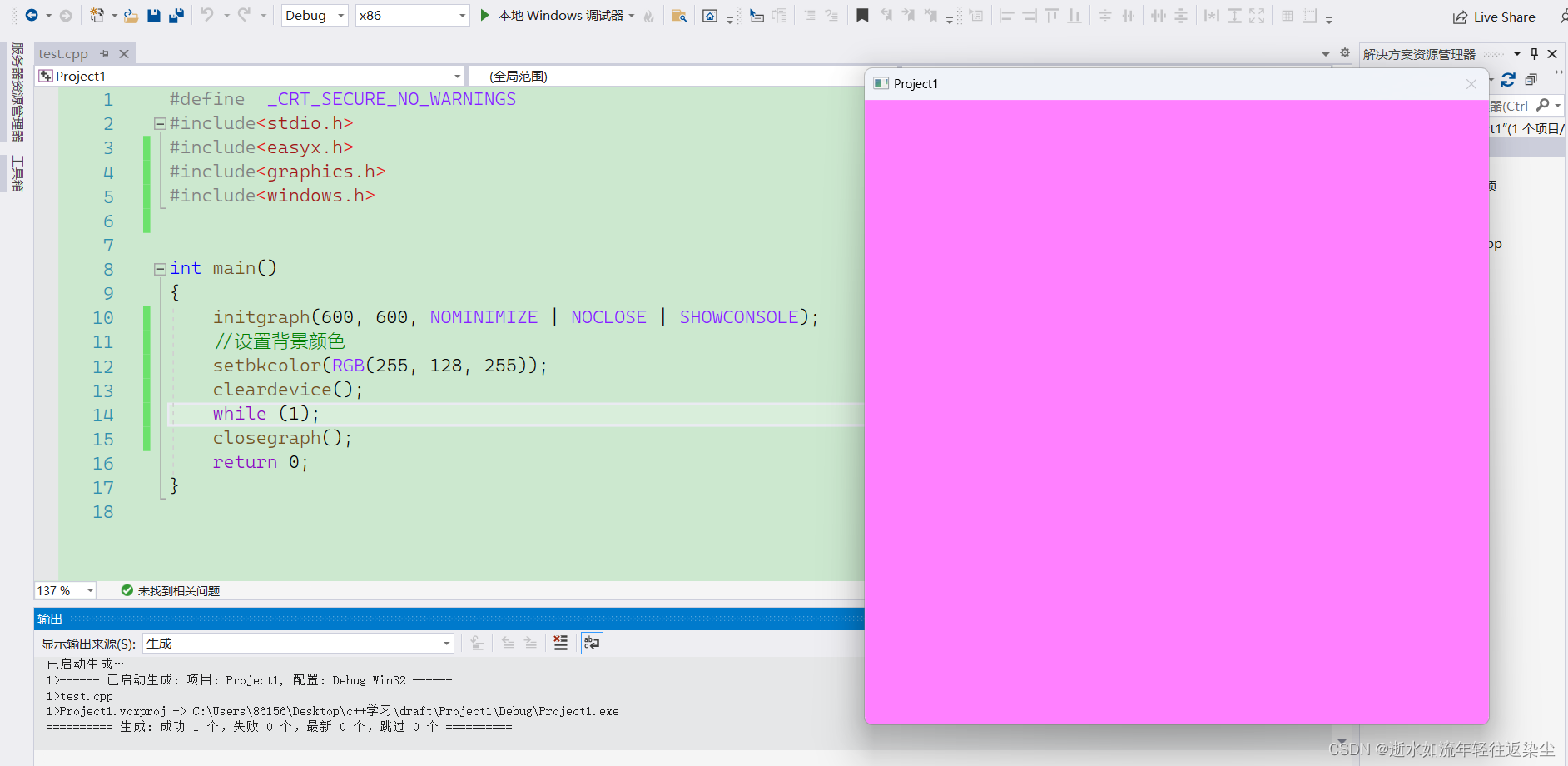
easyx的窗口函数
文章目录 前言一、EasyX的颜色二、EasyX的坐标和设备1,EasyX的坐标2,EasyX的设备 三、窗口函数1,初始化窗口函数2,关闭绘图窗口3,设置窗口背景板颜色4,清空绘图设备 前言 easyx是针对c的图形库,…...

【记录】开始学习网络安全
本文持续更新学习进度 背景 在私企干了5年虚拟化、云原生相关的运维,学到了很多,但不成体系。老板是清华毕业法国留学在德勤干过,最后回国创业的野路子。我工作是为了更好的生活,我挺担心老板因为家庭变故或者炒个原油宝&#x…...
【Java EE初阶三 】线程的状态与安全(下)
3. 线程安全 线程安全:某个代码,不管它是单个线程执行,还是多个线程执行,都不会产生bug,这个情况就成为“线程安全”。 线程不安全:某个代码,它单个线程执行,不会产生bug,…...

MD5算法
一、引言 MD5(Message-Digest Algorithm 5)是一种广泛应用的密码散列算法,由Ronald L. Rivest于1991年提出。MD5算法主要用于对任意长度的消息进行加密,将消息压缩成固定长度的摘要(通常为128位)。在密码学…...

Postman使用
Postman使用 Pre-request Script 参考: Scripting in Postman 可以请求、集合或文件夹中添加Pre-request Script,在请求运行之前执行JavaScript 如设置变量值、参数、Header和正文数据,也可以使用Pre-request Script来调试代码࿰…...

突破性开源Switch模拟器Ryujinx:零基础实现PC端任天堂游戏全兼容
突破性开源Switch模拟器Ryujinx:零基础实现PC端任天堂游戏全兼容 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 想在电脑上体验《塞尔达传说:旷野之息》的冒险…...

避开这些坑,你的YOLO论文才能发得快!目标检测老鸟的实战避坑与效率工具清单
YOLO论文高效产出指南:目标检测老手的避坑策略与工具链实战 实验室的灯光在凌晨三点依然亮着,屏幕上YOLOv8的loss曲线却像心电图一样毫无规律地跳动着。这已经是本周第三次复现顶会论文失败,而距离截稿日期只剩三周。如果你也经历过这种"…...

别再瞎猜了!LaTeX排版中em、ex、pt、px到底该用哪个?一篇讲透所有单位
LaTeX排版单位全指南:从em到px的精准选择法则 当你第一次打开LaTeX文档,准备调整行距或设置边距时,那些神秘的缩写——em、ex、pt、px——是否让你感到困惑?每个单位似乎都有其存在的理由,但何时使用哪个才是最合适的&…...
)
别再只会写脚本了!用Matlab APP Designer给你的数据分析做个可视化界面(附完整代码)
从脚本到交互式应用:用MATLAB APP Designer打造专业数据分析工具 在数据科学和工程领域,MATLAB一直是不可或缺的计算工具。然而,许多用户长期停留在命令行脚本的层面,未能充分发挥MATLAB的完整潜力。本文将带您突破这一局限&#…...

僧伽罗文语音本地化迫在眉睫!斯里兰卡新《数字服务法》2024年10月生效前,你必须掌握的7项ElevenLabs合规配置
更多请点击: https://intelliparadigm.com 第一章:僧伽罗文语音本地化的法律动因与技术紧迫性 斯里兰卡《官方语言法》(No. 33 of 1956)及2023年修订的《国家数字包容战略》明确要求:所有面向公众的政府数字服务必须支…...

企业内网开发场景下,利用Taotoken实现大模型API的统一网关与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网开发场景下,利用Taotoken实现大模型API的统一网关与审计 在中大型企业的研发环境中,引入大模型能力…...

Claude Code出质量事故了?Anthropic发了一篇有诚意的复盘|AI新岗位FDE爆火
每天更新,带你读懂科技圈。 今日看点: Anthropic 正式回应 Claude Code 质量下降的社区讨论,披露三条幕后原因;FDE(Forward Deployed Engineer)正在成为 AI 公司争抢的新岗位;Figma 自研 Redis …...

3步掌握OmenSuperHub:惠普游戏本性能控制终极指南
3步掌握OmenSuperHub:惠普游戏本性能控制终极指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿界面…...

题解:学而思编程 3或5的倍数
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。 欢迎大…...

2026届学术党必备的AI辅助写作网站实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术研究范畴之内,撰写上一篇具备高质量水平的论文,乃是每一位学者…...