【BERT】深入理解BERT模型1——模型整体架构介绍
前言
BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年
近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BERT模型的变体,而且在模型中增加了BERT预训练模型之后,许多NLP任务的模型性能都得到了很大程度的提升,这也说明了BERT模型的有效性。
由于BERT模型内容较多,想要深入理解该模型并不容易,所以我分了大概三篇博客来介绍BERT模型,第一篇(也就是本篇博客)主要介绍BERT模型的整体架构,对模型有一个整体的认识和了解;第二篇详细介绍BERT模型中的重点内容,包括它所提出的两个任务;第三篇从代码的角度来理解BERT模型。
目前我只完成了前两篇论文,地址如下,之后完成第三篇会进行更新。
第一篇:【BERT】深入理解BERT模型1——模型整体架构介绍
第二篇:【BERT】深入BERT模型2——模型中的重点内容,两个任务
第三篇:
BERT整体架构介绍
1、BERT模型基于Transformer架构实现,是一种全新的双向编码器语言模型。与ELMo、GPT等单相语言模型不同,BERT旨在构建一个双向的语言模型来更好地捕获语句间的上下文语义,使其在更多的下游任务上具有更强的泛化能力。因此,预训练完成的BERT模型被迁移到下游任务时,只需要再添加一个额外的输出层便可以进行微调,例如问答和语言推理任务,并不需要针对具体的任务进行模型架构的修改。
2、为了使NLP模型能够充分利用海量廉价的无标注数据信息,预训练语言模型应运而生。
通过模型预训练,我们可以从海量数据集中初步获取潜在的特征规律,再将这些共性特征移植到特定的任务模型中去,将学习到的知识进行迁移。具体来说,我们需要将模型在一个通用任务上进行参数训练,得到一套初始化参数,再将该初始化模型放置到具体任务中,通过进一步的训练来完成更加特殊的任务。
预训练模型的推广,使得许多NLP任务的性能获得了显著提升,它为模型提供了更好的初始化参数,大大提高了其泛化能力。
3、当前的预训练模型主要分为基于特征和微调两大类,但它们大都基于单向的语言模型来进行语言学习表征,这使得许多句子级别的下游任务无法达到最优的训练效果。本文提出的BERT模型(双向预训练表征模型),很大程度上缓解了单向模型带来的约束。同时,引入了“完形填空”和“上下句匹配”分别作为单词级别和句子级别的两大通用任务,对BERT模型进行训练。
基于特征的无监督方法主要是指单词嵌入表征学习。首先将文本级别的输入输出为特征向量的形式,再将预训练好的嵌入向量作为下游任务的输入。
基于微调的无监督方法主要是在,我们在某些通用任务上预训练完成的模型架构,可以被直接复制到下游任务中,下游任务根据自身需求修改目标输出,并利用该模型进行进一步的训练。也就是说,下游任务使用了和预训练相同的模型,但是获得了一个较优的初始化参数,我们需要对这些参数进行微调,从而在特殊任务上获得最优性能。
基于有监督数据的迁移学习,是基于存在大量有监督数据集的任务来获取预训练模型,例如自然语言推理和机器翻译。
4、BERT模型创造性地将Transformer中的Encoder架构引入预训练模型中,成为第一个使用双向表征的预训练语言模型。同时,为了适应该双向架构,BERT引入了两项新的NLP任务——完形填空和上下句匹配,类捕获词语级别和句子级别的表征,并使之具有更强的泛化能力。
5、具体方法:
BERT整体框架包含Pre-training和Fine-tuning两个阶段,Pre-training阶段,模型首先在设定的通用任务上,利用无标签数据进行训练。训练好的模型获得了一套初始化参数之后,再到Fine-tuning阶段,模型被迁移到特定任务中,利用有标签数据继续调整参数,知道在特定任务上重新收敛。
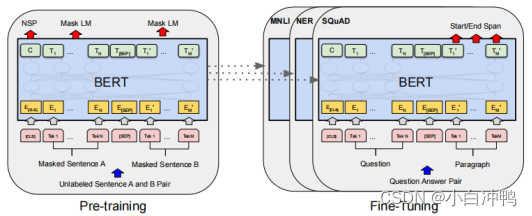
BERT模型采用了Transformer中的Encoder架构,通过引入多头注意力机制,将Encoder块进行堆叠,形成最终的BERT架构。为了适应不同规模的任务,BERT将其结构分为了base和large两类,较小规模的base结构含有12个Encoder单元,每个单元含有12个Attention块,词向量维度为768;较大规模的large结构含有24个Encoder单元,每个单元中含有16个Attention块,词向量维度为1024。通过使用Transformer作为模型的主要框架,BERT能够更彻底地捕获语句中的双向关系,极大地提升了预训练模型在具体任务中的性能。
BERT模型的输入由三部分组成。除了传统意义上的token词向量外,BERT还引入了位置词向量和句子词向量。位置词向量的思想与Transformer一致,但BERT并未使用其计算公式,而是随机初始化后放入模型一同训练;句子词向量实质上是一个0-1表征,目的是区分输入段落中的上下句。这三种不同意义的词向量相加,构成了最终输入模型的词向量。
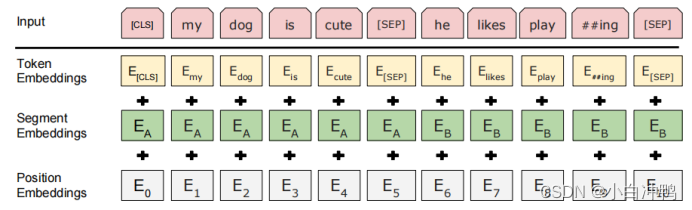
Pre-training:BERT的预训练部分使用了完形填空和上下句匹配两个无监督任务。“完形填空”代表了词语级别的预训练任务,该任务对输入句子中若干随机位置的字符进行遮盖,并利用上下文语境对遮盖字符进行预测。(MLM)“上下句匹配”代表了句子级别的预训练任务,该任务给出两个句子,利用句子之间的语义连贯性判定这两个句子是否存在上下句关系。这两个预训练任务对于大量NLP任务的架构具有更好的代表性,同时也更能匹配模型本身的双向架构,对模型的泛化能力有着巨大的提升帮助。
Fine-tuning:训练具体任务时,我们只需将具体任务中的输入输出传入预训练完成的BERT模型,继续调整参数直至模型再次收敛。该过程成为微调(Fine-tuning)。相比于预训练来说,微调的代价是极小的。在大部分NLP任务中,我们只需要在GPU上对模型进行几个小时的微调,便可使模型在具体任务上收敛,完成训练。
6、实验结果及结论
结果表明,即使是在有标签数据量较小的数据集上,随着模型规模的提高,任务的准确度都获得了显著的提升。进一步可得出结论:如果模型已经经过过滤充分的预训练,那么当将模型缩放到一个极限的规模尺寸时,仍然能够在小规模的微调任务上产生较大的改进。
预训练模型的迁移学习,逐渐成为语言理解系统中不可或缺的一部分,它甚至能够使得一些低资源的任务从深度单向架构中受益。
以上就是对BERT模型理论知识的整体理解,看完之后应该能有个整体的认识吧。
相关文章:
【BERT】深入理解BERT模型1——模型整体架构介绍
前言 BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年 近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BE…...

【Java开发岗面试】八股文—设计模式
声明: 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试…...
、临界资源安全问题(锁、channel))
GO基础进阶篇 (九)、临界资源安全问题(锁、channel)
临界资源安全问题 在并发编程中对临界资源的处理不当,往往会导致数据的不一致问题 package mainimport ("fmt""time" )func main() {a : 1go func() {a 2fmt.Println("goroutine", a)}()a 3fmt.Println("a", a)time.Sl…...
)
Python基础-04(比较运算符、逻辑运算符)
文章目录 前言一、比较运算符二、逻辑运算符1.and(与)2.or(或)3.not(非)4.逻辑运算符的细节(短路原则)(着重理解) 总结 前言 1、比较运算符内容很简单&#…...

MySQL 四种插入命令及其特点与锁机制
目录 1. INSERT INTO 2. INSERT IGNORE INTO 3. INSERT INTO ... ON DUPLICATE KEY UPDATE 4. REPLACE INTO 总结 MySQL提供了多种数据插入方式,每种方式在处理唯一键冲突时的行为不同,同时也涉及不同的锁机制。 1. INSERT INTO INSERT INTO是标准…...

AKShare学习笔记
AKShare学习笔记 本文内容参考AKShare文档。AKShare开源财经数据接口库采集的数据都来自公开的数据源,数据接口查询出来的数据具有滞后性。接口参考AKShare数据字典。 AKShare环境配置 安装Anaconda,使用Anaconda3-2019.07版本包,配置清华数…...

A星寻路算法
A星寻路算法简介 A星寻路算法(A* Search Algorithm)是一种启发式搜索算法,它在图形平面上进行搜索,寻找从起始点到终点的最短路径。A星算法结合了广度优先搜索(BFS)和最佳优先搜索(Best-First S…...
QDialog
属性方法 样式表 background-color: qlineargradient(spread:reflect, x1:0.999896, y1:0.494136, x2:1, y2:1, stop:0 rgba(0, 0, 0, 255), stop:1 rgba(255, 255, 255, 255));border: 1px groove rgb(232, 232, 232);border-radius: 20px; QDialog 的常用方法: e…...
Spark中使用DataFrame进行数据转换和操作
Apache Spark是一个强大的分布式计算框架,其中DataFrame是一个核心概念,用于处理结构化数据。DataFrame提供了丰富的数据转换和操作功能,使数据处理变得更加容易和高效。本文将深入探讨Spark中如何使用DataFrame进行数据转换和操作࿰…...
windows11新装机,简单评测系统自带软件(基本涵盖日常所需应用)
新年将近,由于当年安排的失误,系统盘(100G)和照片视频盘(4T)容量不够了,大容量的那块机械盘放在机箱里就在耳朵根吵吵,烦得很,于是狠狠心决定扩容后重配重装。 2023年最后…...

概念解析 | Shapley值及其在深度学习中的应用
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:Shapley值及其在深度学习中的应用。 1 背景介绍 在机器学习和数据分析中,理解模型的预测是非常重要的。尤其是在深度学习黑盒模型中,我们往往难以直观地理解模型的预测行为。为…...

ajax的完整写法——success/error/complete+then/catch/done+设置请求头两种方法——基础积累
ajax的完整写法——success/error/completethen/catch/done设置请求头两种方法——基础积累 1.完整写法——success/error/complete1.1 GET/DELETE——query传参1.2 GET/DELETE——JSON对象传参1.3 PUT/POST——JSON对象传参 2.简化写法——then/catch/done2.1 GET/DELETE——q…...

《Linux详解:深入探讨计算机基础》
《Linux详解:深入探讨计算机基础》 引言: 在计算机科学领域,操作系统是一个至关重要的概念,而Linux作为一种开源的Unix-like操作系统,不仅在服务器领域广泛应用,也在嵌入式系统、超级计算机等多个领域发挥…...
HarmonyOS 实践之应用状态变量共享
平时在开发的过程中,我们会在应用中共享数据,在不同的页面间共享信息。虽然常用的共享信息,也可以通过不同页面中组件间信息共享的方式,但有时使用应用级别的状态管理会让开发工作变得简单。 根据不同的使用场景,ArkTS…...

ThreadLocal共享变量
一、ThreadLocal 我们知道多线程访问同一个共享变量时,会出现线程安全问题,为了保证线程安全开发者需要对共享变量的访问操作进行适当的同步操作,如加锁等同步操作。 除此之外,Java提供了ThreadLocal类,当一个共享变…...

前端crypto-js 库: MD5
文章目录 什么是crypto-js安装依赖MD5 什么是crypto-js github地址: https://github.com/brix/crypto-js cryptojs文档: https://cryptojs.gitbook.io/docs/#encoders CryptoJS (crypto.js) 为 JavaScript 提供了各种各样的加密算法。 CryptoJS是一个JavaScript加密算法库&a…...

2024新年快乐
2024-1-1 祝福大家和自己健康喜乐,升职加薪,新年快乐 页面加载事件load 我们页面加载事件的触发是等所有的资源加载完毕时触发该事件。和click一样是事件,但是触发时机是等资源加载(浏览器)完毕。这个事件我们可以将…...

OpenCV-Python(21):轮廓特征及周长、面积凸包检测和形状近似
2. 轮廓特征 轮廓特征是指由轮廓形状和结构衍生出来的一些特征参数。这些特征参数可以用于图像识别、目标检测和形状分析等应用中。常见的轮廓特征包括: 面积:轮廓所包围的区域的面积。周长:轮廓的周长,即轮廓线的长度。弧长&…...
连接progressql报错Cannot load JDBC driver class ‘org.postgresql.Driver‘,亲测有效!!!
Jmeter连接progressql报错Cannot load JDBC driver class ‘org.postgresql.Driver’ 1.到官方下载驱动注意:根据项目的JDK版本来下载对应的驱动Download | pgJDBC 2.将postgresql-42.2.27.jar复制到lib目录下面, 然后重新启动 连接driver信息如下&#…...

SQLAlchemy快速入门
安装依赖 pip install sqlalchemy pip install pymysql创建数据库和表 # 创建数据库 drop database if exists sqlalchemy_demo; create database sqlalchemy_demo character set utf8mb4; use sqlalchemy_demo;# 创建表 drop table if exists user; create table user (id …...

AI编程提示工程实战:从AwesomeCursorPrompt看高效开发与社区协作
1. 项目概述:从“Awesome”前缀看提示工程的社区实践在AI应用开发,特别是大语言模型(LLM)和AI助手交互的领域,一个清晰、结构化的提示(Prompt)往往决定了最终输出质量的80%。很多开发者都有过这…...

别再只跑Demo了!用Mask R-CNN和Balloon数据集实战,手把手教你从训练到可视化调参
从Demo到实战:用Mask R-CNN深入掌握目标分割全流程 当你第一次运行Mask R-CNN的官方示例时,那种"成功运行"的喜悦往往伴随着隐约的不安——代码虽然跑通了,但你真的理解模型是如何训练的吗?Balloon数据集作为经典的入门…...
报错?用Clock.tick()轻松搞定(附完整代码示例))
别慌!Pygame里time.sleep()报错?用Clock.tick()轻松搞定(附完整代码示例)
Pygame时间控制革命:为什么Clock.tick()比time.sleep()更适合游戏开发 在Pygame游戏开发的世界里,时间控制是构建流畅游戏体验的核心要素。许多初学者在从Python标准库转向Pygame时,常常会本能地使用time.sleep()来控制游戏节奏,却…...

Infinity Router:构建统一流量网关的架构设计与生产实践
1. 项目概述:一个面向未来的路由聚合器 最近在折腾一个很有意思的项目,叫“Infinity Router”。这名字听起来挺唬人的,但说白了,它就是一个 路由聚合器 。不过,它和我们平时在项目里用的那些路由库(比如 …...

企业级AI助手私有化部署:Open WebUI完全指南
企业级AI助手私有化部署:Open WebUI完全指南 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui 在数据安全和隐私保护日益重要的今天,企…...

Taotoken 用量看板如何帮助团队清晰追踪与优化 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 用量看板如何帮助团队清晰追踪与优化 API 调用成本 对于依赖大模型 API 进行开发的团队而言,成本控制与资源分…...

三步掌握QQ音乐加密文件解码:qmcdump工具完整实战指南
三步掌握QQ音乐加密文件解码:qmcdump工具完整实战指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...
)
【ElevenLabs葡语语音实战指南】:20年AI语音工程师亲测的5大本地化避坑清单(附实测TTS自然度评分92.7%)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡语语音的核心技术架构与本地化本质 ElevenLabs 的葡语语音合成并非简单地在英语模型上叠加音素映射,而是基于多语言联合训练框架构建的端到端神经语音系统,其核心依…...

Bash脚本AI助手:智能生成命令行,提升运维自动化效率
1. 项目概述:当Bash脚本遇见AI,自动化运维的智能进化如果你是一名运维工程师、系统管理员,或者任何需要与Linux命令行打交道的开发者,那么“Bash脚本”一定是你工具箱里的常客。从批量文件处理、定时任务调度到复杂的部署流程&…...

构建个人技能中心:Git+Markdown打造结构化知识库实践
1. 项目概述:一个技能驱动的开源知识库 最近在整理自己的技术栈和项目经验时,我一直在思考一个问题:如何将那些零散的、在不同项目中反复验证过的“技能点”系统化地沉淀下来,形成一个可以随时查阅、复用和迭代的“个人工具箱”&…...