Hbase的基本概念与架构
一、Hbase的概念
HBase是Hadoop的生态系统,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。如果你需要进行实时读写或者随机访问大规模的数据集的时候,请考虑使用HBase!
HBase作为Google Bigtable的开源实现,Google Bigtable利用GFS作为其文件存储系统类似,则HBase利用Hadoop HDFS作为其文件存储系统;Google通过运行MapReduce来处理Bigtable中的海量数据,同样,HBase利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据,设计它的目的就是用于处理非常庞大的表——通过水平扩展的方式,用计算机集群就可以处理由超过 10 亿行数据和数百万列元素所组成的数据表。
二、Hbase的架构
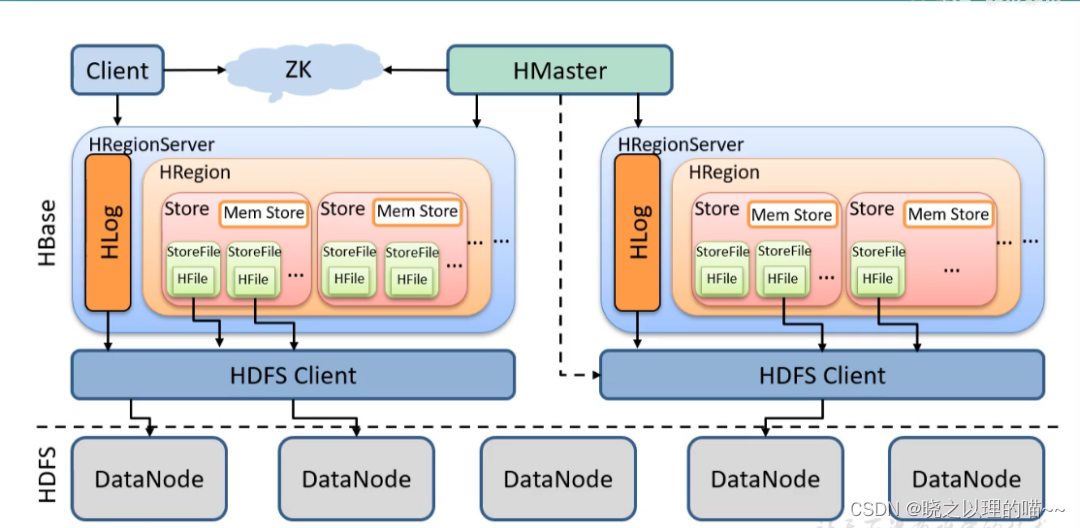
Hbase中的每张表都按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过 256M 就要被分割成两个,由 HRegionServer管理,管理哪些HRegion由HMaster分配。
1,Client
提供了访问HBase的一系列API接口,如Java Native API、Rest风格http API、Thrift API、scala等,并维护cache来加快对HBase的访问。
2,Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用,保证任何时候集群中只有一个Master 、实时监控RegionServer的上线和下线信息,并实时通知Master、元数据的入口以及集群配置的维护等工作。
Zookeeper的作用如下:
- 保证任何时候,
- 集群中只有一个master
- 存储所有Region的寻址入口 实时监控Region
- server的上线和下线信息。并实时通知给master 存储HBase的schema和table元数据
3,HRegion
HBase表在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
4,HRegionServer
(1)RegionServer维护Region,处理对这些Region的IO请求,向HDFS文件系统中读写数据。
一个RegionServer由多个Region组成,一个Region由多个Store组成,一个Store对应一个CF(列族),而一个store包括位于内存中的Mem Store和位于磁盘的StoreFile,每个StoreFile以HFile格式保存在HDFS上。写操作先写入Mem Store,当Mem Store中的数据达到某个阈值时,RegionServer会启动flashcache进程写入StoreFile,每次写入形成单独的一个StoreFile。
(2)RegionServer负责切分在运行过程中变得过大的Region。
每个表一开始只有一个Region,随着表数据不断插入,数据越来越多,StoreFile也越来越大,当StoreFile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),minor主要是合并一些小的文件,不做删除,清理操作,而majar在合并过程中会进行版本合并和删除工作,形成更大的StoreFile。
当一个Region所有StoreFile的大小和数量超过一定阈值后,会把当前的Region分割为两个新的Region(裂变),每个Region保存一段连续的数据片段,如此往复,就会有越来越多的region,并由Master分配到相应的RegionServer服务器,这样一张完整的表被保存在多个RegionServer 上,实现负载均衡。
(3)对于数据的操作:(DML)get, put, delete;
5,Store
每一个Region由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。Store的大小被HBase用来判断是否需要切分Region。
6,StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以HFile的形式存储在HDFS的。每个 Store 会有一个或多个 StoreFile,数据在每个 StoreFile 中都是有序的(按照RowKey的字典顺序排序)。
7,HLog
HLog记录数据的所有变更,可以用来恢复文件,一旦region server 宕机,就可以从log中进行恢复。HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。由于数据要经 Mem Store 排序后才能刷写到 StoreFile,但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logFile的文件中,然后再写入内存中。所以在系统出现故障的时候,可以通过这个日志文件来恢复数据。
8,LogFlusher
一个LogFlusher的类是用来调用HLog.optionalSync()的。
9,HDFS
HDFS 为 HBase 提供底层数据存储服务,同时为 HBase提供高可用的支持, HBase 将 HLog 存储在 HDFS 上,当服务器发生异常宕机时,可以重放 HLog 来恢复数据。
三、Hbase的数据模型
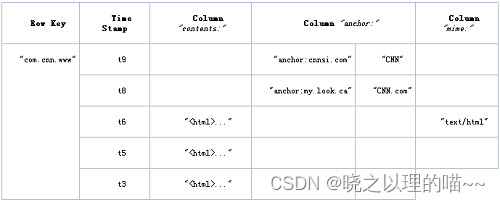
1,逻辑数据模型
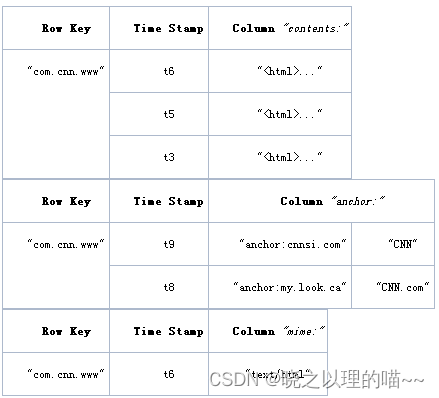
2,物理数据模型
3,数据模型内容
(1)Name Space
命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是“hbase” 和 “default”,“hbase” 中存放的是 HBase 内置的表,“default”表是用户默认使用的命名空间。
(2) Region
类似于关系型数据库的表的概念(实际上Region在HBase数据库中是表的切片)。建表时不同的是,HBase定义表时只需要声明列簇即可,不需要声明具体的列。这意味着,往HBase中写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
(3)Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
(4)Column
HBase 中的每个列都是由Column Family(列簇)和 Column Qualifier(列限定符)运行限定,例如:info: name,info: age 。建表时,只需声明列簇,而列限定符无需预先定义。
(5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。
(6)Cell
由{RowKey, Column Family:Column Qualifier, Time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存储(byte[]数组)。
四、HBase的优缺点
1,HBase的优点
(1)在传统的关系数据库中,如果数据结构发生了变化,就需要停机维护,而且需要修改表结构,而在 HBase 中数据表内的列可以做到动态增加,并且列为空的时候不存储数据,从而节省存储空间。
(2)HBase 适合存储 PB 数量级的海量数据,PB 级的数据在只采用廉价 PC 来存储的情况下,也可以在几十到一百毫秒内返回数据。这与 HBase 的极易扩展息息相关,正因如此,HBase 为海量数据的存储提供了便利。
(3)传统的通用关系数据库无法应对在数据规模剧增时导致的系统扩展性问题和性能问题。HBase 可以做到自动切分数据,并且会随着数据的增长自动地拆分和重新分布。
(4)HBase 可以提供高并发的读写操作,而且可以利用廉价的计算机来处理超过 10 亿行的表数据。
(5)HBase 具有可伸缩性,如果当前集群的处理能力明显下降,可以增加集群的服务器数量来维持甚至提高处理能力。
2,HBase的缺点
(1)不能支持条件查询,只支持按照 RowKey(行键)来查询,也就是只能按照主键来查询。这样在设计 RowKey 时,就需要完美的方案以设计出符合业务的查询。
(2)HBase 不能支持 Master(主)服务器的故障切换,当 Master 宕机后,整个存储系统就会挂掉,不能提供正常的服务。
(3)查询 HBase 时不支持通过 SQL 语句进行查询。
五、HBase的特征
1,海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
2,列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
3,自动分片
HBase 中的表通过 Region 分布在集群上,而且 Region 会随着数据的增长自动拆分和重新分布。
4,并行处理
HBase 支持通过 MapReduce 进行大规模并行处理,将 HBase 用作源和接收器。
5,高可靠性
WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
6,多种语言的API
HBase 支持使用 Java 的 API 来编程进行数据的存取,还支持使用 Thrift 语言和 REST 语言的 API 来编程进行数据的存取。
六、HBase的应用场景
1,数据量超千万,可以选择使用HBase
一般而言,如果单表的数据量只有百万的数量级或者更少,则不建议使用 HBase,而应该考虑关系数据库是否能够满足应用的需求。
2,实时根据主键查询,可以选择使用HBase
HBase 是一个 Key-Value 数据库,默认对 RowKey 做了索引优化,所以即使数据量非常庞大,根据 RowKey 查询的效率也会很高。但是,如果还需要根据其他条件进行查询,则不建议使用 HBase。
3,多表连接查询,不建议使用HBase
HBase 是 NoSQL 产品中的一种,它也具有 NoSQL 的缺点,就是不能进行连表查询等操作,也就是说,如果业务场景是需要事务支持、复杂的关联查询,则不建议使用 HBase。
4,数据分析需求不多,可以选择使用HBase
虽然说 HBase 是一个面向列的数据库,但是它与真正的列式存储系统(比如 Parquet、Kudu等)又有所区别,再加上自身存储架构的设计,使得 HBase 并不擅长做数据分析。所以如果业务需求是为了做数据分析,比如做报表,那么不建议使用 HBase。
相关文章:
Hbase的基本概念与架构
一、Hbase的概念 HBase是Hadoop的生态系统,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。如果你需要进行实时读写或者随机访问大规模的数据集的时候,请考虑使用H…...
颠覆你的认知,业务同事都能开发软件,我简直无地自容……
经常看到网络鼓吹业务人员也能搭建应用,本是嗤之以鼻、半信半疑,但当这件事真实发生在自己身上时,竟觉得此言不虚? 一、背景 最近公司为了集成系统、提升扩展能力,引进了低代码平台JNPF,说个题外话&#…...
01 | n2n虚拟局域网
1 n2n简介 为了满足两个不同局域网的机器进行通信,让不同网段的机器能够进行P2P( 点对点 peer-to-peer ) 通信。2 n2n源码 https://github.com/ntop/n2n.git3 n2n名词 3.1 SuperNode 超级节点 SuperNode 相当与注册中心, 它会记录边缘节点的连接信息,…...
MFC界面控件BCGControlBar v33.4 - 支持Win 11 Mica material主题
BCGControlBar库拥有500多个经过全面设计、测试和充分记录的MFC扩展类。 我们的组件可以轻松地集成到您的应用程序中,并为您节省数百个开发和调试时间。BCGControlBar专业版和BCGSuite for MFC v33.4已正式发布了,该版本包含了对Windows 11 Mica materia…...

手把手教你用js实现手机通讯录功能(附源码)
js实现手机通讯录效果图需求需求一:锚点通过#id配合a标签使用css中scroll-behavior属性的使用需求二需求三获取汉字拼音的首字母方法1:使用插件,这里推荐pinyin-pro方法2:使用unicode去重数组中冗余的对象法一:用Map去…...
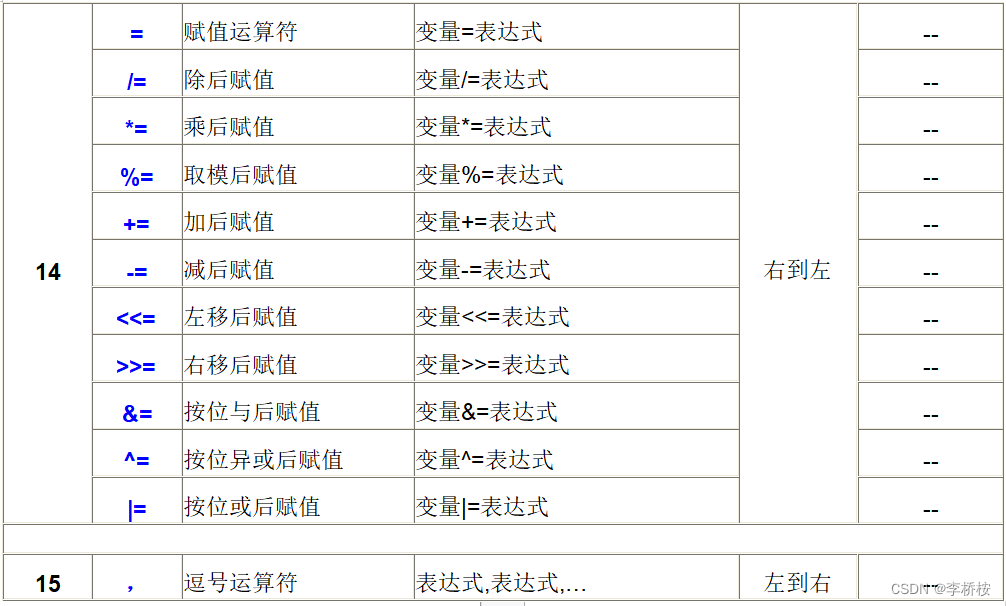
【C/C++】逗号表达式、算术运算符优先级
一、逗号表达式 1、如下图中代码,为变量d赋值,d的值为逗号表达式中的哪一个呢? 运行结果:d的值为6 2、再举个例子 运行结果:d的结果还是6 3、再举个例子 运行结果 以上面三种不同的逗号表达式为例,…...

携禾生物面试总结
面试时间: 2022年2月3日 1.项目C11的特性具体有用到哪些? 智能指针 lambda表达式 auto unordered_map 2.智能指针用到了哪几种智能指针 3.shared_ptr和weak_ptr区别 4.多线程实现方式 prosix线程》pthread windows的_beginthreaex MFC多线程 ACEM中…...

FPGA纯verilog手写HDMI发送IP 提供源码和技术支持
目录1、前言2、设计思路和框架TMDS 编码算法OSERDESE串并转换3、顶层源码和IP封装4、源码和IP获取1、前言 本设计使用Xilinx原语和自己手写的代码实现了HDMI发送功能,纯verilog手写,有源码,也提供封装好的IP,你喜欢用例化的方式就…...
【知识点】OkHttp 原理 8 连问
前言OkHttp可以说是Android开发中最常见的网络请求框架,OkHttp使用方便,扩展性强,功能强大,OKHttp源码与原理也是面试中的常客但是OKHttp的源码内容比较多,想要学习它的源码往往千头万绪,一时抓不住重点.本文从几个问题…...
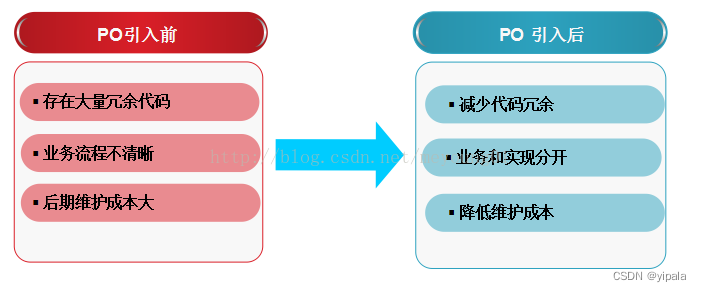
【python】深入了解Selenium-PageObject
1、PageObject 定义 Page Object(简称PO)模式,是Selenium实战中最为流行,并且是自动化测试中最为熟悉和推崇的一种设计模式。在设计自动化测试时,把页面元素和元素的操作方法按照页面抽象出来,分离成一定的对象,然后再…...
)
PAT——7-4 简易测谎 (20 分)
测谎通常使用一套准备好的问题提问被测试者,通过分析被测试者的反应得到结果。比较高级的测谎技术会使用测谎仪,监视被测试者的生理活动状况。我们这里的简易测谎则是通过对问题答案的特征分析来做出判断。 首先我们要求被测试者做完 N 道单选题&#x…...
)
【力扣】 面试题 05.02.二进制数转字符串(超过c++100%)
二进制数转字符串。给定一个介于0和1之间的实数(如0.72),类型为double,打印它的二进制表达式。如果该数字无法精确地用32位以内的二进制表示,则打印“ERROR”。示例1:输入:0.625输出:"0.10…...

软件质量保证与测试 课堂笔记
...

Costco好市多验厂百问百答
【Costco好市多验厂百问百答】美国仓储式超市Costco,中文好市多,近几年发展势头迅猛,大有赶超传统商超巨头沃尔玛之势。之前有出口企业反馈,Costco采购不仅量大,而且价格好,所以Costco成为国内出口企业纷纷…...

Nginx 通过 header 中的标识进行分发
Nginx可以根据请求头中自定义的标识将请求分发到不同的服务器。具体来说,可以使用map指令将请求头中的自定义标识映射为不同的后端服务器地址,然后使用proxy_pass指令将请求转发到对应的后端服务器。 以下是一个示例配置文件: http {map $h…...

如何实现《电子签名法》要求的可靠电子签名?
电子文档的电子签名怎么弄?我们在工作中经常需要在一些Word、pdf等电子版文件中插入签名,而很多人可能不知道,电子签名怎么弄?怎么做电子签名才有效?电子印章或签名图片属于电子签名吗?当工作或商务交易中&…...

工程项目管理软件有哪些?这六款很好用!
工程项目管理软件哪个好用?这六款很不错! 在现代社会中,软件已经成为了企业信息化、项目管理等方面必不可少的工具。尤其是对于工程项目管理而言,借助软件进行协同、计划、控制等方面的工作,已经成为了必要的手段。但…...

多看看spdk代码学习
多看看spdk代码学习还是干货直接上代码简易讲解详细讲解一下这份代码还是干货直接上代码 #include <stdlib.h> #include <stdio.h> #include <string.h> #include <errno.h> #include <unistd.h> #include <signal.h> #include <stdbo…...

宾语从句it做形式主语的句子
It代替从句作形式主语的常见句型 一、it 代替连词 that 引导的从句作形式主语。 1、it be 过去分词 that 从句: It’s said that Tom has come back from abroad . It was reported that dozens of children died in the accident . 可用于该句型的过去分词还有…...

【C#基础】C# 文件与IO
序号系列文章9【C# 基础】C# 异常处理操作10【C#基础】C# 正则表达式11【C#基础】C# 预处理器指令文章目录前言1,文件和IO的概念2,文本文件操作2.1 File 类2.2 FileInfo 类2.3 FileStream 类2.4 StreamReader 类2.5 StreamWriter 类FileStream 和 Stream…...

别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块
别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块 当PLC工程师第一次接触结构化文本(ST)时,往往会被它类似高级编程语言的语法吓退。但事实上,ST在处理复杂算法时的简洁性和高效性&#…...

从Concur到特斯拉:为什么伟大产品始于“丑陋”的1.0版本
1. 从一笔74亿美元的收购案说起:为什么别急着给1.0产品判死刑 前几天翻看一些旧资料,看到一篇2014年的行业评论,讲的是德国软件巨头SAP以74亿美元的天价,收购了一家名叫Concur的西雅图公司。当时很多人觉得不可思议,Co…...

从游戏角色到人脸分析:聊聊‘摇头、点头、转头’背后的欧拉角与万向节死锁
游戏角色控制与人脸分析的奇妙交汇:解码欧拉角与万向节死锁 想象一下你在玩一款3A级开放世界游戏:按下左摇杆,角色开始左右张望;推动右摇杆,角色抬头望向天空中的飞龙;同时扳动两个摇杆,角色做出…...

GLM API配置管理工具glm-switch:告别手动切换,提升AI开发效率
1. 项目概述:一个为AI开发者设计的GLM API配置管理工具如果你和我一样,日常开发中需要频繁地在多个GLM(通用语言模型)API之间切换——比如在测试ChatGLM、Kimi、Minimax或者调试Claude Code的不同配置时——那你肯定对反复手动修改…...

避开BUUCTF《Life on Mars》的思维陷阱:当information_schema查询结果‘不对劲’时,你的排查清单应该有哪些?
破解BUUCTF《Life on Mars》的数据库迷局:当information_schema说谎时的七种侦查策略 在CTF赛场上,SQL注入类题目往往不会按教科书上的剧本发展。当你在BUUCTF《Life on Mars》这道题中执行group_concat(database()) from information_schema.schemata却…...
)
Arduino Uno R3 bootloader烧写避坑全记录:从USBasp驱动安装到熔丝位设置(Win10/11实测)
Arduino Uno R3 bootloader烧写实战指南:从驱动配置到熔丝位安全操作 当一块全新的Atmega328P芯片静静躺在工作台上时,它就像一张白纸,等待着被赋予生命。作为硬件开发者,我们常常需要为这些空白芯片注入灵魂——烧写bootloader。…...

Gemini自动生成PPT实战手册:从零输入到专业演示文稿,3步完成95%的幻灯片工作流
更多请点击: https://intelliparadigm.com 第一章:Gemini自动生成PPT的核心原理与能力边界 Gemini 生成 PPT 的本质并非传统模板填充,而是基于多模态理解与结构化内容重构的端到端推理过程。其核心依赖于对用户输入(文本、大纲、…...

除了综合,DC Shell还能这么用:快速搭建一个轻量级RTL/Netlist查看与调试环境
DC Shell的隐藏技能:打造高效RTL/Netlist交互式调试环境 在数字芯片设计流程中,工程师们经常需要快速查看和分析RTL或网表文件。传统方法要么启动完整的综合流程耗时费力,要么依赖第三方工具可能面临兼容性问题。实际上,Synopsys …...

通过AxisApi中转站使用国外API大模型教程
前言:所有的国外大模型想不通过中转站直接使用,其实是很麻烦的的事情,就拿codex来说,需要一个谷歌账号,没有谷歌账号需要注册,注册还必须要使用国外的手机号码和验证码校验审核,流程很繁琐&…...

测水位·报雨情·预洪水:水文监测站
水文监测站采用先进平面阵列雷达微波探测技术,设备悬空架设、非接触式采集河道水体数据。通过高精度雷达天线持续发射微波信号,穿透空气介质触达水面后反射回波,系统精准测算信号传播时长与多普勒频移变化,结合设备自带角度校准功…...