大模型上下文长度的超强扩展:从LongLora到LongQLora
前言
本文一开始是《七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora Llama》中4.3节的内容,但考虑到
- 一方面,LongLora的实用性较高
- 二方面,为了把LongLora和LongQLora更好的写清楚,而不至于受篇幅之限制
- 三方面,独立成文可以有更好的排版,而更好的排版可以有更高的可读性(哪怕一个小小的换行都能提高可读性,更何况独立成文带来的可读性的提高)
故把这部分的内容抽取出来独立成本文
第一部分 LongLora
具体而言,LongLora是港中文和MIT的研究者通过此篇论文《LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models》于23年9月底提出的(这是其GitHub),其显著特点有三
- longlora的作者团队认为:尽管在推理过程中需要密集的全局注意力,但通过稀疏局部注意力(sparse local attention)也可以高效地完成模型的微调,比如他们提出的移位稀疏注意力(shifted sparse attention,简称S2-Attn)可有效地实现上下文扩展且显著节省计算资源,具有与使用vanilla注意力(vanilla attention)进行微调相似的性能
简言之,用sparse local attention替换掉dense global attention,类似检索,不需要把所有的东西都拿过来,把相似度高的,匹配度高的一部分context拿来就可以了 - 他们发现,LoRA加到embedding matrix以及normalization的子网络上的时候,效果更好
啥意思?这点在于常规操作是lora一般加到query, key, value等部分上,而这里是加到embedding matrix上,以及normaliztion上了 - LongLoRA在保留原始架构的同时扩展了模型的上下文,并且与大多数现有技术(如Flash-Attention2)兼容
此外,还进一步发布了使用LongLoRA技术的长指令遵循数据集LongAlpaca,以进行监督微调(we further conduct supervised fine-tuning with LongLoRA and our long instruction-following LongAlpaca dataset)
1.1 LoRA在长文本上的不足
通过本博客内的多篇文章可知,原始transformer的计算复杂度虽序列长度的二次方成正比,这一点一直导致模型的长下文长度不好扩展(比如把长度从2048扩展到8192,复杂度得上升4x4 = 16倍),对于该问题 很多研究者或团队做了各种改进与探索
- 比如Flash-Attention、Flash-Attention2(详见此文《通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一》)
- 再比如Position Interpolation (详见此文《大模型上下文扩展之YaRN解析:从直接外推ALiBi、位置插值、NTK-aware插值、YaRN》的2.3节) spent 32 A100 GPUs to extend LLaMA models from 2k to 8k context,当然了,这种资源开销即便是七月项目团队也不一定舍得耗(其实,我司项目团队一直在“低成本 高效果”的方向上探索,过程中积攒了这方面的很多经验),更别说一般个人了
如何降低资源开销呢?一种直接的方法是通过LoRA对预训练的LLM进行微调
- 对于预训练的权重矩阵W∈Rd×k,它通过低秩分解W +∆W = W + BA进行更新,其中B∈Rd×r和A∈Rr×k。秩r≪min(d, k),在训练过程中,W被冻结,没有梯度更新,而A和B是可训练的(关于LoRA的更多说明,详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第4部分)
For a pre-trained weight matrix W ∈ R d×k , it is updated with a low-rank decomposition W + ∆W = W + BA, where B ∈ R d×r and A ∈ R r×k .
The rank r ≪ min(d, k). During training, W is frozen with no gradient updates, while A and B are trainable. This is the reason why LoRA training is much more efficient than full fine-tuning.
- 在Transformer结构中,LoRA只关注权重(Wq、Wk、Wv、Wo),而冻结所有其他层,包括MLP层和归一化层
In the Transformer structure, LoRA only adapts the attention weights (Wq, Wk, Wv, Wo) and freezes all other layers, including MLP and normalization layers
LoRA利用低秩矩阵对自注意块中的线性投影层进行修改,从而减少了可训练参数的数量(LoRA modifies the linear projection layers in self-attention blocks by utilizing low-rank matrices, which are generally efficient and reduce the number of trainable parameters)
- 然而,单纯的低秩自适应会导致长上下文扩展的困惑度(perplexityin,简称PPL)很高,如下表所示,且即便将秩增加到一个更高的值,例如rank = 256,也并不能缓解这个问题
那咋办呢?让embedding层和Norm层也添加LoRA训练之后,困惑度PPL可以显著降低
- 在效率方面,无论是否采用LoRA,计算成本都会随着上下文规模的扩大而急剧增加,这主要是由于标准的自注意机制所导致的(Vaswani et al., 2017)。如下图所示,即便使用LoRA,当上下文窗口扩展时,Llama2模型的训练时间也会大大增加
为此,他们提出shifted sparse attention(S2-Attn)以替代标准自注意力机制
1.2 shifted sparse attention(S2-Attn)
1.2.1 S2-Attn的原理解释
如下图所示

- 将上下文长度分成几个组,并在每个组中单独计算注意力。在半注意力头中,将token按半组大小进行移位,这保证了相邻组之间的信息流动(In half attention heads, we shift the tokens by half group size, which ensures the information flow between neighboring groups)
- 例如,使用组大小为2048的S2-Attn来近似总共8192个上下文长度训练,这与Swin Transformer具有高度的相似(详见此文《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》的第五部分)
上面的描述还是不够形象具体,那到底怎么理解这个S2-Attn呢?如下图所示(值得一提的是,这个图是论文v2版的,和论文v1版稍有细微差别,当然 不影响本质)

- 首先,它将沿头部维度的特征分成两大块(即it splits features along the head dimension into two chunks,比如8行4列,8行相当于8个token,4列可以认为是有4个头,然后竖着一切为二)
相当于[L, H, D], L=token num=8, H=head num=4, D=dimension of expression=1(可暂且认为是1了,毕竟一个方块,算是长度为1的一个向量)
执行完操作之后是:[L, H, D] -> [L, H/2, D] and [L, H/2, D],即被竖着切成了左右两个part - 其次,其中一个块中的标记被移动组大小的一半(tokens in one of the chunks are shifted by half of the group size)
如上图step 2的shift所示,shift thepart by half group,相当于
第2个part的第8个token的后一半表示(也即原始inputs第8个token的后两个heads)移动到第2个part的第1行
- 第三,将token分组并重塑为批量维度,注意力只在每个组内计算,信息通过移位在不同组之间流动。虽然移位可能会引入潜在的信息泄漏,但这可以通过对注意力掩码进行微调来避免
Third, we split tokens into groups and reshape them into batch dimensions. Attention only computes in each group in ours while the information flows between groups via shifting. Potential information leakage might be introduced by shifting, while this is easy to prevent via a small modification on the attention mask.
相当于把两个part连起来后,然后横着切三刀切成了4个group,每个group有8个小方块
第一个group相当于包含:第一part的前两行,和第二part中更新之后的前两行
然后计算该group内的注意力,类似于做了“cross-over”,正因为只是计算group内部的几个tokens之间的attention,所以称之为short attention
为方便大家更快的理解,特再补充两点
- 为形象起见,举个例子,假定这8个单词是i am learning Machine Learning by julyedu online,然后上述过程可用下表表示
i 前一半(表示) i 后一半(表示) i 前一半 online 后一半:line am 前一半 am 后一半 am 前一半 i 后一半 learning 前一半 learning 后一半 learning 前一半 am 后一半 Machine 前一半 Machine 后一半 Machine 前一半 learning 后一半 Learning 前一半 Learning 后一半 Learning 前一半 Machine 后一半 by 前一半 by 后一半 by 前一半 Learning 后一半 julyedu 前一半 julyedu 后一半 julyedu 前一半 by 后一半 online 前一半 online 后一半 online 前一半:on julyedu 后一半 - 针对上面那个S2-Attn示意图
该图的左边部分 上文已经解释的很清楚了,那右侧的两个图呢?
咋一看,比较抽象,其实仔细琢磨之后,右侧的两个图描述的注意力范围,pattern2相对于pattern1的注意力窗口是“移位”了的具体到某个token来观察会清楚一点,除了“pattern1中q1”和“pattern2中q1”的注意力范围是一致 都是k1之外
pattern1中q2的注意力范围是[k1,k2],pattern2中q2的注意力范围变成了仅[k2];
pattern1中q3的注意力范围仅是[k3],pattern2中q3的注意力范围变成了[k2,k3];
pattern1中q4的注意力范围是[k3,k4],pattern2中q4的注意力范围变成了仅[k4];
pattern1中q5的注意力范围是仅[k5],pattern2中q5的注意力范围变成了[k4,k5];
...
两个pattern从最开始的token注意力范围就是错位的,所以后续token注意力范围就一直是错开的,这样错开的形式使得两个pattern聚合起来就可以让组外信息有机会产生交互
1.2.2 S2-Attn的伪代码表示
如下图所示

- 第一步,B=batch size, N=sequence length, 3=q,k,v,H=head num,D=每个head的表示维度
例如:qkv=[1, 4, 3, 4, 1]
即batch size=1,一共一个序列;4=4个tokens,3=q,k,v,4=head num,1=dim of a head1 head2 head3 head4 head1 head2 head3 4 2 1 3 2 4 3 - qkv.chunk(2, 3),得到的是一个tuple,包括两个张量,[1, 4, 3, 2, 1]左边的part,以及[1, 4, 3, 2, 1]是右边的part
qkv.chunk(2, 3)[0],即左边的包括两个heads的part
qkv.chunk(2,3)[1], 即右边的包括两个heads的part,这里是对其shift 1个token了 - 接下来,按照group分别计算group内的tokens的注意力
- 最后,复原
1.2.3 LongAlpaca-13B
在llama 13B上应用longlora技术,便是LongAlpaca-13B

第二部分 LongQLora
// 待更
相关文章:
大模型上下文长度的超强扩展:从LongLora到LongQLora
前言 本文一开始是《七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora Llama》中4.3节的内容,但考虑到 一方面,LongLora的实用性较高二方面,为了把LongLora和LongQLora更好的写清楚,而不至于受篇幅…...

pdf格式转换为txt格式
pdf文档转换为txt文档 首先在python3虚拟环境中安装PyPDF2 Python 3.6.8 (default, Jun 20 2023, 11:53:23) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux Type "help", "copyright", "credits" or "license" for more infor…...

scss使用for循环遍历,动态赋值类名并配置不同颜色
需求:后端要传入不同的等级,前端通过等级展示不同的字体颜色,通过scss遍历更有利于动态修改颜色或者增删等级 1.通过 for $i from 1 through 4 定义循环,索引值为i 2.nth($colors, $i) 取出对应的颜色 $colors: #ff0000, #00ff…...

GaussDB数据库使用COPY命令导数
目录 一、前言 二、GaussDB数据库使用COPY命令导数语法 1、语法COPY FROM 2、语法COPY TO 3、特别说明及参数示意 三、GaussDB数据库使用COPY命令导数示例 1、操作步骤 2、准备工作(示例) 3、把一个表的数据拷贝到一个文件(示例&…...

SunFMEA软件免费试用:FMEA的目标和限制是什么?
免费试用FMEA软件-免费版-SunFMEA FMEA,即故障模式与影响分析,是一种预防性的质量工具,旨在识别、评估和优先处理潜在的故障模式及其对系统性能的影响。其目标是提高产品和过程的可靠性和安全性,降低产品故障的风险,并…...
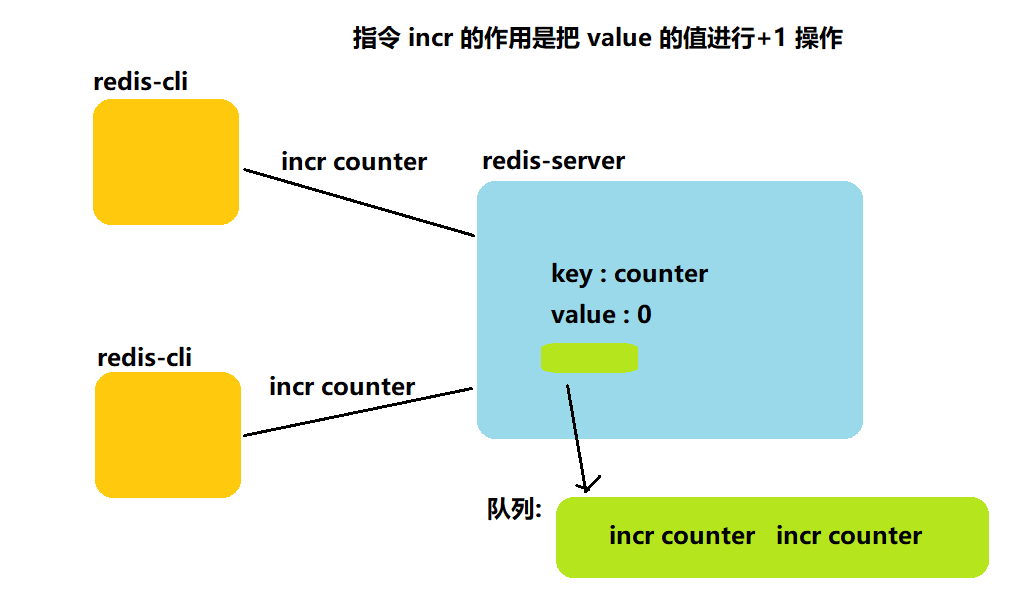
【Redis交响乐】Redis中的数据类型/内部编码/单线程模型
文章目录 一. Redis中的数据类型和内部编码二. Redis的单线程模型面试题: redis是单线程模型,为什么效率之高,速度之快呢? 在上一篇博客中我们讲述了Redis中的通用命令,本篇博客中我们将围绕每个数据结构来介绍相关命令. 一. Redis中的数据类型和内部编码 type命令实际返回的…...

APK 瘦身
APK 瘦身的主要原因是考虑应用的下载转化率和留存率,应用太大了,用户可能就不下载了。再者,因为手机空间问题,用户有可能会卸载一些占用空间比较大的应用,所以,应用的大小也会影响留存率。 1 APK 的结构 …...

GitHub上的15000个Go模块存储库易受劫持攻击
内容概要: 目前研究发现,GitHub上超过15000个Go模块存储库容易受到一种名为“重新劫持”的攻击。 由于GitHub用户名的更改会造成9000多个存储库容易被重新劫持,同时因为帐户删除,会对6000多个存储库造成重新劫持的危机。目前统计…...

避免3ds Max效果图渲染一片黑的4个正确解决方法
在进行3ds Max效果图渲染时,有时候会遇到渲染一片黑的情况,这给我们的工作带来了很大的困扰。为了解决这个问题,下面我将介绍4个正确的解决方法。 1.相机位置 首先需要考虑场景内的相机位置是否有问题。如果相机放在了模型的内部或者墙体的外…...

UI演示双视图立体匹配与重建
相关文章: PyQt5和Qt designer的详细安装教程:https://blog.csdn.net/qq_43811536/article/details/135185233?spm1001.2014.3001.5501Qt designer界面和所有组件功能的详细介绍:https://blog.csdn.net/qq_43811536/article/details/1351868…...
添加一个编辑的小功能(PHP的Laravel)
一个编辑的按钮可以弹出会话框修改断更天数 前台 加一个编辑按钮的样式,他的名字是固定好的 之前有人封装过直接用就好,但是一定放在class里面,不要放在id里面 看见不认识的方法一定要去看里面封装的是什么 之前就是没有看,所以…...

YOLOv8改进 | 主干篇 | ConvNeXtV2全卷积掩码自编码器网络
一、本文介绍 本文给大家带来的改进机制是ConvNeXtV2网络,ConvNeXt V2是一种新型的卷积神经网络架构,它融合了自监督学习技术和架构改进,特别是加入了全卷积掩码自编码器框架和全局响应归一化(GRN)层。我将其替换YOLOv8的特征提取网络,用于提取更有用的特征。经过我的实…...

elasticsearch7.17.9两节点集群改为单节点
需求 将数据从node-23-1节点中迁移到node-83-1节点。但是现在node-83-1并没有加入到集群中,因此首先将node-83-1加入到node-23-1的集群 解决方案 使用ES版本为7.17.9,最开始设置集群为一个节点,node-23-1的配置如下 cluster.name: my-app…...
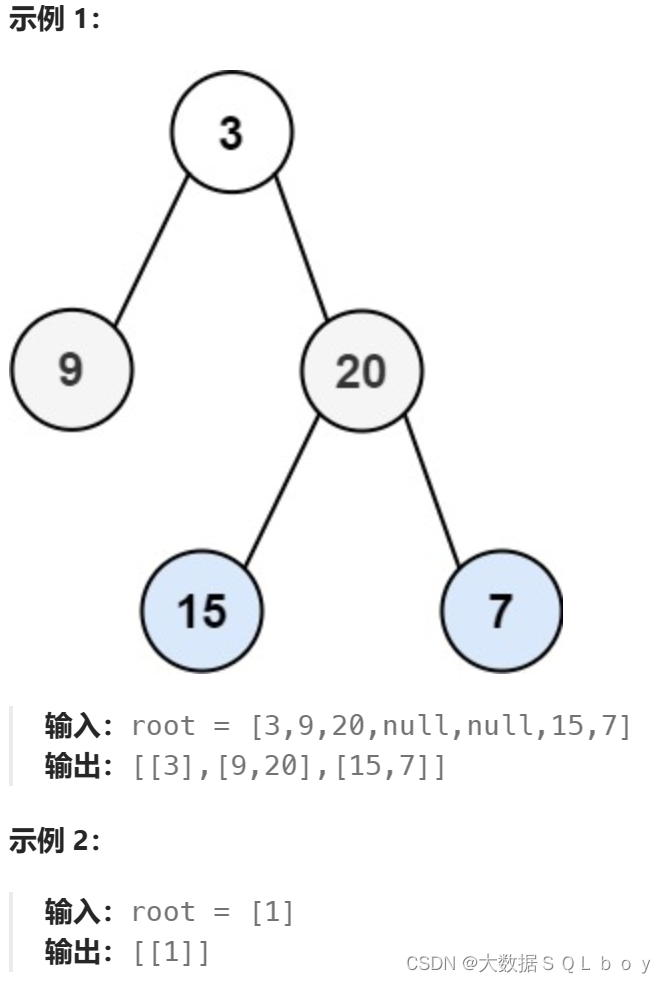
二叉树的层序遍历,力扣
目录 题目地址: 题目: 我们直接看题解吧: 解题方法: 方法分析: 解题分析: 解题思路: 代码实现: 代码补充说明: 题目地址: 102. 二叉树的层序遍历 - 力扣&…...

构建Dockerfile报错/bin/sh: 1: cd: can‘t cd to /xxx/yyy问题记录
目录 关键的命令行 排查分析 原因 附:Dockerfile构建时打印命令输出的办法 关键的命令行 WORKDIR /app COPY record . RUN cd record && xxx 执行到RUN时报了错: /bin/sh: 1: cd: cant cd to /app/record 并且宿主机当前目录也准备好了re…...

Vue常用的修饰符详解(有哪些,怎么用)
文章目录 一、修饰符是什么二、修饰符的作用1.表单修饰符lazytrimnumber 2.事件修饰符stoppreventselfoncecapturepassivenative 3.鼠标按钮修饰符4.键盘修饰符5.v-bind修饰符asyncpropscamel 三、应用场景参考文献 一、修饰符是什么 在程序世界里,修饰符是用于限定…...

Linux C/C++ 获取CPUID
实现方式: INTEL CC 格式 AT^T CC 格式 GCC/C库 __cpuid 宏 大致讲义: AT^T 格式汇编很反人类,GCC可以改编译器选项为INTEL内嵌汇编,但一般在GCC还是按照默认的AT^T汇编来拽写把,不想用也可以让AI工具把INTEL内嵌…...
2023年“中银杯”安徽省网络安全B模块(部分解析)
前言 以下是2023年中银杯安徽省网络安全B模块题目,镜像可以私聊我 B模块安全事件响应/网络安全数据取证/应用安全(400 分) B-1:CMS网站渗透测试 任务环境说明: √服务器场景:Server2206(关…...
】单行道汽车通行时间(迭代计算—JavaPythonC++JS实现))
194.【2023年华为OD机试真题(C卷)】单行道汽车通行时间(迭代计算—JavaPythonC++JS实现)
请到本专栏顶置查阅最新的华为OD机试宝典 点击跳转到本专栏-算法之翼:华为OD机试 🚀你的旅程将在这里启航!本专栏所有题目均包含优质解题思路,高质量解题代码,详细代码讲解,助你深入学习,深度掌握! 文章目录 【2023年华为OD机试真题(C卷)】单行道汽车通行时间(…...
第二证券机构策略:股指预计维持蓄势震荡格局 关注煤炭、电力等板块
第二证券以为,技能面看,在元旦节前资金抄底推进指数收回2900整数关口,并向着3000点渠道压力前进。沪指在底部均线位支撑摆放较强,调整空间估计不大,在3000点渠道下方调整就是再次优化低吸的时机。操作上,在…...

GitHub Explorer:基于OpenClaw的AI Agent自动化项目分析工具
1. 项目概述:一个为AI Agent打造的GitHub项目深度分析工具 如果你和我一样,经常需要快速评估一个GitHub项目的价值、技术栈、社区活跃度以及它在整个生态中的位置,那你一定知道这个过程有多繁琐。你得手动点开仓库,看README&…...

IGH-1.6.2-创龙RK3506-RT-----8-----my_master.c讲解【应用层PDO读写】
本文解决三个应用层问题: 第一,如何从 TxPDO 里读取 3 个 KEY。 第二,如何向 RxPDO 写入 5 个 LED。 第三,如何新增一个 UINT8 数据 PDO。 当前工程里的过程数据指针是 domain_pd,它是应用层读写 PDO 的基础。LED 和 KEY 的字节偏移、bit 位置,都是前面注册 PDO entry …...

superpowers skill 3.1: using-git-worktrees
智能体工作流 安装 $ npx skills add https://github.com/obra/superpowers --skill using-git-worktrees摘要 具有智能目录选择和安全验证的隔离 Git 工作树。 通过检查现有目录、CLAUDE.md 偏好设置或询问用户来自动检测工作树目录位置;支持项目本地ÿ…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...

AI Agent 的难点,不在搭 Demo,而在让人敢交任务
Agent难在让人敢托付 很多团队做 Agent 的误会,是把跑通一次当成好用。 现在搭一个 Demo 确实不难。一个大模型,几段提示词,接几个搜索、表格、浏览器或数据库工具,很快就能演示一个会拆任务、会调用工具、会输出结果的流程。看起…...

别再只用BigGantt了!这个免费JIRA甘特图插件Gantt Suite,配置简单速度快
轻量高效的JIRA甘特图解决方案:Gantt Suite全面评测与迁移指南 在项目管理领域,甘特图作为可视化排期的黄金标准已有百年历史。然而当这一经典工具遇上现代敏捷开发平台JIRA时,许多团队却陷入了两难境地——要么忍受BigGantt等老牌插件的臃肿…...

WindowResizer:轻松掌控Windows窗口的终极解决方案
WindowResizer:轻松掌控Windows窗口的终极解决方案 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为Windows应用程序窗口尺寸无法调整而烦恼吗?Window…...

淘宝商品详情 API 实现标题 / SKU / 主图批量采集
item_get_pro-获得淘宝商品详情高级版请求示例-- 请求示例 url 默认请求参数已经URL编码处理 curl -i "https://api-服务器.cn/taobao/item_get_pro/?key<您自己的apiKey>&secret<您自己的apiSecret>&num_iid678121631641"响应示例"num_ii…...

法律AI助手weclaw:基于RAG与领域大模型的智能法律应用实践
1. 项目概述:一个面向法律领域的智能助手 最近在关注一些开源项目,发现了一个挺有意思的,叫 shp-ai/weclaw 。光看这个名字,就能猜个八九不离十——“weclaw”,听起来像是“we”和“law”的结合,指向性非…...

ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略
ComfyUI ControlNet Aux预处理器深度解析:从模型下载到性能优化全攻略 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux…...