谷歌推出创新SynCLR技术:借助AI生成的数据实现高效图像建模,开启自我训练新纪元!
谷歌推出了一种创新性的合成图像框架,这一框架独特之处在于它完全不依赖真实数据。这个框架首先从合成的图像标题开始,然后基于这些标题生成相应的图像。接下来,通过对比学习的技术进行深度学习,从而训练出能够精准识别和理解这些图像的模型,令人惊讶的是,这种方法在各种下游任务中都表现出色。让我们一起来看看使用了什么神奇的魔法!
论文标题: Learning Vision from Models Rivals Learning Vision from Data
论文链接:
https://arxiv.org/pdf/2312.17742.pdf
引言
集大规模的真实数据往往伴随着许多挑战:未经筛选的庞大数据集虽然成本较低,但其效益却是有限的;而精细筛选的小规模数据集虽然更为精确,但却限制了模型的广泛应用。为了克服这些障碍,一项新的研究提出了一种独特的解决方案——利用合成数据来学习视觉表示。这种方法通过生成大量的图像标题和相应的图像,实现了有效的对比学习,能够将共享同一标题的图像视为相互匹配的正例。研究团队特别强调,这种基于合成数据的学习方法不仅展现了卓越的可扩展性,而且在多种下游任务中展现了与传统方法相媲美的卓越性能。

传统学习方法("Learning from data")侧重于纯粹从真实数据中汲取知识。一个典型的例子是CLIP模型,它直接从文本和图像数据集中提取信息,在ImageNet上实现了令人瞩目的80.2%的线性转移精度。
混合学习方法("Hybrid")则采用了一种双管齐下的策略,结合真实文本和生成图像进行学习。例如,StableRep模型就是在这样的框架下运作,它利用文本数据集和图像生成器进行学习,在ImageNet上也取得了相当不错的76.7%的线性转移精度。
而本文提出的基于模型生成的方法("Learning from models")——SynCLR,标志着一次创新的飞跃。它通过从合成文本和合成图像中学习,即便没有直接接触任何真实数据,也能在ImageNet上展现出与CLIP相匹敌的竞争力,达到了非常优秀的80.7%的线性转移精度。
方法
SynCLR的核心创新在于它通过生成模型重新界定了视觉类别的细粒度。与传统的自监督和监督学习方法相比,SynCLR独特地以标题作为类别定义,其中每个标题都细致地描述了一个视觉类别。这一方法的巧妙之处在于它允许按照标题所共享的语义将图像分组,而非仅限于更为宽泛的类别标签,如“金毛寻回犬”等。在实验中,这种以标题为基础的精细分类方式证明了其优于传统自监督和监督训练方法的效果。该系统包括以下三个步骤:
生成图像标题
首先,作者们成功地生成了一个庞大的图像标题语料库。为了实现这一目标,他们巧妙地利用了大型语言模型(LLMs)的上下文学习能力,精心设计了一系列的提示模板,以指导LLM根据特定上下文产生相关联的文本内容。
通过从现有数据集(如ImageNet-21k和Places-365)中精选概念列表,作者们为每个概念构建了特别的提示,引导LLM生成描述性且富有创意的图像标题。这一过程的核心在于确保生成的标题既准确描述图像内容,又展现足够的多样性,以覆盖广泛的视觉概念。这种多样性至关重要,因为它保证了生成的图像集可以代表尽可能多样的场景、对象和活动,进而提高学习到的视觉表示的泛化能力。

通过这种方式,作者们合成了大量多样化的图像标题,这些标题随后用于指导图像生成模型生成相应的合成图像。将这些合成图像与合成标题结合起来,形成了一个用于训练视觉表示学习模型的丰富数据集。这种方法使得在完全没有真实图像数据的情况下进行视觉模型训练成为可能,为传统依赖真实数据集的视觉学习方法提供了一种创新且有效的补充。

在下图中,研究团队提供了一个上下文(左侧),用于指导模型根据给定的类别对(例如“tiger, forest”或“groom, wedding ceremony”)生成具体的描述性标题。例如,在实际生成的结果中(右侧),对于“red fox, yard”这一类别对,模型生成了以下标题:“wild red fox sitting on a partially snow covered front yard of a house in the suburbs of a small city”。在这个过程中,每次推理都会随机选择三个这样的上下文实例。
图像生成
研究团队采用了一种创新的方法来生成图像,即通过不同的随机噪声启动反向扩散过程。在这个过程中,Classifier-Free Guidance(CFG)比例扮演着至关重要的角色,它有效地平衡了样本质量、文本与图像之间的一致性,以及样本多样性之间的关系。为了为每个文本描述生成一系列不同的图像,团队调整了随机噪声输入,从而丰富了生成图像的多样性。
表示学习方法
这一表示学习方法是在StableRep方法的基础上构建的,引入了一种多正面对比学习损失。其核心思想是在嵌入空间中将由相同标题生成的图像对齐,同时融合了其他自监督学习方法中的多种技术,包括补丁级掩蔽图像建模目标。
StableRep
StableRep方法通过比较不同样本之间的相似性和差异性,最小化交叉熵损失。这一策略训练模型识别和区分由相同或不同标题生成的图像。
iBOT
iBOT方法采用掩蔽图像建模目标,其中局部补丁被掩盖,而模型的任务是预测这些被掩盖的补丁的标记表示。这一策略将DINO模型从图像级别调整到补丁级别。
指数移动平均(EMA)
EMA最初由MoCo在自监督学习中引入,用于编码作物并生成iBOT损失的目标。在训练期间,EMA模型按照余弦计划更新,以平滑模型参数的更新过程,从而使模型在训练过程中保持稳定性。
多作物策略
多作物策略作为一种提高计算效率的方法,允许模型从多个视角和上下文中学习,增加了训练样本的多样性并提升了表示的泛化能力。具体而言,StableRep通过最小化真实分配和对比分配之间的交叉熵损失来提高效率。在这个框架中,存在一个编码的锚点样本和一组编码的候选样本集合。对比分配分布描述了模型预测锚点样本和每个候选样本是否由相同标题生成的概率。他们使用指示函数来标识两个样本是否来自同一个标题。
实验
研究团队对其模型进行了长达500k步骤的预训练,采用8192个标题的大批量尺寸,所有预训练任务均在224x224分辨率下进行。他们将SynCLR与OpenAI的CLIP、OpenCLIP以及DINO v2进行了对比,这些模型分别代表了不同的从数据中学习的方法。特别指出的是,DINO v2中的ViT-B/14和ViT-L/14是由ViT-g模型蒸馏得来,这一点在比较时为DINO v2带来了优势。
ImageNet线性评估
为了进行公平的比较,所有模型均使用最后一个块的cls令牌作为表示(与DINO v2使用多层串联的结果相比)。据表6所示,SynCLR在ViT-B结构上达到了80.7%的成绩,在ViT-L结构上则达到了83.0%。这些成绩与那些直接从真实数据中学习的模型(如CLIP和DINO v2)相当,尽管SynCLR仅使用了合成数据。

UperNet语义分割
研究团队在UperNet语义分割中采用了单一尺度512x512分辨率,部分模型为适应518x518分辨率而使用了14x14的补丁尺寸。他们使用了600M的合成数据,与包括MoCo v3、SimMIM、MAE、PeCo、data2vec、iBOT、BEiT v2、CLIP和OpenCLIP在内的其他模型进行了对比,这些模型主要是基于真实的ImageNet数据预训练的。SynCLR在mIoU指标上分别在标准分辨率和高分辨率下达到了54.3%和57.7%,与使用真实数据训练的模型相比,表现十分出色。

ImageNet图像分类
SynCLR在ImageNet图像分类方面的表现也值得关注。使用600M合成数据,SynCLR与采用不同数据集,如IN21K、WIT-400M和LAION-2B预训练的各种模型进行了比较。在ViT-B结构上,SynCLR的Top-1准确率为85.8%,而在ViT-L结构上则为87.9%,均优于多数使用真实数据训练的模型。

这些结果明确表明,尽管完全依赖合成数据,SynCLR方法在视觉表示学习领域仍能与依赖真实数据的模型媲美,展示了这一方法的显著有效性和巨大潜力。
小结
作者们提出了以下关键观点和结论:
从生成模型中学习的理由:生成模型的一个显著优势在于其能够同时扮演成百上千个数据集的角色。在传统的研究方法中,研究者往往需要为不同的图像类别(比如汽车、花朵、猫、狗等)单独收集数据集。而像DINO v2这样的系统通过综合和整合大量这类数据集,能够构建出强大且鲁棒的表征。
生成模型的显著优势:与传统的数据收集和标注方法相比,生成模型提供了一个更加高效、范围更广的视觉概念覆盖方式。这一方法免去了在真实图像数据收集和标注上耗费的大量时间和资源。
论文强调了合成数据在视觉表示学习中的关键作用。尽管在分类精度方面,合成数据可能不及真实数据,但在训练视觉表示模型方面,合成数据展现出了极高的效果。这些训练好的表示随后可以轻松适应于真实数据量较小的下游任务,显示出合成数据的实用性和适应性。

相关文章:
谷歌推出创新SynCLR技术:借助AI生成的数据实现高效图像建模,开启自我训练新纪元!
谷歌推出了一种创新性的合成图像框架,这一框架独特之处在于它完全不依赖真实数据。这个框架首先从合成的图像标题开始,然后基于这些标题生成相应的图像。接下来,通过对比学习的技术进行深度学习,从而训练出能够精准识别和理解这些…...
Vue2中使用echarts,并从后端获取数据同步
一、安装echarts npm install echarts -S 二、导入echarts 在script中导入,比如: import * as echarts from "echarts"; 三、查找要用的示例 比如柱状图 四、初始化并挂载 <template><div id"total-orders-chart" s…...

【Redux】自己动手实现redux-thunk
1. 前言 在原始的redux里面,action必须是plain object,且必须是同步。而我们经常使用到定时器,网络请求等异步操作,而redux-thunk就是为了解决异步动作的问题而出现的。 2. redux-thunk中间件实现源码 function createThunkMidd…...
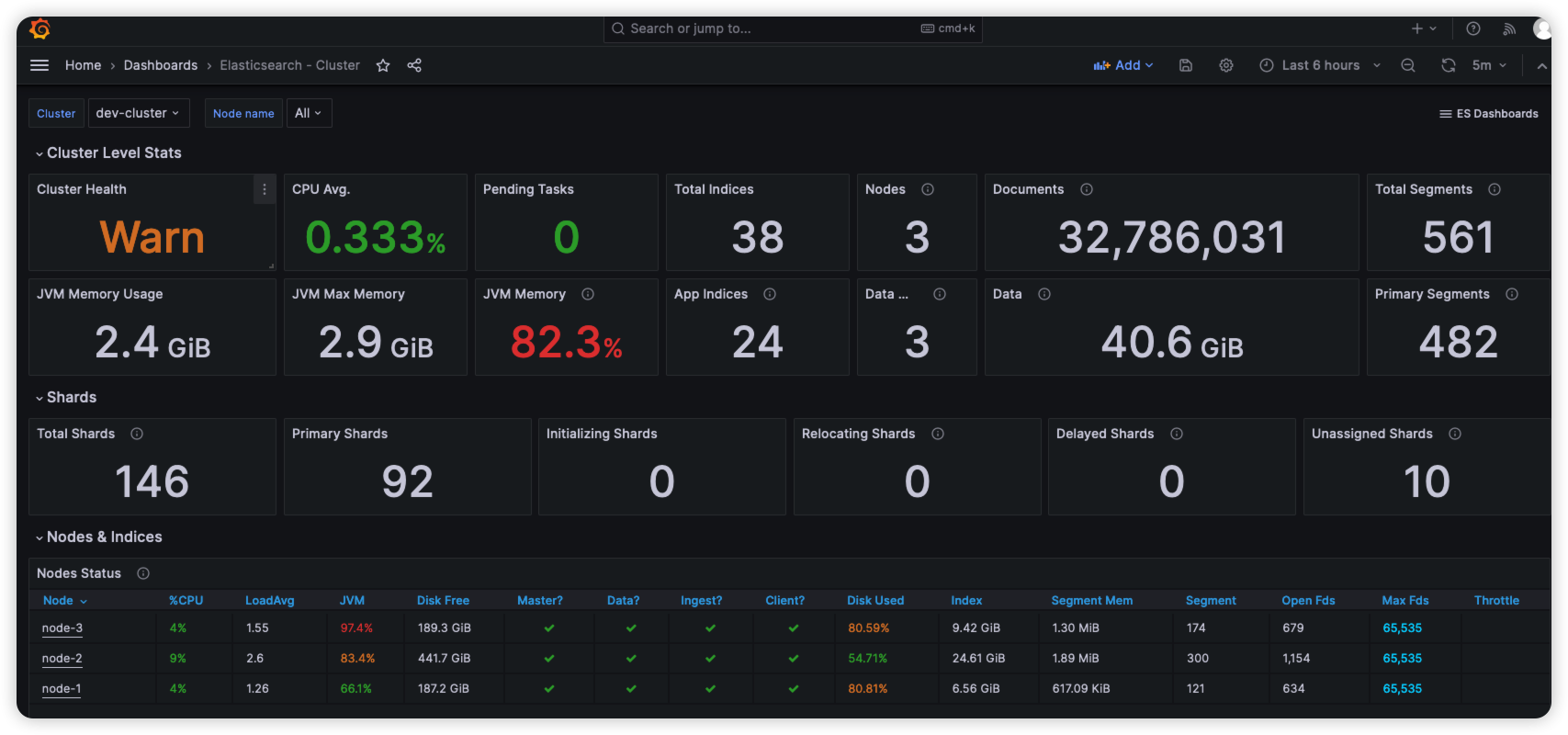
ElasticSearch使用Grafana监控服务状态-Docker版
文章目录 版本信息构建docker-compose.yml参数说明 创建Prometheus配置文件启动验证配置Grafana导入监控模板模板说明 参考资料 版本信息 ElasticSearch:7.14.2 elasticsearch_exporter:1.7.0(latest) 下载地址:http…...
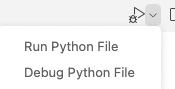
VS Code 如何调试Python文件
VS Code中有1,2,3处跟Run and Debug相关的按钮, 1 处:调试和运行就不多说了,Open Configurations就是打开workspace/.vscode下的lauch.json文件,而Add Configuration就是在lauch.json文件中添加当前运行Python文件的Configuratio…...
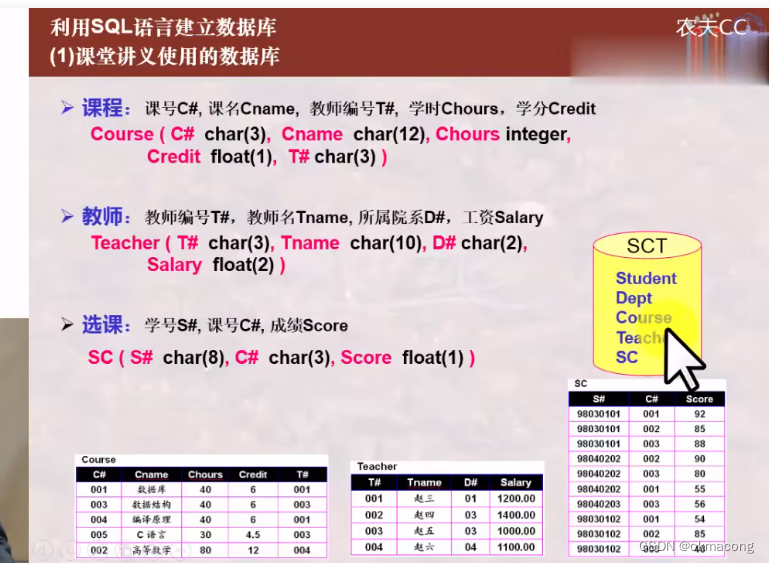
day06、SQL语言之概述
SQl 语言之概述 6.1 SQL语言概述6.2 SQL语言之DDL定义数据库6.3 SQL语言之DML操纵数据库 6.1 SQL语言概述 6.2 SQL语言之DDL定义数据库 6.3 SQL语言之DML操纵数据库...

3D目标检测(教程+代码)
随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。 一、3D目…...

让设备更聪明 |启英泰伦离线自然说,开启智能语音交互新体验!
语音交互按部署方式可以分为两种:离线语音交互和在线语音交互。 在线语音交互是将数据储存在云端,其具备足够大的存储空间和算力,可以实现海量的语音数据处理。 离线语音交互是以语音芯片为载体,语音数据的采集、计算、决策均在…...

React Hooks之useState、useRef
文章目录 React Hooks之useStateReact HooksuseStatedemo:在函数式组件中使用 useState Hook 管理计数器demo:ant-design-pro 中EditableProTable组件使用 useRef React Hooks之useState React Hooks 在 React 16.8 版本中引入了 Hooks,它是…...

提供电商Api接口-100种接口,淘宝,1688,抖音商品详情数据安全,稳定,支持高并发
Java是一种高级编程语言,由Sun Microsystems公司于1995年推出,现在属于Oracle公司开发和维护。Java以平台无关性、面向对象、安全性、可移植性和高性能著称,广泛用于桌面应用程序、嵌入式系统、企业级服务、Android移动应用程序等。 接口是Ja…...

git的使用 笔记1
GIT git的使用 使用git提交的两步 第一步:是使用 git add 把文件添加进去,实际上就是把文件添加到暂存区。第二步:使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。 .git 跟踪管理版本的目录 创建版本库…...

基于SpringBoot的医疗挂号管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot的医疗挂号管理系统,java…...
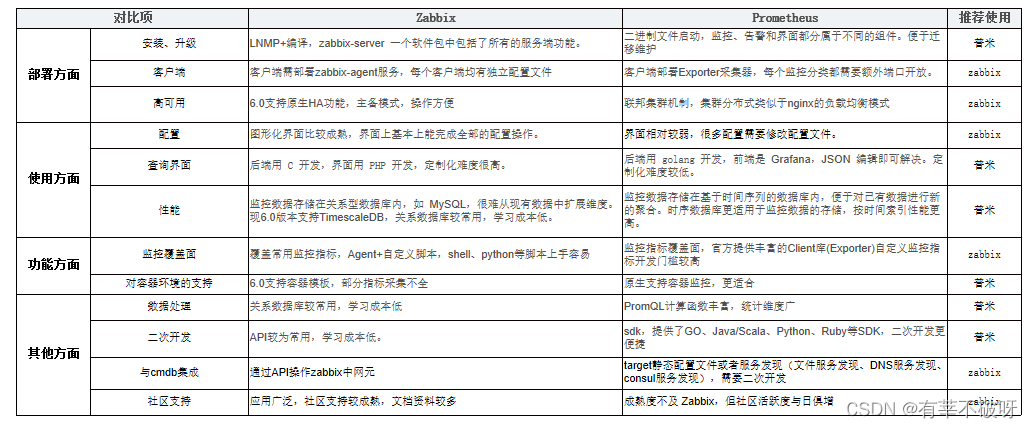
prometheus与zabbix监控的对比介绍
一、普米与zabbix基本介绍 1、prometheus介绍 Prometheus的基本原理是Prometheus Server通过HTTP周期性抓取被监控组件的监控数据,任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。 工作流程大致分为收集数…...
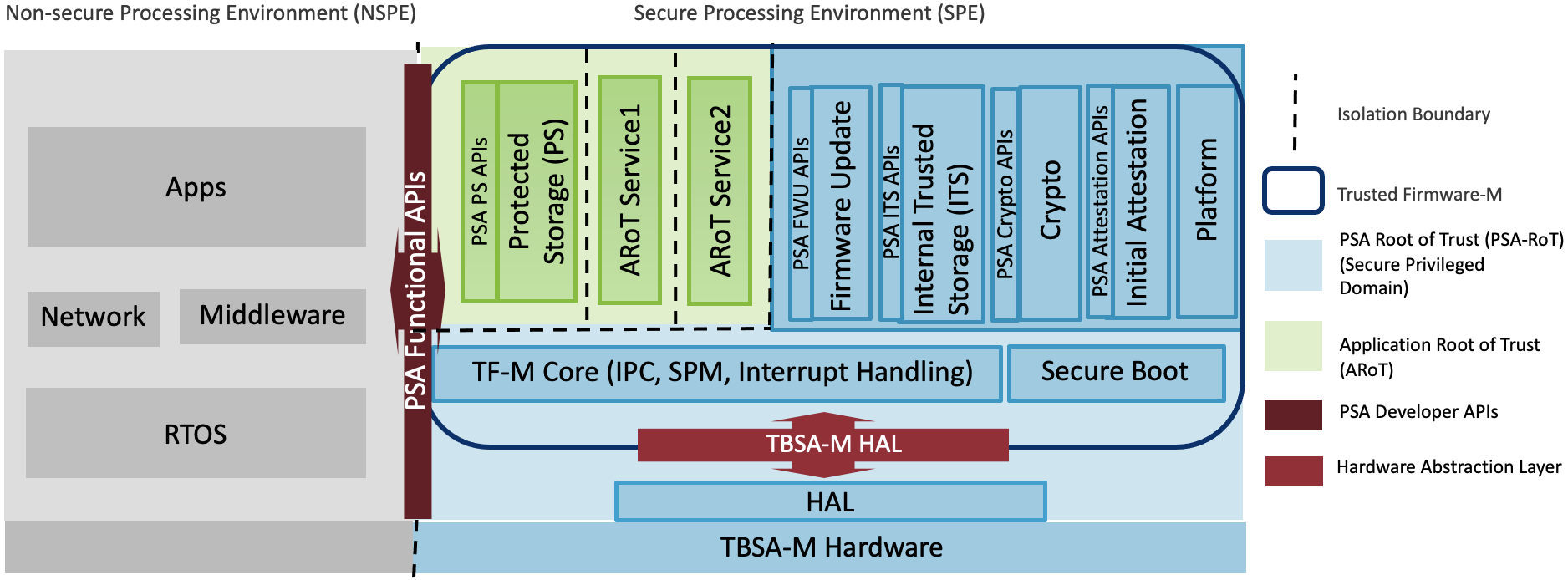
详解全志R128 RTOS安全方案功能
介绍 R128 下安全方案的功能。安全完整的方案基于标准方案扩展,覆盖硬件安全、硬件加解密引擎、安全启动、安全系统、安全存储等方面。 配置文件相关 本文涉及到一些配置文件,在此进行说明。 env*.cfg配置文件路径: board/<chip>/&…...

【MySQL】WITH AS 用法以及 ROW_NUMBER 函数 和 自增ID 的巧用
力扣题 1、题目地址 601. 体育馆的人流量 2、模拟表 表:Stadium Column NameTypeidintvisit_datedatepeopleint visit_date 是该表中具有唯一值的列。每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)每天只有…...
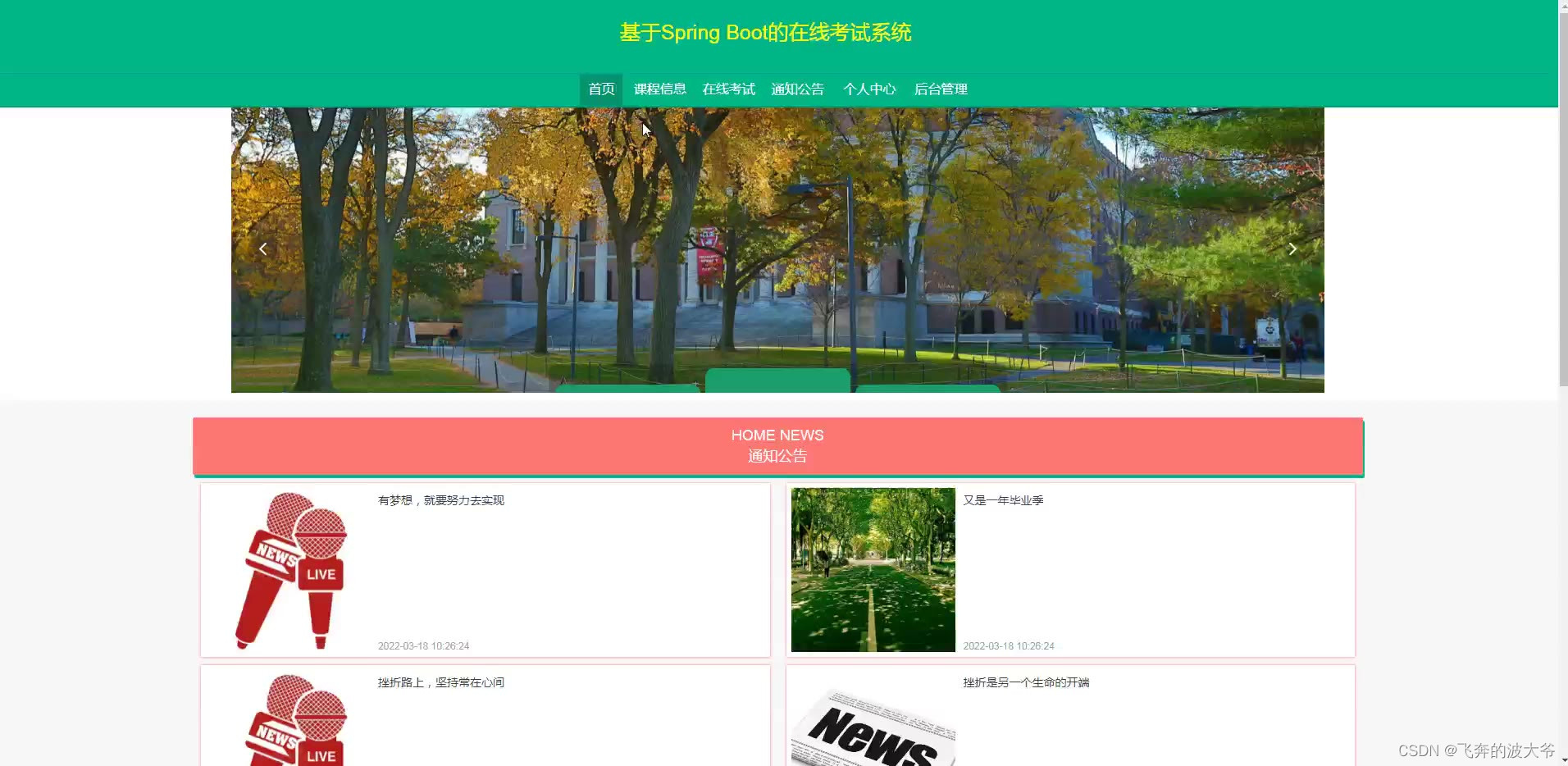
基于SpringBoot的在线考试系统源码和论文
网络的广泛应用给生活带来了十分的便利。所以把在线考试管理与现在网络相结合,利用java技术建设在线考试系统,实现在线考试的信息化管理。则对于进一步提高在线考试管理发展,丰富在线考试管理经验能起到不少的促进作用。 在线考试系统能够通…...

基于Spring Boot的美妆分享系统:打造个性化推荐、互动社区与智能决策
基于Spring Boot的美妆分享系统:打造个性化推荐、互动社区与智能决策 1. 项目介绍2. 管理员功能2.1 美妆管理2.2 页面管理2.3 链接管理2.4 评论管理2.5 用户管理2.6 公告管理 3. 用户功能3.1 登录注册3.2 分享商品3.3 问答3.4 我的分享3.5 我的收藏夹 4. 创新点4.1 …...
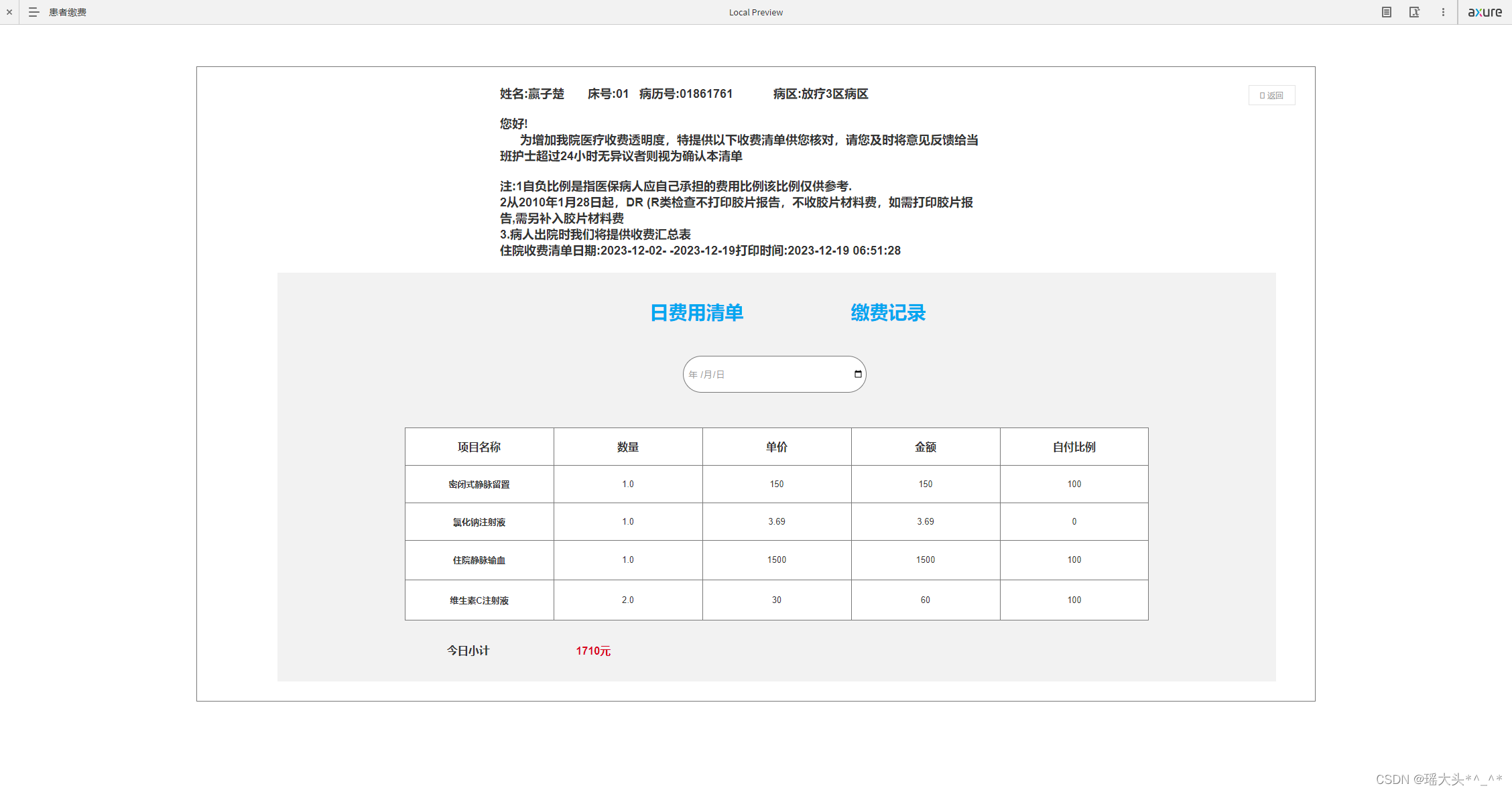
Axure医疗-住院板块,住院患者原型预览,新增医护人员原型预览,新增病房原型预览,选择床位原型预览,主治医生原型预览,主治医生医嘱原型预览
目录 一.医疗项目原型图-----住院板块 1.1 住院板块原型预览 1.2 新增住院患者原型预览 1.3 新增医护人员原型预览 1.4 新增病房原型预览 1.5 选择床位原型预览 1.6 主治医生原型预览 1.7 主治医生医嘱原型预览 1.8 主治医生查看患者报告原型预览 1.9 护士原型预…...

前端实战第一期:悬浮动画
悬浮动画 像这样的悬浮动画该怎么做,让我们按照以下步骤完成 步骤: 先把HTML内容做起来,用button属性创建一个按钮,按钮内写上悬浮效果 <button classbtn>悬浮动画</button>在style标签内设置样式,先设置盒子大小&…...

Python学习笔记(五)函数、异常处理
目录 函数 函数的参数与传递方式 异常处理 函数 函数是将代码封装起来,实现代码复用的目的 函数的命名规则——同变量命名规则: 不能中文、数字不能开头、不能使用空格、不能使用关键字 #最简单的定义函数 user_list[] def fun(): #定义一个函数&…...

C语言文件长度获取:fseek/ftell与stat方法详解与实战对比
1. 项目概述:为什么文件长度获取是基础却关键的操作在C语言开发中,处理文件是家常便饭。无论是读取配置文件、解析日志,还是处理二进制数据,我们经常需要知道一个文件到底有多大。这个看似简单的需求——“获取文件长度”——背后…...

树莓派AI智能体进化框架:轻量化部署与持续学习实践
1. 项目概述:一个面向树莓派的AI智能体进化框架 最近在折腾树莓派上的AI应用时,发现了一个挺有意思的项目: kingkillery/pk-pi-hermes-evolve 。光看这个名字,就能拆解出不少信息点:“pk-pi”显然指的是树莓派平台&…...
)
倍福官网改版后,如何用F12开发者工具找回消失的Twincat3老版本安装包(附4024.11下载链接)
倍福官网改版后如何找回消失的Twincat3老版本安装包 作为一名自动化工程师,你是否遇到过这样的困境:项目需要特定版本的Twincat3进行维护或兼容性测试,但倍福官网改版后,历史版本下载入口却神秘消失了?这种情况在工业软…...
)
【综合能源】电热冷综合能源优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Rust服务脚手架:快速构建生产级微服务的标准化起点
1. 项目概述:为什么我们需要一个Rust服务脚手架?在当今的微服务与云原生架构浪潮中,快速启动一个健壮、可维护的后端服务是每个开发团队的核心诉求。如果你和我一样,厌倦了每次开启新项目时,都要重复搭建项目结构、配置…...

aelf区块链浏览器开发实战:从核心技能到定制化构建
1. 项目概述:一个区块链浏览器背后的技能集如果你在区块链领域,特别是公链开发或生态应用构建中工作过,那么“区块链浏览器”对你来说一定不陌生。它就像是区块链世界的“搜索引擎地图”,让我们能直观地查看链上发生的每一笔交易、…...

人类不擅长做出复杂的决策。人工智能可以指出这些错误。
图片来源:图片由编辑团队使用人工智能生成,仅供参考。来源:https://techxplore.com/news/2026-05-humans-bad-complex-decisions-ai.html当罗列优缺点不足以解决问题时,康奈尔大学研究人员开发的一种新型决策工具可以利用人工智能…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...

基于BLE与CircuitPython的无线8-bit音乐合成器DIY全攻略
1. 项目概述与核心思路想不想亲手做一个能揣在口袋里,随时随地弹奏出复古8-bit音乐的小玩意儿?不是那种手机App模拟的,而是实实在在的、有物理按键、能无线连接、还会发光的小合成器。今天分享的这个项目,就是基于两块小巧但功能强…...

免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽
免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...