DBA技术栈(二):MySQL 存储引擎

2.1 MySQL存储引擎概述
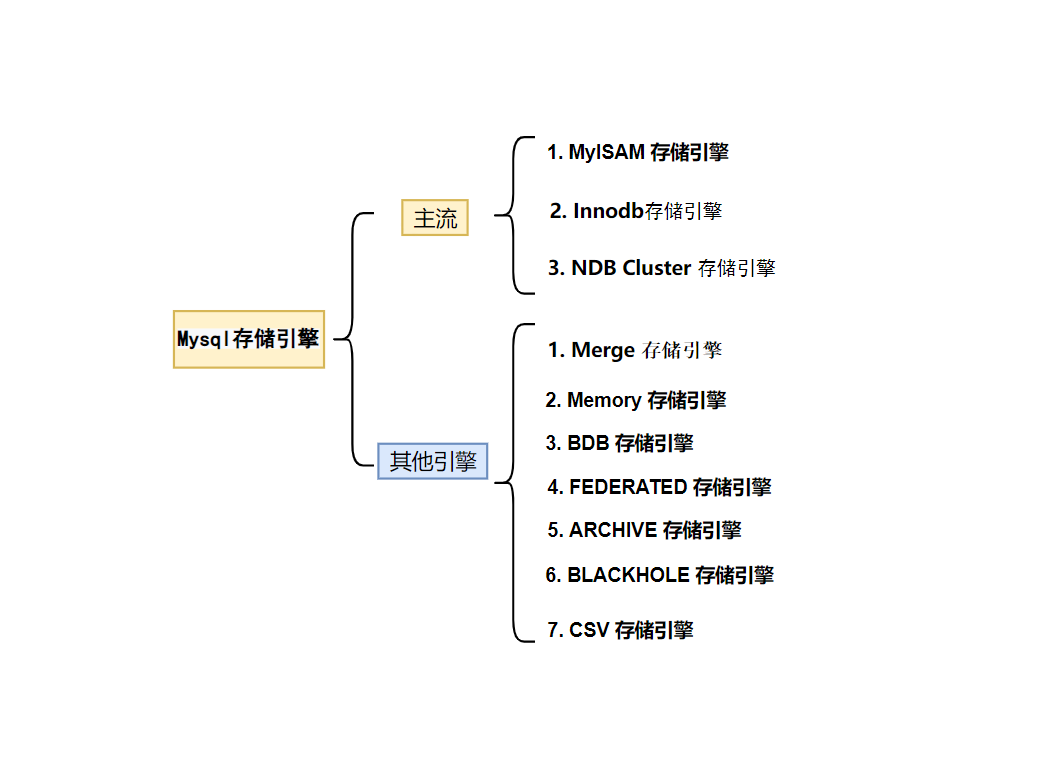
上个业余的图:

MyISAM 存储引擎是 MySQL 默认的存储引擎,也是目前 MySQL 使用最为广泛的存储引擎之一。他的前身就是我们在 MySQL 发展历程中所提到的 ISAM,是 ISAM 的升级版本。在 MySQL最开始发行的时候是 ISAM 存储引擎,而且实际上在最初的时候,MySQL 甚至是没有存储引擎这个概念的。MySQL在架构上面也没有像现在这样的sql layer和storage engine layer这两个结构清晰的层次结构,当时不管是代码本身还是系统架构,对于开发者来说都很痛苦的一件事情。
5.1 之前的 版本中,虽然存储引擎层和 sql层的耦合已经非常少了,基本上完全是通过接口来实现交互,但是这两层之间仍然是没办法分离的,即使在安装的时候也是一样。
MySQL5.1 开始,MySQL AB 对其结构体系做了较大的改造,并引入了一个新的概念:插件式存储引擎体系结构。MySQL AB 在架构改造的时候,让存储引擎层和 sql 层各自更为独立,耦合更小,甚至可以做到在线加载信的存储引擎,也就是完全可以将一个新的存储引擎加载到一个正在 运行的 MySQL 中,而不影响 MySQL 的正常运行。插件式存储引擎的架构,为存储引擎的加载和移出更为灵活方便,也使自行开发存储引擎更为方便简单。在 这
一点上面,目前还没有哪个数据库管理系统能够做到。MySQL 的插件式存储引擎主要包括 MyISAM,Innodb,NDB Cluster,Maria,Falcon,Memory,Archive,Merge,Federated 等,**其中最著名而且使用最为广泛的 MyISAM 和 Innodb两种存储引擎。**MyISAM 是 MySQL 最早的 ISAM 存储引擎的升级版本,也是 MySQL 默认的存储
引擎。而 Innodb 实 际上并不是 MySQ 公司的,而是第三方软件公司 Innobase(在 2005 年被 Oracle 公司所收购)所开发,其最大的特点是提供了事务控制等特性, 所以使用者也非常广泛。
2.2 MySQL存储引擎介绍
MyISAM 存储引擎简介
MyISAM 存储引擎的表在数据库中,每一个表都被存放为三个以表名命名的物理文件。首先肯定会有任何存储引擎都不可缺少的存放表结构定义信息的.frm 文件,另外还有.MYD和.MYI 文件,分别存放了表的数据(.MYD)和索引数据(.MYI)。每个表都有且仅有这样三个文件做为 MyISAM 存储类型的表的存储,也就是说不管这个表有多少个索引,都是存放在同一个.MYI 文件中。
MyISAM 支持以下三种类型的索引:
1、B-Tree 索引
B-Tree 索引,顾名思义,就是所有的索引节点都按照 balance tree 的数据结构来存储,所有的索引数据节点都在叶节点。
2、R-Tree 索引
R-Tree 索引的存储方式和 b-tree 索引有一些区别,主要设计用于为存储空间和多维数据的字段做索引,所以目前的 MySQL 版本来说,也仅支持 geometry 类型的字段作索引。
3、Full-text 索引
Full-text 索引就是我们长说的全文索引,他的存储结构也是 b-tree。主要是为了解决在我们需要用 like 查询的低效问题。
MyISAM 上面三种索引类型中,最经常使用的就是 B-Tree 索引了,偶尔会使用到 Fulltext,但是 R-Tree 索引一般系统中都是很少用到的。另外 MyISAM 的 B-Tree 索引有一个较大的限制,那就是参与一个索引的所有字段的长度之和不能超过 1000 字节。
虽然每一个 MyISAM 的表都是存放在一个相同后缀名的.MYD 文件中,但是每个文件的存放格式实际上可能并不是完全一样的,因为 MyISAM 的数据存放格式是分为静态(FIXED)固定长度、动态(DYNAMIC)可变长度以及压缩(COMPRESSED)这三种格式。当然三种格式中是否压缩是完全可以任由我们自己选择的,可以在创建表的时候通过 ROW_FORMAT 来指定{COMPRESSED | DEFAULT},也可以通过 myisampack 工具来进行压缩,默认是不压缩的。而在非压缩的情况下,是静态还是动态,就和我们表中个字段的定义相关了。只要表中有可变长度类型的字段存在,那么该表就肯定是 DYNAMIC 格式的,如果没有任何可变长度的字段,则为 FIXED 格式,当然,你也可以通过 alter table 命令,强行将一个带有 VARCHAR 类型字段的 DYNAMIC 的表转换为 FIXED,但是所带来的结果是原 VARCHAR 字段类型会被自动转换成CHAR 类型。相反如果将 FIXED 转换为 DYNAMIC,也会将 CHAR 类型字段转换为 VARCHAR 类型,
所以大家手工强行转换的操作一定要谨慎。
MyISAM 存储引擎的表是否足够可靠呢?在 MySQL 用户参考手册中列出在遇到如下情况的时候可能会出现表文件损坏:
1、当 mysqld 正在做写操作的时候被 kill 掉或者其他情况造成异常终止;
2、主机 Crash;
3、磁盘硬件故障;
4、MyISAM 存储引擎中的 bug?
MyISAM 存储引擎的某个表文件出错之后,仅影响到该表,而不会影响到其他表,更不会影响到其他的数据库。如果我们的出据苦正在运行过程中发现某个 MyISAM 表出现问题了,则可以在线通过 check table 命令来尝试校验他,并可以通过 repair table 命令来尝试修复。在数据库关闭状态下,我们也可以通过 myisamchk 工具来对数据库中某个(或某些)表进行检测或者修复。不过强烈建议不到万不得已不要轻易对表进行修复操作,修复之前尽量做好可能的备份工作,以免带来不必要的后果。另外 MyISAM 存储引擎的表理论上是可以被多个数据库实例同时使用同时操作的,但是不论是我们都不建议这样做,而且 MySQL 官方的用户手册中也有提到,建议尽量不要在多个mysqld 之间共享 MyISAM 存储文件。
Innodb 存储引擎简介
在 MySQL 中使用最为广泛的除了 MyISAM 之外,就非 Innodb 莫属了。Innodb 做为第三方公司所开发的存储引擎,和 MySQL 遵守相同的开源 License 协议。Innodb 之所以能如此受宠,主要是在于其功能方面的较多特点:
1、支持事务安装
Innodb在功能方面最重要的一点就是对事务安全的支持,这无疑是让Innodb成为MySQL最为流行的存储引擎之一的一个非常重要原因。而且实现了 SQL92 标准所定义的所有四个级别(READ UNCOMMITTED,READ COMMITTED,REPEATABLE READ, SERIALIZABLE)。对事务安全的支持,无疑让很多之前因为特殊业务要求而不得不放弃使用 MySQL 的用户转向支持MySQL,以及之前对数据库选型持观望态度的用户,也大大增加了对 MySQL 好感。
2、数据多版本读取
Innodb 在事务支持的同时,为了保证数据的一致性已经并发时候的性能,通过对 undo
信息,实现了数据的多版本读取。
3、锁定机制的改进
Innodb 改变了 MyISAM 的锁机制,实现了行锁。虽然 Innodb 的行锁机制的实现是通过
索引来完成的,但毕竟在数据库中 99%的 SQL 语句都是要使用索引来做检索数据的。所以,
行锁定机制也无疑为 Innodb 在承受高并发压力的环境下增强了不小的竞争力。
4、实现外键
Innodb 实现了外键引用这一数据库的重要特性,使在数据库端控制部分数据的完整性成为可能。虽然很多数据库系统调优专家都建议不要这样做,但是对于不少用户来说在数据库端加如外键控制可能仍然是成本最低的选择。
除了以上几个功能上面的亮点之外,Innodb 还有很多其他一些功能特色常常带给使用者不小的惊喜,同时也为 MySQL 带来了更多的客户。
在物理存储方卖弄,Innodb 存储引擎也和 MyISAM 不太一样,虽然也有.frm 文件来存放表结构定义相关的元数据,但是表数据和索引数据是存放在一起的。至于是每个表单独存放还是所有表存放在一起,完全由用户来决定(通过特定配置),同时还支持符号链接。
Innodb 的物理结构分为两大部分:
1、数据文件(表数据和索引数据)
存放数据表中的数据和所有的索引数据,包括主键和其他普通索引。在 Innodb 中,存在了表空间(tablespace)这样一个概念,但是他和 Oracle 的表空间又有较大的不同。首先,Innodb 的表空间分为两种形式。一种是共享表空间,也就是所有表和索引数据被存放在同一个表空间(一个或多个数据文件)中,通过 innodb_data_file_path 来指定,增加数据文件需要停机重启。 另外一种是独享表空间,也就是每个表的数据和索引被存放在一个单独的.ibd 文件中。
虽然我们可以自行设定使用共享表空间还是独享表空间来存放我们的表,但是共享表空间都是必须存在的,因为 Innodb 的 undo 信息和其他一些元数据信息都是存放在共享表空间里面的。共享表空间的数据文件是可以设置为固定大小和可自动扩展大小两种形式的,自动扩展形式的文件可以设置文件的最大大小和每次扩展量。在创建自动扩展的数据文件的时候,建议大家最好加上最大尺寸的属性,一个原因是文件系统本身是有一定大小限制的(但是 Innodb 并不知道),还有一个原因就是自身维护的方便。另外,Innodb 不仅可以使用文
件系统,还可以使用原始块设备,也就是我们常说的裸设备。当我们的文件表空间快要用完的时候,我们必须要为其增加数据文件,当然,只有共享表 空 间 有 此 操 作 。 共 享 表 空 间 增 加 数 据 文 件 的 操 作 比 较 简 单 , 只 需 要 在innodb_data_file_path 参数后面按照标准格式设置好文件路径和相关属性即可,不过这里有一点需要注意的,就是 Innodb 在创建新数据文件的时候是不会创建目录的,如果指定目录不存在,则会报错并无法启动。另外一个较为令人头疼的就是 Innodb 在给共享表空间增加数据文件之后,必须要重启数据库系统才能生效,如果是使用裸设备,还需要有两次重启 。这也是我一直不太喜欢使用共享表空间而选用独享表空间的原因之一。
2、日志文件
Innodb 的日志文件和 Oracle 的 redo 日志比较类似,同样可以设置多个日志组(最少 2个),同样采用轮循策略来顺序的写入,甚至在老版本中还有和 Oracle 一样的日志归档特性 。如果你的数据库中有创建了 Innodb 的表,那么千万别全部删除 innodb 的日志文件,因为很可能就会让你的数据库 crash,无法启动,或者是丢失数据。由于 Innodb 是事务安全的存储引擎,所以系统 Crash 对他来说并不能造成非常严重的损失,由于有 redo 日志的存在,有 checkpoint 机制的保护,Innodb 完全可以通过 redo 日志将数据库 Crash 时刻已经完成但还没有来得及将数据写入磁盘的事务恢复,也能够将所有部分完成并已经写入磁盘的未完成事务回滚并将数据还原。
Innodb 不仅在功能特性方面和 MyISAM 存储引擎有较大区别,在配置上面也是单独处理的。在 MySQL 启动参数文件设置中,Innodb 的所有参数基本上都带有前缀“innodb_”,不论是 innodb 数据和日志相关,还是其他一些性能,事务等等相关的参数都是一样。和所有Innodb 相关的系统变量一样,所有的 Innodb 相关的系统状态值也同样全部以“Innodb_”前缀。当然,我们也完全可以仅仅通过一个参数(skip-innodb)来屏蔽 MySQL 中的 Innodb存储引擎,这样即使我们在安装编译的时候将 Innodb 存储引擎安装进去了,使用者也无法创建 Innodb 的表。
NDB Cluster 存储引擎简介
NDB 存储引擎也叫 NDB Cluster 存储引擎,主要用于 MySQL Cluster 分布式集群环境,Cluster 是 MySQL 从 5.0 版本才开始提供的新功能。这部分我们可能并不仅仅只是介绍 NDB存储引擎,因为离开了 MySQL CLuster 整个环境,NDB 存储引擎也将失去太多意义。 简单的说,Mysql Cluster 实际上就是在无共享存储设备的情况下实现的一种内存数据库 Cluster 环境,其主要是通过 NDB Cluster(简称 NDB)存储引擎来实现的。
一般来说,一个 Mysql Cluster 的环境主要由以下三部分组成:
a) 负责管理各个节点的 Manage 节点主机:
管理节点负责整个 Cluster 集群中各个节点的管理工作,包括集群的配置,启动关闭各节点,以及实施数据的备份恢复等。管理节点会获取整个 Cluster 环境中各节点的状态和错误信息,并且将各 Cluster 集群中各个节点的信息反馈给整个集群中其他的所有节点。由于管理节点上保存在整个 Cluster 环境的配置,同时担任了集群中各节点的基本沟通工作,所以他必须是最先被启动的节点。
b) SQL 层的 SQL 服务器节点(后面简称为 SQL 节点),也就是我们常说的 Mysql Server:
主要负责实现一个数据库在存储层之上的所有事情,比如连接管理,query 优化和响应,cache 管理等等,只有存储层的工作交给了 NDB 数据节点去处理了。也就是说,在纯粹的 Mysql Cluster 环境中的 SQL 节点,可以被认为是一个不需要提供任何存储引擎的 Mysql服务器,因为他的存储引擎有 Cluster 环境中的 NDB 节点来担任。所以,SQL 层各 Mysql 服务器的启动与普通的 Mysql 启动有一定的区别,必须要添加 ndbcluster 项,可以添加在my.cnf 配置文件中,也可以通过启动命令行来指定。
c) Storage 层的 NDB 数据节点,也就是上面说的 NDB Cluster:
NDB 是一个内存式存储引擎也就是说,他会将所有的数据和索引数据都 load 到内存中 ,但也会将数据持久化到存储设备上。不过,最新版本,已经支持用户自己选择数据可以不全部 Load 到内存中了,这对于有些数据量太大或者基于成本考虑而没有足够内存空间来存放所有数据的用户来说的确是一个大好消息。
NDB 节点主要是实现底层数据存储的功能,保存 Cluster 的数据。每一个 NDB 节点保存完整数据的一部分(或者一份完整的数据,视节点数目和配置而定),在 MySQL CLuster 里面叫做一个 fragment。而每一个 fragment,正常情况来讲都会在其他的主机上面有一份(或者多分)完全相同的镜像存在。这些都是通过配置来完成的,所以只要配置得当,MysqlCluster 在存储层不会出现单点的问题。
一般来说,NDB 节点被组织成一个一个的 NDB Group,一个 NDB Group 实际上就是一组存有完全相同的物理数据的 NDB 节点群。上面提到了 NDB 各个节点对数据的组织,可能每个节点都存有全部的数据也可能只保存一部分数据,主要是受节点数目和参数来控制的。首先在 Mysql Cluster 主配置文件(在管理节点上面,一般为 config.ini)中,有一个非常重要的参数叫 NoOfReplicas,这个参数指定了每一份数据被冗余存储在不同节点上面的份数,该参数一般至少应该被设置成 2,也只需要设置成 2 就可以了。因为正常来说,两个互为冗余的节点同时出现故障的概率还是非常小的,当然如果机器和内存足够多的话,也可以继续增大。一个节点上面是保存所有的数据还是一部分数据,还受到存储节点数目的限制。NDB 存储引擎首先保证 NoOfReplicas 参数配置的要求对数据冗余,来使用存储节点,然后再根据节点数目将数据分段来继续使用多余的 NDB 节点,分段的数目为节点总数除以 NoOfReplicas 所得。
其他存储引擎介绍
1. Merge 存储引擎:
MERGE 存储引擎,在 MySQL 用户手册中也提到了,也被大家认识为 MRG_MyISAM 引擎。Why?因为 MERGE 存储引擎可以简单的理解为其功能就是实现了对结构相同的 MyISAM 表 ,通过一些特殊的包装对外提供一个单一的访问入口,以达到减小应用的复杂度的目的。要创建MERGE 表,不仅仅基表的结构要完全一致,包括字段的顺序,基表的索引也必须完全一致。
MERGE 表本身并不存储数据,仅仅只是为多个基表提供一个同意的存储入口。所以在创建 MERGE 表的时候,MySQL 只会生成两个较小的文件,一个是.frm 的结构定义文件,还有一个.MRG 文件,用于存放参与 MERGE 的表的名称(包括所属数据库 schema)。之所以需要有所属数据库的 schema,是因为 MERGE 表不仅可以实现将 Merge 同一个数据库中的表,还可以Merge 不同数据库中的表,只要是权限允许,并且在同一个 mysqld 下面,就可以进行 Merge。MERGE 表在被创建之后,仍然可以通过相关命令来更改底层的基表。MERGE 表不仅可以提供读取服务,也可以提供写入服务。要让 MERGE 表提供可 INSERT服务,必须在在表被创建的时候就指明 INSERT 数据要被写入哪一个基表,可以通过insert_method 参数来控制。如果没有指定该参数,任何尝试往 MERGE 表中 INSERT 数据的操作,都会出错。此外,无法通过 MERGE 表直接使用基表上面的全文索引,要使用全文索引 ,必须通过基表本身的存取才能实现。
2. Memory 存储引擎:
Memory 存储引擎,通过名字就很容易让人知道,他是一个将数据存储在内存中的存储引擎。Memory 存储引擎不会将任何数据存放到磁盘上,仅仅存放了一个表结构相关信息的.frm 文件在磁盘上面。所以一旦 MySQL Crash 或者主机 Crash 之后,Memory 的表就只剩下一个结构了。Memory 表支持索引,并且同时支持 Hash 和 B-Tree 两种格式的索引。由于是存放在内存中,所以 Memory 都是按照定长的空间来存储数据的,而且不支持 BLOB 和 TEXT类型的字段。Memory 存储引擎实现页级锁定。既然所有数据都存放在内存中,那么他对内存的消耗量是可想而知的。在 MySQL 的用户手册上面有这样一个公式来计算 Memory 表实际需要消耗的内存大小:
SUM_OVER_ALL_BTREE_KEYS(max_length_of_key + sizeof(char*) * 4)
+ SUM_OVER_ALL_HASH_KEYS(sizeof(char*) * 2)
+ ALIGN(length_of_row+1, sizeof(char*))
3. BDB 存储引擎:
BDB 存储引擎全称为 BerkeleyDB 存储引擎,和 Innodb 一样,也不是 MySQL 自己开发实现的一个存储引擎,而是由 Sleepycat Software 所提供,当然,也是开源存储引擎,同样支持事务安全。BDB 存储引擎的数据存放也是每个表两个物理文件,一个.frm 和一个.db 的文件,数据和索引信息都是存放在.db 文件中。此外,BDB 为了实现事务安全,也有自己的 redo 日 志 ,和 Innodb 一样,也可以通过参数指定日志文件存放的位置。在锁定机制方面,BDB 和 Memory存储引擎一样,实现页级锁定。由于 BDB 存储引擎实现了事务安全,那么他肯定也需要有自己的 check point 机 制 。BDB在每次启动的时候,都会做一次 check point,并且将之前的所有 redo 日志清空。在运行过程中,我们也可以通过执行 flush logs 来手工对 BDB 进行 check point 操作。
4. FEDERATED 存储引擎:
FEDERATED 存储引擎所实现的功能,和 Oracle 的 DBLINK 基本相似,主要用来提供对远程 MySQL 服务器上面的数据的访问借口。如果我们使用源码编译来安装 MySQL,那么必须手工指定启用FEDERATED 存储引擎才行,因为 MySQL 默认是不起用该存储引擎的。当我们创建一个 FEDERATED 表的时候,仅仅在本地创建了一个表的结构定义信息的文件而已,所有数据均实时取自远程的 MySQL 服务器上面的数据库。当我们通过 SQL 操作 FEDERATED 表的时候,实现过程基本如下:
a、SQL 调用被本地发布
b、MySQL 处理器 API(数据以处理器格式)
c、MySQL 客户端 API(数据被转换成 SQL 调用)
d、远程数据库-> MySQL 客户端 API
e、转换结果包(如果有的话)到处理器格式
f、处理器 API -> 结果行或受行影响的对本地的计数
5. ARCHIVE 存储引擎:
ARCHIVE 存储引擎主要用于通过较小的存储空间来存放过期的很少访问的历史数据。ARCHIVE 表不支持索引,通过一个.frm 的结构定义文件,一个.ARZ 的数据压缩文件还有一个.ARM 的 meta 信息文件。由于其所存放的数据的特殊性,ARCHIVE 表不支持删除,修改操作,仅支持插入和查询操作。锁定机制为行级锁定。
6. BLACKHOLE 存储引擎:
BLACKHOLE 存储引擎是一个非常有意思的存储引擎,功能恰如其名,就是一个“黑洞”。就像我们 unix 系统下面的“/dev/null”设备一样,不管我们写入任何信息,都是有去无回 。那么BLACKHOLE存储引擎对我们有什么用呢?在我最初接触MySQL的时候我也有过同样的疑问,不知道 MySQL 提供这样一个存储引擎给我们的用意为何?但是后来在又一次数据的迁移过程中,正是 BLACKHOLE 给我带来了非常大的功效。在那次数据迁移过程中,由于数据需要经过一个中转的 MySQL 服务器做一些相关的转换操作,然后再通过复制移植到新的服务器上
面。可当时我没有足够的空间来支持这个中转服务器的运作。这时候就显示出 BLACKHOLE的功效了,他不会记录下任何数据,但是会在 binlog 中记录下所有的 sql。而这些 sql 最终都是会被复制所利用,并实施到最终的 slave 端。
BLACKHOLE 存储引擎其他几个用途如下:
a、SQL 文件语法的验证。
b、来自二进制日志记录的开销测量,通过比较允许二进制日志功能的 BLACKHOLE 的性能与禁止二进制日志功能的 BLACKHOLE 的性能。
c、因为 BLACKHOLE 本质上是一个“no-op” 存储引擎,它可能被用来查找与存储引擎自身不相关的性能瓶颈。
7. CSV 存储引擎:
CSV 存储引擎实际上操作的就是一个标准的 CSV 文件,他不支持索引。起主要用途就是大家有些时候可能会需要通过数据库中的数据导出成一份报表文件,而 CSV 文件是很多软件都支持的一种较为标准的格式,所以我们可以通过先在数据库中建立一张 CVS 表,然后将生成的报表信息插入到该表,即可得到一份 CSV 报表文件了
相关文章:
DBA技术栈(二):MySQL 存储引擎
2.1 MySQL存储引擎概述 上个业余的图: MyISAM 存储引擎是 MySQL 默认的存储引擎,也是目前 MySQL 使用最为广泛的存储引擎之一。他的前身就是我们在 MySQL 发展历程中所提到的 ISAM,是 ISAM 的升级版本。在 MySQL最开始发行的时候是 ISAM 存…...
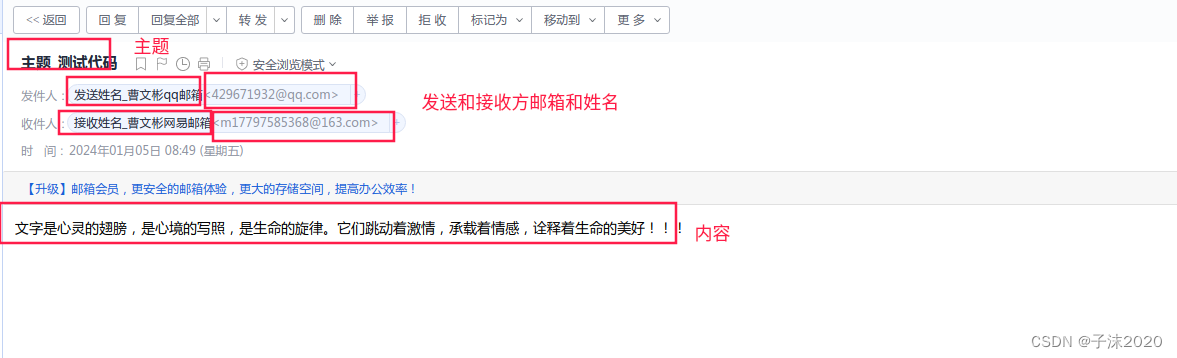
java发送邮件到qq邮箱
自己的授权码自己记好 引入依赖 <dependency><groupId>com.sun.mail</groupId><artifactId>javax.mail</artifactId><version>1.6.2</version> </dependency> <dependency><groupId>javax.mail</groupId>&…...

MySQL中的JSON数据类型计数及多张表COUNT的数据相加
1.使用场景:在MySQL中,JSON作为一种数据类型存储在表的列中。需计算键值对的数量。 2.方法:SELECT COUNT(chief>$.number) FROM t_projectapplication where id #{id};(t_projectapplication:表;chief&…...

XDOJ78.机器人
标题 机器人 类别 综合 时间限制 1S 内存限制 256Kb 问题描述 机器人按照给定的指令在网格中移动,指令有以下四种: N 向北(上)移动 S 向南(下)移动 E 向东(右)移动 W 向西&…...

分布式系统架构设计之分布式事务的概述和面临的挑战
在当今大规模应用和服务的背景下,分布式系统的广泛应用已经成为了一种必然的主流趋势。然后,伴随着分布式系统的应用范围的增长,分布式事务处理成为了一个至关重要的关键话题。在传统的单体系统中,事务处理通常相对简单࿰…...
私有化部署你的甘特图协作工具
安装 首先去官网 https://zz-plan.com/deploy 下载对应的版本 arm是对应m1 m2 m3的mac amd是老的intel处理器 准备工作 安装mysql zz-plan需要依赖mysql 生成token 解压下载的压缩包 创建token./zz-plan -c 复制创建的token去获取授权码,点击获取免费授权码 …...

编程笔记 html5cssjs 011 HTML内连框架
编程笔记 html5&css&js 011 HTML内连框架 一、内连框架(一)意义(二)属性 二、操作注意 接下来要看一下网页内的划分。通过内连框架在当前页面嵌入一个特定内容,是一种特定需要。 一、内连框架 HTML 内联框架元…...
Stable Diffusion 系列教程 - 5 ControlNet
ControlNet和LORA的定位都是对大模型做微调的额外网络。作为入门SD的最后一块拼图是必须要去了解和开发的。为什么ControlNet的影响力如此的大?在它之前,基于扩散模型的AIGC是非常难以控制的,扩散整张图像的过程充满了随机性。这种随机性并不…...
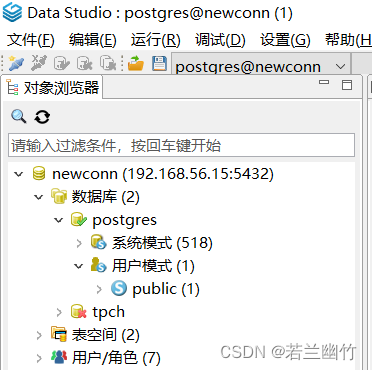
【导出与导入Virtualbox虚拟机和启动连接openGauss数据库】
【导出与导入Virtualbox虚拟机和启动连接openGauss数据库】 一、导出虚拟机二、导入虚拟机三、启动数据库四、使用Data Studio连接数据库 一、导出虚拟机 选择关机状态的虚拟机 -> 管理菜单 -> 导出虚拟电脑 点击完成后,需要等待一小段时间,如…...
“华为杯”杭州电子科技大学2023新生编程大赛---树
题目链接 Problem Description 给定一棵包含 n 个节点的带边权的树,树是一个无环的无向联通图。定义 xordist(u,v) 为节点 u 到 v 的简单路径上所有边权值的异或和。 有 q 次询问,每次给出 l r x,求 ∑rilxordist(i,x) 的值。 Input 测试…...
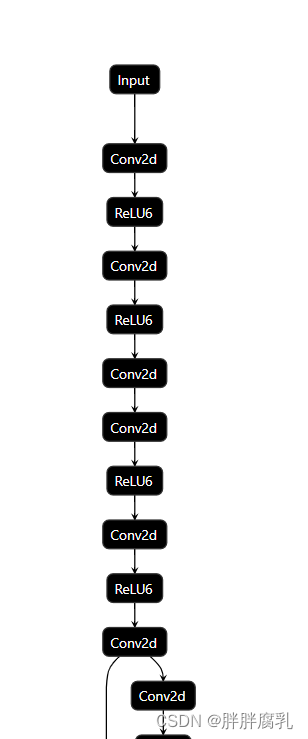
使用pnnx将Torch模型转换为ncnn
1. 引言 以往我们将Torch模型转换为ncnn模型,通常需经过Torch–>onnx,onnx–>ncnn两个过程。但经常会出现某些算子不支持的问题。 ncnn作者针对该问题,直接开发一个Torch直接转换ncnn模型的工具 (PNNX),以下为相关介绍及使…...

linux卸载小皮面板phpstudy教程
千万不要直接删文件夹! 千万不要直接删文件夹! 千万不要直接删文件夹! 我就是按照网上搜索的教程,直接删了,然后 系统就不停的崩溃 生成这种文件: -rw------- 1 root root 223M Dec 28 22:36…...
【萤火虫系列教程】1/5-Adobe Firefly 注册账号
001-Adobe Firefly 注册账号 AI时代如火如荼,Adobe也不甘落后,于今年3月份发布AI创意生成工具Firefly(中文翻译:萤火虫) Adobe Firefly简介 Adobe Firefly的官方介绍为:Firefly是Adobe产品中新的创意生成…...

【docker】Dockerfile 指令详解
一、Dockerfile 指令详解 Dockerfile是一个用于编写docker镜像生成过程的文件,其有特定的语法。Dockerfile的基本指令有十三个,分别是:FROM、MAINTAINER、RUN、CMD、EXPOSE、ENV、ADD、COPY、ENTRYPOINT、VOLUME、USER、WORKDIR、ONBUILD。 …...

内存管理机制
内存管理机制与内存映射相关。 一、C与C 之所以将C与C放在一起是因为C是C的超集; 但是C是面向过程语言,C是面向对象的语言; C与C都可以使用malloc、calloc、realloc来申请内存空间; 其中void* malloc(size_t size)是在内存的动态…...
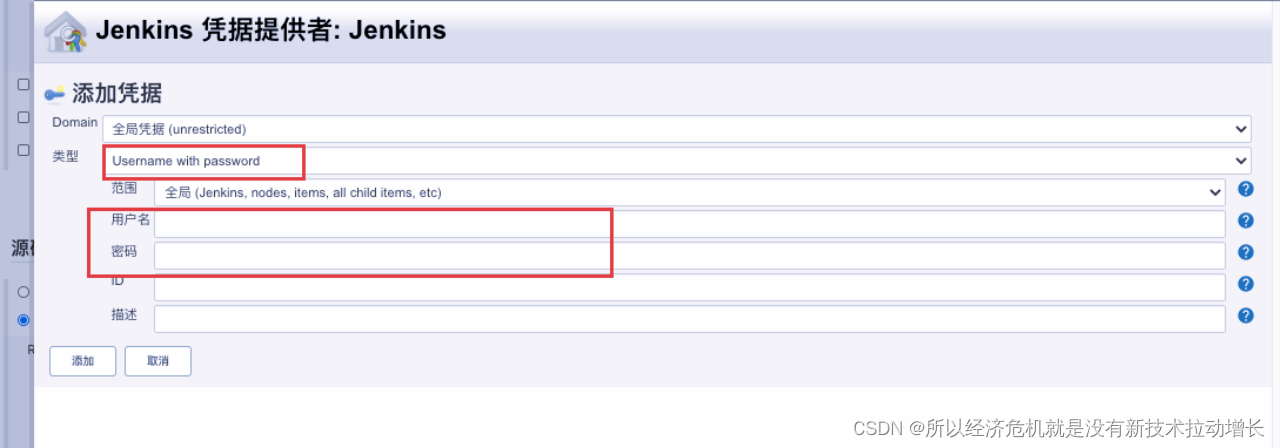
Jenkins工具使用
学习目录: 1、jenkins的安装 2、junkins的常规使用 3、jenkins在接口自动化测试实践 具体内容: 1、jenkins的安装 安装包下载:推荐Index of /jenkins/war/latest/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror,…...

SpringBoot从配置文件中获取属性的方法
方式一:Value 基本类型属性注入,直接在字段上添加Value("${xxx.xxx}")即可.注意这里用的是$,而不是#,Value注入的属性,一般其他属性没有关联关系。 配置文件 user:name: Manaphyage: 19sex: m…...
oracle物化视图
物化视图定义 视图是一个虚拟表(也可以认为是一条语句),基于它创建时指定的查询语句返回的结果集,每次访问它都会导致这个查询语句被执行一次,为了避免每次访问都执行这个查询,可以将这个查询结果集存储到…...

基于ssm校园线上订餐系统的设计与实现论文
摘 要 信息数据从传统到当代,是一直在变革当中,突如其来的互联网让传统的信息管理看到了革命性的曙光,因为传统信息管理从时效性,还是安全性,还是可操作性等各个方面来讲,遇到了互联网时代才发现能补上自古…...
鸿蒙南向开发—OpenHarmony技术编译构建框架
概述 OpenHarmony编译子系统是以GN和Ninja构建为基座,对构建和配置粒度进行部件化抽象、对内建模块进行功能增强、对业务模块进行功能扩展的系统,该系统提供以下基本功能: 以部件为最小粒度拼装产品和独立编译。支持轻量、小型、标准三种系…...

数据分析进阶——【连载 5/9】《Power BI数据分析与可视化案例教程》项目5 数据建模
Power BI 数据建模教程|推介总结 适应人群:数据分析师、业务分析人员、财务 / 运营 / 销售岗、高校学生、企业内训学员、Power BI 进阶学习者。 重要性总结:本文档是 Power BI 数据建模核心实操教程,系统讲解数据建模全流程&#…...

Windows 11优化终极指南:使用Win11Debloat一键提升电脑性能51%
Windows 11优化终极指南:使用Win11Debloat一键提升电脑性能51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

3步解锁游戏窗口任意分辨率:SRWE终极使用指南
3步解锁游戏窗口任意分辨率:SRWE终极使用指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾经遇到过这样的情况:想用游戏截图制作精美的壁纸,却发现游戏内置的分辨…...

如何轻松掌握开源OCR插件的实用技巧:5步快速上手指南
如何轻松掌握开源OCR插件的实用技巧:5步快速上手指南 【免费下载链接】Umi-OCR_plugins Umi-OCR 插件库 项目地址: https://gitcode.com/gh_mirrors/um/Umi-OCR_plugins 你是否曾被纸质文档的数字化问题困扰?或者需要从图片中提取数学公式却找不到…...
pc手机通用)
明末:渊虚之羽加修改器2026.5.12最新破解版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机通用
游戏本体下载链接 修改器链接 由成都灵泽科技(Leenzee Games)开发,505 Games发行的动作角色扮演游戏《明末:渊虚之羽》(WUCHANG: Fallen Feathers)在近年来备受动作游戏玩家的关注。作为一款扎根于中国历…...

终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验
终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器&#x…...

5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南
5分钟实现电脑风扇智能控制:FanControl.HWInfo终极指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要告别电脑风扇的噪音困扰吗?FanCon…...

科技成果转化平台建设成本高如何解决?
观点作者:科易网-国家科技成果转化(厦门)示范基地现状概述(成效与短板) 近年来,我国科技成果转化平台建设取得显著进展,各地政府部门、高校、科研院所积极探索,累计建成各类技术转移…...

Pega Helm Charts:Kubernetes上企业级低代码BPM平台部署指南
1. 项目概述:Pega Helm Charts 是什么,以及为什么你需要它如果你正在或计划在 Kubernetes 上部署 Pega Platform,那么pegasystems/pega-helm-charts这个项目就是你绕不开的“官方说明书”和“自动化部署工具箱”。简单来说,这是一…...
深入Linux网络栈:当虚拟机网络中断时,如何像侦探一样解读‘transmit queue timed out‘内核警告
深入Linux网络栈:当虚拟机网络中断时,如何像侦探一样解读transmit queue timed out内核警告 在虚拟化环境中,网络中断往往是最令人头疼的问题之一。当虚拟机突然失去网络连接,而宿主机的物理网卡却显示一切正常时,问题…...