详解bookkeeper AutoRecovery机制
引言小故事
张三在一家小型互联网公司上班,由于公司实行的996,因此经常有同事“不辞而别”,为了工作的正常推进,团队内达成了某种默契,这种默契就是通过某个规则来选出一个同事,这个同事除了工作之余还有额外看看每天是否有同事“不辞而别”,当发现有同事李四离职时,就会去把李四负责的工作的内容进行拆分给其他的同事进行处理。整个过程大致如下图

由上图可以看到这个公司通过一个签到本和工作进度表来完成整个流程,每个同事上班时都要在签到本上进行签到,每天下班前要在工作进度表上同步今天的工作进展;例如今天李四“不辞而别”溜了,张三在签到本上看到李四没有签到记录,就判定这家伙不干了同时在工作进度表中把李四的任务进行拆分给大狗和二狗来做…
通过上面的故事会发现有几个问题
- 张三是通过什么规则被选成“监督者”的?
- 如果张三也不辞而别呢?
- 为啥要通过签到本的方式,而不是张三直接去挨个挨个看?
- …
咱们可以带着这些种种心里的疑惑看下面的文章,这个故事其实是一个分布式存储组件的雏形,刚刚所讨论的那些问题也是这些组件所会遇到的且大部分都是有解法的,所以咱们接下来就来看看bookkeeper这个分布式存储组件是如何解决上述问题的
bookkeeper基础
“硬件无法保证不故障”,在这个大前提下,所有运行在硬件上的存储组件都一定会做一件很重要的事情,这件事就是数据恢复,要么是在组件内部来做,要么是在组件外部来做。
bk是一个具有容错的分布式存储组件,同一份数据会有多个副本,分别存在多个bookie中来提供容错保证,那么当一台bookie不可用时,其上面保存的数据都少了一个副本,如果不进行数据恢复/复制的话再有其他的bookie不可用就很容易造成数据的丢失。因此bk自身内部提供了数据恢复的机制,今天通篇大论都是围绕bk的这个机制进行展开的
数据恢复一般分为手动和自动,bk同时支持这两种方式,接下来就看看具体怎么操作的
手动恢复
bin/bookkeeper shell recover 192.168.1.10:3181 指定bookie机器来恢复
bin/bookkeeper shell recover 192.168.1.10:3181 --ledger ledgerID 指定bookie机器上的某个ledgerId进行恢复
在执行手动恢复时,会发生以下四个步骤
- 客户端从zookeeper读取Ledger信息
- 根据Ledger信息确定需要做数据复制的Ledger(根据Ledger中存有被哪些bookie存储的元信息来确定)
- 在客户端启动一个做数据恢复的进程,针对需要做数据复制的Ledger进行数据恢复
- 一旦所有Ledger被标记为全副本了,则恢复动作完成
自动恢复
bin/bookkeeper autorecovery bookie 集群开启自动恢复机制
bin/bookkeeper shell autorecovery -disable 关闭自动恢复机制
bin/bookkeeper shell autorecovery -enable 关闭恢复后再重新开启
除了通过指令的方式启动,bk还支持配置的方式,只需要在bookie节点配置autoRecoveryDaemonEnabled为false,这个bookie节点在启动的时候也同样会启动autorecovery服务
autorecovery机制
上一章节讲了怎么使用,本章节主要讲明autorecovery这个机制
自动恢复机制中有两个角色Auditor和replication worker,在启动自动恢复机制后,会在每个bookie实例中启动这两个角色
Auditor
bk集群中的Auditor们会通过zookeeper选举产生一位leader,这个leader负责监听 zookeeper /ledgers/available 节点变化情况来判定是否要做数据恢复动作,因为所有节点启动都会注册在上面,如果有服务不可用由于zookeeper的临时目录机制,会自动删除在此目录下自己节点的信息,因此leader通过watch机制可以轻松感知到有节点不可用,当Auditor leader感知到有节点不可用时,会将此bookie所负责的所有Ledger加在zookeeper /ledgers/underreplicated 路径下,通过这种方式通知replication worker做数据恢复过程
replication worker
每个replication worker都会监听 /ledgers/underreplicated 地址,在监听到有数据恢复任务时,会在 /ledgers/underreplication/locks下添加锁从而避免并发问题;如果在开始恢复前发下当前Ledger的Fragment还处于写入中的状态,replication worker会先尝试等待它写完再做数据恢复动作,但如果等了一段时间还没写完会通过Fence机制处理再做复制,同时开启一个新的Fragment给客户端做数据的继续写入
启动工作流程

参照上图,在服务器节点上执行bin/bookkeeper autorecovery bookie 后会发生以下步骤
- 通过exec shell指令调用操作系统拉起AutoRecoveryMain 这个Java进程
- AutoRecoveryMain进程启动时会同时启动Auditor线程和ReplicationWorker线程,由于环境中可能会启动多个AutoRecoveryMain进程来做HA高可用,因此多个Auditor线程会通过zookeeper选举来产生一个Auditor Leader
- 由于bookie集群用zookeeper来做集群感知,因此Auditor Leader只需要通过watch监听zookeeper上 bookie所注册的地址就能感知到是否有bookie节点不可用;当bookie节点不可用时一般就不会上报心跳给zookeeper,zookeeper就会将该节点创建的临时目录进行删除并告知添加watch的Auditor Leader
- Auditor Leader收到通知后会去zookeeper查询该不可用bookie所负责的Ledger列表,理论上这些Ledger都是需要做数据恢复的,因此会将它们放在zookeeper的/ledgers/underreplicated 目录下来通知ReplicationWorker
- ReplicationWorker通过watch监听到此目录有需要做数据恢复的Ledger后,会先在zk加锁再进行数据恢复逻辑;通过将Ledger划分为多个Fragment来轮训进行数据恢复,通过读取其他正常bookie上该Ledger的数据并写到其他没有该数据的bookie的节点上从而保证每份数据都有多个副本,直到将/ledgers/underreplicated 下的所有Ledger进行复制完,本次 autorecovery就算完成了。而Auditor线程和ReplicationWorker线程会不停的监听zookeeper直到下一个bookie节点不可用
通过此机制给bookkeeper提高了稳定性以及高可用能力,在有个别节点挂掉的时候依然能自动做到数据完备不丢,这种设计是一个成熟的组件该具备的能力
autorecovery启动源码
源码主要分 启动流程以及工作流程进行讲解,同时在这里给需要阅读的朋友提供一个可能会用上的“词典”
AutoRecoveryMain核心类, 主要负责启动AutoRecovery服务
AutoRecoveryService核心类,主要负责AutoRecovery相关的服务
LedgerManager 对外提供一个管理ledger的api,对内负责如何将ledger的元数据存储在kv存储上。提供增删、读写、注册/注销六个核心接口
AbstractZkLedgerManager 抽象类
LedgerIdGenerator:基于zk实现全局唯一递增的ledgerId
ZkLedgerUnderreplicationManager:管理未完成复制的Ledger
ZkLedgerAuditorManager:管理Auditor
ReplicationWorker:负责从ZkLedgerUnderreplicationManager中获取未完成复制的Ledger并进行复制,每隔rwRereplicateBackoffMs触发一次
LedgerFragment:组成Ledger的单元,也是恢复复制的单元
EmbeddedServer:启动bk实例的节点
从现在开始跟踪启动的源码,在客户端执行 bin/bookkeeper autorecovery bookie 后会走到 bookkeeper/bin/bookkeeper 这个脚本下面的这行逻辑
if [ ${COMMAND} == "autorecovery" ]; thenexec "${JAVA}" ${OPTS} ${JMX_ARGS} org.apache.bookkeeper.replication.AutoRecoveryMain --conf ${BOOKIE_CONF} $@
逻辑非常清晰,其实就是通过shell启动AutoRecovery 这样一个独立的Java进程,专门负责做故障数据恢复。JVM会从启动类的main方法进行引导执行,因此咱们接下来从AutoRecoveryMain的main方法作为入口来看看后面会发生哪些事情
public static void main(String[] args) {//调用真正执行的方法,开源项目中真正执行某个操作会以do前缀来进行修饰int retCode = doMain(args);....}static int doMain(String[] args) {ServerConfiguration conf;try {//根据shell启动命令中指定的配置地址加载成配置对象conf = parseArgs(args);} catch (IllegalArgumentException iae) {....}LifecycleComponent server;try {//构建AutoRecoveryServer对象,比较重要的方法server = buildAutoRecoveryServer(new BookieConfiguration(conf));} catch (Exception e) {....}try {//启动AutoRecoveryServer对象ComponentStarter.startComponent(server).get();} catch (InterruptedException ie) {....}return ExitCode.OK;}
通过这里可以发现AutoRecoveryMain的main方法只是做一个引导的动作,最终启动的是AutoRecoveryServer对象。因此让我们深入看看这个服务的构造以及启动的流程
public static LifecycleComponentStack buildAutoRecoveryServer(BookieConfiguration conf) throws Exception {LifecycleComponentStack.Builder serverBuilder = LifecycleComponentStack.newBuilder().withName("autorecovery-server");// 1. 创建StatsProviderService对象,主要用来记录AutoRecovery服务的各项指标状态StatsProviderService statsProviderService = new StatsProviderService(conf);....// 2. 通过构造函数的方式创建AutoRecoveryService对象,这是核心的代码AutoRecoveryService autoRecoveryService = new AutoRecoveryService(conf, rootStatsLogger);....// 3. 创建BKHttpServiceProvider对象,主要用来对外提供http服务,支持通过http方式读取内部状态信息等if (conf.getServerConf().isHttpServerEnabled()) {BKHttpServiceProvider provider = new BKHttpServiceProvider.Builder().setAutoRecovery(autoRecoveryService.getAutoRecoveryServer()).setServerConfiguration(conf.getServerConf()).setStatsProvider(statsProviderService.getStatsProvider()).build();HttpService httpService = new HttpService(provider, conf, rootStatsLogger);....}return serverBuilder.build();}
再看AutoRecoveryService的构造函数
public AutoRecoveryService(BookieConfiguration conf, StatsLogger statsLogger) throws Exception {super(NAME, conf, statsLogger);//通过构造函数创建AutoRecoveryMain,AutoRecoveryMain是AutoRecoveryService的成员变量//进入看看它的实现this.main = new AutoRecoveryMain(conf.getServerConf(),statsLogger);}public AutoRecoveryMain(ServerConfiguration conf, StatsLogger statsLogger)throws IOException, InterruptedException, KeeperException, UnavailableException,CompatibilityException {....//创建AuditorElector对象,负责选举产生Auditor LeaderauditorElector = new AuditorElector(BookieImpl.getBookieId(conf).toString(),conf,bkc,statsLogger.scope(AUDITOR_SCOPE),false);//创建ReplicationWorker对象,负责做数据的拷贝工作replicationWorker = new ReplicationWorker(conf,bkc,false,statsLogger.scope(REPLICATION_WORKER_SCOPE));deathWatcher = new AutoRecoveryDeathWatcher(this);}
服务构造的逻辑差不多就跟到这了,我们知道最终是为了创建AuditorElector和ReplicationWorker这两个对象就够了。服务启动这块从上面的 ComponentStarter.startComponent(server).get(); 进行跟踪
public static CompletableFuture<Void> startComponent(LifecycleComponent component) {....//调用start方法,这里涉及上采用了模版方法设计模式以及闭包,本质上就是就是调用创建的//StatsProviderService、 AutoRecoveryService、HttpService这三个服务的doStart方法component.start();....}protected void doStart() {//还是调的AutoRecoveryMain方法的start方法this.main.start();}public void start() {//启动auditorElector服务auditorElector.start();//启动replicationWorker服务replicationWorker.start();....deathWatcher.start();}
结合上面的可以发现AutoRecovery的启动本质上就是启动AuditorElector和ReplicationWorker这两个服务,因此接下来咱们就来看看这两个服务的start过程,先来看看AuditorElector
public Future<?> start() {running.set(true);//提交选举任务return submitElectionTask();}Future<?> submitElectionTask() {Runnable r = new Runnable() {@Overridepublic void run() {....//创建一个Auditor对象并进行启动auditor = new Auditor(bookieId, conf, bkc, false, statsLogger);auditor.start();}};try {//异步执行以上逻辑return executor.submit(r);} catch (RejectedExecutionException e) {....}}
在这里其实就是对Auditor对象进行初始化以及启动,再进一步跟踪
public Auditor(final String bookieIdentifier,ServerConfiguration conf,BookKeeper bkc,boolean ownBkc,BookKeeperAdmin admin,boolean ownAdmin,StatsLogger statsLogger)throws UnavailableException {....//调用初始化Auditor对象逻辑initialize(conf, bkc);....}private void initialize(ServerConfiguration conf, BookKeeper bkc)throws UnavailableException {try {LedgerManagerFactory ledgerManagerFactory = bkc.getLedgerManagerFactory();ledgerManager = ledgerManagerFactory.newLedgerManager();this.bookieLedgerIndexer = new BookieLedgerIndexer(ledgerManager);this.ledgerUnderreplicationManager = ledgerManagerFactory.newLedgerUnderreplicationManager();....lostBookieRecoveryDelayBeforeChange = this.ledgerUnderreplicationManager.getLostBookieRecoveryDelay();} catch (CompatibilityException ce) {....}}
看完了初始化逻辑,再继续看下Auditor的启动逻辑
public void start() {LOG.info("I'm starting as Auditor Bookie. ID: {}", bookieIdentifier);synchronized (this) {....try {//1. 监听bookie变更事件,本质上就是在zk /ledgers/available 目录下增加watch监听节点的变动//这里还会监听 只读bookie 节点的变动watchBookieChanges();//从zk获取处于可用的bk节点列表knownBookies = getAvailableBookies();} catch (BKException bke) {....}try {//1. 在感知到有bookie节点不可用时回调LostBookieRecoveryDelayChangedCb进行逻辑处理this.ledgerUnderreplicationManager.notifyLostBookieRecoveryDelayChanged(new LostBookieRecoveryDelayChangedCb());} catch (UnavailableException ue) {....}try {//1. 感知到有Ledger的副本少时触发,跟上面一样也是通过回调方式进行处理this.ledgerUnderreplicationManager.notifyUnderReplicationLedgerChanged(new UnderReplicatedLedgersChangedCb());} catch (UnavailableException ue) {....}scheduleBookieCheckTask();//启动一个线程检查Ledger的状态scheduleCheckAllLedgersTask();schedulePlacementPolicyCheckTask();scheduleReplicasCheckTask();}}
这些就是Auditor启动的逻辑,接下来再看看ReplicationWorker的启动逻辑
public void start() {//workerThread实际上就是一个BookieThread对象this.workerThread.start();}public void run() {workerRunning = true;while (workerRunning) {try {//核心逻辑就是循环调用rereplicate方法if (!rereplicate()) {LOG.warn("failed while replicating fragments");waitBackOffTime(rwRereplicateBackoffMs);}} catch (InterruptedException e) {....}}LOG.info("ReplicationWorker exited loop!");}private boolean rereplicate() throws InterruptedException, BKException,UnavailableException {//获取需要做数据恢复的Ledgerlong ledgerIdToReplicate = underreplicationManager.getLedgerToRereplicate();Stopwatch stopwatch = Stopwatch.createStarted();boolean success = false;try {//进行数据恢复success = rereplicate(ledgerIdToReplicate);} finally {....}return success;}
autorecovery工作源码
这块由于逻辑相对较多,因此针对autorecovery工作流程单独开一章。经过上面我们可以清晰的知道在经过启动后都发生了哪些事情,接下来咱们看看autorecovery真正工作的逻辑。在Auditor start的时候,会通过监听zookeeper来感知数据的动态变化
public void start() {//感知bookie节点下线,将这些bookie上管理的Ledger标记为需要备份放到zookeeper上this.ledgerUnderreplicationManager.notifyLostBookieRecoveryDelayChanged(new LostBookieRecoveryDelayChangedCb());//感知Ledger副本变动,统计到指标里this.ledgerUnderreplicationManager.notifyUnderReplicationLedgerChanged(new UnderReplicatedLedgersChangedCb());
}
上述两个唤醒方法主要是通过watch感知zookeeper事件,所以咱们主要看回调类里面的处理逻辑,先看下LostBookieRecoveryDelayChangedCb类
private class LostBookieRecoveryDelayChangedCb implements GenericCallback<Void> {@Overridepublic void operationComplete(int rc, Void result) {....Auditor.this.ledgerUnderreplicationManager.notifyLostBookieRecoveryDelayChanged(LostBookieRecoveryDelayChangedCb.this);....//提交事件变动处理任务,进去看看Auditor.this.submitLostBookieRecoveryDelayChangedEvent();}}synchronized Future<?> submitLostBookieRecoveryDelayChangedEvent() {return executor.submit(() -> {int lostBookieRecoveryDelay = -1;try {waitIfLedgerReplicationDisabled();lostBookieRecoveryDelay = Auditor.this.ledgerUnderreplicationManager.getLostBookieRecoveryDelay();....//核心逻辑,进去看看都做了些什么auditorBookieCheckTask.startAudit(false);} else if (auditTask != null) {LOG.info("lostBookieRecoveryDelay has been set to {}, so rescheduling AuditTask accordingly",lostBookieRecoveryDelay);auditTask = executor.schedule(() -> {auditorBookieCheckTask.startAudit(false);auditTask = null;bookiesToBeAudited.clear();}, lostBookieRecoveryDelay, TimeUnit.SECONDS);auditorStats.getNumBookieAuditsDelayed().inc();}} catch (InterruptedException ie) {....} finally {if (lostBookieRecoveryDelay != -1) {lostBookieRecoveryDelayBeforeChange = lostBookieRecoveryDelay;}}});}void startAudit(boolean shutDownTask) {try {//看起来是开始做Auditor的主要任务了,继续往下auditBookies();shutDownTask = false;} catch (BKException bke) {....}}void auditBookies()throws ReplicationException.BKAuditException, InterruptedException, BKException {....List<String> availableBookies = getAvailableBookies();// find lost bookiesSet<String> knownBookies = ledgerDetails.keySet();//通过之前内存中存的bookie集合减去 zk当前bookie集合即可得出都有哪些bookie节点不可用了Collection<String> lostBookies = CollectionUtils.subtract(knownBookies,availableBookies);....//如果本次变动涉及到bookie节点不可用,则调用handleLostBookiesAsync方法处理不可用的节点if (lostBookies.size() > 0) {try {FutureUtils.result(handleLostBookiesAsync(lostBookies, ledgerDetails), ReplicationException.EXCEPTION_HANDLER);} catch (ReplicationException e) {....}....}....}private CompletableFuture<?> handleLostBookiesAsync(Collection<String> lostBookies,Map<String, Set<Long>> ledgerDetails) {LOG.info("Following are the failed bookies: {},"+ " and searching its ledgers for re-replication", lostBookies);return FutureUtils.processList(Lists.newArrayList(lostBookies),//看方法名大概能猜得出来计算这些bookie上的Ledger,并针对这些Ledger进行数据恢复//由于之前有存节点跟Ledger的映射关系,因此直接通过ledgerDetails映射表来获取这些不可用节点所负责的LedgerbookieIP -> publishSuspectedLedgersAsync(Lists.newArrayList(bookieIP), ledgerDetails.get(bookieIP)),null);}protected CompletableFuture<?> publishSuspectedLedgersAsync(Collection<String> missingBookies, Set<Long> ledgers) {....LongAdder underReplicatedSize = new LongAdder();FutureUtils.processList(Lists.newArrayList(ledgers),ledgerId ->//通过读取这些Ledger的元数据,方便后续的数据恢复动作ledgerManager.readLedgerMetadata(ledgerId).whenComplete((metadata, exception) -> {if (exception == null) {underReplicatedSize.add(metadata.getValue().getLength());}}), null).whenComplete((res, e) -> {....});return FutureUtils.processList(Lists.newArrayList(ledgers),//主流程,继续往下ledgerId -> ledgerUnderreplicationManager.markLedgerUnderreplicatedAsync(ledgerId, missingBookies),null);}public CompletableFuture<Void> markLedgerUnderreplicatedAsync(long ledgerId, Collection<String> missingReplicas) {....final String znode = getUrLedgerZnode(ledgerId);//标记需要做备份的LedgertryMarkLedgerUnderreplicatedAsync(znode, missingReplicas, zkAcls, createFuture);return createFuture;}private void tryMarkLedgerUnderreplicatedAsync(final String znode,final Collection<String> missingReplicas,final List<ACL> zkAcls,final CompletableFuture<Void> finalFuture) {....//将需要做数据恢复的副本进行进行proto编码missingReplicas.forEach(builder::addReplica);....ZkUtils.asyncCreateFullPathOptimistic(zkc, znode, urLedgerData, zkAcls, CreateMode.PERSISTENT,(rc, path, ctx, name) -> {if (Code.OK.intValue() == rc) {FutureUtils.complete(finalFuture, null);} else if (Code.NODEEXISTS.intValue() == rc) {//要在zookeeper将这些Ledger标记为需要做数据恢复handleLedgerUnderreplicatedAlreadyMarked(znode, missingReplicas, zkAcls, finalFuture);} else {FutureUtils.completeExceptionally(finalFuture, KeeperException.create(Code.get(rc)));}}, null);}private void handleLedgerUnderreplicatedAlreadyMarked(final String znode,final Collection<String> missingReplicas,final List<ACL> zkAcls,final CompletableFuture<Void> finalFuture) {// get the existing underreplicated ledger datazkc.getData(znode, false, (getRc, getPath, getCtx, existingUrLedgerData, getStat) -> {if (Code.OK.intValue() == getRc) {// deserialize existing underreplicated ledger datafinal UnderreplicatedLedgerFormat.Builder builder = UnderreplicatedLedgerFormat.newBuilder();try {TextFormat.merge(new String(existingUrLedgerData, UTF_8), builder);} catch (ParseException e) {....}UnderreplicatedLedgerFormat existingUrLedgerFormat = builder.build();boolean replicaAdded = false;for (String missingReplica : missingReplicas) {if (existingUrLedgerFormat.getReplicaList().contains(missingReplica)) {continue;} else {builder.addReplica(missingReplica);replicaAdded = true;}}....//盲猜这里在zk将Ledger标志为需要做数据同步zkc.setData(znode, newUrLedgerData, getStat.getVersion(), (setRc, setPath, setCtx, setStat) -> {if (Code.OK.intValue() == setRc) {FutureUtils.complete(finalFuture, null);} else if (Code.NONODE.intValue() == setRc) {tryMarkLedgerUnderreplicatedAsync(znode, missingReplicas, zkAcls, finalFuture);} else if (Code.BADVERSION.intValue() == setRc) {handleLedgerUnderreplicatedAlreadyMarked(znode, missingReplicas, zkAcls, finalFuture);} else {FutureUtils.completeExceptionally(finalFuture, KeeperException.create(Code.get(setRc)));}}, null);} else if (Code.NONODE.intValue() == getRc) {tryMarkLedgerUnderreplicatedAsync(znode, missingReplicas, zkAcls, finalFuture);} else {FutureUtils.completeExceptionally(finalFuture, KeeperException.create(Code.get(getRc)));}}, null);}
从ReplicationWorker的rereplicate方法开始就是真正做数据恢复的过程
private boolean rereplicate(long ledgerIdToReplicate) throws InterruptedException, BKException,UnavailableException {....//获取需要做数据恢复的Ledger的处理对象LedgerHandle try (LedgerHandle lh = admin.openLedgerNoRecovery(ledgerIdToReplicate)) {//通过对Ledger进行分解成更小数据恢复单位LedgerFragment,后续分别对LedgerFragment进行数据恢复Set<LedgerFragment> fragments = getUnderreplicatedFragments(lh,conf.getAuditorLedgerVerificationPercentage());....for (LedgerFragment ledgerFragment : fragments) {....try {//对LedgerFragment进行数据恢复admin.replicateLedgerFragment(lh, ledgerFragment, onReadEntryFailureCallback);numFragsReplicated++;if (ledgerFragment.getReplicateType() == LedgerFragment.ReplicateType.DATA_NOT_ADHERING_PLACEMENT) {numNotAdheringPlacementFragsReplicated++;}} catch (BKException.BKBookieHandleNotAvailableException e) {....}}....fragments = getUnderreplicatedFragments(lh, conf.getAuditorLedgerVerificationPercentage());....} catch (BKNoSuchLedgerExistsOnMetadataServerException e) {....} finally {....}}
继续进一步看admin.replicateLedgerFragment的实现
public void replicateLedgerFragment(LedgerHandle lh, final LedgerFragment ledgerFragment,final BiConsumer<Long, Long> onReadEntryFailureCallback) throws InterruptedException, BKException {....//继续往下跟踪replicateLedgerFragment(lh, ledgerFragment, targetBookieAddresses, onReadEntryFailureCallback);}private void replicateLedgerFragment(LedgerHandle lh,final LedgerFragment ledgerFragment,final Map<Integer, BookieId> targetBookieAddresses,final BiConsumer<Long, Long> onReadEntryFailureCallback)throws InterruptedException, BKException {....//在这里看到这个恢复其实是异步处理的过程,继续往下asyncRecoverLedgerFragment(lh, ledgerFragment, cb, targetBookieSet, onReadEntryFailureCallback);....}private void asyncRecoverLedgerFragment(final LedgerHandle lh,final LedgerFragment ledgerFragment,final AsyncCallback.VoidCallback ledgerFragmentMcb,final Set<BookieId> newBookies,final BiConsumer<Long, Long> onReadEntryFailureCallback) throws InterruptedException {//发现会调用LedgerFragmentReplicator对象进行数据恢复,继续往下lfr.replicate(lh, ledgerFragment, ledgerFragmentMcb, newBookies, onReadEntryFailureCallback);}void replicate(final LedgerHandle lh, final LedgerFragment lf,final AsyncCallback.VoidCallback ledgerFragmentMcb,final Set<BookieId> targetBookieAddresses,final BiConsumer<Long, Long> onReadEntryFailureCallback)throws InterruptedException {Set<LedgerFragment> partionedFragments = splitIntoSubFragments(lh, lf,bkc.getConf().getRereplicationEntryBatchSize());....//继续往下看实现replicateNextBatch(lh, partionedFragments.iterator(),ledgerFragmentMcb, targetBookieAddresses, onReadEntryFailureCallback);}private void replicateNextBatch(final LedgerHandle lh,final Iterator<LedgerFragment> fragments,final AsyncCallback.VoidCallback ledgerFragmentMcb,final Set<BookieId> targetBookieAddresses,final BiConsumer<Long, Long> onReadEntryFailureCallback) {if (fragments.hasNext()) {try {//来了,一般有Internal的地方都会有实现的干货,继续进去replicateFragmentInternal(lh, fragments.next(),new AsyncCallback.VoidCallback() {@Overridepublic void processResult(int rc, String v, Object ctx) {if (rc != BKException.Code.OK) {ledgerFragmentMcb.processResult(rc, null,null);} else {replicateNextBatch(lh, fragments,ledgerFragmentMcb,targetBookieAddresses,onReadEntryFailureCallback);}}}, targetBookieAddresses, onReadEntryFailureCallback);} catch (InterruptedException e) {.....}} else {ledgerFragmentMcb.processResult(BKException.Code.OK, null, null);}}private void replicateFragmentInternal(final LedgerHandle lh,final LedgerFragment lf,final AsyncCallback.VoidCallback ledgerFragmentMcb,final Set<BookieId> newBookies,final BiConsumer<Long, Long> onReadEntryFailureCallback) throws InterruptedException {....//针对每个Entry对象循环做数据恢复,Entry是BK里最小的数据单元for (final Long entryId : entriesToReplicate) {recoverLedgerFragmentEntry(entryId, lh, ledgerFragmentEntryMcb,newBookies, onReadEntryFailureCallback);}}private void recoverLedgerFragmentEntry(final Long entryId,final LedgerHandle lh,final AsyncCallback.VoidCallback ledgerFragmentEntryMcb,final Set<BookieId> newBookies,final BiConsumer<Long, Long> onReadEntryFailureCallback) throws InterruptedException {....long startReadEntryTime = MathUtils.nowInNano();/** Read the ledger entry using the LedgerHandle. This will allow us to* read the entry from one of the other replicated bookies other than* the dead one.*///到了真正读取Entry的逻辑,继续往下lh.asyncReadEntries(entryId, entryId, new ReadCallback() {....}}, null);}public void asyncReadEntries(long firstEntry, long lastEntry, ReadCallback cb, Object ctx) {....//调用异步读取逻辑asyncReadEntriesInternal(firstEntry, lastEntry, cb, ctx, false);}void asyncReadEntriesInternal(long firstEntry, long lastEntry, ReadCallback cb,Object ctx, boolean isRecoveryRead) {if (!clientCtx.isClientClosed()) {//继续往下跟踪readEntriesInternalAsync(firstEntry, lastEntry, isRecoveryRead).whenCompleteAsync(new FutureEventListener<LedgerEntries>() {....}, clientCtx.getMainWorkerPool().chooseThread(ledgerId));} else {cb.readComplete(Code.ClientClosedException, LedgerHandle.this, null, ctx);}}CompletableFuture<LedgerEntries> readEntriesInternalAsync(long firstEntry,long lastEntry,boolean isRecoveryRead) {//构造读数据的对象PendingReadOp op = new PendingReadOp(this, clientCtx,firstEntry, lastEntry, isRecoveryRead);//运行起来,跟进去瞅瞅op.run();return op.future();}public void run() {//无他,继续往下initiate();}void initiate() {....do {//决定是串行读取数据还是并行读取数据if (parallelRead) {entry = new ParallelReadRequest(ensemble, lh.ledgerId, i);} else {entry = new SequenceReadRequest(ensemble, lh.ledgerId, i);}seq.add(entry);i++;} while (i <= endEntryId);// read the entries.for (LedgerEntryRequest entry : seq) {//核心逻辑,这里进行数据读取操作entry.read();}}void read() {//继续往下看sendNextRead();}synchronized BookieId sendNextRead() {....try {BookieId to = ensemble.get(bookieIndex);//发送读取请求的操作sendReadTo(bookieIndex, to, this);....} catch (InterruptedException ie) {....}}void sendReadTo(int bookieIndex, BookieId to, LedgerEntryRequest entry) throws InterruptedException if (isRecoveryRead) {....} else {//调用BK客户端进行数据的读取clientCtx.getBookieClient().readEntry(to, lh.ledgerId, entry.eId,this, new ReadContext(bookieIndex, to, entry), BookieProtocol.FLAG_NONE);}}default void readEntry(BookieId address, long ledgerId, long entryId,ReadEntryCallback cb, Object ctx, int flags) {//继续往下readEntry(address, ledgerId, entryId, cb, ctx, flags, null);}default void readEntry(BookieId address, long ledgerId, long entryId,ReadEntryCallback cb, Object ctx, int flags, byte[] masterKey) {//继续往下readEntry(address, ledgerId, entryId, cb, ctx, flags, masterKey, false);}public void readEntry(final BookieId addr, final long ledgerId, final long entryId,final ReadEntryCallback cb, final Object ctx, int flags, byte[] masterKey,final boolean allowFastFail) {//获取要访问的客户端对象final PerChannelBookieClientPool client = lookupClient(addr);....client.obtain((rc, pcbc) -> {if (rc != BKException.Code.OK) {completeRead(rc, ledgerId, entryId, null, cb, ctx);} else {//调用读取逻辑pcbc.readEntry(ledgerId, entryId, cb, ctx, flags, masterKey, allowFastFail);}}, ledgerId);}public void readEntry(final long ledgerId,final long entryId,ReadEntryCallback cb,Object ctx,int flags,byte[] masterKey,boolean allowFastFail) {//看到Internal就知道要有东西了,继续往下readEntryInternal(ledgerId, entryId, null, null, false,cb, ctx, (short) flags, masterKey, allowFastFail);}private void readEntryInternal(final long ledgerId,final long entryId,final Long previousLAC,final Long timeOutInMillis,final boolean piggyBackEntry,final ReadEntryCallback cb,final Object ctx,int flags,byte[] masterKey,boolean allowFastFail) {....//构造请求对象ReadRequest.Builder readBuilder = ReadRequest.newBuilder().setLedgerId(ledgerId).setEntryId(entryId);....request = withRequestContext(Request.newBuilder()).setHeader(headerBuilder).setReadRequest(readBuilder).build();....//继续往下writeAndFlush(channel, completionKey, request, allowFastFail);}private void writeAndFlush(final Channel channel,final CompletionKey key,final Object request,final boolean allowFastFail) {....try {....//跟到这里就知道最终调用了Netty的客户端来发起请求channel.writeAndFlush(request, promise);} catch (Throwable e) {....}}
到这里数据就发出去了,我们也能知道AutoRecovery进程是通过Netty向BK的服务端进行数据读取,那么服务端在接收到请求后又是怎么处理的呢,这里咱们从服务端接收请求的逻辑开始跟,由于BK本身也是通过Netty实例进行网络请求处理的,因此可以轻松找到BookieRequestHandler的channelRead方法监听外部网络请求
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {....//职责分离做得很好,BookieRequestHandler只负责接收请求,逻辑处理相关的全权交给requestProcessor对象requestProcessor.processRequest(msg, this);}public void processRequest(Object msg, BookieRequestHandler requestHandler) {Channel channel = requestHandler.ctx().channel();if (msg instanceof BookkeeperProtocol.Request) {BookkeeperProtocol.Request r = (BookkeeperProtocol.Request) msg;restoreMdcContextFromRequest(r);try {BookkeeperProtocol.BKPacketHeader header = r.getHeader();//非常好的一种设计,kafka的KafkaApis类里也是这样设计,服务端支持的操作在这里就能很清晰的看到switch (header.getOperation()) {case ADD_ENTRY:processAddRequestV3(r, requestHandler);break;case READ_ENTRY://在这里可以处理的读取请求,从这里进去看看processReadRequestV3(r, requestHandler);break;case FORCE_LEDGER:processForceLedgerRequestV3(r, requestHandler);break;....case WRITE_LAC:processWriteLacRequestV3(r, requestHandler);break;case READ_LAC:processReadLacRequestV3(r, requestHandler);break;case GET_BOOKIE_INFO:processGetBookieInfoRequestV3(r, requestHandler);break;case START_TLS:processStartTLSRequestV3(r, requestHandler);break;case GET_LIST_OF_ENTRIES_OF_LEDGER:processGetListOfEntriesOfLedgerProcessorV3(r, requestHandler);break;default:....break;}} finally {MDC.clear();}} else {....}}private void processReadRequestV3(final BookkeeperProtocol.Request r, final BookieRequestHandler requestHandler) {//能看到BK也同时支持长轮询的方式读取数据if (RequestUtils.isLongPollReadRequest(r.getReadRequest())) {....read = new LongPollReadEntryProcessorV3(r, requestHandler, this, fenceThread,lpThread, requestTimer);} else {read = new ReadEntryProcessorV3(r, requestHandler, this, fenceThread);....}if (null == threadPool) {//跟进去看看实现read.run();} else {....}}public void run() {....//执行读取操作executeOp();}protected void executeOp() {//这里感觉设计得不是很清晰,应该先读取数据出来再构造返回对象的,你们觉得呢?ReadResponse readResponse = getReadResponse();if (null != readResponse) {sendResponse(readResponse);}}protected ReadResponse getReadResponse() {// 读取Entry数据的地方,在此处深入探索下return readEntry(readResponse, entryId, startTimeSw);} catch (Bookie.NoLedgerException e) {....}}protected ReadResponse readEntry(ReadResponse.Builder readResponseBuilder,long entryId,Stopwatch startTimeSw)throws IOException, BookieException {//继续深入return readEntry(readResponseBuilder, entryId, false, startTimeSw);}protected ReadResponse readEntry(ReadResponse.Builder readResponseBuilder,long entryId,boolean readLACPiggyBack,Stopwatch startTimeSw)throws IOException, BookieException {//调用Bookie的readEntry来读取数据ByteBuf entryBody = requestProcessor.getBookie().readEntry(ledgerId, entryId);....}public ByteBuf readEntry(long ledgerId, long entryId)throws IOException, NoLedgerException, BookieException {....try {LedgerDescriptor handle = handles.getReadOnlyHandle(ledgerId);....//调用真正读数据的逻辑,因为在这里能看到获取的值entry也是对外返回的//这里调用的是LedgerDescriptor类的readEntry方法ByteBuf entry = handle.readEntry(entryId);....return entry;} finally {....}}ByteBuf readEntry(long entryId) throws IOException, BookieException {//调用LedgerStorage接口,SingleDirectoryDbLedgerStorage实现类来读取Entryreturn ledgerStorage.getEntry(ledgerId, entryId);}public ByteBuf getEntry(long ledgerId, long entryId) throws IOException, BookieException {long startTime = MathUtils.nowInNano();try {//继续往下跟踪ByteBuf entry = doGetEntry(ledgerId, entryId);recordSuccessfulEvent(dbLedgerStorageStats.getReadEntryStats(), startTime);return entry;} catch (IOException e) {....}}private ByteBuf doGetEntry(long ledgerId, long entryId) throws IOException, BookieException {....//尝试从BK本地缓存中读取数据ByteBuf entry = localWriteCache.get(ledgerId, entryId);//尝试从本地缓存flush中进行数据命中数据entry = localWriteCacheBeingFlushed.get(ledgerId, entryId);// 尝试从读缓存中进行数据读取entry = readCache.get(ledgerId, entryId);//从磁盘文件中进行数据读取, 调用的是EntryLogger接口,DefaultEntryLogger对象的readEntry方法entry = entryLogger.readEntry(ledgerId, entryId, entryLocation);//写到读缓存中readCache.put(ledgerId, entryId, entry);....return entry;}public ByteBuf readEntry(long ledgerId, long entryId, long entryLocation)throws IOException, Bookie.NoEntryException {//再进一步探索return internalReadEntry(ledgerId, entryId, entryLocation, true /* validateEntry */);}private ByteBuf internalReadEntry(long ledgerId, long entryId, long location, boolean validateEntry)throws IOException, Bookie.NoEntryException {//获取entry所在的LogIdlong entryLogId = logIdForOffset(location);long pos = posForOffset(location);BufferedReadChannel fc = null;int entrySize = -1;try {fc = getFCForEntryInternal(ledgerId, entryId, entryLogId, pos);ByteBuf sizeBuff = readEntrySize(ledgerId, entryId, entryLogId, pos, fc);entrySize = sizeBuff.getInt(0);if (validateEntry) {validateEntry(ledgerId, entryId, entryLogId, pos, sizeBuff);}} catch (EntryLookupException e) {....}ByteBuf data = allocator.buffer(entrySize, entrySize);//进行数据读取int rc = readFromLogChannel(entryLogId, fc, data, pos);....data.writerIndex(entrySize);return data;}private int readFromLogChannel(long entryLogId, BufferedReadChannel channel, ByteBuf buff, long pos)throws IOException {BufferedLogChannel bc = entryLogManager.getCurrentLogIfPresent(entryLogId);....//继续往下return channel.read(buff, pos);}public int read(ByteBuf dest, long pos) throws IOException {//继续往下return read(dest, pos, dest.writableBytes());}public synchronized int read(ByteBuf dest, long pos, int length) throws IOException {....while (length > 0) {// Check if the data is in the buffer, if so, copy it.if (readBufferStartPosition <= currentPosition&& currentPosition < readBufferStartPosition + readBuffer.readableBytes()) {int posInBuffer = (int) (currentPosition - readBufferStartPosition);int bytesToCopy = Math.min(length, readBuffer.readableBytes() - posInBuffer);dest.writeBytes(readBuffer, posInBuffer, bytesToCopy);currentPosition += bytesToCopy;length -= bytesToCopy;cacheHitCount++;} else {// We don't have it in the buffer, so put necessary data in the bufferreadBufferStartPosition = currentPosition;int readBytes = 0;//从磁盘读取数据到readBuffer中,再将readBuffer的数据写到 dest中作为返回值//这里调用的是Java NIO FileChannel类的read方法来从磁盘进行数据的读取if ((readBytes = validateAndGetFileChannel().read(readBuffer.internalNioBuffer(0, readCapacity),currentPosition)) <= 0) {throw new IOException("Reading from filechannel returned a non-positive value. Short read.");}readBuffer.writerIndex(readBytes);}}return (int) (currentPosition - pos);}总结
在这里解答下引言小故事
-
张三是通过什么规则被选成“监督者”的?
张三是通过zookeeper的Paxos算法选举产生的
-
如果张三也不辞而别呢?
大狗和二狗也会通过zookeeper监听张三的状态,如果张三不辞而别的话,大狗二狗会通过zookeeper选举成为新的“监督者”
-
为啥要通过签到本的方式,而不是张三直接去挨个挨个看?
通过签到本的方式比较节约张三的时间,否则当员工比较多的时候并且对感知时间比较快的时候,张三就要每隔几分钟就要跑去挨个挨个看,这样没多久张三也要“不辞而别”了。通过签到本如果某个同事不签到了张三就能很轻松感知到并做相对应的处理了
参考资料
- https://bookkeeper.apache.org/docs/admin/autorecovery/
- bk项目 site3/website/docs/admin/* 指令使用说明
相关文章:
详解bookkeeper AutoRecovery机制
引言小故事 张三在一家小型互联网公司上班,由于公司实行的996,因此经常有同事“不辞而别”,为了工作的正常推进,团队内达成了某种默契,这种默契就是通过某个规则来选出一个同事,这个同事除了工作之余还有额…...

使用 Ubuntu 20.04 进行初始服务器设置
前些天发现了一个人工智能学习网站,通俗易懂,风趣幽默,最重要的屌图甚多,忍不住分享一下给大家。点击跳转到网站。 使用 Ubuntu 20.04 进行初始服务器设置 介绍 首次创建新的 Ubuntu 20.04 服务器时,应该执行一些重…...

【SpringCloud】6、Spring Cloud Gateway路由配置
在 Spring Cloud Gateway 中配置 uri 有三种方式,包括: 1、WebSocket路由 spring:cloud:gateway:routes:- id: bt-apiuri: ws://localhost:9090/predicates:...

pdf转换成word怎么转?一篇文章教你轻松搞定
pdf转换成word怎么转?你是否曾经遇到过需要将PDF文件转换成Word格式的情况?比如,你需要编辑一个文档,或者想将一些电子书或报告复制到Word中以便于编辑或重新排版。在这种情况下,如何将PDF文件转换成Word格式呢&#x…...
【中南林业科技大学】计算机组成原理复习包括题目讲解(超详细)
来都来了点个赞收藏关注一下再走呗🌹🌹🌹🌹 第1章:绪论 1.冯诺依曼机特点,与现代计算机的区别 冯诺依曼计算机的基本思想是:程序和数据以二进制形式表示,存储程序控制。在计算机中&…...

恭喜 Databend 上榜 2023 开源创新榜「优秀开源项目 」
近日,国家科技传播中心见证了一场开源界的重要事件:由中国科协科学技术传播中心、中国计算机学会、中国通信学会和中国科学院软件研究所联合主办,CSDN 承办的 2023 年开源创新榜专家评审会圆满落幕。由王怀民院士担任评委会主任,评…...

网络连通性批量检测工具
一、背景介绍 企业网络安全防护中,都会要求配置物理网络防火墙以及主机防火墙,加强对网络安全的防护。云改数转之际,多系统上云过程中都会申请开通大量各类网络配置,针对这些复杂且庞大的网络策略开通配置,那么在网络配…...
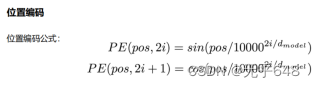
2023高级人工智能期末总结
1、人工智能概念的一般描述 人工智能是那些与人的思维相关的活动,诸如决策、问题求解和学习等的自动化; 人工智能是一种计算机能够思维,使机器具有智力的激动人心的新尝试; 人工智能是研究如何让计算机做现阶段只有人才能做得好的…...

Oracle数据库迁移所有文件到新挂载磁盘路径
主要步骤: 1、停掉服务, 2、关闭数据库shutdown immediate 3、移动数据文件到新的位置。 4、启动到mount状态,如果也移动了ctl,需要启动到nomount下,生成参数文件。 5、alter database rename 文件名 to 新位置&a…...

基于YOLOv7算法的高精度实时安全背心目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时安全背心目标检测系统可用于日常生活中检测与定位安全背心,此系统可完成对输入图片、视频、文件夹以及摄像头方式的目标检测与识别,同时本系统还支持检测结果可视化与导出。本系统采用YOLOv7目标检测算法来训…...
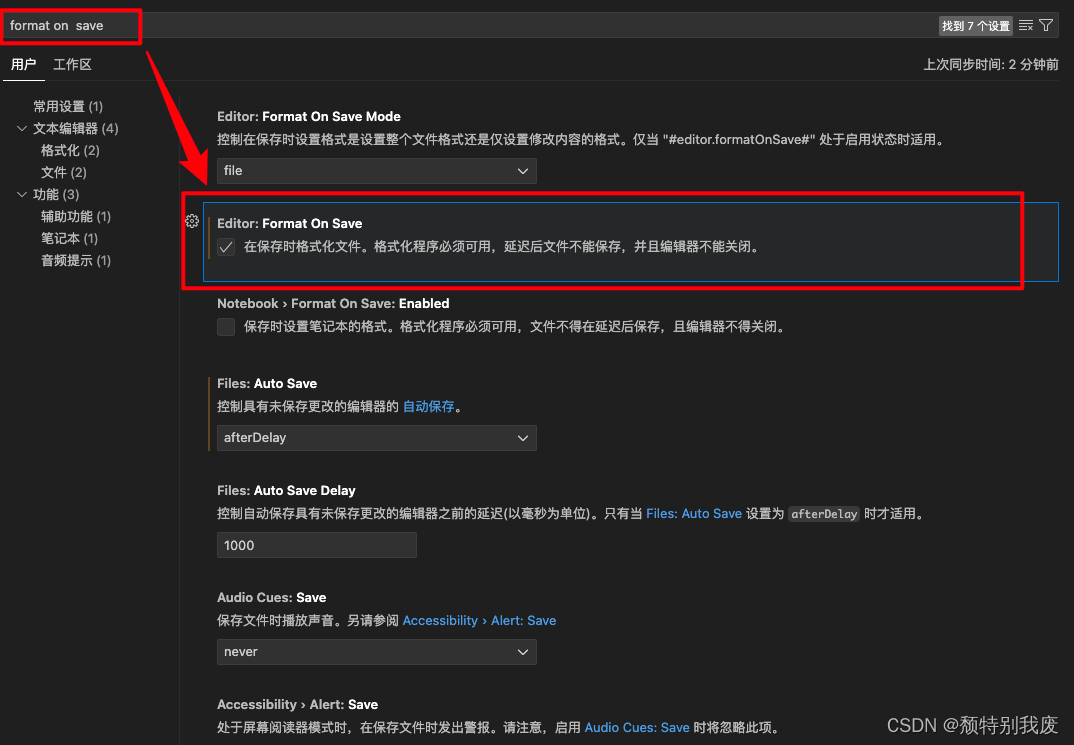
Mac——VsCode使用格式化工具进行整理和格式化
1. 打开VSCode编辑器。 2. 点击左下角⚙️图标,打开设置 3. 进入设置后,你会看到一个搜索框,在搜索框中输入 format on save 来查找相关设置项。 4. 在设置列表中找到 Editor: Format On Save 选项,勾选它以启用在保存文件时自动格…...
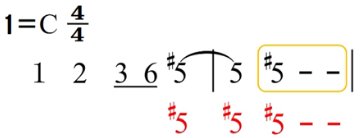
73.乐理基础-打拍子-还原号、临时变音记号在简谱中的规则
上一个内容:72.乐理基础-打拍子-加延音线的节奏型-CSDN博客 下图中1-13,就是四几拍中所有可能出现的节奏型,以及它们的组合方式,需要练习,可以买一本视唱书去练习,搜乐谱练习,自己写节奏型根据…...

一款超酷的一体化网站测试工具:Web-Check
Web-Check 是一款功能强大的一体化工具,用于发现网站/主机的相关信息。用于检查网页的工具,用于确保网页的正确性和可访问性。它可以帮助开发人员和网站管理员检测网页中的错误和问题,并提供修复建议。 它只需要输入一个网站就可以查看一个网…...

MockServer简单使用记录
下载源码 下载git源码:git clone https://github.com/mock-server/mockserver.git 通过执行文件编译成jar包 ./mvnw clean package 可能会报错。 启动命令 java -jar ./mockserver-netty-jar-with-dependencies.jar -serverPort 1080 -proxyRemotePort 80 -pro…...

AI+金融:大模型引爆金融科技革命
仅供机构投资者使用 证券研究报告|行业深度研究报告 AI金融:大模型引爆金融科技革命 “AI应用”系列(二) 华西计算机团队 2023年7月28日 分析师:刘泽晶 联系人:刘波 SAC NO:S1120520020002 邮箱:…...
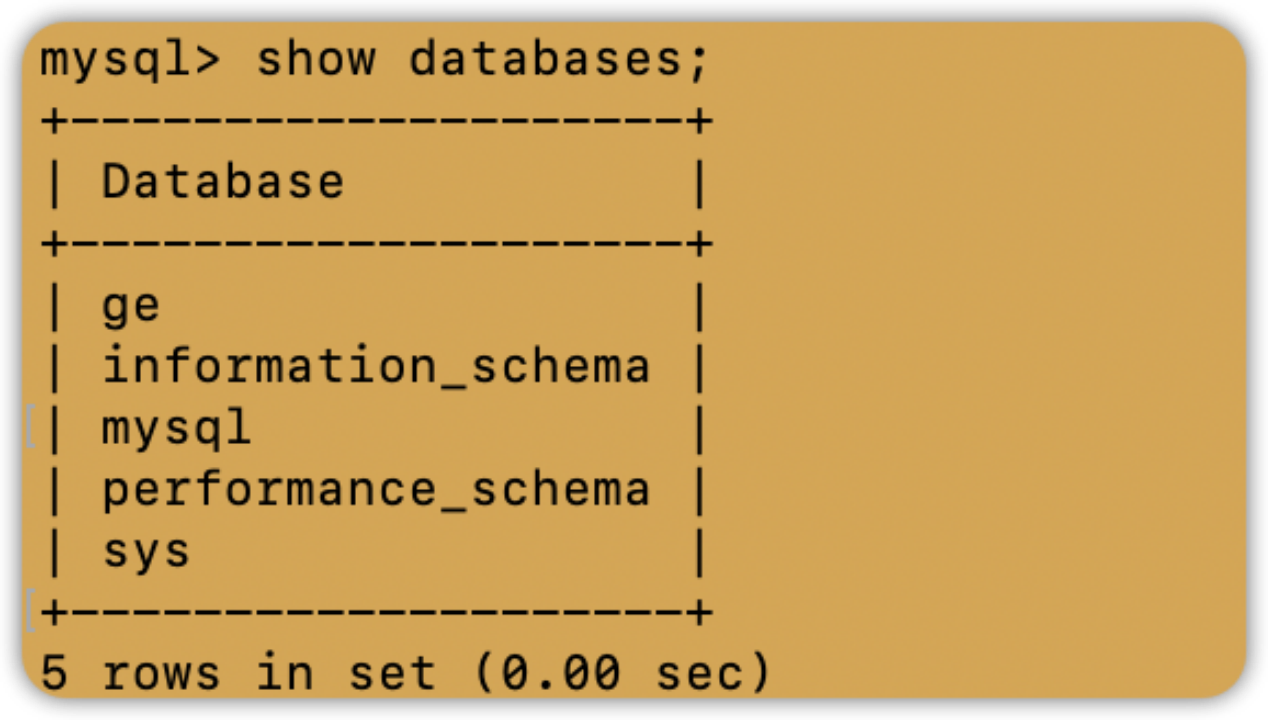
数据库(二)实验一:MySQL数据库的C/S模式部署
实验要求 在云服务器上启动两个实例Server和Client,并实现两个实例之间的免密ssh登录。在Server和Client上分别安装MySQL,在Server上创建数据库和用户,在Client上远程连接Server的数据库。 实验内容 创建两个云服务器实例 在腾讯云购买两个…...
)
RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat)
原文:RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat) - 知乎 目录 收起 一、RLHF的作用 二、实践效果 三、怎么做 1、框架 2、算法 3、数据 4、调参 一、RLHF的作用 从InstructGPT的论文中看,RLHF目的…...

Oracle/Myql批量操作
前言:在oracle中使用insert into values (),(),()多种方式都不能成功,记录正确的批量方法 注意:oracle有自己实现批量的方法,mysql适用的,oracle不一定适用 <insert id"insertTaskImportOpen" parameterType"l…...

关于一个web站点的欢迎页面
- 什么是一个web站点的欢迎页面? - 对于一个webapp来说,我们是可以设置它的欢迎页面的。 - 设置了欢迎页面之后,当你访问这个webapp的时候,或者访问这个web站点的时候,没有指定任何“资源路径”,这个时候…...
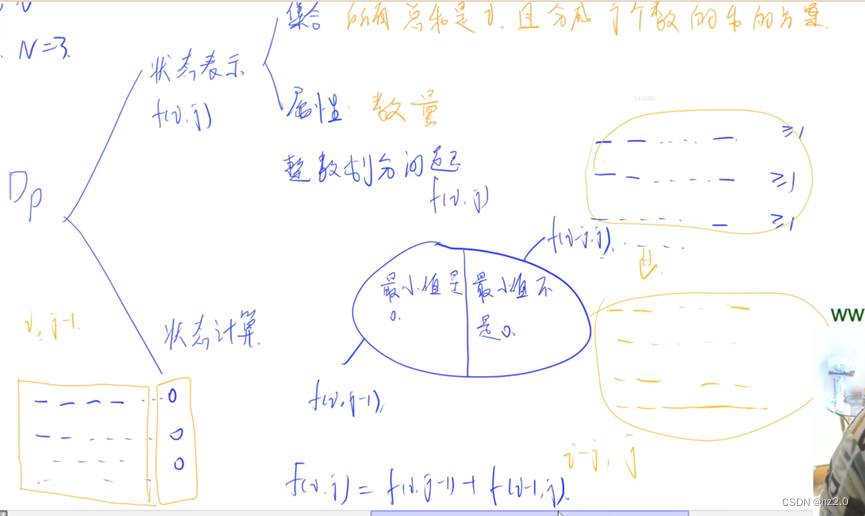
1050. 鸣人的影分身(dp划分)
题目: 1050. 鸣人的影分身 - AcWing题库 输入样例: 1 7 3输出样例: 8 思路: 代码: #include<iostream> using namespace std; const int N20; int f[N][N]; int main() {int T,m,n;cin>>T;while(T--)…...

AI赋能医院物流:基于PDCA循环的智能供应链韧性提升实践
1. 项目概述:当医院物流遇上AI与PDCA医院物流,听起来可能有点“幕后”,但它绝对是现代医疗体系顺畅运转的“大动脉”。从高值耗材、药品、检验试剂,到被服布草、医疗废物,甚至是一日三餐,这条链条上任何一个…...

2026年度能耗监测系统的深度分析与展望
在当前全球可持续发展的大背景下,能耗监测系统的重要性愈发凸显。随着技术的进步和社会对节能减排的需求,2026年度的能耗监测系统将迎来一场技术革命和应用升级。本文将从市场需求、技术现状、未来发展方向及实施策略等多个方面,对2026能耗监…...
)
专利技术复杂性地级市面板(2001-2025)
核心速览数据编号:2323时间跨度:2001–2025空间尺度:中国全部地级市数据格式:Excel 年度面板测算依据:Research Policy 2026 顶刊范式(Frigon)测算方法(可直接写论文)以I…...
)
告别手动复制粘贴!用Python-pptx库5分钟搞定PPT批量生成(附完整代码)
职场效率革命:Python-pptx全自动PPT生成实战指南 每次月度汇报前夜,市场部的张伟总要面对几十页PPT的复制粘贴地狱——从Excel拉数据、调整格式、核对图表,最后发现领导临时改了需求又得重来。这种场景在数据驱动型岗位中已成常态,…...

Loop习惯追踪:从零开始构建你的长期习惯养成系统
Loop习惯追踪:从零开始构建你的长期习惯养成系统 【免费下载链接】uhabits Loop Habit Tracker, a mobile app for creating and maintaining long-term positive habits 项目地址: https://gitcode.com/gh_mirrors/uh/uhabits 你是否曾下定决心培养一个好习…...

veil:专为AI智能体设计的无头浏览器自动化工具
1. 项目概述:为AI智能体打造的“隐形之手”如果你正在构建或使用AI智能体,并且希望它能像真人一样操作浏览器——登录社交平台、发布内容、浏览网页、点击按钮——那么你很可能已经感受到了传统自动化工具的掣肘。Selenium、Puppeteer这些工具很棒&#…...

信息学奥赛经典回溯:八皇后问题深度解析与OpenJudge实战
1. 八皇后问题:从棋盘游戏到算法经典 第一次接触八皇后问题时,我正在准备信息学奥赛的选拔考试。当时觉得这不过是个棋盘游戏,直到真正动手编码时,才发现其中蕴含的算法智慧远比想象中丰富。这个问题要求在一个8x8的国际象棋棋盘上…...

三步实现iOS虚拟定位:无需越狱的终极免费方案
三步实现iOS虚拟定位:无需越狱的终极免费方案 【免费下载链接】iFakeLocation Simulate locations on iOS devices on Windows, Mac and Ubuntu. 项目地址: https://gitcode.com/gh_mirrors/if/iFakeLocation iFakeLocation是一个专业级的iOS虚拟定位工具&am…...

地理空间AI基准测试平台geobench:标准化评估与实战指南
1. 项目概述:一个为地理空间AI量身定制的基准测试平台如果你正在或即将踏入地理空间人工智能这个领域,无论是想评估一个预训练模型在遥感影像上的表现,还是想为自己的新算法找一个公平、全面的“擂台”,你大概率会遇到一个头疼的问…...

开源量化分析平台Fin-Maestro:十大核心模块构建个人交易决策系统
1. 项目概述:一个为独立交易者打造的量化分析工具箱 如果你和我一样,在股票和加密货币市场里摸爬滚打了好些年,那你一定经历过这样的阶段:面对海量的K线图、财务数据和市场新闻,感觉信息过载,决策时总是犹…...