RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat)
原文:RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat) - 知乎
目录
收起
一、RLHF的作用
二、实践效果
三、怎么做
1、框架
2、算法
3、数据
4、调参
一、RLHF的作用
从InstructGPT的论文中看,RLHF目的就是为了让模型输出的结果能和人类对齐。而所谓对齐,体现在三点:
- 有用:即遵守指令的能力
- 诚实:不容易胡说八道
- 安全:不容易生成不合法的、有害、有毒的信息
RLHF在这篇论文中,我们都知道分为三个步骤,包括SFT(微调模型)、RM(训练回报模型或者叫偏好模型)、RL(强化学习)。那么只靠SFT能做到对齐这件事吗?应该可以做到一部分,现在网上大多数流行的开源模型基本上也止步到SFT这个步骤。其实SFT其实也展现出了很不错的性能,但是从实践上看,例如moss要做到和人类比较好的对齐,光微调的数据就达到100w的级别,这个级别的高质量数据收集起来代价还是比较高的,而后面RL的步骤,从实践结果来看,它能够用少量的数据让模型在对齐上的效果和泛化性达到一个新的高度。
从这个文章Awesome 论文合集 |不看这些论文,你都不知道 RLHF 是如此的神奇 (4) - OpenDILab浦策的文章 - 知乎 Awesome 论文合集 |不看这些论文,你都不知道 RLHF 是如此的神奇 (4) - 知乎看,RLHF有这三个优点:
- 建立优化范式:为无法显式定义奖励函数的决策任务,建立新的优化范式。对于需要人类偏好指引的机器学习任务,探索出一条可行且较高效的交互式训练学习方案。
- 省数据(Data-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 能够利用更少的人类反馈数据达到相近的训练效果。
- 省参数(Parameter-Efficient):相对其他的训练方法,例如监督学习,Top-K 采样等,RLHF 可以让参数量较小的神经网络也能发挥出强大的性能。
从符尧大神的文章Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.里可以看出RLHF的效果如下:
- 翔实的回应: text-davinci-003 的生成通常比 text-davinci-002长。 ChatGPT 的回应则更加冗长,以至于用户必须明确要求“用一句话回答我”,才能得到更加简洁的回答。这是 RLHF 的直接产物。
- **公正的回应:**ChatGPT 通常对涉及多个实体利益的事件(例如政治事件)给出非常平衡的回答。这也是RLHF的产物。
- **拒绝不当问题:**这是内容过滤器和由 RLHF 触发的模型自身能力的结合,过滤器过滤掉一部分,然后模型再拒绝一部分。
- **拒绝其知识范围之外的问题:**例如,拒绝在2021 年 6 月之后发生的新事件(因为它没在这之后的数据上训练过)。这是 RLHF 最神奇的部分,因为它使模型能够隐式地区分哪些问题在其知识范围内,哪些问题不在其知识范围内。
二、实践效果
我们的中文实验大多是基于GLM10B的huggingface版本进行的。SFT和大多网上的策略是一样的,使用开源的指令数据集,和一些ChatgptAPI生成的数据集训练。目前网上没有像英文领域有那么多公开的偏好数据集,早期我们直接用翻译接口翻译了HH-RLHF数据集,然后训练了一个回报模型。之后在一些中文的多轮对话上做强化学习,这样粗糙的RLHF,已经可以得到一个能够生成翔实的回应的PPO模型了。但是,也只是变得翔实而已,遵守指令的能力甚至变弱了,也没有丝毫安全性的提升(因为完全没相关数据)。
后来在清华开源的安全数据集上,经过一些精挑细选,分布到RM和PPO中,模型就可以保持翔实的前提下提高安全性,但是指令的遵循能力还很弱。但是这里也证明了一点,只要数据分布合理,RM和PPO就能让模型得到相关能力的提升。所以要得到一个对指令有广泛理解,答案翔实,安全且诚实,对于RM数据集的要求还是蛮高的,同时PPO应该也有相同的分布。
我们使用的RM的数据集和PPO数据集都没有达到1w级别,这也证实了强化学习算法的泛化性确实很强。
三、怎么做
1、框架
现在RLHF相关的框架非常多,基本上每周都有新的开源框架出现。选择一个合适的框架,一个是方便我们写代码,一个是能够节省更多显存。我们学习使用的框架有DeepspeedChat、Trlx、ColossalAI-Chat,同时也包括一些常用的框架例如Accelerate、PEFT等。每个框架都有自己的优缺点,这里大概说一下:
Trlx:GitHub - CarperAI/trlx: A repo for distributed training of language models with Reinforcement Learning via Human Feedback (RLHF)
优势:应该是目前网上大家提到的,使用最广泛的LLM的强化学习框架了。这个框架里面的算法基本是参考了OpenAI当年LM强化学习开源代码的实现,在此基础上,增加了Accelerate框架的调用支持,还有对各种常见的LM的封装,主要是添加了ValueFunction的head,还有一些冻结参数的支持。
不足:代码逻辑比起其他框架来说,有些凌乱,新手看起来不太友好。我第一个学的就是Trlx,后来看ColossalAI感觉Trlx写的真乱。还有就是Trlx的代码里,默认情况下,离线策略只执行一次,然后就训练,感觉有点奇怪。我实践经验上看,多次迭代效果是更好的。其次就是Trlx里面对Huggingface的模型封装比较复杂,我要在GLM上改挺麻烦的。
补充:trlx默认的参数基本是都是ok的,特别是gamma和lam的值,改了之后效果可能会差很多
- DeepspeedChat:DeepSpeedExamples/applications/DeepSpeed-Chat at master · microsoft/DeepSpeedExamples
优势:应该是目前最容易能达成100B以上Huggingface模型强化学习的框架了。里面强化学习的部分大多和Trlx的算法一致,添加了PTX损失和EMA算法。代码逻辑也比较清晰。借助最新0.9.0版本deepspeed新增的混合引擎,实现zero3推理时,自动完成张量并行,大大降低了100B基本模型的强化学习门槛。
缺点:lora功能不完善。deepspeed混合引擎目前只支持几个BLOOM、GPT等LM,如果要支持GLM不知道要怎么改。所以暂时没有使用它。
- ColossalAI-Chat:https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat
优势:代码逻辑清晰,新手学习非常友好。自己实现了一个和Trlx不太一样的PPO算法,每个句子只生成一个reward,没有时间步的概念,自然也就没有基于GAE求解优势函数的算法。这个算法本身我实践下来不太好训练,后面我们自己将其中的value function进行优化后,才成功训练起来,效果还是很不错的。
不足:ColossalAI框架本身不太完善。新功能得等社区慢慢更新,和很多流行的框架也不兼容,比较麻烦。
目前我们采用的是Accelerate+deepspeed的基本框架,同时用PEFT的lora减少显存占用。其实Accelerate和deepspeed的组合也不是特别好,Accelerate里面如果调用deepspeed的话,只支持一个模型和一个优化器,这导致ppo训练的时候比较麻烦,还不如直接使用原生的deepspeed。但是accelerate在分布式训练的时候,确实有它的优势,帮你解决了很多麻烦的事情,代码写起来比较省心。
这里我们特别提一下PEFT新分支中有个对多适配器lora的支持,这个功能天生就和PPO非常的搭,相当于一个基模型,通过挂多个lora的适配器,就可以随时变成RM、Critic、Actor、RefModel。同时加载四个模型,只需要消耗几乎等同于一个模型的显存,非常的香。GLM10B,开启zero2,在PPO训练的时候,单卡开到bs4,最终大概占用了30多G的显存。
补充:lora Multi Adapter功能已经合并到主分支了,详情可以看0.3.0的更新公告。
顺便提一下RLHF里一些好用的显存优化方法:
- 多lora适配器(不全量训练的PPO神器)
- deepspeed zero(什么地方都可以用它)
- gradient checkpointing(显存节省神器)
- flash attention(也是显存节省神器,LLAMA可以直接用,GLM不知道怎么适配)
- deepspeed混合引擎(30B以上PPO神器,希望以后能提供如何适配更多模型的文档)
- BF16(不会有FP16的溢出问题,训练PPO的时候比较安全)
2、算法
我们在Accelerate+deepspeed+peft的基本框架下,参照ColossalAI的代码逻辑,重新实现了一种回报模型算法和三种对齐算法。
2.1 回报模型
回报模型的结构和loss设计基本和Trlx保持一致,分数是取句末token的分数,实践证明这样训练后的权重用来初始化Critic是最有利于训练多时间步的PPO的。ColossalAI的回报模型分数是将句子所有的token求平均,这个如果是训练单步的PPO是没啥区别的,但是训练多步的话就不太合适。所以最后我还是都统一用Trlx的风格。
2.2 对齐算法
对齐算法我们实现了三种,一个是Trlx的多步PPO算法、一个是ColossalAI的单步PPO算法、一个是最近阿里开源的RRHF算法GitHub - GanjinZero/RRHF: RRHF & Wombat。
其中单步的PPO算法,ColossalAI默认是用一个Critic模型去拟合reward,这样训练出来的优势值很小很难训练。其实优势函数的本意就是累积奖励-累积奖励的期望。而对于单步的PPO来说,累积奖励就是单步奖励,而单步奖励的期望,其实并不需要一个神经网络去拟合。我们可以简单的通过随机生成n个答案,将它们的平均reward作为累积奖励的期望就可以训练的。这样即节省了一个神经网络,效果也非常好。
对于RRHF算法,原文中是离线生成了所有训练数据的答案,再去做训练。比较费时,训练起来也比较慢。我们也改成和ColossalAI类似的制作一小批数据就训练一次的方式,这样reward的增长会快一些。
实践下来,Trlx的多步PPO算法、ColossalAI的单步PPO、RRHF它们三者的reward上涨的量都差不多。RRHF上涨会快一些,但是的KL散度偏离要比PPO大很多。不过,RRHF基本不需要调参,PPO需要比较精细的调参。
3、数据
不知道中文什么时候能够有开源的比较完备的偏好数据集,能够涵盖较多的指令场景,同时在真实性、安全性方便也能有所顾及。其实只要有问题就行,答案最好是让sft去生成再找人打标,从instructgpt论文里看,这样ppo阶段的分数才是最精确的。
4、调参
在影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现) - Beaman的文章 - 知乎 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现) - 知乎这篇文章里,提到了很多PPO的优化方法,里面我只试了一部分,目前来看,对优势值的正则化是有效的,能够让actor的loss变得稳定,如果是分布式的场景,记得要同步后再做正则,这块Trlx有相关的实现。Adam Optimizer Epsilon Parameter这个也是有效的,很神奇。对reward和value的正则化我没有试过。然后梯度裁剪、学习率衰减那些我都是有加的,多少都有点用。
目前来看,主要就是每轮到底要制作多少离线的数据,太少模型会学的不太稳定,太多模型会学的太慢,这个需要多做实验尝试。然后就是每批数据要训练多少轮,太少,模型学的慢,太多容易过拟合。不知道deepspeedchat为什么会说他们只制作一次,训练一轮是最好的。这个我这边感觉还是多轮迭代比较好。
希望各位大佬也能分享一下经验,一起学习学习
参考:1、https://www.libhunt.com/compare-DeepSpeed-vs-ColossalAI
2、https://aicconf.net/pdf/AI%20infra%E6%8A%80%E6%9C%AF%E5%88%9B%E6%96%B0%E8%AE%BA%E5%9D%9B-%E3%80%90%E5%B0%A4%E6%B4%8B%E4%B8%A8%E6%BD%9E%E6%99%A8%E7%A7%91%E6%8A%80%E3%80%91-%E3%80%8AColossal-AI%EF%BC%9AAI%E5%A4%A7%E6%A8%A1%E5%9E%8B%E7%9A%84%E6%8C%91%E6%88%98%E4%B8%8E%E7%B3%BB%E7%BB%9F%E4%BC%98%E5%8C%96%E3%80%8B.pdf
3、https://hpc-ai.com/benchmarks
相关文章:
)
RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat)
原文:RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat) - 知乎 目录 收起 一、RLHF的作用 二、实践效果 三、怎么做 1、框架 2、算法 3、数据 4、调参 一、RLHF的作用 从InstructGPT的论文中看,RLHF目的…...

Oracle/Myql批量操作
前言:在oracle中使用insert into values (),(),()多种方式都不能成功,记录正确的批量方法 注意:oracle有自己实现批量的方法,mysql适用的,oracle不一定适用 <insert id"insertTaskImportOpen" parameterType"l…...

关于一个web站点的欢迎页面
- 什么是一个web站点的欢迎页面? - 对于一个webapp来说,我们是可以设置它的欢迎页面的。 - 设置了欢迎页面之后,当你访问这个webapp的时候,或者访问这个web站点的时候,没有指定任何“资源路径”,这个时候…...
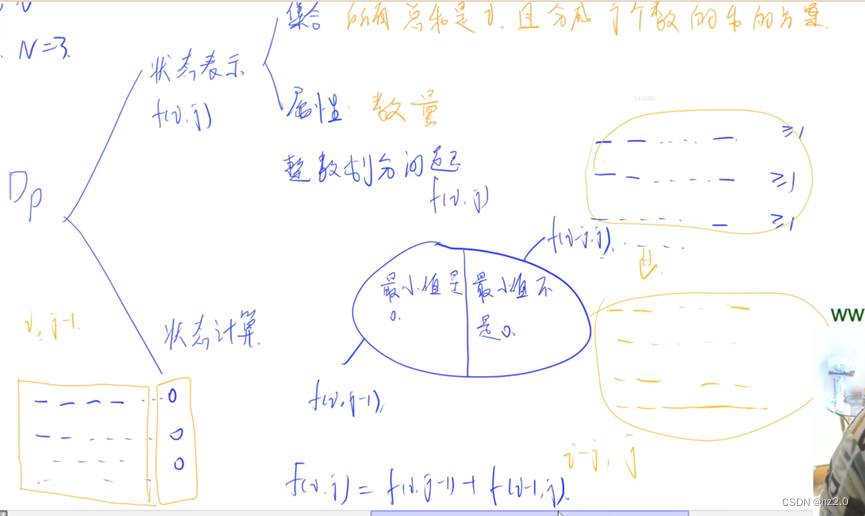
1050. 鸣人的影分身(dp划分)
题目: 1050. 鸣人的影分身 - AcWing题库 输入样例: 1 7 3输出样例: 8 思路: 代码: #include<iostream> using namespace std; const int N20; int f[N][N]; int main() {int T,m,n;cin>>T;while(T--)…...

51单片机点灯入门教程——2. 呼吸灯效果
基本说明 本章使用芯片:STC8H8K64U核心板 芯片手册:点此查看 Keil 开发环境配置:点此查看 本章学习内容:利用库函数,开发C程序,实现呼吸灯效果。 代码实例 需求:使用串口来控制呼吸灯效果&…...
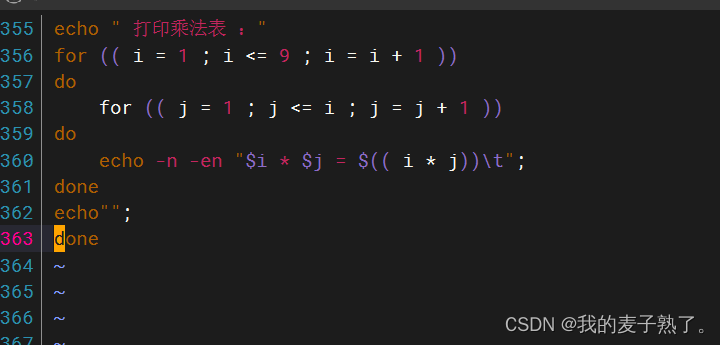
shell脚本实现九九乘法表
9*9乘法表 判断服务是否开启 1.查看80端口是否被监听 [rootlocalhost ~]# ss -an | grep 80 tcp LISTEN 0 128 *:80 *:* 2.查看80端口/httpd服务是否开启 [rootlocalhost ~]# n…...

CAAC无人机操作证考证报名流程及白底证件照片制作方法
在这个无人机技术日新月异的时代,拥有一张CAAC民用无人机操作证不仅意味着你能够合法地在天空翱翔,也象征着你对飞行技术的尊重和对规章制度的遵守。如果你怀揣着成为无人机飞行员的梦想,那么,让我们一起揭开CAAC民用无人机操作证…...

RPC介绍
什么是RPC RPC是远程过程调用(Remote Procedure Call)的缩写形式。在学校学编程,我们写一个函数都是在本地调用就行了。但是在互联网公司,服务都是部署在不同服务器上的分布式系统。 SAP(System Applications and Products/企业管…...

23 导航栏
效果演示 实现了一个响应式的导航栏,当鼠标悬停在导航栏上的某个选项上时,对应的横条会从左到右地移动,从而实现了导航栏的动态效果。 Code <div class"flex"><ul><li>1</li><li>2</li><l…...

express框架搭建后台服务
express 1. 使用express创建web服务器:2. 中间件中间件分类: 3.解决跨域问题:1. CORS2.JSONP 1. 使用express创建web服务器: 1. 导入express2. 创建web服务器3. 启动web服务器// 1. 导入express const express require(express)/…...

信息学奥赛一本通2067详解+代码
题目:http://ybt.ssoier.cn:8088/show_source.php?runid24484837 2067:【例2.5】圆 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 98334 通过数: 53637 【题目描述】 输入半径r,输出圆的直径、周长、面积,数与数…...
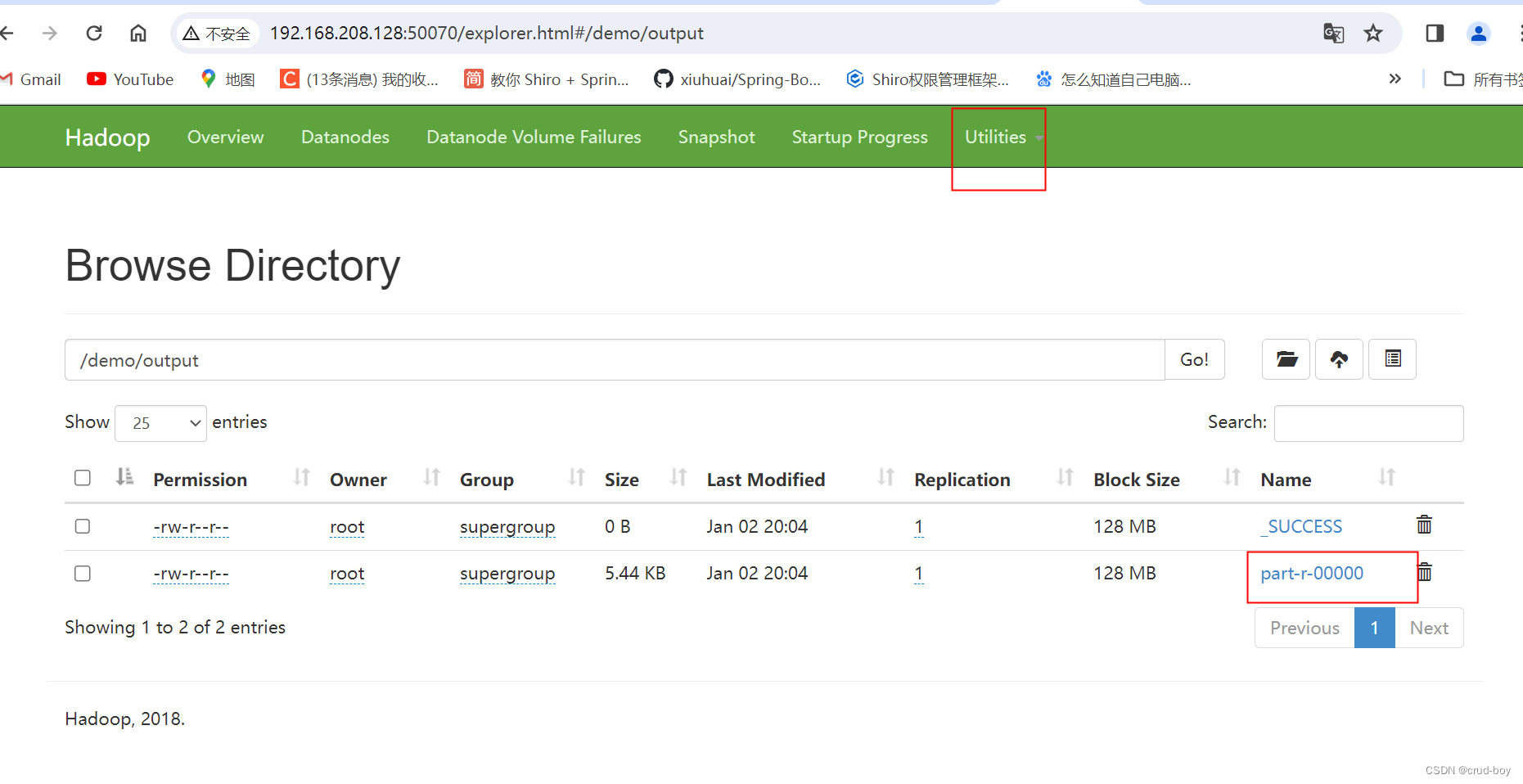
Java大数据hadoop2.9.2搭建伪分布式yarn资源管理器
1、修改配置文件 cd /usr/local/hadoop/etc/hadoop cp ./mapred-site.xml.template ./mapred-site.xml vi mapred-site.xml <configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property> &l…...
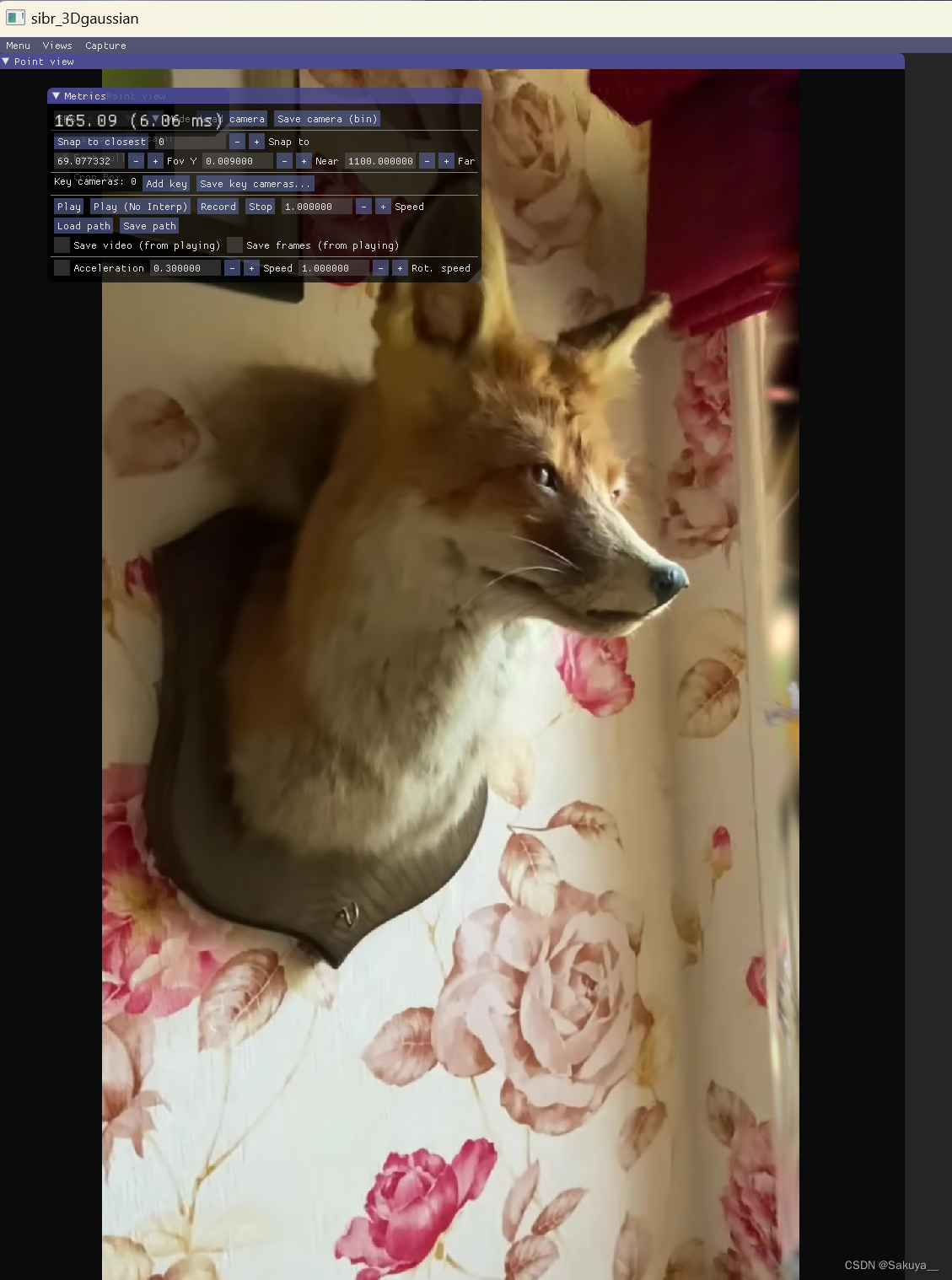
3D Gaussian Splatting复现
最近3D Gaussian Splatting很火,网上有很多复现过程,大部分都是在Windows上的。Linux上配置环境会方便简单一点,这里记录一下我在Linux上复现的过程。 Windows下的环境配置和编译,建议看这个up主的视频配置,讲解的很细…...

tf-idf +逻辑回归来识别垃圾文本
引入相关包 from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, auc, roc_auc_score import joblib import os import pandas as pd from sklearn.model_select…...

Oracle - 数据库的实例、表空间、用户、表之间关系
Oracle是一种广泛使用的关系型数据库管理系统,它具有高性能、高可靠性、高安全性等特点。1Oracle数据库的结构和组成是一个复杂而又有趣的话题,本文将介绍Oracle数据库的四个基本概念:数据库、实例、表空间和用户,以及它们之间的关…...
Java面试项目推荐,异构数据源数据流转服务DatalinkX
前言 作为一个年迈的夹娃练习生,每次到了春招秋招面试实习生时都能看到一批简历,十个简历里得有七八个是写商城或者外卖项目。 不由得想到了我大四那会,由于没有啥项目经验,又想借一个质量高点的项目通过简历初筛,就…...

一、Vue3组合式基础[ref、reactive]
一、ref 解释:ref是Vue3通过ES6的Proxy实现的响应式数据,其与基本的js类型不同,其为响应式数据,值得注意的是,reactive可以算是ref的子集,ref一般用来处理js的基本数据类型如整型、字符型等等(也可以用来处…...
unity网页远程手机游戏Inspector面板proxima
https://www.unityproxima.com/docs...
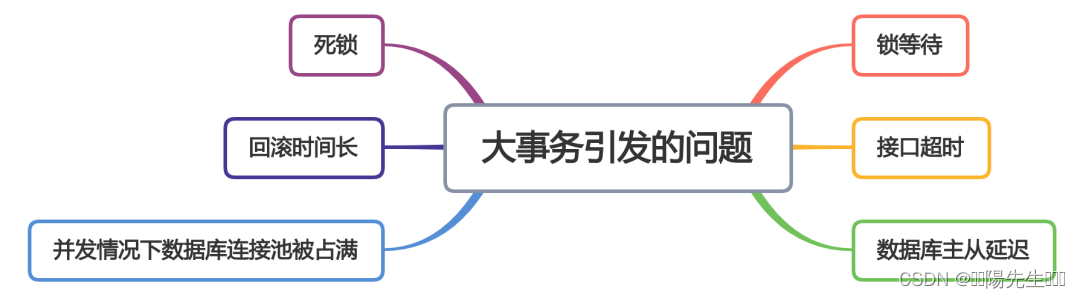
聊聊spring事务12种场景,太坑了
前言 对于从事java开发工作的同学来说,spring的事务肯定再熟悉不过了。 在某些业务场景下,如果一个请求中,需要同时写入多张表的数据。为了保证操作的原子性(要么同时成功,要么同时失败),避免数…...

mysql 数据查重与查重分页
起因是公司的crm录入不规范,有重复数据。 之后考虑到需要手动处理,首先需要自动找出重复的数据 查重要求: 存在多个不允许重复的字段,任一字段重复,则判断为同一个客户。划分到同一重复组中。 查重sql如下 SELECT C…...

PheroPath:自定义代谢通路构建与可视化工具在组学数据分析中的应用
1. 项目概述与核心价值最近在生物信息学和计算生物学领域,一个名为“PheroPath”的项目引起了我的注意。这个项目由用户starpig1129托管,从名字上就能嗅到一丝“信息素”和“路径”结合的味道。作为一名长期在组学数据分析、特别是代谢通路研究一线摸爬滚…...

星际软件开发:为火星殖民地编写第一批代码
一、引言:当测试左移到大气层之外2041年,第一批火星殖民者即将启程。他们携带的不仅是氧气和速食,还有一座预装在密封舱里的微型数据中心。在这片红色荒漠上,代码将比氧气更早醒来——生命维持系统的控制逻辑、通讯中继的协议栈、…...

TextInputLayout实战:从属性解析到自定义样式进阶
1. TextInputLayout基础入门:从零开始掌握Material输入框 第一次接触TextInputLayout时,我被它丝滑的浮动提示动画惊艳到了。相比传统的EditText,这个Material Design组件确实能让表单界面瞬间提升好几个档次。记得去年做登录页面重构时&…...

从RIPv2到RIPng:IPv6时代路由协议的演进与实战部署
1. 从RIPv2到RIPng:为什么IPv6需要新的路由协议? 第一次在实验室配置RIPv2时,我盯着那些IPv4地址看了整整三天。直到某天客户突然要求支持IPv6,才发现这个诞生于1988年的老协议已经跟不上时代——就像用传呼机收发4K视频ÿ…...

别再复制粘贴了!手把手教你封装一个可复用的Qt文本编辑器核心组件类
从零封装高复用Qt文本编辑器核心类:工程化实践指南 在Qt开发中,文本编辑器是最常见的功能需求之一。许多开发者习惯将所有逻辑堆砌在MainWindow类中,导致代码臃肿、难以维护和复用。本文将带你从工程化角度重构文本编辑器,将其核心…...
)
别再乱加电阻了!手把手教你用SI9000搞定PCB阻抗匹配(附50欧姆计算实例)
高速PCB设计实战:用SI9000精准计算阻抗匹配的工程方法 当信号频率突破百兆赫兹时,PCB走线就不再是简单的电气连接——它们变成了需要精密控制的传输线。去年参与一个千兆以太网项目时,我曾目睹团队因阻抗失配导致信号完整性崩溃的惨痛案例&am…...

终极指南:5分钟搭建SillyTavern AI聊天前端,解锁个性化角色对话体验
终极指南:5分钟搭建SillyTavern AI聊天前端,解锁个性化角色对话体验 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想要创建专属的AI聊天伙伴,体验深度…...

NovelForge:AI长篇小说创作引擎,结构化写作与知识图谱实战
1. 项目概述:一个为长篇创作而生的AI写作伙伴如果你和我一样,是一个对长篇故事创作充满热情,但又时常被海量设定、角色关系、情节推进和前后一致性搞得焦头烂额的作者,那么NovelForge的出现,可能正是我们一直在等待的“…...

教育资源共享新范式:智能解析技术如何重塑教材获取体验
教育资源共享新范式:智能解析技术如何重塑教材获取体验 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 项目地址…...

Go语言AI Agent框架goclaw:模块化架构与技能系统实战
1. 项目概述:一个用Go语言构建的现代化AI Agent框架如果你正在寻找一个功能全面、架构清晰,并且能让你快速上手构建智能助理的Go语言框架,那么goclaw(狗爪)绝对值得你花时间研究。我最近在评估几个开源的AI Agent框架&…...