PostgreSQL 作为向量数据库:入门和扩展
PostgreSQL 拥有丰富的扩展和解决方案生态系统,使我们能够将该数据库用于通用人工智能应用程序。本指南将引导您完成使用 PostgreSQL 作为向量数据库构建生成式 AI 应用程序所需的步骤。
我们将从pgvector 扩展开始,它使 Postgres 具有特定于向量数据库的功能。然后,我们将回顾增强在 PostgreSQL 上运行的 AI 应用程序的性能和可扩展性的方法。最后,我们将拥有一个功能齐全的生成式人工智能应用程序,向前往旧金山旅行的人推荐 Airbnb 房源。
Airbnb的推荐服务
该示例应用程序是住宿推荐服务。想象一下,您计划访问旧金山,并希望住在金门大桥附近的一个不错的街区。您访问该服务,输入提示,应用程序将建议三个最相关的住宿选项。
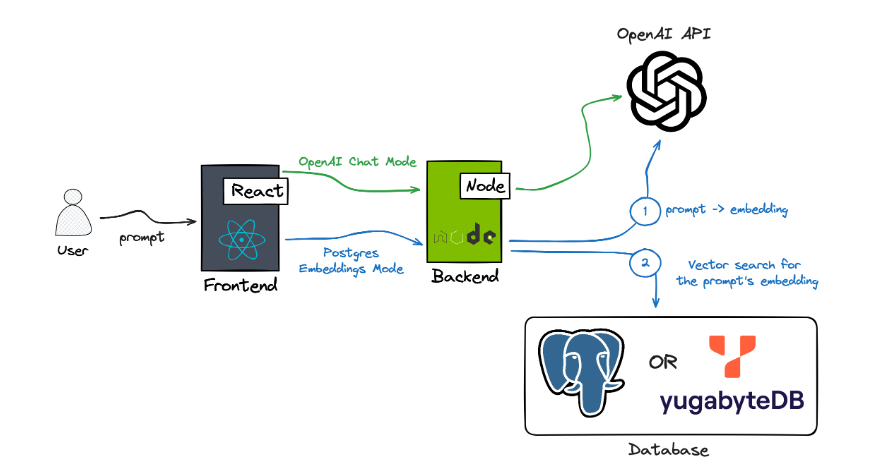
该应用程序支持两种不同的模式:
-
OpenAI 聊天模式:在此模式下,Node.js 后端利用OpenAI 聊天完成 API和 GPT-4 模型根据用户的输入生成住宿推荐。虽然此模式不是本指南的重点,但我们鼓励您尝试一下。
-
Postgres Embeddings 模式:最初,后端使用OpenAI Embeddings API将用户的提示转换为嵌入(文本数据的矢量化表示)。接下来,该应用程序在 Postgres 或 YugabyteDB(分布式 PostgreSQL)中进行相似性搜索,以查找与用户提示匹配的 Airbnb 属性。Postgres 利用 pgvector 扩展在数据库中进行相似性搜索。本指南将深入研究该特定模式在应用程序中的实现。
先决条件
-
可以访问嵌入模型的OpenAI订阅。
-
最新的Node.js 版本
-
最新版本的Docker
使用 Pgvector 启动 PostgreSQL
pgvector 扩展将向量数据库的所有基本功能添加到 Postgres 中。它允许您存储和处理具有数千个维度的向量,计算向量化数据之间的欧几里德距离和余弦距离,并执行精确和近似最近邻搜索。
1. 在 Docker 中使用 pgvector 启动 Postgres 实例:
docker run --name postgresql \-e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password \-p 5432:5432 \-d ankane/pgvector:latest
2. 连接到数据库容器并打开 psql 会话:
docker exec -it postgresql psql -h 127 .0.0.1 -p 5432 -U postgres3.启用pgvector扩展:
create extension vector;4. 确认向量存在于扩展列表中:
select * from pg_extension;oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+---------+----------+--------------+----------------+------------+-----------+--------------13561 | plpgsql | 10 | 11 | f | 1.0 | |16388 | vector | 10 | 2200 | t | 0.5.1 | |
(2 rows)加载 Airbnb 数据集
该应用程序使用 Airbnb 数据集,其中包含旧金山列出的 7,500 多个出租房产。每个列表都提供了详细的属性描述,包括房间数量、设施类型、位置和其他功能。该信息非常适合根据用户提示进行相似性搜索。
按照以下步骤将数据集加载到启动的 Postgres 实例中:
1. 克隆应用程序存储库:
git clone https://github.com/YugabyteDB-Samples/openai-pgvector-lodging-service.git2. 将 Airbnb 架构文件复制到 Postgres 容器(将 替换{app_dir}为应用程序目录的完整路径):
docker cp {app_dir}/sql/airbnb_listings.sql postgresql:/home/airbnb_listings.sql3.从下面的 Google Drive 位置下载包含 Airbnb 数据的文件。文件大小为 174MB,前提是它已包含使用 OpenAI 嵌入模型为每个 Airbnb 房产的描述生成的嵌入。
4. 将数据集复制到 Postgres 容器(将 替换{data_file_dir}为应用程序目录的完整路径)。
docker cp {data_file_dir}/airbnb_listings_with_embeddings.csv postgresql:/home/airbnb_listings_with_embeddings.csv5. 创建 Airbnb 架构并将数据加载到数据库中:
# Create schemadocker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-a -q -f /home/airbnb_listings.sql# Load datadocker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-c "\copy airbnb_listing from /home/airbnb_listings_with_embeddings.csv with DELIMITER '^' CSV;"
每个 Airbnb 嵌入都是一个 1536 维浮点数数组。它是 Airbnb 房产描述的数字/数学表示。
docker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-c "\x on" \-c "select name, description, description_embedding from airbnb_listing limit 1"# Truncated output
name | Monthly Piravte Room-Shared Bath near Downtown !3
description | In the center of the city in a very vibrant neighborhood. Great access to other parts of the city with all modes of public transportation steps away Like the general theme of San Francisco, our neighborhood is a melting pot of different people with different lifestyles ranging from homeless people to CEO''s
description_embedding | [0.0064848186,-0.0030366974,-0.015895316,-0.015803888,-0.02674906,-0.0083198985,-0.0063770646,0.010318241,-0.011003947,-0.037981577,-0.008783566,-0.0005710134,-0.0028015983,-0.011519859,-0.02011404,-0.02023159,0.03325347,-0.017488765,-0.014902675,-0.006527267,-0.027820067,0.010076611,-0.019069154,-0.03239144,-0.013243919,0.02170749,0.011421901,-0.0044701495,-0.0005861153,-0.0064978795,-0.0006775427,-0.018951604,-0.027689457,-0.00033081227,0.0034317947,0.0098349815,0.0034775084,-0.016835712,-0.0013787586,-0.0041632145,-0.0058219694,-0.020584237,-0.007386032,0.012486378,0.012473317,0.005815439,-0.010990886,-0.015111651,-0.023366245,0.019069154,0.017828353,0.030249426,-0.04315376,-0.01790672,0.0047444315,-0.0053419755,-0.02195565,-0.0057338076,-0.02576948,-0.009769676,-0.016914079,-0.0035232222,...嵌入是使用 OpenAI 的text-embedding-ada-002模型生成的。如果您需要使用不同的模型,那么:
-
{app_dir}/backend/embeddings_generator.js 更新和{app_dir}/backend/postgres_embeddings_service.js文件中的模型
-
通过使用node embeddings_generator.js命令启动生成器来重新生成嵌入。
查找最相关的 Airbnb 房源
至此,Postgres 已准备好向用户推荐最相关的 Airbnb 房产。应用程序可以通过将用户的提示嵌入与 Airbnb 描述的嵌入进行比较来获取这些推荐。
首先,启动 Airbnb 推荐服务的实例:
1. 使用您的 OpenAI API 密钥更新{app_dir}/application.properties.ini :
OPENAI_API_KEY=<your key>2.启动Node.js后端:
cd {app_dir}npm icd backendnpm start
3.启动React前端:
cd {app_dir}/frontendnpm inpm start
应用程序 UI 应在您的默认浏览器中自动打开。否则,在地址http://localhost:3000/打开。
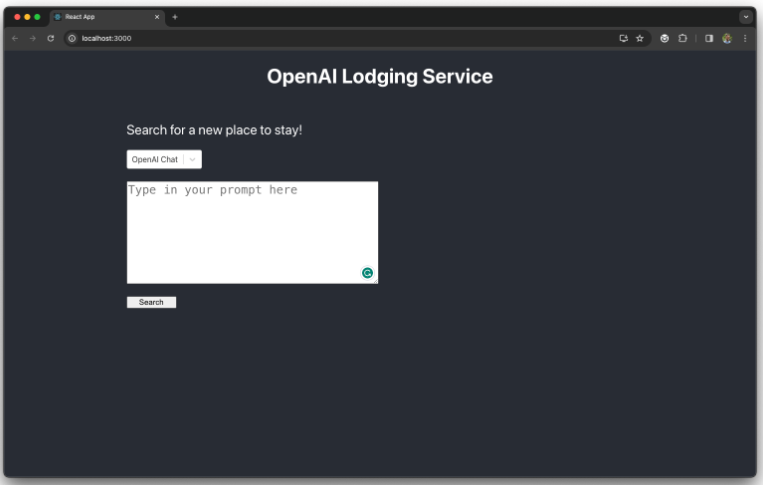
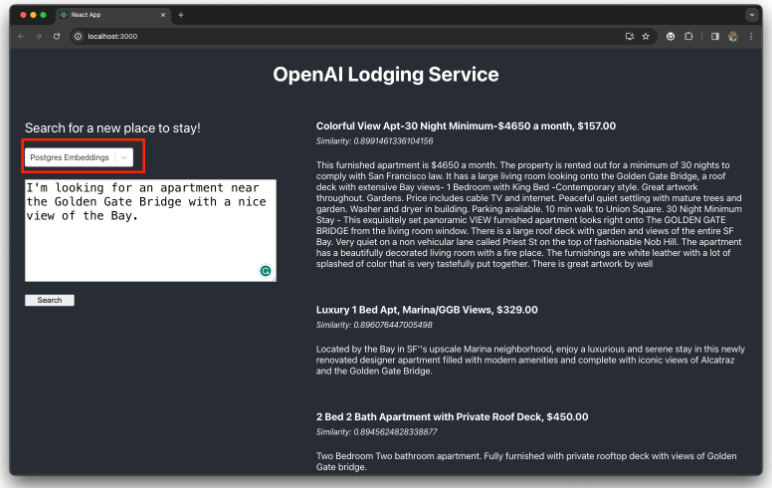
现在,从应用程序 UI 中选择Postgres Embeddings模式,并要求应用程序推荐一些与以下提示最相关的 Airbnb 房源:
I'm looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.该服务将推荐三种住宿选择:
在内部,应用程序执行以下步骤来生成建议({app_dir}/backend/postgres_embeddings_service.js有关详细信息,请参阅 ):
1. 应用程序使用 OpenAI Embeddings 模型生成用户提示的矢量化表示 ( text-embedding-ada-002):
const embeddingResp = await this.#openai.embeddings.create({model: "text-embedding-ada-002",input: prompt});
2. 应用程序使用生成的向量来检索存储在 Postgres 中最相关的 Airbnb 属性:
const res = await this.#client.query("SELECT name, description, price, 1 - (description_embedding <=> $1) as similarity " +"FROM airbnb_listing WHERE 1 - (description_embedding <=> $1) > $2 ORDER BY description_embedding <=> $1 LIMIT $3",['[' + embeddingResp.data[0].embedding + ']', matchThreshold, matchCnt]);相似度计算为description_embedding列中存储的嵌入与用户提示向量之间的余弦距离。
3. 建议的 Airbnb 属性以 JSON 格式返回到 React 前端:
let places = [];for (let i = 0; i < res.rows.length; i++) {const row = res.rows[i];places.push({"name": row.name, "description": row.description, "price": row.price, "similarity": row.similarity });
}return places;扩展的方法
目前,Postgres 存储了 7,500 多个 Airbnb 房产。数据库需要几毫秒的时间来执行精确的最近邻搜索,比较用户提示和 Airbnb 描述的嵌入。
然而,精确最近邻搜索(全表扫描)有其局限性。随着数据集的增长,Postgres 将需要更长的时间来对多维向量执行相似性搜索。
为了在数据量和流量不断增加的情况下保持 Postgres 的性能和可扩展性,您可以使用矢量化数据的专用索引和/或使用Postgres 的分布式版本水平扩展存储和计算资源。
pgvector 扩展支持多种索引类型,包括性能最好的 HNSW 索引(分层可导航小世界)。该索引对矢量化数据执行近似最近邻搜索 (ANN),使数据库即使在数据量很大的情况下也能保持较低且可预测的延迟。然而,由于搜索是近似的,搜索的召回率可能不是 100% 相关/准确,因为索引仅遍历数据的子集。
例如,以下是如何在 Postgres 中为 Airbnb 嵌入创建 HNSW 索引:
CREATE INDEX ON airbnb_listingUSING hnsw (description_embedding vector_cosine_ops)WITH (m = 4, ef_construction = 10);
借助分布式 PostgreSQL,当单个数据库服务器的容量不再充足时,您可以轻松扩展数据库存储和计算资源。尽管 PostgreSQL 最初是为单服务器部署而设计的,但其生态系统现在包含多个扩展和解决方案,使其能够在分布式配置中运行。其中一个解决方案是 YugabyteDB,这是一种分布式 SQL 数据库,它扩展了 Postgres 的分布式环境功能。
YugabyteDB 从 2.19.2 版本开始支持 pgvector 扩展。它将数据和嵌入分布在节点集群中,促进大规模的相似性搜索。因此,如果您希望 Airbnb 服务在 Postgres 的分布式版本上运行:
1. 部署多节点YugabyteDB集群。
2. 更新文件中的数据库连接设置{app_dir}/application.properties.ini:
# Configuration for a locally running YugabyteDB instance with defaults.DATABASE_HOST=localhostDATABASE_PORT=5433DATABASE_NAME=yugabyteDATABASE_USER=yugabyteDATABASE_PASSWORD=yugabyte
3. 从头开始加载数据(或使用 YugabyteDB Voyager 从正在运行的 Postgres 实例迁移数据)并重新启动应用程序。不需要进行其他代码级别的更改,因为 YugabyteDB 的功能和运行时与 Postgres 兼容。
作者:Denis Magda
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。
相关文章:
PostgreSQL 作为向量数据库:入门和扩展
PostgreSQL 拥有丰富的扩展和解决方案生态系统,使我们能够将该数据库用于通用人工智能应用程序。本指南将引导您完成使用 PostgreSQL 作为向量数据库构建生成式 AI 应用程序所需的步骤。 我们将从pgvector 扩展开始,它使 Postgres 具有特定于向量数据库…...
亚信安慧AntDB数据库:企业核心业务系统数据库升级改造的可靠之选
在近期召开的“2023年国有企业应用场景发布会”上,亚信安慧公司的核心数据库产品AntDB闪耀登场,技术总监北陌先生针对企业核心业务系统数据库升级改造的关键议题发表了深度分享。他从研发、工程实施和运维管理三个维度细致剖析了当前企业在进行数据库升级…...

CommonJS 和 ES6 Module:一场模块规范的对决(上)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

python快速实现简易电子音乐盒(电子钢琴)
首先第一步附上完整源码(基于pygame库) import pygame# 初始化pygame pygame.init()# 设置窗口大小 window_size (800, 600) screen pygame.display.set_mode(window_size)# 加载音频文件 C4 pygame.mixer.Sound("test1/C4.wav") D4 pyga…...

详解bookkeeper AutoRecovery机制
引言小故事 张三在一家小型互联网公司上班,由于公司实行的996,因此经常有同事“不辞而别”,为了工作的正常推进,团队内达成了某种默契,这种默契就是通过某个规则来选出一个同事,这个同事除了工作之余还有额…...

使用 Ubuntu 20.04 进行初始服务器设置
前些天发现了一个人工智能学习网站,通俗易懂,风趣幽默,最重要的屌图甚多,忍不住分享一下给大家。点击跳转到网站。 使用 Ubuntu 20.04 进行初始服务器设置 介绍 首次创建新的 Ubuntu 20.04 服务器时,应该执行一些重…...

【SpringCloud】6、Spring Cloud Gateway路由配置
在 Spring Cloud Gateway 中配置 uri 有三种方式,包括: 1、WebSocket路由 spring:cloud:gateway:routes:- id: bt-apiuri: ws://localhost:9090/predicates:...

pdf转换成word怎么转?一篇文章教你轻松搞定
pdf转换成word怎么转?你是否曾经遇到过需要将PDF文件转换成Word格式的情况?比如,你需要编辑一个文档,或者想将一些电子书或报告复制到Word中以便于编辑或重新排版。在这种情况下,如何将PDF文件转换成Word格式呢&#x…...
【中南林业科技大学】计算机组成原理复习包括题目讲解(超详细)
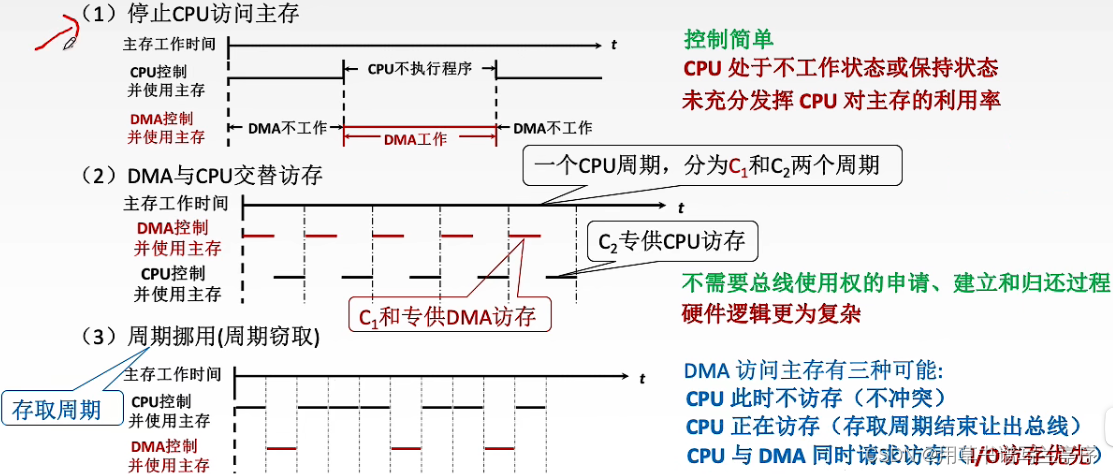
来都来了点个赞收藏关注一下再走呗🌹🌹🌹🌹 第1章:绪论 1.冯诺依曼机特点,与现代计算机的区别 冯诺依曼计算机的基本思想是:程序和数据以二进制形式表示,存储程序控制。在计算机中&…...

恭喜 Databend 上榜 2023 开源创新榜「优秀开源项目 」
近日,国家科技传播中心见证了一场开源界的重要事件:由中国科协科学技术传播中心、中国计算机学会、中国通信学会和中国科学院软件研究所联合主办,CSDN 承办的 2023 年开源创新榜专家评审会圆满落幕。由王怀民院士担任评委会主任,评…...

网络连通性批量检测工具
一、背景介绍 企业网络安全防护中,都会要求配置物理网络防火墙以及主机防火墙,加强对网络安全的防护。云改数转之际,多系统上云过程中都会申请开通大量各类网络配置,针对这些复杂且庞大的网络策略开通配置,那么在网络配…...
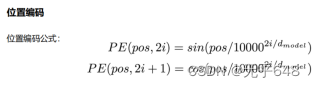
2023高级人工智能期末总结
1、人工智能概念的一般描述 人工智能是那些与人的思维相关的活动,诸如决策、问题求解和学习等的自动化; 人工智能是一种计算机能够思维,使机器具有智力的激动人心的新尝试; 人工智能是研究如何让计算机做现阶段只有人才能做得好的…...

Oracle数据库迁移所有文件到新挂载磁盘路径
主要步骤: 1、停掉服务, 2、关闭数据库shutdown immediate 3、移动数据文件到新的位置。 4、启动到mount状态,如果也移动了ctl,需要启动到nomount下,生成参数文件。 5、alter database rename 文件名 to 新位置&a…...

基于YOLOv7算法的高精度实时安全背心目标检测识别系统(PyTorch+Pyside6+YOLOv7)
摘要:基于YOLOv7算法的高精度实时安全背心目标检测系统可用于日常生活中检测与定位安全背心,此系统可完成对输入图片、视频、文件夹以及摄像头方式的目标检测与识别,同时本系统还支持检测结果可视化与导出。本系统采用YOLOv7目标检测算法来训…...
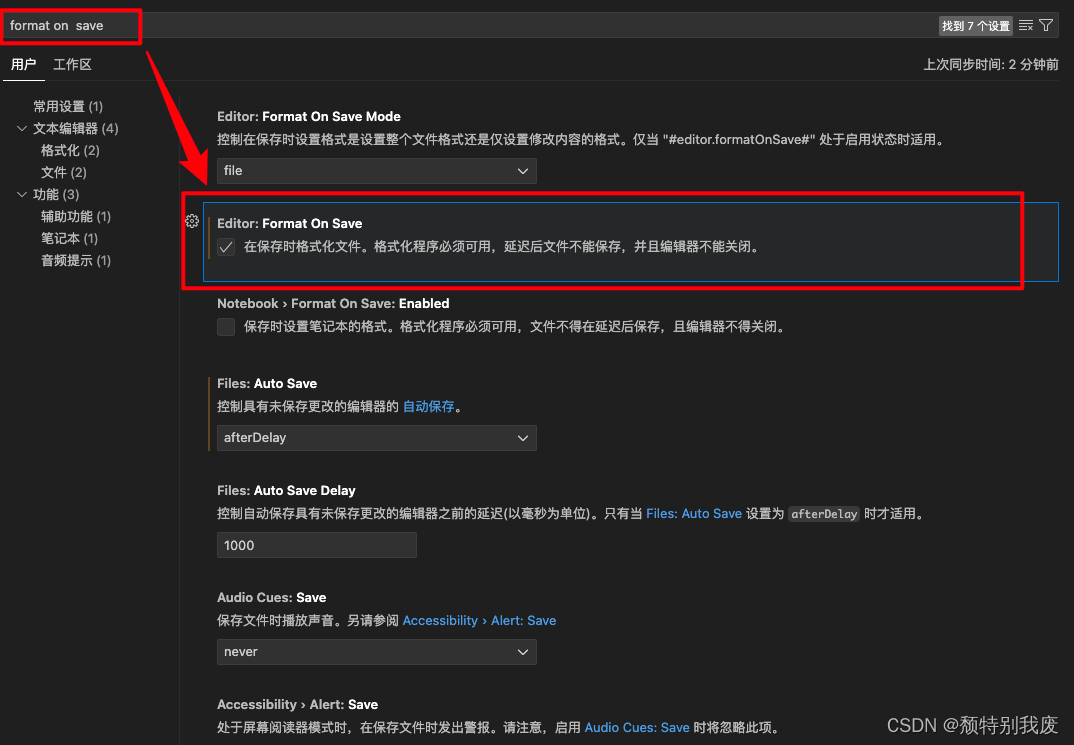
Mac——VsCode使用格式化工具进行整理和格式化
1. 打开VSCode编辑器。 2. 点击左下角⚙️图标,打开设置 3. 进入设置后,你会看到一个搜索框,在搜索框中输入 format on save 来查找相关设置项。 4. 在设置列表中找到 Editor: Format On Save 选项,勾选它以启用在保存文件时自动格…...
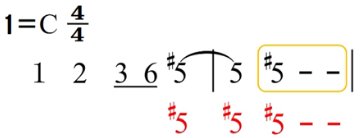
73.乐理基础-打拍子-还原号、临时变音记号在简谱中的规则
上一个内容:72.乐理基础-打拍子-加延音线的节奏型-CSDN博客 下图中1-13,就是四几拍中所有可能出现的节奏型,以及它们的组合方式,需要练习,可以买一本视唱书去练习,搜乐谱练习,自己写节奏型根据…...

一款超酷的一体化网站测试工具:Web-Check
Web-Check 是一款功能强大的一体化工具,用于发现网站/主机的相关信息。用于检查网页的工具,用于确保网页的正确性和可访问性。它可以帮助开发人员和网站管理员检测网页中的错误和问题,并提供修复建议。 它只需要输入一个网站就可以查看一个网…...

MockServer简单使用记录
下载源码 下载git源码:git clone https://github.com/mock-server/mockserver.git 通过执行文件编译成jar包 ./mvnw clean package 可能会报错。 启动命令 java -jar ./mockserver-netty-jar-with-dependencies.jar -serverPort 1080 -proxyRemotePort 80 -pro…...

AI+金融:大模型引爆金融科技革命
仅供机构投资者使用 证券研究报告|行业深度研究报告 AI金融:大模型引爆金融科技革命 “AI应用”系列(二) 华西计算机团队 2023年7月28日 分析师:刘泽晶 联系人:刘波 SAC NO:S1120520020002 邮箱:…...
数据库(二)实验一:MySQL数据库的C/S模式部署
实验要求 在云服务器上启动两个实例Server和Client,并实现两个实例之间的免密ssh登录。在Server和Client上分别安装MySQL,在Server上创建数据库和用户,在Client上远程连接Server的数据库。 实验内容 创建两个云服务器实例 在腾讯云购买两个…...
了!Qt 5.10+ 的 QRandomGenerator 让你的随机数更安全、更高效)
别再只用rand()了!Qt 5.10+ 的 QRandomGenerator 让你的随机数更安全、更高效
别再只用rand()了!Qt 5.10 的 QRandomGenerator 让你的随机数更安全、更高效 在开发过程中,随机数生成是一个看似简单却暗藏玄机的功能。许多开发者习惯性地使用C标准库中的rand()函数,殊不知这种做法在现代软件开发中已经显得力不从心。rand…...

2025届最火的六大AI辅助写作网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 这些年,“论文一键生成”类工具可多了,吸引着有写作压力的学生&#…...

怎么降维普AI率到30%以下?本科合格区间实战完整路径方案!
怎么降维普AI率到30%以下?本科合格区间实战完整路径方案! 本科生维普 AI 率合格线 30%,比硕博严标准 15% 宽松一倍。但如果你的论文 AI 率 60% 重灾区,降到 30% 以下还是需要工具。你的真实情况是什么? 本科 4-5 万字论…...

如何用bitsandbytes轻松实现PyTorch大模型量化:内存减半,性能不减
如何用bitsandbytes轻松实现PyTorch大模型量化:内存减半,性能不减 【免费下载链接】bitsandbytes Accessible large language models via k-bit quantization for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/bi/bitsandbytes 你是否曾因…...

解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析
解锁PS4游戏存档的终极掌控:Apollo Save Tool深度技术解析 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 在PlayStation 4的游戏生态中,PS4存档管理和游戏数据修改一直是玩家和开…...

Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践 对于有稳定大模型调用需求的开发者或团队而言࿰…...

实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略
本文由知学术AIPaperGPT内容团队实测撰写 2026-05-11实测推荐!2026年毕业论文5000字范文免费下载AI写作工具排行,查重降AI率全攻略又是一年毕业季,无数本科、硕士生正为毕业…...

免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案
免费开源!3分钟让Mac鼠标滚动告别卡顿的终极平滑方案 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independently fo…...

零成本AI评审知识库:基于GitHub Actions与Gemini的自动化学术发布平台
1. 项目概述:一个零成本、AI驱动的开放知识库如果你是一名研究者、开发者,或者正在构建一个需要实时验证信息的AI智能体,那么你一定对传统学术出版的漫长周期和封闭性感到头疼。一篇论文从投稿到发表,动辄数月,评审过程…...

西门子S7-300/400跨网段数据交换:DP/DP Coupler模块的Step7组态避坑指南
西门子S7-300/400跨网段数据交换实战:DP/DP Coupler组态深度解析与故障排查 在工业自动化系统中,多套PLC之间的数据交互是常见需求。当这些PLC分布在不同Profibus-DP网络时,西门子DP/DP Coupler模块成为实现跨网段通讯的关键组件。然而&#…...