【头歌实训】Spark MLlib ( Python 版 )
文章目录
- 第1关:基本统计
- 编程要求
- 测试说明
- 答案代码
- 第2关:回归
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第3关:分类
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第4关:协同过滤
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第5关:聚类
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第6关:降维
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第7关:特征提取与转化
- 编程要求
- 测试说明
- 答案代码
- 第8关:频繁模式挖掘
- 编程要求
- 测试说明
- 参考资料
- 答案代码
- 第9关:评估指标
- 编程要求
- 测试说明
- 答案代码
第1关:基本统计
编程要求
根据提示,在右侧编辑器补充代码,计算所给数据的 pearson 相关系数和 spearman 相关系数。
测试说明
平台会对你编写的代码进行测试:
预期输出:
DenseMatrix([[1. , 0.05564149, nan, 0.40047142],[0.05564149, 1. , nan, 0.91359586],[ nan, nan, 1. , nan],[0.40047142, 0.91359586, nan, 1. ]])
DenseMatrix([[1. , 0.10540926, nan, 0.4 ],[0.10540926, 1. , nan, 0.9486833 ],[ nan, nan, 1. , nan],[0.4 , 0.9486833 , nan, 1. ]])
答案代码
from pyspark.ml.linalg import Vectors
from pyspark.ml.stat import Correlation
from pyspark.sql import SparkSessiondef trainingModel(spark):# 自定义数据集data = [(Vectors.sparse(4, [(0, 1.0), (3, -2.0)]),),(Vectors.dense([4.0, 5.0, 0.0, 3.0]),),(Vectors.dense([6.0, 7.0, 0.0, 8.0]),),(Vectors.sparse(4, [(0, 9.0), (3, 1.0)]),)]########## Begin ########### 将 data 转化为 DataFramedata = spark.createDataFrame(data, ['features'])# 计算 df 的 pearson 相关系数pearsonCorr = Correlation.corr(data, 'features', 'pearson').collect()[0][0]# 计算 df 的 spearman 相关系数spearmanCorr = Correlation.corr(data, 'features', 'spearman').collect()[0][0]# 返回 pearson 相关系数和 spearman 相关系数return pearsonCorr, spearmanCorr########## End ##########第2关:回归
编程要求
根据提示,在右侧编辑器补充代码,实现线性回归的过程函数trainingModel(spark) ,函数返回训练好的模型。其中LinearRegression 只需设置以下三个参数:
maxIter=10
regParam=0.3
elasticNetParam=0.8
所需数据在 /data/workspace/myshixun/project/src/step2/linear.txt 中。
测试说明
平台会对你编写的代码进行测试,最终会输出该模型的 RMSE 指标:
R M S E = 1 m ∑ i ( f ( x i ) − y i ) 2 RMSE=\sqrt{\frac1m\sum_i(f(x_i)-y_i)^2} RMSE=m1i∑(f(xi)−yi)2
如果该指标在规定的范围内,则通过测试,测试代码将会输出 success,如果没有通过测试,将会输出 fail。 预期输出: success
参考资料
Spark 官方文档
答案代码
from pyspark.ml.regression import LinearRegression
from pyspark.sql import SparkSessiondef trainingModel(spark):########## Begin ########### 读取数据data = spark.read.format("libsvm").load("/data/workspace/myshixun/project/src/step2/linear.txt")# 建立模型lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)# 训练模型model = lr.fit(data)# 返回模型return model########## end ##########第3关:分类
编程要求
根据提示,在右侧编辑器补充代码,实现逻辑回归的过程函数trainingModel(spark) ,函数返回训练好的模型。其中LogisticRegression 只需设置以下三个参数:
maxIter=10
regParam=0.3
elasticNetParam=0.8
所需数据在 /data/workspace/myshixun/project/src/step3/logistic.txt 中。
测试说明
平台会对你编写的代码进行测试,最终会输出该模型的 roc 指标,如果该指标在规定的范围内,则通过测试,测试代码将会输出 success,如果没有通过测试,将会输出 fail。 预期输出: success
参考资料
Spark 官方文档
答案代码
from pyspark.ml.classification import LogisticRegression
from pyspark.sql import SparkSessiondef trainingModel(spark):########## Begin ########### 读取数据data = spark.read.format("libsvm").load("/data/workspace/myshixun/project/src/step3/logistic.txt")# 建立模型lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)# 训练模型model = lr.fit(data)# 返回模型,数据集return model########## End ##########第4关:协同过滤
编程要求
根据提示,在右侧编辑器补充代码,实现协同过滤的过程函数trainingModel(spark) ,函数返回训练好的模型。 所需数据在 /data/workspace/myshixun/project/src/step4/movie.txt 中,读取数据后请按如下要求命名列:
- 第一列:userID 数据类型:int
- 第二列:movieID 数据类型:int
- 第三列:rating 数据类型:float
- 第四列:timestamp 数据类型:int
其中ALS 除了要设置 userCol , itemCol 和 rating ,还需要设置以下三个参数:
maxIter=5
regParam=0.01
coldStartStrategy="drop"
测试说明
平台会对你编写的代码进行测试,最终会输出该模型的 RMSE 指标,如果该指标在规定的范围内,则通过测试,测试代码将会输出 success,如果没有通过测试,将会输出 fail。 预期输出: success
参考资料
Spark 官方文档
答案代码
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession,Rowdef trainingModel(spark):########## Begin ########### 读取数据data = spark.read.text("/data/workspace/myshixun/project/src/step4/movie.txt")# 数据预处理,处理分隔符,为每一列添加索引data = data.rdd.map(lambda line: line.value.split('::'))\.map(lambda p: Row(userID=int(p[0]), movieID=int(p[1]), rating=float(p[2]), timestamp=int(p[3])))# 创建数据框ratings = spark.createDataFrame(data)# 划分训练集和测试集 8:2(train, test) = ratings.randomSplit([0.8, 0.2], seed=0)# 在训练集上使用 ALS 建立推荐系统als = ALS(maxIter=5, regParam=0.01, coldStartStrategy="drop", userCol="userID", itemCol="movieID", ratingCol="rating")# 训练模型model = als.fit(train)########## End ########### 计算测试集上的 RMSE 值predictions = model.transform(test)rmse = RegressionEvaluator(metricName="rmse", labelCol="rating",predictionCol="prediction").evaluate(predictions)# 返回 rmsereturn rmse第5关:聚类
编程要求
根据提示,在右侧编辑器补充代码,实现聚类的过程函数trainingModel(spark) ,函数返回训练好的模型,对于模型你只需要设置以下两个参数:
k = 2
seed = 1
所需数据在 /data/workspace/myshixun/project/src/step5/k-means.txt 中
测试说明
平台会对你编写的代码进行测试,最终会输出该模型的 Silhouette score ,如果该指标在规定的范围内,则通过测试,测试代码将会输出 success,如果没有通过测试,将会输出 fail。 预期输出: success
参考资料
Spark 官方文档
答案代码
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
from pyspark.sql import SparkSessiondef trainingModel(spark):########## Begin ########### 读取数据data = spark.read.format("libsvm").load("/data/workspace/myshixun/project/src/step5/k-means.txt")# 建立 kmeans 模型kmeans = KMeans(k=2)kmeans.setSeed(1)# 训练模型model = kmeans.fit(data)########## End ##########predictions = model.transform(data)# 返回 模型、预测值return model, predictions
第6关:降维
编程要求
根据提示,在右侧编辑器补充代码,实现降维的过程函数trainingModel(spark) ,其中PCA 只需要设置以下三个参数:
k=3
inputCol="features",
outputCol="pcaFeatures"
测试说明
平台会对你编写的代码进行测试,测试代码将会输训练好的矩阵。 预期输出:
+-----------------------------------------------------------+
|pcaFeatures |
+-----------------------------------------------------------+
|[1.6485728230883807,-4.013282700516296,-5.524543751369388] |
|[-4.645104331781534,-1.1167972663619026,-5.524543751369387]|
|[-6.428880535676489,-5.337951427775355,-5.524543751369389] |
+-----------------------------------------------------------+
参考资料
Spark 官方文档
答案代码
from pyspark.ml.feature import PCA
from pyspark.ml.linalg import Vectors
from pyspark.sql import SparkSessiondef trainingModel(spark):# 自定义数据集data = [(Vectors.sparse(5, [(1, 1.0), (3, 7.0)]),),(Vectors.dense([2.0, 0.0, 3.0, 4.0, 5.0]),),(Vectors.dense([4.0, 0.0, 0.0, 6.0, 7.0]),)]########## Begin ########### 创建数据框df = spark.createDataFrame(data, ["features"])# 建立模型pca = PCA(k=3, inputCol="features", outputCol="pcaFeatures")# 训练模型model = pca.fit(df)########## End ########### 返回计算结果result = model.transform(df).select('pcaFeatures')return result第7关:特征提取与转化
编程要求
根据提示,在右侧编辑器补充代码,输出经过ml.feature.FeatureHasher 的特征,输出的特征命名为 features。注意,只需输出 feature 特征列。
测试说明
平台会对你编写的代码进行测试,测试代码将会输训练好的特征矩阵。 预期输出:
+--------------------------------------------------------+
|features |
+--------------------------------------------------------+
|(262144,[174475,247670,257907,262126],[2.2,1.0,1.0,1.0])|
|(262144,[70644,89673,173866,174475],[1.0,1.0,1.0,3.3]) |
|(262144,[22406,70644,174475,187923],[1.0,1.0,4.4,1.0]) |
|(262144,[70644,101499,174475,257907],[1.0,1.0,5.5,1.0]) |
+--------------------------------------------------------+
答案代码
from pyspark.ml.feature import FeatureHasher
from pyspark.sql import SparkSessiondef trainingModel(spark):# 自定义数据集data = spark.createDataFrame([(2.2, True, "1", "foo"),(3.3, False, "2", "bar"),(4.4, False, "3", "baz"),(5.5, False, "4", "foo")], ["real", "bool", "stringNum", "string"])########## Begin ########### 特征提取,使用 FeatureHasherhasher = FeatureHasher()hasher.setInputCols(["real", "bool", "stringNum", "string"])hasher.setOutputCol("features")hashed_df = hasher.transform(data)# 返回特征return hashed_df.select("features")########## End ##########第8关:频繁模式挖掘
编程要求
根据提示,在右侧编辑器补充代码,实现频繁模式挖掘的过程函数trainingModel(spark) ,在设置 FPGrowth 只需要设置以下三个参数:
itemsCol="items",
minSupport=0.5,
minConfidence=0.6
测试说明
平台会对你编写的代码进行测试,最终会输出训练后的结果 预期输出:
+---+------------+----------+
| id| items|prediction|
+---+------------+----------+
| 0| [1, 2, 5]| []|
| 1|[1, 2, 3, 5]| []|
| 2| [1, 2]| [5]|
+---+------------+----------+
参考资料
Spark 官方文档
答案代码
from pyspark.ml.fpm import FPGrowth
from pyspark.sql import SparkSessiondef trainingModel(spark):# 自定义数据集df = spark.createDataFrame([(0, [1, 2, 5]),(1, [1, 2, 3, 5]),(2, [1, 2])], ["id", "items"])########## Begin ########### 建立模型fp = FPGrowth(minSupport=0.5, minConfidence=0.6, itemsCol="items")# 训练模型fpm = fp.fit(df)# 返回模型,数据集return fpm, df########## End ##########第9关:评估指标
编程要求
根据提示,在右侧编辑器补充代码,在逻辑回归实例中返回 areaUnderROC 指标和 acc 指标。
测试说明
平台会对你编写的代码进行测试,最终会返回逻辑回归实例中的 areaUnderROC 指标和 acc 指标,如果这两个值在设定范围内,将输出 success,否则输出 fail 。 预期输出: success
答案代码
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluator, MulticlassClassificationEvaluator
from pyspark.sql import SparkSessiondef trainingModel(spark):# 读取数据集data = spark.read.format("libsvm").load("/data/workspace/myshixun/project/src/step9/data.txt")# 建立模型lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)# 训练模型model = lr.fit(data)########## Begin ########### 使用模型进行预测predictions = model.transform(data)# 创建 BinaryClassificationEvaluator 来计算 areaUnderROCevaluator_roc = BinaryClassificationEvaluator(rawPredictionCol="rawPrediction", labelCol="label", metricName="areaUnderROC")areaUnderROC = evaluator_roc.evaluate(predictions)# 创建 MulticlassClassificationEvaluator 来计算 accuracyevaluator_acc = MulticlassClassificationEvaluator(predictionCol="prediction", labelCol="label", metricName="accuracy")accuracy = evaluator_acc.evaluate(predictions)# 返回 areaUnderROC 指标和 acc 指标return areaUnderROC, accuracy########## End ##########相关文章:
)
【头歌实训】Spark MLlib ( Python 版 )
文章目录 第1关:基本统计编程要求测试说明答案代码 第2关:回归编程要求测试说明参考资料答案代码 第3关:分类编程要求测试说明参考资料答案代码 第4关:协同过滤编程要求测试说明参考资料答案代码 第5关:聚类编程要求测…...

Java基础进阶(学习笔记)
注:本篇的代码和PPT图片来源于黑马程序员,本篇仅为学习笔记 static static 是静态的意思,可以修饰成员变量,也可以修饰成员方法 修饰成员的特点: 被其修饰的成员, 被该类的所有对象所共享 多了一种调用方式, 可以通过…...

uView NoticeBar 滚动通知
该组件用于滚动通告场景,有多种模式可供选择 #平台差异说明 App(vue)App(nvue)H5小程序√√√√ #基本使用 通过text参数设置需要滚动的内容 <template><view><u-notice-bar :text"text1&quo…...
外包干了3个多月,技术退步明显。。。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...

JSON的一些资源
以下是一些推荐的学习资源: 1. **官方网站**: - JSON.org: 这是一个很好的起点,它提供了JSON的基本介绍和语法规则。 2. **在线教程和课程**: - CSDN全方面学习各种资源。 - W3Schools (w3schools.com): 提供了一个关于JSON的教程,涵…...

最优化理论期末复习笔记 Part 1
数学基础线性代数 从行的角度从列的角度行列式的几何解释向量范数和矩阵范数 向量范数矩阵范数的更强的性质的意义 几种向量范数诱导的矩阵范数 1 范数诱导的矩阵范数无穷范数诱导的矩阵范数2 范数诱导的矩阵范数 各种范数之间的等价性向量与矩阵序列的收敛性 函数的可微性与展…...
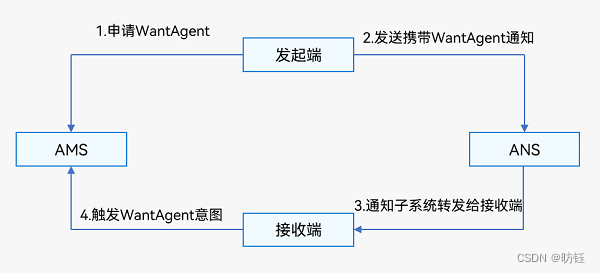
鸿蒙应用中的通知
目录 1、通知流程 2、发布通知 2.1、发布基础类型通知 2.1.1、接口说明 2.1.2、普通文本类型通知 2.1.3、长文本类型通知 2.1.4、多行文本类型通知 2.1.5、图片类型通知 2.2、发布进度条类型通知 2.2.1、接口说明 2.2.2、示例 2.3、为通知添加行为意图 2.3.1、接…...

如何停止一个运行中的Docker容器
要停止一个运行中的Docker容器,你可以使用以下命令: docker stop <容器ID或容器名> 将 <容器ID或容器名> 替换为你要停止的具体容器的标识符或名称。你可以使用以下命令查看正在运行的容器:docker ps 这将列出所有正在运行的…...
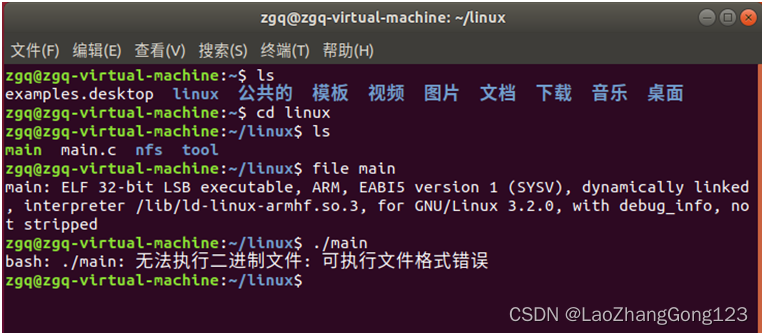
Linux第19步_安装“Ubutun交叉编译工具链”
由于Ubuntu系统使用的GCC编译器,编译结果是X86文件,只能在X86上运行,不能在ARM上直接运行。因此,还要安装一个“Ubutun交叉编译工具链”,才可以在ARM上运行。 arm-none-linux-gnueabi-gcc是 Codesourcery 公司&#x…...
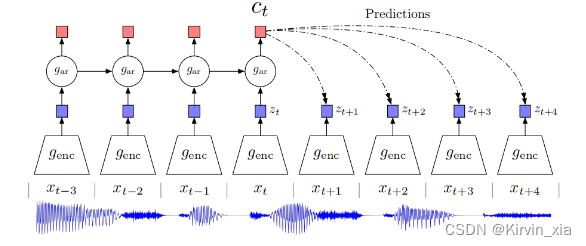
【论文阅读笔记】 Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding 摘要 这段文字是论文的摘要,作者讨论了监督学习在许多应用中取得的巨大进展,然而无监督学习并没有得到如此广泛的应用,仍然是人工智能中一个重要且具有挑战性的任务。在这项工作…...

CNN——LeNet
1.LeNet概述 LeNet是Yann LeCun于1988年提出的用于手写体数字识别的网络结构,它是最早发布的卷积神经网络之一,可以说LeNet是深度CNN网络的基石。 当时,LeNet取得了与支持向量机(support vector machines)性能相…...
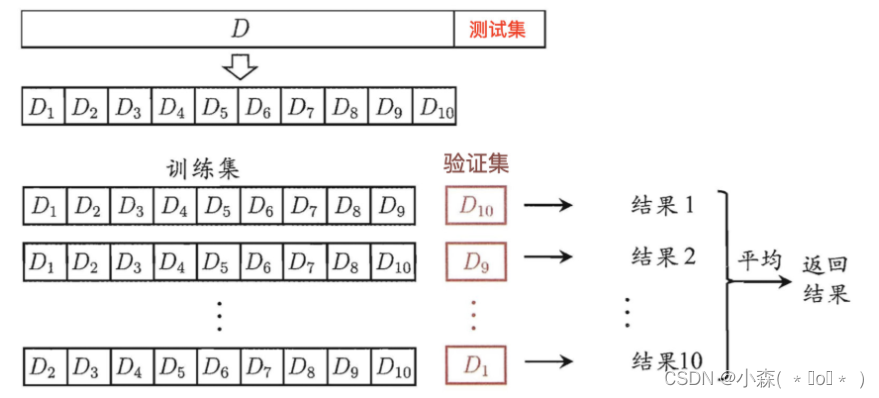
分类模型评估方法
1.数据集划分 1.1 为什么要划分数据集? 思考:我们有以下场景: 将所有的数据都作为训练数据,训练出一个模型直接上线预测 每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别 存在问题&…...

RabbitMQ高级
文章目录 一.消息可靠性1.生产者消息确认 MQ的一些常见问题 1.消息可靠性问题:如何确保发送的消息至少被消费一次 2.延迟消息问题:如何实现消息的延迟投递 3.高可用问题:如何避免单点的MQ故障而导致的不可用问题 4.消息堆积问题:如何解决数百万消息堆积,无法及时…...
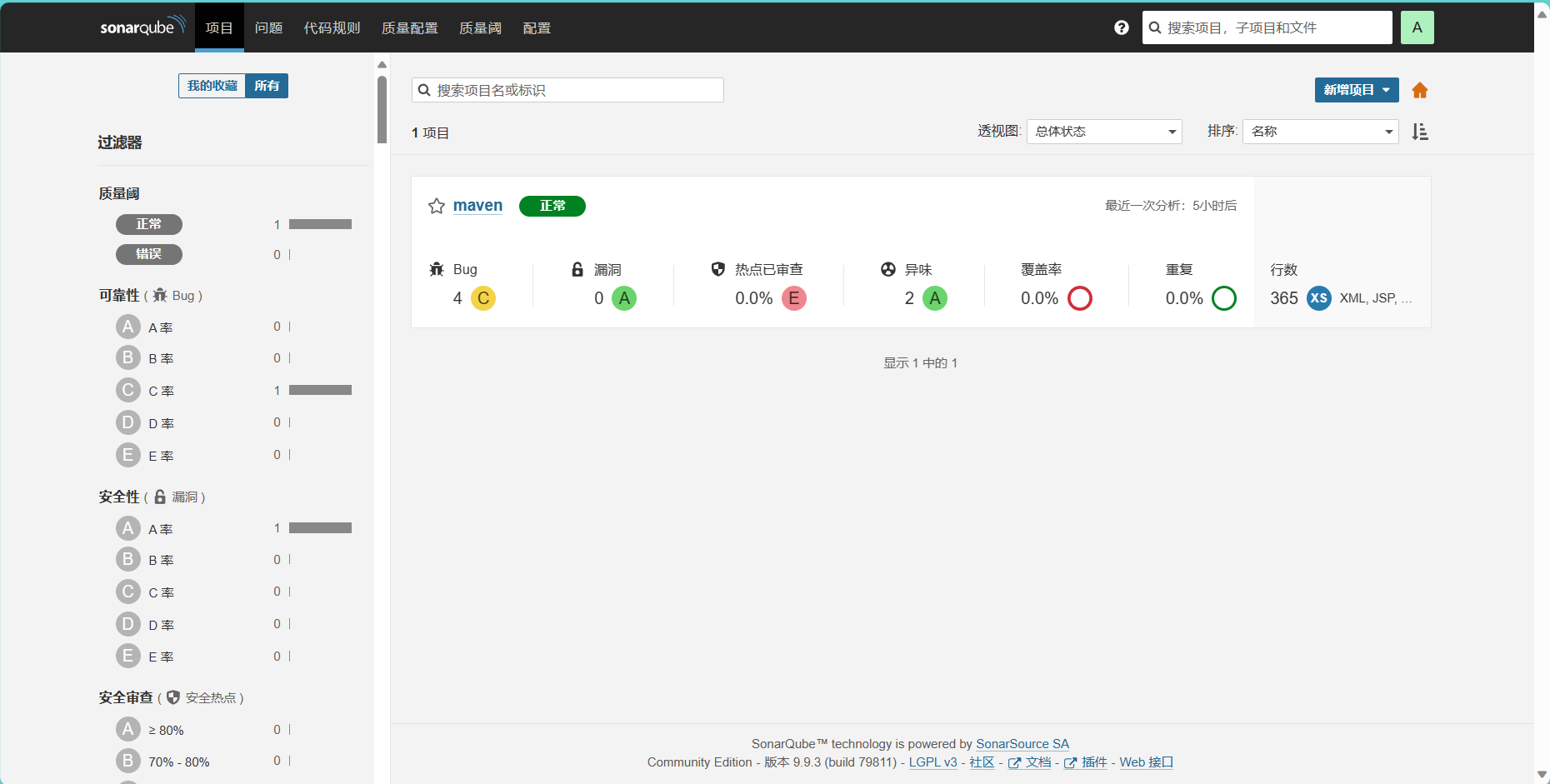
SonarQube 漏洞扫描
SonarQube 漏洞扫描 一、部署服务 1.1 docker方式部署 #安装docker curl -L download.beyourself.org.cn/shell-project/os/get-docker-latest.sh | sh yum install -y docker-compose #进去输入:set paste可以保证不穿行 [rootlocalhost sonar]# vim docker-compose.yml v…...

Web前端篇——ElementUI的Backtop 不显示问题
在使用ElementUI的Backtop回到顶部组件时,单独复制这一行代码 <el-backtop :right"100" :bottom"100" /> 发现页面在向下滚动时,并未出现Backtop组件。 可从以下3个方向进行分析: 指定target属性,且…...

MySQL 管理工具
1、MySQL 管理 系统数据库 a. mysql 命令 语法:mysql [options] [database] -u,--username 指定用户名-p,--password[name] 指定密码-h, --hostname 指定服务器IP或域名-P, --portport 指定连接端-e,--executename 执行SQL语句并退出 mysql -h192.168.200.202 -…...

LeetCode 33 搜索旋转排序数组
题目描述 搜索旋转排序数组 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., num…...
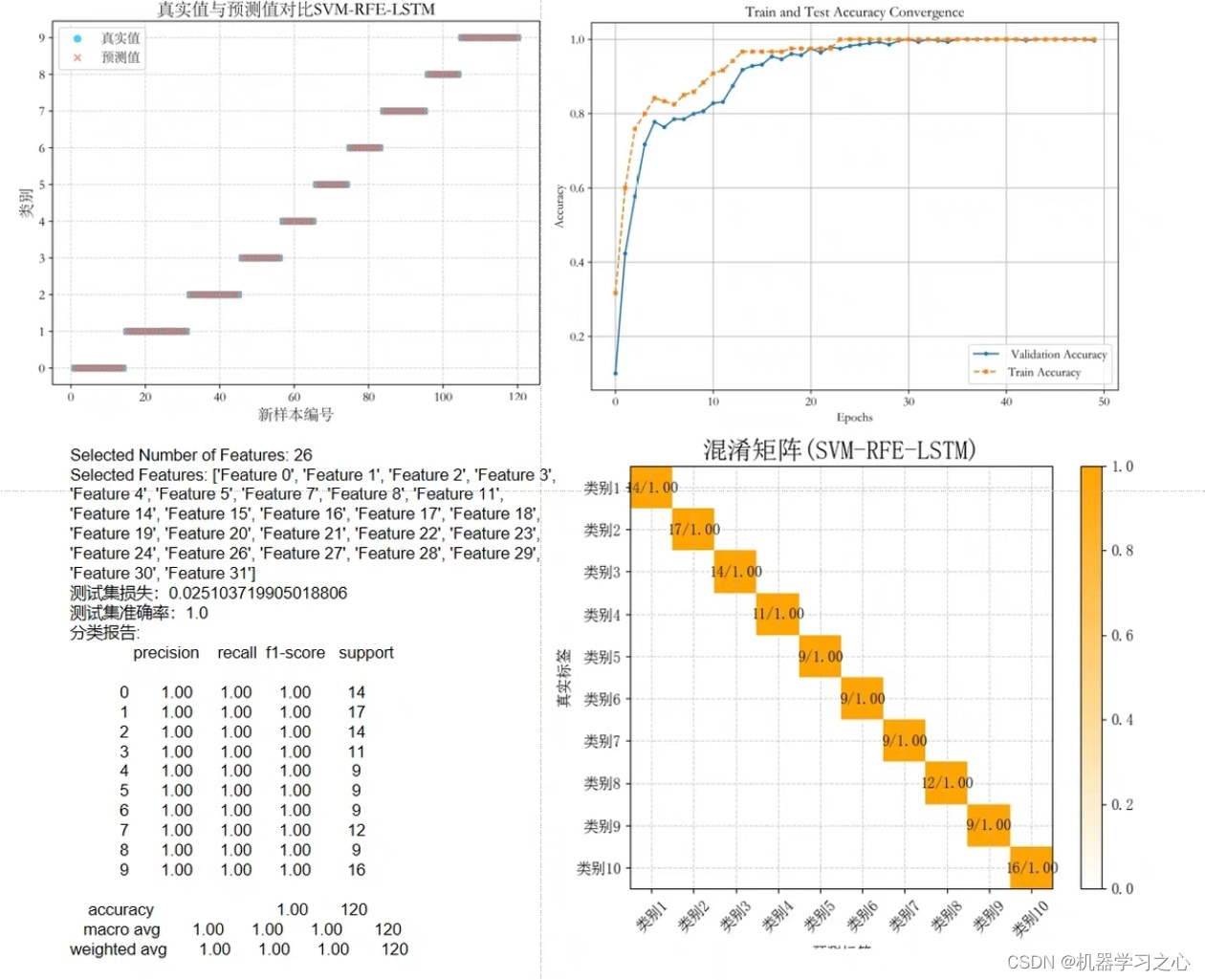
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测
分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测 目录 分类预测 | Python实现基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 基于SVM-RFE-LSTM的特征…...
JetBrains Rider使用总结
简介: JetBrains Rider 诞生于2016年,一款适配于游戏开发人员,是JetBrains旗下一款非常年轻的跨平台 .NET IDE。目前支持包括.NET 桌面应用、服务和库、Unity 和 Unreal Engine 游戏、Xamarin 、ASP.NET 和 ASP.NET Core web 等多种应用程序…...
C# Emgu.CV4.8.0读取rtsp流录制mp4可分段保存
【官方框架地址】 https://github.com/emgucv/emgucv 【算法介绍】 EMGU CV(Emgu Computer Vision)是一个开源的、基于.NET框架的计算机视觉库,它提供了对OpenCV(开源计算机视觉库)的封装。EMGU CV使得在.NET应用程序…...

用普通光耦TLP521-2实现宽范围线性隔离?一个低成本替代线性光耦的电路设计与实测
用普通光耦TLP521-2实现宽范围线性隔离的工程实践 在工业传感器接口和模拟信号采集领域,信号隔离是确保系统稳定性和安全性的关键技术。传统专用线性光耦(如LOC系列)虽性能优异,但高昂的成本和有限的线性输出范围(通常…...

终极CH55xduino指南:5分钟构建低成本USB微控制器项目
终极CH55xduino指南:5分钟构建低成本USB微控制器项目 【免费下载链接】ch55xduino An Arduino-like programming API for the CH55X 项目地址: https://gitcode.com/gh_mirrors/ch/ch55xduino CH55xduino为CH55X系列低成本MCS51 USB微控制器提供了完整的Ardu…...

汉森软件冲刺港股:年营收6亿 净利1.4亿 已获IPO备案
雷递网 雷建平 5月15日深圳市汉森软件股份有限公司(简称:“汉森软件”)日前更新招股书,准备在港交所上市。汉森软件已获IPO备案,拿到了上市的钥匙,同期一并拿到备案的企业还包括南京海纳医药科技股份有限公…...

基于Agen项目构建个人AI代理:从LLM原理到邮件处理实战
1. 项目概述:从“Agen”看个人化AI代理的构建思路最近在GitHub上看到一个名为“Agen”的项目,作者是Anjuan555。这个项目名本身就很值得玩味——“Agen”,很容易让人联想到“Agent”(代理),但又少了一个“t…...

MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南
MAA助手:解放双手的明日方舟全自动游戏管理工具实战指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://g…...

ChatGPT-PerfectUI:开源前端界面部署与核心功能解析
1. 项目概述:一个为ChatGPT打造的“完美”前端界面如果你和我一样,是ChatGPT的重度用户,每天都要和它进行大量的对话,那么你肯定对官方那个略显简陋的Web界面有过一些“怨念”。功能切换不够直观、对话管理略显笨拙、界面风格万年…...

【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 + WHO标准分类算法实战指南
【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 WHO标准分类算法实战指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net🎯 写在前面 嗨,大家好!我是上海某高校大一计算机专业的学生…...

基于CircuitPython的红外遥控发射器:从原理到实现的万能控制方案
1. 项目概述:打造你的万能红外遥控发射器搞嵌入式开发的朋友,对红外遥控肯定不陌生。家里电视、空调、风扇的遥控器,本质上都是一个红外信号发射器。你有没有想过,自己动手做一个能模拟所有遥控器的“万能发射器”?今天…...

程序员,真要失业了:Claude Code新增/goal指令,一个命令,AI替你干完整个项目
最近,GitHub上发生了一件小事。 一个全美排名Top 5的软件工程师,发了一条帖子,只有三句话: “我用/goal重构了一个3万行的遗留项目,花了4小时。” “没有人盯着我,没有PR被拒,没有半夜爬起来看…...
)
告别在线安装卡顿:手把手教你离线部署Vitis 2021.2到Ubuntu 20.04(含77G包处理技巧)
高效离线部署Vitis 2021.2:Ubuntu 20.04全流程实战指南 对于从事FPGA开发的工程师而言,稳定可靠的开发环境搭建是项目成功的第一步。当网络条件受限或需要批量部署时,离线安装方式往往成为刚需。本文将深入解析如何在Ubuntu 20.04系统上完成V…...