Zookeeper之Java客户端实战
ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。可供选择的Java客户端API有:
- ZooKeeper官方的Java客户端API。
- 第三方的Java客户端API,比如Curator。
接下来我们将逐一学习一下这两个java客户端是如何操作zookeeper的。
1. ZooKeeper官方的Java客户端
1.1 简介
ZooKeeper官方的客户端API提供了基本的操作。例如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。不过,对于实际开发来说,ZooKeeper官方API有一些不足之处,具体如下:
- ZooKeeper的Watcher监听是一次性的,每次触发之后都需要重新进行注册。
- 会话超时之后没有实现重连机制。
- 异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
- 仅提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
- 创建节点时如果抛出异常,需要自行检查节点是否存在。
- 无法实现级联删除。
总之,ZooKeeper官方API功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。
1.2 基础使用
使用zookeeper原生客户端,需要引入zookeeper客户端的依赖。
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.3</version></dependency>注意:保持与服务端版本一致,不然会有很多兼容性的问题。
ZooKeeper原生客户端主要使用org.apache.zookeeper.ZooKeeper这个类来调用ZooKeeper服务的。
1.2.1 连接zk集群
ZooKeeper构造器:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) throws IOException {this(connectString, sessionTimeout, watcher, false);}connectString:使用逗号分隔的列表,每个ZooKeeper节点是一个host.port对,host 是机器名或者IP地址,port是ZooKeeper节点对客户端提供服务的端口号。客户端会任意选取connectString 中的一个节点建立连接。
sessionTimeout : session timeout时间。
watcher:用于接收到来自ZooKeeper集群的事件。
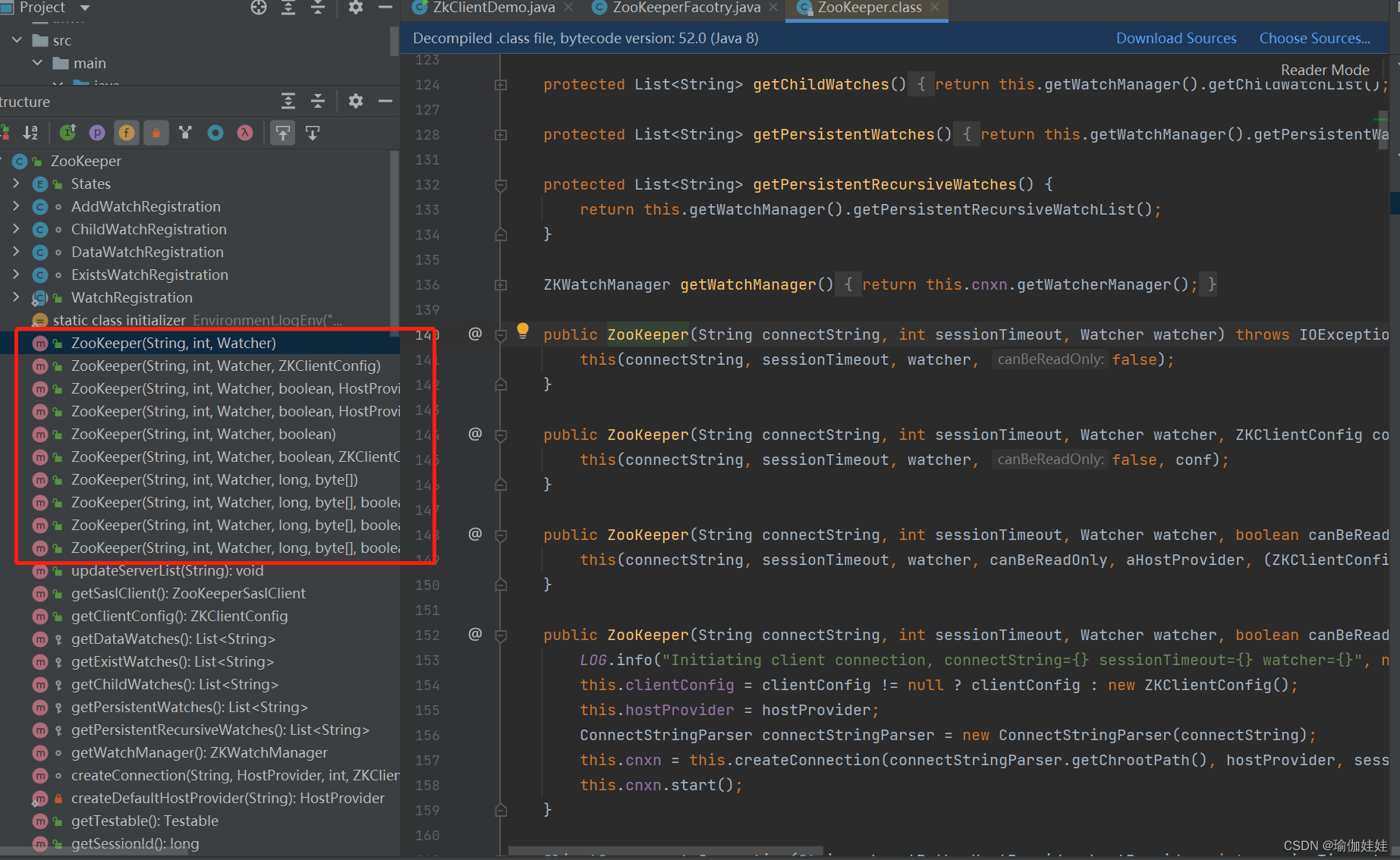
如何使用客户端构造器与服务端建立连接:
建立连接的工具类;因为zookepper建立连接时特别慢,所以采用了CountDownLatch同步工具类,等待zookeeper客户端与服务端建立完成后,继续后续操作。
public class ZooKeeperFacotry {private static final int SESSION_TIMEOUT = 5000;public static ZooKeeper create(String connectionString) throws Exception {final CountDownLatch connectionLatch = new CountDownLatch(1);ZooKeeper zooKeeper = new ZooKeeper(connectionString, SESSION_TIMEOUT, new Watcher() {@Overridepublic void process(WatchedEvent event) {if (event.getType()== Event.EventType.None&& event.getState() == Watcher.Event.KeeperState.SyncConnected) {connectionLatch.countDown();System.out.println("连接建立");}}});System.out.println("等待连接建立...");connectionLatch.await();return zooKeeper;}}public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState()); }运行结果:

1.2.2 操作节点
以下是Zookeeper原生客户端操作服务端的一些主要API:
- create(path, data, acl,createMode): 创建一个给定路径的 znode,并在 znode 保存 data[]的 数据,createMode指定 znode 的类型。
- delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除 znode。
- exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
- getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。
- setData(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置znode 数据。
- getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode 设置一个 watch。
- sync(path):把客户端 session 连接节点和 leader 节点进行同步。
API特点:
- 所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化。
- 所有更新 znode 数据的 API 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为 -1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响 应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来 自服务端的响应。
接下来,我们利用这些API对zk的节点进行简单的操作
1.2.2.1 创建持久节点
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);if(null ==stat){//创建持久节点zooKeeper.create("/order","001".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}System.out.println("执行完了");
}运行的结果:

我们在服务器的客户端查看一下数据:

有数据,创建成功了。
1.2.2.2 永久监听节点
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);//永久监听 addWatch -m modezooKeeper.addWatch("/order",new Watcher() {@Overridepublic void process(WatchedEvent event) {System.out.println(event);//TODO}},AddWatchMode.PERSISTENT);Thread.sleep(Integer.MAX_VALUE);
}启动程序后,在服务器的客户端修改监听的节点。
 程序监听到 /order这个节点被修改了。
程序监听到 /order这个节点被修改了。

1.2.2.3 根据版本更新
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);stat = new Stat();byte[] data = zooKeeper.getData("/order", false, stat);System.out.println(" data: "+new String(data));// -1: 无条件更新//zooKeeper.setData("/user", "third".getBytes(), -1);// 带版本条件更新int version = stat.getVersion();zooKeeper.setData("/order", "updateByVersion".getBytes(), version);Thread.sleep(Integer.MAX_VALUE);}}第一次打印的数据结果:

待程序执行完,在服务器客户端查询的结果:更具版本更新数据成功了。

对于zookeeper java原生客户端的使用,就简单介绍这么多,不在过多赘述,只是为了是让大家感受一下,原生客户端的使用。实际开发中并不推荐使用zk的原生客户端,过于笨重。
2. 开源的第三方客户端:Curator
2.1 简介
官网:https://curator.apache.org/
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册Watcher的问题以及NodeExistsException异常等。
Curator是Apache基金会的顶级项目之一,Curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。
Curator还为ZooKeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
在实际的开发场景中,使用Curator客户端就足以应付日常的ZooKeeper集群操作的需求。
2.2 基础使用
使用Curator我们需要引入依赖,官网上介绍到,Curator有多个 artifacts,使用者根据自己的需求,进行引入依赖。对于大多数使用者来说,引入curator-recipes就足够了。
Curator的几个重要包介绍:
curator-framework:是对ZooKeeper的底层API的一些封装。
curator-client:提供了一些客户端的操作,例如重试策略等。
curator-recipes:封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。

依赖: 以防Curator中的zookeeper版本和我们的服务端不匹配,我们需要排除Curator中的zookeeper的客户端,自己手动引入合适版本的zk的客户端。
<!-- zookeeper client --><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.3</version></dependency><!--curator--><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>5.1.0</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency>
2.2.1 连接zk集群
连接zk集群,我们需要创建一个客户端示例,然后启动客户端。创建客户端实例的方法有两种。
方法一:使用工厂类CuratorFrameworkFactory的静态newClient()方法。
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {// 重试策略RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);//创建客户端实例CuratorFramework client = CuratorFrameworkFactory.newClient(CLUSTER_CONNECT_STR, retryPolicy);//启动客户端client.start();Thread.sleep(Integer.MAX_VALUE);} }

方法二:使用工厂类CuratorFrameworkFactory的静态builder构造者方法。
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();Thread.sleep(Integer.MAX_VALUE);} }

参数解释:
connectionString:服务器地址列表,在指定服务器地址列表的时候可以是一个地址,也可以是多个地址。如果是多个地址,那么每个服务器地址列表用逗号分隔, 如 host1:port1,host2:port2,host3;port3 。
retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接ZooKeeper 服务端。而 Curator 提供了 一次重试、多次重试等不同种类的实现方式。在 Curator 内部,可以通过判断服务器返回的 keeperException 的状态代码来判断是否进行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR 表示系统或服务端错误。
超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。sessionTimeoutMs 作用在服务端,而 connectionTimeoutMs 作用在客户端。

2.2.2 节点操作
描述一个节点要包括节点的类型,即临时节点还是持久节点、节点的数据信息、节点是否是有序节点等属性和性质。接下来,我们逐一看一下利用Curator如何操作一个节点的。
2.2.2.1 创建节点
那么如何用Curator来创建一个节点呢?
在 Curator 中,可以使用 create 函数创建数据节点,并通过 withMode 函数指定节点类型(持久化节点,临时节点,顺序节点,临时顺序节点,持久化顺序节点等),默认是持久化节点,之后调用forPath 函数来指定节点的路径和数据信息。
第一步: 我们在服务器客户端,查看一下当前服务端有哪些节点

第二步:利用Curator创建一个持久节点,运行下述代码
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";// 检查节点是否存在Stat stat = curatorFramework.checkExists().forPath(path);if (stat != null) {// 删除节点curatorFramework.delete().deletingChildrenIfNeeded() // 如果存在子节点,则删除所有子节点.forPath(path); // 删除指定节点}// 创建节点curatorFramework.create().creatingParentsIfNeeded() // 如果父节点不存在,则创建父节点.withMode(CreateMode.PERSISTENT).forPath(path, "user".getBytes());Thread.sleep(Integer.MAX_VALUE);} }
第三步: 我们再次在服务器的客户端查看一下,节点创建成功了没有
创建了users和其子节点user成功。

如果我们需要创建有序节点,临时节点则只需要改变代码中的withMode的参数。具体参数如下:
PERSISTENT:持久节点
PERSISTENT_SEQUENTIAL:持久有序节点
EPHEMERAL:临时节点
EPHEMERAL_SEQUENTIAL:临时有序节点
CONTAINER:容器节点
PERSISTENT_WITH_TTL:持久TTL节点
PERSISTENT_SEQUENTIAL_WITH_TTL:持久有序TTL节点

2.2.2.2 更新节点
那么我们如何更新一个节点呢?
我们通过客户端实例的 setData() 方法更新 ZooKeeper 服务上的数据节点,在setData 方法的后边,通过 forPath 函数来指定更新的数据节点路径以及要更新的数据。
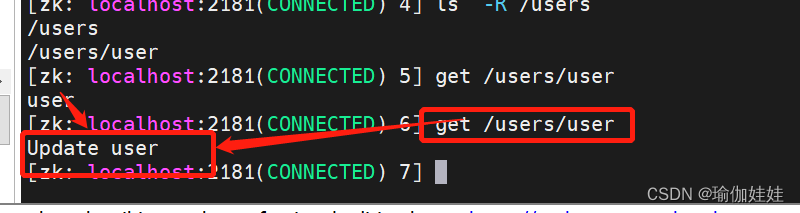
第一步:服务器端的客户端查看节点/users/user原始数据:

第二步:更改/users/user节点的数据,执行以下代码
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";// 更新节点数据 set //users/user Update usercuratorFramework.setData().forPath(path, "Update user".getBytes());Thread.sleep(Integer.MAX_VALUE);} }
第三步:再次使用服务器端的客户端查看/users/user的数据有没有更新成功
更新成功了。
2.2.2.3 查看节点
那么我们如何查看一个节点呢?
我们通过客户端实例的 getData() 方法更新 ZooKeeper 服务上的数据节点,在getData 方法的后边,通过 forPath 函数来指定查看的节点路径。
第一步: 服务器端的客户端查看/users/user的节点数据

第二步:执行以下代码,在java客户端,查看/users/user的数据
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";byte[] bytes = curatorFramework.getData().forPath(path);System.out.println("get data from node :{/users/user} successfully."+new String(bytes));Thread.sleep(Integer.MAX_VALUE);} }执行结果:

2.2.2.4 删除节点
那么我们如何删除一个节点呢?
我们通过客户端实例的 delete() 方法删除 ZooKeeper 服务上的数据节点,在delete方法的后边,通过 forPath 函数来指定删除的节点路径。
第一步:服务器端查看节点

第二步:执行以下代码 删除users节点
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";//删除节点curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(path);Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端查看节点是否还存在:users和其子节点user都被删除了

删除中一些函数含义:
guaranteed:该函数的功能如字面意思一样,主要起到一个保障删除成功的作用,其底层工作方式是:只要该客户端的会话有效,就会在后台持续发起删除请求,直到该数据节点在ZooKeeper 服务端被删除。
deletingChildrenIfNeeded:指定了该函数后,系统在删除该数据节点的时候会以递归的方式直接删除其子节点,以及子节点的子节点。
2.2.2.4 监听
Curator Caches:Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一个本地缓存视图与远程 Zookeeper 视图的对比过程。Cache 提供了反复注册的功能。Cache 分为两类注册类型:节点监听和子节点监听。
2.2.2.4.1 监听节点数据变化
第一步: 服务器端客户端查看数据

第二步: 启动以下代码,监听/user节点数据
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";// 创建节点缓存,用于监听指定节点的变化final NodeCache nodeCache = new NodeCache(curatorFramework, path);// 启动NodeCache并立即从服务端获取最新数据nodeCache.start(true);// 注册节点变化监听器nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {byte[] newData = nodeCache.getCurrentData().getData();System.out.println("Node data changed: " + new String(newData));}});Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端的客户端更新/users节点的数据,更改了4次

第四步:查看java客户端 监听到了数据

2.2.2.4.2 监听一级子节点
第一步服务器端客户端查看节点数据:

第二步: 执行以下代码,监听节点:
注意:PathChildrenCache 会对子节点进行监听,但是不会对二级子节点进行监听
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";// 创建PathChildrenCachePathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, path, true);pathChildrenCache.start();// 注册子节点变化监听器pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {if (event.getType() == PathChildrenCacheEvent.Type.CHILD_ADDED) {ChildData childData = event.getData();System.out.println("Child added: " + childData.getPath());} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_REMOVED) {ChildData childData = event.getData();System.out.println("Child removed: " + childData.getPath());} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_UPDATED) {ChildData childData = event.getData();System.out.println("Child updated: " + childData.getPath());}}});Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端增加子节点、修改子节点、删除子节点

第四步:查看java客户端控制台消息,监听到了对应修改

2.2.2.4.3 监听所有子节点
第一步:服务器端客户端查看节点:

第二步:执行以下代码,进行监听
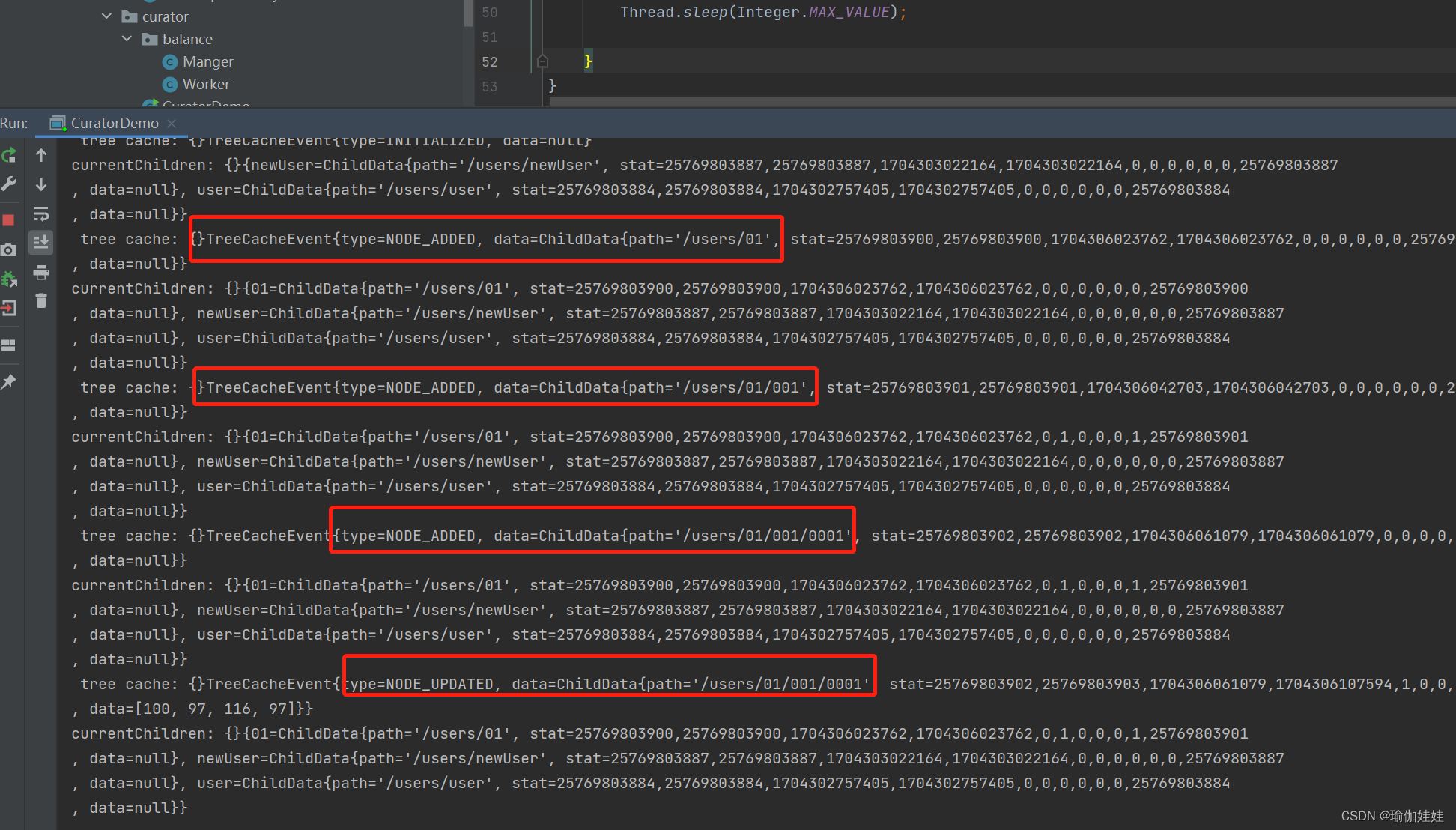
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";Stat stat = curatorFramework.checkExists().forPath(path);if (stat==null){String s = curatorFramework.create().forPath(path);}TreeCache treeCache = new TreeCache(curatorFramework, path);treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {System.out.println(" tree cache: {}"+event.toString());Map<String, ChildData> currentChildren = treeCache.getCurrentChildren(path);System.out.println("currentChildren: {}"+ currentChildren.toString());}});treeCache.start();Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端对节点进行一些操作

第四步:查看java客户端控制台信息:监听到了对应操作
3. 总结
以上是对zookeeper java客户端对zookeeper的基本操作,到此zookeeper java客户端的介绍到此为止,更详细的实践应用,后续会出一些zk常用场景是如何实现的文章。
相关文章:
Zookeeper之Java客户端实战
ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。可供选择的Java客户端API有: ZooKeeper官方的Java客户端API。第三方的Java客户端API,比如Curator。 接下来我们将逐一学习一下这两个java客户端是如何操作zookeeper的。 1. ZooKe…...

将文本文件导入Oracle数据库的简便方法:SQL Loader Express
需求 我有一个文本文件dbim.txt,是通过alert log生成的,内容如下: 2020-09-11 2020-09-11 ... 2023-12-03 2023-12-03 2023-12-26我已经在Oracle数据库中建立了目标表: create table dbim(a varchar(16));我想把日志文件导入Or…...
element-ui table-自定义表格某列的表头样式或者功能
自带表格 自定义表格某列的表头样式或者功能 <el-table><el-table-column :prop"date">//自定义表身每行数据<template slot-scope"scope">{{scope.row[scope.column.label] - ? - : scope.row[scope.column.label]}}</template>…...
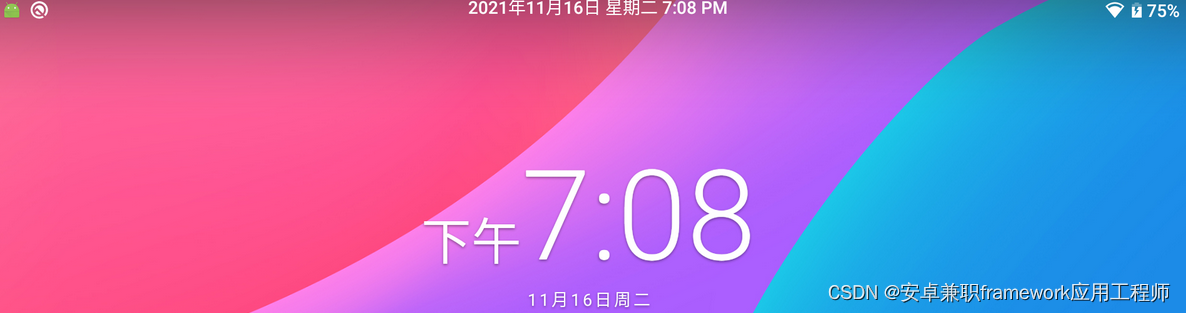
Android 13.0 SystemUI状态栏居中显示时间和修改时间显示样式
1.概述 在13.0的系统rom定制化开发中,在systemui状态栏系统时间默认显示在左边和通知显示在一起,但是客户想修改显示位置,想显示在中间,所以就要修改SystemUI 的Clock.java 文件这个就是管理显示时间的,居中显示的话就得修改布局文件了 效果图如下: 2.SystemUI状态栏居中显…...

讲解eureca和nacus的区别
Eureca和Nacus都是远程过程调用(RPC)框架,用于实现分布式系统中不同节点之间的通信。它们之间的主要区别如下: 架构设计:Eureca是一个基于JavaScript的RPC框架,它使用了WebSockets作为传输层协议。Eureca C…...
python中parsel模块的css解析
一、爬虫页面分类 1.想要爬取的内容全部在标签中,可以使用xpath去进行解析如下图 2.想要爬取的内容呈现json的数据特征,用.json()转换为字典格式 3.页面不规则,标签中包含大括号,如下面想要获取键值内容怎么做,先用re正…...
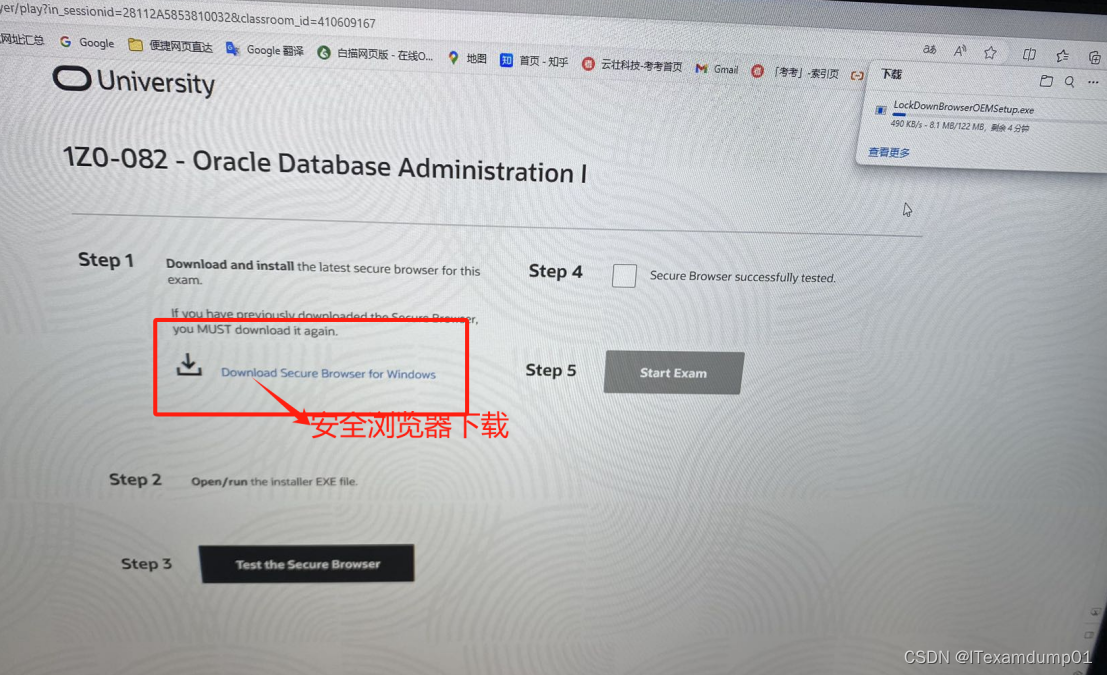
Oracle OCP怎么样线上考试呢
大家好!今天咱们就来聊聊Oracle OCP这个让人又爱又恨的认证。为啥说又爱又恨呢?因为它既是IT界的“金字招牌”,又是一块硬骨头,不是那么容易啃下来的。好了,废话不多说,我们直奔主题,来看看关于…...
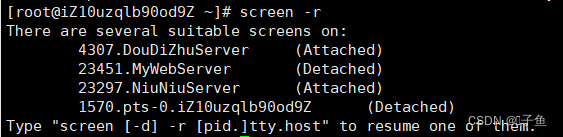
如何让自己的写的程序在阿里云一直运行
购买了阿里云服务器后,每次要用自己写在阿里云的服务器程序都要连接到云端 然后./运行该程序,而且每次一断开终端,该服务器就会自动停止,这样使用相当麻烦。那怎样才能让我们的服务器一直在云端后台运行,即便退出终端…...

【计算机图形学】NAP: Neural 3D Articulation Prior
文章目录 1. 这篇论文做了什么事,有什么贡献?2. Related Work铰接物体建模3D中的Diffusion model扩散模型 3. Pipeline铰接树参数化基于Diffusion的铰接树生成去噪网络 4. 实验评价铰接物体生成——以往做法与本文提出的新指标NAP捕捉到的铰接物体分布质…...

知识付费平台搭建?找明理信息科技,专业且高效
明理信息科技知识付费saas租户平台 在当今数字化时代,知识付费已经成为一种趋势,越来越多的人愿意为有价值的知识付费。然而,公共知识付费平台虽然内容丰富,但难以满足个人或企业个性化的需求和品牌打造。同时,开发和…...

CentOS7部署Kafka
CentOS7部署Kafka 一、部署1、前置条件2、下载与解压3、修改配置4、启动kafka二、使用详解1、创建一个主题2、展示所有主题3、启动消费端接收消息4、生产端发送消息三、代码集成pom.xmlapplication.propertiesKafkaConfiguration.javaKafkaConsumer.javaKafkaProducer.javaVehi…...
JS的防抖和节流
目录 防抖 搜索框带来的问题 实现的思路 案例 封装防抖函数 节流 滚动条加载带来的问题 实现的思路 案例 封装节流函数 防抖 搜索框带来的问题 需求:根据输入框内容来请求数据 <!DOCTYPE html> <html lang"en"> <head><…...
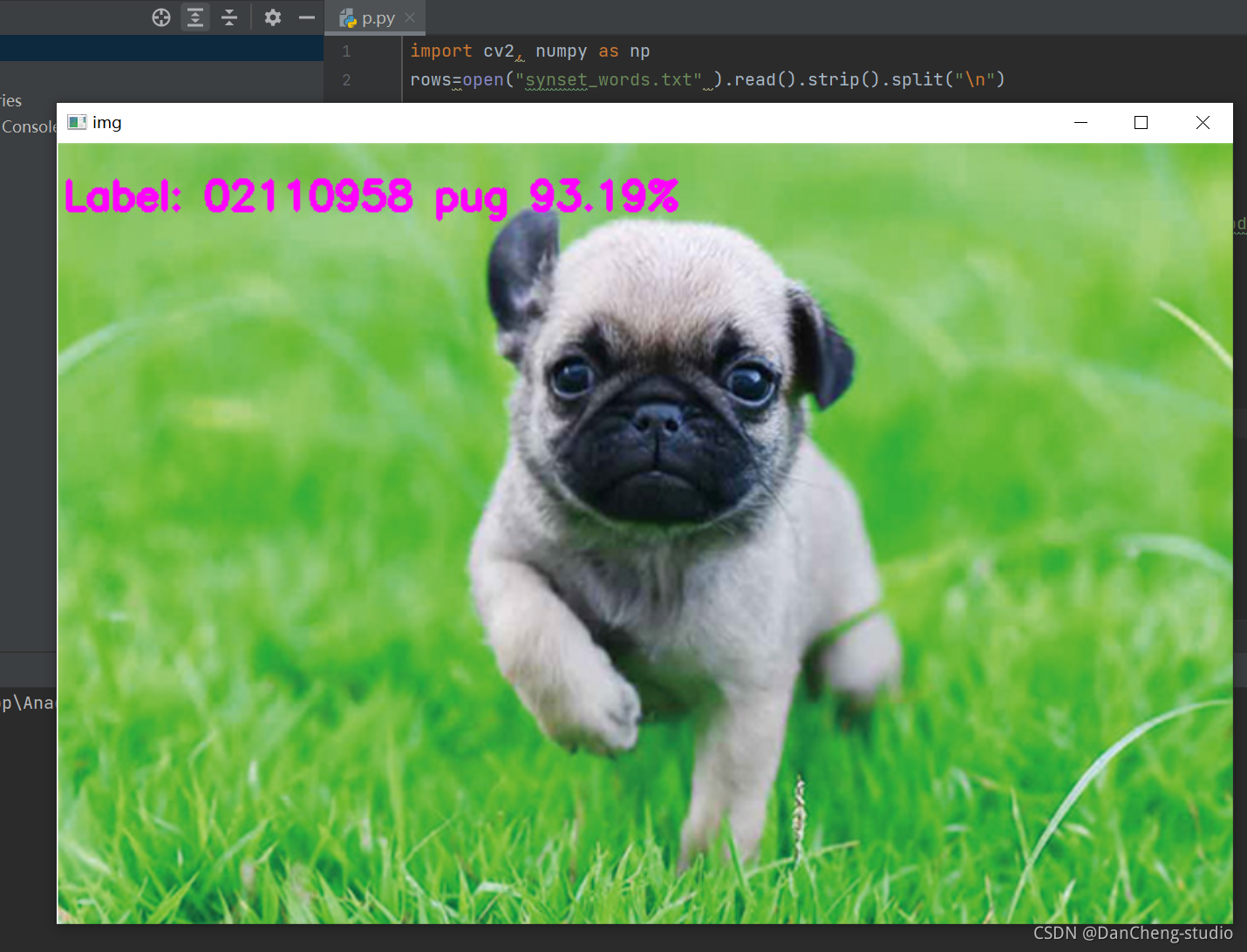
互联网加竞赛 基于人工智能的图像分类算法研究与实现 - 深度学习卷积神经网络图像分类
文章目录 0 简介1 常用的分类网络介绍1.1 CNN1.2 VGG1.3 GoogleNet 2 图像分类部分代码实现2.1 环境依赖2.2 需要导入的包2.3 参数设置(路径,图像尺寸,数据集分割比例)2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)2.5 数据预…...

pip安装报错SSL
confirming the ssl certificate: HTTPSConnectionPool(hostmirrors.cloud.tencent.com, port443) 错误代码如上 偶然搜索:ubuntu pip出错 confirming the ssl certificate: HTTPSConnectionPool(host‘mirrors.cloud.tencent.com’, port443) 看到这个回答 【日常踩…...
手机视频监控客户端APP如何实现跨安卓、苹果和windows平台,并满足不同人的使用习惯
目 录 一、手机视频监控客户端的应用和发展 二、手机视频监控客户端存在的问题 三、HTML5视频监控客户端在手机上实现的方案 (一)HTML5及其优点 (二)HTML5在手机上实现视频应用功能的优势 四、手机HTML5…...

从写下第1个脚本到年薪40W,我的自动化测试心路历程
我希望我的故事能够激励现在的软件测试人,尤其是还坚持在做“点点点”的测试人。 你可能会有疑问:“我也能做到这一点的可能性有多大?”因此,我会尽量把自己做决定和思考的过程讲得更具体一些,并尽量体现更多细节。 …...
Vue CLI组件通信
目录 一、组件通信简介1.什么是组件通信?2.组件之间如何通信3.组件关系分类4.通信解决方案5.父子通信流程6.父向子通信代码示例7.子向父通信代码示例8.总结 二、props1.Props 定义2.Props 作用3.特点4.代码演示 三、props校验1.思考2.作用3.语法4.代码演示 四、prop…...
C语言编译器(C语言编程软件)完全攻略(第九部分:VS2019使用教程(使用VS2019编写C语言程序))
介绍常用C语言编译器的安装、配置和使用。 九、VS2019使用教程(使用VS2019编写C语言程序) 继《八、VS2019下载地址和安装教程(图解)》之后,本节给大家讲解如何用 VS2019 编写并运行 C 语言程序。 例如,在…...

走向云原生 破局数字化
近年来,随着云计算概念和技术的普及,云原生一词也越来越热门,云原生成为云计算领域的新变量。行业内,华为、阿里巴巴、字节跳动等各个大厂都在“抢滩”云原生市场。行业外,云原生也逐渐出圈,出现在大众视野…...
springbean类)
spring常用注解(三)springbean类
一、Service用于标注业务层组件、 二、Repository用于标注数据访问组件,即DAO组件。 三、Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。(pojo) 四、Scope用于指定scope作用域的ÿ…...

快速迭代的 AI 应用项目如何借助 Taotoken 实现模型热切换与降级
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 快速迭代的 AI 应用项目如何借助 Taotoken 实现模型热切换与降级 在快速迭代的 AI 应用项目中,模型服务的稳定性与灵活…...

PowerPoint插件latex-ptt安装踩坑全记录:从‘无法下载’到‘点击报错’的保姆级排雷指南
LaTeX公式输入神器latex-ppt插件安装与排雷全攻略 在学术报告、技术分享或教学演示中,数学公式的呈现质量直接影响专业形象。虽然PowerPoint作为主流演示工具广受欢迎,但其原生公式编辑器功能有限,无法满足科研工作者对LaTeX公式排版的需求。…...

开源项目如何从“用爱发电”变成可持续收入?
一、为什么测试领域的开源项目更需要可持续收入?在测试领域,开源工具早已成为基础设施。从UI自动化的Selenium、移动端的Appium,到性能压测的JMeter、新一代端到端框架Playwright,几乎每个测试工程师的日常工作都构建在开源软件之…...

ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析
ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾渴望拥有额外的屏幕空间,却受限于物理显示…...

从入门到精通:trtexec命令行工具在TensorRT模型部署中的实战指南
1. trtexec工具基础入门 第一次接触trtexec时,我也被这个命令行工具的参数数量吓到了。但实际用下来发现,它就像瑞士军刀一样,虽然功能多但每个都很实用。trtexec是TensorRT安装包自带的命令行工具,主要用来做三件事:…...
)
别再死记硬背了!用Python手把手带你画一棵哈夫曼树(附完整代码)
用Python动态构建哈夫曼树:从理论到可视化的完整实践指南 在计算机科学中,数据压缩是一个永恒的话题。想象一下,当你需要传输大量数据时,如何用最少的比特数表示最多的信息?这就是哈夫曼编码要解决的问题。传统的教科书…...

Faust高级特性:窗口聚合与状态管理完整教程
Faust高级特性:窗口聚合与状态管理完整教程 【免费下载链接】faust Python Stream Processing. A Faust fork 项目地址: https://gitcode.com/gh_mirrors/faus/faust 掌握Faust的窗口聚合与状态管理功能,构建高效的Python流处理应用!&…...
)
仅限本周开放|DeepSeek Chat V3.2功能测试黄金 checklist(含17个边界Case+响应时延基线数据)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat V3.2功能测试黄金 checklist 发布说明 DeepSeek Chat V3.2 已正式面向开发者开放灰度测试,本次版本聚焦多模态理解增强、长上下文稳定性优化及企业级安全策略集成。为保障测试…...

CircuitPython displayio与触摸交互实战:复刻经典Neko猫咪动画
1. 项目概述与核心价值如果你玩过一些复古的掌机或者小型的嵌入式设备,可能会对屏幕上那只跟着你手指或光标跑的“Neko猫咪”有印象。这个源自上世纪经典屏保的小动画,在今天看来,依然是学习嵌入式图形和交互编程的绝佳入门项目。它麻雀虽小&…...

开发者技能图谱实战指南:从结构化知识到可执行代码的进阶之路
1. 项目概述:一个面向开发者的技能图谱与实战仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫GuDaStudio/skills。乍一看名字,你可能会觉得这又是一个普通的“技能清单”或者“学习路线图”项目。但点进去仔细研究后…...