debug mccl 02 —— 环境搭建及初步调试
1, 搭建nccl 调试环境
下载 nccl 源代码
git clone --recursive https://github.com/NVIDIA/nccl.git
只debug host代码,故将设备代码的编译标志改成 -O3
(base) hipper@hipper-G21:~/let_debug_nccl/nccl$ git diff
diff --git a/makefiles/common.mk b/makefiles/common.mk
index a037cf3..ee2aa8e 100644
--- a/makefiles/common.mk
+++ b/makefiles/common.mk
@@ -82,7 +82,8 @@ ifeq ($(DEBUG), 0)NVCUFLAGS += -O3CXXFLAGS += -O3 -gelse
-NVCUFLAGS += -O0 -G -g
+#NVCUFLAGS += -O0 -G -g
+NVCUFLAGS += -O3CXXFLAGS += -O0 -g -ggdb3endif修改后变成如下:
nccl$ vim makefiles/common.mk
ifeq ($(DEBUG), 0)
NVCUFLAGS += -O3
CXXFLAGS += -O3 -g
else
#NVCUFLAGS += -O0 -G -g
NVCUFLAGS += -O3
CXXFLAGS += -O0 -g -ggdb3
endif
构建 nccl shared library:
机器上是几张sm_85 的卡,故:
$ cd nccl
$ make -j src.build DEBUG=1 NVCC_GENCODE="-gencode=arch=compute_80,code=sm_80"到此即可,不需要安装nccl,直接过来使用即可;
2, 创建调试APP
在nccl所在的目录中创建app文件夹:
$ mkdir app$ cd app$ vim sp_md_nccl.cpp$ vim Makefilesp_md_nccl.cpp:
#include <stdlib.h>
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include <time.h>
#include <sys/time.h>#define CUDACHECK(cmd) do { \cudaError_t err = cmd; \if (err != cudaSuccess) { \printf("Failed: Cuda error %s:%d '%s'\n", \__FILE__,__LINE__,cudaGetErrorString(err)); \exit(EXIT_FAILURE); \} \
} while(0)#define NCCLCHECK(cmd) do { \ncclResult_t res = cmd; \if (res != ncclSuccess) { \printf("Failed, NCCL error %s:%d '%s'\n", \__FILE__,__LINE__,ncclGetErrorString(res)); \exit(EXIT_FAILURE); \} \
} while(0)void get_seed(long long &seed)
{struct timeval tv;gettimeofday(&tv, NULL);seed = (long long)tv.tv_sec * 1000*1000 + tv.tv_usec;//only second and usecond;printf("useconds:%lld\n", seed);
}void init_vector(float* A, int n)
{long long seed = 0;get_seed(seed);srand(seed);for(int i=0; i<n; i++){A[i] = (rand()%100)/100.0f;}
}void print_vector(float* A, float size)
{for(int i=0; i<size; i++)printf("%.2f ", A[i]);printf("\n");
}void vector_add_vector(float* sum, float* A, int n)
{for(int i=0; i<n; i++){sum[i] += A[i];}
}int main(int argc, char* argv[])
{ncclComm_t comms[4];printf("ncclComm_t is a pointer type, sizeof(ncclComm_t)=%lu\n", sizeof(ncclComm_t));//managing 4 devices//int nDev = 4;int nDev = 2;//int size = 32*1024*1024;int size = 16*16;int devs[4] = { 0, 1, 2, 3 };float** sendbuff_host = (float**)malloc(nDev * sizeof(float*));float** recvbuff_host = (float**)malloc(nDev * sizeof(float*));for(int dev=0; dev<nDev; dev++){sendbuff_host[dev] = (float*)malloc(size*sizeof(float));recvbuff_host[dev] = (float*)malloc(size*sizeof(float));init_vector(sendbuff_host[dev], size);init_vector(recvbuff_host[dev], size);}//sigma(sendbuff_host[i]); i = 0, 1, ..., nDev-1float* result = (float*)malloc(size*sizeof(float));memset(result, 0, size*sizeof(float));for(int dev=0; dev<nDev; dev++){vector_add_vector(result, sendbuff_host[dev], size);printf("sendbuff_host[%d]=\n", dev);print_vector(sendbuff_host[dev], size);}printf("result=\n");print_vector(result, size);//allocating and initializing device buffersfloat** sendbuff = (float**)malloc(nDev * sizeof(float*));float** recvbuff = (float**)malloc(nDev * sizeof(float*));cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));CUDACHECK(cudaMemcpy(sendbuff[i], sendbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));CUDACHECK(cudaMemcpy(recvbuff[i], recvbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));CUDACHECK(cudaStreamCreate(s+i));}//initializing NCCLNCCLCHECK(ncclCommInitAll(comms, nDev, devs));//calling NCCL communication API. Group API is required when using//multiple devices per threadNCCLCHECK(ncclGroupStart());printf("blocked ncclAllReduce will be calleded\n");fflush(stdout);for (int i = 0; i < nDev; ++i)NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum, comms[i], s[i]));printf("blocked ncclAllReduce is calleded nDev =%d\n", nDev);fflush(stdout);NCCLCHECK(ncclGroupEnd());//synchronizing on CUDA streams to wait for completion of NCCL operationfor (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaStreamSynchronize(s[i]));}for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaMemcpy(recvbuff_host[i], recvbuff[i], size*sizeof(float), cudaMemcpyDeviceToHost));}for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaStreamSynchronize(s[i]));}for(int i=0; i<nDev; i++) {printf("recvbuff_dev2host[%d]=\n", i);print_vector(recvbuff_host[i], size);}//free device buffersfor (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaFree(sendbuff[i]));CUDACHECK(cudaFree(recvbuff[i]));}//finalizing NCCLfor(int i = 0; i < nDev; ++i)ncclCommDestroy(comms[i]);printf("Success \n");return 0;
}Makefile:
INC := -I /usr/local/cuda/include -I ../nccl/build/include
LD_FLAGS := -L ../nccl/build/lib -lnccl -L /usr/local/cuda/lib64 -lcudartEXE := singleProc_multiDev_ncclall: $(EXE)%: %.cppg++ -g -ggdb3 $< -o $@ $(INC) $(LD_FLAGS).PHONY: clean
clean: -rm -rf $(EXE)export LD_LIBRARY_PATH=../nccl/build/lib
3, 开始调试
$ cuda-gdb sp_md_nccl(cuda-gdb) start (cuda-gdb) rbreak doLauches(cuda-gdb) c(cuda-gdb) p ncclGroupCommHead->tasks.collQueue.head->op 初步实现了可debug的效果:
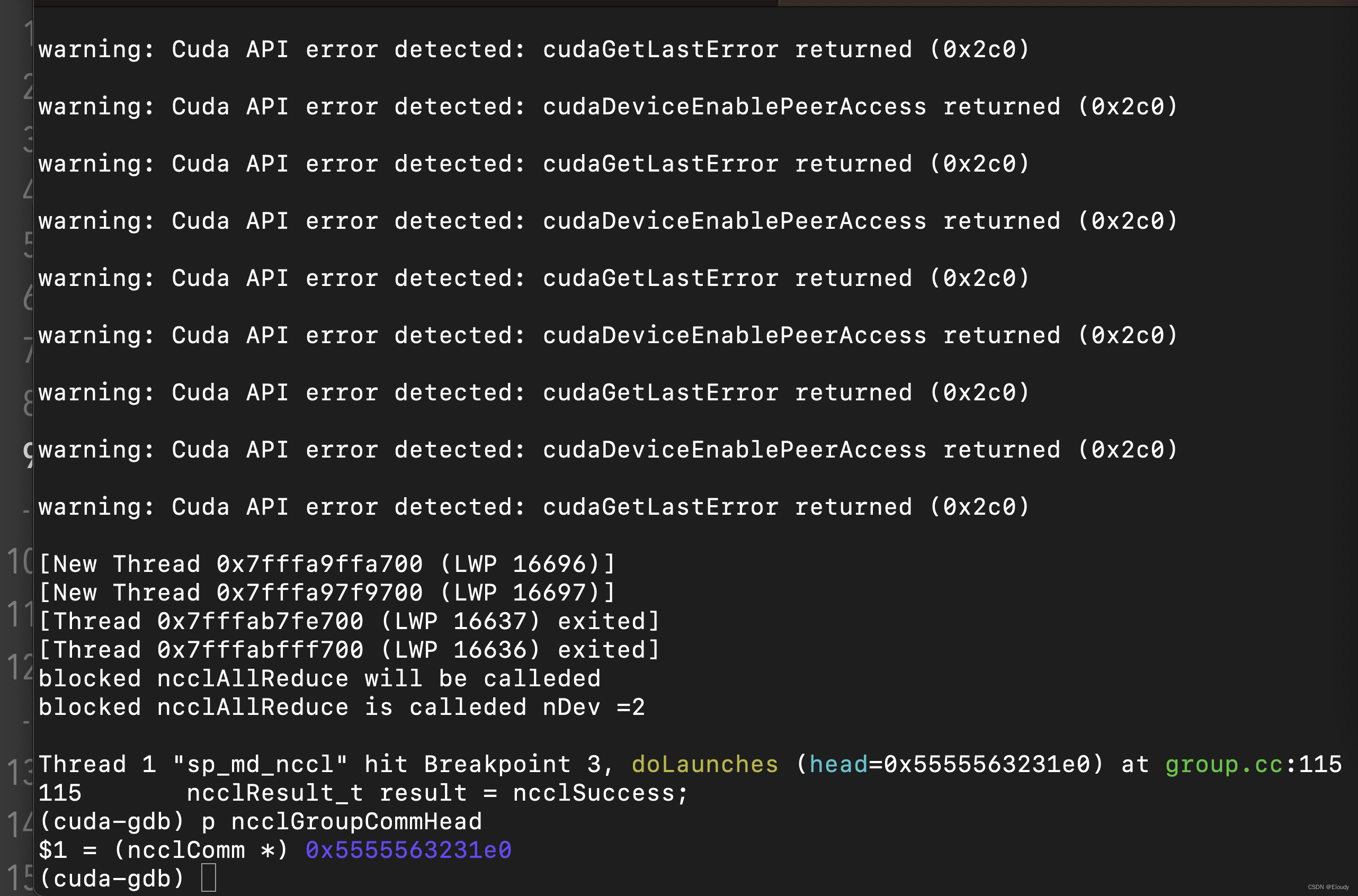
现在想要搞清楚在程序调用 ncclAllReduce(..., ncclSum, ... ) 后,是如何映射到 cudaLaunchKernel调用到了正确的 cuda kernel 函数的。
在doLaunches函数中,作如下debug动作:
查看 doLaunches(ncclComm*) 的函数参数,即,gropu.cc中的变量:ncclGroupCommHead的某个成员的成员的值:op
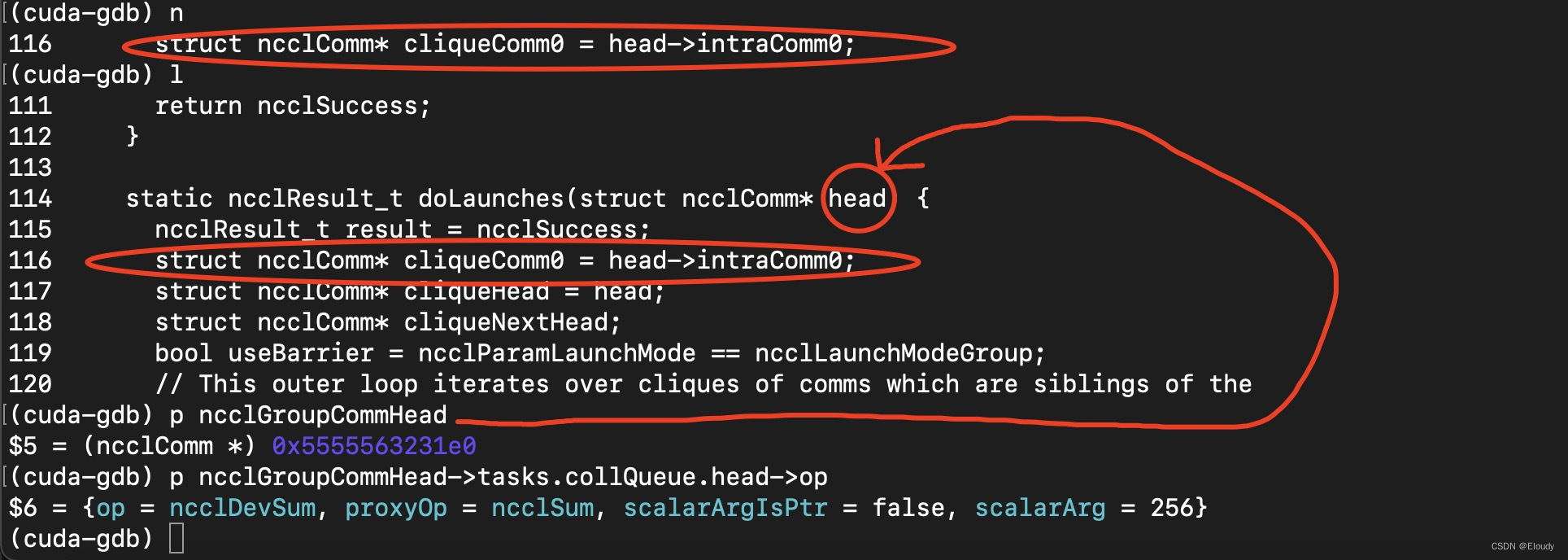
其结果如下:
(cuda-gdb) p ncclGroupCommHead
$5 = (ncclComm *) 0x5555563231e0
(cuda-gdb) p ncclGroupCommHead->tasks.collQueue.head->op
$6 = {op = ncclDevSum, proxyOp = ncclSum, scalarArgIsPtr = false, scalarArg = 256}
(cuda-gdb) 不过这依然只停留在了 ncclSum的这个枚举类型上,还没锁定对应的cudaKernel。
接下来继续努力 ...
相关文章:
debug mccl 02 —— 环境搭建及初步调试
1, 搭建nccl 调试环境 下载 nccl 源代码 git clone --recursive https://github.com/NVIDIA/nccl.git 只debug host代码,故将设备代码的编译标志改成 -O3 (base) hipperhipper-G21:~/let_debug_nccl/nccl$ git diff diff --git a/makefiles/common.mk b/makefiles/…...

ros python 接收GPS RTK 串口消息再转发 ros 主题消息
代码是一个ROS(Robot Operating System)节点,用于从GPS设备读取RTK(实时动态)数据并通过ROS主题发布。 步骤: 导入必要的模块: rospy 是ROS的Python库,用于ROS的节点、发布者和订阅者。serial 用于串行通信。NavSatFix 和 NavSatStatus 是从GPS接收的NMEA 0183标准消息…...

2024年网络安全竞赛-页面信息发现任务解析
页面信息发现任务说明: 服务器场景:win20230305(关闭链接)在渗透机中对服务器信息收集,将获取到的服务器网站端口作为Flag值提交;访问服务器网站页面,找到主页面中的Flag值信息,将Flag值提交;访问服务器网站页面,找到主页面中的脚本信息,并将Flag值提交;访问服务器…...

ARM DMA使用整理
Direct Memory Access, 直接存储访问。同SPI,IIC,USART等一样,属于MCU的一个外设,用于在不需要MCU介入的情况下进行数据传输。可以将数据从外设传输到flash,也可以将数据从flash传输到外设,或者flash内部数据移动。 它…...
移动通信原理与关键技术学习(第四代蜂窝移动通信系统)
前言:LTE 标准于2008 年底完成了第一个版本3GPP Release 8的制定工作。另一方面,ITU 于2007 年召开了世界无线电会议WRC07,开始了B3G 频谱的分配,并于2008 年完成了IMT-2000(即3G)系统的演进——IMT-Advanc…...

光明源@智慧厕所技术:优化生活,提升卫生舒适度
在当今数字科技飞速发展的时代,我们的日常生活正在经历一场革命,而这场革命的其中一个前沿领域就是智慧厕所技术。这项技术不仅仅是对传统卫生间的一次升级,更是对我们生活品质的全方位提升。从智能感应到数据分析,从环保设计到舒…...

【Bootstrap学习 day13】
Bootstrap5 下拉菜单 下拉菜单通常用于导航标题内,在用户鼠标悬停或单击触发元素时显示相关链接列表。 基础的下拉列表 <div class"dropdown"><button type"button" class"btn btn-primary dropdown-toggle" data-bs-toggl…...

Shell:常用命令之dirname与basename
一、介绍 1、dirname命令用于去除文件名中的非目录部分,删除最后一个“\”后面的路径,显示父目录。 语法:dirname [选项] 参数 2、basename命令用于打印目录或者文件的基本名称,显示最后的目录名或文件名。 语法:basen…...
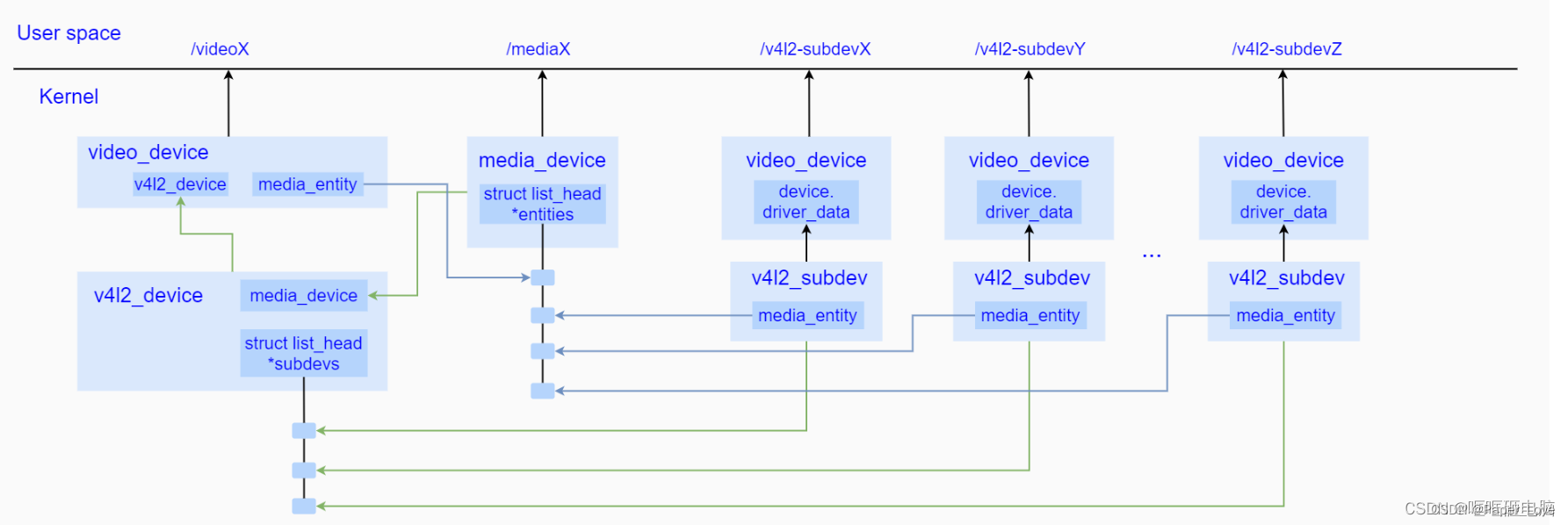
Linux-v4l2框架
框架图 从上图不难看出,v4l2_device作为顶层管理者,一方面通过嵌入到一个video_device中,暴露video设备节点给用户空间进行控制;另一方面,video_device内部会创建一个media_entity作为在media controller中的抽象体&a…...

VPC网络架构下的网络上数据采集
介绍 想象这样一个场景,一开始在公司里,所有的部门的物理机、POD都在一个经典网络内,它们可以通过 IP 访问彼此,没有任何限制。因此有很多系统基于此设计了很多点对点 IP 直连的访问,比如中心控制服务器 S 会主动访问物…...

模拟算法(模拟算法 == 依葫芦画瓢)万字
模拟算法 基本思想引入算法题替换所有的问号提莫攻击Z字形变换外观数列数青蛙 基本思想 模拟算法 依葫芦画瓢解题思维要么通俗易懂,要么就是找规律,主要难度在于将思路转换为代码。 特点:相对于其他算法思维,思路比较简单&#x…...

QtApplets-SystemInfo
QtApplets-SystemInfo 今天是2024年1月3日09:18:44,这也是2024年的第一篇博客,今天我们主要两件事,第一件,获取系统CPU使用率,第二件,获取系统内存使用情况。 这里因为写博客的这个本本的环境配置不…...

vue3防抖函数封装与使用,以指令的形式使用
utils/debounce.js /*** 防抖函数* param {*} fn 函数* param {*} delay 暂停时间* returns */ export function debounce(fn, delay 500) {let timer nullreturn function (...args) {// console.log(arguments);// const args Array.from(arguments)if (timer) {clearTim…...
Hive学习(13)lag和lead函数取偏移量
hive里面lag函数 在数据处理和分析中,窗口函数是一种重要的技术,用于在数据集中执行聚合和分析操作。Hive作为一种大数据处理框架,也提供了窗口函数的支持。在Hive中,Lag函数是一种常用的窗口函数,可以用于计算前一行…...

Centos Unable to verify the graphical display setup
ERROR: Unable to verify the graphical display setup. 在Linux下安装Oracle时 运行 ./runInstaller 报错 ERROR: Unable to verify the graphical display setup. This application requires X display. Make sure that xdpyinfo exist under PATH variable. No X11 DISPL…...

Java 说一下 synchronized 底层实现原理?
Java 说一下 synchronized 底层实现原理? synchronized 是 Java 中用于实现同步的关键字,它保证了多个线程对共享资源的互斥访问。底层实现涉及到对象头的 Mark Word 和锁升级过程。 synchronized 可以用于方法上或代码块上,分别对应于方法…...

nginx访问路径匹配方法
目录 一:匹配方法 二:location使用: 三:rewrite使用 一:匹配方法 location和rewrite是两个用于处理请求的重要模块,它们都可以根据请求的路径进行匹配和处理。 二:location使用: 1:简单匹配…...

偌依 项目部署及上线步骤
准备实验环境,准备3台机器 1.作为前端服务器,mysql,redis服务器--同时临时作为代码打包服务器 192.168.2.65 nginx-server 2.作为后端服务器 192.168.2.66 java-server-1 192.168.2.67 java-server-2 安装nginx/mysql #安装nginx [rootweb-nginx ~]…...

PHP特性知识点扫盲 - 上篇
概述 之前在分析thinkphp源码的时候,对依赖注入等等php高级的特性一直想做一个梳理和总结,一直没有时间,好不容易抽一点时间对技术的盲点做一个扫盲和总结。 特性 1.命名空间 命名空间是在PHP5.3中引入,是一个很重要的工具&am…...
Docker一键极速安装Nacos,并配置数据库!
1 部署方式 1.1 DockerHub javaedgeJavaEdgedeMac-mini ~ % docker run --name nacos \ -e MODEstandalone \ -e JVM_XMS128m \ -e JVM_XMX128m \ -e JVM_XMN64m \ -e JVM_MS64m \ -e JVM_MMS64m \ -p 8848:8848 \ -d nacos/nacos-server:v2.2.3 a624c64a1a25ad2d15908a67316d…...

Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面
Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面 【免费下载链接】sdow Six Degrees of Wikipedia 项目地址: https://gitcode.com/gh_mirrors/sd/sdow Six Degrees of Wikipedia(简称sdow)是一个基于维基百科页面…...

ORT Reporter输出格式全解析:生成SPDX、CycloneDX和静态HTML报告的终极指南
ORT Reporter输出格式全解析:生成SPDX、CycloneDX和静态HTML报告的终极指南 【免费下载链接】ort A suite of tools to automate software compliance checks. 项目地址: https://gitcode.com/gh_mirrors/or/ort ORT(Open Source Review Toolkit&…...

终极营销自动化工作流设计:工程师如何构建高效营销流程
终极营销自动化工作流设计:工程师如何构建高效营销流程 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers …...
)
认识Python网络套接字编程之流式套接字(一)
流式套接字当你需要使用 TCP 协议进行通信时,需要创建流式套接字。这是套接字编程中最常用的一种。光谈这些概念显得很抽象,还是举送外卖的这个例子,假设你点了一份烤鸭,外卖骑手需要先去店铺取餐,然后送到你的家门口&…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...
)
用Python+OpenCV搞定热红外与可见光图像自动对齐(附完整代码与避坑指南)
PythonOpenCV实战:热红外与可见光图像自动配准全流程解析 引言 在工业检测、安防监控、医疗诊断等领域,热红外与可见光图像的融合分析正成为关键技术。两种成像模式各具优势:可见光图像色彩丰富、细节清晰,而热红外图像则能揭示物…...

3D模型格式转换终极方案:用stltostp轻松实现STL到STEP的专业转换
3D模型格式转换终极方案:用stltostp轻松实现STL到STEP的专业转换 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾遇到这样的困境:3D打印的STL模型无法在专业CAD…...

网络安全新态势与应对策略
网络安全新态势与应对策略 在数字化浪潮席卷全球的今天,网络空间已成为国家竞争的新战场、经济发展的新引擎和社会生活的新空间。然而,伴随技术飞速发展的,是日益严峻和复杂的网络安全挑战。传统的边界防御模式在AI驱动的自动化攻击、无孔不…...

LILY-W131-00B,支持USB与SDIO双高速主机接口的IEEE 802.11b/g/n模块
简介今天我要向大家介绍的是 u-blox 的前端模块——LILY-W131-00B。这是一款专为高要求工业设备及蜂窝网络回传应用而设计的超紧凑高性价比模块。该模块基于高性能 NXP 88W8801 芯片组,支持 IEEE 802.11b/g/n 标准;具备外部天线引脚,支持天线…...

STM32CubeMX+STM32CubeIDE:STM32G030F6P6TR的免费开发生态入门
STM32G030F6P6TR:超值型Cortex-M0 MCU如何以最小封装实现64MHz性能突破在嵌入式系统设计中,“性价比”往往意味着在某些关键指标上的妥协——更小的封装通常伴随更低的主频或更少的外设。然而,STM32G0系列的推出打破了这一行业惯例。STM32G03…...