数据分析——快递电商
一、任务目标
1、任务
总体目的——对账
本项目解决同时使用多个快递发货,部分隔离区域出现不同程度涨价等情形下,如何快速准确核对账单的问题。
1、在订单表中新增一列【运费差异核对】来表示订单运费实际有多少差异,结果为数值。
2、将整个核对过程包装为一个OrderCheck类,方便后续直接调用它进行数据核对。
二、数据形式
1、图像呈现
账单形式
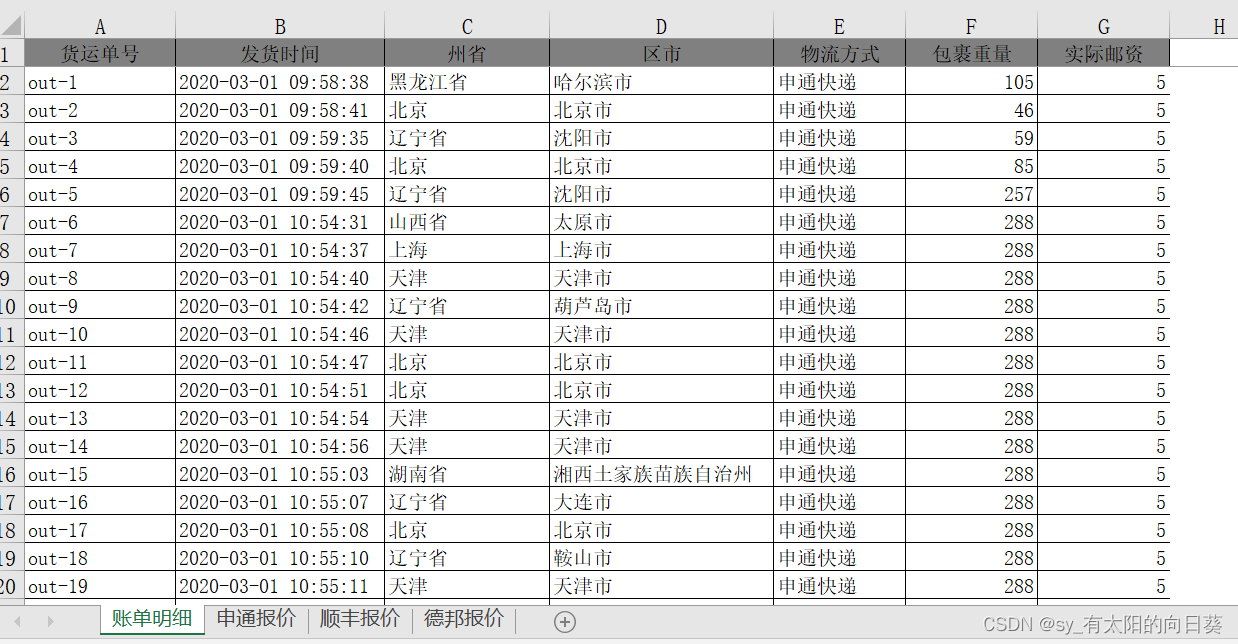
邮寄费(不同公司)
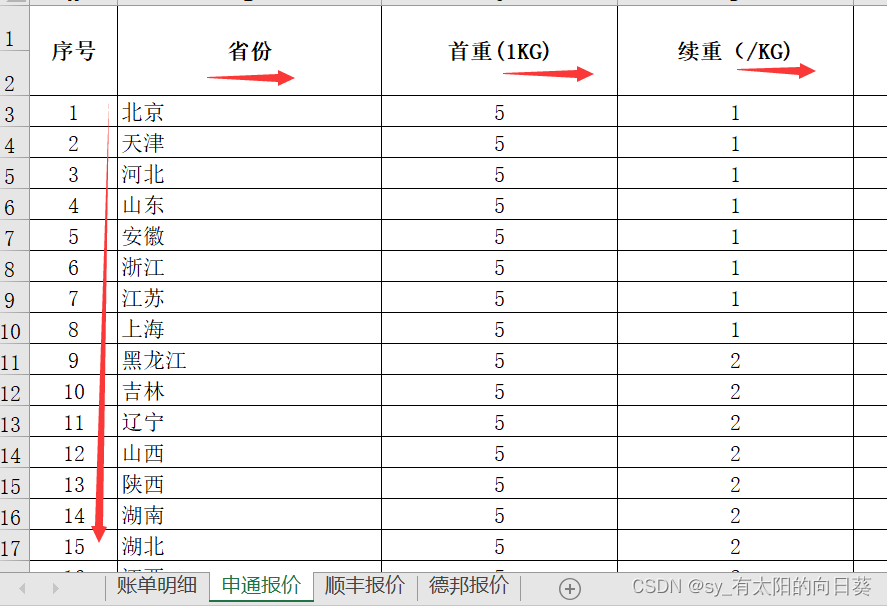
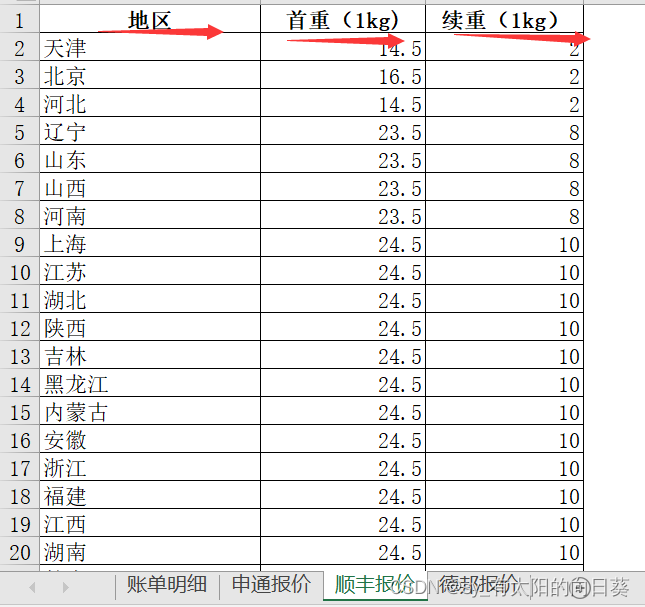
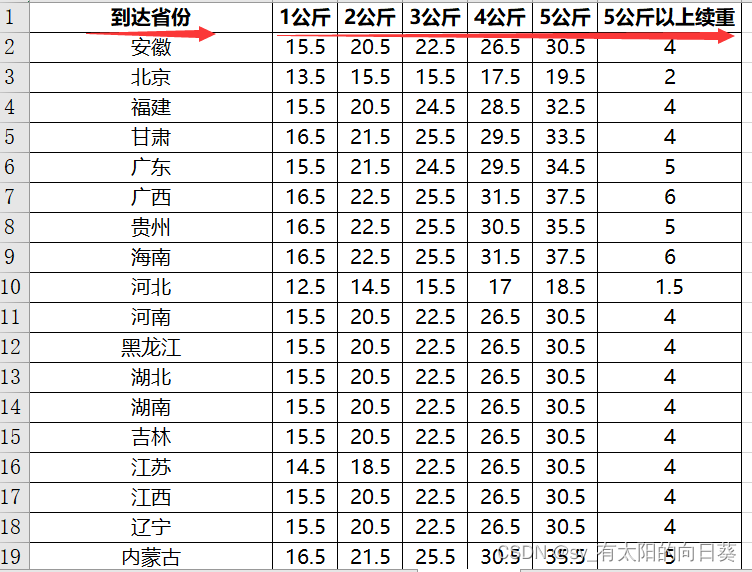
2、文字描述
一个excel文件中有四个表,第一张是账单形式,后面是不同公司的计费方式
每个公司的信息不同(如送达地址的描述、包裹重量单位等),需要统一
三、分析步骤
1、导入数据
3.1.1存在问题
问题一:
由于原数据表中有空格,或最后有总计、数据源等不规则信息导致的,需要进行处理


问题二:
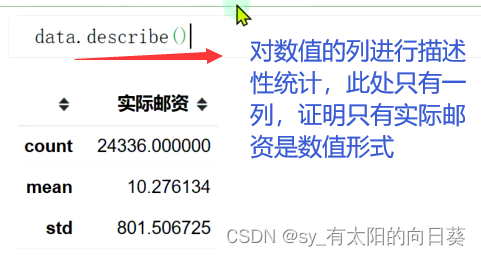
用describe()查看数值信息,发现只有邮资是纯数值,则需要对其他属性的数据进行数值转换
本数据源中,理应只有包裹重量和实际邮资是数值
但由于包裹重量的最后一行是单位(整个表最后的统计部分),不能被统计为数值

3.1.2解决方案
1、处理空行和空值
思路1:用loc定位删除空行
缺点:若新加入表,则行索引会改变,定位也就改变了
思路2:删除重复值
因为有三行空值,可先删除重复的空行
缺点:前面有数据的部分也许也会有重复值,容易导致数据缺失
思路3:统计每一行空值,判断需要删除的行






2、数据类型转换

3.1.3
语法扩展
2、数据处理
3.2.1计算运费
方法一:for循环算每一行
分析:根据地区、快递公司、重量计算运费
问题1:地区不统一
每个表的“地区”描述形式不一样



处理1:
1、读入所有表



2、统一各个表的名称
一张表:
reaname(,inplace=True)
![]()
多张表:


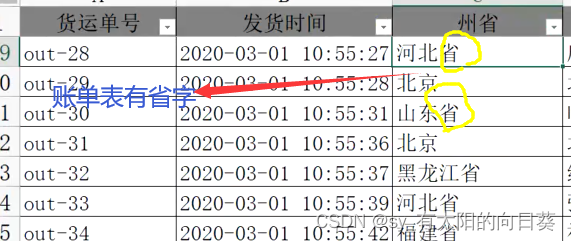
问题2:内容不统一
每个表省份的内容不一样

处理2:
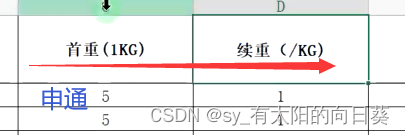
问题3:单位不统一
每个表首重续重的写法不同,需要统一
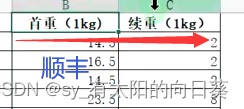
处理3:

问题4:时间是object型,而非数值型
不能直接用于时间的比较和计算,需要转换
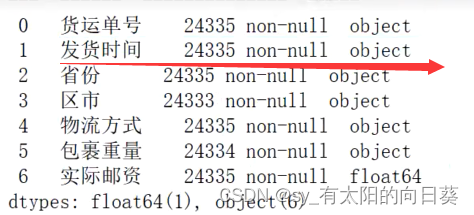
处理4:

进一步分析
1、取出所需数据
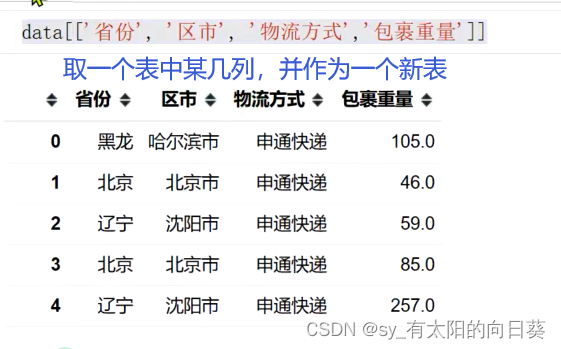



2、计算每一行的运费
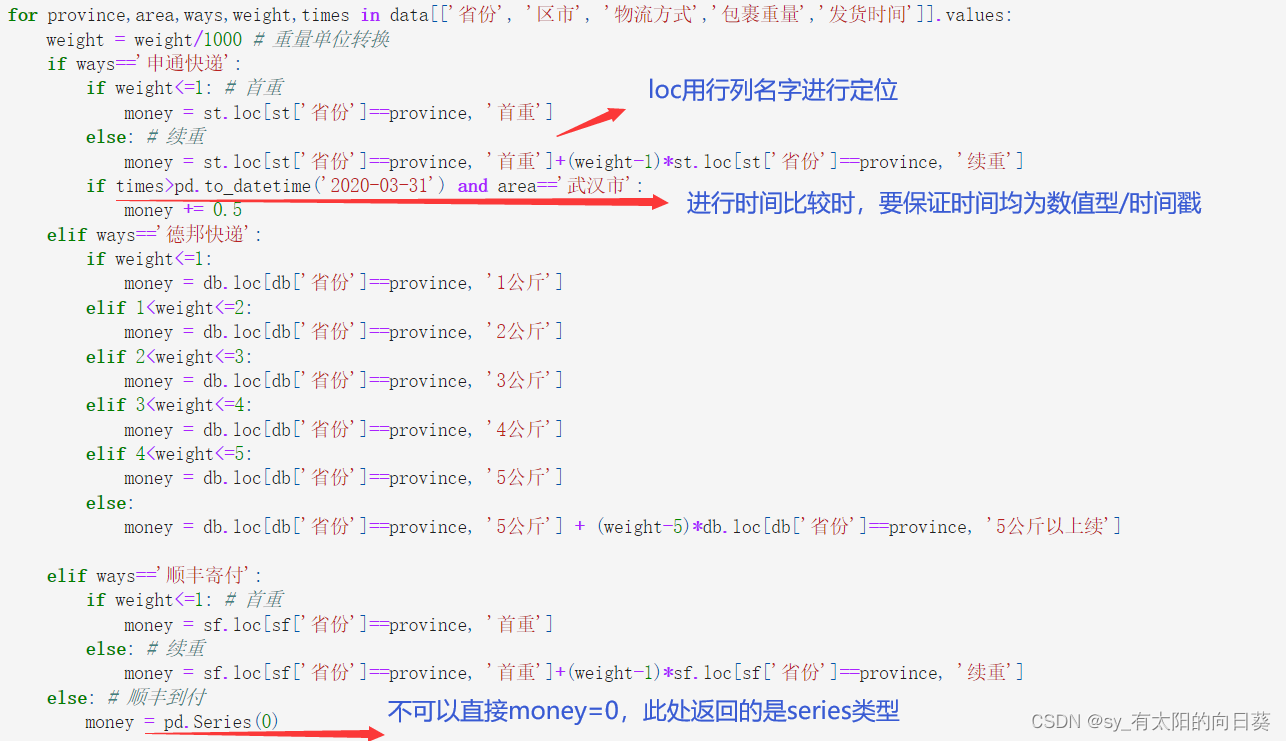
一个小问题,关于money的取值
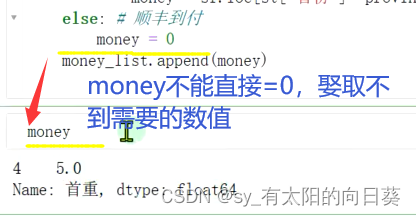

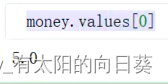
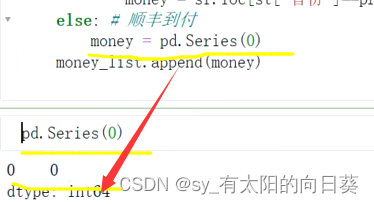

方法二:apply()算某一行
暂未开发
3、数据分析
3.3.1将计算结果放入一个列表
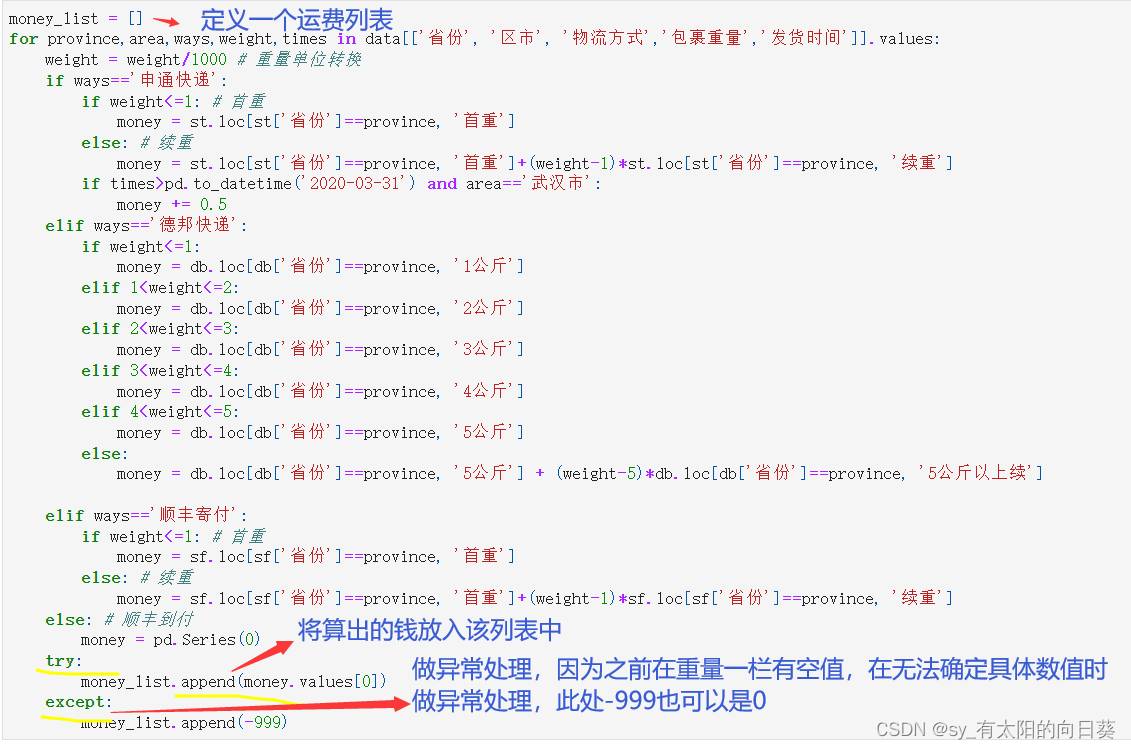
3.3.2将所需数据加入表中
4、封装类

5、运行检查得结论
1、调用

2、检查是否成功
3、数据异常
4、 核对后的数据
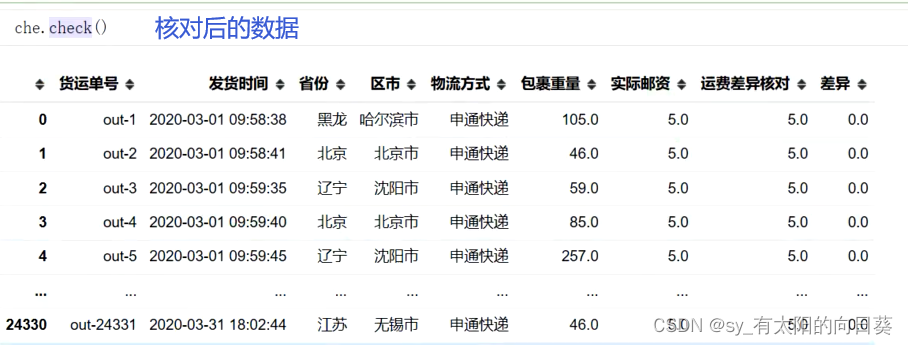
5、 存在差异的数据
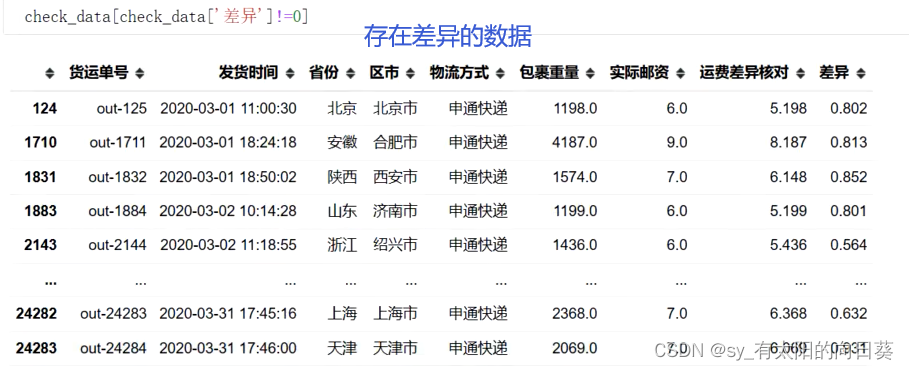
四、总体代码
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
datas = pd.read_excel('./data_check_transport_fee.xlsx', sheet_name=None)
datas.keys()# 各个表的名称处理
for k in datas.keys():datas[k].columns = ['省份' if '省' in i or '地' in i else i for i in datas[k].columns]# 各个表的省份名称处理 广东省---->广东
for k in datas.keys():datas[k]['省份'] = datas[k]['省份'].str[:2]#把每张表拿出来
data = datas['账单明细']
st = datas['申通报价']
sf = datas['顺丰报价']
db = datas['德邦报价']# 空行处理
data = data[data.isna().sum(axis=1)<5]
data.shap# 筛选有缺失的数据
ind = data.isna().sum(axis=1)>0
data[ind ]# 包裹在重量转为数值
data['包裹重量'] = data['包裹重量'].astype(float)# 修改首重续重列名称
st.rename(columns={'首重(1KG)':'首重', '续重(/KG)':'续重'}, inplace=True)
sf.rename(columns={'首重(1kg)':'首重', '续重(1kg)':'续重'}, inplace=True)# 修改时间格式
data['发货时间'] = pd.to_datetime(data['发货时间'] )money_list = []
for province,area,ways,weight,times in data[['省份', '区市', '物流方式','包裹重量','发货时间']].values:weight = weight/1000 # 重量单位转换if ways=='申通快递':if weight<=1: # 首重money = st.loc[st['省份']==province, '首重']else: # 续重money = st.loc[st['省份']==province, '首重']+(weight-1)*st.loc[st['省份']==province, '续重']if times>pd.to_datetime('2020-03-31') and area=='武汉市':money += 0.5elif ways=='德邦快递':if weight<=1:money = db.loc[db['省份']==province, '1公斤']elif 1<weight<=2:money = db.loc[db['省份']==province, '2公斤']elif 2<weight<=3:money = db.loc[db['省份']==province, '3公斤']elif 3<weight<=4:money = db.loc[db['省份']==province, '4公斤']elif 4<weight<=5:money = db.loc[db['省份']==province, '5公斤']else: money = db.loc[db['省份']==province, '5公斤'] + (weight-5)*db.loc[db['省份']==province, '5公斤以上续']elif ways=='顺丰寄付':if weight<=1: # 首重money = sf.loc[sf['省份']==province, '首重']else: # 续重money = sf.loc[sf['省份']==province, '首重']+(weight-1)*sf.loc[sf['省份']==province, '续重']else: # 顺丰到付money = pd.Series(0)try:money_list.append(money.values[0])except:money_list.append(-999)#把数据加入表中
data['运费差异核对'] = money_list
data['差异'] = data['实际邮资'] - data['运费差异核对']#定义类和函数
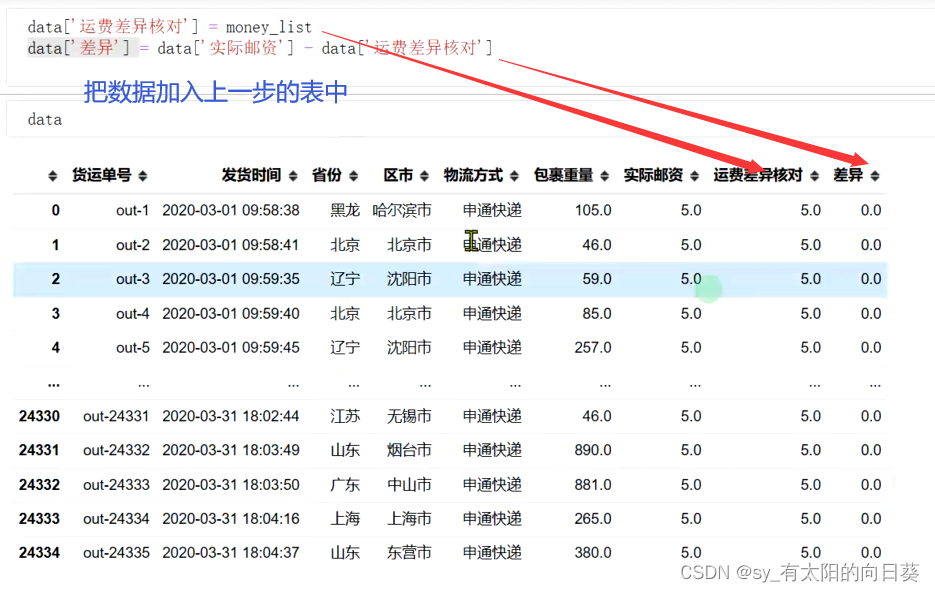
# 定义一OrderCheck, 返回异常数据、核对异常的数据、核对正常数据
class OrderCheck():def __init__(self, root):self.root = rootself.data, self.st, self.sf, self.db = self.prepare_data()def prepare_data(self,):datas = pd.read_excel(self.root, sheet_name=None)## 各个表的名称处理for k in datas.keys():datas[k].columns = ['省份' if '省' in i or '地' in i else i for i in datas[k].columns]## 各个表的省份名称处理 广西壮族自治区-->广西 for k in datas.keys():datas[k]['省份'] = datas[k]['省份'].str[:2]data = datas['账单明细']st = datas['申通报价']sf = datas['顺丰报价']db = datas['德邦报价']## 空行处理data = data[data.isna().sum(axis=1)<5]## 包裹在重量转为数值data['包裹重量'] = data['包裹重量'].astype(float)## 修改首重续重列名称st.rename(columns={'首重(1KG)':'首重', '续重(/KG)':'续重'}, inplace=True)sf.rename(columns={'首重(1kg)':'首重', '续重(1kg)':'续重'}, inplace=True)# 修改时间格式data['发货时间'] = pd.to_datetime(data['发货时间'] )return data,st,sf,dbdef get_bad_data(self): # 返回异常数据# 筛选有缺失的数据ind = self.data.isna().sum(axis=1)>0return self.data[ind]def check(self):data, st, sf, db = self.prepare_data()money_list = []for province,area,ways,weight,times in data[['省份', '区市', '物流方式','包裹重量','发货时间']].values:weight = weight/1000 # 重量单位转换if ways=='申通快递':if weight<=1: # 首重money = st.loc[st['省份']==province, '首重']else: # 续重money = st.loc[st['省份']==province, '首重']+(weight-1)*st.loc[st['省份']==province, '续重']if times>pd.to_datetime('2020-03-31') and area=='武汉市':money += 0.5elif ways=='德邦快递':if weight<=1:money = db.loc[db['省份']==province, '1公斤']elif 1<weight<=2:money = db.loc[db['省份']==province, '2公斤']elif 2<weight<=3:money = db.loc[db['省份']==province, '3公斤']elif 3<weight<=4:money = db.loc[db['省份']==province, '4公斤']elif 4<weight<=5:money = db.loc[db['省份']==province, '5公斤']else: money = db.loc[db['省份']==province, '5公斤'] + (weight-5)*db.loc[db['省份']==province, '5公斤以上续']elif ways=='顺丰寄付':if weight<=1: # 首重money = sf.loc[sf['省份']==province, '首重']else: # 续重money = sf.loc[sf['省份']==province, '首重']+(weight-1)*sf.loc[sf['省份']==province, '续重']else: # 顺丰到付money = pd.Series(0)try:money_list.append(money.values[0])except:money_list.append(-999)data['运费差异核对'] = money_listdata['差异'] = data['实际邮资'] - data['运费差异核对']return data #调用一下
che = OrderCheck('./data_check_transport_fee.xlsx')#检查路径和是否成功
che.root
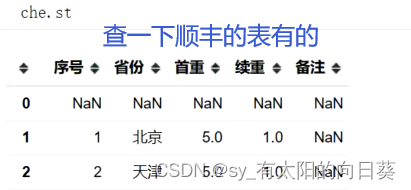
che.st#查看异常数据
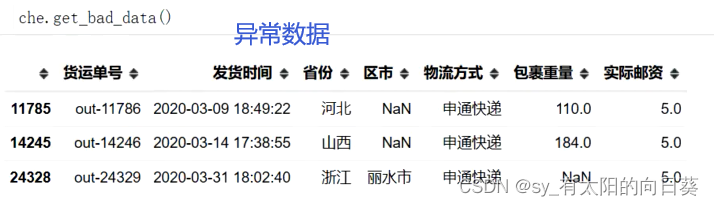
che.get_bad_data()#查看核对数据
check_data = che.check()#查看差异存在的数据
check_data[check_data['差异']==0]五、总结
5.1难点总结
1、异常值处理
询问业务、手动填补、try
2、名称、内容、单位、数值类型的统一
3、重量计算
用定位实现,要注意取不到最后一行的需要+1
4、类的书写和函数定义
取值需要多尝试,要清楚的判断数值类型,输出类型,用value或多套data,或者分开取
5.2方案总结
5.2.1思维总结
1、对于订单、账单等含有多种数值、涉及计算的数据源,需要多次用info()查看数据类型,确保类型为纯数值,方便后续处理
2、拿到数据源后,要根据目标or要得到的分析结果,判断表中的有效信息数据为哪些,并取出来
3、找表之间的关系时,想到表连接,或内容匹配(如:河北省与河北,都有河北二字,就取相同值)
5.2.2方法总结
1、数值转换
2、空值处理
isna()
3、将数据加入列表再加入表
4、数值获取
········太多了都在上面了
相关文章:
数据分析——快递电商
一、任务目标 1、任务 总体目的——对账 本项目解决同时使用多个快递发货,部分隔离区域出现不同程度涨价等情形下,如何快速准确核对账单的问题。 1、在订单表中新增一列【运费差异核对】来表示订单运费实际有多少差异,结果为数值。 2、将…...
《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(8)
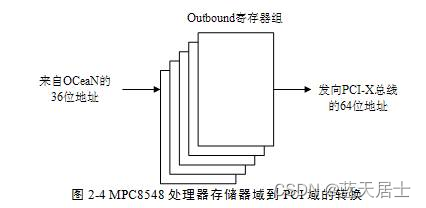
接前一篇文章:《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(7) 2.2 HOST主桥 MPC8548处理器的拓扑结构如图2-2所示: 2.2.2 存储器域地址空间到PCI总线域地址空间的转换 MPC8548处理器使用ATMUÿ…...
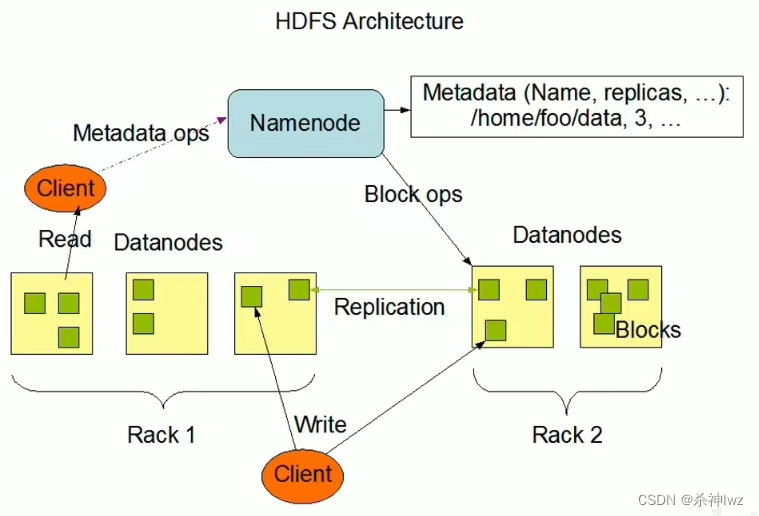
Hadoop分布式文件系统(二)
目录 一、Hadoop 1、文件系统 1.1、文件系统定义 1.2、传统常见的文件系统 1.3、文件系统中的重要概念 1.4、海量数据存储遇到的问题 1.5、分布式存储系统的核心属性及功能含义 2、HDFS 2.1、HDFS简介 2.2、HDFS设计目标 2.3、HDFS应用场景 2.4、HDFS重要特性 2.4…...
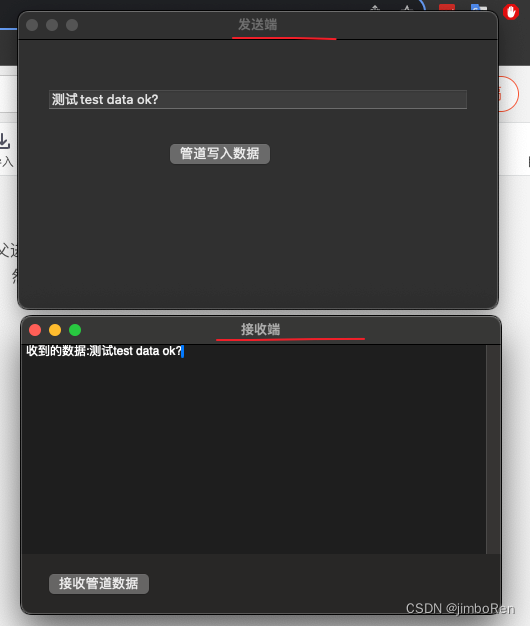
macOS跨进程通信: FIFO(有名管道) 创建实例
一: 简介 在类linux系统中管道分为有名管道和匿名管道。两者都能单方向的跨进程通信。 匿名管道(pipe): 必须是父子进程之间,而且子进程只能由父进程fork() 出来的,才能继承父进程的管道句柄,一般mac 开发…...
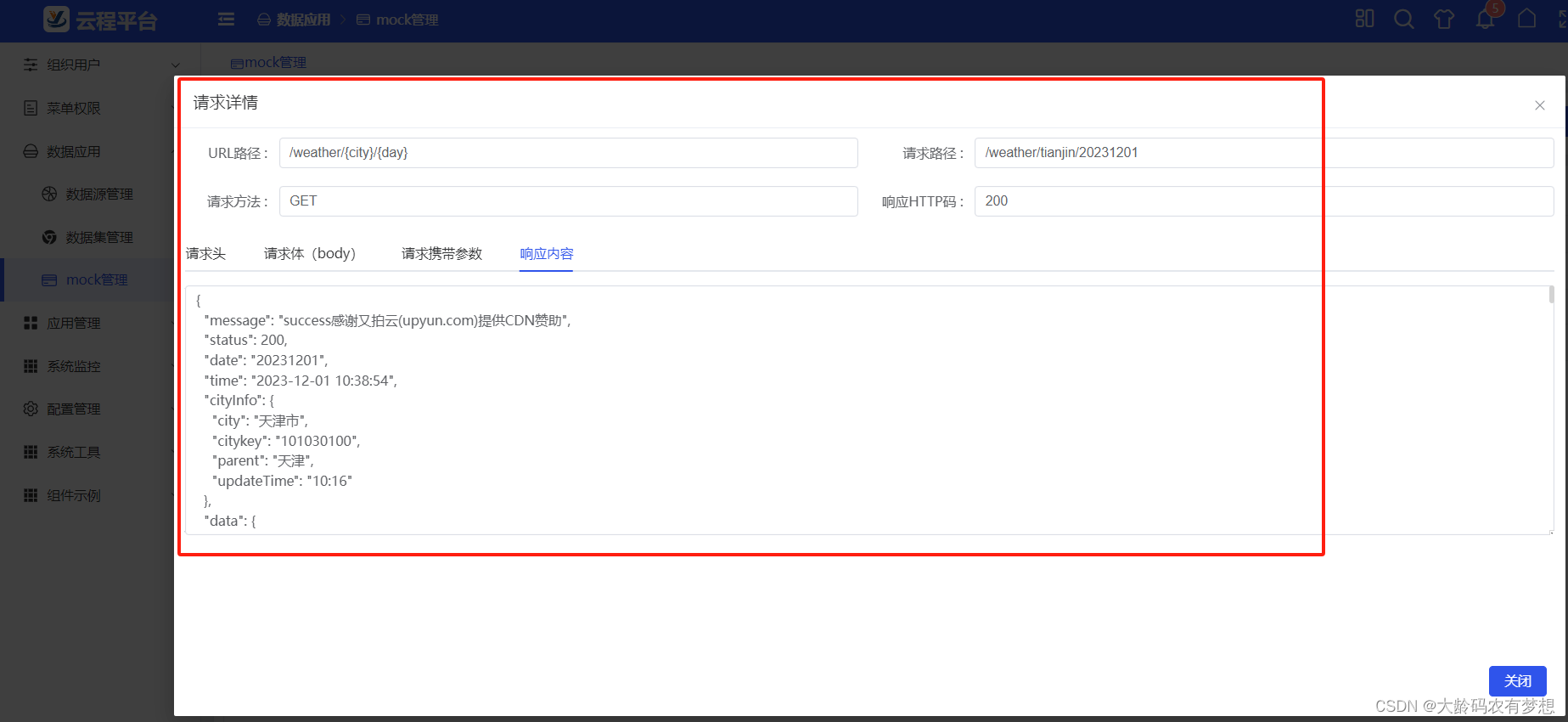
推荐几个免费的HTTP接口Mock网站和工具
在前后端分离开发架构下,经常遇到调用后端数据API接口进行测试、集成、联调等需求,比如: (1)前端开发人员很快开发完成了UI界面,但后端开发人员的API接口还没有完成,不能进行前后端数据接口对接…...

企业数据库安全管理规范
1.目的 为规范数据库系统安全使用活动,降低因使用不当而带来的安全风险,保障数据库系统及相关应用系统的安全,特制定本数据库安全管理规范。 2.适用范围 本规范中所定义的数据管理内容,特指存放在信息系统数据库中的数据。 本…...

react:ffcreator中FFCreatorCenter视频队例
最近项目要求,一键生成房子的推荐视频,选几张图,加上联系人的方式就是一个简单的视频,因为有web端、小程序端,为了多端口用,决定放在服务器端生成。 目前用的是react中的nextjs来开发项目。 nextjs中怎样…...
第434题字符串中的单词数(Python))
力扣(leetcode)第434题字符串中的单词数(Python)
434.字符串中的单词数 题目链接:434.字符串中的单词数 统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。 请注意,你可以假定字符串里不包括任何不可打印的字符。 示例: 输入: “Hello, my name is John” 输出: 5 解释: 这…...
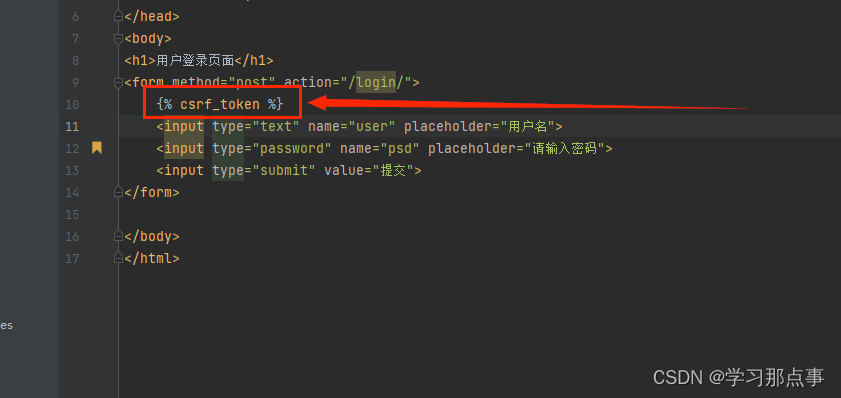
django学习:页面渲染与请求和响应
1.请求过程 2.页面渲染 在app中新建一个目录(Directory),文件名命名为templates。该文件名命名是固定的,不可命名出错,如若后续步骤出错,该目录文件名是一个检查的重点项目。在该目录下新建一个html文件&a…...

Redis 数据一致性
概述 当我们在使用缓存时,如果发生数据变更,那么你需要同时操作缓存和数据库,而它们两个又分属不同的系统,因此无法做到同时操作成功或失败,因此在并发读写下很可能出现缓存与数据库数据不一致的情况 理论上可以通过…...
Mac环境下反编译apk
Mac环境下反编译apk 安装反编译工具dex2jar:[官网下载](https://sourceforge.net/projects/dex2jar/)JD-GUI:[官网下载](https://jd-gui.apponic.com/) 实操1. 将需要反编译的 .apk 文件放在下载的 dex2jar 文件夹目录下2. 使用 cd /xxx/dex2jar-2.0 命令…...

计算机网络——网络模型的组织、看法以及标准化流程
1. 通信技术和标准化领域中扮演重要角色的组织 1.1 国际和国家官方标准化机构 OSI:国际标准化组织(ISO),负责国际标准的制定,旨在确保全球产品和服务的安全性、可靠性和效率。它有许多国家分支机构,包括法…...

【JAVA】volatile 关键字的作用
🍎个人博客:个人主页 🏆个人专栏: JAVA ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 volatile 的作用: 结语 我的其他博客 前言 在多线程编程中,保障数据的一致性和线程之间的可见性是…...
Next.js 第一次接触
因为需要整个漂亮的在线文档,所以接触了next.js,因为对前端js本身不够熟悉,别说对react.js 又不会,时间又不允许深入研究,所以,为了加一个导航菜单,极其痛苦。 有点小bug,不过不影响…...

CISSP 第7章:PKI和密码学应用
第七章 PKI和密码学应用 7.1 非对称密码学 对称密码系统具有共享的秘钥系统,从而产生了安全秘钥分发的问题 非对称密码学使用公钥和私钥对,无需支出复杂密码分发系统 7.1.1 公钥与私钥 7.1.2 RSA(兼具加密和数字签名) RSA算法依赖…...
ROS中创建dji_sdk节点包(二)实现代码)
dji uav建图导航系列()ROS中创建dji_sdk节点包(二)实现代码
在前文 【dji uav建图导航系列()ROS中创建dji_sdk节点包(一)项目结构】中简单介绍了项目的结构,和一些配置文件的代码。本文详细说明目录src下的节点源代码实现。 文章目录 1、代码结构2、PSDK部分3、ROS部分3.1、头文件3.1.1、外部调用 node_service.h3.1.2、节点类定义…...

数字化工厂产品推荐 带OPC UA的分布式IO模块
背景 近年来,为了提升在全球范围内的竞争力,制造企业希望自己工厂的机器之间协同性更强,自动化设备采集到的数据能够发挥更大的价值,越来越多的传统型工业制造企业开始加入数字化工厂建设的行列,实现智能制造。 数字化…...

使用OHOS SDK构建opus
参照OHOS IDE和SDK的安装方法配置好开发环境。 从github下载源码。 执行如下命令: git clone --depth1 https://github.com/xiph/opus进入源码所在的目录,创建批处理文件ohos_build.cmd,内容如下: echo off setlocalset OHOS_…...
K-means 聚类算法分析
算法简述 K-means 算法原理 我们假定给定数据样本 X ,包含了 n 个对象 ,其中每一个对象都具有 m 个维度的属性。而 K-means 算法的目标就是将 n 个对象依据对象间的相似性聚集到指定的 k 个类簇中,每个对象属于且仅属于一个其到类簇中心距离…...

uniapp获取定位
Uniapp 是一种跨平台应用开发框架,它能够快速地构建出针对不同平台的应用程序。在Uniapp中,实现定位功能也变得十分简单,只需要简单的配置就能轻松实现。 一、高德地图根据指定位置获取经纬度 参考地址:地理/逆地理编码-基础 API…...

Nexus:RAG 时代终结?编译器 AI 知识层来了
最近 Pinecone 发布了一个新东西:**Nexus。**最早我是在抖音上看到的,说实话,这种标题挺吓人的,低劣但有效,我都忍不住要点进去: RAG 时代终结了。向量数据库不够用了。Agent 需要 Knowledge Engine。因为…...

为AI智能体设计的任务管理后端:构建标准化、机器友好的任务元模型
1. 项目概述:一个为AI而生的待办清单最近在折腾各种AI工具链和自动化流程时,我遇到了一个挺普遍的问题:如何让AI助手,比如ChatGPT、Claude或者本地部署的大语言模型,更好地理解并管理我手头一堆零散、动态的任务&#…...

GPT-4 API交互式实验场:开发者如何自建安全可控的Playground
1. 项目概述:一个面向开发者的GPT-4交互式实验场如果你是一名开发者,或者对大型语言模型(LLM)的应用开发感兴趣,那么你很可能已经不止一次地思考过:如何能更高效、更直观地测试GPT-4的API能力?如…...

多脉冲重复频率解速度模糊:原理、仿真与MATLAB实现
1. 脉冲雷达的速度模糊问题 雷达测速的基本原理大家都懂,就是通过多普勒效应计算目标速度。但实际操作中会遇到一个头疼的问题——速度模糊。这就像用卷尺量身高,如果身高超过卷尺长度,就得把几段卷尺接起来量,但接缝处容易出错。…...

Smart-10 多模光时域反射仪:铁路高速光纤故障首选
铁路、高速公路通信光纤线路长、环境复杂,精准检测与故障定位是运维关键。Smart-10 多模光时域反射仪集成 OTDR、光功率计、红光源等功能,为交通行业光纤运维提供高效、可靠的解决方案。Smart-10 多模光时域反射仪是一款一体化光纤综合测试仪,…...

别再手动拼接URL了!若依集成JimuReport报表,一个优雅的Token传递方案
若依系统与JimuReport深度集成:Token安全传递的架构实践 在当今企业级应用开发中,报表功能是不可或缺的核心模块,而如何将第三方报表系统无缝集成到现有框架中,同时确保认证体系的安全性与一致性,一直是开发者面临的挑…...

MOXA NPort 5110串口服务器避坑指南:网线直连、波特率设置与Web管理那些事儿
MOXA NPort 5110串口服务器实战避坑手册:从硬件部署到批量管理的深度解析 第一次接触工业级串口服务器时,我对着那个巴掌大的金属盒子发呆了十分钟——RJ45、DB9、电源接口密密麻麻挤在一起,配套光盘里还有三个不同功能的配置工具。直到现场调…...

告别单一地图!用BIGEMAP叠加ArcGIS Online和OpenStreetMap,打造你的专属作业底图
告别单一地图!用BIGEMAP叠加ArcGIS Online和OpenStreetMap,打造你的专属作业底图 在GIS专业领域,单一地图源往往难以满足复杂分析需求。当我们需要同时兼顾权威数据和社区更新时,如何将不同特性的地图源智能叠加,成为提…...

Chrome QRCode插件终极指南:如何在3分钟内实现跨设备无缝内容同步
Chrome QRCode插件终极指南:如何在3分钟内实现跨设备无缝内容同步 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维…...

利用 Taotoken 多模型聚合能力优化内容生成流水线的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型聚合能力优化内容生成流水线的实践 对于内容创作团队而言,不同题材和创作阶段往往需要不同特长的…...