K-means 聚类算法分析
算法简述
K-means 算法原理
我们假定给定数据样本 X ,包含了 n 个对象 ,其中每一个对象都具有 m 个维度的属性。而 K-means 算法的目标就是将 n 个对象依据对象间的相似性聚集到指定的 k 个类簇中,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中。对于 K-means 算法,首先需要初始化 k 个聚类中心
, 然后通过计算每一个对象到每一个聚类中心的欧式距离,如下式所示:
这里的 表示第i个对象
,
表示第 j 个聚类中心
,
表示第i个对象的第t个属性,
,
表示第j个聚类中心的第t个属性。
依次比较每一个对象到每一个聚类中心的距离,将对象分配到距离最近的聚类中心的类簇中,得到k个类簇,kmeans 算法定义了类簇的原型,类簇中心就是类簇内所有对象在各个维度的均值,其计算公式如下所示:
式中, 表示第l个聚类中心,
,
表示第l个类簇中对象的个数,
表示第l个类簇中第i个对象,
算法实现流程
- 随机设置 K 个特征空间内的点作为初始的聚类中⼼。
- 对于其他每个点计算到 K 个中⼼的距离,未知的点选择最近的⼀个聚类中⼼点作为标记类别。
- 接着对着标记的聚类中⼼之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中⼼点与原中⼼点⼀样(质⼼不再移动),那么结束,否则重新进⾏第⼆步过程。
核心代码
手写实现 K-means 算法:
import numpy as np
import random
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
"""
手写实现Kmeans
"""
data = np.genfromtxt("classes.txt", delimiter='\t')
X = data
K = 5
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
max_iterations = 10000
random.seed(100)
def kmeans(data, K, max_iterations):initial_centers = random.sample(list(data), K)centers = initial_centersfor iteration in range(max_iterations):clusters = {i: [] for i in range(K)}for point in data:distances = [np.linalg.norm(point - center) for center in centers]cluster_index = np.argmin(distances)clusters[cluster_index].append(point)new_centers = [np.mean(clusters[i], axis=0) for i in range(K)]if np.all(np.array_equal(centers[i], new_centers[i]) for i in range(K)):breakcenters = new_centersreturn centers, clustersfinal_centers, final_clusters = kmeans(X, K, max_iterations)
for i in range(K):cluster = np.array(final_clusters[i])plt.scatter(cluster[:, 0], cluster[:, 1], c=colors[i], label=f'簇 {i + 1}')centers = np.array(final_centers)
plt.scatter(centers[:, 0], centers[:, 1], c='k', marker='x', s=100, label='簇中心')plt.xlabel('高度')
plt.ylabel('宽度')
plt.legend()
plt.show()
调用 sklearn 包的 K-means 算法:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
"""
调用sklearn库的Kmeans算法
"""
data = np.genfromtxt("classes.txt", delimiter='\t')
X = data
K = 3
num_experiments = 5
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
for i in range(num_experiments):kmeans = KMeans(n_clusters=K, init='k-means++', random_state=i)kmeans.fit(X)print(f"实验 {i + 1} - 初始中心: {kmeans.cluster_centers_}")kmeans = KMeans(n_clusters=K, init='k-means++', random_state=0)
kmeans.fit(X)labels = kmeans.labels_clustered_data = {i: [] for i in range(K)}
for i, label in enumerate(labels):clustered_data[label].append(X[i])for i in range(K):cluster = np.array(clustered_data[i])plt.scatter(cluster[:, 0], cluster[:, 1], c=colors[i], label=f'簇 {i + 1}')centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='k', marker='x', s=100, label='簇中心')plt.xlabel('高度')
plt.ylabel('宽度')
plt.legend()
plt.show()手写实现 K-means 的算法流程:
- 随机选择 initial centers:从数据集中随机选择 K 个数据点,作为 initial centers。
- 计算距离:对于每个数据点,计算它与当前的 K 个 centers 之间的距离。
- 分配数据点:将每个数据点分配到最近的 center 所对应的集合中。
- 更新 centers:将每个集合的中心点更新为集合中的均值。
- 重复步骤 2-4:直到 centers 不再发生变化,或者达到最大迭代次数。
- 返回 centers 和 clusters:返回最终的 centers 和 clusters。
实验结果与分析
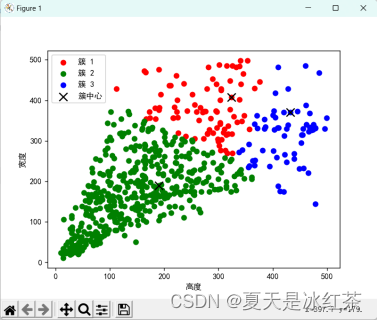
使用 python 手写实现 K-means 算法效果(假设 K=3 的时候):
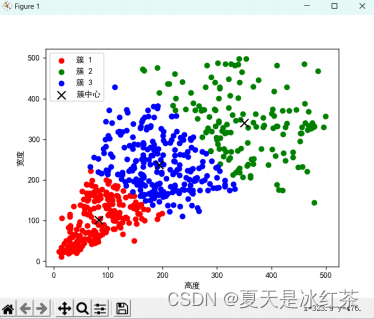
使用 sklearn 中的 K-means 算法效果(假设 K=3 的时候):
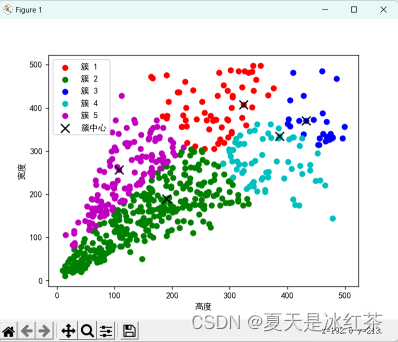
使用 python 手写实现 K-means 算法效果(假设 K=5 的时候):
这里使用了 Python 手写实现 K-means 算法,并与 scikit-learn 库中的K-means 算法进行了比较。结果发现手写实现的 K-means 算法的效果与scikit-learn 库中的 K-means 算法相似,都可以很好地聚集数据点。
结论与心得体会
K-means 算法是一种常用的聚类算法,可以用来分组数据点 K 个聚类。在本实验中,我们使用了 VOC 数据集中的 600 张图像,并将每个图像的边界框标注为一个数据点。这里使用了 K-means 算法将这些数据点聚集到 K 个聚类中。
classes.txt文件:
201 158
171 330
94 137
300 180
175 250
190 265
150 146
222 274
102 372
213 122
19 43
202 297
163 348
174 356
29 53
31 81
85 105
77 159
102 140
333 482
148 229
97 200
133 186
52 76
256 306
411 332
30 115
151 202
164 233
283 328
394 237
107 153
151 128
99 139
118 318
240 311
420 371
153 188
75 148
54 52
197 326
14 34
196 250
295 374
230 167
206 161
105 164
41 28
119 108
328 360
252 414
279 429
135 251
101 156
75 169
123 311
238 298
132 157
79 64
15 106
52 172
159 327
82 90
82 252
273 305
281 211
205 291
456 330
223 372
199 118
116 162
231 212
19 25
334 346
68 222
116 179
165 206
222 461
91 277
36 25
86 155
162 251
173 372
255 228
74 171
296 440
118 158
288 271
120 87
31 87
300 206
131 195
69 109
71 186
300 298
330 190
222 187
56 135
192 276
95 300
209 166
100 309
455 315
38 42
89 177
303 401
277 200
216 357
221 246
130 106
232 263
340 498
126 213
162 343
465 221
130 280
144 223
499 356
35 60
260 372
64 153
181 161
55 153
42 78
182 295
178 333
460 485
121 354
142 227
299 304
194 147
478 332
236 441
132 108
56 45
242 374
30 73
40 27
46 57
230 228
251 221
217 356
104 264
108 150
26 35
172 275
261 199
17 30
272 197
324 408
10 24
76 45
160 215
274 373
248 201
128 104
311 329
413 176
267 382
160 331
255 175
97 224
306 240
367 252
198 219
222 260
214 292
225 358
66 167
146 137
96 344
353 498
167 100
287 191
445 373
372 331
474 328
117 185
386 334
124 202
74 68
27 83
405 418
57 121
214 225
166 469
347 362
209 437
251 302
188 167
30 110
155 198
227 225
231 290
314 188
13 20
243 206
23 51
385 330
26 31
164 280
355 235
385 353
77 184
148 288
82 134
220 309
366 341
150 104
126 318
163 473
37 135
315 485
187 242
339 484
236 177
159 176
339 402
260 274
145 277
231 237
246 270
158 117
49 139
276 373
60 167
281 482
60 190
191 382
325 317
252 298
147 235
64 71
67 127
280 318
212 437
184 165
165 288
61 188
290 319
62 115
301 232
478 144
254 169
106 123
70 70.1
100 223
97 130
96 282
201 309
110 183
99 214
159 186
92 266
82 150
151 248
226 319
100 113
195 192
471 326
202 238
98 216
478 331
159 160
402 374
220 138
239 261
248 176
108 118
297 372
155 287
30 57
192 163
19 23
112 429
363 251
83 173
134 373
341 440
309 321
190 476
120 149
67 233
30 35
102 196
68 188
62 158
305 425
196 178
184 354
121 140
165 243
121 320
314 315
198 170
190 376
215 184
193 114
148 161
138 222
262 203
301 487
361 210
87 216
183 381
318 337
401 275
64 55
43 49
254 137
316 270
439 268
41 32
155 133
223 175
46 50
142 161
381 276
71 199
81 55
184 287
304 276
162 213
81 59
341 229
85 63
187 275
74 256
121 109
167 354
160 200
346 466
202 320
289 453
303 182
422 266
49 56
156 194
267 124
333 178
173 127
185 178
326 485
177 280
222 245
313 277
99 152
74 98
410 188
148 51
161 140
428 428.1
318 317
65 117
496 330
255 166
274 245
100 114
158 138
74 130
184 273
260 204
90 67
150 246
126 96
190 233
170 324
301 288
356 292
462 340
297 332
48 97
343 349
57 131
110 79
58 70
253 226
23 25
466 323
179 260
198 215
341 219
76 66
324 255
218 170
376 446
88 216
146 338
280 265
216 298
222 185
268 175
194 414
118 214
273 234
62 149
366 239
181 188
258 198
42 20
224 401
30 22
108 257
139 285
428 339
140 162
92 90
314 184
263 206
180 170
246 223
127 67
403 327
189 273
280 317
288 272
56 118
77 72
38 27
468 368
96 164
169 149
240 190
219 383
232 135
136 366
145 306
361 206
165 209
305 428
105 232
305 222
182 139
108 141
32 38
123 83
425 247
201 261
61 133
88 88.1
400 364
100 191
109 107
122 92
107 340
329 213
152 133
147 130
57 134
251 187
31 57
449 231
347 207
164 292
314 199
175 198
48 63
74 76
121 120
98 81
52 38
106 163
298 230
344 278
249 201
432 371
43 23
82 220
152 92
236 111
190 189
228 173
134 322
290 246
82 48
220 182
40 65
338 272
103 302
453 315
138 200
339 224
165 128
184 155
256 389
407 259
293 180
264 351
283 175
334 218
303 345
127 139
166 252
70 51
175 166
439 256
247 257
321 448
207 204
271 370
164 261
306 303
303 342
155 118
405 358
177 330
96 71
420 174
62 87
76 57
475 340
163 190
167 164
177 238
190 104
357 329
97 77
163 213
46 38
43 34
49 37
113 99
421 313
32 31
410 482
128 173
366 430
39 29
457 232
36 66
485 468
118 112
89 77
132 107
233 304
425 330
112 79
102 117
452 295
71 48
46 89
267 229
85 163
326 269
161 214
409 332
299 180
49 29
116 118
209 137
264 132
273 269
162 105
202 171
70 163
97 170
286 355
323 174
117 161
117 214
223 220
138 95
110 100
468 333
57 55
168 186
27 19
189 220
141 134
371 362
46 30
253 280
135 106
321 377
68 65
182 260
126 218
162 165
111 125
312 258
357 238
461 388
240 176
177 150
156 116
321 250
31 43
65 52
186 183
163 160
147 196
82 64
219 214
101 131
247 154
70 42
37 31
113 186
145 171
14 11
相关文章:
K-means 聚类算法分析
算法简述 K-means 算法原理 我们假定给定数据样本 X ,包含了 n 个对象 ,其中每一个对象都具有 m 个维度的属性。而 K-means 算法的目标就是将 n 个对象依据对象间的相似性聚集到指定的 k 个类簇中,每个对象属于且仅属于一个其到类簇中心距离…...

uniapp获取定位
Uniapp 是一种跨平台应用开发框架,它能够快速地构建出针对不同平台的应用程序。在Uniapp中,实现定位功能也变得十分简单,只需要简单的配置就能轻松实现。 一、高德地图根据指定位置获取经纬度 参考地址:地理/逆地理编码-基础 API…...
Python 面向对象之反射
Python 面向对象之反射 【一】概念 反射是指通过对象的属性名或者方法名来获取对象的属性或调用方法的能力反射还指的是在程序额运行过程中可以动态获取对象的信息(属性和方法) 【二】四个内置函数 又叫做反射函数 万物皆对象(整数、字符串、函数、模块、类等等…...
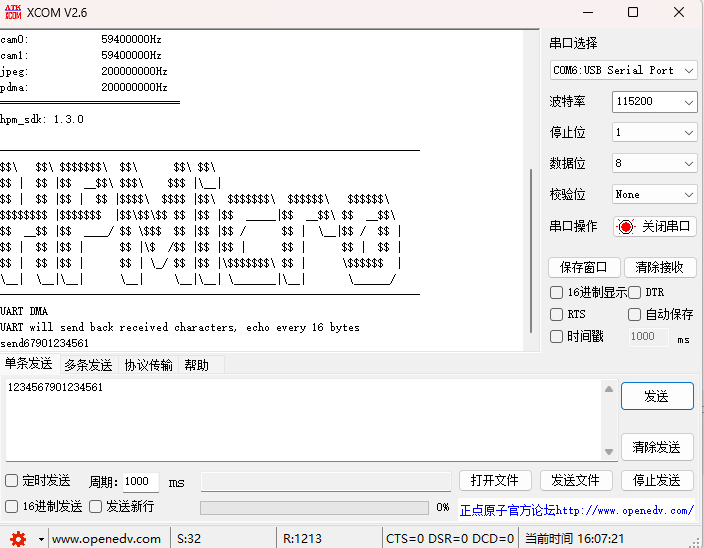
HPM6750开发笔记《DMA接收和发送数据UART例程深度解析》
目录 概述: 端口设置: 代码分析: 运行现象: 概述: DMA(Direct Memory Access)是一种计算机系统中的数据传输技术,它允许数据在不经过中央处理器(CPU)的直…...

SQL IN 操作符
IN 操作符 IN 操作符允许您在 WHERE 子句中规定多个值。 SQL IN 语法 SELECT column1, column2, ... FROM table_name WHERE column IN (value1, value2, ...); 参数说明: column1, column2, ...:要选择的字段名称,可以为多个字段。如果…...
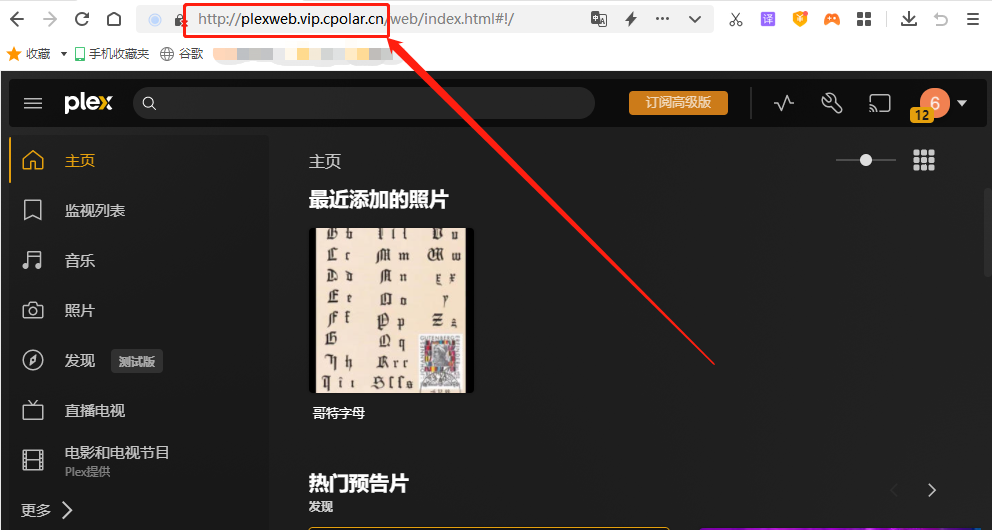
如何使用Plex在Windows系统搭建个人媒体站点公网可访问
文章目录 1.前言2. Plex网站搭建2.1 Plex下载和安装2.2 Plex网页测试2.3 cpolar的安装和注册 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 用手机或者平板电脑看视频,已经算是生活中稀松平常的场景了,特别是各…...

web前端——clear可以清除浮动产生的影响
clear可以解决高度塌陷的问题,产生的副作用要小 未使用clear之前 <!DOCTYPE html> <head><meta charset"UTF-8"><title>高度塌陷相关学习</title><style>div{font-size:50px;}.box1{width:200px;height:200px;backg…...

centos用yum安装mysql详细教程
1 查询安装mysql的yum源,命令如下 ls /etc/yum.repos.d/ -l 界面如下图所示,未显示mysql的安装源 2 安装mysql相关的yum源,例如: 例如:rpm -ivh mysql57-community-release-el7.rpm 要注意 mysql的版本和系统的版本匹配 mysql57-communi…...

冲刺2024年AMC8竞赛的专题突破:匹克定律和不规则形状面积的求法
先温馨提示:2024年AMC8比赛报名今天是最后一天,如果还想参加比赛的孩子今天务必完成报名,错过今天再等一年。需要AMC8自由报名通道可以问我。 到昨天为止,六分成长已经把过去20多年的AMC8竞赛真题都给大家过了一遍,今天为大家做一…...

阿里云迁移AWS视频点播技术攻坚
文章目录 🐷 背景🦥 简述🐥 Aws服务🦜 AWS CloudFormation🐞 问题🐉 落地方案🦉 Aws vs Aliyun🍄 避坑指南 🐷 背景 由于AWS整体成本略低于阿里云,公司决定将…...

Scrum敏捷认证CSM官方认证班Certified ScrumMaster - CSM认证班
课程简介 Scrum是目前运用最为广泛的敏捷开发方法,是一个轻量级的项目管理和产品研发管理框架,旨在最短时间内交付最大价值。根据2021年全球敏捷状态报告,Scrum及Scrum衍生方法的应用占比达到81%。 在企业的敏捷转型历程中,Scru…...

深度解析qt核心机制:信号槽的多线程行为与对象的线程依附性
对象的线程依附性 每一个学过C以及系统编程的程序员,对于变量会与特定线程有关联都会感到不可思议;在qt中所说的对象的线程依附性,只是针对继承自QObject的对象而言的;对象的线程依附性,并不是代表真的某个底层线程才…...
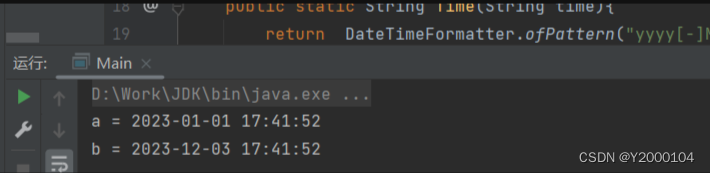
关于时间格式yyyy-M-d或yyyy-MM-d到yyyy-MM-dd的转换
工作时遇到前端传的时间格式是"2023-12-3 17:41:52",和"2023-1-1 17:41:52"但是我想要的是"2023-12-03 17:41:52"和"2023-01-01 17:41:52"。下面给大家分享几个解决方法 方法一: 找前端!让他改&…...

【Windows】之微软输入法配置小鹤双拼
前言 Windows 自带的输入法微软输入法本身就是个最简洁、最方便的输入法,不需要去安装多余的第三方输入法软件。同时,微软中文拼音输入法支持双拼输入法,但微软自带的双拼输入法不包含小鹤双拼方案的。所以,在这里将会讲解如何配置…...

【AI】使用Jan.ai在本地部署大模型开启AI对话(含通过huggingface下载大模型,实现大模型自由)
文章目录 前言一、Jan.ai是什么?二、下载大模型1. 找到大模型文件地址2. 下载大模型3. 修改model.json文件 三、使用Jan调用大模型进行对话总结 前言 2023年是AIGC元年。以后,每个人多少都会接触到GPT带来的变化。别人都在用,我们也不能落下…...

C++摸版(初阶)----函数模版与类模版
本专栏内容为:C学习专栏,分为初阶和进阶两部分。 通过本专栏的深入学习,你可以了解并掌握C。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚代码仓库:小小unicorn的代码仓库&…...
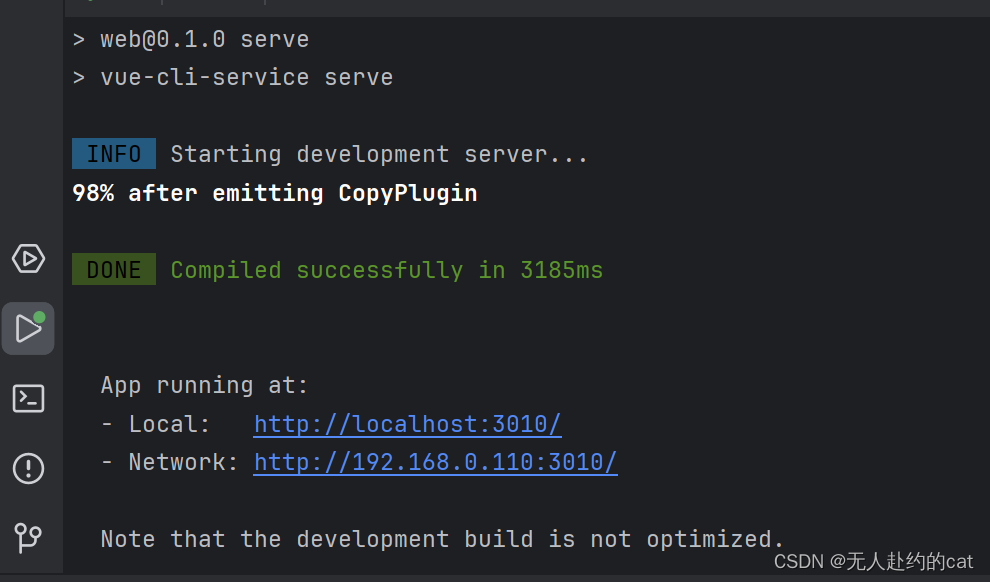
Embedded-Project项目介绍
Embedded-Project项目介绍 Server后端项目后端启动连接数据库启动时可能遇到的问题架构介绍 web前端项目前端启动启动时可能遇到的问题架构介绍 前后端分离开发流程 项目地址: https://github.com/Catxiaobai/Embedded-Project Server后端项目 系统后端项目&#…...

golang 的那些花样
从 A Tour of Go 可以看到一些 Go 比较特殊的点 文章目录 变量声明时,类型放在后面Array 的引用 Slicereceiver 和 argumentbuilt-int特殊接口Error 变量声明时,类型放在后面 var i, j int 1, 2declaration-syntax Array 的引用 Slice slices-intro …...
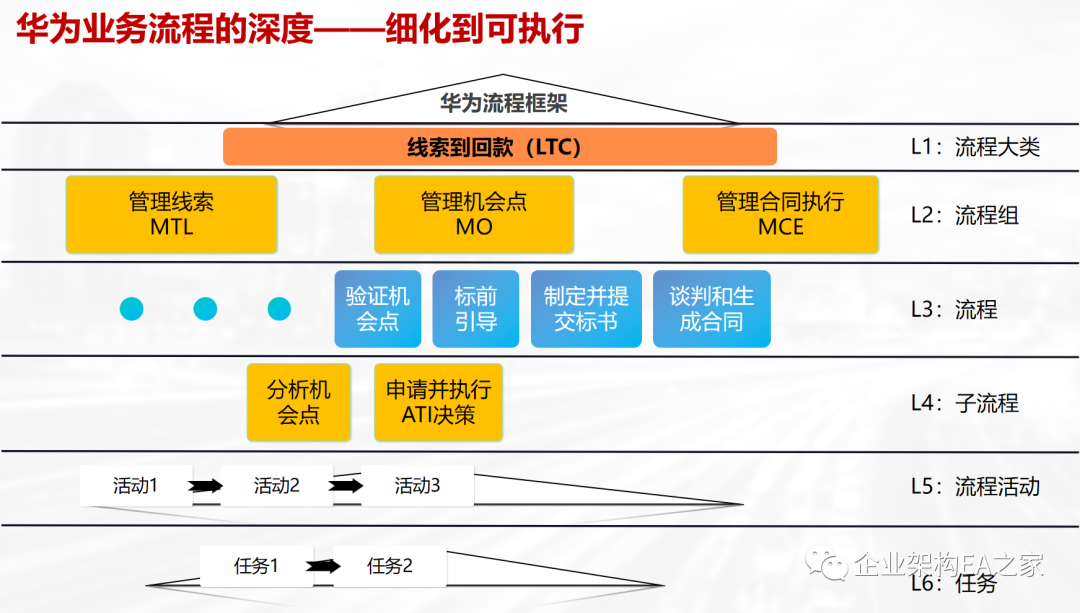
如何设计企业级业务流程?学习华为的流程六级分类经验
业务流程管理(BPM)是一种系统化的方法,用于分析、设计、执行、监控和优化组织的业务流程,以实现预期的目标和价值。业务流程管理中,流程的分级方法有多种,常见的有以下几种: APQC的流程分级方法…...

视频智能分析支持摄像头异常位移检测,监测摄像机异常位移变化,保障监控状态
我们经常在生产场景中会遇到摄像头经过风吹日晒,或者异常的触碰,导致了角度或者位置的变化,这种情况下,如果不及时做出调整,会导致原本的监控条件被破坏,发生事件需要追溯的时候,查不到对应位置…...

自建轻量级Docker镜像中心:聚合管理与加速部署实践
1. 项目概述:一个面向容器化开发者的中心化镜像仓库最近在和一些做容器化开发的朋友交流时,大家普遍提到一个痛点:随着团队项目增多,Docker镜像的管理变得越来越零散。有的镜像放在Docker Hub,有的放在阿里云镜像服务&…...

PromptCraft-Robotics:基于LLM的机器人任务规划与安全控制实践
1. 项目概述与核心价值最近在机器人编程和AI应用领域,一个名为“PromptCraft-Robotics”的项目在开发者社区里引起了不小的讨论。这个项目由微软开源,其核心目标直指一个困扰许多开发者和研究者的痛点:如何让大型语言模型(LLM&…...

基于CircuitPython与AMG8833的嵌入式热成像系统:从8x8数据到15x15伪彩色显示的完整实现
1. 项目概述:从传感器到屏幕的嵌入式热成像之旅在嵌入式开发领域,将原始传感器数据转化为直观、可交互的视觉信息,是连接物理世界与数字世界的核心桥梁。这不仅仅是简单的数据读取与显示,更是一个涉及信号处理、算法优化和实时渲染…...

基于SpringBoot+Flowable的办公流程审批系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Flowable框架的办公流程审批系统以解决传统审批模式中存在的效率低下问题。当前多数组织机构在日常运营中普遍采用人工审批…...
)
C语言结构体:从‘学生信息管理‘到‘链表实现‘的保姆级跃迁指南(含typedef避坑)
C语言结构体:从学生信息管理到链表实现的实战进阶 在C语言的世界里,结构体就像是一个神奇的收纳盒,它能够将不同类型的数据打包成一个整体。想象一下,当你需要管理学生信息时,不再需要为姓名、学号、成绩等分别定义变量…...

越刷越空?不是自控力太差,是你的大脑“最高权限”丢了
被一块屏幕“遛”着走的人前几天深夜,我和几个以前在老东家一起扛过枪的兄弟,在一个烤串摊喝酒。一桌人,平均四十多岁,平时在公司里不是总监就是合伙人,西装革履,人模狗样。按理说,都算是社会化…...

【2026最新】鸿蒙NEXT数据持久化实战:培训班管理系统数据存储全攻略
鸿蒙开发中数据总是丢失?本地存储和网络请求搞不定?本文用15分钟带你彻底搞懂Preferences、RDB、HTTP三大数据持久化方案,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App数据存储从此安全可靠!一、学员信息本地…...

Linux驱动开发:原子操作实现LED设备互斥访问
1. 项目概述:用原子操作给LED驱动加把“锁”在嵌入式Linux开发里,驱动开发是绕不开的一环。很多时候,一个硬件设备,比如一个简单的LED灯,可能会被多个用户空间的应用程序同时访问。想象一下,一个APP想开灯&…...

PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题
PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题 【免费下载链接】PoE-Overlay An Overlay for Path of Exile. Built with Overwolf and Angular. 项目地址: https://gitcode.com/gh_mirrors/po/PoE-Overlay 你是否曾经在《流放之路》中面对满…...

基于ADT7410与ESP8266的物联网温度监测系统实战指南
1. 项目概述:从传感器到云端的温度监测闭环在嵌入式开发和物联网项目中,温度监测是一个经典且高频的需求场景。无论是实验室环境监控、智能家居的恒温控制,还是工业设备的状态感知,一个稳定、精确且能远程访问的温度数据流都是基础…...