Python从入门到网络爬虫(MySQL链接)
前言
在实际数据分析和建模过程中,我们通常需要从数据库中读取数据,并将其转化为 Pandas dataframe 对象进行进一步处理。而 MySQL 数据库是最常用的关系型数据库之一,因此在 Python 中如何连接 MySQL 数据库并查询数据成为了一个重要的问题。

本文将介绍两种方法来连接 MySQL 数据库,并将查询结果转化为 Pandas dataframe 对象:第一种方法使用 pymysql 库来连接 MySQL 数据库;第二种方法则使用 SQLAlchemy 的 create_engine 函数创建 MySQL 数据库连接引擎。同时,针对这两种方法,我们还将对代码进行封装和优化,提高程序的可读性和健壮性。
1. 使用 pymysql 库连接 MySQL 数据库
1.1 连接 MySQL 数据库
import pymysql# 连接 MySQL 数据库
conn = pymysql.connect(host='159.xxx.xxx.216', # 主机名port=3306, # 端口号,MySQL默认为3306user='xxxx', # 用户名password='xxxx', # 密码database='xx', # 数据库名称
)在上面的代码中,我们通过 pymysql 库的 connect() 函数连接 MySQL 数据库,并指定主机名、端口号、用户名、密码和数据库名称等参数。如果连接成功,则该函数将返回一个数据库连接对象 conn。
1.2 执行 SQL 查询语句
连接 MySQL 数据库之后,我们就可以使用游标对象来执行 SQL 查询语句,如下所示:
# 创建游标对象
cursor = conn.cursor()# 执行 SQL 查询语句
cursor.execute("SELECT * FROM users WHERE gender='female'")# 获取查询结果
result = cursor.fetchall()在上面的代码中,我们使用 cursor() 方法创建游标对象 cursor,并使用 execute() 方法执行 SQL 查询语句。在执行查询时,我们可以使用任何符合 MySQL 语法的 SQL 查询语句。最后,我们使用 fetchall() 方法获取查询结果。
1.3 将查询结果转化为 Pandas dataframe 对象
获取查询结果之后,我们需要将其转化为 Pandas dataframe 对象,以便于进行进一步的数据处理和分析。具体代码如下
import pandas as pd# 将查询结果转化为 Pandas dataframe 对象
df = pd.DataFrame(result, columns=[i[0] for i in cursor.description])在上面的代码中,我们使用 pd.DataFrame() 方法将查询结果转化为 Pandas dataframe 对象。在转化过程中,我们需要指定字段名,可以通过游标对象的 description 属性来获取查询结果的元数据,其中包括字段名等信息。
1.4 关闭游标和数据库连接
最后,我们需要关闭游标对象和数据库连接,以释放资源。具体代码如下:
# 关闭游标和数据库连接
cursor.close()
conn.close()2. 使用 SQLAlchemy 的 create_engine 函数连接 MySQL 数据库
除了使用 pymysql 库连接 MySQL 数据库之外,我们还可以使用 SQLAlchemy 的 create_engine 函数创建 MySQL 数据库连接引擎,并使用 Pandas 库中的 read_sql 函数直接将查询结果转化为 Pandas dataframe 对象。
# 步骤 1:创建 MySQL 数据库连接引擎
from sqlalchemy import create_engine# 创建 MySQL 数据库连接引擎
engine = create_engine('mysql+pymysql://username:password@host:port/database')步骤 2:执行 SQL 查询语句并将结果转化为 Pandas dataframe 对象
import pandas as pd# 执行 SQL 查询语句,并将结果转化为 Pandas dataframe 对象
df = pd.read_sql("SELECT * FROM users WHERE gender='female'", con=engine)# 关闭数据库连接
engine.dispose()在上面的代码中,我们使用 create_engine 函数创建了一个 MySQL 数据库连接引擎。其中,我们需要将数据库连接信息输入到一个字符串中,并作为函数的参数传入。其中,username 和 password 分别表示登录 MySQL 数据库所需的用户名和密码,host 和 port 表示 MySQL 数据库的主机名和端口号,database 表示要连接的 MySQL 数据库名称。
接着使用使用 pd.read_sql() 函数执行 SQL 查询语句,并将数据库连接引擎对象 engine 作为参数传入。在执行查询时,我们可以使用任何符合 MySQL 语法的 SQL 查询语句。最后,该函数将返回查询结果的 Pandas dataframe 对象。
最后,我们需要关闭数据库连接,以释放资源。
3. 函数封装
以上介绍了两种方法来连接 MySQL 数据库,并将查询结果转化为 Pandas dataframe 对象。为了方便重复使用,我们可以将这些代码封装成一个函数。
import pandas as pd
import pymysql
from sqlalchemy import create_enginedef query_mysql(sql_query, host=None, port=None, user=None, password=None, database=None, engine=None):"""连接 MySQL 数据库,执行查询,并将查询结果转化为 Pandas DataFrame 对象。:param sql_query: SQL 查询语句:param host: 主机名,默认为 None:param port: 端口号,默认为 None:param user: 用户名,默认为 None:param password: 密码,默认为 None:param database: 数据库名称,默认为 None:param engine: SQLAlchemy 的数据库引擎对象,默认为 None:return: Pandas DataFrame 对象"""# 如果未提供数据库连接引擎,则使用 pymysql 库连接 MySQL 数据库if engine is None:# 连接 MySQL 数据库conn = pymysql.connect(host=host,port=port,user=user,password=password,database=database,)# 创建游标对象cursor = conn.cursor()# 执行 SQL 查询语句cursor.execute(sql_query)# 获取查询结果result = cursor.fetchall()# 将查询结果转化为 Pandas DataFrame 对象df = pd.DataFrame(result, columns=[i[0] for i in cursor.description])# 关闭游标和数据库连接cursor.close()conn.close()# 如果已提供数据库连接引擎,则使用 SQLAlchemy 库连接 MySQL 数据库else:# 执行 SQL 查询语句,并将结果转化为 Pandas DataFrame 对象df = pd.read_sql(sql_query, con=engine)return df在上面的代码中,我们创建了一个名为 query_mysql 的函数,用于连接 MySQL 数据库,并执行查询操作。该函数接受以下参数:
- sql_query:SQL 查询语句;
- host:主机名,默认为 None;
- port:端口号,默认为 None;
- user:用户名,默认为 None;
- password:密码,默认为 None;
- database:数据库名称,默认为 None;
- engine:SQLAlchemy 的数据库引擎对象,默认为 None。
在函数中,我们首先判断是否已提供数据库连接引擎对象。如果未提供,则使用 pymysql 库连接MySQL 数据库,并执行查询操作,步骤与前面的第一种方法相同。如果已提供数据库连接引擎对象,则使用 SQLAlchemy 库连接 MySQL 数据库,并执行查询操作,步骤与前面的第二种方法相同。
最后,在函数中我们返回查询结果的 Pandas dataframe 对象
# 使用 pymysql 库连接 MySQL 数据库
df1 = query_mysql(sql_query="SELECT * FROM users WHERE gender='female'",host='159.xxx.xxx.216', # 主机名port=3306, # 端口号,MySQL默认为3306user='xxxx', # 用户名password='xxxx', # 密码database='xx', # 数据库名称
)# 使用 SQLAlchemy 库连接 MySQL 数据库
engine = create_engine('mysql+pymysql://xxx:xxx@localhost:3306/ad')
df2 = query_mysql(sql_query="SELECT * FROM users WHERE gender='female'", engine=engine)通过使用 query_mysql 函数,我们可以更加方便地连接 MySQL 数据库并查询数据,并且代码量更少、可读性更好。同时,由于该函数使用了 pymysql 和 SQLAlchemy 两个库,因此也具有较好的跨平台性,可以在不同的操作系统和环境下运行。
最后也分享一下个人通过使用的模板:
# 法一:import pymysql
import pandas as pddef query_data(sql_query):# 连接数据库conn = pymysql.connect(host='xxx.xxx.xxx.xxx', # 主机名port=3306, # 端口号,MySQL默认为3306user='xxx', # 用户名password='xxx', # 密码database='xxx', # 数据库名称)try:# 创建游标对象cursor = conn.cursor()# 执行 SQL 查询语句cursor.execute(sql_query)# 获取查询结果result = cursor.fetchall()# 获取查询结果的字段名和元数据columns = [col[0] for col in cursor.description]# 将查询结果封装到 Pandas DataFrame 中df = pd.DataFrame(result, columns=columns)return dffinally:# 关闭游标和连接cursor.close()conn.close()db_data = query_data(sql_query)# 法二:
from sqlalchemy import create_engine
import pandas as pddef getdata_from_db(query, db, host='xxx.xxx.xxx.xxx', port=3306, user='xxx', password='xxx'):try:engine = create_engine(f'mysql+pymysql://{user}:{password}@{host}:{port}/{db}?charset=utf8')# 使用 with 语句自动管理连接的生命周期with engine.connect() as conn:data = pd.read_sql(query, conn)return dataexcept Exception as e:print(f"Error occurred when executing SQL query: {e}")return Nonedb_data = getdata_from_db(sql_query, 'ad')# 法三:超级精简版
from sqlalchemy import create_engine
import pandas as pdengine = create_engine(f'mysql+pymysql://xxx:xxx@xxx:3306/xx?charset=utf8')
db_data = pd.read_sql(sql, engine)
db_data.head()最后,说一下在访问数据库时,可能存在一些潜在的问题和注意事项。
- 首先,在使用 pandas.read_sql() 时,需要在 SQL 查询语句中包含所有必要的过滤条件、排序方式等信息,以确保返回的结果集合是正确的,而不是整个表或视图中的所有数据。如果没有限制返回的数据量,可能会导致内存溢出或其他性能问题。因此,在实际应用中,推荐使用 LIMIT 等关键字来设置最大返回数据量,以便更好地控制查询结果。
- 其次,在实际生产环境中,为了避免泄漏敏感信息和减少攻击面,建议将数据库连接字符串等敏感信息存储在单独的配置文件中,并且只授权给有限的用户使用。另外,在向 SQL 查询语句中传递参数时,也需要进行安全过滤和转义,以避免 SQL 注入等安全问题。
- 最后,在使用完毕后,需要及时关闭数据库连接,以释放资源并减少数据库服务器的负载。或者,可以使用 with 语句自动管理连接的生命周期。
总之,学习如何连接 MySQL 数据库并将查询结果转化为 Pandas dataframe 对象是数据分析和建模过程中的重要一步。希望本文对您有所帮助!
相关文章:
Python从入门到网络爬虫(MySQL链接)
前言 在实际数据分析和建模过程中,我们通常需要从数据库中读取数据,并将其转化为 Pandas dataframe 对象进行进一步处理。而 MySQL 数据库是最常用的关系型数据库之一,因此在 Python 中如何连接 MySQL 数据库并查询数据成为了一个重要的问题…...

2020年认证杯SPSSPRO杯数学建模A题(第二阶段)听音辨位全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 A题 听音辨位 原题再现: 把若干 (⩾ 1) 支同样型号的麦克风固定安装在一个刚性的枝形架子上 (架子下面带万向轮,在平地上可以被水平推动或旋转,但不会歪斜),这样的设备称为一个麦克风树。不同的麦…...

深入理解CRON表达式:时间调度的艺术
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Mi…...
网络安全—模拟IP代理隐藏身份
文章目录 网络拓扑安装使用代理服务器设置隐藏者设置 使用古老的ccproxy实现代理服务器,仅做实验用途,禁止做违法犯罪的事情,后果自负。 网络拓扑 均使用Windows Server 2003系统 Router 外网IP:使用NAT模式 IP DHCP自动分配或者…...
)
Resilience4j相关问题及答案(2024)
1、什么是Resilience4j,与Hystrix有何不同? Resilience4j是一个为Java 8和函数式编程设计的故障恢复库,它主要利用了Vavr库中的函数式编程概念。Resilience4j提供了一系列的故障恢复机制,包括断路器(Circuit Breaker&…...

XSKY SDS 产品率先获得 OceanBase V4 新版本认证
近日,北京奥星贝斯科技有限公司(简称:OceanBase)与北京星辰天合科技股份有限公司(简称:XSKY 星辰天合)顺利完成产品兼容性认证。 XSKY 的高性能全闪存储以及混闪存储,与 OceanBase V…...
:静态方法(staticmethod)和类方法(classmethod)-[基础知识])
系统学习Python——类(class):静态方法(staticmethod)和类方法(classmethod)-[基础知识]
分类目录:《系统学习Python》总目录 我们可以在类中定义两种方法,它们不需要一个实例就可以被调用:静态方法(staticmethod)大致与一个类中简单的无实例函数的工作方式类似,而类方法则被传人一个类而不是一个…...
kotlin isEmpty/isNotEmpty/isNullOrEmpty和isBlank/isNotBlank/isNullOrBlank
kotlin 中 isEmpty :如果判断的字符为空返回值返回true否则返回false 它的源码 kotlin.internal.InlineOnly public inline fun CharSequence.isEmpty(): Boolean length 0 length 0: 首先检查字符序列的长度是否为 0。如果长度为 0,则表明这个字…...
Qt/QML编程学习之心得:Linux下USB接口使用(25)
很多linux嵌入式系统都有USB接口,那么如何使用USB接口呢? 首先,linux的底层驱动要支持,在linux kernal目录下可以找到对应的dts文件,(device tree) usb0: usb@ee520000{compatible = "myusb,musb";status = "disabled";reg = <0xEE520000 0x100…...

概率论与数理统计 知识点+课后习题
文章目录 💖 [学习资源整合](https://www.cnblogs.com/duisheng/p/17872980.html)📚 总复习📙 选择题📙 填空题📙 大题1. 概率2. 概率3. 概率4. P5. 概率6. 概率密度函数 F ( X ) F(X) F(X)7. 分布列求方差 V ( X ) …...

Spring Boot实战:深入理解@Service与@Mapper注解
1. Service 注解 Service 是Spring框架提供的一个注解,用于标记类为业务逻辑层的组件。当类上标注了Service注解后,Spring容器会自动扫描并创建该类的一个实例(即Bean),这样我们就可以在其他地方通过自动装配…...
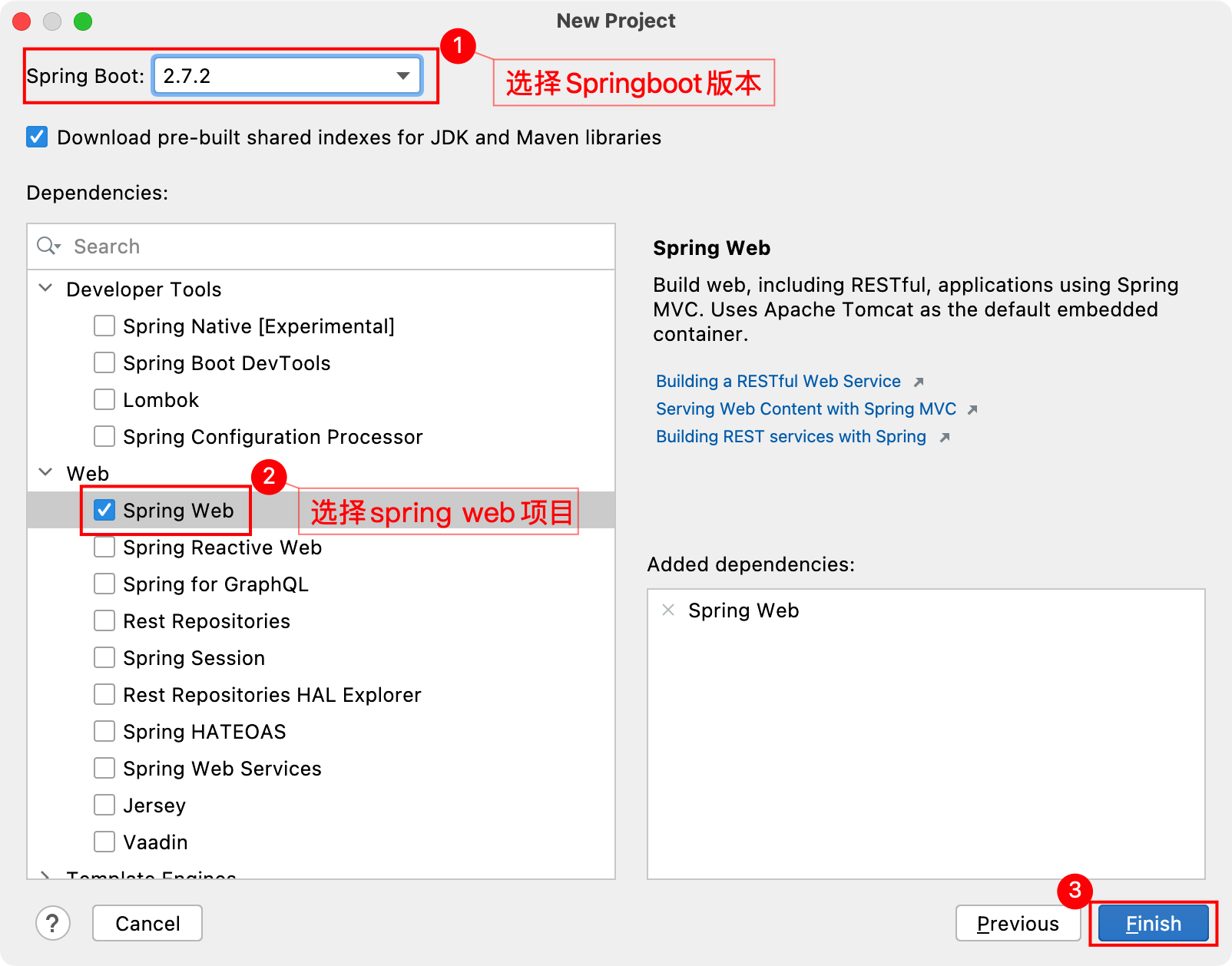
【DevOps-06】Jenkins实现CI/CD操作
一、简要说明 基于Jenkins拉取GitLab的SpringBoot代码进行构建发布到测试环境实现持续集成 基于Jenkins拉取GitLab指定发行版本的SpringBoot代码进行构建发布到生产环境实现CD实现持续部署 二、准备Springboot工程 1、IDEA新建工程 2、填写项目工程信息 3、选择Springboot版本…...
华为面经总结
为了帮助大家更好的应对面试,我整理了往年华为校招面试的题目,供大家参考~ 面经1 技术一面 自我介绍说下项目中的难点volatile和synchronized的区别, 问的比较细大顶堆小顶堆怎么删除根节点CSRF攻击是什么,怎么预防线程通信方式…...
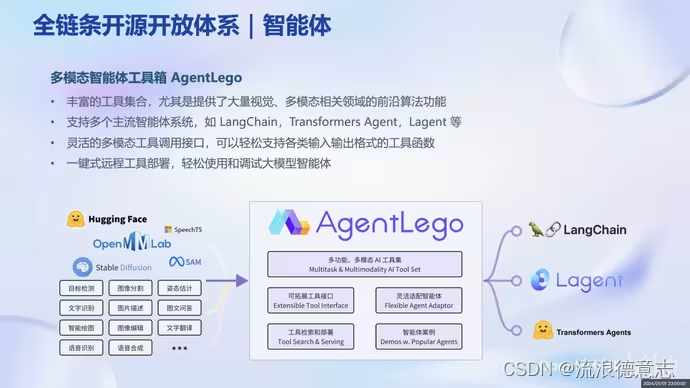
大模型实战营Day1 书生·浦语大模型全链路开源体系
1.大模型为发展通用人工智能的重要途经 专用模型:针对特定任务解决特定问题 通用大模型:一个模型对应多模态多任务 2.InternLM大模型开源历程 3.InternLM-20B大模型性能 4.从模型到应用:智能客服、个人助手、行业应用 5.书生浦语全链条开源…...

Java 集合面试题真实场景还原
Java 集合面试题真实场景还原 文章目录 Java 集合面试题真实场景还原Java常见的集合类ListHashMap Java常见的集合类 面试官:说一说Java提供的常见集合?(画一下集合结构图) 候选人: 嗯~~,好的。 在java中提…...
4.9-Autoar_BSW小结)
AutoSAR(基础入门篇)4.9-Autoar_BSW小结
Autoar_BSW小结 Autoar_BSW小结 一、Autoar_BSW小结 1、BSW组件图 2、BSW的功能概述 3、BSW在工程里的应用实际工程...
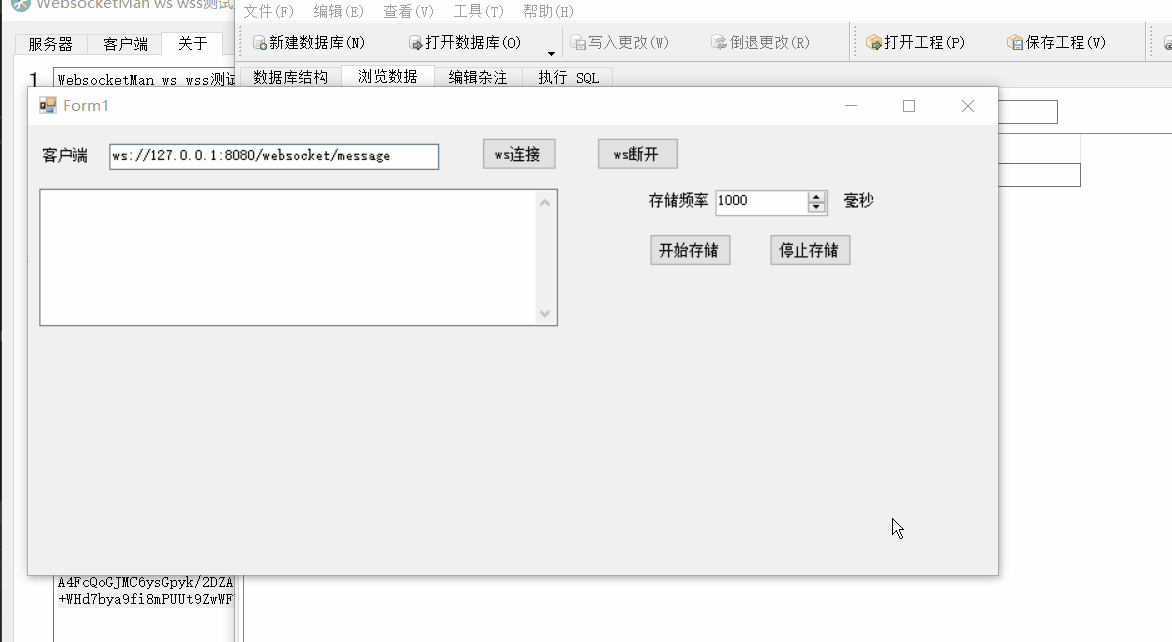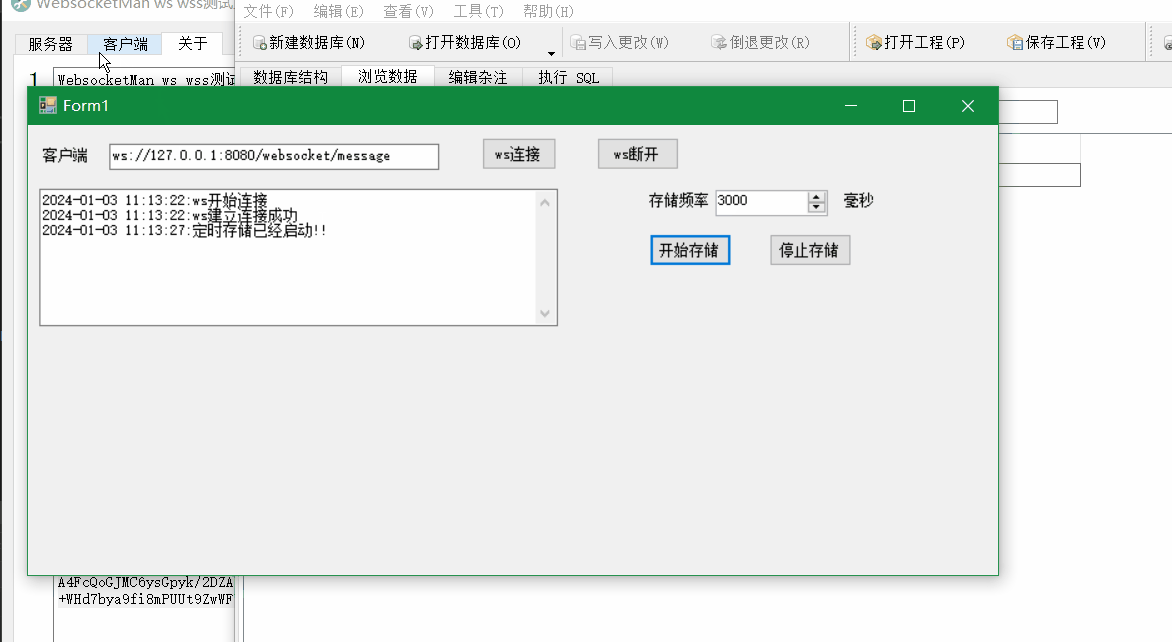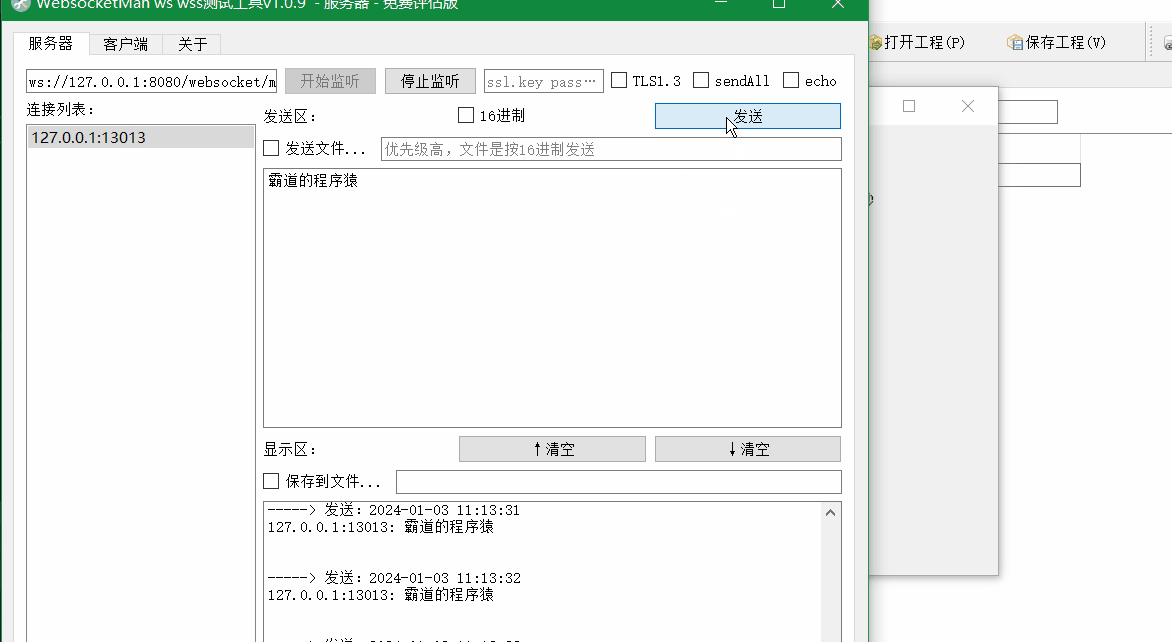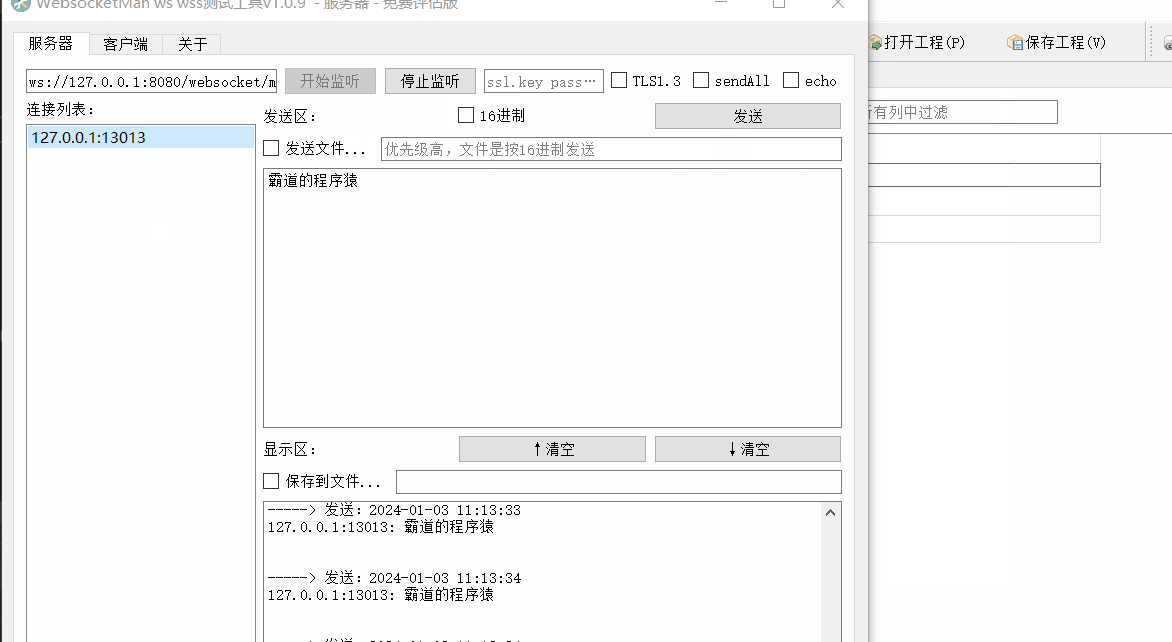
Winform中使用Websocket4Net实现Websocket客户端并定时存储接收数据到SQLite中
场景 SpringBootVue整合WebSocket实现前后端消息推送: SpringBootVue整合WebSocket实现前后端消息推送_websocket vue3.0 springboot 往客户端推送-CSDN博客 上面实现ws推送数据流程后,需要在windows上使用ws客户端定时记录收到的数据到文件中&#x…...
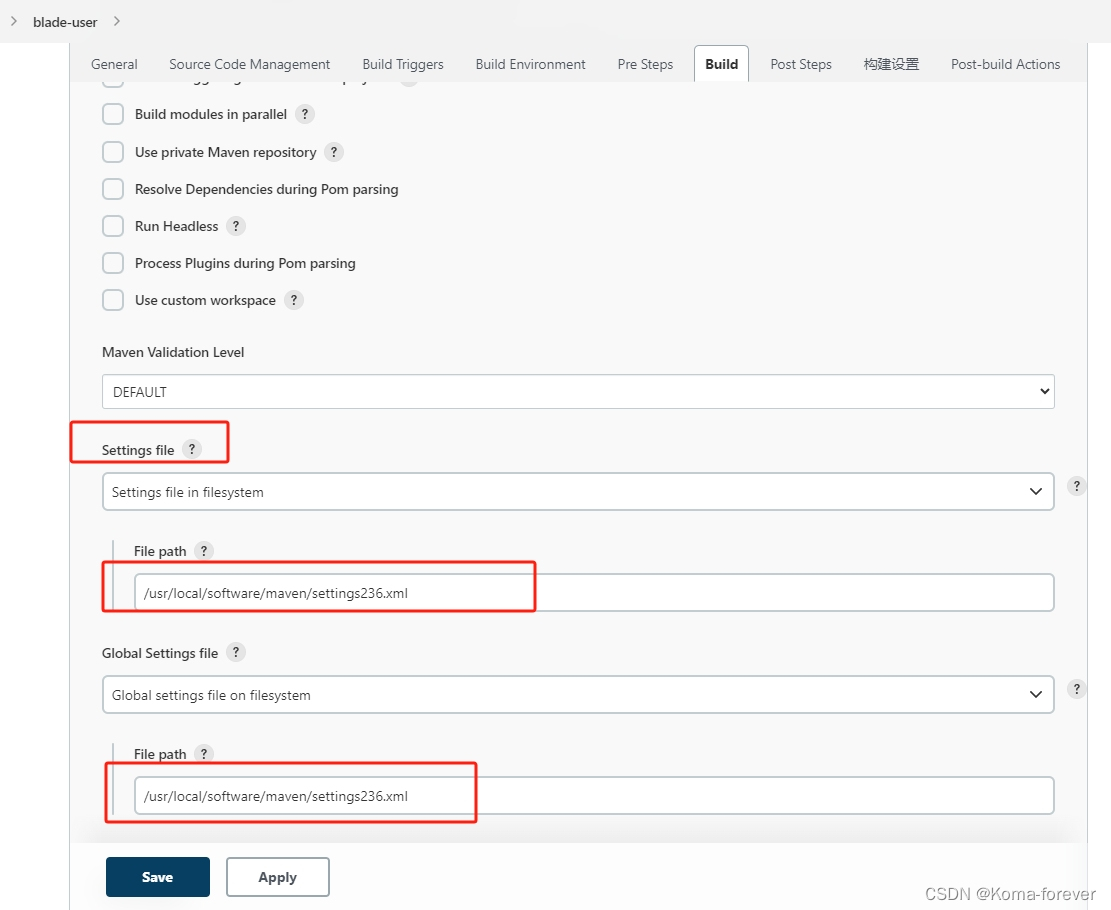
Jenkins修改全局maven配置后不生效解决办法、以及任务读取不同的settings.xml文件配置
一、修改Global Tool Configuration的maven配置不生效 说明:搭建好jenkins后,修改了全局的settings.xml,导致读取settings一直是之前配置的。 解决办法一 Jenkins在创建工作任务时,会读取当前配置文件内容,固定在这…...
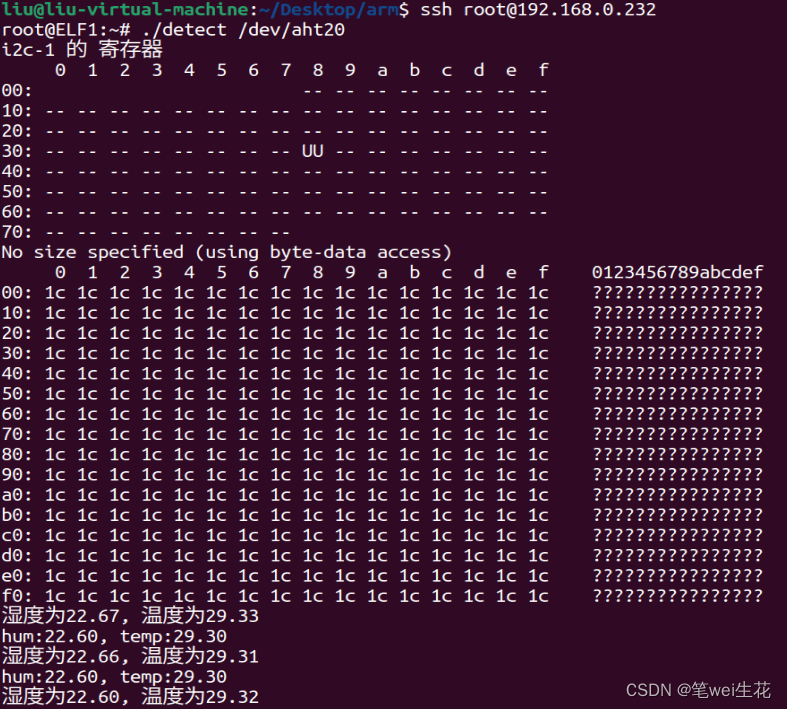
【elfboard linux开发板】7.i2C工具应用与aht20温湿度寄存器读取
1. I2C工具查看aht20的温湿度寄存器值 1.1 原理图 传感器通过IIC方式进行通信,连接的为IIC1总线,且设备地址为0x38,实际上通过后续iic工具查询,这个设备是挂载在iic-0上 1.2 I2C工具 通过i2c工具可以实现查询i2c总线、以及上面…...

LeetCode-有效的字母异位词(242)
题目描述: 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 思路: 这题还是比较简单的,首先将两个字符…...

YOLOv5/v7改进系列——融合EfficientNetV2主干网络的轻量化部署实践
1. 为什么选择EfficientNetV2作为YOLO的主干网络 在目标检测领域,YOLO系列算法因其出色的实时性能而广受欢迎。但当我们把YOLOv5/v7部署到移动端或嵌入式设备时,模型的计算量和内存占用就成了必须面对的难题。这时候,EfficientNetV2就像一位轻…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...

十六呀,今天对我们都是很特殊的一天吧
今天对你坦白了 不是表白,是坦白 说了一些你早就知道的话 我说我想放下了 我说交给时间 不是我真的想放下 是我没有别的选择了 就做好朋友吧 如果你还愿意的话 我们会是很好的朋友 放下吧,如果真的可以,真的甘心的话。 好久好久之后 也许真的…...

新手如何通过Taotoken控制台快速创建并管理自己的API Key
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手如何通过Taotoken控制台快速创建并管理自己的API Key 对于初次接触大模型服务的开发者而言,如何安全、便捷地获取和…...

基于MCP与RAG构建私有化智能代码助手:从原理到部署实践
1. 项目概述:当MCP遇上RAG,一个为开发者定制的智能对话新范式最近在探索如何让AI助手更深入地理解我的代码库和私有文档时,我遇到了一个非常有意思的项目:gogabrielordonez/mcp-ragchat。乍一看,这个名字融合了当下两个…...

极简黑魔法:用 gh gist 搭建我们的私有配置分发 CDN
在多端协作的时代,我们经常需要在 PC、手机和路由器之间同步一些私密的订阅配置(如应用服务配置文件,凭据等)。 如果使用公共 Gist 会有隐私泄露风险;维护一个私有 Git 仓库又需要处理复杂的 API Token 鉴权࿰…...

终极指南:如何用UniversalSplitScreen在一台电脑上玩多人游戏
终极指南:如何用UniversalSplitScreen在一台电脑上玩多人游戏 【免费下载链接】UniversalSplitScreen Split screen multiplayer for any game with multiple keyboards, mice and controllers. 项目地址: https://gitcode.com/gh_mirrors/un/UniversalSplitScree…...

别再只会用L298N了!用STM32高级定时器玩转H桥双极模式,精准控制直流电机转速与刹车
从L298N到STM32高级定时器:H桥双极模式下的直流电机精准控制实战 在嵌入式开发领域,直流电机控制一直是经久不衰的话题。许多开发者入门时都会选择L298N这类现成驱动模块,它们简单易用,却隐藏着响应迟滞、效率低下和功能局限等问题…...

告别3389端口暴露:零信任防火墙重塑RDP安全访问新范式
1. 传统RDP安全方案的致命短板 每次看到服务器日志里那些密密麻麻的暴力破解尝试记录,我的后颈都会发凉。作为从业十年的运维老兵,我见过太多因为3389端口暴露引发的安全事故。有个客户的数据库服务器,明明设置了16位复杂密码,还是…...

阿里云百炼 + OpenClaw 打造超强自动化 AI
前置准备 已安装并可正常打开 OpenClaw Windows 版本 OpenClaw 部署包获取:https://xiake.yun/api/download/package/14?promoCodeIVD643FDE29AOpenClaw 顶部 Gateway 状态显示为在线准备好可正常登录的阿里云账号可正常访问阿里云百炼控制台地址确认账号已开通百…...