ELK+kafka+filebeat企业内部日志分析系统搭建
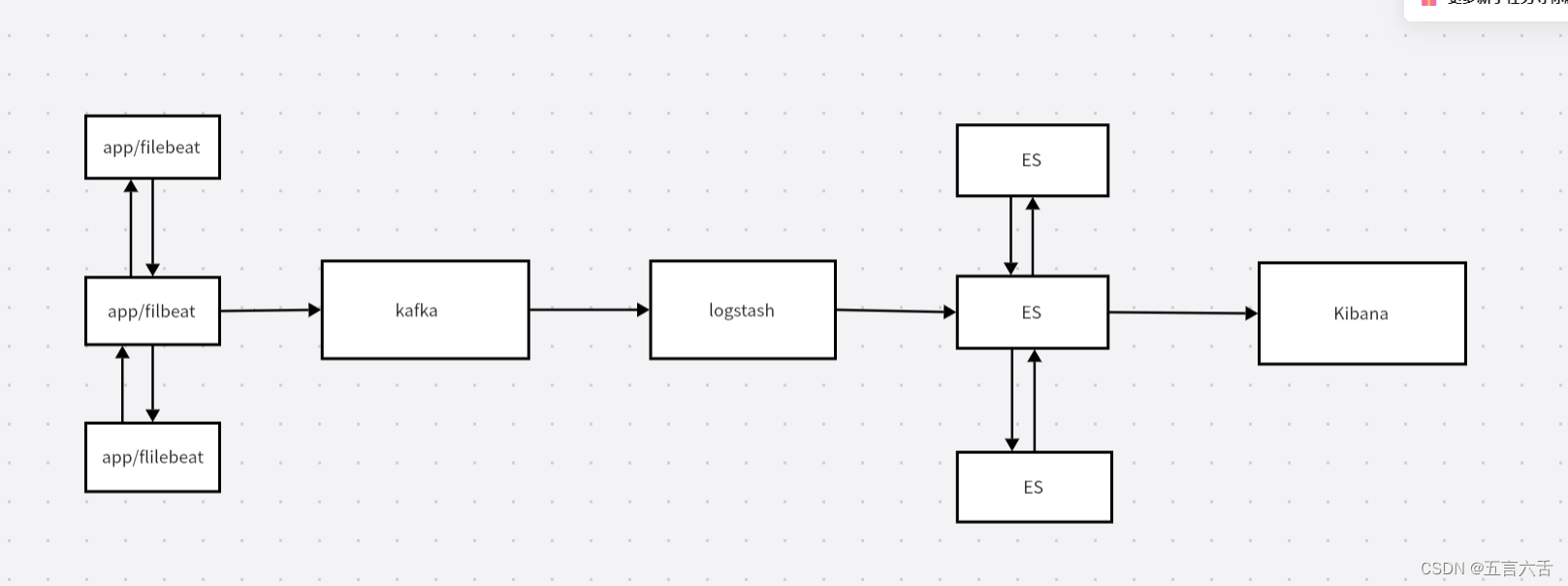
看上面的拓扑图,我们至少准备七台机器进行下面的实验项目。
机器主要作用分布如下:
三台安装elasticsearch来搭建ES集群实现高可用,其他机器就依次安装filebeat,kafka,logstash和kibana软件
一、部署elasticsearch来搭建ES集群
1.安装jdk
由于ES运行依赖于java环境,所以在部署es之前,我们要安装好jdk
我们事先在官网上下载好jdk的安装包并上传到机器,接下来就可以直接安装了,三台机器都需要安装好
tar xzf jdk-8u191-linux-x64.tar.gz -C /usr/local/ #解压
mv /usr/local/jdk1.8.0_191/ /usr/local/java #改名
echo '
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
source /etc/profile安装好jdk环境,我们就可以安装ES了
2、创建运行ES的普通用户(三台机器都需要操作)
useradd elsearch #创建用户
echo "123456" | passwd --stdin "elsearch" #给用户设置密码
3、安装配置ES
[root@mes-1 ~]# tar xzf elasticsearch-6.5.4.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/elasticsearch-6.5.4/config/
[root@mes-1 config]# ls
elasticsearch.yml log4j2.properties roles.yml users_roles
jvm.options role_mapping.yml users
[root@mes-1 config]# cp elasticsearch.yml elasticsearch.yml.bak
[root@mes-1 config]# vim elasticsearch.yml ----找个地方添加如下内容
cluster.name: elk
cluster.initial_master_nodes: ["192.168.246.234","192.168.246.231","192.168.246.235"]
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.246.234", "192.168.246.235"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
配置项含义
cluster.name 集群名称,各节点配成相同的集群名称。
cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock
bootstrap.system_call_filter
network.host 绑定节点IP。
http.port 端口。
transport.tcp.port 集群内部tcp连接端口
discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。4、设置JVM堆大小
[root@mes-1 config]# vim jvm.options ----将
-Xms1g ----修改成 -Xms2g
-Xmx1g ----修改成 -Xms2g
5、创建ES数据及日志存储目录
[root@mes-1 ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@mes-1 ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)6、修改安装目录及存储目录权限
[root@mes-1 ~]# chown -R elsearch:elsearch /data/elasticsearch
[root@mes-1 ~]# chown -R elsearch:elsearch /usr/local/elasticsearch-7.13.27、系统优化
#增加最大文件打开数
echo "* - nofile 65536" >> /etc/security/limits.conf#增加最大进程数
[root@mes-1 ~]# vim /etc/security/limits.conf ---在文件最后面添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
更多的参数调整可以直接用这个#增加最大内存映射数
[root@mes-1 ~]# vim /etc/sysctl.conf ---添加如下
vm.max_map_count=262144
vm.swappiness=0
[root@mes-1 ~]# sysctl -p
8、启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个解决:切换到root用户下面,vim /etc/security/limits.conf在最后添加
* hard nofile 65536
* hard nofile 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
# sysctl -w vm.max_map_count=262144
就可以了完成以上操作,我们就可以启动了
9、启动
[root@mes-1 ~]# su - elsearch
[root@mes-1 ~]$ cd /usr/local/elasticsearch-6.5.4/
[root@mes-1 elasticsearch-6.5.4]$ ./bin/elasticsearch #先启动看看报错不,需要多等一会
终止之后
[root@mes-1 elasticsearch-6.5.4]$ nohup ./bin/elasticsearch & #放后台启动
[1] 11462
nohup: ignoring input and appending output to ‘nohup.out’
[root@mes-1 elasticsearch-6.5.4]$ tail -f nohup.out #看一下是否启动二、安装head插件和部署Kibana(安装在同一台机器上)
1、安装node
# wget https://npm.taobao.org/mirrors/node/v14.15.3/node-v14.15.3-linux-x64.tar.gz# tar xzvf node-v14.15.3-linux-x64.tar.gz -C /usr/local/# vim /etc/profile
NODE_HOME=/usr/local/node-v14.15.3-linux-x64
PATH=$NODE_HOME/bin:$PATH
export NODE_HOME PATH# source /etc/profile# node --version #检查node版本号2、下载head插件
# wget https://github.com/mobz/elasticsearch-head/archive/master.zip# unzip -d /usr/local/ master.zip3、安装grunt
# cd /usr/local/elasticsearch-head-master/# npm config set registry https://registry.npm.taobao.org #更换一个镜像,如果不更换下载会很慢# npm install -g grunt-cli #时间会很长# grunt --version #检查grunt版本号4、修改head源码
# vim /usr/local/elasticsearch-head-master/Gruntfile.js (95左右)
# vim /usr/local/elasticsearch-head-master/_site/app.js (4359左右)

5、下载head必要的文件
# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2# yum -y install bzip2# tar -jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp/ #解压6、运行head
# cd /usr/local/elasticsearch-head-master/# npm config set registry https://registry.npm.taobao.org #先执行这条命令更换一个镜像# npm install# nohup grunt server &7、部署kibana
# tar zvxf kibana-6.5.4-linux-x86_64.tar.gz -C /usr/local/# cd /usr/local/kibana-7.13.2-linux-x86_64/config/# vim kibana.yml
server.port: 5601
server.host: "192.168.246.235"
elasticsearch.hosts: ["http://192.168.246.234:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"配置项含义
server.port kibana服务端口,默认5601
server.host kibana主机IP地址,默认localhost
elasticsearch.hosts 用来做查询的ES节点的URL,默认http://localhost:9200
kibana.index kibana在Elasticsearch中使用索引来存储保存
dashboards,默认.kibana8、启动kibana
[root@es-3-head-kib config]# cd ..
[root@es-3-head-kib kibana-7.13.2-linux-x86_64]# nohup ./bin/kibana --allow-root &
[1] 12054
[root@es-3-head-kib kibana-7.13.2-linux-x86_64]# nohup: ignoring input and appending output to ‘nohup.out’9、配置Nginx反向代理
[root@es-3-head-kib ~]# cd /etc/nginx/conf.d/
[root@es-3-head-kib conf.d]# cp default.conf nginx.conf
[root@es-3-head-kib conf.d]# mv default.conf default.conf.bak
[root@es-3-head-kib conf.d]# vim nginx.conf
[root@es-3-head-kib conf.d]# cat nginx.confserver {listen 80;server_name 192.168.246.235;#charset koi8-r;# access_log /var/log/nginx/host.access.log main;# access_log off;location / { proxy_pass http://192.168.246.235:5601;proxy_set_header Host $host:5601; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Via "nginx"; }location /head/{proxy_pass http://192.168.246.235:9100;proxy_set_header Host $host:9100;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header Via "nginx";}
}[root@es-3-head-kib conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",''"@version":"1",''"client":"$remote_addr",''"url":"$uri",''"status":"$status",''"domain":"$host",''"host":"$server_addr",''"size":$body_bytes_sent,''"responsetime":$request_time,''"referer": "$http_referer",''"ua": "$http_user_agent"''}';
# 引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;[root@es-3-head-kib ~]# systemctl start nginx
三、logstash部署
1、安装
tar xvzf logstash-6.5.4.tar.gz -C /usr/local/2、配置
创建目录,我们将所有input、filter、output配置文件全部放到该目录中。
1.安装nginx:
[root@es-2-zk-log ~]# rpm -ivh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
[root@es-2-zk-log ~]# yum install -y nginx
将原来的日志格式注释掉定义成json格式:
[root@es-2-zk-log conf.d]# vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",''"@version":"1",''"client":"$remote_addr",''"url":"$uri",''"status":"$status",''"domain":"$host",''"host":"$server_addr",''"size":$body_bytes_sent,''"responsetime":$request_time,''"referer": "$http_referer",''"ua": "$http_user_agent"''}';
2.引用定义的json格式的日志:
access_log /var/log/nginx/access_json.log json;[root@es-2-zk-log ~]# systemctl start nginx
[root@es-2-zk-log ~]# systemctl enable nginx
浏览器多访问几次
[root@es-2-zk-log ~]# mkdir -p /usr/local/logstash-7.13.2/etc/conf.d
[root@es-2-zk-log ~]# cd /usr/local/logstash-6.5.4/etc/conf.d/
[root@es-2-zk-log conf.d]# vim input.conf #---在下面添加
input{ #让logstash可以读取特定的事件源。file{ #从文件读取path => ["/var/log/nginx/access_json.log"] #要输入的文件路径type => "shopweb" #定义一个类型,通用选项. }}[root@es-2-zk-log conf.d]# vim output.conf
output{ #输出插件,将事件发送到特定目标elasticsearch { #输出到eshosts => ["192.168.246.234:9200","192.168.246.231:9200","192.168.246.235:9200"] #指定es服务的ip加端口index => ["%{type}-%{+YYYY.MM.dd}"] #引用input中的type名称,定义输出的格式}
}启动:
[root@es-2-zk-log conf.d]# cd /usr/local/logstash-7.13.2/
[root@es-2-zk-log logstash-7.13.2]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic & 相关文章:
ELK+kafka+filebeat企业内部日志分析系统搭建
看上面的拓扑图,我们至少准备七台机器进行下面的实验项目。 机器主要作用分布如下: 三台安装elasticsearch来搭建ES集群实现高可用,其他机器就依次安装filebeat,kafka,logstash和kibana软件 一、部署elasticsearch来搭建ES集群 1.安装jdk 由于ES运行…...
勒索检测能力升级,亚信安全发布《勒索家族和勒索事件监控报告》
评论员简评 近期(12.08-12.14)共发生勒索事件119起,相较之前呈现持平趋势。 与上周相比,近期仍然流行的勒索家族为lockbit3和8base。在涉及的勒索家族中,活跃程度Top5的勒索家族分别是:lockbit3、siegedsec、dragonforce、8base和…...

编译原理复习的有用链接
2024年1月7日,考完编译原理,是时候和考试时候的她说再见了,整理一些收藏夹里的链接和思考吧 实验看这里: 编译原理_HNU岳麓山大小姐的博客-CSDN博客 课后习题看这里: 编译原理作业答案github LL1文法复习 [编译原…...
不带控制器打包exe,转pdf文件时失败的原因
加了注释的两条代码后,控制器会显示一个docx转pdf的进度条。这个进度条需要控制器的实现,如果转exe不带控制器的话,当点击转换为pdf的按钮就会导致程序出错和闪退。 __init__.py文件的入口...

Python 注释的方法
在Python中,有两种常见的注释方法: 单行注释:使用#符号来注释一行代码。在#符号后面的内容将被视为注释,不会被解释器执行,如: # 这是一个单行注释 print(hello world!) # 打印字符串多行注释࿱…...

webman插件创建
webman插件创建 介绍 应用插件实际上是一个完整的应用,它能以插件的形式安装到主项目中,使主项目快速获得某个模块功能。 例如:主项目需要一个问答系统,则可以安装一个问答应用插件,需要一个商城系统,则安…...
大模型迎来“AppStore时刻”,OpenAI给2024的新想象
一夜之间,OpenAI公布了多个重磅消息,引发市场关注。 钛媒体App 1月5日消息,今晨,OpenAI公司向所有GPT开发者们发布一封邮件称,下周将上线自定义的“GPT Store”商店,这有望推动ChatGPT开发者生态不断完善。…...

ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题
ubuntu解决在pycharm上使用jupyter无法导入虚拟环境中的包的问题 根本原因是jupyter 没有和他对应的kernel 需要先使用命令行建立kernel 下载ipykernel pip install ipykernel 首先激活conda conda activate然后添加你的kernel到虚拟环境 python -m ipykernel install -…...
探索2024年软件测试的几大主导趋势
进入2024年,考虑影响测试环境的问题至关重要。这种思考将成为团队了解主要瓶颈和实现当今不断提高的期望的首要因素。 01 了解关键测试瓶颈 毋庸置疑,现代团队需要不断创新、适应和拥抱最新趋势,以保持竞争力并提供以客户为中心的解决方案。尽…...

Linux C语言 48-信号总结
Linux C语言 48-信号总结 本节关键字:Linux、C语言、常用信号 相关C库函数:printf、signal、kill Linux中都有哪些信号 信号在Linux操作系统中是很重要的,信号的产生方式可以是来自键盘、由软件条件产生、调用硬件异常产生。来自系统函数调…...

【vue技巧】之如何让mixin的data 比本身vue的data优先级要高
GPT4.0国内站点:海鲸AI 在 Vue 中,当组件和 mixin 包含有冲突的选项时,这些选项将以一定的方式合并。对于 data 选项,组件自身的 data 会优先级更高,这意味着如果组件和 mixin 中出现了相同的字段,组件的数…...

全解析阿里云Alibaba Cloud Linux镜像操作系统
Alibaba Cloud Linux是基于龙蜥社区OpenAnolis龙蜥操作系统Anolis OS的阿里云发行版,针对阿里云服务器ECS做了大量深度优化,Alibaba Cloud Linux由阿里云官方免费提供长期支持和维护LTS,Alibaba Cloud Linux完全兼容CentOS/RHEL生态和操作方式…...

什么是数据结构?
1、一种非常经典的数据结构。 栈数据结构:stack 2、什么是数据结构? 数据结构通常是:存储数据的容器。而该容器可能存在不同的结构。 数据结构和 java 语言实际上是没有关系,数据结构是一门独立的学科。 在大学计算机专业中&#…...

GOOS=darwin 代表macOS环境
GOOSdarwin 是一个环境变量设置,表示目标操作系统为 macOS。 在Go语言中,可以使用环境变量 GOOS 来指定目标操作系统,用于交叉编译或跨平台开发。darwin 是指苹果公司的操作系统系列,主要是 macOS。 通过设置 GOOSdarwin&#x…...
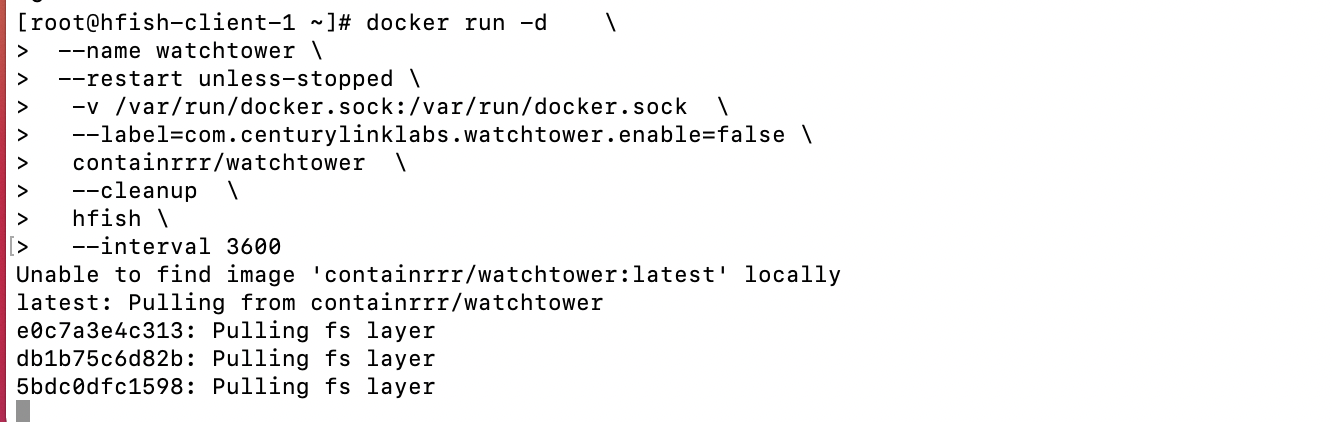
hfish蜜罐docker部署
centos 安装 docker-CSDN博客Docker下载部署 Docker是我们推荐的部署方式之一,当前的版本拥有以下特性: 自动升级:每小时请求最新镜像进行升级,升级不会丢失数据。数据持久化:在宿主机/usr/share/hfish目录下建立dat…...

我的创作纪念日——redis的历史纪录
机缘 最开始只想存留点Redis的操作信息,后来写着写着也就写多了,虽然后面很长时间由于忙就没继续写,但是还是偶尔登录看一下,有好几篇文章的浏览量还是很多的呢。 收获 收获不多,粉丝也才三十多个,浏览量感…...

【Bootstrap5学习 day10】
Flex布局 弹性盒子是CSS3的一种新的布局模式,更适合响应式的设计 创建一个弹性盒子容器 使用d-flex类,创建flexbox容器并将直接子项转换为flex项 <div class"d-flex p-3 bg-info text-white"><div class"p-2 bg-secondary"…...

2024年学习计划
2024-2-29号完成 机器视觉基础知识学习,并可以处理视觉工作中的需求。 2024-3月份学习SCARA机械手应用开发SCARA机器人-埃斯顿自动化 - ESTUN 2024-4月份继续学习python 好了,今年可以完成这三个目标就满足了 好好学习,天天向上。每天进步…...
学习笔记:C++之 switch语句
Switch语句 作用:执行多条件分支语句 语法: switch(表达式){ case 结果1:执行语句;break; case 结果2:执行语句;break; ... default:执行语句&a…...

C++ 具名要求-全库范围的概念
此页面中列出的具名要求,是 C 标准的规范性文本中使用的具名要求,用于定义标准库的期待。 某些具名要求在 C20 中正在以概念语言特性进行形式化。在那之前,确保以满足这些要求的模板实参实例化标准库模板是程序员的重担。若不这么做…...

别再乱收CAN报文了!STM32F407的HAL库CAN过滤器配置保姆级避坑指南
STM32F407 HAL库CAN过滤器配置:从原理到实战的深度解析 在嵌入式系统开发中,CAN总线因其高可靠性和实时性被广泛应用于汽车电子、工业控制等领域。然而,许多开发者在STM32F407上使用HAL库配置CAN过滤器时,常常陷入"能接收数据…...

基于Code Llama的本地AI编程助手:VSCode插件部署与优化实战
1. 项目概述:为什么我们需要一个更聪明的代码助手?在VSCode的插件市场里搜索“AI代码补全”,结果可能会让你眼花缭乱。从基于GPT的Copilot到各种开源模型驱动的工具,选择很多,但痛点也很明显:要么需要稳定的…...
)
YOLOv8无人机识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 针对低空无人机(drone)的检测需求,本文基于YOLOv8目标检测算法构建了一个无人机识别系统。实验采用自建无人机数据集,包含训练集1012张图像、验证集347张图像,类别为单一目标“drone”。模型训练过程中ÿ…...

量子计算中的辛基理论与MBQC实现
1. 量子计算中的辛基基础概念在量子计算领域,辛基(Symplectic Basis)是描述多量子比特系统的重要数学工具。它本质上是一个满足特定对易关系的基组,能够简洁地表示量子态和量子操作。理解辛基需要从有限域上的向量空间开始——具体…...

嵌入式飞行控制实战:从传感器融合到PID调参的无人机飞控开发指南
1. 项目概述与核心价值最近在嵌入式开发圈子里,一个名为trsdn/nanopielot的项目引起了我的注意。乍一看这个名字,它像是一个针对特定硬件平台(比如树莓派 Pico 或类似的 RP2040 微控制器)的飞行控制项目。nanopi可能指代 NanoPi 系…...
Transformer与NLP资源全指南:从原理到工程实践的高效学习路径
1. 项目概述:为什么我们需要一个Transformer与NLP的“Awesome”清单?如果你在过去几年里深度参与过自然语言处理(NLP)领域的工作或学习,那么“Transformer”这个词对你来说,可能已经从一种新颖的架构&#…...

VCF 9.1 实验室部署 ESX 配置变通方案
以下配置适用于资源受限环境、非生产用途,仅用于功能测试与学习目的。一、物理 ESX 9.1 主机1. vSAN 压缩算法(CPU 受限环境)VCF 9.1 默认从 LZ4 改为 Zstd,压缩率更高但 CPU 占用更高。切回 LZ4(无需重启)…...

告别烦人黑窗口!QT Creator控制台程序输出完美嵌入IDE的两种方法
告别烦人黑窗口!QT Creator控制台程序输出完美嵌入IDE的两种方法 每次调试QT控制台程序时,那个突然弹出的黑窗口是否总让你手指悬停在AltTab键上?作为深耕QT开发多年的技术顾问,我见过太多开发者被这个"窗口刺客"打断思…...
)
从Processing到Arduino IDE:一个让硬件编程变简单的GUI故事(附STM32兼容板配置避坑)
从Processing到Arduino IDE:硬件编程的平民化革命与STM32实战指南 2005年,当Massimo Banzi在意大利伊夫雷亚交互设计学院第一次向学生们展示那块蓝色电路板时,他可能没想到这个简单的教学工具会彻底改变嵌入式开发的世界。Arduino IDE的诞生并…...

面试鸭:一站式面试题库解决方案,助你轻松备战技术面试
面试鸭:一站式面试题库解决方案,助你轻松备战技术面试 【免费下载链接】mianshiya-public 持续维护的企业面试题库网站,帮你拿到满意 offer!⭐️ 2026年最新Java面试题、前端面试题、AI大模型面试题、AI Agent面试题、RAG面试题、…...