CoTracker 环境配置与ORB 特征点提取结合实现视频特征点追踪
CoTracker 环境配置&与ORB 特征点提取结合实现视频特征点追踪
文章目录
- CoTracker 环境配置&与ORB 特征点提取结合实现视频特征点追踪
- Step1:配置 CoTracker 环境
- Step2:运行官方的例程
- Step3:结合 ORB 特征点提取
- 结果展示:
- Step4:针对相机进行实时追踪,但失败
- 5.内部代码的修改
Meta 新开源 CoTracker:跟踪任意长视频中的任意多个点,并且可以随时添加新的点进行跟踪!并且性能上直接超越了谷歌的 OmniMotion。
我所做的项目是对相机捕获的图像进行实时追踪。当时没有研究过这个网络,所以想着配一下环境,看看后续可不可以应用在相机上。
但是:事与愿违,配好了环境,并且在 Demo 里面也可以获取视频,对视频第一帧进行 ORB 特征点识别然后在全局视频里面进行追踪,可是发现没有办法进行相机的实时跟踪处理。
后面在大致看过网络结构(其实)以及相关文献之后,终于确定 ,这个牛逼的 CoTracker 因为其网路输入只能是视频格式的长时间数据 因此并不能进行相机的实时处理。所以如果后面的小伙伴也要用相机去做,建议搜索 LightGlue 等其他的方法(光流法、或者神经网络)等等进行实时追踪。
想继续了解 CoTracker 原理的小伙伴可以参考这一篇博文相关链接: CoTracker跟踪器 - CoTracker: It is Better to Track Together
CoTracker 项目的源代码链接也在这里,可自行下载: co-tracker
Step1:配置 CoTracker 环境
首先下载 conda,然后安装虚拟环境。
conda craete -n cotracker python=3.8conda activate cotracker
然后根据官方提示从 Github 上面下载源码。
参考官方的提示,这个项目支持在 CPU 和 GPU 上运行,因此在配置环境时建议同时安装支持 CUDA 的 PyTorch 和 TorchVision。
官方链接的终端命令贴出来了,需要可自行粘帖。
git clone https://github.com/facebookresearch/co-trackercd co-trackerpip install -e .pip install matplotlib flow_vis tqdm tensorboard
因为官方有已经训练好的权重文件,我们只需要下载下来就可以在 Demo 里面直接调用。命令也在此处。
mkdir -p checkpointscd checkpointswget https://huggingface.co/facebook/cotracker/resolve/main/cotracker2.pthcd ..
当然,这个 CoTracker 在配置环境过程中肯定会有一些库的版本不对,因此需要重新卸载再安装一些库的版本。
以下是我的 cotracker 虚拟环境里面需要的库版本(只摘出来 Setup.py 文件里安装的,以及通过命令行安装的库)。大家可自行对照。
matplotlib 3.7.3flow-vis 0.1opencv-python 4.8.1.78torch 2.1.1torchaudio 2.1.1torchsummary 1.5.1torchvision 0.16.1tqdm 4.66.1tensorboard#(没找到,不过并不影响 CoTracker 的使用)
Step2:运行官方的例程
官方有一份 demo.py 文件可以直接调用一些接口,方便进行视频的处理,但是为了更好的了解里面的一些借口的参数。建议可以参考项目里面的 demo.ipynb 文件,按照里面的步骤,自己重新写一个 demo 文件。
Step3:结合 ORB 特征点提取
为了下一步进行视频帧追踪预演,提前编写了一个针对连续图像读取并追踪的代码(注意:代码里面输入的不是一个视频,而是将一连串连续的图片转换成张量的数据格式传入了 GPU,所以虽然不是视频,但是效果差不多)。如下所示:
import os
import cv2
import torch
import argparse
import numpy as np
from base64 import b64encode
from PIL import Image
import matplotlib.pyplot as plt
from cotracker.utils.visualizer import Visualizer, read_video_from_path
from cotracker.predictor import CoTrackerPredictor
import torch.nn.functional as Fdef convert_images_to_tensor(image_folder):image_files = sorted(os.listdir(image_folder)) # 获取图片文件列表并排序first_path = os.path.join(image_folder, image_files[0])print(first_path)images = []n = 0for image_file in image_files:n += 1print(n)image_path = os.path.join(image_folder, image_file)image = cv2.imread(image_path) # 使用OpenCV读取图片height, width, _ = image.shapeleft_half = image[:, :width//2, :]image = cv2.cvtColor(left_half, cv2.COLOR_BGR2RGB) # 将图片从BGR颜色空间转换为RGBimage_tensor = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0).float() # 转换为PyTorch张量images.append(image_tensor)video_tensor = torch.stack(images)video_tensor = video_tensor.permute(1, 0, 2, 3, 4) # 转换成视频张量的形式shape = video_tensor.shapeprint(shape[0], shape[1], shape[2], shape[3], shape[4])return first_path, video_tensor# 特征点检测的参数
max_corners = 30
quality_level = 0.1
min_distance = 200def orb_track_points(first_image_path):raw_image = cv2.imread(first_image_path)height, width, _ = raw_image.shaperaw_left_image = raw_image[:, :width // 2, :] # 只取左边部分corners = cv2.goodFeaturesToTrack(cv2.cvtColor(raw_left_image, cv2.COLOR_BGR2GRAY), max_corners, quality_level, min_distance)corners = np.int0(corners)queries = []# 將图像上检测到的特征点,添加到追踪里面for corner in corners:x, y = corner.ravel()# cv2.circle(raw_left_image, (x, y), 2, vector_color[i].tolist(), 2)coordinate = [0., float(x), float(y)]queries.append(coordinate)queries = torch.tensor(queries)print(queries)# 并将图像上选取的点变成张量输入if torch.cuda.is_available():queries = queries.cuda()# 创建了一个包含四个子图的2x2图像网格,用于可视化查询点的位置,将查询点的帧号提取出来,并转换为整数类型的列表 frame_numbers。帧号将用于在每个子图上显示对应的帧数frame_numbers = queries[:, 0].int().tolist()# plt.subplots()函数创建了一个图像网格, 并将返回的“轴”对象存储在变量axs中fig, axs = plt.subplots(1, 1)# 通过调用axs.set_title()设置子图的标题为"Frame {}axs.set_title("Frame {}".format(0))# 通过enumerate()函数同时迭代查询点(query)和对应的帧号(frame_number)for i, (query, frame_number) in enumerate(zip(queries, frame_numbers)):# 使用plot()函数在该子图上绘制一个红色的点,其坐标为(query[1].item(), query[2].item())axs.plot(query[1].item(), query[2].item(), 'ro')# 设置子图的x和y轴范围axs.set_xlim(0, video.shape[4])axs.set_ylim(0, video.shape[3])# 翻转y轴,以与视频的坐标系一致axs.invert_yaxis()# 调整子图之间的布局plt.tight_layout()plt.savefig('./saved_videos/image_grid.png')return queries# 指定图片文件夹路径
# images_folder = "./assets/1212/snapSave_p/Cam_2" # Pitch 俯仰角
images_folder = "./assets/1212/snapSave_r/Cam_2" # Roll 翻滚角
# images_folder = "./assets/1212/snapSave_y/Cam_2" # Taw 偏航角# 调用函数将图片转换为张量
first_im_path, video = convert_images_to_tensor(images_folder)
image_queries = orb_track_points(first_im_path)model = CoTrackerPredictor(checkpoint=os.path.join('./checkpoints/cotracker_stride_4_wind_8.pth')
)if torch.cuda.is_available():model = model.cuda()video = video.cuda()# 前向
pred_tracks, pred_visibility = model(video, queries=image_queries[None])
print("数据计算完毕")
vis = Visualizer(save_dir='./saved_videos', linewidth=2, mode='cool', tracks_leave_trace=-1)# tracks_leave_trace = -1 可以显示出跟踪点的轨迹
vis.visualize(video=video, tracks=pred_tracks, visibility=pred_visibility, filename='orb_track')
print("视频存储完成")
# 原文里面有考虑对相机运动的补偿消除一些影响,但是代码里面这一部分设定为 False,即没有考虑相机运动的影响
# 因此 pred_tracks, pred_visibility 即跟踪真实值
track_save_data = './saved_videos/track_data'
if not os.path.exists(track_save_data):os.makedirs(track_save_data)for i in range(max_corners):format_i = "{:02d}".format(i)with open(track_save_data + '/save_data_' + str(format_i), 'w') as data_txt:for pred_track in pred_tracks[0]:point_track = str(pred_track[i][0].item()) + ' ' + \str(pred_track[i][1].item()) + '\n'data_txt.write(point_track)data_txt.close()print("数据文件关闭")
结果展示:
orb_track_pred_track
Step4:针对相机进行实时追踪,但失败
还是之前说的,因为 CoTracker 的神经网络本身在训练模型的时候就是以视频作为输入数据进行输入的,因此针对连续图片可以做到追踪,但时如果只是单个图片,那么追踪将无法进行。
下面可能就有小伙伴会想,通过缩小传入视频的帧率再输入。例如将 3 ~ 4 帧的图片作为一个短视频输入进去,然后计算出来结果后,将结果保存并用于下一个短视频的追踪,如此往复,实现相机实时追踪效果。
这个方向我也尝试过,但时 CoTracker 本身在进行视频的特征点计算的时候,就极其消耗算力。而且这个消耗的时间随着传入的视频时间以及要追踪的特征点数量线性增加。
我的设备是 RTX4060 和 i7-12650。性能还算可以。但是在传入一个连续 5 帧的视频,并追踪 10 个点的时候,依旧要花费 0.3 ~ 0.4 秒时间计算。出现的结构就是,视频一卡一卡的,实时跟踪效果很差。
(为什么传入 5 帧? 因为 5 帧已经是网络输入要求的最低帧数了,再小就没有结果输出了。)
代码依旧贴在下面,其实就是在上面视频的基础上进行的改进:
import os
import cv2
import torch
import argparse
import numpy as np
from base64 import b64encode
from PIL import Image
import matplotlib.pyplot as plt
from cotracker.utils.visualizer import Visualizer, read_video_from_path
from cotracker.predictor import CoTrackerPredictor
import torch.nn.functional as F
import timedef mkdir():if not os.path.exists(saved_videos):os.makedirs(saved_videos)def initialize(first_image):n = 5i = 0images_pytorch = []image = cv2.cvtColor(first_image, cv2.COLOR_BGR2RGB) # 将第一张图片从BGR颜色空间转换为RGBimage_tensor = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0).float() # 转换为PyTorch张量images_pytorch.append(image_tensor)while i < 5:ret, current_image = cap.read()image = cv2.cvtColor(current_image, cv2.COLOR_BGR2RGB) # 将第一张图片从BGR颜色空间转换为RGBimage_tensor = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0).float() # 转换为PyTorch张量images_pytorch.append(image_tensor)i += 1# 將图片张量转换成网络输入视频张量的形式video_tensor = torch.stack(images_pytorch)video_tensor = video_tensor.permute(1, 0, 2, 3, 4) # 转换成视频张量的形式print("video tensor------------------------------------------------------")print(video_tensor)return images_pytorch, video_tensor# 特征点检测的参数
max_corners = 5
quality_level = 0.1
min_distance = 100def orb_track_points(first_image_):# # 仿生眼相机图像前处理部分# raw_image = cv2.imread(first_image_path)# height, width, _ = raw_image.shape# raw_left_image = raw_image[:, :width // 2, :] # 只取左边部分# corners = cv2.goodFeaturesToTrack(cv2.cvtColor(raw_left_image, cv2.COLOR_BGR2GRAY), max_corners, quality_level, min_distance)# corners = np.int0(corners)# # 电脑相机图像处理部分corners = cv2.goodFeaturesToTrack(cv2.cvtColor(first_image_, cv2.COLOR_BGR2GRAY), max_corners, quality_level, min_distance)corners = np.int0(corners)queries = []# 將图像上检测到的特征点,添加到追踪里面for corner in corners:x, y = corner.ravel()coordinate = [0., float(x), float(y)]queries.append(coordinate)queries = torch.tensor(queries)# 并将图像上选取的点变成张量输入if torch.cuda.is_available():queries = queries.cuda()return queriesdef convert_images_to_tensor(current_image, pre_images_pytorch):# # 將当前图像转换成 pytorch 张量,仿生眼相机图像预处理# height, width, _ = current_image.shape# left_half = current_image[:, :width // 2, :]# image = cv2.cvtColor(left_half, cv2.COLOR_BGR2RGB) # 将图片从BGR颜色空间转换为RGB# 將当前图像转换成 pytorch 张量,电脑相机图像预处理image = cv2.cvtColor(current_image, cv2.COLOR_BGR2RGB) # 将图片从BGR颜色空间转换为RGBimage_tensor = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0).float() # 转换为PyTorch张量# 再將图片存入 pre_images 里面进行后续的跟踪计算pre_images_pytorch.append(image_tensor)update_images_pytorch = pre_images_pytorch[1:]# print("update_images_pytorch: %d", update_images_pytorch)# 將图片张量转换成网络输入视频张量的形式video_tensor = torch.stack(update_images_pytorch)video_tensor = video_tensor.permute(1, 0, 2, 3, 4) # 转换成视频张量的形式return update_images_pytorch, video_tensorif __name__ == '__main__':saved_videos = "./assets/saved_videos/"mkdir()# 开启相机获取图像cap = cv2.VideoCapture(0)if not cap.isOpened():print("无法打开视频文件")exit()ret, first_frame = cap.read()if not ret:print("无法获取图像")exit()first_queries = orb_track_points(first_frame)first_images_pytorch, first_video = initialize(first_frame)print(first_queries) # 分别是 0, x, y# 加载模型文件model = CoTrackerPredictor(checkpoint=os.path.join('./checkpoints/cotracker_stride_4_wind_8.pth'))print("模型创建完毕")# 將视频数据和模型数据转换if torch.cuda.is_available():model = model.cuda()first_video = first_video.cuda()# 前向first_tracks, first_visibility = model(first_video, queries=first_queries[None]) # 此处的 None 是用来增加维度的print("数据计算完毕")vis = Visualizer(save_dir=saved_videos, linewidth=2, mode='cool', tracks_leave_trace=-1) # t_l_t:-1显示跟踪轨迹print('----------------------------------------------------------------------pre')print(first_tracks[0])vis.visualize(video=first_video, tracks=first_tracks, visibility=first_visibility, filename='orb_track')print("视频存储完成")images_pytorch = first_images_pytorch# 跟踪部分while True:ret, current_frame = cap.read()cv2.imshow("current", current_frame)cv2.waitKey(20)images_pytorch, current_video = convert_images_to_tensor(current_frame, images_pytorch)# 將视频数据和模型数据转换if torch.cuda.is_available():model = model.cuda()current_video = current_video.cuda()# 前向current_tracks, current_visibility = model(current_video, queries=first_queries[None]) # 此处的 None 是用来增加维度的print("----------------------------------------------------------")print(current_tracks[0][0])print("数据计算完毕")5.内部代码的修改
原本代码里面为了显示跟踪的连续性,在可视化部分 ,将追踪点在不同时间段的轨迹连成了一条线。
我的项目里面之前为了结果的点的轨迹可以清楚一些,因此修改了原本可视化里面连线的部分,该成了画点。如下所示,里面注释掉的部分为曾经画线的代码,下面新增的为画点的代码
def _draw_pred_tracks(self,rgb: np.ndarray, # H x W x 3tracks: np.ndarray, # T x 2vector_colors: np.ndarray,alpha: float = 0.5,):radius = 2 # 半径thickness = 2 # 线条宽度T, N, _ = tracks.shapefor s in range(T - 1):vector_color = vector_colors[s]original = rgb.copy()alpha = (s / T) ** 2for i in range(N):coord_x = (int(tracks[s, i, 0]), int(tracks[s, i, 1]))if coord_x[0] != 0 and coord_x[1] != 0:cv2.circle(rgb, coord_x, radius, vector_color[i].tolist(), thickness) # 直接画出之前轨迹的点if self.tracks_leave_trace > 0:rgb = cv2.addWeighted(rgb, alpha, original, 1 - alpha, 0)# 遍历之前追踪的点集,然后连接相邻两点,画一条直线,构成轨迹图
# for s in range(T - 1):
# vector_color = vector_colors[s]
# original = rgb.copy()
# alpha = (s / T) ** 2
# for i in range(N):
# coord_y = (int(tracks[s, i, 0]), int(tracks[s, i, 1]))
# coord_x = (int(tracks[s + 1, i, 0]), int(tracks[s + 1, i, 1]))
# if coord_y[0] != 0 and coord_y[1] != 0:
# cv2.line(
# rgb,
# coord_y,
# coord_x,
# vector_color[i].tolist(),
# self.linewidth,
# cv2.LINE_AA,
# )
# if self.tracks_leave_trace > 0:
# rgb = cv2.addWeighted(rgb, alpha, original, 1 - alpha, 0)return rgb
当然不排除可能是本人技术太菜无法实现 CoTracker 的相机实时性追踪。如果后面有小伙伴实现了,欢迎在评论区里面分享。
相关文章:
CoTracker 环境配置与ORB 特征点提取结合实现视频特征点追踪
CoTracker 环境配置&与ORB 特征点提取结合实现视频特征点追踪 文章目录 CoTracker 环境配置&与ORB 特征点提取结合实现视频特征点追踪Step1:配置 CoTracker 环境Step2:运行官方的例程Step3:结合 ORB 特征点提取结果展示: …...
10000000000 大瓜背后的真相(附 PDD 算法真题)
10 个亿的大事? 京东诉阿里强迫商家「二选一」,京东胜诉,获阿里赔偿 10 亿。 很多小伙伴见到公主号开创了锐评时事板块,当天就在后台留言问我看法。 先说结论:这是一则「媒体影响力」远大于「实际意义」的报道。 首先&…...

python爬虫,简单的requests的get请求,百度搜索实例
1、百度搜索实例 import requests url https://www.baidu.com/s? # key_word 迪丽热巴 key_word input(输入搜索内容:) headers {User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537…...

UNION 和 UNION ALL
概述 UNION 和 UNION ALL 都是 SQL 中用于将多个 SELECT 语句的结果合并成一个结果集的操作符。它们都适用于需要将多个表或查询结果合并在一起的情况。但是它们的行为略有不同。 区别 UNION 和 UNION ALL 的区别在于,UNION 会将结果集合并成一个不含重复行的结果…...
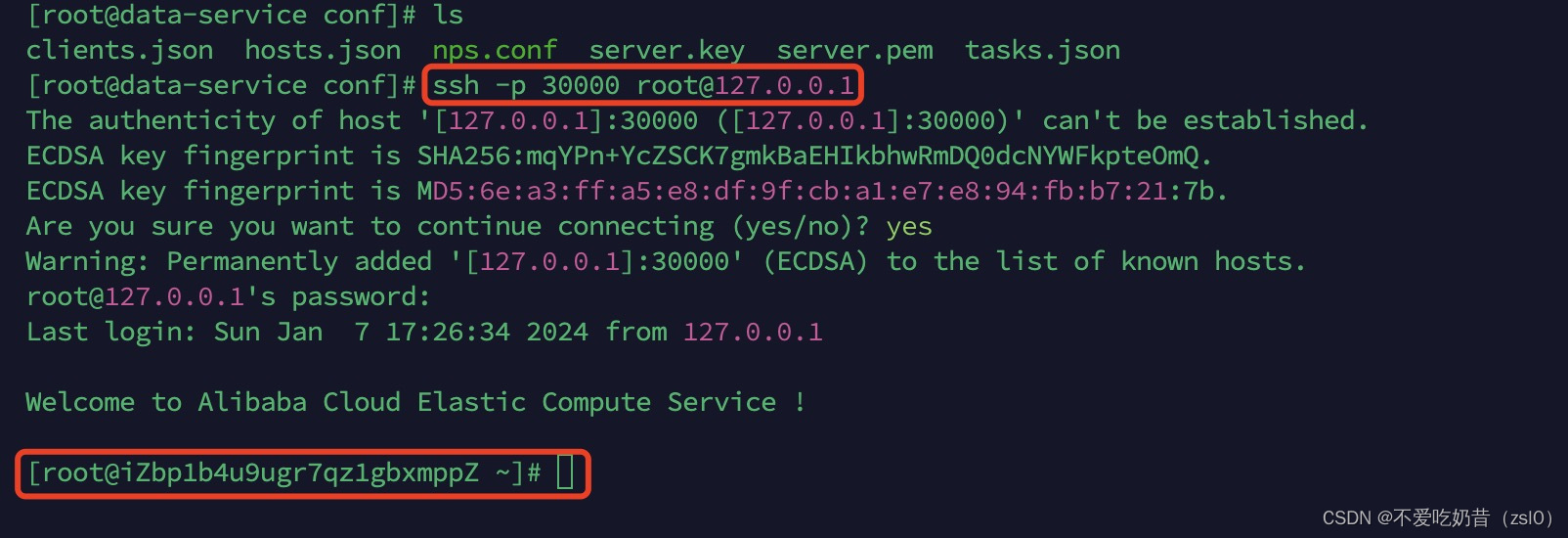
NPS 内网穿透安装
NPS 内网穿透安装 NPS 内网穿透安装服务端搭建SSH配置流程 NPS 内网穿透安装 NPS分为服务端和客户端,对应的不同操作系统软件可以在GitHub RELEASES自行选择下载。 服务端搭建 由于个人非企业级使用,为了方便直接使用docker安装 1.docker运行 (注意…...

【C++学习笔记】C++多值返回写法
C不像python可以轻易地处理多值返回问题,处理使用指针或者引用将需要返回的值通过参数带出来,还有几种特殊的方式。 引用自:https://mp.weixin.qq.com/s/VEvUxpcJPsxT9kL7-zLTxg 1. Tuple tie 通过使用std::tie,我们可以将tuple…...

读取带有梯度的张量的具体的值
问题:存在一个带有梯度的张量tensor_example,怎么读取它具体的值 方法:可以使用 .detach().cpu().numpy() 的组合。这样可以在保留值的同时,将张量从计算图中分离(detach)并移动到 CPU 上。 示例…...
【分布式微服务专题】SpringSecurity快速入门
目录 前言阅读对象阅读导航前置知识笔记正文一、Spring Security介绍1.1 什么是Spring Security1.2 它是干什么的1.3 Spring Security和Shiro比较 二、快速开始2.1 用户认证2.1.1 设置用户名2.1.1.1 基于application.yml配置文件2.1.1.2 基于Java Config配置方式 2.1.2 设置加密…...
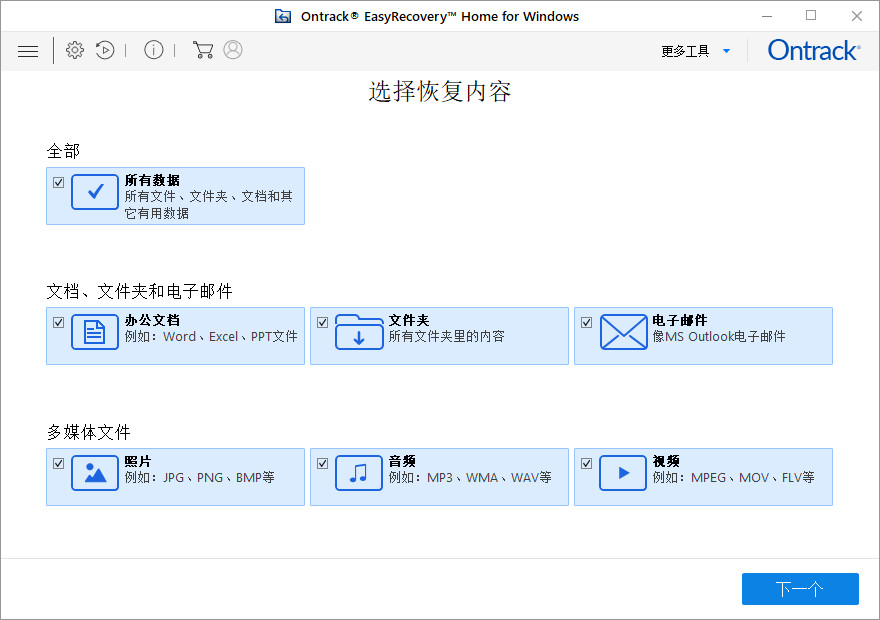
EasyRecovery2024永久免费版电脑数据恢复软件
EasyRecovery是一款操作安全、价格便宜、用户自主操作的非破坏性的只读应用程序,它不会往源驱上写任何东西,也不会对源驱做任何改变。它支持从各种各样的存储介质恢复删除或者丢失的文件,其支持的媒体介质包括:硬盘驱动器、光驱、…...
iphone 苹果 IOS 越狱详细图文保姆级教程非常简单
现在随着各个工具的升级,越狱的难度也是越来越低,还记得 iphone 4 的时候我越狱还是花钱请别人搞得,现在只要你的机型支持越狱,下个工具点一点就可以了,非常简单 目前来说整个越狱过程中,寻找合适机型是最…...
华为HarmonyOS 创建第一个鸿蒙应用 运行Hello World
使用DevEco Studio创建第一个项目 Hello World 1.创建项目 创建第一个项目,命名为HelloWorld,点击Finish 选择Empty Ability模板,点击Next Hello World 项目已经成功创建,接来下看看效果 2.预览 Hello World 点击右侧的预…...
[C#]Onnxruntime部署Chinese CLIP实现以文搜图以文找图功能
【官方框架地址】 https://github.com/OFA-Sys/Chinese-CLIP 【算法介绍】 在当今的大数据时代,文本信息处理已经成为了计算机科学领域的核心议题之一。为了高效地处理海量的文本数据,自然语言处理(NLP)技术应运而生。而在诸多N…...

openssl ans1定义的实体
由于openssl中的ASN1的结构是通过宏来定义的,导致我们经常找不到他的结构在哪里,通过阅读rfc,并且对照OPENSSL,发现OPENSSL中的结构基本是按照相关rfc中的名称,在openssl中进行搜索,就能找到具体的定义了。…...

【Linux Shell】4. 数组
文章目录 【 1. 数组的定义 】【 2. 读取数组 】【 3. 关联数组 】3.1 关联数组的定义3.2 关联数组元素的调用 【 4. 获取数组中的所有元素 】【 5. 获取数组的长度 】 数组中可以存放多个值。 Bash Shell 只支持一维数组(不支持多维数组),初…...

蓝牙运动耳机哪款好用?运动用什么耳机比较好?2024运动耳机推荐
在众多的耳机类型中,运动耳机因其独特的设计和功能而备受青睐。它们不仅要具备出色的音质,还需要能够适应激烈的运动环境,如防水、防汗、牢固耐用等。今天,我想向大家推荐一些在这些方面表现出色的运动耳机,这些耳机…...
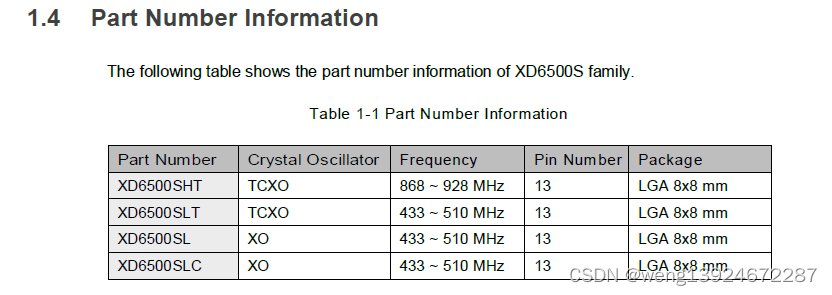
XD6500S一款串口SiP模块 射频LoRa芯片 内置sx1262
1.1产品介绍 XD6500S是一款集射频前端和LoRa射频于一体的LoRa SIP模块系列收发器SX1262 senies,支持LoRa⑧和FSK调制。LoRa技术是一种扩频协议优化低数据速率,超长距离和超低功耗用于LPWAN应用的通信。 XD6500S设计具有4.2 mA的有效接收电流消耗&#…...
【华为OD机试真题2023CD卷 JAVAJS】测试用例执行计划
华为OD2023(C&D卷)机试题库全覆盖,刷题指南点这里 测试用例执行计划 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 某个产品当前迭代周期内有N个特性()需要进行覆盖测试,每个特性都被评估了对应的优先级,特性使用其ID作为下标进行标识。 设计了M个测试用…...

猫长期吃猫粮好吗?主食冻干猫粮那种好吃又健康
许多铲屎官可能认为,只需给猫咪喂食猫粮就足够了。然而,猫咪实际上是肉食动物,对蛋白质的需求非常高。冻干猫粮采用低温真空干燥处理技术,将鲜肉经过预冻、升华、解析三个过程,去除水分的同时保持蛋白质等营养物质不变…...

计算机毕业设计-----ssm停车位租赁系统
项目介绍 该系统采用了经典的springmvc,spring,mybatis的框架组合,对于物业公司来说,有助于管理车位信息。系统分为了两个角色:车主和租客。 车主主要功能包括: 停车位信息 停车位列表 添加停车位 租赁合…...
Git保姆级安装教程
Git保姆级安装教程 一、去哪下载二、安装2.1 具体安装步骤2.2 设置全局用户签名 一、去哪下载 1、官网(有最新版本):https://git-for-windows.github.io/ 2、本人学习时安装的版本,链接:https://pan.baidu.com/s/1uAo…...

Windows: 深入剖析pip install SSLError与SSL模块缺失的根源及系统级修复
1. Windows下pip install SSLError的典型表现 最近在Windows系统上用pip安装Python包时,不少朋友都遇到了这样的报错信息:"Cant connect to HTTPS URL because the SSL module is not available"。这个错误通常会出现在使用清华源、阿里云源等…...

告别手动PPT制作:用JavaScript实现自动化演示文稿生成
告别手动PPT制作:用JavaScript实现自动化演示文稿生成 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 还在为每周重…...

现代前端项目模板:从工程化配置到最佳实践全解析
1. 项目概述:一个现代前端开发的起点在接手一个新项目,特别是前端项目时,最耗时的往往不是核心业务逻辑的开发,而是那些重复性的基础搭建工作:配置构建工具、集成代码规范、设置路由和状态管理、搭建基础布局组件……每…...

Vivado功耗分析保姆级教程:从综合后DCP到布局布线后的精确估算
Vivado功耗分析深度实战:从DCP文件到精准优化策略 在FPGA设计流程中,功耗分析往往被工程师视为"最后一公里"的验证环节,但实际上它应该贯穿整个设计周期。Xilinx Vivado提供的功耗分析工具链,能够帮助我们从早期综合阶段…...

Python小说爬虫框架NovelClaw:模块化设计与规则驱动实践
1. 项目概述:一个为小说爱好者打造的智能采集与整理工具如果你和我一样,是个重度小说爱好者,同时又有点技术背景,那你肯定遇到过这样的烦恼:追更的小说散落在十几个不同的网站,更新提醒全靠缘分;…...

驾驶舱前端设计方案:从“花架子”到“真能用”的组件化实战
很多人一提起“驾驶舱”或“ dashboard ”,脑海里浮现的就是:满屏图表、深色背景、会转动的3D地球、还有一堆看起来很高端但没人点开的按钮。但真正在一线做过驾驶舱的人都知道——大部分驾驶舱,上线当天截个图发朋友圈之后,就再也…...

3分钟掌握Ofd2Pdf:轻松解决OFD转PDF的格式兼容难题
3分钟掌握Ofd2Pdf:轻松解决OFD转PDF的格式兼容难题 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf Ofd2Pdf是一款专为中文用户设计的开源工具,能够高效地将OFD格式文件转换为通…...

HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案
HsMod:炉石传说终极模改插件完整指南 - 300%游戏体验提升方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...

从仿真到避坑:在Matlab中为LFM信号加噪与时频分析的正确姿势
从仿真到避坑:在Matlab中为LFM信号加噪与时频分析的正确姿势 信号处理工程师们常说:"仿真的第一步,往往决定了结果的最后一步。"这句话在LFM(线性调频)信号处理中尤为贴切。作为雷达、声呐等领域的核心波形&…...

GSE-Advanced-Macro-Compiler:重新定义魔兽世界技能管理的智能编排系统
GSE-Advanced-Macro-Compiler:重新定义魔兽世界技能管理的智能编排系统 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advan…...