Elasticsearch中object类型与nested类型以及数组之间的区别
一、区别:
0、一般情况下用object 类型来查es中为json对象的字段数据,用nested来查es中为JsonArray数组类型的字段数据。
1、默认情况下ES会把JSON对象直接映射为object类型,只有手动设置才会映射为nested类型
2、object类型可以直接使用普通的逗号(.)查询,比如
{"query": {"term": {"inspector.id": {"value": "222"}}}
}
3、nested类型的查询需要使用nested查询:
{"query": {"nested": {"path": "inspector","query": {"term": {"inspector.id": {"value": "222"}}}} }
}
4、两种查询方式不兼容,如果大家想做改动的话,需要对java程序进行修改,风险比较大。
5、存储方式不同。对象数组在后台是扁平化存储,嵌套对象数组是每个对象独立成文档存储。因此,对象数据有时会有"且"条件查询出"或"结果,嵌套对象的文档聚合可能会多计数(除非加reverse_nested),想保持数组中对象的独立性,就需要使用嵌套字段类型。
二、Object类型字段
1:mapping
注意,如果没有写明type,比如categoryObj,ES会默认object类型,并且就算查看mapping,也不会显示出来:
// 所属类目,对象类型,注意这里没有写明type,ES则会默认为object"categoryObj": {//"type":"object","properties": {"class1": {"type": "keyword"},"class2": {"type": "keyword"},"class3": {"type": "keyword"}}}
2:增加数据
PUT test_index_20211220/e-com/1
{"id": "1","name": "L'oreal/欧莱雅复颜玻尿酸水光充盈导入膨润精华液","brand": "欧莱雅","price": 279,"desc": "补水 提拉紧致 淡化细纹","categoryObj": {"class1": "欧莱雅","class2": "补水","class3": "面部护理"}
}3:查询
在样例数据中,“categoryObj"字段被默认设置为object类型(没有显示设置type),对于对象类型,在查询时需要用”."号连接整个字段:
GET test_index_20211220/_search
{"query": {"term": {"categoryObj.class1": "欧莱雅"}}
}4:对象数组特性
我们知道了嵌套字段中的对象被ES存储为了独立的文档,那对象字段呢?ES在后台将对象字段进行打平处理,后台其实存储的是扁平结构,以categoryObj字段为例:
"categoryObj": [{"class1": "欧莱雅","class2": "补水","class3": "面部护理"},{"class1": "欧莱雅","class2": "补水","class3": "面部精华"},{"class1": "雅诗兰黛","class2": "美白","class3": "面霜"}
]后台存储的其实是:
{"categoryObj.class1": ["欧莱雅","欧莱雅","雅诗兰黛"],"categoryObj.class2": ["补水","补水","美白"],"categoryObj.class3": ["面部护理","面部精华","面霜"]
}这就牺牲了对象之间的独立性,有时候会带来一些影响,具体就是某些情况下,对对象数组的"且"查询可能会变成"或"查询。
这个时候我们去同时查询"欧莱雅"和"美白"这两个关键词,正常来说是不应该差出来任何文档的,因为categoryObj中没有任何一个对象同时具备"欧莱雅"和"美白"这两个关键词,可事实确不是这样:
GET test_index_20211220/_search
{"query": {"bool": {// filter上下文"filter": {"bool": {"must": [{"term": {"categoryObj.class1": "欧莱雅"}},{"term": {"categoryObj.class2": "美白"}}]}}}}
}结果居然将文档查询出来了
所以当字段为数组的时候,建议使用nested类型字段。
三、Nested类型字段
1:mapping
// 所属类目,嵌套类型"categoryNst": {"type": "nested","properties": {"class1": {"type": "keyword"},"class2": {"type": "keyword"},"class3": {"type": "keyword"}}}
2:增加数据
PUT test_index_20211220/e-com/1
{"id": "1","name": "L'oreal/欧莱雅复颜玻尿酸水光充盈导入膨润精华液","brand": "欧莱雅","price": 279,"desc": "补水 提拉紧致 淡化细纹","categoryNst": {"class1": "欧莱雅","class2": "补水","class3": "面部护理"}
}3:查询
GET test_index_20211220/_search
{"query": {"nested": {"path": "categoryNst", #nested对象的查询深度"query": {"term": {// 在以前的版本中直接写 "class2": "补水"也是可以的,因为已经在外部声明了path// 不知道从哪个版本改了,现在必须写 "categoryNst.class2": "补水",否则报错"categoryNst.class2": "补水"}}}}
}4: 嵌套字段的特性
嵌套字段其实是把其内部成员当做了一条独立文档进行了索引。如何理解这句话呢?在上面的数据中,"categoryNst"数组已经有两个对象成员了
ES在后台其实将这两个对象成员当成了两条独立文档进行索引,所以ES一共索引了3条文档(一条外部文档,两条嵌套字段对象的文档),这点可以从对嵌套字段的terms聚合中看出来:
GET test_index_20211220/_search
{"query": {"nested": {"path": "categoryNst","query": {"term": {"categoryNst.class2": "补水"}}}},"aggs": {"nestedAgg":{"nested": {"path": "categoryNst"},"aggs": {"termAgg": {"terms": {// 这里一样不能写成"class2",否则虽不报错,但聚合无结果。"field": "categoryNst.class2"}}}}}
}{"took": 6,"timed_out": false,"_shards": {"total": 2,"successful": 2,"skipped": 0,"failed": 0},"hits": {"total": 1,"max_score": 0.18232156,"hits": []},"aggregations": {"nestedAgg": {"doc_count": 2,"termAgg": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "补水","doc_count": 2}]}}}
}明明只有一条整体的文档,但聚合结果却是2,岂不是结果错误了?如何才能得到我们需要的结果呢?这个时候就要用到反转嵌套(reverse_nested),改写上面查询语句的聚合部分:
GET test_index_20211220/_search
{"size":0,"query": {"nested": {"path": "categoryNst","query": {"term": {"categoryNst.class2": "补水"}}}},"aggs": {"nestedAgg":{"nested": {"path": "categoryNst"},"aggs": {"termAgg": {"terms": {"field": "categoryNst.class2"},"aggs": {"reverseAgg": {"reverse_nested": {}}}}}}}
}5:java查询
public static void main(String[] args) {//创建ES客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//创建搜索对象SearchRequest searchRequest = new SearchRequest();searchRequest.indices("user");//构建请求体SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//查询数据-对nested类型数据查询searchSourceBuilder.query(QueryBuilders.nestedQuery("check_error", QueryBuilders.termsQuery("check_error.errtype", errtype), ScoreMode.None));//发送请求searchRequest.source(searchSourceBuilder);SearchResponse search = null;try {search = esClient.search(searchRequest, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}//解析结果SearchHits hits = search.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}//关闭ES客户端esClient.close();}
四、数组类型字段
1:mapping
ES中没有专门的数组类型,默认情况下任何字段都可以包含一个或者多个值,但一个数组中的值必须是同一种类型。
// 数组类型"comments": {"type": "keyword"}
2:增加数据
当数组类型字段(comments)中只有一个数据时:
GET test_index_20211220/e-com/1
{"_index": "test_index_20211220","_type": "e-com","_id": "1","_version": 1,"found": true,"_source": {"id": "1","name": "L'oreal/欧莱雅复颜玻尿酸水光充盈导入膨润精华液","brand": "欧莱雅","price": 279,"desc": "补水 提拉紧致 淡化细纹","comments": "还没有用,赠品跟欧莱雅旗舰店的同款赠品有差异。味道也不一样"}
}可以看到此时的comments还不是数组,现在我们增加一条评论,覆盖写入一次:
PUT test_index_20211220/e-com/1
{"id": "1","name": "L'oreal/欧莱雅复颜玻尿酸水光充盈导入膨润精华液","brand": "欧莱雅","price": 279,"desc": "补水 提拉紧致 淡化细纹","comments": ["还没有用,赠品跟欧莱雅旗舰店的同款赠品有差异。味道也不一样","只有这支玻璃尿酸水光充盈是真的"]
}重新查询,可以看到,"commts"在索引的时候,如果有多个值,则会自动转化成了数组,且文档版本号+1:
GET test_index_20211220/e-com/1
{"_index": "test_index_20211220","_type": "e-com","_id": "1","_version": 2,"found": true,"_source": {"id": "1","name": "L'oreal/欧莱雅复颜玻尿酸水光充盈导入膨润精华液","brand": "欧莱雅","price": 279,"desc": "补水 提拉紧致 淡化细纹","comments": ["还没有用,赠品跟欧莱雅旗舰店的同款赠品有差异。味道也不一样","只有这支玻璃尿酸水光充盈是真的"]}
}3:查询
此时数组类型就当做正常的字段进行查询即可
GET my_test_index/_search
{"query": {"bool": {"must": [{"terms": {"label": ["10","100"]}},{"term": {"name": {"value": "旺仔33333"}}}]}}
}
相关文章:

Elasticsearch中object类型与nested类型以及数组之间的区别
一、区别: 0、一般情况下用object 类型来查es中为json对象的字段数据,用nested来查es中为JsonArray数组类型的字段数据。 1、默认情况下ES会把JSON对象直接映射为object类型,只有手动设置才会映射为nested类型 2、object类型可以直接使用普…...

办公文档,私人专用
一、安装Minio 1.1、创建文件夹,并在指定文件夹中下载minio文件 cd /opt mkdir minio cd minio touch minio.log wget https://dl.minio.io/server/minio/release/linux-amd64/minio1.2、赋予minio文件执行权限 chmod 777 minio1.3、启动minio ./minio server /…...
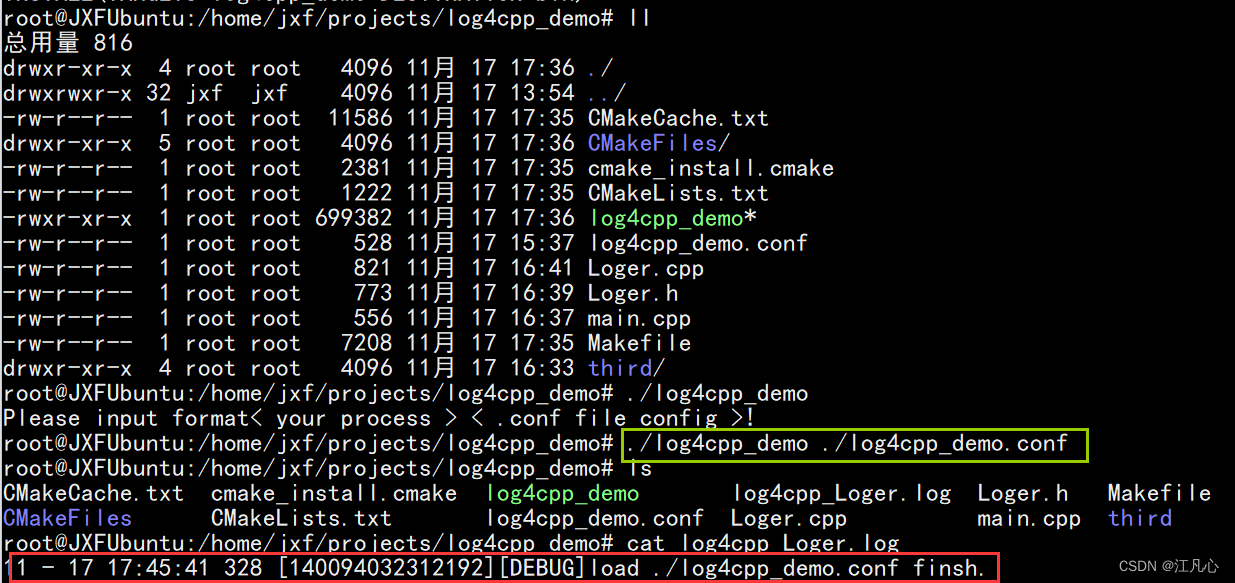
linux 使用log4cpp记录项目日志
为什么要用log4cpp记录项目日志 在通常情况下,Linux/UNIX 每个程序在开始运行的时刻,都会打开 3 个已经打开的 stream. 分别用来输入,输出,打印错误信息。通常他们会被连接到用户终端。这 3 个句柄的类型为指向 FILE 的指针。可以…...

Kafka集群部署
文章目录 一、实例配置二 、zookeeper集群安装三、kafka集群安装四、验证 没有提示,所有机器都执行 在kafka集群中引入zookeeper,主要是为了管理kafka集群的broker。负责管理集群的元数据信息,确保 Kafka 集群的高可用性、高性能和高可靠性。…...

软件测试|深入理解SQL CROSS JOIN:交叉连接
简介 在SQL查询中,CROSS JOIN是一种用于从两个或多个表中获取所有可能组合的连接方式。它不依赖于任何关联条件,而是返回两个表中的每一行与另一个表中的每一行的所有组合。CROSS JOIN可以用于生成笛卡尔积,它在某些情况下非常有用ÿ…...
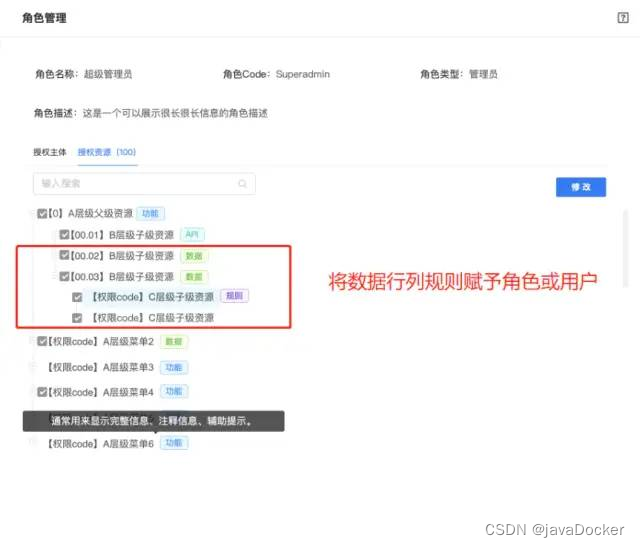
数据权限-模型简要分析
权限管控可以通俗的理解为权力限制,即不同的人由于拥有不同权力,他所看到的、能使用的可能不一样。对应到一个应用系统,其实就是一个用户可能拥有不同的数据权限(看到的)和操作权限(使用的)。 …...
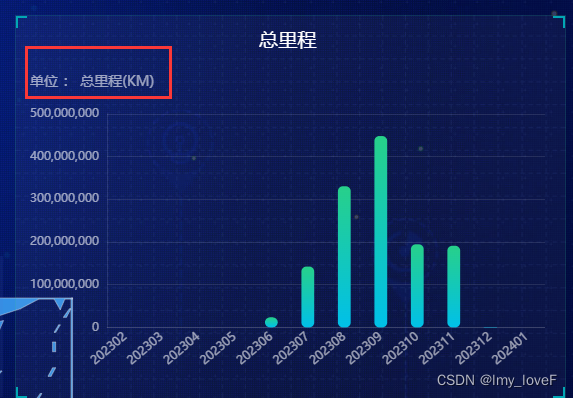
echarts柱状图加单位,底部文本溢出展示
刚开始设置了半天都不展示单位,后来发现是被挡住了,需要调高top值 // 基于准备好的dom,初始化echarts实例var myChart echarts.init(document.getElementById("echartD"));rankOption {// backgroundColor: #00265f,tooltip: {…...

x-cmd pkg | gh - GitHub 官方 CLI
目录 简介首次用户功能特点与 x-cmd gh 模块的关系相关作品进一步探索 简介 gh,是由 GitHub 官方使用 Go 语言开发和维护的命令行工具,旨在脚本或是命令行中便捷管理和操作 GitHub 的工作流程。 注意: 由于 x-cmd 提供了同名模块,因此使用官…...

Python解析XML,简化复杂数据操作的最佳工具!
更多Python学习内容:ipengtao.com XML(可扩展标记语言)是一种常见的文本文件格式,用于存储和交换数据。Python提供了多种库和模块,用于解析和操作XML文件。本文将深入探讨如何使用Python操作XML文件,包括XM…...

rpm数据库被破坏,无法使用yum
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 问题描述: 云服务器在安装了开源的HIDS插件后,发现安装了插件的服务器全部突然无法正常使用yum安装软件…...
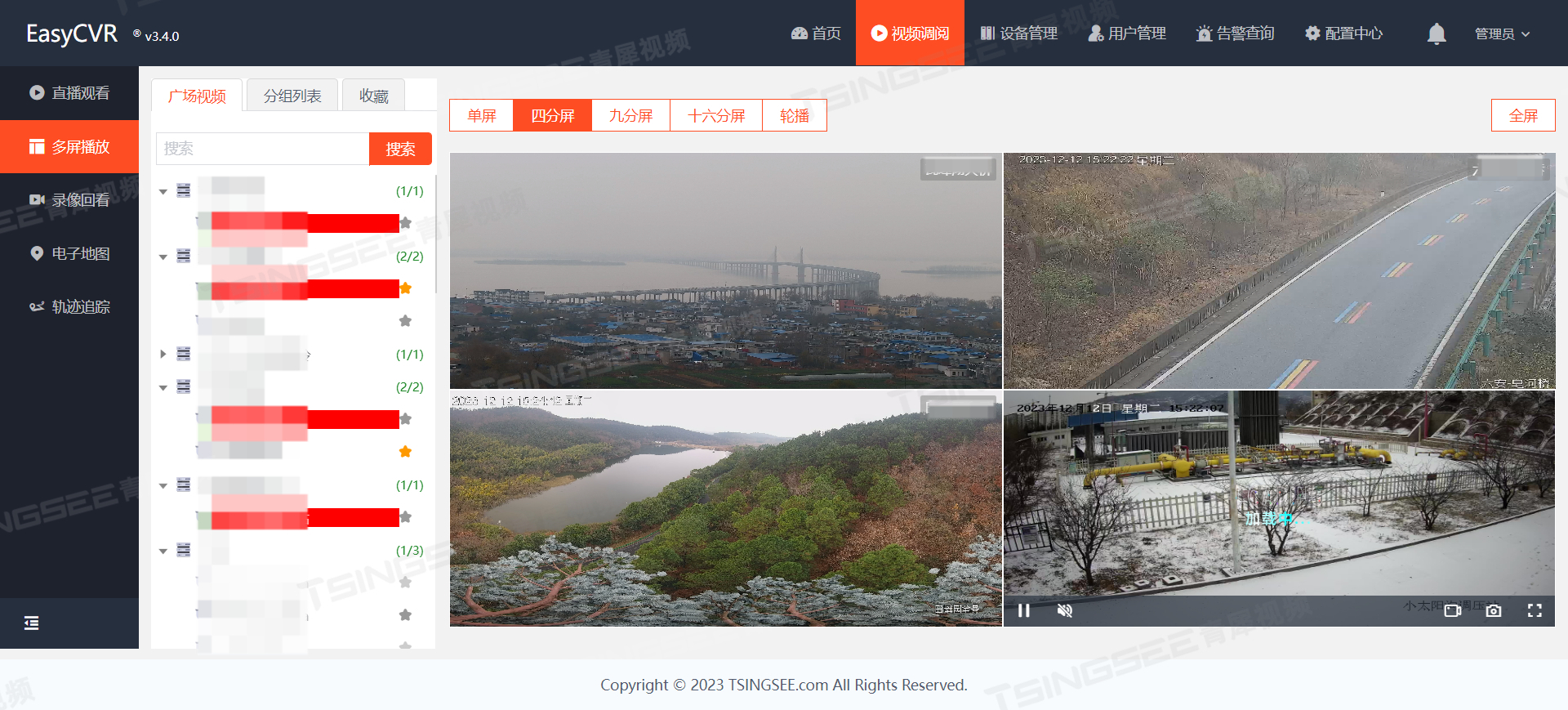
国标GB28181视频监控EasyCVR平台:视频集中录制存储/云端录像功能及操作介绍
安防视频监控系统EasyCVR视频综合管理平台,采用了开放式的网络结构,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,同时还具备权限管理、设…...

Wargames与bash知识11
Wargames与bash知识11 bandit19 关卡提示: 要获得对下一级别的访问权限,您应该使用家目录中的setuid二进制文件。在不带参数的情况下执行它,以了解如何使用。在使用setuid二进制文件后,可以在通常的位置(/etc/bandit…...
:基本语句)
Python 基础(一):基本语句
目录 1 条件语句2 循环语句2.1 for 循环2.2 while 循环2.3 break2.4 continue 3 pass 语句 1 条件语句 在进行逻辑判断时,我们需要用到条件语句,Python 提供了 if、elif、else 来进行逻辑判断。格式如下所示: if 判断条件1:执行语句1... el…...
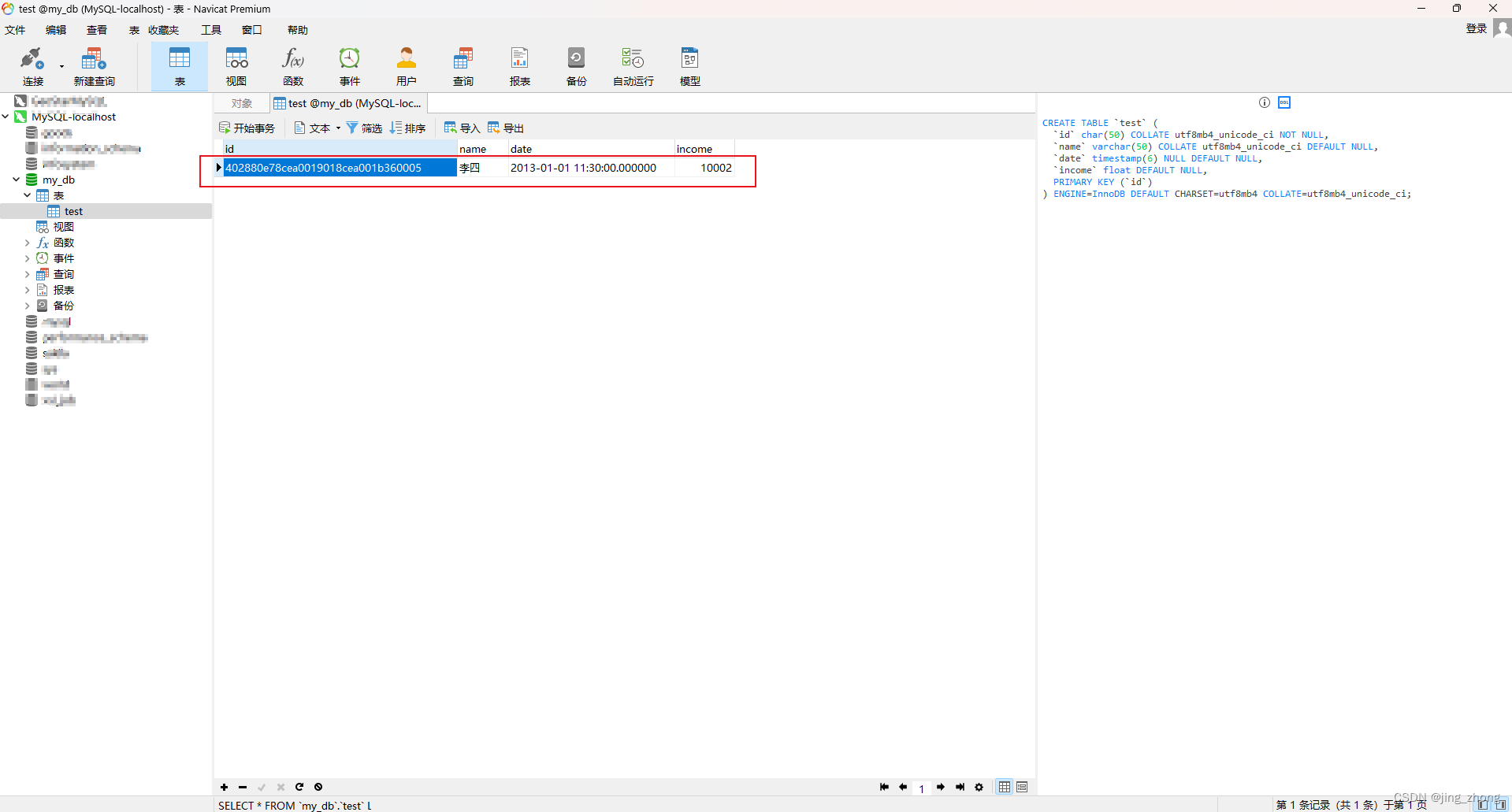
Hibernate实战之操作MySQL数据库(2024-1-8)
Hibernate实战之操作MySQL数据库 2024.1.8 前提环境(JavaMySQLNavicatVS Code)1、Hibernate简介1.1 了解HQL 2、MySQL数据库建表2.1 编写SQL脚本2.2 MySQL执行脚本 3、Java操作MySQL实例(Hibernate)3.1 准备依赖的第三方jar包3.2 …...

【Spring Boot 3】【数据源】自定义JDBC多数据源
【Spring Boot 3】【数据源】自定义JDBC多数据源 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术…...

番茄工作法
番茄工作法是一种时间管理方法,主要适用于专注工作。它的基本步骤包括: 设定一个25分钟的闹钟。默念三二一(321法则),开始全身心投入工作。用专注的状态高效工作25分钟,不允许走神。如果做到了步骤3&#…...
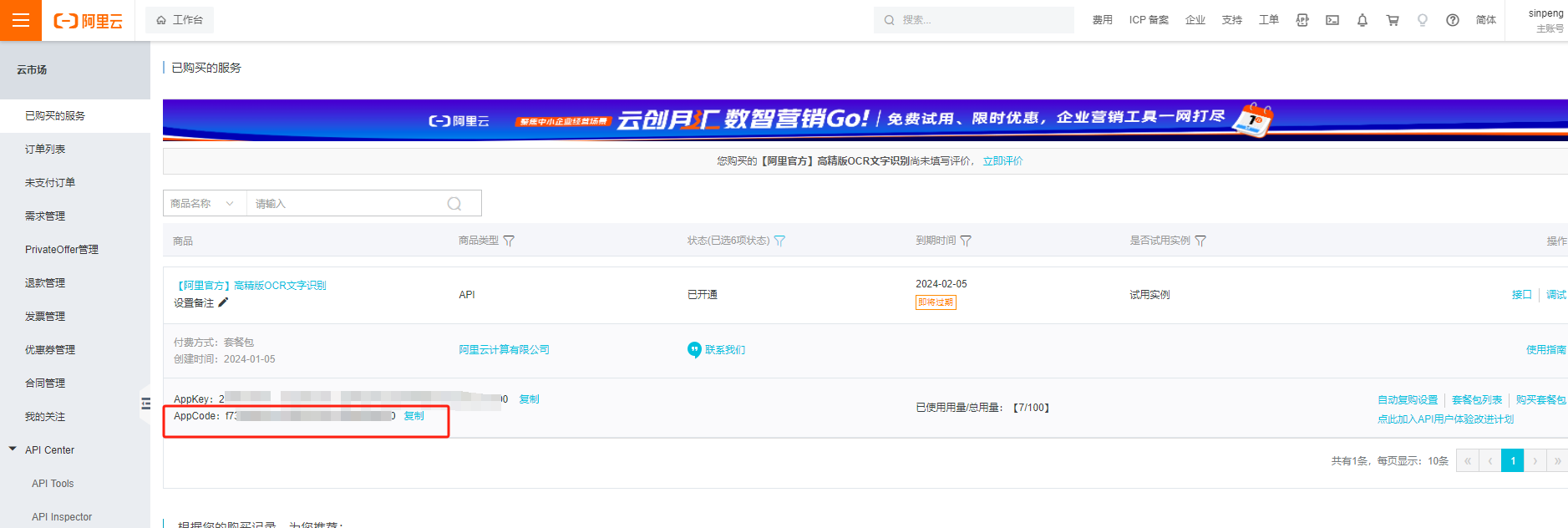
【uniapp】调用阿里云OCR图片识别文字:
文章目录 一、效果:二、实现: 一、效果: 二、实现: 【阿里官方】高精版OCR文字识别【最新版】-云市场-阿里云 <template><view class"container"><!-- 选择图片 --><button click"imageO…...

软考高级选择考哪个好?
📒软考高级总共5个科目,同样是高级证书,认可度也有区别! 大家一般在「信息系统项目管理师」✔️和「系统架构设计师」✔️二选一 1️⃣信息系统项目管理师 ❤️信息系统项目管理师也叫「高项」,考试内容主要是「项目管理」相关&am…...
在云服务器ECS上用Python写一个搜索引擎
在云服务器ECS上用Python写一个搜索引擎 一、场景介绍二、搜索引擎的组成2.1 网页的爬取及排序2.2 用户使用搜索引擎进行搜索 三、操作步骤3.1 环境准备3.2 安装Anaconda3.3 安装Streamlit3.4 下载搜索引擎代码3.5 运行搜索引擎 四、常见问题4.1 运行setup.py时可能的问题4.2 如…...

Python在智能手机芯片研发
Python在智能手机芯片研发中扮演着重要的角色。以下是几个方面的重要性: 快速原型设计:Python具有简洁易读的语法和丰富的第三方库,使工程师能够快速构建原型和进行快速迭代。这对于芯片研发来说,可以加快开发速度,减少…...

java+uniapp集成unipush2实现消息推送
一、开通uniPush2.0 1.实名认证 登录DCloud开发者中心,通过实名认证 2.进入UniPush控制台 HBuilderX中打开项目的manifest.json文件 导航在“App模块配置” → 项的“Push(消息推送)” → “UniPush”下点击配置 或者申请开通。 3.配置应用信息 在UniPush开通界面…...

技术决策的后悔药:选型错误后的补救策略
在软件测试的全生命周期中,技术选型是影响测试效率、质量与项目成败的关键环节。小到一款测试工具的挑选,大到整个测试框架的搭建,每一次决策都如同在迷雾中航行,稍有不慎便可能驶入“选型错误”的漩涡。当测试环境兼容性问题频发…...

ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南
ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式无法在其他播放器播放而烦恼吗?你是否经历过精心收藏的音乐只能…...
)
AI大模型选型生死线(2026企业级部署避坑指南)
更多请点击: https://intelliparadigm.com 第一章:AI大模型选型生死线(2026企业级部署避坑指南) 企业在2026年落地AI大模型时,选型失误的代价已远超算力采购成本——模型架构错配、上下文长度硬伤、商用许可证模糊、推…...

详解51单片机智能小车避障核心:超声波、漫反射与红外传感器的实战选型与调试
1. 智能小车避障传感器的核心选择 做智能小车最让人头疼的就是避障功能了。我当年第一次做51单片机小车时,光选传感器就折腾了好几个星期。市面上常见的避障传感器主要有三种:超声波模块、漫反射光电管和红外传感器。每种传感器都有自己的脾气ÿ…...

nlux框架:快速构建可定制AI对话界面的JavaScript解决方案
1. 项目概述:一个面向未来的对话式AI集成框架如果你最近在关注AI应用开发,尤其是想在自己的产品里快速集成一个类似ChatGPT那样的智能对话界面,那你很可能已经听说过或者搜索过“nlux”或“nlkitai/nlux”这个项目。简单来说,nlux…...

哪个降AI软件好?2026年4款主流降AI工具按场景对位横评!
哪个降AI软件好?2026年4款主流降AI工具按场景对位横评! 「哪个降 AI 软件好」没有标准答案。学生最常踩的坑是把这个问题简化成「哪款最便宜」或者「哪款最有效」——其实好不好用看你的场景。学校送知网严标准、送维普重灾区、自媒体被判 AI、本科双重问…...

Ciao故障排除终极指南:10个常见问题与解决方案大全
Ciao故障排除终极指南:10个常见问题与解决方案大全 【免费下载链接】ciao HTTP checks & tests (private & public) monitoring - check the status of your URL 项目地址: https://gitcode.com/gh_mirrors/ci/ciao Ciao是一款强大的HTTP(S) URL监控…...
)
SAP销售单抬头文本写入与读取:手把手教你用SAVE_TEXT和READ_TEXT BAPI(含完整ABAP代码)
SAP销售订单文本处理实战:从BAPI调用到最佳实践 在SAP项目实施过程中,销售订单抬头文本的自动化处理是常见需求场景。无论是特殊客户要求、内部审批备注还是物流特殊说明,都需要通过程序化方式精准写入和读取。对于ABAP开发者而言,…...
)
2026前端AI开发必备:核心工具\+配套联动指南(附实战组合)
前言:随着AI原生开发范式的普及,前端开发已从“手动编码”向“AI协同”全面转型。2026年数据显示,85%的前端岗位要求掌握AI辅助开发技能,具备AI能力的前端工程师平均薪资比传统前端高40%。但很多开发者仅用单一AI工具,…...