mysql集群简介
 集群的好处
集群的好处
高可用性:故障检测及迁移,多节点备份。
可伸缩性:新增数据库节点便利,方便扩容。
负载均衡:切换某服务访问某节点,分摊单个节点的数据库压力。
集群要考虑的风险
网络分裂:群集还可能由于网络故障而拆分为多个部分,每部分内的节点相互连接,但各部分之间的节点失去连接。
脑裂:导致数据库节点彼此独立运行的集群故障称为“脑裂”。这种情况可能导致数据不一致,并且无法修复,例如当两个数据库节点独立更新同一表上的同一行时。
@[toc]
一,mysql原厂出品
1,MySQL Replication
mysql复制(MySQL Replication),是mysql自带的功能。
原理简介:
主从复制是通过重放binlog实现主库数据的异步复制。即当主库执行了一条sql命令,那么在从库同样的执行一遍,从而达到主从复制的效果。在这个过程中,master对数据的写操作记入二进制日志文件中(binlog),生成一个 log dump 线程,用来给从库的 i/o线程传binlog。而从库的i/o线程去请求主库的binlog,并将得到的binlog日志写到中继日志(relaylog)中,从库的sql线程,会读取relaylog文件中的日志,并解析成具体操作,通过主从的操作一致,而达到最终数据一致。
技术图片
MySQL Replication一主多从的结构,主要目的是实现数据的多点备份(没有故障自动转移和负载均衡)。相比于单个的mysql,一主多从下的优势如下:
如果让后台读操作连接从数据库,让写操作连接主数据库,能起到读写分离的作用,这个时候多个从数据库可以做负载均衡。
可以在某个从数据库中暂时中断复制进程,来备份数据,从而不影响主数据的对外服务(如果在master上执行backup,需要让master处于readonly状态,这也意味这所有的write请求需要阻塞)。
就各个集群方案来说,其优势为:
主从复制是mysql自带的,无需借助第三方。
数据被删除,可以从binlog日志中恢复。
配置较为简单方便。
其劣势为:
从库要从binlog获取数据并重放,这肯定与主库写入数据存在时间延迟,因此从库的数据总是要滞后主库。
对主库与从库之间的网络延迟要求较高,若网络延迟太高,将加重上述的滞后,造成最终数据的不一致。
单一的主节点挂了,将不能对外提供写服务。
2,MySQL Fabirc
mysql织物(MySQL Fabirc),是mysql官方提供的。
这是在MySQL Replication的基础上,增加了故障检测与转移,自动数据分片功能。不过依旧是一主多从的结构,MySQL Fabirc只有一个主节点,区别是当该主节点挂了以后,会从从节点中选择一个来当主节点。
就各个集群方案来说,其优势为:
mysql官方提供的工具,无需第三方插件。
数据被删除,可以从binlog日志中恢复。
主节点挂了以后,能够自动从从节点中选择一个来当主节点,不影响持续对外提供写服务。
其劣势为:
从库要从binlog获取数据并重放,这肯定与主库写入数据存在时间延迟,因此从库的数据总是要滞后主库。
对主库与从库之间的网络延迟要求较高,若网络延迟太高,将加重上述的滞后,造成最终数据的不一致。
2014年5月推出的产品,数据库资历较浅,应用案例不多,网上各种资料相对较少。
事务及查询只支持在同一个分片内,事务中更新的数据不能跨分片,查询语句返回的数据也不能跨分片。
节点故障恢复30秒或更长(采用InnoDB存储引擎的都这样)。
3,MySQL Cluster
mysql集群(MySQL Cluster)也是mysql官方提供的。
MySQL Cluster是多主多从结构的
就各个集群方案来说,其优势为:
mysql官方提供的工具,无需第三方插件。
高可用性优秀,99.999%的可用性,可以自动切分数据,能跨节点冗余数据(其数据集并不是存储某个特定的MySQL实例上,而是被分布在多个Data Nodes中,即一个table的数据可能被分散在多个物理节点上,任何数据都会在多个Data Nodes上冗余备份。任何一个数据变更操作,都将在一组Data Nodes上同步,以保证数据的一致性)。
可伸缩性优秀,能自动切分数据,方便数据库的水平拓展。
负载均衡优秀,可同时用于读操作、写操作都都密集的应用,也可以使用SQL和NOSQL接口访问数据。
多个主节点,没有单点故障的问题,节点故障恢复通常小于1秒。
其劣势为:
架构模式和原理很复杂。
只能使用存储引擎 NDB ,与平常使用的InnoDB 有很多明显的差距。比如在事务(其事务隔离级别只支持Read Committed,即一个事务在提交前,查询不到在事务内所做的修改),外键(虽然最新的NDB 存储引擎已经支持外键,但性能有问题,因为外键所关联的记录可能在别的分片节点),表限制上的不同,可能会导致日常开发出现意外。点击查看具体差距比较
作为分布式的数据库系统,各个节点之间存在大量的数据通讯,比如所有访问都是需要经过超过一个节点(至少有一个 SQL Node和一个 NDB Node)才能完成,因此对节点之间的内部互联网络带宽要求高。
Data Node数据会被尽量放在内存中,对内存要求大,而且重启的时候,数据节点将数据load到内存需要很长时间。
官方的三兄弟的区别对比如下图所示;
技术图片
二,mysql第三方优化
4,MMM
MMM是在MySQL Replication的基础上,对其进行优化。
MMM(Master Replication Manager for MySQL)是双主多从结构,这是Google的开源项目,使用Perl语言来对MySQL Replication做扩展,提供一套支持双主故障切换和双主日常管理的脚本程序,主要用来监控mysql主主复制并做失败转移。
技术图片
注意:这里的双主节点,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热。
就各个集群方案来说,其优势为:
自动的主主Failover切换,一般3s以内切换备机。
多个从节点读的负载均衡。
其劣势为:
无法完全保证数据的一致性。如主1挂了,MMM monitor已经切换到主2上来了,而若此时双主复制中,主2数据落后于主1(即还未完全复制完毕),那么此时的主2已经成为主节点,对外提供写服务,从而导致数据不一。
由于是使用虚拟IP浮动技术,类似Keepalived,故RIP(真实IP)要和VIP(虚拟IP)在同一网段。如果是在不同网段也可以,需要用到虚拟路由技术。但是绝对要在同一个IDC机房,不可跨IDC机房组建集群。
5,MHA
MHA是在MySQL Replication的基础上,对其进行优化。
MHA(Master High Availability)是多主多从结构,这是日本DeNA公司的youshimaton开发,主要提供更多的主节点,但是缺少VIP(虚拟IP),需要配合keepalived等一起使用。
要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
技术图片
就各个集群方案来说,其优势为:
可以进行故障的自动检测和转移
具备自动数据补偿能力,在主库异常崩溃时能够最大程度的保证数据的一致性。
其劣势为:
MHA架构实现读写分离,最佳实践是在应用开发设计时提前规划读写分离事宜,在使用时设置两个连接池,即读连接池与写连接池,也可以选择折中方案即引入SQL Proxy。但无论如何都需要改动代码;
关于读负载均衡可以使用F5、LVS、HAPROXY或者SQL Proxy等工具,只要能实现负载均衡、故障检查及备升级为主后的读写剥离功能即可,建议使用LVS
6,Galera Cluster
Galera Cluster是由Codership开发的MySQL多主结构集群,这些主节点互为其它节点的从节点。不同于MySQL原生的主从异步复制,Galera采用的是多主同步复制,并针对同步复制过程中,会大概率出现的事务冲突和死锁进行优化,就是复制不基于官方binlog而是Galera复制插件,重写了wsrep api。
异步复制中,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化。这种情况下,在主库事务提交后的短时间内,主从库数据并不一致。
同步复制时,主库的单个更新事务需要在所有从库上同步 更新。换句话说,当主库提交事务时,集群中所有节点的数据保持一致。
对于读操作,从每个节点读取到的数据都是相同的。对于写操作,当数据写入某一节点后,集群会将其同步到其它节点。
技术图片
就各个集群方案来说,其优势为:
多主多活下,可对任一节点进行读写操作,就算某个节点挂了,也不影响其它的节点的读写,都不需要做故障切换操作,也不会中断整个集群对外提供的服务。
拓展性优秀,新增节点会自动拉取在线节点的数据(当有新节点加入时,集群会选择出一个Donor Node为新节点提供数据),最终集群所有节点数据一致,而不需要手动备份恢复。
其劣势为:
能做到数据的强一致性,毫无疑问,也是以牺牲性能为代价。
三,依托硬件配合
不同主机的数据同步不再依赖于MySQL的原生复制功能,而是通过同步磁盘数据,来保证数据的一致性。
然后处理故障的方式是借助Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。
7,heartbeat+SAN
SAN:共享存储,主库从库用的一个存储。SAN的概念是允许存储设施和解决器(服务器)之间建立直接的高速连接,通过这种连接实现数据的集中式存储。
技术图片
就各个集群方案来说,其优势为:
保证数据的强一致性;
与mysql解耦,不会由于mysql的逻辑错误发生数据不一致的情况;
其劣势为:
SAN价格昂贵;
8,heartbeat+DRDB
DRDB:这是linux内核板块实现的快级别的同步复制技术。通过各主机之间的网络,复制对方磁盘的内容。当客户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据即可以保证明时同步。
技术图片
就各个集群方案来说,其优势为:
相比于SAN储存网络,价格低廉;
保证数据的强一致性;
与mysql解耦,不会由于mysql的逻辑错误发生数据不一致的情况;
其劣势为:
对io性能影响较大;
从库不提供读操作;
四,其它
9,Zookeeper + proxy
Zookeeper使用分布式算法保证集群数据的一致性,使用zookeeper可以有效的保证proxy的高可用性,可以较好的避免网络分区现象的产生。
技术图片
就各个集群方案来说,其优势为:
扩展性较好,可以扩展为大规模集群。
缺其劣势为:
搭建Zookeeper 集群,在配置一套代理,整个系统的逻辑变得更加复杂。
10,Paxos
分布式一致性算法,Paxos 算法处理的问题是一个分布式系统如何就某个值(决议)达成一致。这个算法被认为是同类算法中最有效的。Paxos与MySQL相结合可以实现在分布式的MySQL数据的强一致性。
相关文章:
mysql集群简介
集群的好处 高可用性:故障检测及迁移,多节点备份。 可伸缩性:新增数据库节点便利,方便扩容。 负载均衡:切换某服务访问某节点,分摊单个节点的数据库压力。 集群要考虑的风险 网络分裂:群集还…...

装饰器模式
概述 当我们编写软件时,有时我们会遇到需要在不修改现有代码的情况下添加新功能的情况。这时,我们可以使用装饰器模式。 装饰器模式是一种结构性设计模式,它允许我们在不改变对象接口的情况下动态地向对象添加功能。装饰器模式通过创建一个…...

21 Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移 在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。 本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当中&a…...

遍历读取文件夹下的所有文件
遍历读取文件夹下的所有文件 例如,读取文件夹下,子文件夹的所有的jpg文件: import glob path "./database/20230302/night/*/*.jpg"#设置自己的文件夹路径以及文件 image_files glob.glob(path, recursiveTrue)for image_file …...
nexus安装与入门
安装 nexus-3.31.1-01-unix.tar.gz 链接:https://pan.baidu.com/s/1YrJMwpGxmu8N2d7XMl6fSg 提取码:kfeh 上传到服务器,解压 tar -zvxf nexus-3.31.1-01-unix.tar.gz进入bin目录,启动 ./nexus start查看状态 ./nexus status默…...
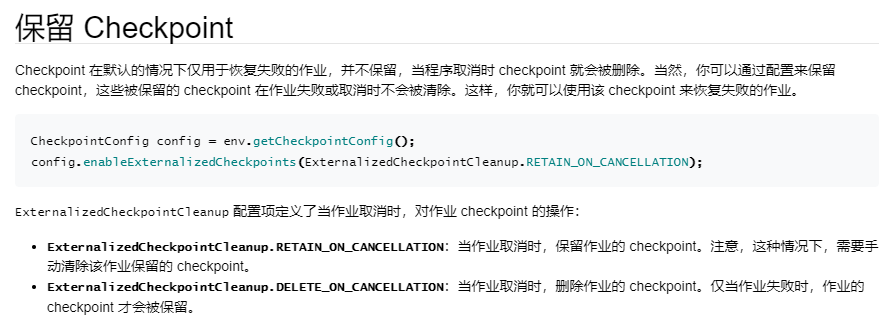
Flink SQL Checkpoint 学习总结
前言 学习总结Flink SQL Checkpoint的使用,主要目的是为了验证Flink SQL流式任务挂掉后,重启时还可以继续从上次的运行状态恢复。 验证方式 Flink SQL流式增量读取Hudi表然后sink MySQL表,任务启动后处于running状态,先查看sin…...
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 本地安全策略配置 A-3 流量完整性保护 A-4 事件监控 …...

MyBatis中主键回填的两种实现方式
主键回填其实是一个非常常见的需求,特别是在数据添加的过程中,我们经常需要添加完数据之后,需要获取刚刚添加的数据 id,无论是 Jdbc 还是各种各样的数据库框架都对此提供了相关的支持,本文我就来和和大家分享下数据库主…...

Windows11如何打开ie浏览器
目录1.背景:2.方法一:在 edge 中配置使用 ie 模式3.方法二:通过 Internet 选项 打开1.背景: 昨天电脑自动从win10升级为win11了,突然发现电脑找不到ie浏览器了,打开全都是直接跳转到 edge 浏览器࿰…...

Linux:进程间通信
目录 进程间通信目的 进程间通信分类 管道 System V IPC POSIX IPC 什么是管道 站在文件描述符角度-深度理解管道 管道使用 管道通信的四种情况 管道通信的特点 进程池管理 命名管道 创建一个命名管道 命名管道的打开规则 命名管道通信实例 匿名管道与命名管道的…...

【java】将LAC改造成Elasticsearch分词插件
目录 为什么要将LAC改造成ES插件? 怎么将LAC改造成ES插件? 确认LAC java接口能work 搭建ES插件开发调试环境 编写插件 生成插件 安装、运行插件 linux版本的动态链接库生成 总结 参考文档 为什么要将LAC改造成ES插件? ES是著名的非…...
)
TPM 2.0实例探索3 —— LUKS磁盘加密(5)
接前文:TPM 2.0实例探索3 —— LUKS磁盘加密(4) 本文大部分内容参考: Code Sample: Protecting secret data and keys using Intel Platform... 二、LUKS磁盘加密实例 4. 将密码存储于TPM的PCR 现在将TPM非易失性存储器中保护…...
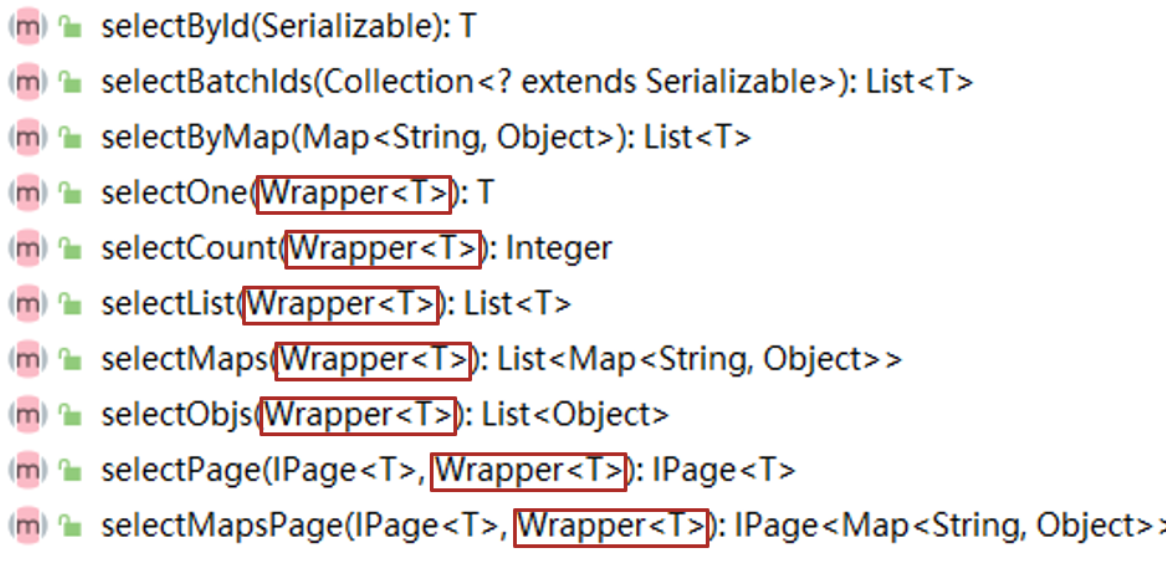
mybatisplus复习(黑马)
学习目标能够基于MyBatisPlus完成标准Dao开发能够掌握MyBatisPlus的条件查询能够掌握MyBatisPlus的字段映射与表名映射能够掌握id生成策略控制能够理解代码生成器的相关配置一、MyBatisPlus简介MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工…...

【数据聚类|深度聚类】Deep Comprehensive Correlation Mining for Image Clustering(DCCM)论文研读
Abstract 翻译 最近出现的深度无监督方法使我们能够联合学习表示和对未标记数据进行聚类。这些深度聚类方法主要关注样本之间的相关性,例如选择高精度对来逐步调整特征表示,而忽略了其他有用的相关性。本文提出了一种新的聚类框架,称为深度全面相关挖掘(DCCM),从三个方面…...

CE认证机构有哪些机构?
CE认证机构有哪些机构? 所有出口欧盟的产品都需要办理CE证明,而电子电器以及玩具是强制性要做CE认证。很多人以为只有办理欧盟NB公告机构的CE认证才可以被承认,实际上并不是。那么,除了NB公告上的机构,还有哪些认证机…...
解决方法)
MYSQL5.7:Access denied for user ‘root‘@‘localhost‘ (using password:YES)解决方法
一、打开MySQL目录下的my.ini文件,在文件的[mysqld]下面添加一行 skip-grant-tables,保存并关闭文件;skip-grant-tables :跳过密码登录,登录时无需密码。my.ini :一般在和bin同目录下,如果没有的话可自己创…...

单目运算符、双目运算符、三目运算符
单目运算符是什么 单目运算符是指运算所需变量为一个的运算符 又叫一元运算符,其中有逻辑非运算符:!、按位取 反运算符:~、自增自减运算符:,-等。 逻辑非运算符【!】、按位取反运算符【~】、 自…...
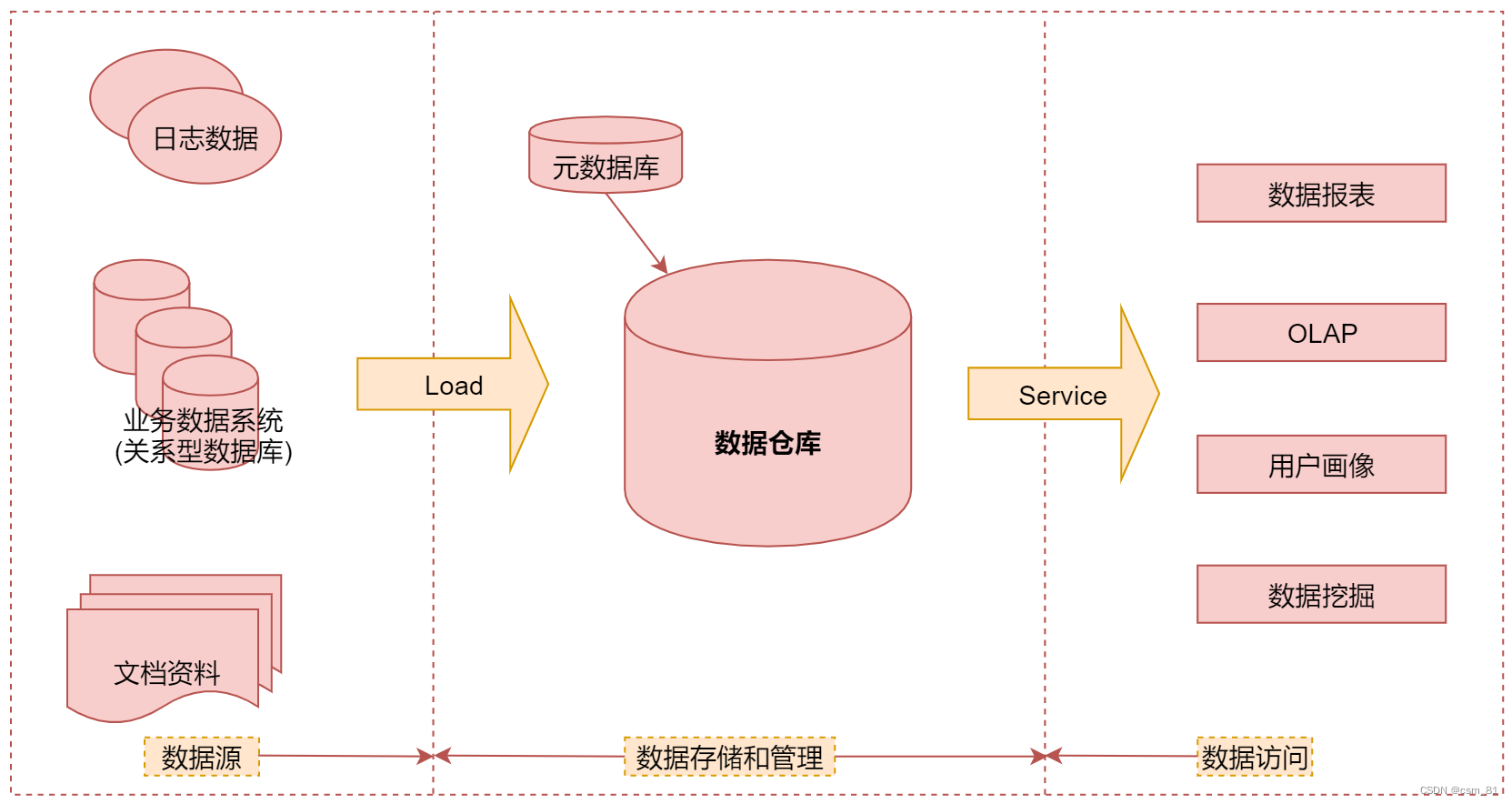
离线数据仓库项目搭建——准备篇
文章目录(一)什么是数据仓库(二)数据仓库基础知识(三)数据仓库建模方式(1)星行模型(2)雪花模型(3)星型模型 VS 雪花模型(四…...
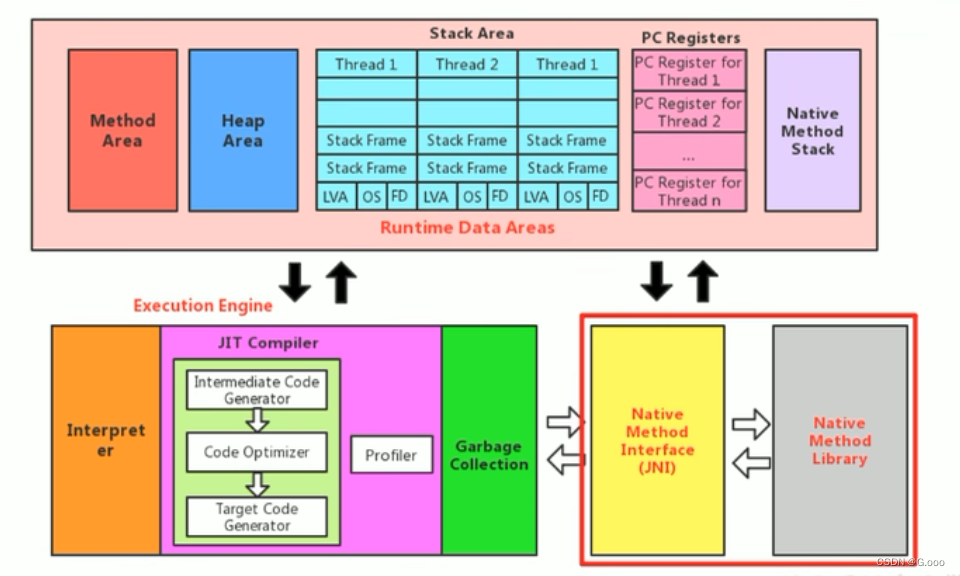
十七、本地方法接口的理解
什么是本地方法? 1.简单来讲,一个Ntive method 就是一个Java调用非Java代码的接口.一个Native Method 是这样一个Java方法:该方法的实现由非Java语言实现,比如C,这个特征并非Java所特有,很多其他的编程语言都由这一机制,比如在C中…...
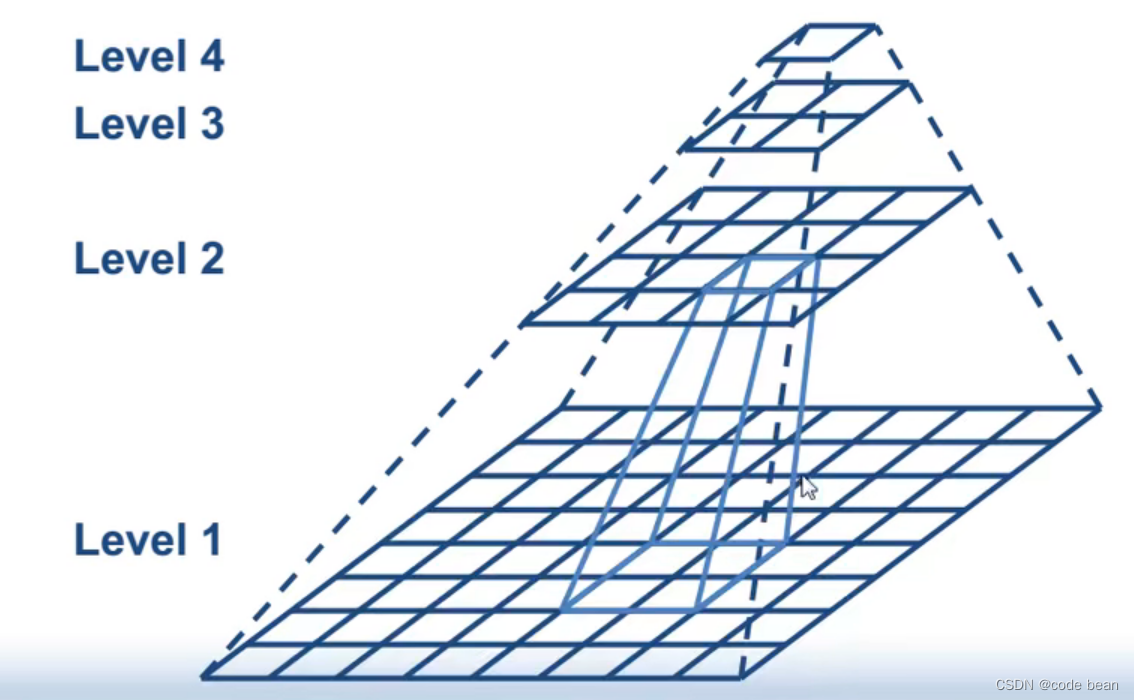
【halcon】模板匹配参数之金字塔级数
背景 今天,在使用模板匹配的时候,突然程序卡死,CPU直接飙到100%。最后排查发现是模板匹配其中一个参数 NumLevels 导致的: NumLevels: The number of pyramid levels used during the search is determined with numLevels. If n…...

CentOS 8系统下EMQX 4.3.8安装避坑实录:解决crypto和libncurses依赖报错
CentOS 8系统下EMQX 4.3.8深度部署指南:从依赖解析到高可用架构 在物联网和边缘计算领域,MQTT协议凭借其轻量级和高效性已成为设备通信的事实标准。而EMQX作为基于Erlang/OTP平台开发的开源MQTT消息服务器,其单节点支持200万连接的能力使其成…...
)
告别盲调!用STM32CubeMonitor实时可视化你的MCU变量(附Windows/Mac安装包)
告别盲调!用STM32CubeMonitor实时可视化你的MCU变量(附Windows/Mac安装包) 调试嵌入式系统时,最令人抓狂的莫过于反复修改代码、下载、断点查看变量——这种"盲人摸象"式的开发方式,在调试动态系统ÿ…...
)
从App Inventor到数据解析:打造一个专属的Android蓝牙温湿度监测App(适配HC-05+Arduino)
从零构建Android蓝牙温湿度监测系统:App Inventor与Arduino实战指南 在物联网技术快速普及的今天,将传感器数据可视化呈现已成为许多创客和教育场景中的常见需求。本文将以DHT-11温湿度传感器为核心,通过HC-05蓝牙模块搭建Arduino与Android设…...

为什么2025年是AI Agent的爆发元年?
目录为什么2025年是AI Agent的爆发元年?引言:一个被产业界共同认定的“元年”一、产业共识:为什么“元年”不是一个空洞的口号?1.1 从“千模大战”到“智能体竞速”1.2 权威机构的一致判断1.3 市场规模的数据佐证二、技术底座&…...

ReRAM与PCM存内计算:突破冯·诺依曼瓶颈,赋能边缘AI与类脑计算
1. 从冯诺依曼瓶颈到存内计算:一场芯片架构的范式转移最近几年,但凡关注芯片和人工智能领域的朋友,肯定对“存内计算”这个词不陌生。它听起来像是一个技术术语,但背后直指一个困扰了我们半个多世纪的计算机根本性难题:…...

锂电池热失控防护:从封装技术到系统级安全设计
1. 从三星Note 7到航天器:锂电池安全问题的根源与演进2016年,三星Galaxy Note 7的“燃损门”事件,将锂电池安全问题以一种极其戏剧化且代价高昂的方式,推到了全球消费者和整个电子产业的聚光灯下。官方调查最终指向了电池设计缺陷…...

OpenAI成立部署公司并收购Tomoro,AI竞争焦点转向企业落地
OpenAI成立部署公司背后的战略布局品玩5月12日消息,据techstartups报道,OpenAI近日宣布成立“OpenAI部署公司”,该实体由OpenAI控股。同时,OpenAI获TPG领投,还有包括Bain Capital、Brookfield、Goldman Sachs及SoftBan…...
)
告别单调!用LVGL Button控件打造3种高级交互动效(附完整C代码)
用LVGL Button控件实现高级交互动效的实战指南 在嵌入式设备上打造流畅、生动的用户界面一直是开发者的挑战。LVGL作为轻量级图形库,其Button控件的基础功能虽然简单,但通过巧妙运用样式和动画API,可以实现媲美移动端的高级交互效果。本文将深…...

如何一次性解决Windows系统DLL缺失问题:VisualCppRedist AIO终极指南
如何一次性解决Windows系统DLL缺失问题:VisualCppRedist AIO终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在安装新游戏或软件时…...

从零构建开发者效率工具:CLI脚手架与自动化工作流实践
1. 项目概述与核心价值最近在开源社区里,一个名为smouj/smouj的项目引起了我的注意。乍一看这个标题,可能会让人有些摸不着头脑,它不像常见的vue/vue或tensorflow/tensorflow那样直白地揭示了其技术栈。但恰恰是这种看似“神秘”的命名&#…...