数据分析——火车信息
任务目标
任务
1、整理火车发车信息数据,结果的表格形式为:

2、并输出最终的发车信息表
难点
1、多文件
一个文件夹,多个月的发车信息,一个excel,放一天的发车情况
2、数据表的格式特殊
如何分析表是一个难点
数据形式
图像呈现

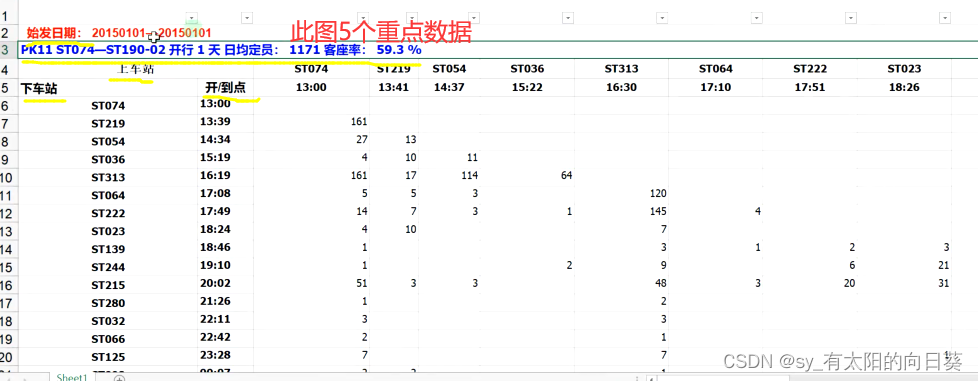


文字描述
1、一张表含多辆车次信息
2、一辆车次信息分为标题(日期、车次、定员、客座率)和表格信息部分
3、表格信息部分分为x,y轴看
横着是发车站点、发车时间、下车人数
竖着是目标站点、到达时间、上车人数
4、图标呈现下三角趋势,因为过站无上车人数
注意:
因为横着是上车站点,终点站没有人上车,所以横着的车次不包含终点站,是所有车次-1
竖着的车次包含终点站——即所有车次信息
分析步骤
1、导入数据


存在问题
与原数据不同,原数据中的表头在该表的第一列中,每个属性对应的行为空值
处理方法

处理结果

结果分析
1、38列
因为原excel表中,有车次信息到第38列,导入数据会保持表格格式完整性,所以取最大列数
不到38的列数均为空值,需要处理
2、表格信息被存放在第一行中,还需处理
3、目标需求信息只到29列的下车人数,所以需要把有效信息抠出来
语法扩展(别人的资料)
python中pandas包使用的一个header参数_header=none-CSDN博客



2、数据处理
2.1获取有效信息(扣表)
2.1.1思路分析
1、判断车次
整张表包含很多车次
要知道哪一辆车是第几行到第几行,需要拆分
(即怎么判断,eg:0-33为车1,34-45为车2,······)

2、处理表头
导入的表中有很多表头,需要处理 ,把所有车次的表头抽取出来,找共同点
都有客座率


2.1.2解决方案
1、找表头
1.1data[0]
因为数据表行列均有属性,表头均在第0列,所以先判断data[0]是第0行还是第0列

1.2找到含有“客座率”的行数

语法扩展
apply()、lambda
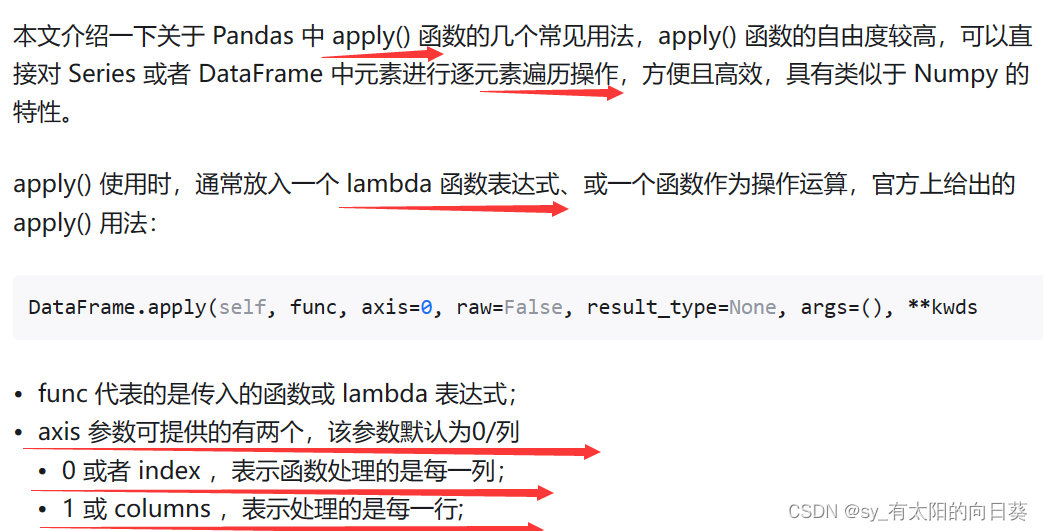
loc()
Pandas读取某列、某行数据——loc、iloc用法总结_pandas读取某一行的数据-CSDN博客

1.3生成由表头信息组成的表

1.4批量分割+展开表
按照空格分割后得到一个表格

split()
Python知识精解:str split()方法 - 知乎 (zhihu.com)
expand参数
pandas的分列操作str.split()_pandas数据分列-CSDN博客

2、生成除表头外的信息表
data=data[~ind]


3、生成一趟车的数据
1、根据上车站点和上车人数所在的行(用遍历匹配)
确定每一趟列车所包含的行数,再扣其中的数据
 2、找第一趟车的信息
2、找第一趟车的信息

3、重置行索引
因为之前删数据把行索引删了,出现了数据缺失,需要重置行索引
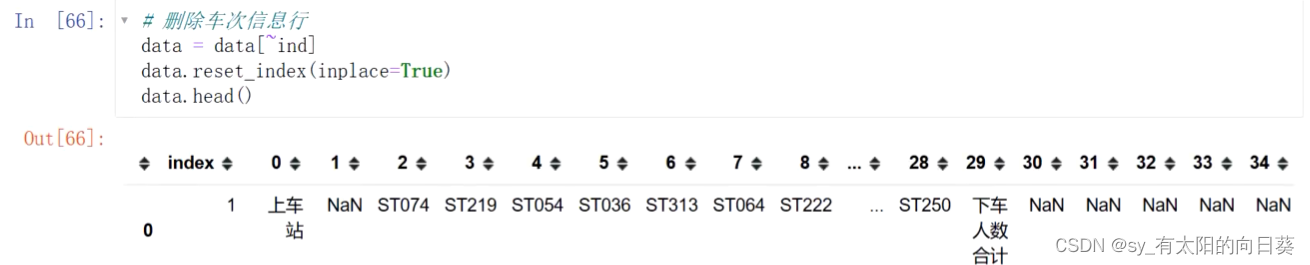

drop——删除多余的一列index
4、删除空值
重置索引后的表格为

表中30列后的值均为空值,需要删除
用空值数量进行判断,若某一列中空值数量=行数,则证明该列全为空,需要删除

5、生成完整一趟车的信息表
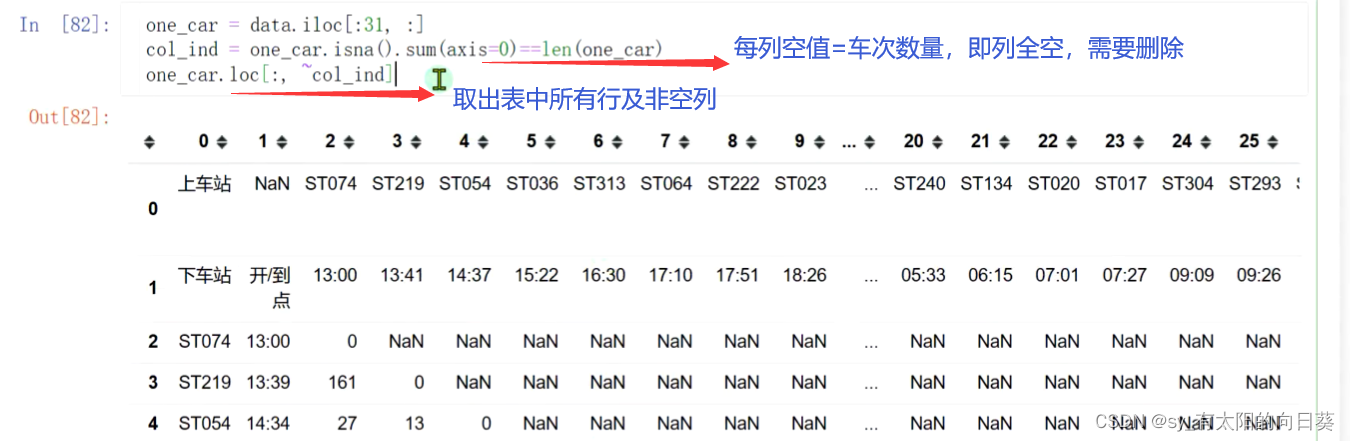
语法扩展
loc、iloc区别
pandas索引函数loc和iloc的区别_pandas loc与iloc区别-CSDN博客
loc基于标签索引、iloc基于位置索引
reset_index()
如何在pandas中使用set_index( )与reset_index( )设置索引 - 知乎 (zhihu.com)
3、数据分析
处理后的表

3.1取表头信息表中所需数据

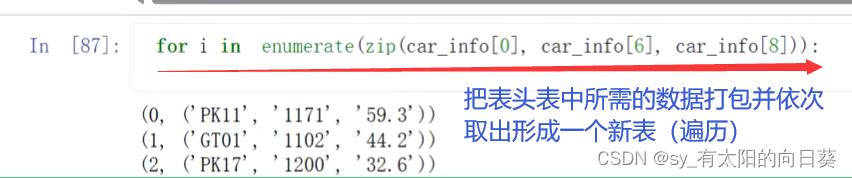
3.2把表头信息与每辆车挂钩
原数据(2个表)
表头表
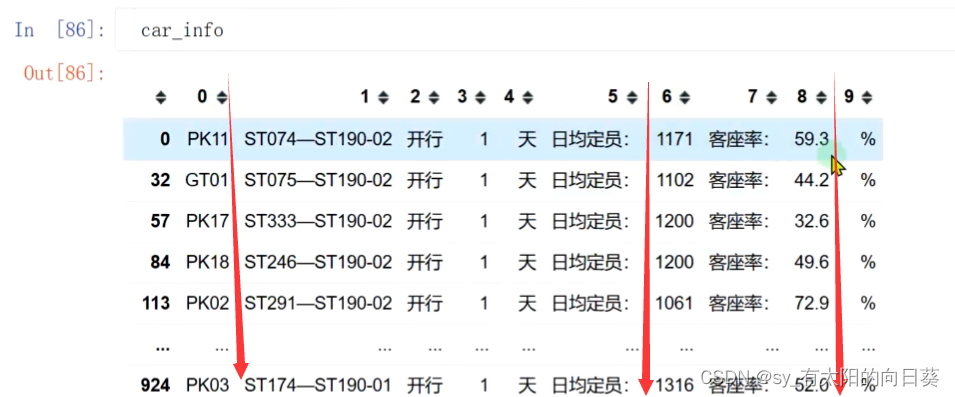
车次表

通过索引和步长取出需要的信息行
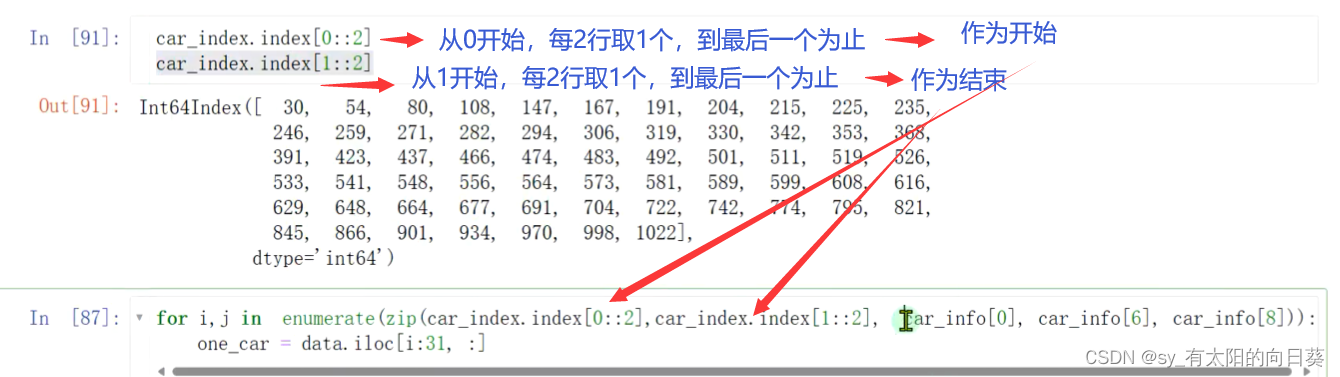
这样就匹配成功了

3.3、取所有站点
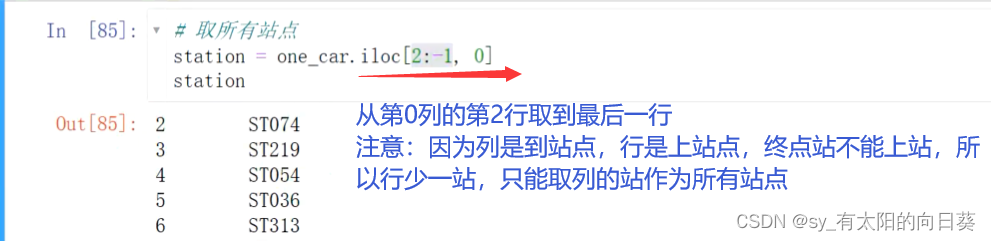
3.4循环所有站点取数据(用定位)

都用条件筛选

3.5整体操作(合并前面操作)

语法扩展
python dataframe是什么_Pandas 库之 DataFrame-CSDN博客
4、封装函数

5、数据导出


语法扩展
glob——查找文件
Python标准库glob模块详解_python glob-CSDN博客
tpdm——进度条
【python第三方库】tqdm简介_python tqdm库-CSDN博客
enumerate() 函数
Python enumerate() 函数 | 菜鸟教程
to_csv()
pandas的to_csv()使用方法_pandas to_csv-CSDN博客
总体代码
import warnings
warnings.filterwarnings('ignore')
import pandas as pdpath = './201501-201603/201501/20150101.xls'
data = pd.read_excel(path, skiprows=2, header=None)
data.head(50)# 日期
dates = path.split('/')[-1][:8]ind = data[0].apply(lambda x: '客座率' in x) # 筛选有车次信息的行数据
car_info = data.loc[ind, 0]
car_info = car_info.str.split(' ', expand=True) # 这里的得到车次、定员、客座率car_info# 删除车次信息行
data = data[~ind]
data.reset_index(inplace=True, drop=True)
data.head()## 接下来:找到某一趟车所在的小表格,思路就是找到【上车站、上车人数合计】所在的行
ind = data[0].apply(lambda x: '上车站'==x or '上车人数合计'==x)
car_index = data[ind]all_car = pd.DataFrame()
for start, end, checi, dingyuan, kezuolv in zip(car_index.index[0::2],car_index.index[1::2], car_info[0], car_info[6], car_info[8]):one_car = data.iloc[start:end+1, :] # 截取其中一趟车的数据one_car.reset_index(inplace=True, drop=True) # 重置索引col_ind = one_car.isna().sum(axis=0)==len(one_car) # 判断全为空的列one_car = one_car.loc[:, ~col_ind] # 删除空列station = one_car.iloc[2:-1, 0] # 取所有站点,在2至倒数第一行one_car_list = []for s in station: # 循环每个站点去取数据one_car_dict = {}one_car_dict['车次'] = checione_car_dict['定员'] = dingyuanone_car_dict['客座率'] = kezuolvone_car_dict['日期'] = datesone_car_dict['站点'] = sone_car_dict['进站时间'] = one_car.loc[one_car[0]==s, 1].values[0] # 进站时间one_car_dict['下车人数'] = one_car.loc[one_car[0]==s, one_car.shape[1]-1].values[0] # 下车人数try:one_car_dict['离站时间'] = one_car.loc[1,one_car.iloc[0]==s].values[0] # 离站时间one_car_dict['上车人数'] = one_car.loc[len(one_car)-1,one_car.iloc[0]==s].values[0] # 上车人数except:one_car_dict['离站时间'] = '--' # 终点站没有出站时间和人数one_car_dict['上车人数'] = '--'one_car_list.append(one_car_dict)one_car_data = pd.DataFrame(one_car_list)break#all_car = pd.concat([all_car, one_car_data])
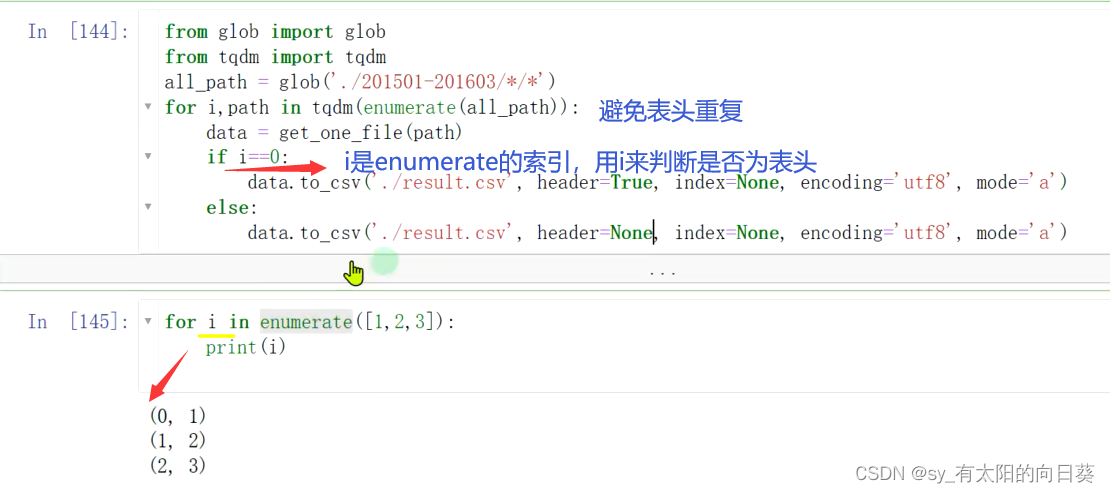
#这一步结束就能看到处理后表的信息了one_car_datadef get_one_file(path):data = pd.read_excel(path, skiprows=2, header=None) # 读数据dates = path.split('/')[-1][:8] # 日期ind = data[0].apply(lambda x: '客座率' in x) # 筛选有车次信息的行数据car_info = data.loc[ind, 0]car_info = car_info.str.split(' ', expand=True) # 这里的得到车次、定员、客座率data = data[~ind] # 删除车次信息行data.reset_index(inplace=True, drop=True)## 接下来:找到某一趟车所在的小表格,思路就是找到【上车站、上车人数合计】所在的行ind = data[0].apply(lambda x: '上车站'==x or '上车人数合计'==x)car_index = data[ind]all_car = pd.DataFrame()for start, end, checi, dingyuan, kezuolv in zip(car_index.index[0::2],car_index.index[1::2], car_info[0], car_info[6], car_info[8]):one_car = data.iloc[start:end+1, :] # 截取其中一趟车的数据one_car.reset_index(inplace=True, drop=True) # 重置索引col_ind = one_car.isna().sum(axis=0)==len(one_car) # 判断全为空的列one_car = one_car.loc[:, ~col_ind] # 删除空列station = one_car.iloc[2:-1, 0] # 取所有站点,在2至倒数第一行one_car_list = []for s in station: # 循环每个站点去取数据one_car_dict = {}one_car_dict['车次'] = checione_car_dict['定员'] = dingyuanone_car_dict['客座率'] = kezuolvone_car_dict['日期'] = datesone_car_dict['站点'] = sone_car_dict['进站时间'] = one_car.loc[one_car[0]==s, 1].values[0] # 进站时间one_car_dict['下车人数'] = one_car.loc[one_car[0]==s, one_car.shape[1]-1].values[0] # 下车人数try:one_car_dict['离站时间'] = one_car.loc[1,one_car.iloc[0]==s].values[0] # 离站时间one_car_dict['上车人数'] = one_car.loc[len(one_car)-1,one_car.iloc[0]==s].values[0] # 上车人数except:one_car_dict['离站时间'] = '--' # 终点站没有出站时间和人数one_car_dict['上车人数'] = '--'one_car_list.append(one_car_dict)one_car_data = pd.DataFrame(one_car_list)all_car = pd.concat([all_car, one_car_data])return all_carfrom glob import glob
from tqdm import tqdm
all_path = glob('./201501-201603/*/*')
for i,path in tqdm(enumerate(all_path)):data = get_one_file(path)if i==0:data.to_csv('./result.csv', header=True, index=None, encoding='utf8', mode='a')else:data.to_csv('./result.csv', header=None, index=None, encoding='utf8', mode='a')相关文章:
数据分析——火车信息
任务目标 任务 1、整理火车发车信息数据,结果的表格形式为: 2、并输出最终的发车信息表 难点 1、多文件 一个文件夹,多个月的发车信息,一个excel,放一天的发车情况 2、数据表的格式特殊 如何分析表是一个难点 数…...
Bert-vits2最终版Bert-vits2-2.3云端训练和推理(Colab免费GPU算力平台)
对于深度学习初学者来说,JupyterNoteBook的脚本运行形式显然更加友好,依托Python语言的跨平台特性,JupyterNoteBook既可以在本地线下环境运行,也可以在线上服务器上运行。GoogleColab作为免费GPU算力平台的执牛耳者,更…...
Asp .Net Web应用程序(.Net Framework4.8)网站发布到IIS
开启IIS 如果已开启跳过这步 打开控制面板-程序 打开IIS 发布Web程序(.Net Framework 4.8 web网页) 进入IIS管理器新建一个应用池 新建一个网站 网站创建完毕 为文件夹添加访问权限 如果不添加访问权限,运行时将会得到如下错误 设置权限 勾…...

vue element plus Typography 排版
我们对字体进行统一规范,力求在各个操作系统下都有最佳展示效果。 字体# 字号# LevelFont SizeDemoSupplementary text12px Extra SmallBuild with ElementBody (small)13px SmallBuild with ElementBody14px BaseBuild with ElementSmall Title16px MediumBuild w…...

理论U3 决策树
文章目录 一、决策树算法1、基本思想2、构成1)节点3)有向边/分支 3、分类步骤1)第1步-决策树生成/学习、训练2)第2步-分类/测试 4、算法关键 二、信息论基础1、概念2、信息量3、信息熵: 二、ID3 (Iterative Dichotomis…...

Redis 常用操作
一、Redis常用的5种数据类型 字符串(String):最基本的数据类型,可以存储字符串、整数或浮点数。哈希(Hash):键值对的集合,可以在一个哈希数据结构中存储多个字段和值。列表…...

c# 使用Null合并操作符例子
在这个示例中,我们定义了两个字符串变量 name 和 defaultName。变量 name 被赋值为 null,而变量 defaultName 被赋值为 “John Doe”。 接下来,我们使用 Null 合并操作符 ?? 来获取一个非空值。如果 name 不为 null,则 result 的…...
【Docker】docker部署conda并激活环境
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、新建dockerfile文件二、使用build创建镜像1.报错:Your shell has not been properly configured to use conda activate.…...
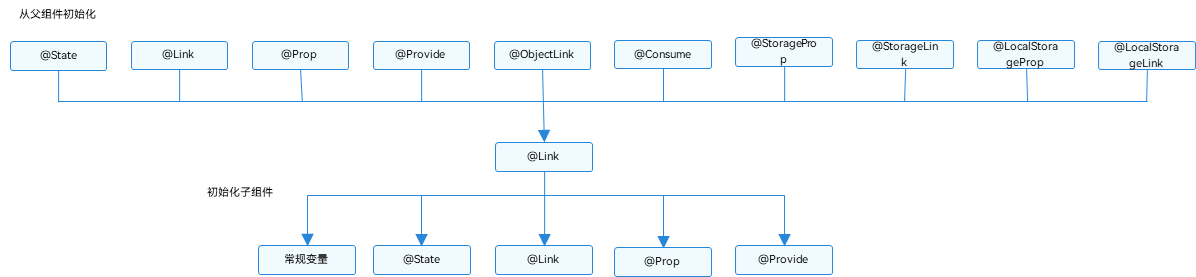
HarmonyOS@Link装饰器:父子双向同步
Link装饰器:父子双向同步 子组件中被Link装饰的变量与其父组件中对应的数据源建立双向数据绑定。 说明 从API version 9开始,该装饰器支持在ArkTS卡片中使用。 概述 Link装饰的变量与其父组件中的数据源共享相同的值。 装饰器使用规则说明 Link变…...
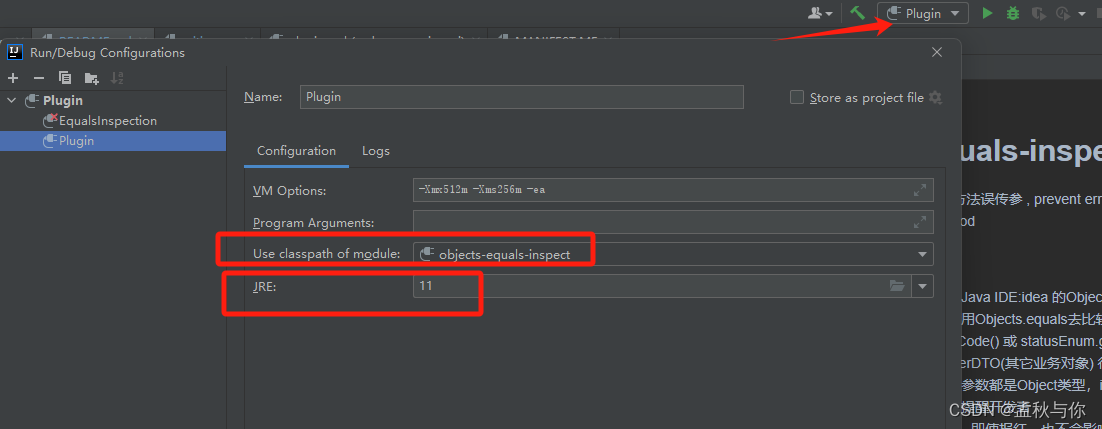
【idea】idea插件编写教程,博主原创idea插件 欢迎下载
前言:经常使用Objects.equals(a,b)方法的同学 应该或多或少都会因为粗心而传错参, 例如日常开发中 我们使用Objects.equals去比较 status(入参),statusEnum(枚举), 很容易忘记statusEnum.getCode() 或 statusEnum.getVaule() ,再比…...
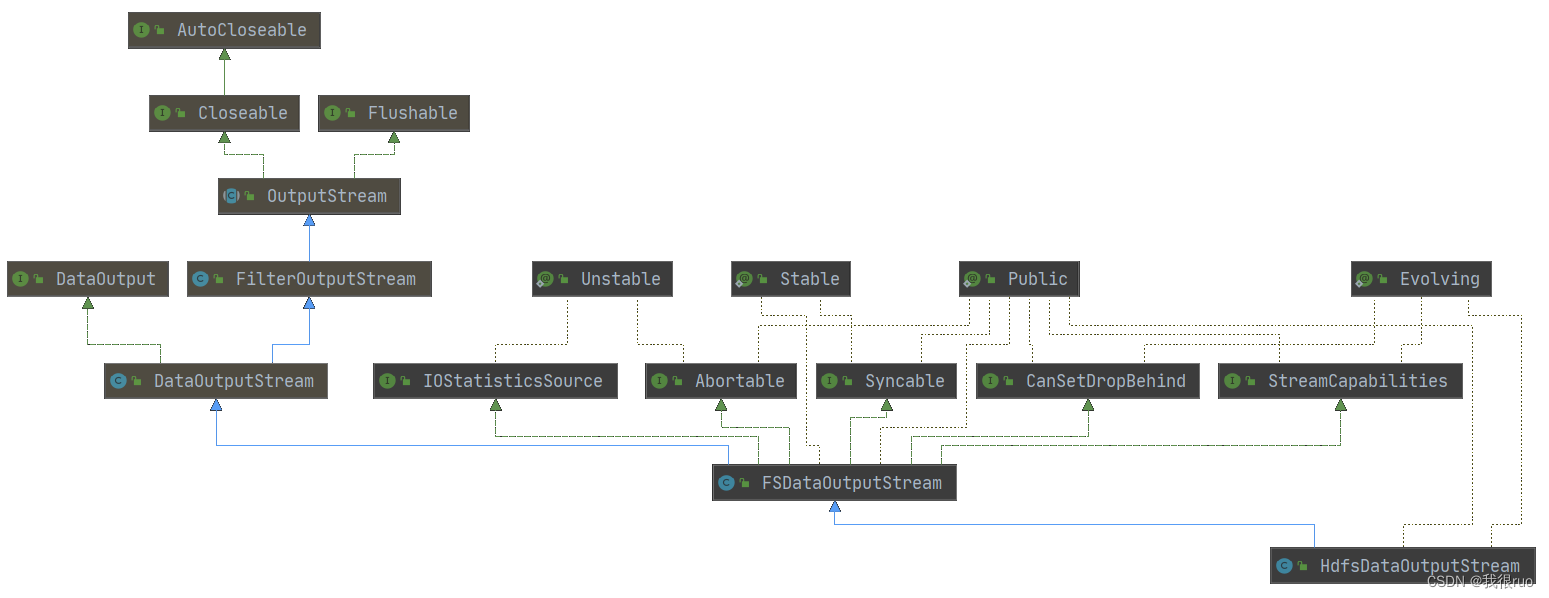
深入理解 Hadoop (四)HDFS源码剖析
HDFS 集群启动脚本 start-dfs.sh 分析 启动 HDFS 集群总共会涉及到的角色会有 namenode, datanode, zkfc, journalnode, secondaryName 共五种角色。 JournalNode 核心工作和启动流程源码剖析 // 启动 JournalNode 的核心业务方法 public void start() throws IOException …...
【Vue3+React18+TS4】1-1 : 课程介绍与学习指南
本书目录:点击进入 一、为什么做这样一门课程? 二、本门课的亮点有哪些? 2.1、轻松驾驭 2.2、体系系统 2.3、高效快捷 2.4、融合贯通 三、课程内容包括哪些? 四、项目实战 《在线考勤系统》 五、课适合哪些同学? 一、为什么做这样一门课程? 近十年内前端…...

Nacos与Eureka的区别详解
Nacos与Eureka的区别详解 在微服务架构中,服务注册与发现是核心组件之一,它们允许服务实例在启动时自动注册,并且能被其他服务发现,从而实现服务之间的互相通信。Nacos和Eureka都是现代微服务体系中广泛使用的服务注册与发现工具。本文将深入分析二者的区别,并为您提供一…...
【算法刷题】Day28
文章目录 1. 买卖股票的最佳时机 III题干:算法原理:1. 状态表示:2. 状态转移方程3. 初始化4. 填表顺序5. 返回值 代码: 2. Z 字形变换题干:算法原理:1. 模拟2. 找规律 代码: 1. 买卖股票的最佳时…...

深入了解pnpm:一种高效的包管理工具
✨专栏介绍 在当今数字化时代,Web应用程序已经成为了人们生活和工作中不可或缺的一部分。而要构建出令人印象深刻且功能强大的Web应用程序,就需要掌握一系列前端技术。前端技术涵盖了HTML、CSS和JavaScript等核心技术,以及各种框架、库和工具…...
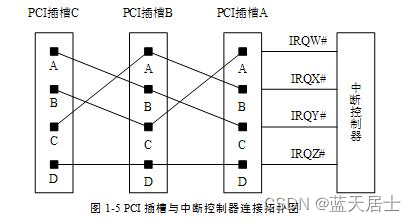
QEMU源码全解析 —— PCI设备模拟(1)
接前一篇文章: 1. PCI设备简介 PCI是用来连接外设的一种局部(local)总线,其主要功能是连接外部设备。PCI总线规范在20世纪90年代提出以后,其逐渐取代了其它各种总线,被各种处理器所支持。直到现在…...
Vue-10、Vue键盘事件
1、vue中常见的按键别名 回车 ---------enter <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>键盘事件</title><!--引入vue--><script type"text/javascript" src"h…...
胡圆圆的暑期实习经验分享
背景 实验室一般是在研究生二年级的时候会放实习,在以后的日子就是自己完成毕业工作要求,基本上不再涉及实验室的活了,目前是一月份也是开始准备暑期实习的好时间。实验室每年这个时候都会有学长学姐组织暑期实习经验分享,本着不…...
基于uniapp封装的table组件
数据格式 tableData: [{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},{elcInfo: [{tableData:[1,293021.1,293021.1,293021.1,293021.1,]}]},/* {title: "2",elcInfo: [{…...
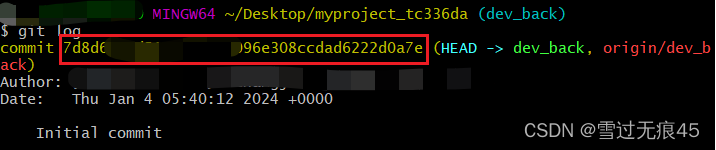
Git删除远程仓库某次提交记录后的所有提交
1、鼠标右键->git bash here,然后cd切换到代码目录; 2、git log查看提交记录,获取commit id 3、git reset commit id(commit id指要保留的最新的提交记录id) 4、git push --force,强制push 如果出现…...

告别枯燥理论:用Verilog在FPGA上实现一个可交互的I2C温度传感器从机
从零构建FPGA上的智能温度传感器:Verilog I2C从机实战指南 当你想在FPGA上连接一个温度传感器时,市面上常见的I2C传感器如LM75似乎是个简单选择——但你是否想过,用Verilog自己实现一个会是什么体验?本文将带你从协议层开始&#…...

别再让电机烧了!聊聊工业设备中三相电源保护的两种经典电路设计与选型
工业三相电机保护电路设计实战:从原理到工程落地 在空压机房嘈杂的轰鸣声中,老王师傅正对着烧毁的电机摇头叹气——这已经是本月第三台因电源故障报废的设备。类似场景在工业现场屡见不鲜,统计显示超过40%的电机故障源于电源异常,…...

【译】《心悟内核:先懂设计,再读代码》—1、内核并非进程,而是整个系统本身
作者:Moon Hee Lee 原文: The Kernel in the Mind 心悟内核:先懂设计,再读代码——内核并非进程,而是整个系统本身Linux 内核既不是普通进程、守护进程,也不是应用程序。它是一套常驻内存的高特权运行环境,…...

AIKit:基于容器的一站式开源大语言模型部署与微调平台
1. AIKit项目概述:一站式开源大语言模型部署与微调平台 如果你和我一样,在尝试将Llama、Mistral这类开源大语言模型(LLM)真正用起来时,被复杂的依赖、环境配置和性能优化搞得焦头烂额,那么AIKit的出现&…...

如何在Dev-C++中配置TDM-GCC编译器
在Dev-C中配置TDM-GCC编译器的步骤如下: 步骤1:下载TDM-GCC编译器 访问 TDM-GCC官网下载适用于Windows的安装包(推荐选择64位版本:tdm-gcc-xxx.exe) 步骤2:安装TDM-GCC 运行安装程序,选择默认…...

告别工具堆叠:2026 年智能运维的核心竞争力是数据一体化
在运维行业待得越久,越能感受到一个普遍的痛点:很多团队工具越买越多,效率却没跟上。你是不是也踩过类似的坑?装了 Zabbix、Prometheus、ELK,再配上一堆自研脚本和自动化工具,看起来功能齐全,实…...

OpenClaw智能体引导基准测试:本地LLM多步骤任务执行能力评估
1. 项目概述:一个专为LLM智能体设计的“开箱即用”能力基准测试 如果你最近在关注本地大语言模型(LLM)和智能体(Agent)的进展,可能会发现一个现象:很多模型在标准问答或代码生成任务上表现不错…...

交完Essay才发现Turnitin更新了AI检测?我是这么应对的
上学期我的一个朋友被约谈了。 教授发邮件说:"你的Essay和AI生成文本相似度过高,请来办公室解释。" 他确实用了AI——谁没用呢——但他也认真改写了好几遍。问题是,Turnitin在2025年更新了AI检测模型,现在它不只看词汇…...

Flexpilot AI:开源可定制的VS Code AI编程助手配置与实战指南
1. 项目概述与核心价值作为一名在开发工具领域摸爬滚打了十多年的老码农,我见证过无数个“下一代编辑器”和“智能助手”的兴衰。当GitHub Copilot横空出世,确实改变了游戏规则,但随之而来的,是开发者们被锁定在单一服务商、高昂的…...

微博数据接口解决方案:Python爬虫工程实践与反爬策略
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫longlannet/weibo。乍一看,这像是一个与微博相关的代码仓库,但它的价值远不止于一个简单的爬虫或客户端。作为一个在数据工程和自动化领域摸爬滚打多年的从业者,我深知在当今…...