【Flink精讲】Flink数据延迟处理
面试题:Flink数据延迟怎么处理?
- 将迟到数据直接丢弃【默认方案】
- 将迟到数据收集起来另外处理(旁路输出)
- 重新激活已经关闭的窗口并重新计算以修正结果(Lateness)
Flink数据延迟处理方案
用一个案例说明三种处理方式
举个例子:左流跟右流按照5秒的时间窗口进行coGroup操作(按单词进行关联),超过5秒进行丢弃。
结果说明:在Socket数据源输入 "1005000 java" 后,会统计1005000时间戳之前的数据,而在1005000时间戳之后输入的hello就没有被统计输出。当输入 "1010000 xixi" 后,触发了第2个窗口,只输出了java,还是没有后输入的hello统计结果,这也更明确了1005000时间戳之后输入的hello被丢弃了。
object MyCoGroupJoin {def main(args: Array[String]): Unit = {//创建环境变量val env = StreamExecutionEnvironment.getExecutionEnvironment//指定事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)//创建Socket源数据流,内容格式 "时间戳 单词"val s1 = env.socketTextStream("127.0.0.1", 9000)// 设置事件时间戳字段.assignAscendingTimestamps(_.split(" ")(0).toLong).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})//创建Socket源数据流,内容格式 "时间戳 单词"val s2 = env.socketTextStream("127.0.0.1", 8888)// 设置事件时间戳字段.assignAscendingTimestamps(_.split(" ")(0).toLong).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})//将两个数据流进行合并统计,这里是将两数据流利用窗口进行单词拼串处理s1.coGroup(s2).where(_._2).equalTo(_._2).window(TumblingEventTimeWindows.of(Time.seconds(5))) //滚动窗口,窗口大小5秒.apply(new CoGroupFunction[(Long, String), (Long, String), String] {override def coGroup(first: lang.Iterable[(Long, String)], second: lang.Iterable[(Long, String)], out: Collector[String]): Unit = {//对两数据流中的数据进行循环遍历,并拼串下发first.forEach(r1 => {second.forEach(r2 => {println(s"${r1}::${r2}")val str = r1._2 + r2._2out.collect(str)})})}}).print()env.execute("cogroupjoin")}
}运行效果
========左流========
nc -l 99991001000 hello
1005000 java
1003000 hello [这条被丢弃了]
1010000 xixi========右流========
nc -l 88881002000 hello
1005000 java
1001000 hello [这条被丢弃了]
1010000 xixi========程序控制台输出结果========
(1001000,hello)::(1002000,hello)
4> hellohello
(1005000,java)::(1005000,java)
2> javajava设置Watermark
时间语义:
- Event Time(事件时间):每条数据或事件自带的时间属性。由于时间属性依附于数据本身,在高并发的情况下可能存在Event Time的到达为乱序的,即一个较早发生的数据延迟到达
- Process Time(处理时间):对于某个算子来说,Processing Time指算子使用当前机器的系统时钟时间
- Ingestion Time(接入时间):事件到达Flink Source的时间
Flink的三种时间语义中,Processing Time和Ingestion Time都是基于Flink本身所产生的时间,可以不用设置时间字段和Watermark。如果要使用Event Time,以下两项配置缺一不可:第一,使用一个时间戳为数据流中每个事件的Event Time赋值;第二,生成Watermark。
Event Time是每个事件的元数据,如果不设置,Flink并不知道每个事件的发生时间,我们必须要为每个事件的Event Time赋值一个时间戳。关于时间戳,包括Flink在内的绝大多数系统都使用Unix时间戳系统(Unix time或Unix epoch)。Unix时间戳系统以1970-01-01 00:00:00.000 为起始点,其他时间记为距离该起始时间的整数差值,一般是毫秒(millisecond)精度。
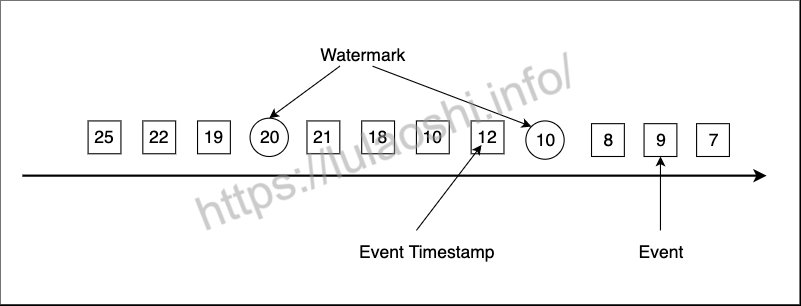
有了Event Time时间戳,我们还必须生成Watermark。Watermark是Flink插入到数据流中的一种特殊的数据结构,它包含一个时间戳,并假设后续不会有小于该时间戳的数据,如果后续数据存在小于该时间戳的数据则视为延迟数据,需另外处理。下图展示了一个乱序数据流,其中方框是单个事件,方框中的数字是其对应的Event Time时间戳,圆圈为Watermark,圆圈中的数字为Watermark对应的时间戳。
将之前的例子进行处理说明
object MyCoGroupJoin {def main(args: Array[String]): Unit = {// 创建环境变量val env = StreamExecutionEnvironment.getExecutionEnvironment// 指定事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// 创建Socket源数据流,内容格式 "时间戳 单词"val s1 = env.socketTextStream("127.0.0.1", 9999)// 设置事件时间戳字段// .assignAscendingTimestamps(_.split(" ")(0).toLong)// 这里可以指定周期性产生WaterMark 或 间歇性产生WaterMark,分别使用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks来实现// 这里使用周期性产生WaterMark,延长2秒.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(2)) {override def extractTimestamp(element: String): Long = {val strs = element.split(" ")strs(0).toLong}}).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})// 创建Socket源数据流,内容格式 "时间戳 单词"val s2 = env.socketTextStream("127.0.0.1", 8888)// 设置事件时间戳字段// .assignAscendingTimestamps(_.split(" ")(0).toLong)// 这里可以指定周期性产生WaterMark 或 间歇性产生WaterMark,分别使用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks来实现// 这里使用周期性产生WaterMark,延长2秒.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(2)) {override def extractTimestamp(element: String): Long = {val strs = element.split(" ")strs(0).toLong}}).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})//将两个数据流进行合并统计,这里是将两数据流利用窗口进行单词拼串处理s1.coGroup(s2).where(_._2).equalTo(_._2).window(TumblingEventTimeWindows.of(Time.seconds(5))) //滚动窗口,窗口大小5秒.apply(new CoGroupFunction[(Long, String), (Long, String), String] {override def coGroup(first: lang.Iterable[(Long, String)], second: lang.Iterable[(Long, String)], out: Collector[String]): Unit = {// 对两数据流中的数据进行循环遍历,并拼串下发first.forEach(r1 => {second.forEach(r2 => {println(s"${r1}::${r2}")val str = r1._2 + r2._2out.collect(str)})})}}).print()env.execute("cogroupjoin")}
}执行效果
=========左流=========
nc -l 9999
1001000 hello
1005000 java
1003000 hello
1007000 java=========右流=========
nc -l 8888
1002000 hello
1005000 java
1001000 hello
1007000 java=========程序控制台输出=========
(1001000,hello)::(1002000,hello)
4> hellohello
(1001000,hello)::(1001000,hello)
4> hellohello
(1003000,hello)::(1002000,hello)
4> hellohello
(1003000,hello)::(1001000,hello)
4> hellohello当我们使用Watermark后,我们可以发现在两个Socket终端输入"1005000 java"时,控制台并没有立刻统计输出信息。而是在两个Socket终端输入 "1007000 java"后,控制台才将统计结果输出出来,且在时间戳"1005000"之后输入的hello也同时给统计出来了,上面的问题可以解决了,但是 "1007000 java" 之后我们再输入 hello ,你会发现还是存在问题,没有输出又给丢弃了。继续测试如下。
======左流======
nc -l 9999
1001000 hello
1005000 java
1003000 hello
1007000 java
1003000 hello
1012000 spark======右流======
nc -l 8888
1002000 hello
1005000 java
1001000 hello
1007000 java
1004000 hello
1012000 spark=======程序执行控制台输出结果=======
(1001000,hello)::(1002000,hello)
4> hellohello
(1001000,hello)::(1001000,hello)
4> hellohello
(1003000,hello)::(1002000,hello)
4> hellohello
(1003000,hello)::(1001000,hello)
4> hellohello
(1005000,java)::(1005000,java)
2> javajava
(1005000,java)::(1007000,java)
2> javajava
(1007000,java)::(1005000,java)
2> javajava
(1007000,java)::(1007000,java)
2> javajava所以waterMark只能在一定程度上解决这种问题。我们再来看看allowedLateness机制。
设置Lateness
object MyCoGroupJoin {def main(args: Array[String]): Unit = {// 创建环境变量val env = StreamExecutionEnvironment.getExecutionEnvironment// 指定事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// 创建Socket源数据流,内容格式 "时间戳 单词"val s1 = env.socketTextStream("127.0.0.1", 9999)// 设置事件时间戳字段// .assignAscendingTimestamps(_.split(" ")(0).toLong)// 这里可以指定周期性产生WaterMark 或 间歇性产生WaterMark,分别使用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks来实现// 这里使用周期性产生WaterMark,延长2秒.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(2)) {override def extractTimestamp(element: String): Long = {val strs = element.split(" ")strs(0).toLong}}).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})// 创建Socket源数据流,内容格式 "时间戳 单词"val s2 = env.socketTextStream("127.0.0.1", 8888)// 设置事件时间戳字段// .assignAscendingTimestamps(_.split(" ")(0).toLong)// 这里可以指定周期性产生WaterMark 或 间歇性产生WaterMark,分别使用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks来实现// 这里使用周期性产生WaterMark,延长2秒.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(2)) {override def extractTimestamp(element: String): Long = {val strs = element.split(" ")strs(0).toLong}}).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})//将两个数据流进行合并统计,这里是将两数据流利用窗口进行单词拼串处理s1.coGroup(s2).where(_._2).equalTo(_._2).window(TumblingEventTimeWindows.of(Time.seconds(5))) //滚动窗口,窗口大小5秒// 允许数据迟到2秒,窗口触发后2秒内过来的数据还可以重新被计算.allowedLateness(Time.seconds(2)).apply(new CoGroupFunction[(Long, String), (Long, String), String] {override def coGroup(first: lang.Iterable[(Long, String)], second: lang.Iterable[(Long, String)], out: Collector[String]): Unit = {// 对两数据流中的数据进行循环遍历,并拼串下发first.forEach(r1 => {second.forEach(r2 => {println(s"${r1}::${r2}")val str = r1._2 + r2._2out.collect(str)})})}}).print()env.execute("cogroupjoin")}
}执行效果
======左流======
nc -l 9999
1001000 hello
1007000 java======右流======
nc -l 8888
1002000 hello
1007000 java
1003000 hello=======程序执行控制台输出结果=======
(1001000,hello)::(1002000,hello)
4> hellohello
(1001000,hello)::(1002000,hello)
4> hellohello
(1001000,hello)::(1003000,hello)
4> hellohello到这里估计有朋友又有疑问了,allowedLateness机制解决数据延迟设置的时间段,那之后再来的延迟数据呢,还是被丢弃了并没有彻底解决问题。别慌,针对allowedLateness机制之后来的延迟数据Flink还提供了另一种方案就是sideOutput机制。
旁路输出
Side Output简单来说就是在程序执行过程中,将主流stream流中的不同的业务类型或者不同条件的数据分别输出到不同的地方。如果我们想对没能及时在Flink窗口计算的延迟数据专门处理,也就是窗口已经计算了,但后面才来的数据专门处理,我们可以使用旁路输出到侧流中去处理。
object MyCoGroupJoin {def main(args: Array[String]): Unit = {// 创建环境变量val env = StreamExecutionEnvironment.getExecutionEnvironment// 指定事件时间env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// 创建Socket源数据流,内容格式 "时间戳 单词"val s1 = env.socketTextStream("127.0.0.1", 9999)// 这里可以指定周期性产生WaterMark 或 间歇性产生WaterMark,分别使用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks来实现// 这里使用周期性产生WaterMark,延长2秒.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(2)) {override def extractTimestamp(element: String): Long = {val strs = element.split(" ")strs(0).toLong}}).map(line => {val strs = line.split(" ")(strs(0).toLong, strs(1))})// 定义一个侧输出流val lateData: OutputTag[(Long, String)] = new OutputTag[(Long, String)]("late")val s2 = s1.timeWindowAll(Time.seconds(5))//允许迟到2秒数据.allowedLateness(Time.seconds(2))//迟到长于2秒的数据将被保存到lateData侧数据流中.sideOutputLateData(lateData).process(new ProcessAllWindowFunction[(Long, String), (Long, String), TimeWindow] {override def process(context: Context, elements: Iterable[(Long, String)], out: Collector[(Long, String)]): Unit = {elements.foreach(ele => {out.collect(ele)})}})s2.print("主流")s2.getSideOutput(lateData).print("侧流")env.execute("cogroupjoin")}
}=======数据流======
nc -l 9999
1001000 hello
1005000 java
1007000 python
1002000 hello
1009000 java
1001000 xixi
1002000 haha=======程序执行控制台输出结果=====
主流:10> (1001000,hello)
主流:11> (1001000,hello)
主流:12> (1002000,hello)
侧流:1> (1001000,xixi)
侧流:2> (1002000,haha)通过上面测试可以发现晚于allowedLateness机制的延迟数据,Flink没有丢弃而是输出到了侧输出流中等待处理了,这样延迟数据就完美解决了。
双流Join中的数据延迟处理
- 数据质量问题:流式数据到达计算引擎的时间不一定:比如 A 流的数据先到了,A 流不知道 B 流对应同 key 的数据什么时候到,没法关联;
- 数据时效问题:流式数据不知何时、下发怎样的数据:A 流的数据到达后,如果 B 流的数据永远不到,那么 A 流的数据在什么时候以及是否要填充一个 null 值下发下去。
Window Join
Flink Window Join。就是将两条流的数据从无界数据变为有界数据,即划分出时间窗口,然后将同一时间窗口内的两条流的数据做 Join(这里的时间窗口支持 Tumbling、Sliding、Session)。
解法说明:
- 流式数据到达计算引擎的时间不一定:数据已经被划分为窗口,无界数据变为有界数据,就和离线批处理的方式一样了,两个窗口的数据简单的进行关联即可
- 流式数据不知何时、下发怎样的数据:窗口结束就把数据下发下去,关联到的数据就下发 [A, B],没有关联到的数据取决于是否是 outer join 然后进行数据下发
Tumbling

Sliding

Session

Flink SQL(Flink 1.14 版本 Window TVF 中支持):
SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, L.window_start, L.window_end
FROM (SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L
FULL JOIN (SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
ON L.num = R.num
AND L.window_start = R.window_start
AND L.window_end = R.window_end;方案特点
⭐ 产出数据质量:低
⭐ 产出数据时效性:中
当我们的窗口大小划分的越细时,在窗口边缘关联不上的数据就会越多,数据质量就越差。窗口大小划分的越宽时,窗口内关联上的数据就会越多,数据质量越好,但是产出时效性就会越差。所以要注意取舍。
举个例子:以曝光关联点击来说,如果我们划分的时间窗口为 1 分钟,那么一旦出现曝光在 0:59,点击在 1:01 的情况,就会关联不上,当我们的划分的时间窗口 1 小时时,只有在每个小时的边界处的数据才会出现关联不上的情况。
适用场景
该种解决方案适用于可以评估出窗口内的关联率高的场景,如果窗口内关联率不高则不建议使用。注意:这种方案由于上面说到的数据质量和时效性问题在实际生产环境中很少使用。
Interval Join
Interval Join。其也是将两条流的数据从无界数据变为有界数据,但是这里的有界和Window Join 的有界的概念是不一样的,这里的有界是指两条流之间的有界。
以 A 流 join B 流举例,interval join 可以让 A 流可以关联 B 流一段时间区间内的数据,比如 A 流关联 B 流前后 5 分钟的数据。
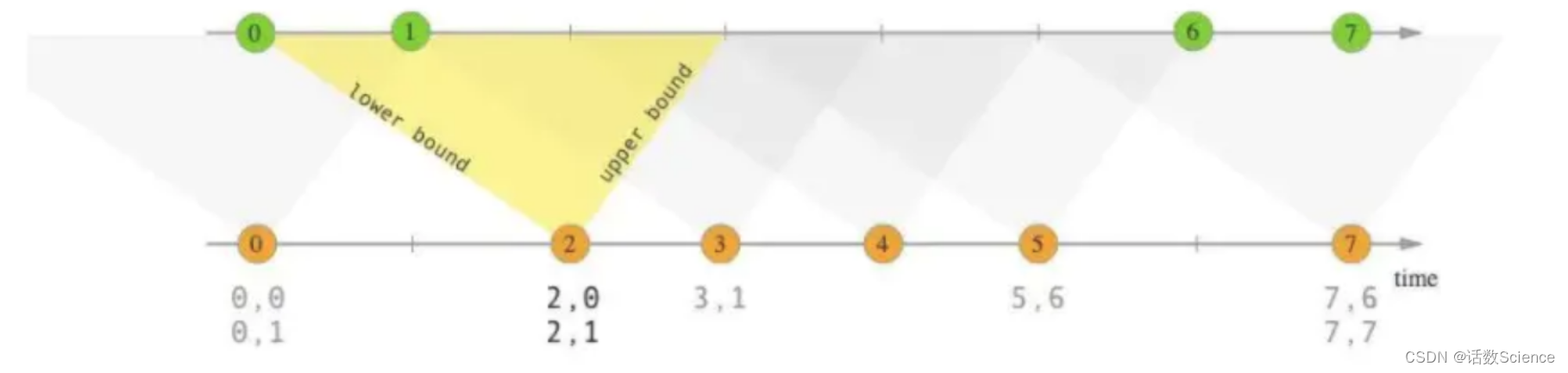
解法说明:
- 流式数据到达计算引擎的时间不一定:数据已经被划分为窗口,无界数据变为有界数据,就和离线批处理的方式一样了,两个窗口的数据简单的进行关联即可
- 流式数据不知何时、下发怎样的数据:窗口结束(这里的窗口结束是指 interval 区间结束,区间的结束是利用 watermark 来判断的)就把数据下发下去,关联到的数据就下发 [A, B],没有关联到的数据取决于是否是 outer join 然后进行数据下发
CREATE TABLE show_log_table (log_id BIGINT,show_params STRING,row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),WATERMARK FOR row_time AS row_time) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.show_params.length' = '1','fields.log_id.min' = '1','fields.log_id.max' = '10');CREATE TABLE click_log_table (log_id BIGINT,click_params STRING,row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),WATERMARK FOR row_time AS row_time)WITH ('connector' = 'datagen','rows-per-second' = '1','fields.click_params.length' = '1','fields.log_id.min' = '1','fields.log_id.max' = '10');CREATE TABLE sink_table (s_id BIGINT,s_params STRING,c_id BIGINT,c_params STRING) WITH ('connector' = 'print');INSERT INTO sink_tableSELECTshow_log_table.log_id as s_id,show_log_table.show_params as s_params,click_log_table.log_id as c_id,click_log_table.click_params as c_paramsFROM show_log_table FULL JOIN click_log_table ON show_log_table.log_id = click_log_table.log_idAND show_log_table.row_time BETWEEN click_log_table.row_time - INTERVAL '5' SECOND AND click_log_table.row_time方案特点
⭐ 产出数据质量:中
⭐ 产出数据时效性:中
interval join 的方案比 window join 方案在数据质量上好很多,但是其也是存在 join 不到的情况的。并且如果为 outer join 的话,outer 一测的流数据需要要等到区间结束才能下发。
适用场景
该种解决方案适用于两条流之间可以明确评估出相互延迟的时间是多久的,这里我们可以使用离线数据进行评估,使用离线数据的两条流的时间戳做差得到一个分布区间。
比如在 A 流和 B 流时间戳相差在 1min 之内的有 95%,在 1-4 min 之内的有 4.5%,则我们就可以认为两条流数据时间相差在 4 min 之内的有 99.5%,这时我们将上下界设置为 4min 就是一个能保障 0.5% 误差的合理区间。
注意:这种方案在生产环境中还是比较常用的。
Regular Join
Regular Join。上面两节说的两种 Join 都是基于划分窗口,将无界数据变为有界数据进行关联机制,但是本节说的 regular join 则还是基于无界数据进行关联。
以 A 流 left join B 流举例,A 流数据到来之后,直接去尝试关联 B 流数据。
1. 如果关联到了则直接下发关联到的数据
2. 如果没有关联到则也直接下发没有关联到的数据,后续 B 流中的数据到来之后,会把之前下发下去的没有关联到数据撤回,然后把关联到的数据数据进行下发。由此可以看出这是基于 Flink SQL 的 retract 机制,则也就说明了其目前只支持 Flink SQL。
解法说明:
- 流式数据到达计算引擎的时间不一定:两条流的数据会尝试关联,能关联到直接下发,关联不到先下发一个目前的结果数据
- 流式数据不知何时、下发怎样的数据:两条流的数据会尝试关联,能关联到直接下发,关联不到先下发一个目前的结果数据
CREATE TABLE show_log_table (log_id BIGINT,show_params STRING
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.show_params.length' = '3','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE click_log_table (log_id BIGINT,click_params STRING
)
WITH ('connector' = 'datagen','rows-per-second' = '1','fields.click_params.length' = '3','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE sink_table (s_id BIGINT,s_params STRING,c_id BIGINT,c_params STRING
) WITH ('connector' = 'print'
);INSERT INTO sink_table
SELECTshow_log_table.log_id as s_id,show_log_table.show_params as s_params,click_log_table.log_id as c_id,click_log_table.click_params as c_params
FROM show_log_table
LEFT JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id;方案特点
产出数据质量:高
产出数据时效性:高
数据质量和时效性高的原因都是因为 regular join 会保障目前 Flink 任务已经接收到的数据中能关联的一定是关联上的,即使关联不上,数据也会下发,完完全全保障了当前数据的客观性和时效性。
适用场景
该种解决方案虽然是目前在产出质量、时效性上最好的一种解决方案,但是在实际场景中使用时,也存在一些问题:
基于 retract 机制,所有的数据都会存储在 state 中以判断能否关联到,所以我们要设置合理的 state ttl 来避免大 state 问题导致的任务不稳定
基于 retract 机制,所以在数据发生更新时,会下发回撤数据、最新数据 2 条消息,当我们的关联层级越多,则下发消息量的也会放大
sink 组件要支持 retract,我们不要忘了最终数据是要提供数据服务给需求方进行使用的,所以我们最终写入的数据组件也需要支持 retract,比如 MySQL。如果写入的是 Kafka,则下游消费这个 Kafka 的引擎也需要支持回撤\更新机制。
相关文章:
【Flink精讲】Flink数据延迟处理
面试题:Flink数据延迟怎么处理? 将迟到数据直接丢弃【默认方案】将迟到数据收集起来另外处理(旁路输出)重新激活已经关闭的窗口并重新计算以修正结果(Lateness) Flink数据延迟处理方案 用一个案例说明三…...
)
vue项目心得(复盘)
在编写项目过程中,首先是接手一个需要优化的项目,需要查看vue.config.js环境配置地址,确认好测试地址后进行开发,目前在开发过程中,遇到的最多的问题就是关于组件间的, 组件间传值 1、父组件异步传值&…...

Linux——firewalld防火墙(一)
一、Linux防火墙基础 Linux 的防火墙体系主要工作在网络层.针对TCP/P数据包实时过滤和限制.属于典型的包过滤防火墙(或称为网络层防火墙)。Linux系统的防火墙体系基于内核编码实现.具有非常稳定的性能和高效率,也因此获得广泛的应用.在CentOS 7系统中几种…...
JMeter之Windows安装
JMeter之Windows安装 一、安装JDK二、安装JMeter1、下载JMeter2、配置环境变量3、验证JMeter 三、扩展知识1、汉化 一、安装JDK 略 二、安装JMeter 1、下载JMeter 官网地址:https://jmeter.apache.org/download_jmeter.cgi 放到本地目录下 2、配置环境变量 变量…...

用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
Retrieval-Augmented Generation(RAG)是一种强大的技术,能够提高大型语言模型(LLM)的性能,使其能够从外部知识源中检索信息以生成更准确、具有上下文的回答。 本文将详细介绍 RAG 在 LangChain 中的应用&a…...
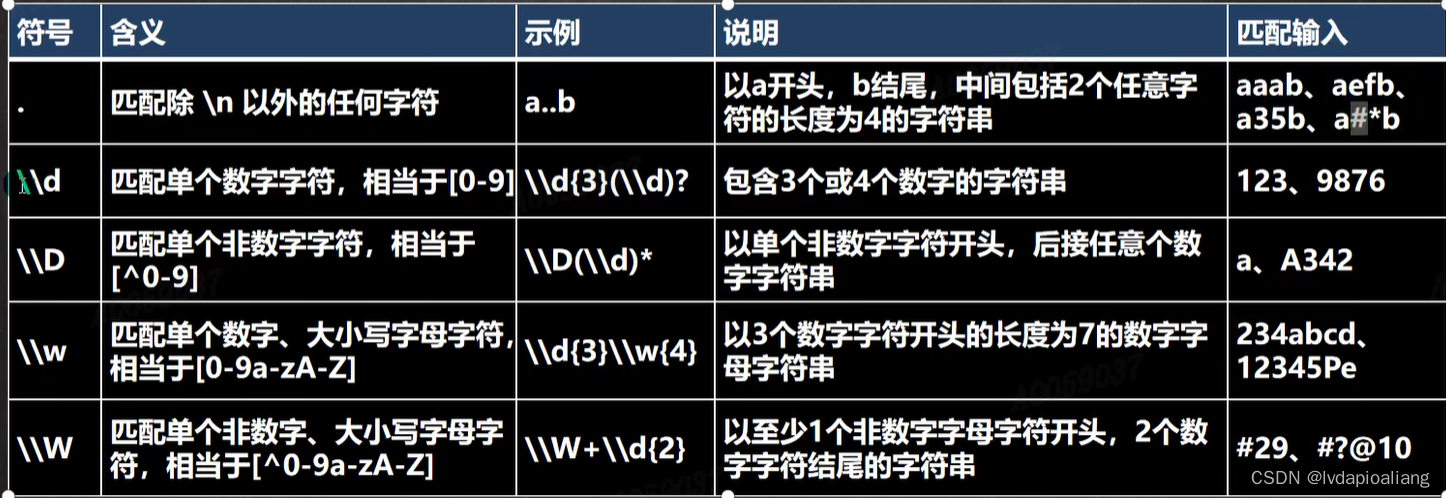
正则表达式的语法
如果要想灵活的运用正则表达式,必须了解其中各种元素字符的功能,元字符从功能上大致分为: 限定符 选择匹配符 分组组合和反向引用符 特殊字符 字符匹配符 定位符 我们先说一下元字符的转义号 元字符(Metacharacter)-转义号 \\ \\ 符号…...

MyBatis分页插件的实现原理
MyBatis 分页插件的实现原理是通过拦截器(Interceptor)来实现的。拦截器可以在 SQL 执行前后对 SQL 进行拦截和处理。 简单来说,就是通过在查询语句中添加额外的参数和逻辑,以支持分页功能。它的核心思想是将分页参数传递给插件&…...

Winform、WPF如何解决前端卡死问题
在WinForms和WPF中,前端卡死问题通常是由于长时间的计算或阻塞操作导致的。以下是一些解决前端卡死问题的常见方法: 使用异步操作:将长时间的计算或阻塞操作放在后台线程中执行,以避免阻塞UI线程。可以使用Task、async/await等异步…...

python内app自动化测试的局限性,该如何破局?
Python在App自动化测试方面非常流行,尤其对于移动应用(Android和iOS)的测试,可以借助于像Appium、Robot Framework等工具进行跨平台自动化。然而,即使使用Python这样的强大语言,App自动化测试也存在一些局限…...
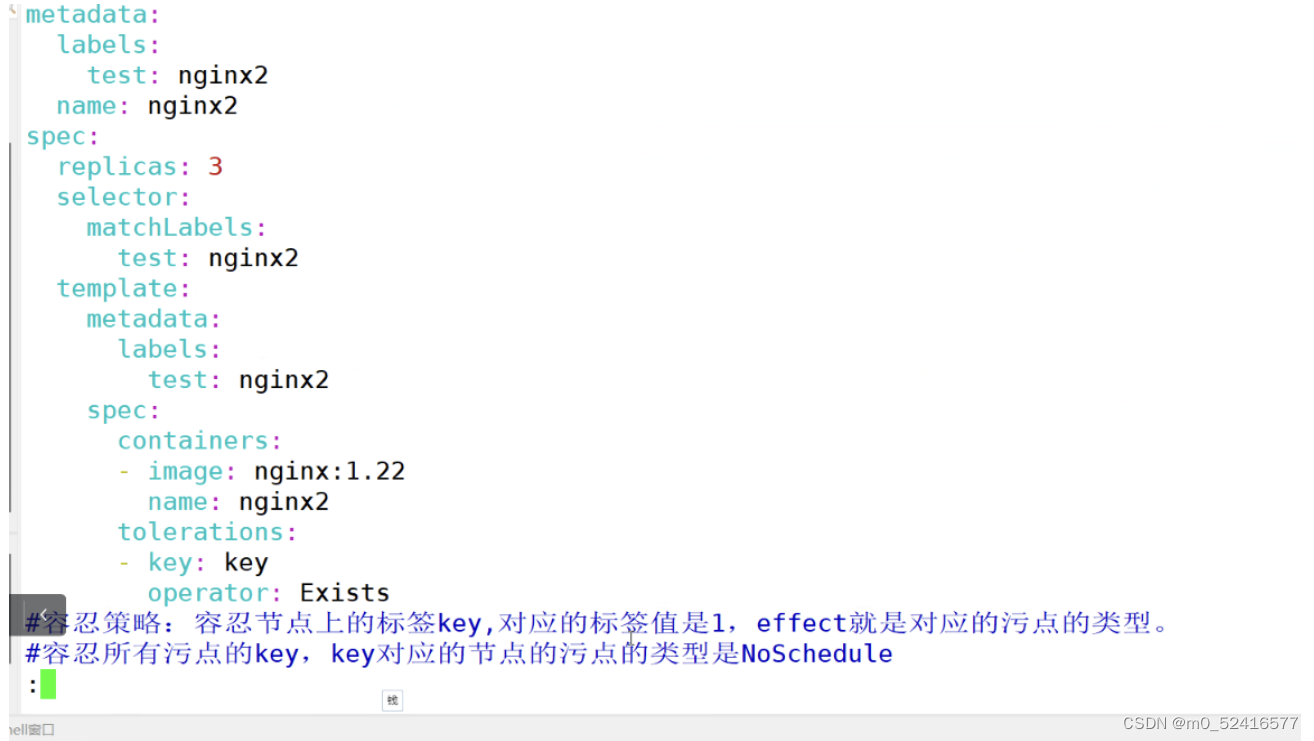
k8s的node亲和性和pod亲和性和反亲和性 污点 cordon drain
node亲和性和pod亲和性和反亲和性 污点 cordon drain 集群调度: schedule的调度算法 预算策略 过滤出合适的节点 优先策略 选择部署的节点 nodeName:硬匹配,不走调度策略,node01 nodeSelector:根据节点的标签选择,会走调度的算法 只…...
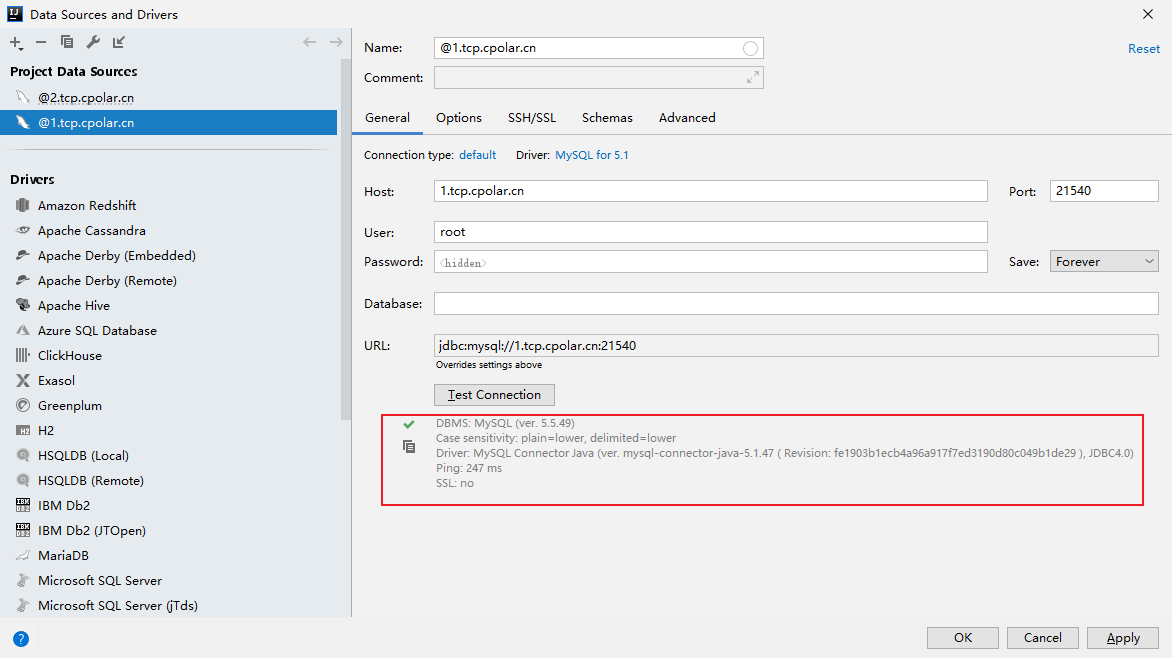
IntelliJ IDEA如何使用固定地址公网远程访问本地Mysql数据库
文章目录 1. 本地连接测试2. Windows安装Cpolar3. 配置Mysql公网地址4. IDEA远程连接Mysql小结 5. 固定连接公网地址6. 固定地址连接测试 IDEA作为Java开发最主力的工具,在开发过程中需要经常用到数据库,如Mysql数据库,但是在IDEA中只能连接本…...

GIT - 清除历史 Commit 瘦身仓库
目录 一.引言 二.仓库清理 ◆ 创建一个船新分支 ◆ 提交最新代码 ◆ 双指针替换分支 三.总结 一.引言 由于项目运行时间较长,分支较多,且分支内包含很多不同的大文件,随着时间的推移,历史 Git 库的容量日渐增发,…...
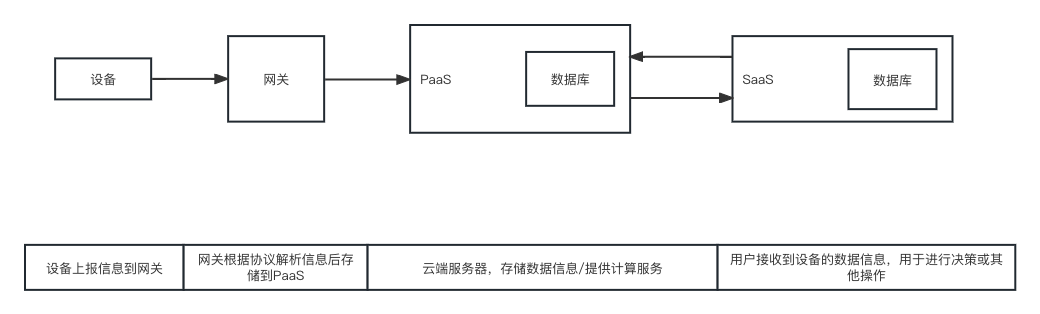
物联网产品中,终端、网关、协议、PaaS、SaaS之间的关系
在互联网产品中,经常提到的终端、网关、协议、PaaS、SaaS之间,到底有什么关系呢? 一、基本概念 在百度/其他地方搜集的信息中,对于终端、网关、协议、PaaS、SaaS的解释各有不同,整理如下: 终端࿱…...
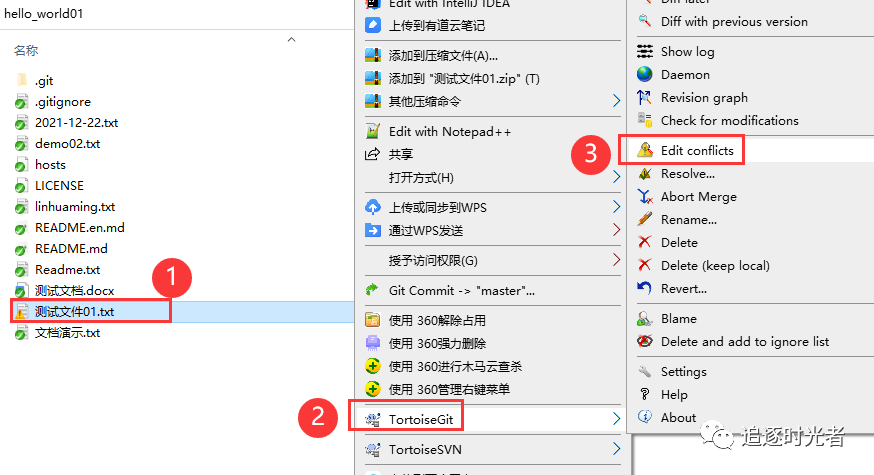
6款实用的Git可视化管理工具
前言 俗话说得好“工欲善其事,必先利其器”,合理的选择和使用可视化的管理工具可以降低技术入门和使用门槛。我们在团队开发中统一某个开发工具能够降低沟通成本,提高协作效率。今天给大家分享6款实用的Git可视化管理工具。 Git是什么&…...

python_selenium零基础爬虫学习案例_知网文献信息
案例最终效果说明: 去做这个案例的话是因为看到那个博主的分享,最后通过努力,我基本实现了进行主题、关键词、更新时间的三个筛选条件去获取数据,并且遍历数据将其导出到一个CSV文件中,代码是很简单的,没有…...

MindSpore Serving基于昇腾910B实现大模型部署
一、Why MindSpore Serving 大模型时代,作为一个开发人员更多的是关注一个大模型如何训练好、如何调整模型参数、如何才能得到一个更高的模型精度。而作为一个整体项目,只有项目落地才能有其真正的价值。那么如何才能够使得大模型实现落地?如…...
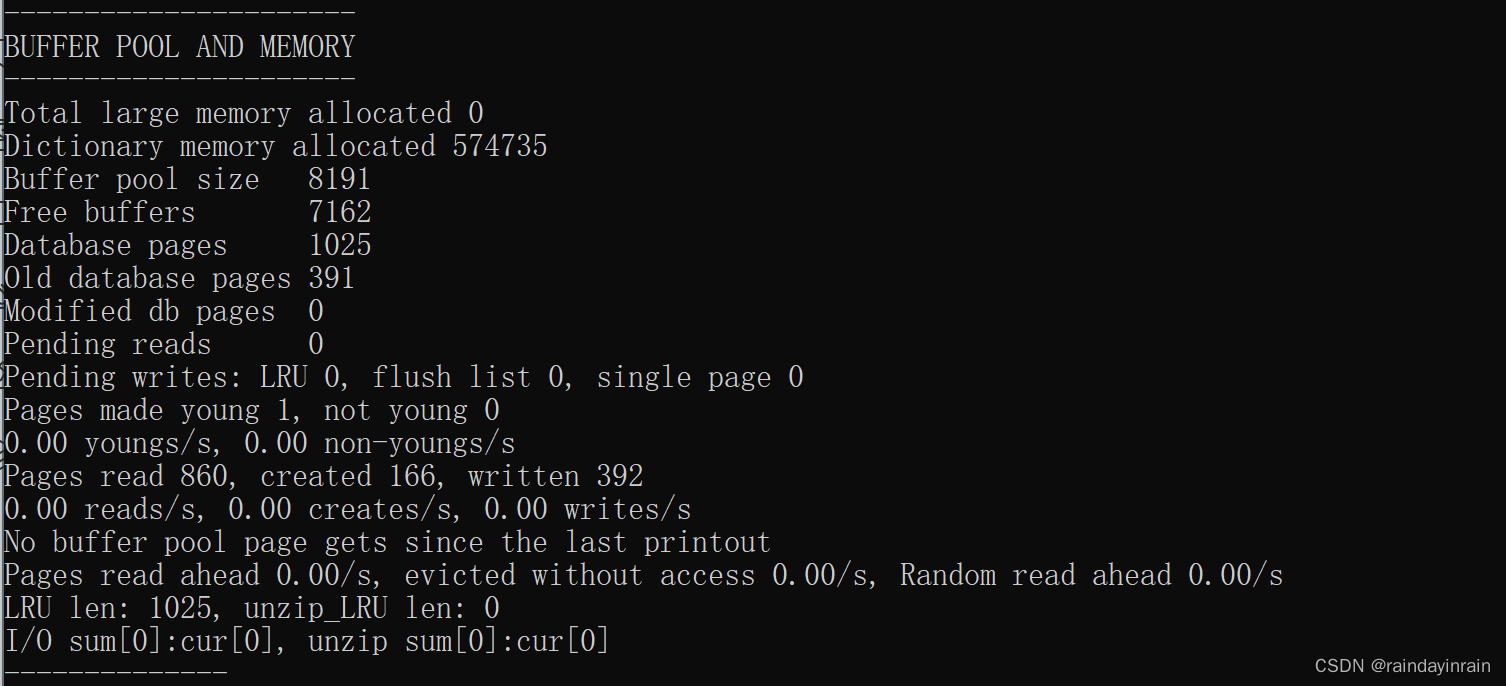
mysql原理--InnoDB的Buffer Pool
1.缓存的重要性 对于使用 InnoDB 作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以 页 的形式存放在 表空间 中的,而所谓的 表空间 只不过是 InnoDB 对…...
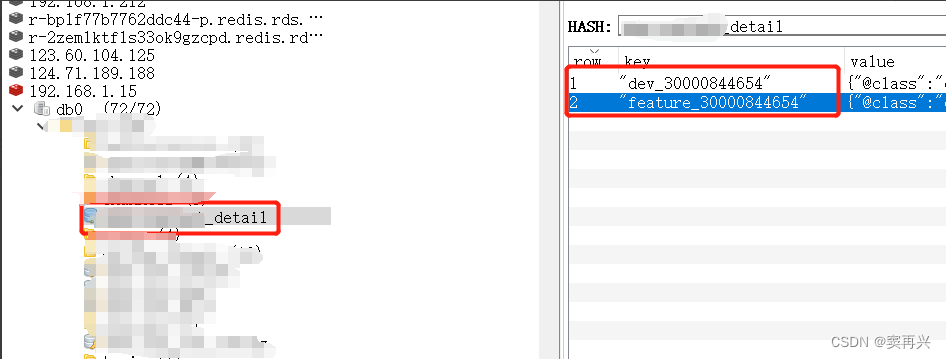
Redis不同环境缓存同一条数据,数据内部值不同
背景 现实中,本地环境(dev)和开发环境(feature)会共同使用相同的中间件(本篇拿Redis举例),对于不同环境中的,图片、视频、语音等资源类型的预览地址url,需要配…...
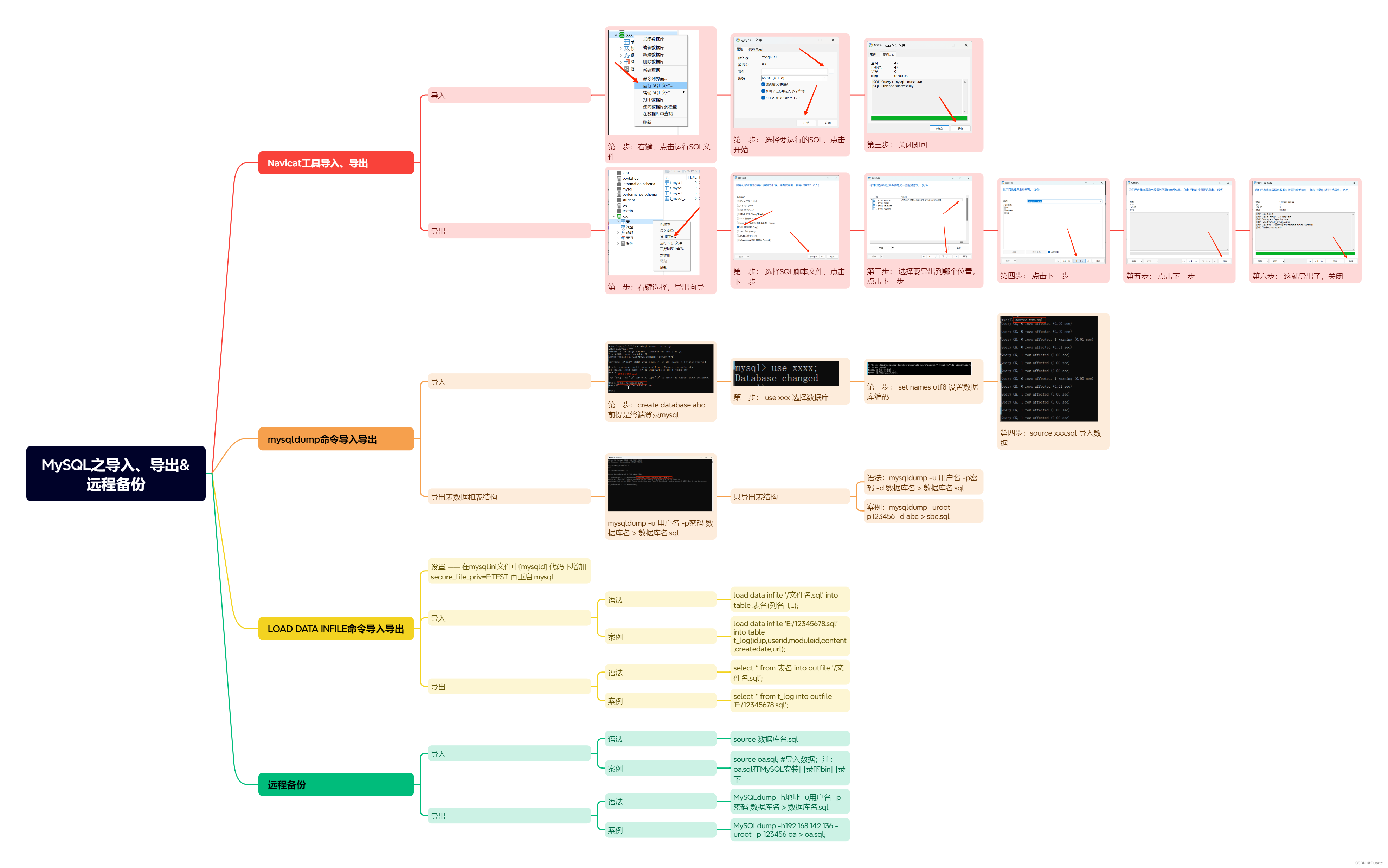
MySQL之导入、导出远程备份
一、Navicat工具导入、导出 1.1 导入 第一步: 右键,点击运行SQL文件 第二步: 选择要运行的SQL,点击开始 第三步: 关闭即可 1.2 导出 第一步: 右键选择,导出向导 第二步: 选择SQL脚…...
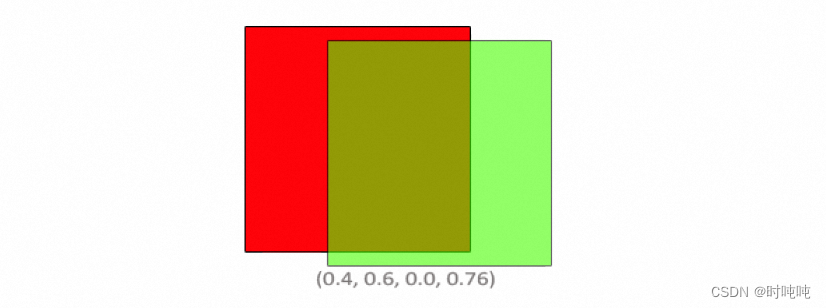
OpenGL学习笔记-Blending
混合方程中,Csource是片段着色器输出的颜色向量(the color output of the fragment shader),其权重为Fsource。Cdestination是当前存储在color buffer中的颜色向量(the color vector that is currently stored in the …...

AI原生Next.js启动器:集成Claude与Cursor的现代前端开发模板
1. 项目概述:一个为AI时代开发者量身定制的Next.js启动器如果你和我一样,每天都在和Next.js、TypeScript、Tailwind CSS打交道,同时又在频繁地与Claude、Cursor、Copilot这些AI编程助手“对话”,那你肯定也遇到过类似的烦恼&#…...

从引脚到协议:USB接口演进与Type-C双角色设计解析
1. USB接口的演进之路 记得我第一次拆解老式MP3播放器时,面对那个四针脚的USB接口,完全搞不懂为什么同样的接口有的能传数据有的只能充电。后来才发现,原来USB接口的发展史就是一部微型计算机外设的进化史。 1996年问世的USB 1.0标准只有12Mb…...

终极解决方案:如何一键修复所有Visual C++运行库问题
终极解决方案:如何一键修复所有Visual C运行库问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经因为"找不到MSVCR140.dll"而…...

数据中心网络跃迁:25GbE以太网如何以创造性破坏重塑技术路径
1. 从技术演进到范式跃迁:我眼中的“创造性破坏”风暴我是在上世纪90年代末来到这里的,那是一个技术浪潮奔涌的年代。我亲眼见证了录像带从VHS到DVD,再到如今的云DVR和视频流媒体的完整迭代;也目睹了通信设备从固定电话到功能手机…...

凌扬微优势代理 LY3508 4.2V/1A充电/1.6A驱动 全桥马达驱动控制芯片 ESOP8 技术解析
在电动牙刷、智能垃圾桶等单节锂电池供电的马达类产品中,需要一款集成锂电池充电管理和全桥马达驱动的芯片,以实现电机正反转、刹车控制,并简化外围电路设计。LY3508是一款集成了锂电池充电管理模块、全桥马达驱动模块、续流二极管和逻辑控制…...
完整配置步骤)
SAP S/4HANA 利润中心(PCA)完整配置步骤
SAP S/4HANA 利润中心(PCA)完整配置步骤按项目上线标准顺序一步步来,从零到可用,含前台 后台、必配 可选,通俗易懂不绕弯路一、前期基础前提(必须先做好)公司代码、控制范围已创建控制范围与公…...

5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南
5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 还在为传统神…...

VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战
VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存…...

工业数据采集新思路:用一台NET30-CS桥接器同时搞定欧姆龙PLC的FINS/TCP和ModbusTCP协议
工业数据采集新思路:NET30-CS桥接器实现欧姆龙PLC双协议并行接入 在工业自动化系统升级过程中,新旧设备协议兼容性问题一直是困扰工程师的技术痛点。当车间里同时存在依赖FINS/TCP协议的老旧监控系统和仅支持ModbusTCP的新型MES平台时,传统解…...

CANN/Ascend C逻辑异或API文档
LogicalXor 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com…...