MindSpore Serving基于昇腾910B实现大模型部署
一、Why MindSpore Serving
大模型时代,作为一个开发人员更多的是关注一个大模型如何训练好、如何调整模型参数、如何才能得到一个更高的模型精度。而作为一个整体项目,只有项目落地才能有其真正的价值。那么如何才能够使得大模型实现落地?如何才能使大模型项目中的文件以app的形式呈现给用户?
解决这个问题的一个组件就是Serving(服务),它主要解决的问题有:
- 模型如何提交给服务;
- 服务如何部署;
- 服务如何呈现给用户;
- 如何应用各种复杂场景等待
MindSpore Serving就是为了实现将大模型部署到生产环境而产生的。
MindSpore Serving是一个轻量级、高性能的服务模块,旨在帮助MindSpore开发者在生产环境中高效部署在线推理服务。当用户使用MindSpore完成模型训练后,导出MindIR,即可使用MindSpore Serving创建该大模型的推理服务。
MindSpore Serving实现的是一个模型服务化的部署,也就是说模型以线上的形式部署在服务器和云上,客户通过浏览器或者客户端去访问这个服务,将需要进行推理的输入内容发送给服务器,然后服务器将推理的结果返回给用户。
二、Component
MindSpore Serving由三部分组成,分别是客户端(Client)、Master和Worker。
-
客户端是用户节点,提供了gRPC和RESTful的访问。
-
Master是一个管理节点,管理所有Worker的信息,包括Worker有哪些模型的信息;Master也是一个分化节点,接收到了客户端的请求之后,会根据请求的内容,结合当前管理的Worker节点的信息进行分发,将请求分发给不同的Worker执行。
-
Worker是一个执行节点,会执行加载、模型的更新,在接收到Master转发的请求之后,会将请求进行组装和拆分,然后做前处理、推理和后处理,执行完之后将结果返回给Master,Master再将结果返回给客户端。
三、Features
1.简单易用:
对客户端提供了gRPC和RESTful的服务,同时又提供了服务的拉起、服务的部署和客户端的访问,提供了简单的python接口,通过python接口,用户可以很方便的定制和访问部署服务,只需要一行命令就能够完成一件事。
2.提供定制化的服务:
对于模型来说输入和输出一般是固定的,而对于用户来说输入和输出可能是多变的,这就需要一个预处理模块,将模型的输入转为一个模型可以识别的输入。同时还需要一个后处理模块,给用户提供定制化的服务,针对模型可以定制方法classifly_top,用户根据需要去写前处理和后处理的操作。对于客户端来说只要指定模型名和方法名就能实现推理的结果。
3.支持批处理:
主要是针对具有batchsize维度的文本来说。batchsize实现了文本的并行,在硬件资源足够的情况下,batchsize可以很大地提高性能。对于MindSpore Serving来说,用户一次性发送的请求是不确定的,因此Serving分割和组合一个或者多个请求以匹配用户模型的batchsize。例如batchsize=2,但是有三个请求发过来,这时候就会将两个请求合并处理,到后面再拆分,这样就实现了三个请求的并行,提高了效率。
- 高性能扩展:
MindSpore Serving所使用的算子引擎框架是MindSpore框架,具有自动融合和自动并行的高性能,再加上MindSpore Serving本身具有一个高性能的底层通信能力,客户端可以进行多实例组装,模型支持批处理,多模型之间支持并发,预处理和后处理支持多线程的处理。客户端和Worker可以实现扩展的,因此它也实现了一个高扩展性。
四、Demo
基于昇腾910B3
start_agent.py
from agent.agent_multi_post_method import *
from multiprocessing import Queuefrom config.serving_config import AgentConfig, ModelNameif __name__ == "__main__":startup_queue = Queue(1024)startup_agents(AgentConfig.ctx_setting,AgentConfig.inc_setting,AgentConfig.post_model_setting,len(AgentConfig.AgentPorts),AgentConfig.prefill_model,AgentConfig.decode_model,AgentConfig.argmax_model,AgentConfig.topk_model,startup_queue)started_agents = 0while True:value = startup_queue.get()print("agent : %f started" % value)started_agents = started_agents + 1if started_agents >= len(AgentConfig.AgentPorts):print("all agents started")break# server_app_post.init_server_app()# server_app_post.warmup_model(ModelName)# server_app_post.run_server_app()client/server_app_post.py
import asyncio
import json
import logging
import signal
import sys
import uuid
from multiprocessing import Processimport uvicorn
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from sse_starlette.sse import EventSourceResponse, ServerSentEventfrom client.client_utils import ClientRequest, Parameters
from config.serving_config import SERVER_APP_HOST, SERVER_APP_PORT
from server.llm_server_post import LLMServerlogging.basicConfig(level=logging.DEBUG,filename='./output/server_app.log',filemode='w',format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')app = FastAPI()
llm_server = Noneasync def get_full_res(request, results):all_texts = ''async for result in results:prompt_ = result.promptanswer_texts = [output.text for output in result.outputs]text = answer_texts[0]if text is None:text = ""all_texts += textret = {"generated_text": all_texts,}yield (json.dumps(ret, ensure_ascii=False) + '\n').encode("utf-8")async def get_full_res_sse(request, results):all_texts = ''async for result in results:answer_texts = [output.text for output in result.outputs]text = answer_texts[0]if text is None:text = ""all_texts += textret = {"event": "message", "retry": 30000, "generated_text": all_texts}yield json.dumps(ret, ensure_ascii=False)async def get_stream_res(request, results):all_texts = ''index = 0async for result in results:prompt_ = result.promptanswer_texts = [output.text for output in result.outputs]text = answer_texts[0]if text is None:text = ""else:index += 1all_texts += textret = {"token": {"text": text,"index": index},}print(ret, index)yield ("data:" + json.dumps(ret, ensure_ascii=False) + '\n').encode("utf-8")print(all_texts)return_full_text = request.parameters.return_full_textif return_full_text:ret = {"generated_text": all_texts,}yield ("data:" + json.dumps(ret, ensure_ascii=False) + '\n').encode("utf-8")async def get_stream_res_sse(request, results):all_texts = ""index = 0async for result in results:answer_texts = [output.text for output in result.outputs]text = answer_texts[0]if text is None:text = ""else:index += 1all_texts += textret = {"event": "message", "retry": 30000, "data": text}yield json.dumps(ret, ensure_ascii=False)print(all_texts)if request.parameters.return_full_text:ret = {"event": "message", "retry": 30000, "data": all_texts}yield json.dumps(ret, ensure_ascii=False)def send_request(request: ClientRequest):print('request: ', request)request_id = str(uuid.uuid1())if request.parameters is None:request.parameters = Parameters()if request.parameters.do_sample is None:request.parameters.do_sample = Falseif request.parameters.top_k is None:request.parameters.top_k = 3if request.parameters.top_p is None:request.parameters.top_p = 1.0if request.parameters.temperature is None:request.parameters.temperature = 1.0if request.parameters.repetition_penalty is None:request.parameters.repetition_penalty = 1.0if request.parameters.max_new_tokens is None:request.parameters.max_new_tokens = 300if request.parameters.return_protocol is None:request.parameters.return_protocol = "sse"if request.parameters.top_k < 0:request.parameters.top_k = 0if request.parameters.top_p < 0.01:request.parameters.top_p = 0.01if request.parameters.top_p > 1.0:request.parameters.top_p = 1.0params = {"prompt": request.inputs,"do_sample": request.parameters.do_sample,"top_k": request.parameters.top_k,"top_p": request.parameters.top_p,"temperature": request.parameters.temperature,"repetition_penalty": request.parameters.repetition_penalty,"max_token_len": request.parameters.max_new_tokens}print('generate_answer...')global llm_serverresults = llm_server.generate_answer(request_id, **params)return results@app.post("/models/llama2")
async def async_generator(request: ClientRequest):results = send_request(request)if request.stream:if request.parameters.return_protocol == "sse":print('get_stream_res_sse...')return EventSourceResponse(get_stream_res_sse(request, results),media_type="text/event-stream",ping_message_factory=lambda: ServerSentEvent(**{"comment": "You can't see this ping"}),ping=600)else:print('get_stream_res...')return StreamingResponse(get_stream_res(request, results))else:print('get_full_res...')return StreamingResponse(get_full_res(request, results))@app.post("/models/llama2/generate")
async def async_full_generator(request: ClientRequest):results = send_request(request)print('get_full_res...')return StreamingResponse(get_full_res(request, results))@app.post("/models/llama2/generate_stream")
async def async_stream_generator(request: ClientRequest):results = send_request(request)if request.parameters.return_protocol == "sse":print('get_stream_res_sse...')return EventSourceResponse(get_stream_res_sse(request, results),media_type="text/event-stream",ping_message_factory=lambda: ServerSentEvent(**{"comment": "You can't see this ping"}),ping=600)else:print('get_stream_res...')return StreamingResponse(get_stream_res(request, results))def update_internlm_request(request: ClientRequest):if request.inputs:request.inputs = "<s><|User|>:{}<eoh>\n<|Bot|>:".format(request.inputs)@app.post("/models/internlm")
async def async_internlm_generator(request: ClientRequest):# update_internlm_request(request)return await async_generator(request)@app.post("/models/internlm/generate")
async def async_internlm_full_generator(request: ClientRequest):# update_internlm_request(request)return await async_full_generator(request)@app.post("/models/internlm/generate_stream")
async def async_internlm_stream_generator(request: ClientRequest):# update_internlm_request(request)return await async_stream_generator(request)def init_server_app():global llm_serverllm_server = LLMServer()print('init server app finish')async def warmup(request: ClientRequest):request.parameters = Parameters(max_new_tokens=3)results = send_request(request)print('warmup get_stream_res...')async for item in get_stream_res(request, results):print(item)def warmup_llama2():request = ClientRequest(inputs="test")asyncio.run(warmup(request))print('warmup llama2 finish')def warmup_internlm():request = ClientRequest(inputs="test")update_internlm_request(request)asyncio.run(warmup(request))print('warmup internlm finish')def run_server_app():print('server port is: ', SERVER_APP_PORT)uvicorn.run(app, host=SERVER_APP_HOST, port=SERVER_APP_PORT)WARMUP_MODEL_MAP = {"llama": warmup_llama2,"internlm": warmup_internlm,
}def warmup_model(model_name):model_prefix = model_name.split('_')[0]if model_prefix in WARMUP_MODEL_MAP.keys():func = WARMUP_MODEL_MAP[model_prefix]warmup_process = Process(target=func)warmup_process.start()warmup_process.join()print("mindspore serving is started.")else:print("model not support warmup : ", model_name)async def _get_batch_size():global llm_serverbatch_size = llm_server.get_bs_current()ret = {'event': "message", "retry": 30000, "data": batch_size}yield json.dumps(ret, ensure_ascii=False)async def _get_request_numbers():global llm_serverqueue_size = llm_server.get_queue_current()ret = {'event': "message", "retry": 30000, "data": queue_size}yield json.dumps(ret, ensure_ascii=False)@app.get("/serving/get_bs")
async def get_batch_size():return EventSourceResponse(_get_batch_size(),media_type="text/event-stream",ping_message_factory=lambda: ServerSentEvent(**{"comment": "You can't see this ping"}),ping=600)@app.get("/serving/get_request_numbers")
async def get_request_numbers():return EventSourceResponse(_get_request_numbers(),media_type="text/event-stream",ping_message_factory=lambda: ServerSentEvent(**{"comment": "You can't see this ping"}),ping=600)def sig_term_handler(signal, frame):print("catch SIGTERM")global llm_serverllm_server.stop()print("----serving exit----")sys.exit(0)if __name__ == "__main__":signal.signal(signal.SIGTERM, sig_term_handler)init_server_app()# warmup_model(ModelName)run_server_app()
相关文章:

MindSpore Serving基于昇腾910B实现大模型部署
一、Why MindSpore Serving 大模型时代,作为一个开发人员更多的是关注一个大模型如何训练好、如何调整模型参数、如何才能得到一个更高的模型精度。而作为一个整体项目,只有项目落地才能有其真正的价值。那么如何才能够使得大模型实现落地?如…...
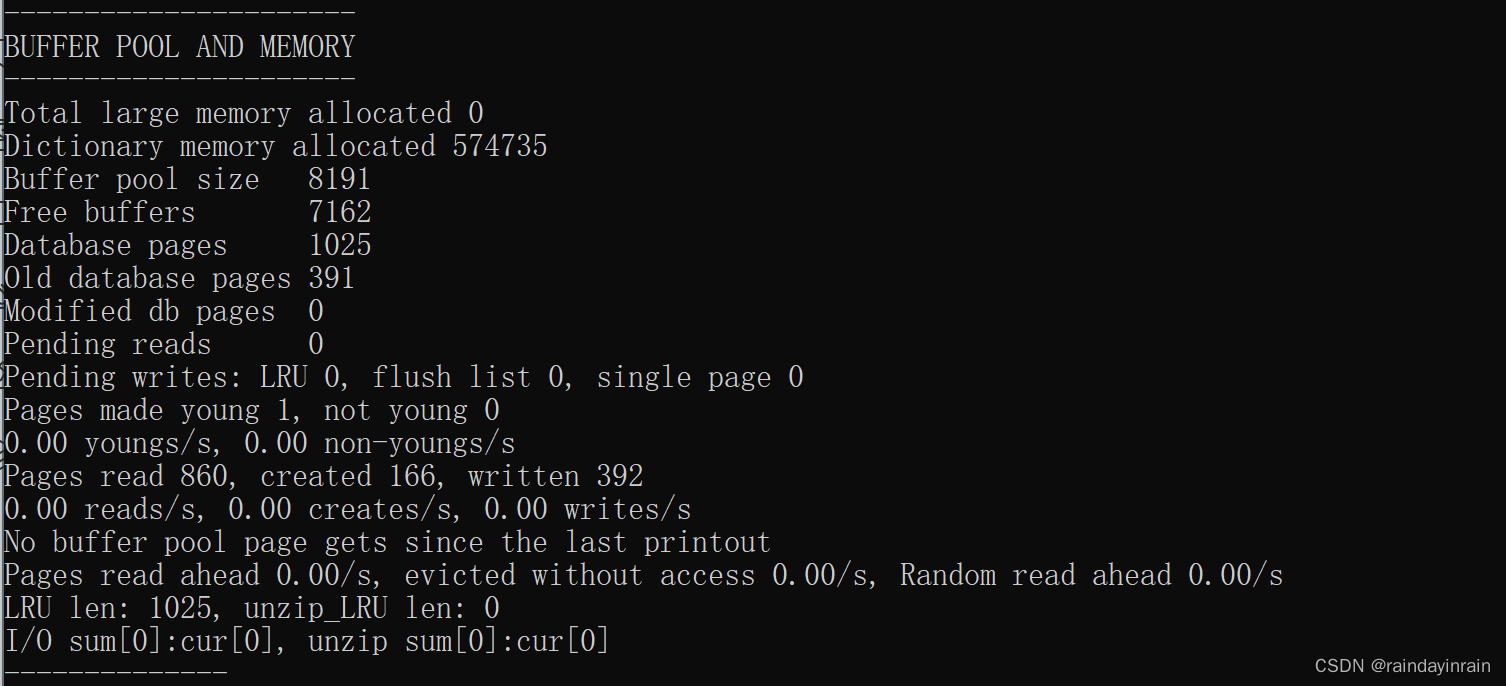
mysql原理--InnoDB的Buffer Pool
1.缓存的重要性 对于使用 InnoDB 作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以 页 的形式存放在 表空间 中的,而所谓的 表空间 只不过是 InnoDB 对…...
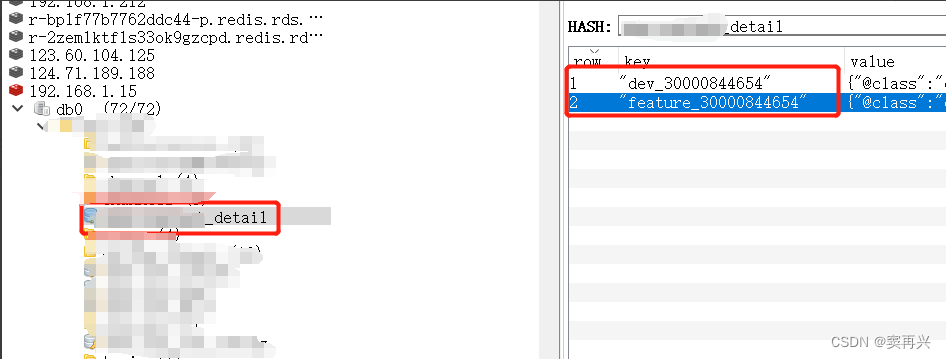
Redis不同环境缓存同一条数据,数据内部值不同
背景 现实中,本地环境(dev)和开发环境(feature)会共同使用相同的中间件(本篇拿Redis举例),对于不同环境中的,图片、视频、语音等资源类型的预览地址url,需要配…...
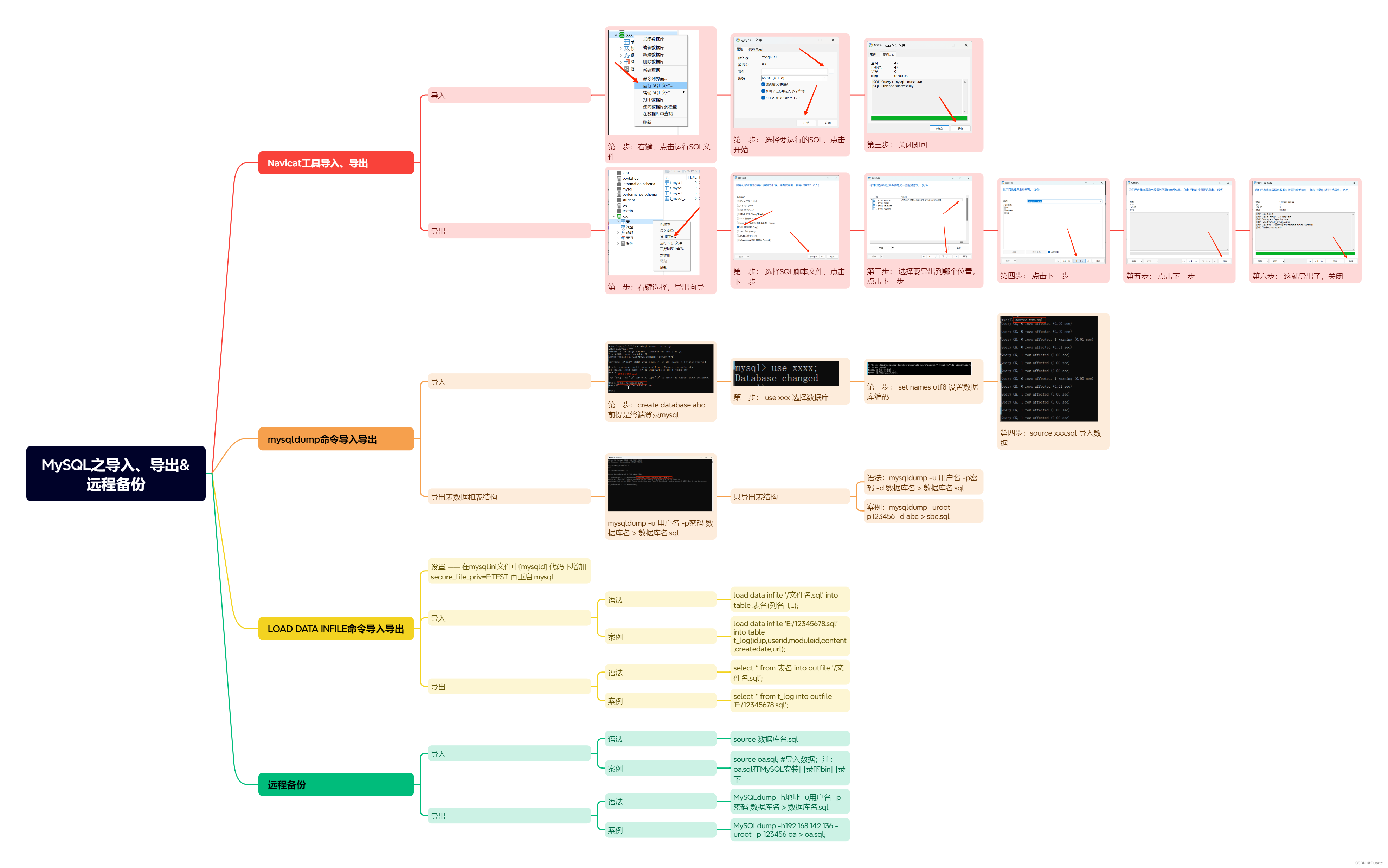
MySQL之导入、导出远程备份
一、Navicat工具导入、导出 1.1 导入 第一步: 右键,点击运行SQL文件 第二步: 选择要运行的SQL,点击开始 第三步: 关闭即可 1.2 导出 第一步: 右键选择,导出向导 第二步: 选择SQL脚…...
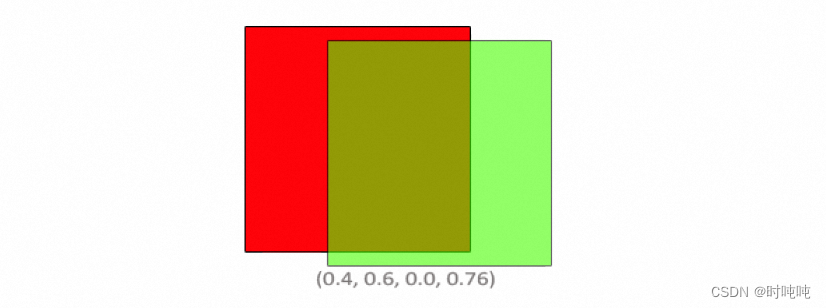
OpenGL学习笔记-Blending
混合方程中,Csource是片段着色器输出的颜色向量(the color output of the fragment shader),其权重为Fsource。Cdestination是当前存储在color buffer中的颜色向量(the color vector that is currently stored in the …...
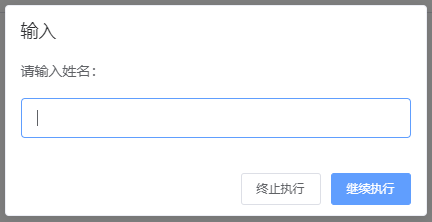
支持 input 函数的在线 python 运行环境 - 基于队列
支持 input 函数的在线 python 运行环境 - 基于队列 思路两次用户输入三次用户输入 实现前端使用 vue element uiWindows 环境的执行器子进程需要执行的代码 代码仓库参考 本文提供了一种方式来实现支持 input 函数,即支持用户输的在线 python 运行环境。效果如下图…...

欧拉Euler release 21.10 (LTS-SP2)升级openssh至9版本记录
背景:安扫漏洞,需要对openssh经行升级 1.先查看升级前的openssh版本 2.避免升级失败断开远程登录,先开启telnt服务用于远程连接(这步可查看其他博客) 3.从欧拉官网下载rpm包,https://www.openeuler.org/zh…...
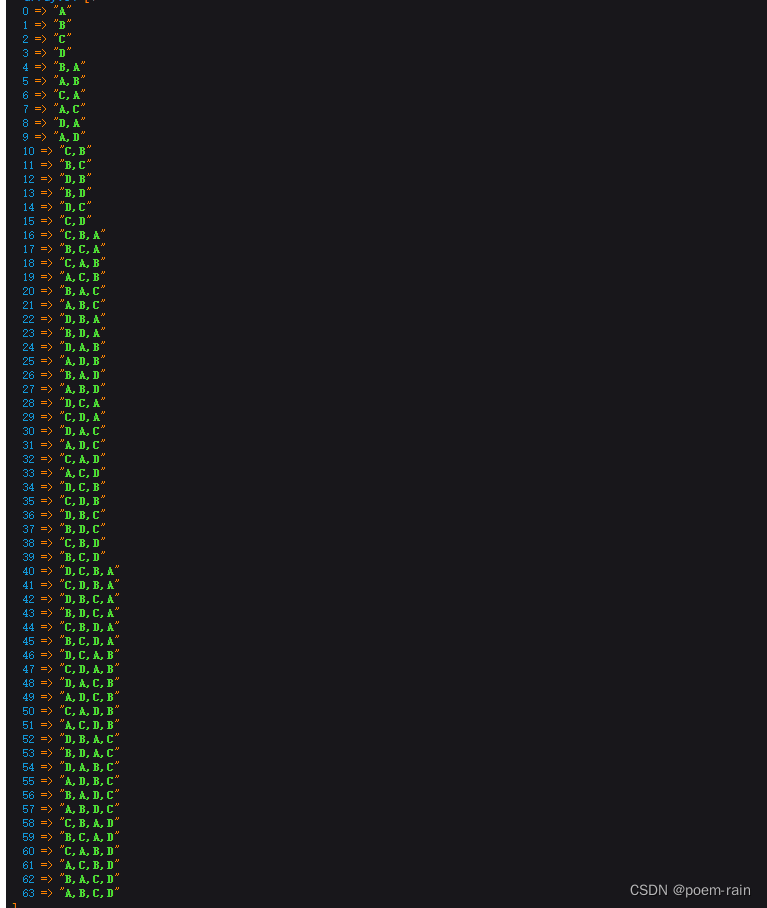
php 数组中的元素进行排列组合
需求背景:计算出数组[A,B,C,D]各种排列组合,希望得到的是数据如下图 直接上代码: private function finish_combination($array, &$groupResult [], $splite ,){$result [];$finish_result [];$this->diffArrayItems($array, $…...
Python从入门到网络爬虫(OS模块详解)
前言 本章介绍python自带模块os,os为操作系统 operating system 的简写,意为python与电脑的交互。os 模块提供了非常丰富的方法用来处理文件和目录。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面页可以极大增强…...

人机交互不是人机融合智能
一、人机交互和人机融合智能是两个不同的概念 人机交互是指人类与计算机之间的信息交流和操作方式,包括输入和输出界面、交互技术、用户体验等方面。人机交互的目标是提供用户友好的界面和自然的交互方式,使人类能够与计算机更加高效地进行沟通和协作。 …...

RabbitMQ解决消息丢失以及重复消费问题
文章目录 1、概念2、基于ACK/NACK机制2.1 基于Spring AMQP框架整合ACK/NACK机制2.2 测试消费失败1.02.3 测试结果1.02.4 测试MQ宕机2.5 测试结果2.0 3、RabbitMQ 如何实现幂等性设计3.1 幂等服务设计思路3.1.1 通过雪花算法生成分布式唯一ID3.1.2 通过枚举类,设计Me…...

docker 安装redis集群
一、准备6台机器 二、6台机器分别拉取镜像: docker pull redis三、6台机器分别建立挂载文件夹 mkdir -p /home/redis/data四、6台机器分别执行容器操作 docker run --restartalways -d --name redis-node-1 --net host --privilegedtrue -v /home/redis/data:/da…...

锂电池制造设备中分布式IO模块优势
在“碳达峰、碳中和”目标推动下,新能源汽车当下发展势头正盛,而纯电动车的核心部件则是:锂电池。动力型锂电池作为新能源汽车核心零部件,其发展与新能源汽车行业息息相关,迎来广阔的市场空间。 为何采用I/O模块&#…...

Android Room数据库升级Migration解决方案
一、介绍 Android Room 是 Android 官方提供的一个轻量级数据库框架,用于在 Android 应用程序中管理数据持久性。它简化了数据库访问,提供了更安全、更快速的数据存储方式,并使得数据操作更加便捷。 二、Room的特点(八股文可以参考) 以下是…...

离线安装docker和docker-compose
1.下载 docker Index of linux/static/stable/x86_64/ docker-compose Overview of installing Docker Compose | Docker Docs 2.docker /etc/systemd/system/docker.service [Unit] DescriptionDocker Application Container Engine Documentationhttps://docs.docker.…...

奇怪的事情记录:外置网卡和外置显示器不兼容
身为程序员,不应该对世界上的稀奇古怪的事情感到惊讶(毕竟,大部分都是程序员自己搞出来的)。 外置网卡和外置显示器不兼容 mbp2019intel版,win10,外接有线网卡,平时用得很好,接上外…...
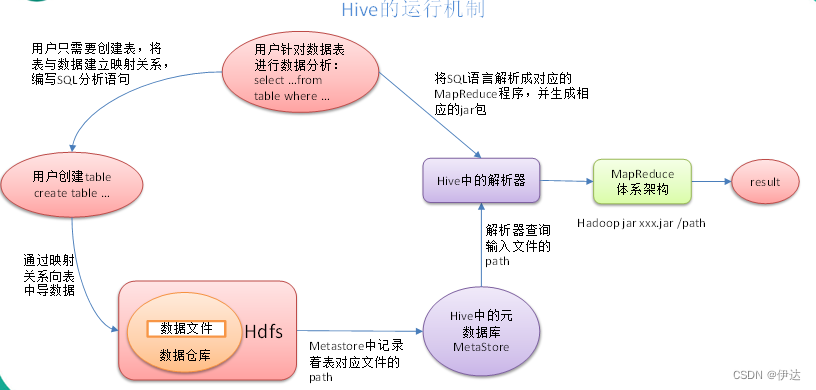
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录 1、什么是Hive 2、Hive的优缺点 2.1、 优点 2.2、 缺点 2.2.1、Hive的HQL表达能力有限 2.2.2、Hive的效率比较低 3、Hive架构原理 3.1、用户接口:Client 3.2、元数据:Metastore 3.3、Hadoop 3.4、驱动器:Driver Hive运行机制…...

第三代量子计算机交付,中国芯片开辟新道路,光刻机难挡中国芯
日前安徽本源量子宣布第三代超导量子计算系统正式上线,这是中国最先进的量子计算机,计算量子比特已达到72个,在全球已居于较为领先的水平,这对于中国芯片在原来的硅基芯片受到光刻机阻碍无疑是巨大的鼓舞。 据悉本源量子的第一代、…...
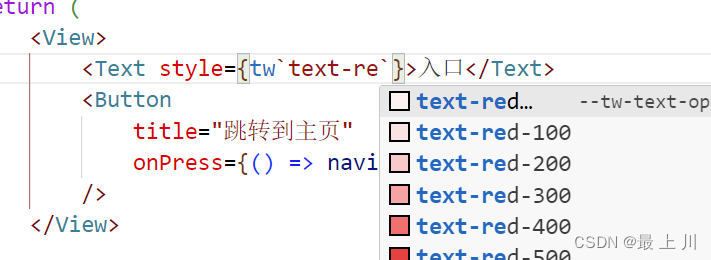
react native中使用tailwind并配置自动补全
使用的第三方库是tailwind-react-native-classnames,同类的也有tailwind-rn,但是我更喜欢前者官方demo: import { View, Text } from react-native; import tw from twrnc;const MyComponent () > (<View style{twp-4 android:pt-2 b…...
数据分析——火车信息
任务目标 任务 1、整理火车发车信息数据,结果的表格形式为: 2、并输出最终的发车信息表 难点 1、多文件 一个文件夹,多个月的发车信息,一个excel,放一天的发车情况 2、数据表的格式特殊 如何分析表是一个难点 数…...

保姆级教程:STM32F407驱动AD9926并行ADC,从硬件连线到DMA数据搬运全流程
STM32F407实战:AD9926并行ADC驱动与DMA高效数据采集全解析 在工业自动化与精密测量领域,高速数据采集系统的设计一直是嵌入式开发的难点之一。AD9926作为一款12位并行输出ADC芯片,配合STM32F407强大的DCMI接口和DMA控制器,能够构…...

终极指南:如何用3步清理Windows右键菜单,让电脑操作效率翻倍
终极指南:如何用3步清理Windows右键菜单,让电脑操作效率翻倍 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾被Windows右键菜单的…...

【灶台导航】 RAG系统的容错设计:从向量搜索到关键词降级,一个都不能少
当三个外部依赖都可能随时挂掉时,如何保证用户永远有响应?问题:完美主义害死人 做RAG系统时,我们很容易陷入一种思维定势:向量检索要准、LLM要强、整个链路要丝滑。但现实是——任何一个外部服务挂了,用户就…...

DOM Node:深入解析与高效使用
DOM Node:深入解析与高效使用 引言 DOM(Document Object Model)是现代网页开发的核心技术之一,它允许开发者以程序化的方式操作HTML文档。DOM Node是DOM的核心概念之一,理解并熟练使用DOM Node对于提高网页开发效率至关重要。本文将深入解析DOM Node的概念、类型、属性和…...

“为什么我的NotebookLM Agent总在胡说?”——20年NLP老兵手把手调试LLM引用可信度的5个黄金检查点
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Agent研究辅助 核心能力与适用场景 NotebookLM Agent 是 Google 推出的基于私有文档理解的 AI 助手,专为研究者设计。它支持上传 PDF、TXT、Markdown 等格式的研究资料…...

Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门
更多请点击: https://intelliparadigm.com 第一章:Starter计划配额耗尽预警失效?我们逆向解析其API响应头,发现3个未文档化的速率控制暗门 在对 Starter 计划的 API 调用行为进行深度监控时,我们观察到配额耗尽告警频…...
)
保姆级教程:用MNN在Android上部署你的第一个图像分类App(从模型转换到实时摄像头识别)
从零构建Android端智能图像分类应用:MNN实战全流程解析 在移动互联网时代,将AI能力嵌入移动端应用已成为提升用户体验的关键。想象一下这样的场景:用户打开手机就能实时识别植物种类、辨别商品真伪,或是自动分类相册中的照片——这…...

管 Vibe Coding 项目,就像管公共厕所
本文整理自"AI炼金术"播客对徐文浩的访谈,探讨 AI 辅助编程(Vibe Coding)在组织落地后面临的治理挑战和应对策略。从"屎山三年一遇"到"屎山月月有"传统软件开发中,一个系统的"屎山化"通常…...

12-分布式系统测试-缓存-注册中心与链路追踪验证
分布式系统测试:缓存、注册中心与链路追踪验证上篇咱们搞定了消息队列测试,今天继续深入分布式系统的其他组件——Redis缓存、服务注册中心、分布式链路追踪。这些"基础设施"的测试往往被忽略,但出了问题定位起来最头疼。一、Redis…...

API淘宝关键词搜索:运用场所、使用方式及获客逻辑
在电商生态中,淘宝关键词搜索API是连接第三方系统与平台商品数据的核心桥梁。其核心价值在于通过标准化接口,精准、合规地获取关键词对应的商品、店铺及市场数据,为各类业务提供坚实的数据支撑。相较于传统爬虫,API调用具备合规性…...