为什么分库分表
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、什么是分库分表
- 二、分库分表的原因
- 分库
- 分表
- 三、如何分库分表
- 3.1 垂直拆分
- 1.垂直分库
- 2、垂直分表
- 3.2 水平拆分
- 水平分库
- 水平分表
- 水平分库分表的策略
- hash取模算法
- range范围
- range+hash取模混合
- 地理位置分片
- 预定义算法
- 四、分库分表的问题
- 分页、排序、跨节点联合查询
- 事务一致性
- 全局唯一的主键
- 多数据库高效治理
- 历史数据迁移
- 参考
前言
想要开发一个基于 HashMap 核心设计原理,使用哈希散列+扰动函数的方式,把数据散列到多个库表中的组件,并验证使用。这里是分库分表的基础知识
一、什么是分库分表
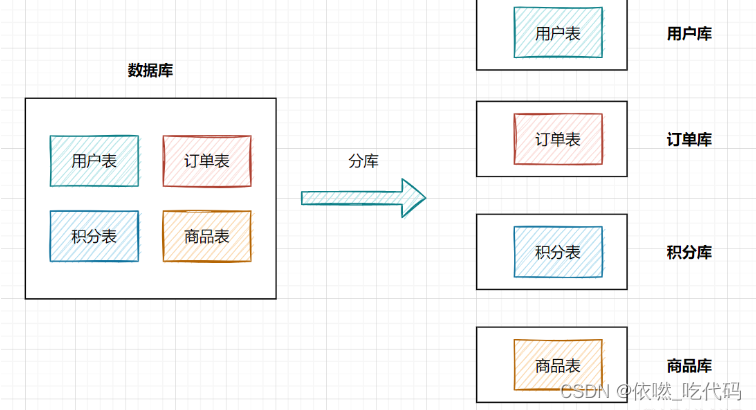
分库:就是一个数据库分成多个数据库,部署到不同机器。
分表:就是一个数据库表分成多个表。
二、分库分表的原因
分库
如果业务量剧增,数据库可能会出现性能瓶颈,这时候我们就需要考虑拆分数据库。从这几方面来看:
- 磁盘存储
业务量剧增,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
- 并发连接支撑
我们知道数据库连接是有限的。在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!当前非常火的微服务架构出现,就是为了应对高并发。它把订单、用户、商品等不同模块,拆分成多个应用,并且把单个数据库也拆分成多个不同功能模块的数据库(订单库、用户库、商品库),以分担读写压力。
分表
数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量的表可能会拖垮这个数据库。
即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
- 一棵高度为2的B+树,能存放
1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,大概可以存放两千万左右的记录。B+树高度一般为1-3层,如果B+到了4层,查询的时候会多查磁盘的次数,SQL就会变慢。
因此单表数据量超过千万,就需要考虑分表啦。 是否分库分表的关键指标是数据量
三、如何分库分表
分库分表的核心就是对数据的分片(Sharding)并相对均匀的路由在不同的库、表中,以及分片后对数据的快速定位与检索结果的整合。

首先我们要知道为什么要用分库分表,其实就是由于业务体量较大,数据增长较快,所以需要把用户数据拆分到不同的库表中去,减轻数据库压力。
分库分表操作主要有垂直拆分和水平拆分:
垂直拆分:指按照业务将表进行分类,分布到不同的数据库上,这样也就将数据的压力分担到不同的库上面。最终一个数据库由很多表的构成,每个表对应着不同的业务,也就是专库专用。
水平拆分:如果垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。如:user_001、user_002
3.1 垂直拆分
1.垂直分库

但是随着业务蒸蒸日上,系统功能逐渐完善。这时候,可以按照系统中的不同业务进行拆分,比如拆分成用户库、订单库、积分库、商品库,把它们部署在不同的数据库服务器,这就是垂直分库。
垂直分库把一个库的压力分摊到多个库,提升了一些数据库性能,但并没有解决由于单表数据量过大导致的性能问题,所以就需要配合后边的分表来解决。
2、垂直分表
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select *的话,还占用IO资源。这时候,我们可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。
比如一张用户表,它包含user_id、user_name、mobile_no、age、email、nickname、address、user_desc,如果email、address、user_desc等字段不常用,我们可以把它拆分到另外一张表,命名为用户详细信息表。这就是垂直分表

3.2 水平拆分
当我们的应用已经无法在细粒度的垂直切分时,依旧存在单库读写、存储性能瓶颈,这时就要配合水平分库、水平分表一起了。
水平分库
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。
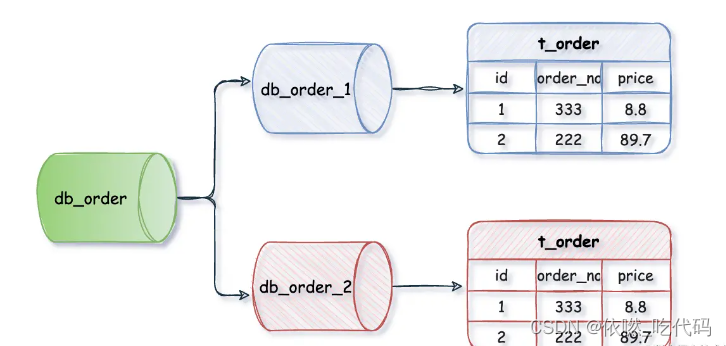
例如:db_orde_1、db_order_2两个数据库内有完全相同的t_order表,我们在访问某一笔订单时可以通过对订单的订单编号取模的方式 订单编号 mod 2 (数据库实例数) ,指定该订单应该在哪个数据库中操作。
这种方案往往能解决单库存储量及性能瓶颈问题,但由于同一个表被分配在不同的数据库中,数据的访问需要额外的路由工作,因此系统的复杂度也被提升了。
水平分表
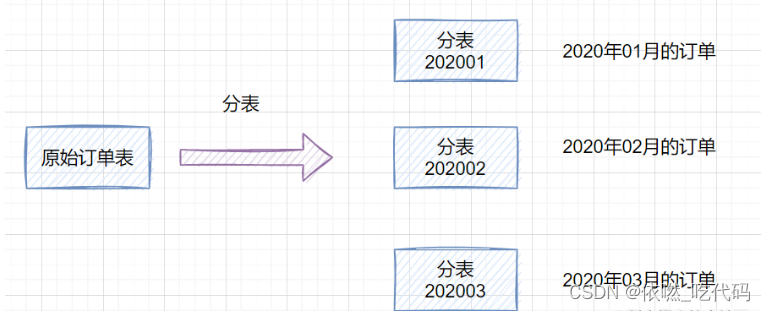
水平分表是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
例如:一张t_order订单表有900万数据,经过水平拆分出来三个表,t_order_1、t_order_2、t_order_3,每张表存有数据300万,以此类推。

水平分库分表的策略
如果一个表的数据量太大,可以按照某种规则(如hash取模、range),把数据切分到多张表去。
其实这个规则它是一种路由算法,决定了一条数据具体应该存在哪个数据库的哪张表里。
常见的有 取模算法 、范围限定算法、范围+取模算法 、预定义算法
hash取模算法
hash取模策略:指定的路由key(一般是user_id、订单id作为key)对分表总数进行取模,把数据分散到各个表中。

- 比如id=1,对4取模,就会得到1,就把它放到第1张表,即
t_order_0; - id=3,对4取模,就会得到3,就把它放到第3张表,即
t_order_2;
这种方案的优点:
hash取模的方式,不会存在明显的热点问题。
缺点:
如果一开始按照hash取模分成4个表了,未来某个时候,表数据量又到瓶颈了,需要扩容,这就比较棘手了。比如你从4张表,又扩容成8张表,那之前id=5的数据是在(5%4=1,即第一张表),现在应该放到(5%8=5,即第5张表),也就是说历史数据要做迁移了。
range范围
range,即范围策略划分表。比如我们可以将表的主键,按照从01000万的划分为一个表,10002000万划分到另外一个表。如下图:
这种方案的优点:
这种方案有利于扩容,不需要数据迁移。假设数据量增加到5千万,我们只需要水平增加一张表就好啦,之前0~4000万的数据,不需要迁移。
缺点:
这种方案会有热点问题,因为订单id是一直在增大的,也就是说最近一段时间都是汇聚在一张表里面的。比如最近一个月的订单都在1000万~2000万之间,平时用户一般都查最近一个月的订单比较多,请求都打到order_1表啦,这就导致表的数据热点问题。
range+hash取模混合
既然range存在热点数据问题,hash取模扩容迁移数据比较困难,我们可以综合两种方案一起嘛,取之之长,弃之之短。
比较简单的做法就是,在拆分库的时候,我们可以先用range范围方案,比如订单id在04000万的区间,划分为订单库1,id在4000万8000万的数据,划分到订单库2,将来要扩容时,id在8000万~1.2亿的数据,划分到订单库3。然后订单库内,再用hash取模的策略,把不同订单划分到不同的表。

地理位置分片
地理位置分片其实是一个更大的范围,按城市或者地域划分,比如华东、华北数据放在不同的分片库、表。
预定义算法
预定义算法是事先已经明确知道分库和分表的数量,可以直接将某类数据路由到指定库或表中,查询的时候亦是如此。
四、分库分表的问题
分页、排序、跨节点联合查询
分页、排序、联合查询,这些看似普通,开发中使用频率较高的操作,在分库分表后却是让人非常头疼的问题。把分散在不同库中表的数据查询出来,再将所有结果进行汇总合并整理后提供给用户。
比如:我们要查询11、12月的订单数据,如果两个月的数据是分散到了不同的数据库实例,则要查询两个数据库相关的数据,在对数据合并排序、分页,过程繁琐复杂。
- 方案1:在个节点查到对应结果后,在代码端汇聚再分页。
- 方案2:把分页交给前端,前端传来pageSize和pageNo,在各个数据库节点都执行分页,然后汇聚总数量前端。这样缺点就是会造成空查,如果分页需要排序,也不好搞。
- 排序问题:
跨节点的count,order by,group by以及聚合函数等问题:可以分别在各个节点上得到结果后在应用程序端进行合并。
事务一致性
分库分表后由于表分布在不同库中,不可避免会带来跨库事务问题。后续会分别以阿里的Seata和MySQL的XA协议实现分布式事务,用来比较各自的优势与不足。
全局唯一的主键
分库分表后数据库表的主键ID业务意义就不大了,因为无法在标识唯一一条记录,例如:多张表t_order_1、t_order_2的主键ID全部从1开始会重复,此时我们需要主动为一条记录分配一个ID,这个全局唯一的ID就叫分布式ID,发放这个ID的系统通常被叫发号器。
- 分布式ID
数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID,或者使用雪花算法生成分布式ID。
多数据库高效治理
对多个数据库以及库内大量分片表的高效治理,是非常有必要,因为像某宝这种大厂一次大促下来,订单表可能会被拆分成成千上万个t_order_n表,如果没有高效的管理方案,手动建表、排查问题是一件很恐怖的事。
历史数据迁移
分库分表架构落地以后,首要的问题就是如何平滑的迁移历史数据,增量数据和全量数据迁移,
排序问题
参考
https://juejin.cn/post/7085132195190276109#heading-15
https://juejin.cn/post/7155784807702593572#heading-39
相关文章:
为什么分库分表
系列文章目录 文章目录系列文章目录前言一、什么是分库分表二、分库分表的原因分库分表三、如何分库分表3.1 垂直拆分1.垂直分库2、垂直分表3.2 水平拆分水平分库水平分表水平分库分表的策略hash取模算法range范围rangehash取模混合地理位置分片预定义算法四、分库分表的问题分…...

1625_MIT 6.828 stabs文档信息整理_下
全部学习汇总: GreyZhang/g_unix: some basic learning about unix operating system. (github.com) 继续之前的学习笔记,整理一下最近看过的一点stabs资料。 这一页中有一半的信息是Fortran专用的,直接跳过。参数的符号修饰符是p,…...
论文阅读 | Rethinking Coarse-to-Fine Approach in Single Image Deblurring
前言:ICCV2021图像单帧运动去糊论文 论文地址:【here】 代码地址:【here】 Rethinking Coarse-to-Fine Approach in Single Image Deblurring 引言 图像去糊来自与物体或相机的运动。现有的deblur领域的深度学习方法大多都是coarse-to-fin…...

Mysql 增删改查(二)—— 增(insert)、删(delete)、改(update)
目录 一、插入 1、insert 2、replace(插入否则更新) 二、更新(update) 三、删除 1、delete 2、truncate(截断表,慎用) 一、插入 1、insert (1) 单行 / 多行插入 全列插入:…...

JSD2212复习串讲
1. Java语言基础阶段 这一部分主要是练,给一些题目还有讲解一些最基础的语法,做一些额外的补充 1.1 基本概念 1.2 变量 1.2.1 数据类型 4类8种 基本类型:整形、浮点型、字符型、布尔型 整形:byte -》short-》int-》long 浮点…...

sphinx 升级到6.x后的Jquery问题
sphinx 升级到6.0 后,以前对于jquery的默认引用方式发生了改变以前在编译后的html中jquery是如下引用的:<script src"_static/jquery.js"></script>而升级到6.0后,对于jquery 是一个googleapi的远程jquery调用…...

NSSCTF Round#8 Basic
from:http://v2ish1yan.top MyDoor 使用php伪协议读取index.php的代码 php://filter/readconvert.base64-encode/resourceindex.php<?php error_reporting(0);if (isset($_GET[N_S.S])) {eval($_GET[N_S.S]); }if(!isset($_GET[file])) {header(Location:/index.php?fi…...

多传感器融合定位十二-基于图优化的建图方法其一
多传感器融合定位十二-基于图优化的建图方法其一1. 基于预积分的融合方案流程1.1 优化问题分析1.2 预积分的作用1.3 基于预积分的建图方案流程2. 预积分模型设计3. 预积分在优化中的使用3.1 使用方法3.2 残差设计3.3 残差雅可比的推导3.3.1 姿态残差的雅可比3.3.2 速度残差的雅…...

RockChip MPP编码
概述瑞芯微提供的媒体处理软件平台(Media Process Platform,简称 MPP)是适用于瑞芯微芯片系列的通用媒体处理软件平台。该平台对应用软件屏蔽了芯片相关的复杂底层处理,其目的是为了屏蔽不同芯片的差异,为使用者提供统…...

【学习笔记】NOIP暴零赛2
细思极恐,我的能力已经退步到这个地步了吗? 数据结构 这题的修改是强行加进去迷惑你的。 考虑怎么求树的带权重心。 完了我只会树形dp 完了完了 结论:设uuu的子树和为szusz_uszu,所有点权值和为sss,那么树的带…...

linux基本功系列之hostname实战
文章目录前言一. hostname命令介绍二. 语法格式及常用选项三. 参考案例3.1 显示本机的主机名3.2 临时修改主机名3.3 显示短格式的主机名3.4 显示主机的ip地址四. 永久修改主机名4.1 centos6 修改主机名的方式4.2 centos7中修改主机名永久生效总结前言 大家好,又见面…...
Easy-Es框架实践测试整理 基于ElasticSearch的ORM框架
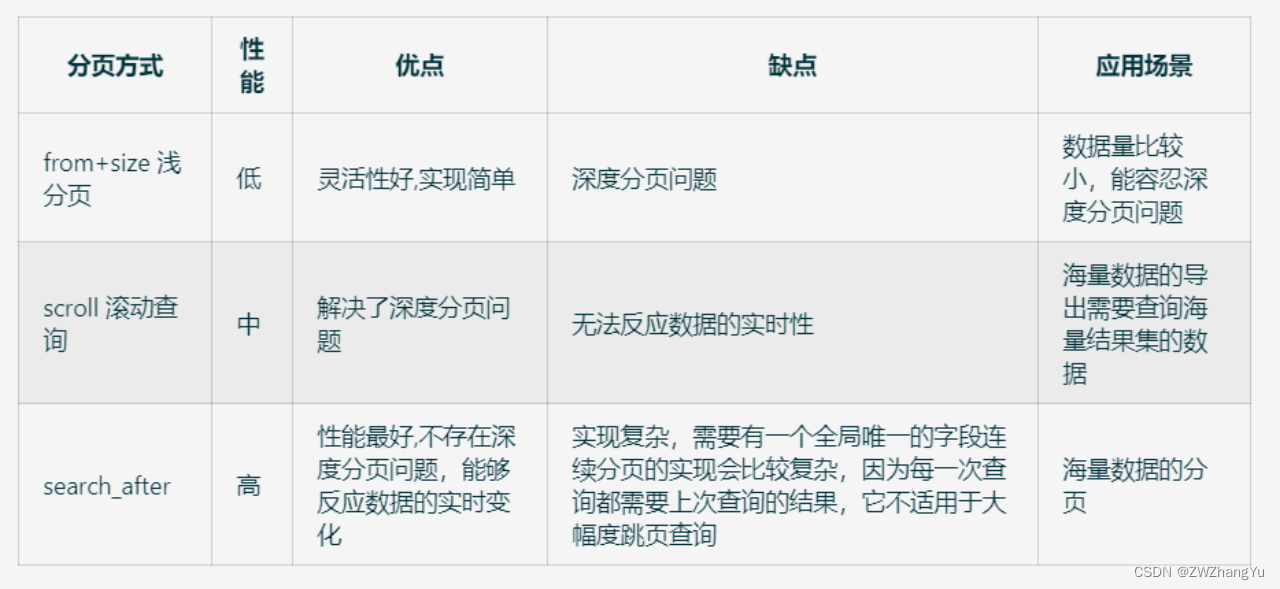
文章目录介绍(1)Elasticsearch java 客户端种类(2)优势和特性分析(3)性能、安全、拓展、社区(2)ES版本及SpringBoot版本说明索引处理(一)索引别名策略&#x…...
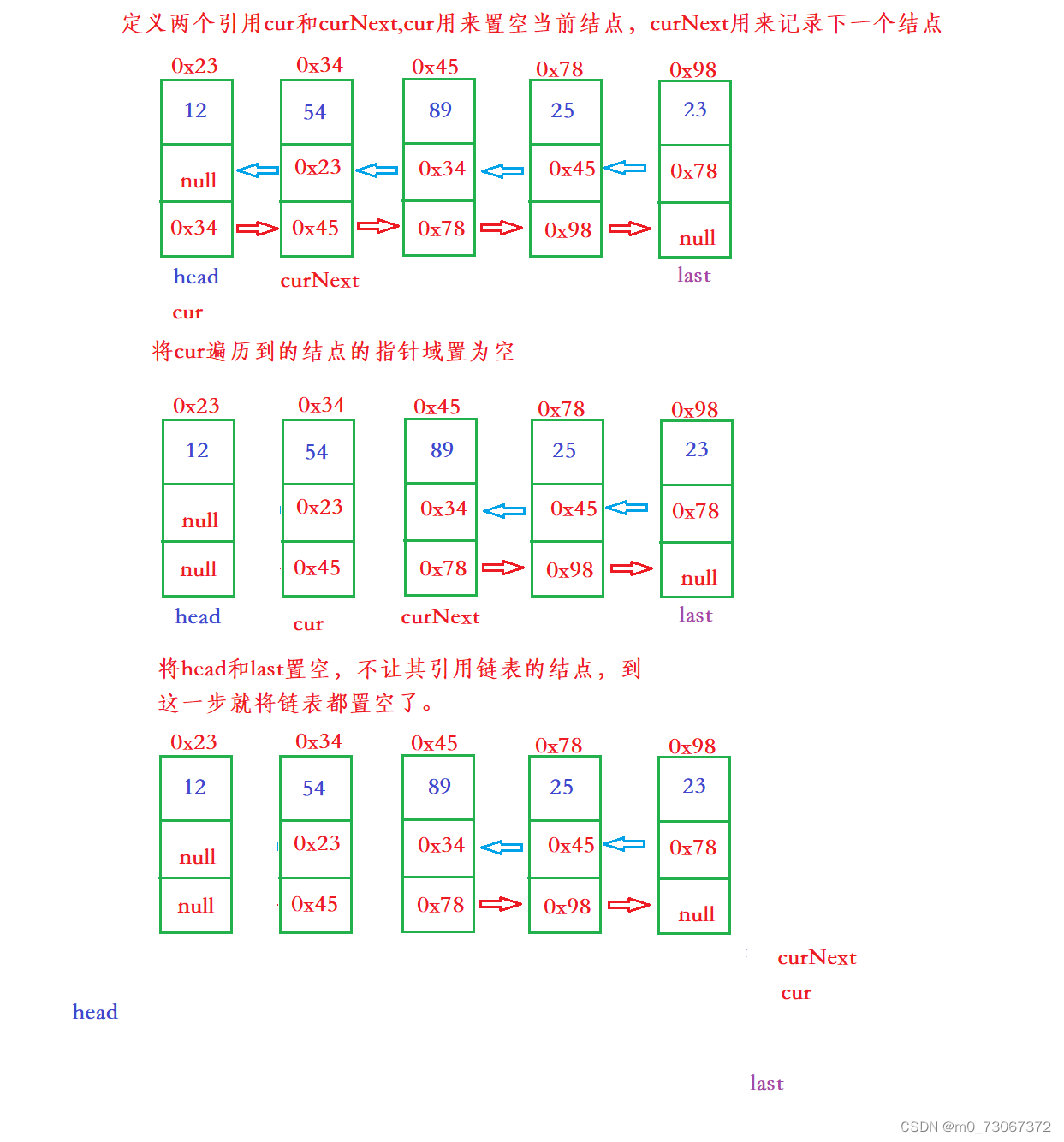
【数据结构】双向链表的模拟实现(无头)
目录 前言: 1、认识双向链表中的结点 2、认识并创建无头双向链表 3、实现双向链表当中的一些方法 3.1、遍历输出方法(display) 3.2、得到链表的长度(size) 3.3、查找关键字key是否包含在双链表中(contains) 3.…...

vue自定义指令---处理加载图片失败时出现的碎图,onerror事件
目录 一、自定义指令 1、局部注册和使用 2、全局注册和使用 二、自定义指令处理图片加载失败(碎图) 一、自定义指令 vue中除v-model、v-show等内置指令之外,还允许注册自定义指令,获取DOM元素,扩展额外的功能。 1、局…...

加盟管理系统挑选法则,看完不怕被坑!
经营服装连锁店铺究竟有多难?小编已经不止一次听到身边的老板,抱怨加盟连锁店铺难以管理了,但同时呢,也听到了很多作为加盟商的老板,抱怨总部给的支持和管理不到位。服装加盟店铺管理,到底有哪些难点呢&…...

alertmanager笔记
1 prometheus的思想 所有告警都应该立刻处理掉,不应该存在长时间未解决的告警。所以具体的表现就是高频的数据采集,和告警的自动恢复(默认5分钟) 2 alertmanager API调用 使用如下命令即可手工制造告警,注意startsA…...
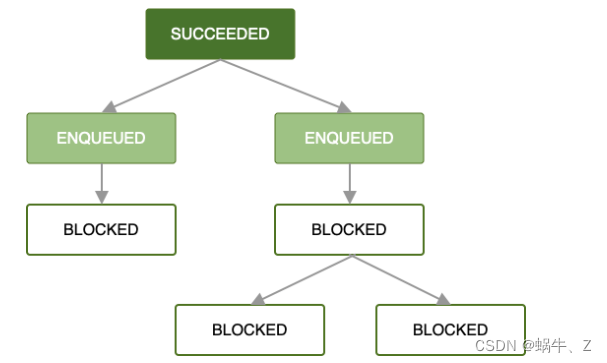
Android Jetpack组件之WorkManager后台任务管理的介绍与使用(二)
一、介绍 通过上一篇文,Android Jetpack组件之WorkManager后台任务管理的介绍与使用(一)_蜗牛、Z的博客-CSDN博客 我们可以弄清楚workmanager从接入到使用的基本流程。基本可以满足我们日常。那只是简单的入门。如果遇到更复杂的功能,那简单的就无法满…...

【MySQL】第十七部分 约束
【MySQL】第十七部分 约束 文章目录【MySQL】第十七部分 约束17. 约束17.1 约束的分类17.2 非空约束17.3 唯一性约束17.4 主键约束17.5 自增列约束17.6 外键约束17.7 默认约束17.8 check约束总结17. 约束 约束: 可以在创建表的时候规定约束,也可以在表创建之后添加,约束顾名思…...
java ssm集装箱码头TOS系统调度模块的设计与实现
由于历史和经济体制的原因,国内码头物流企业依然保持大而全的经营模式。企业自己建码头、场地、经营集装箱运输车辆。不过近几年来随着经济改革的进一步深入和竞争的激烈,一些大型的码头物流企业逐步打破以前的经营模式,其中最明显的特征就是…...

MS14-064(OLE远程代码执行漏洞复现)
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :内网安全-漏洞复现 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台…...

基于Terraform与Ansible的OpenClaw私有化AI代理自动化部署实践
1. 项目概述如果你和我一样,对AI助手的能力有更高的期待,希望它能深度融入你的工作流,甚至能帮你处理一些自动化任务,那么OpenClaw这个项目绝对值得你花时间研究。它不是一个简单的聊天机器人,而是一个可以部署在你私有…...

从原理到实战:阻容降压电路的设计要点与避坑指南
1. 阻容降压电路基础认知 第一次接触阻容降压电路是在五年前的一个智能插座项目上,当时为了把220V交流电转换成5V直流给单片机供电,团队在开关电源和阻容降压方案之间犹豫了很久。最终因为成本控制选择了后者,这个决定让我深刻体会到了阻容降…...

独立开发者如何借助多模型选型能力为产品选择最佳AI引擎
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助多模型选型能力为产品选择最佳AI引擎 对于独立开发者而言,为产品选择一个合适的AI模型引擎是一项关…...

从人工到有机:数字健康AI的范式转变与工程实践
1. 从“人工”到“有机”:一次关于智能本质的范式转变在数字健康领域,我们每天都在与“人工智能”打交道。从辅助医生阅片的影像分析系统,到预测患者风险的算法模型,AI似乎已经成为推动医疗革新的核心引擎。然而,当我们…...

【Claude Code 源码解析教程】第33章:性能调优实战
本章深入解析 Claude Code 的性能优化策略,包括内存优化、响应速度优化、缓存策略和并发处理。性能优化是提升用户体验的关键。 目录 33.1 内存优化策略 33.1.1 慢操作监控 33.1.2 慢操作检测使用示例 33.1.3 内存管理策略 33.1.4 内存泄漏检测与修复 33.2 响应速度优化…...

软件工程自动化浪潮下,工程师如何从代码生产者转型为系统架构师?
1. 软件工程的自动化浪潮:从手工艺到基础设施的必然之路最近和几个在头部大厂干了十几年的老同事聊天,话题总绕不开一个词:焦虑。不是对业务增长的焦虑,而是对自身角色价值的焦虑。一个在阿里做P8的朋友说,他团队里新来…...

芯片行业变革:开源硬件、可重构芯片与商业模式创新
1. 行业拐点:传统芯片商业模式为何难以为继?干了十几年芯片设计,从流片工程师到项目负责人,我亲眼见证了行业从“黄金时代”到如今“卷成本、卷工艺”的艰难转型。最近和几个老同事聊天,大家不约而同地提到一个词&…...

基于MCP协议与本地全文检索的电子元件文档AI查询系统
1. 项目概述:为LLM构建一个本地化的电子元件文档搜索引擎如果你是一名嵌入式工程师、硬件开发者,或者像我一样,经常需要和德州仪器(TI)、意法半导体(ST)、亚德诺(ADI)这些…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

免费开源桌面分区工具:如何用NoFences在5分钟内整理好你的Windows桌面
免费开源桌面分区工具:如何用NoFences在5分钟内整理好你的Windows桌面 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都要面对杂乱无章的Windows桌面&…...