其他排序(基数排序,希尔排序和桶排序)(数据结构课设篇3,python版)(排序综合)
本篇博客主要详细讲解一下其他排序(基数排序,希尔排序和桶排序)也是排序综合系列里最后一篇博客。第一篇博客讲解的是LowB三人组(冒泡排序,插入排序,选择排序)(数据结构课设篇1,python版)(排序综合),第二篇博客讲解的是NB三人组(堆排序,归并排序,快速排序)(数据结构课设篇2,python版)(排序综合)。
random和time库的用法在第一篇冒泡排序里讲解过。数据结构课设实验内容和要求也在第一篇博客中。
基数排序:
概念:
基数排序是一种非比较型的排序算法,它根据数字的位数进行排序。它首先按照个位数进行排序,然后按照十位数进行排序,以此类推,直到最高位数。基数排序适用于整数或字符串的排序。假设待排序的数据有 n 个,每个数据的位数为 d,数据的范围为 k,那么基数排序的时间复杂度可以表示为 O(d*(n+k))。基数排序的基本思想是:
- 根据个位数进行排序,将数据分配到0-9的桶中。
- 按照顺序将桶中的数据合并起来。
- 根据十位数进行排序,再次将数据分配到0-9的桶中。
- 按照顺序将桶中的数据合并起来。 依次类推,直到最高位排序完成。
如图:

代码及详细注释:
import random
import time
def radix_sort(li):max_num = max(li) # 找到列表中的最大值it = 0 # 初始化迭代次数while 10 ** it <= max_num: # 循环直到最高位buckets = [[] for _ in range(10)] # 定义十个空桶for val in li:digit = (val // 10 ** it) % 10 # 取val的第it位数字(个位、十位、百位等)buckets[digit].append(val) # 将val放入对应的桶中# 分桶完成li.clear()for buc in buckets: # 将桶中的元素按顺序合并为一个列表li.extend(buc)# 把数重新写回liit += 1 # 迭代次数加1li = [random.randint(1, 100000000) for i in range(10000)]
print(li)
start = time.time()
radix_sort(li)
end = time.time()
print(li)
print('运行时间:%s Seconds'%(end-start))
基数排序的思想和代码都比较好理解,详细过程注释中都有说明。
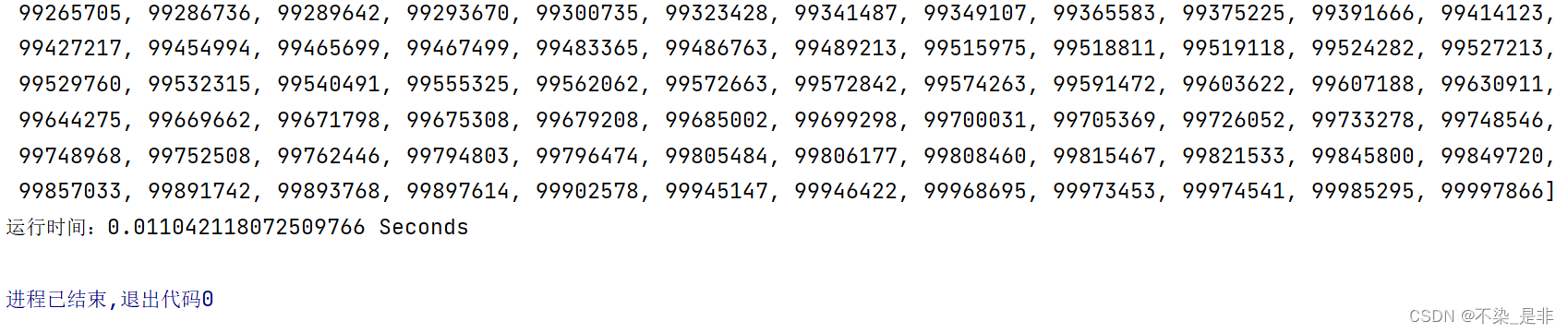
运行结果:
希尔排序:
概念:
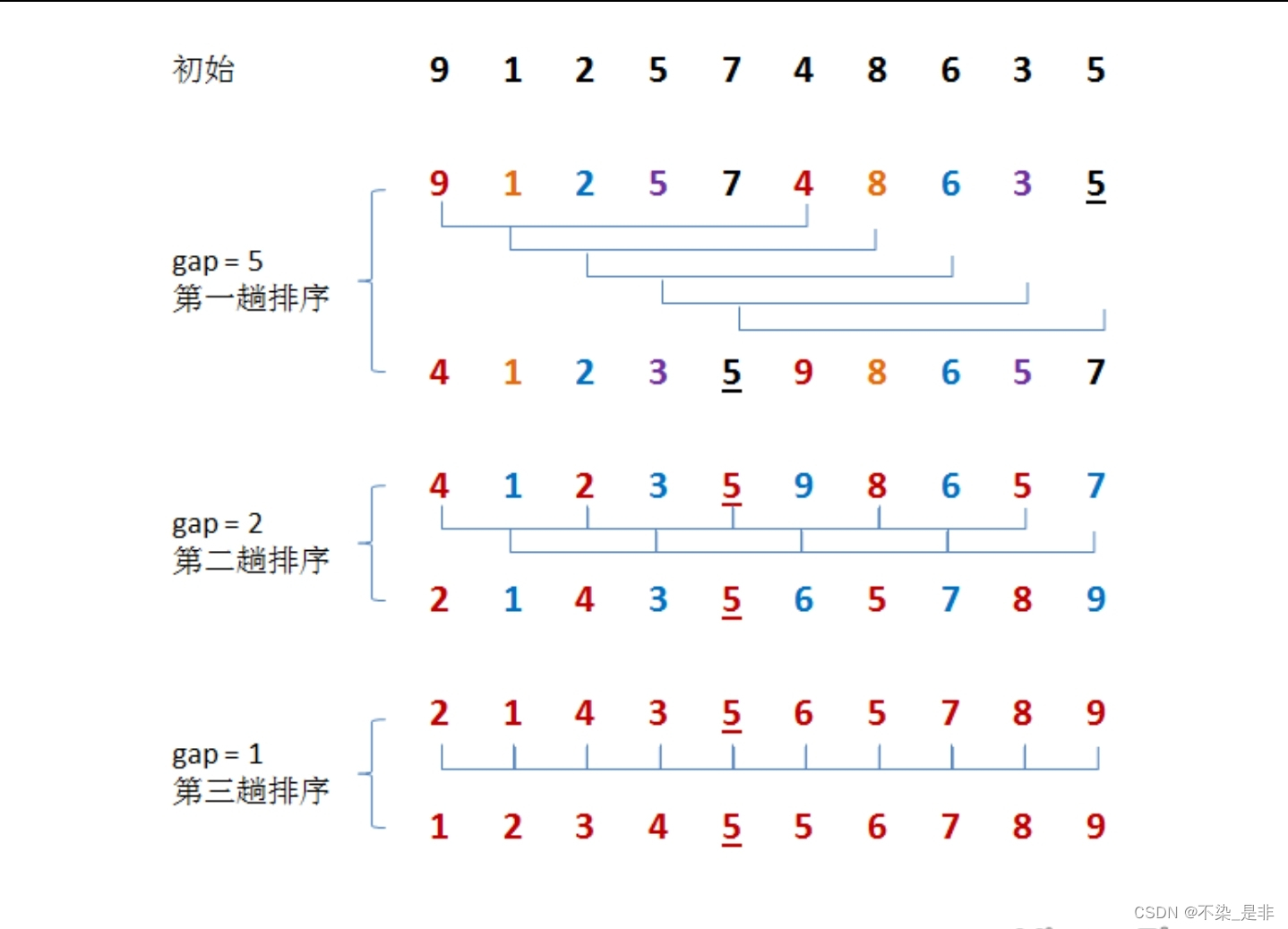
希尔排序是一种插入排序的改进版本,它通过将待排序的数据分成若干个小组,分别进行插入排序,然后逐渐减少小组的数量和增加小组内元素的间隔,直到最后一次将整个数据序列作为一个小组进行插入排序。希尔排序的时间复杂度在O(nlogn)和O(n^2)之间。希尔排序的基本思想是:
- 首先,选择一个增量序列,例如n/2、n/4、n/8等,将待排序的数据分成若干个小组。
- 然后,对每个小组内的数据进行插入排序。
- 接着,逐渐减少增量,重复上述步骤,直到增量为1,最后进行一次插入排序。
如图:
代码及详细注释:
import random
import time
def insert_sort_gap(li, gap):for i in range(gap, len(li)): # 从第gap个元素开始,依次向前进行插入排序j = i - gap # j指向当前元素的前一个元素tmp = li[i] # 记录当前元素的值while j >= 0 and li[j] > tmp: # 如果前面的元素比当前元素大li[j + gap] = li[j] # 将前面的元素后移gap位j -= gap # 继续向前寻找插入位置li[j + gap] = tmp # 插入当前元素到正确的位置
def shell_sort(li):d = len(li) // 2 # 初始步长取数组长度的一半while d >= 1:insert_sort_gap(li, d) # 对每个步长进行插入排序d //= 2 # 步长减半li = [random.randint(1, 100000000) for i in range(100000)]
print(li)
start = time.time()
shell_sort(li)
end = time.time()
print(li)
print('运行时间:%s Seconds'%(end-start))
希尔排序的思路和代码也是比较好理解和实现的,注释里讲解的还是比较详细的。
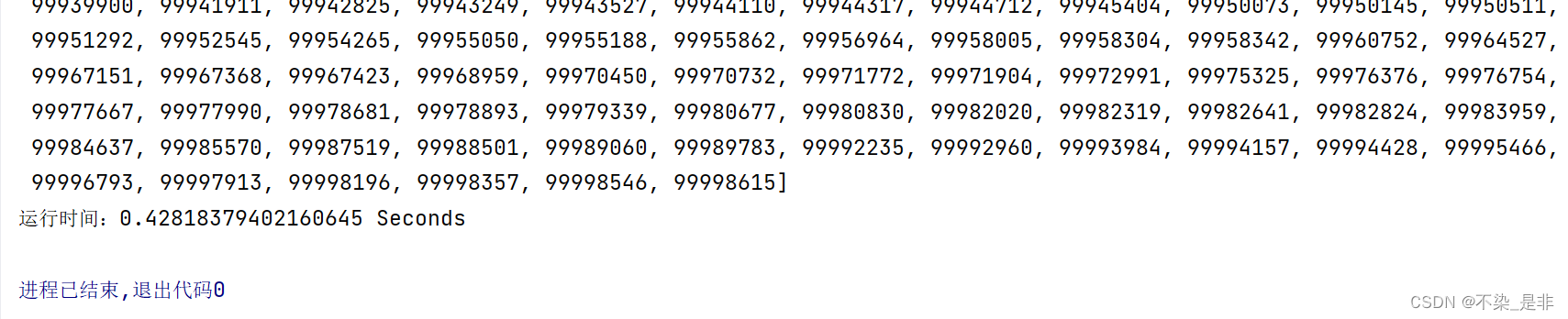
运行结果:
桶排序:
概念:
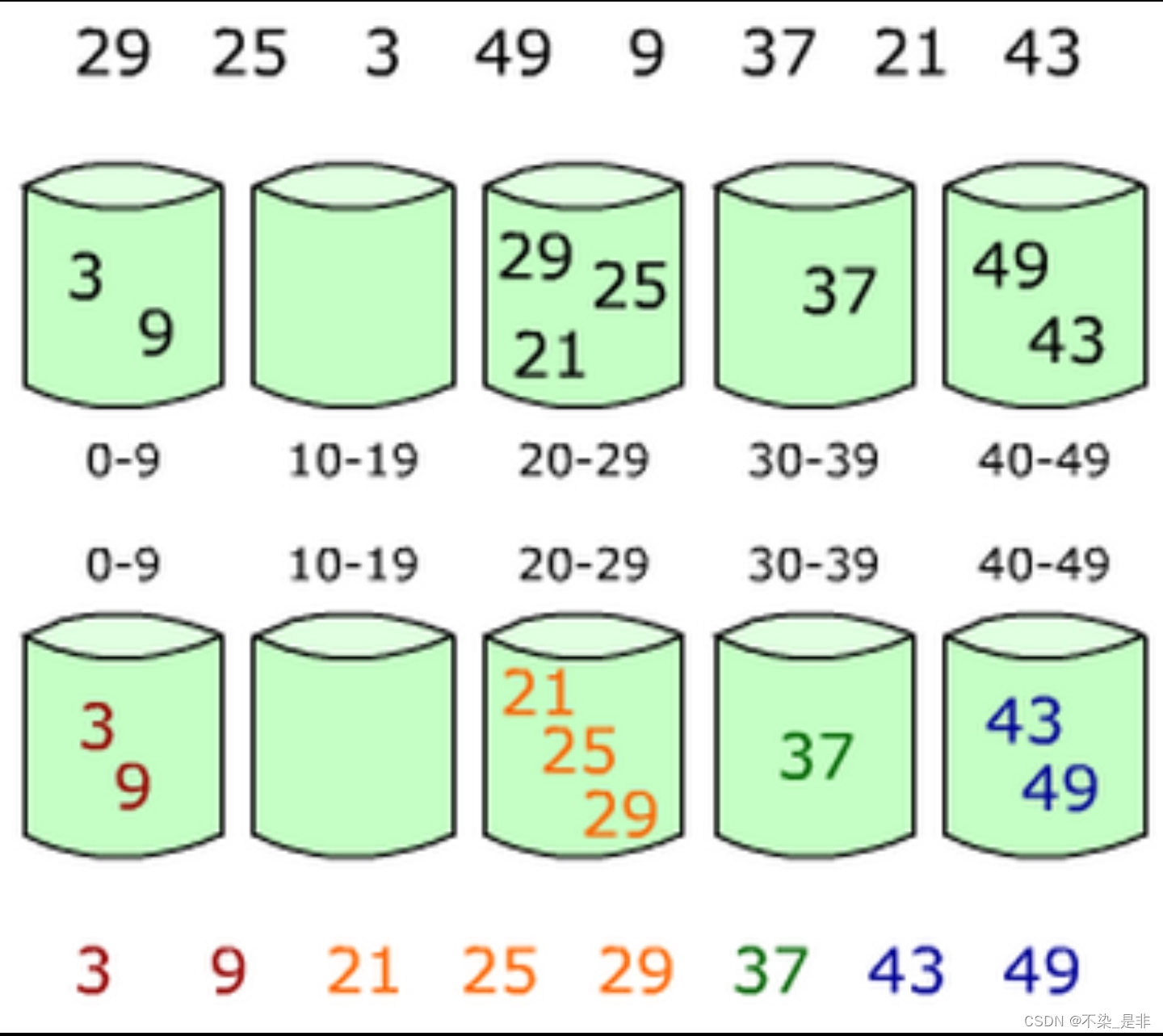
桶排序是一种排序算法,它将待排序的数据分成若干个桶,然后对每个桶内的数据进行排序,最后将所有桶内的数据按照顺序合并起来。桶排序适用于待排序的数据分布比较均匀的情况下。
桶排序的时间复杂度取决于使用的排序算法和桶的数量。在最理想的情况下,桶排序的时间复杂度为O(n+k),其中n是待排序元素的数量,k是桶的数量。这是因为在最理想的情况下,每个桶中的元素都是均匀分布的,因此每个桶内的排序所需的时间是O(1)。然而,在最坏的情况下,所有元素都被放入同一个桶中,此时桶排序的时间复杂度将变为O(nlogn),这是因为在这种情况下需要使用其他的排序算法对桶内的元素进行排序。
桶排序的基本思想是:
- 首先,确定桶的数量,并将待排序的数据分配到对应的桶中。
- 然后,对每个桶内的数据进行排序,可以使用任何一种排序算法,通常使用插入排序或者快速排序。
- 最后,按照桶的顺序将所有桶内的数据合并起来。
如图:
代码及详细注释:
import random
import time
def bucket_sort(li, n=100, max_num=10000):buckets = [[] for _ in range(n)] # 创建n个空桶for val in li:i = min(val // (max_num // n), n - 1) # 计算val应该放到哪个桶里buckets[i].append(val) # 将val加入对应的桶中# 保持桶内的顺序for j in range(len(buckets[i]) - 1, 0, -1): # 对桶内元素进行排序if buckets[i][j] < buckets[i][j - 1]: # 如果当前元素比前一个元素小buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j] # 交换两个元素的位置else:break # 如果当前元素大于等于前一个元素,则停止排序sorted_li = []for buc in buckets: # 将所有桶中的元素按顺序合并为一个列表sorted_li.extend(buc)return sorted_li # 返回排序后的列表li = [random.randint(1, 100000000) for i in range(10000)]
print(li)
start = time.time()
bucket_sort(li)
end = time.time()
print(li)
print('运行时间:%s Seconds'%(end-start))
运行结果:
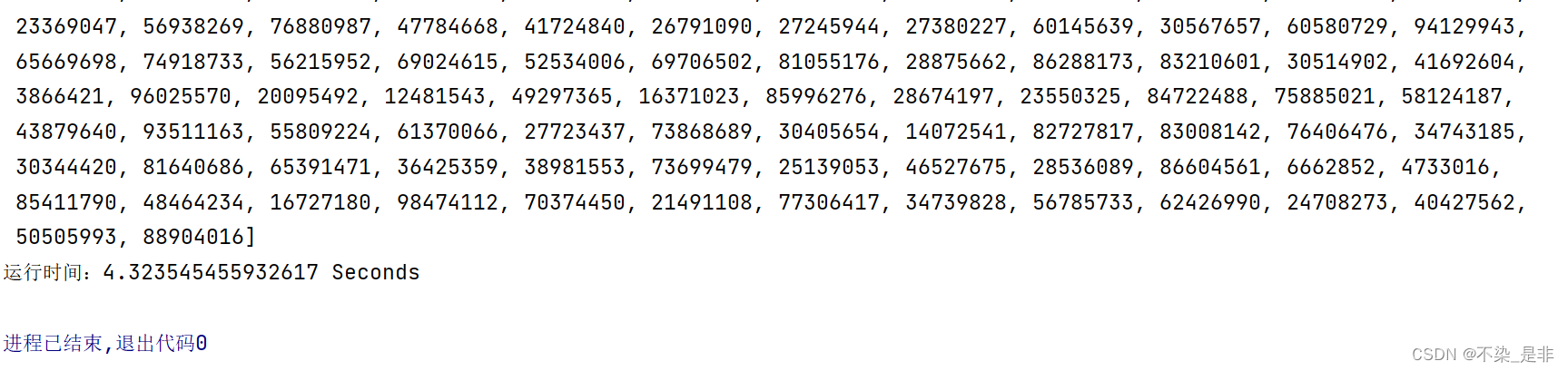
总结:
至此排序综合系列讲解完毕,排序综合1讲解了LowB三人组(冒泡排序,插入排序,选择排序)(数据结构课设篇1,python版)(排序综合),排序综合2讲解了NB三人组(堆排序,归并排序,快速排序)(数据结构课设篇2,python版)(排序综合)。这些也是数据结构的课设之一,大家可以借鉴参考一下。总体来说排序的思路和代码还是相对与其他算法好理解和实现的
在这里我也给大家对所有讲过的排序进行一个运行效率上的比较(不是通过时间复杂度而是通过运行结果),在此之前每个排序我都对好几组不同内容和不同规模大小的数组进行排序运行,最后得出的结果是:桶排序和冒泡排序最慢,其次是插入排序和选择排序,再次是希尔排序,最后是基数排序,堆排序,归并排序和快速排序(其中基数排序在大规模运算下效率高,运行时间最短)如有不对,欢迎指正。
相关文章:
其他排序(基数排序,希尔排序和桶排序)(数据结构课设篇3,python版)(排序综合)
本篇博客主要详细讲解一下其他排序(基数排序,希尔排序和桶排序)也是排序综合系列里最后一篇博客。第一篇博客讲解的是LowB三人组(冒泡排序,插入排序,选择排序)(数据结构课设篇1&…...

【复现】DiffTalk
code:GitHub - sstzal/DiffTalk: [CVPR2023] The implementation for "DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation" 问题1. ERROR: Failed building wheel for pysptk Cython.Compiler.Errors.CompileError:…...

SQLServer 系统概述
目录 1.SQL语言的发展和特点 2.SQL语言的特点 1.SQL语言的发展和特点 SQL是利用一些简单的语句构成的基本语法,来存储数据库的内容。目前已经成为关系型数据库系统中使用最广泛的语言。 1974年SQL语言由Boyce和Chamberlin提出来。 1975~1979年研制了著名的关系数…...

Vue3 + TS + Element-Plus —— 项目系统中封装表格+搜索表单 十分钟写五个UI不在是问题
前期回顾 纯前端 —— 200行JS代码、实现导出Excel、支持DIY样式,纵横合并-CSDN博客https://blog.csdn.net/m0_57904695/article/details/135537511?spm1001.2014.3001.5501 目录 一、🛠️ newTable.vue 封装Table 二、🚩 newForm.vue …...

Linux系统——测试端口连通性方法
目录 一、TCP端口连通性测试 1、ssh 2、telnet(可能需要安装) 3、curl 4、tcping(需要安装) 5、nc(需要安装) 6、nmap(需要安装) 二、UDP端口连通性测试 1、nc(…...

Python虚拟环境轻松配置:Jupyter Notebook中的内核管理指南
问题 在Python开发中,一些人在服务器上使用Jupyter Notebook中进行开发。一般是创建虚拟环境后,向Jupyter notebook中添加虚拟环境中的Kernel,后续新建Notebook中在该Kernel中进行开发,这里记录一下如何创建Python虚拟环境以及添…...
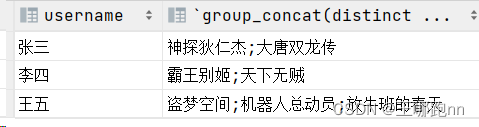
大数据-hive函数与mysql函数的辨析及练习-将多行聚合成一行
目录 1. 🥙collect_list: 聚合-不去重 2. 🥙collect_set(col): 聚合-去重 3. 🥙mysql的聚合函数-group_concat 4. leetcode练习题 1. 🥙collect_list: 聚合-不去重 将组内的元素收集成数组 不会去重 2. 🥙collec…...

【AI视野·今日NLP 自然语言处理论文速览 第七十三期】Tue, 9 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 9 Jan 2024 Totally 80 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Infe…...

vue知识-03
购物车案例 要实现的功能: 1、计算商品总价格 2、全选框和取消全选框 3、商品数量的增加和减少 <body> <div id"app"><div class"row"><div class"col-md-6 col-md-offset-3"><h1 class"text-center…...

关于httpClient 使用的注意事项
关于httpClient 使用的注意事项 用例 PoolingHttpClientConnectionManager connectionManager new PoolingHttpClientConnectionManager();// 最大连接数-不设置默认20connectionManager.setMaxTotal(200);// 每个路由最大连接数-不设置默认2connectionManager.setDefaultMax…...
Docker 发布自定义镜像到公共仓库
Docker 发布自定义镜像到公共仓库 引言 Docker 是一种轻量级、便携式的容器化技术,可以使应用程序在不同环境中更加可移植。在本文中,我们将学习如何使用 Docker 从公共仓库拉取 Nginx 镜像,定制该镜像,添加自定义配置文件&…...

程序员有哪些接单的渠道?
这题我会!程序员接单的渠道那可太多了,想要接到合适的单子,筛选一个合适的平台很重要。如果你也在寻找一个合适的接单渠道,可以参考以下这些方向。 首先,程序员要对接单有一个基本的概念:接单渠道可以先粗略…...
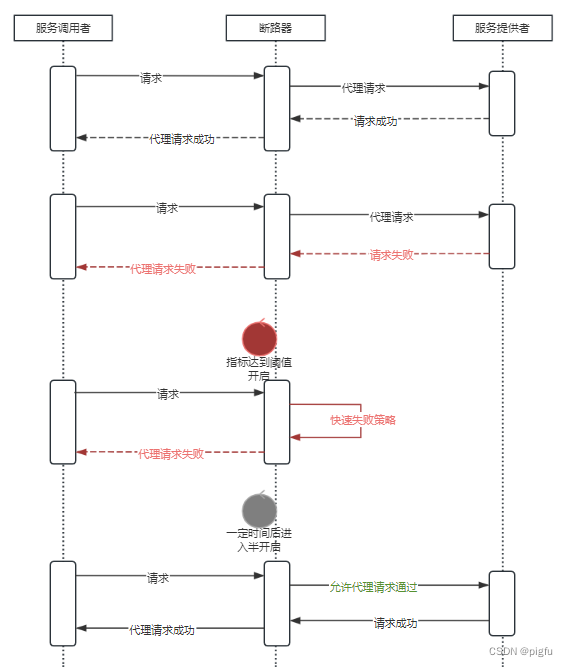
服务容错-熔断策略之断路器hystrix-go
文章目录 概要一、服务熔断二、断路器模式三、hystrix-go3.1、使用3.2、源码 四、参考 概要 微服务先行者Martin Fowler与James Lewis在文章microservices中指出了微服务的九大特征,其中一个便是容错性设计(Design for failure)。正如文章中提到的,微服…...
C++进阶(三)多态
📘北尘_:个人主页 🌎个人专栏:《Linux操作系统》《经典算法试题 》《C》 《数据结构与算法》 ☀️走在路上,不忘来时的初心 文章目录 一、多态的概念1、概念 二、多态的定义及实现1、多态的构成条件2、虚函数3、虚函数的重写4、C…...

大众汽车宣布将ChatGPT,批量集成在多种汽车中!
1月9日,大众汽车在官网宣布,将ChatGPT批量集成到电动、内燃机汽车中。 大众表示,将ChatGPT与其IDA语音助手相结合,用户通过自然语言就能与ChatGPT进行互动,例如,帮我看看最近的三星米其林饭店在哪里&#…...

React----函数组件和类组件
函数组件与类组件:React 中的两种组件风格 React 是一个用于构建用户界面的流行 JavaScript 库,其中组件是构建块的基本单元。在 React 中,有两种主要的组件风格:函数组件和类组件。本文将使用TypeScript介绍它们的用法、区别以及…...
Kafka集群部署 (KRaft模式集群)
KRaft 模式是 Kafka 在 3.0 版本中引入的新模式。KRaft 模式使用了 Raft 共识算法来管理 Kafka 集群元数据。Raft 算法是一种分布式共识算法,具有高可用性、可扩展性和安全性等优势。 在 KRaft 模式下,Kafka 集群中的每个 Broker 都具有和 Zookeeper 类…...

Vue 自定义仿word表单录入之日期输入组件
因项目需要,要实现仿word方式录入数据,要实现鼠标经过时才显示编辑组件,预览及离开后则显示具体的文字。 鼠标经过时显示 正常显示及离开时显示 组件代码 <template ><div class"paper-input flex flex-col border-box "…...

Oracle与Java JDBC数据类型对照
Oracle Database JDBC开发人员指南和参考 SQL Data TypesJDBC Type CodesStandard Java TypesOracle Extension Java Types CHAR java.sql.Types.CHAR java.lang.String oracle.sql.CHAR VARCHAR2 java.sql.Types.VARCHAR java.lang.String oracle.sql.CHAR LONG jav…...

C++力扣题目226--翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]示例 2: 输入:root [2,1,3] 输出:[2,3,1]示例 3&#x…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案
如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载缓慢而烦恼…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤
iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: ht…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

从开源物理拼图游戏学习Unity 2D物理引擎与游戏架构设计
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“openclaw-puzzle-game”。光看名字,你可能会觉得这又是一个普通的开源拼图游戏,但点进去仔细研究后,我发现它的设计思路和实现方式,对于想学习游戏开…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...

数据中心碳足迹与可靠性优化框架解析
1. 数据中心碳足迹与可靠性优化的挑战 现代数据中心已成为数字经济的动力引擎,但伴随算力需求的爆炸式增长,其能源消耗与碳排放问题日益凸显。根据最新统计,全球数据中心年耗电量已达4600亿度,占全球总用电量的2%。随着大语言模型…...

基于Feather微控制器的智能灯光系统:颜色感应与BLE遥控实现
1. 项目概述与核心价值又到了折腾点节日氛围的时候了。往年都是买现成的彩灯串,总觉得少了点意思,今年决定自己动手,做个能“听懂”指令、甚至能“看见”颜色的智能灯光系统。这个项目的核心,就是用一块小小的微控制器,…...