Spark九:Spark调优之Shuffle调优
Spark shuffle调优方法
map端和reduce端缓存大小设置,reduce端重试次数和等待时间间隔,以及bypass设置
学习资料:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ
一、map和reduce端缓冲区大小
1.1 map端
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下。
通过调节map端缓冲的大小,可以避免频繁的磁盘IO操作,进而提升Spark任务的整体性能。
map端缓冲的默认配置是32KB,如果每个task处理640kb数据,那么会发生640/32=20次溢写,如果每个task处理64000KB数据,则发生2000次溢写,这对于性能的影响是非常重要的。
map端缓冲的配置方法
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64")
1.2 reduce端
Spark Shuffle过程中,shuffle reduce task的buffer缓冲区大小决定了reduce task每次能够缓冲的数据量,也就是每次能够拉取的数据量,如果内存资源较为充足,适当增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。
reduce端数据拉去缓冲区的大小可以通过spark.reducer.maxSizeInFlight设置,默认为48M,设置方法:
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "96")
二、reduce端重试次数和等待时间间隔
2.1 重试次数
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试。对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
reduce端拉取数据重试次数可以通过spark.shuffle.io.maxRetries参数设置,该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败,默认为3,该参数的设置方法如下:
val conf = new SparkConf().set("spark.shuffle.io.maxRetries", "6")
2.2 增大等待时间间隔
Spark Shuffle过程中,reduce task拉取属于自己的数据时,如果因为网络异常等原因导致失败会自动进行重试,在一次失败后,会等待一定的时间间隔再进行重试,可以通过加大间隔时长(比如60s),以增加shuffle操作的稳定性。
reduce端拉取数据等待间隔可以通过spark.shuffle.io.retryWait参数进行设置,默认值为5s,该参数的设置方法如下:
val conf = new SparkConf().set("spark.shuffle.io.retryWait", "60s")
三、bypass机制开启阈值
对于SortShuffleManager,如果shuffle reduce task的数量小于某一阈值,则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
当使用SortShuffleManager且不需要排序操作,建议将SortShuffleManager参数调大,大于shuffle read task的数量,那么此时map-side就不会进行排序了,减少了排序的性能开销,但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
可以通过spark.shuffle.sort.bypassMergeThreshold这个参数设置,默认200。
val conf = new SparkConf().set("spark.shuffle.sort.bypassMergeThreshold", "400")
相关文章:

Spark九:Spark调优之Shuffle调优
Spark shuffle调优方法 map端和reduce端缓存大小设置,reduce端重试次数和等待时间间隔,以及bypass设置 学习资料:https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ 一、map和reduce端缓冲区大小 1.1 map端 在Spark任务运行过程中&…...

linux c多线程优先级
在 Linux 系统中,可以使用 pthread_setschedparam 函数来设置线程的优先级。该函数需要传入一个指向 pthread_t 类型的线程 ID,以及一个指向 struct sched_param 类型的结构体对象。struct sched_param 结构体包含了线程的优先级信息。 下面是一个示例代…...

Redis在项目开发中的应用
Spring Boot集成Redis构建博客应用 在这个示例中,我们将展示如何使用Spring Boot和Redis构建一个简单的博客应用,包括文章发布、点赞和评论功能。 1. 添加依赖 首先,我们需要在pom.xml文件中添加Spring Boot和Redis的依赖项。 <!-- Sp…...
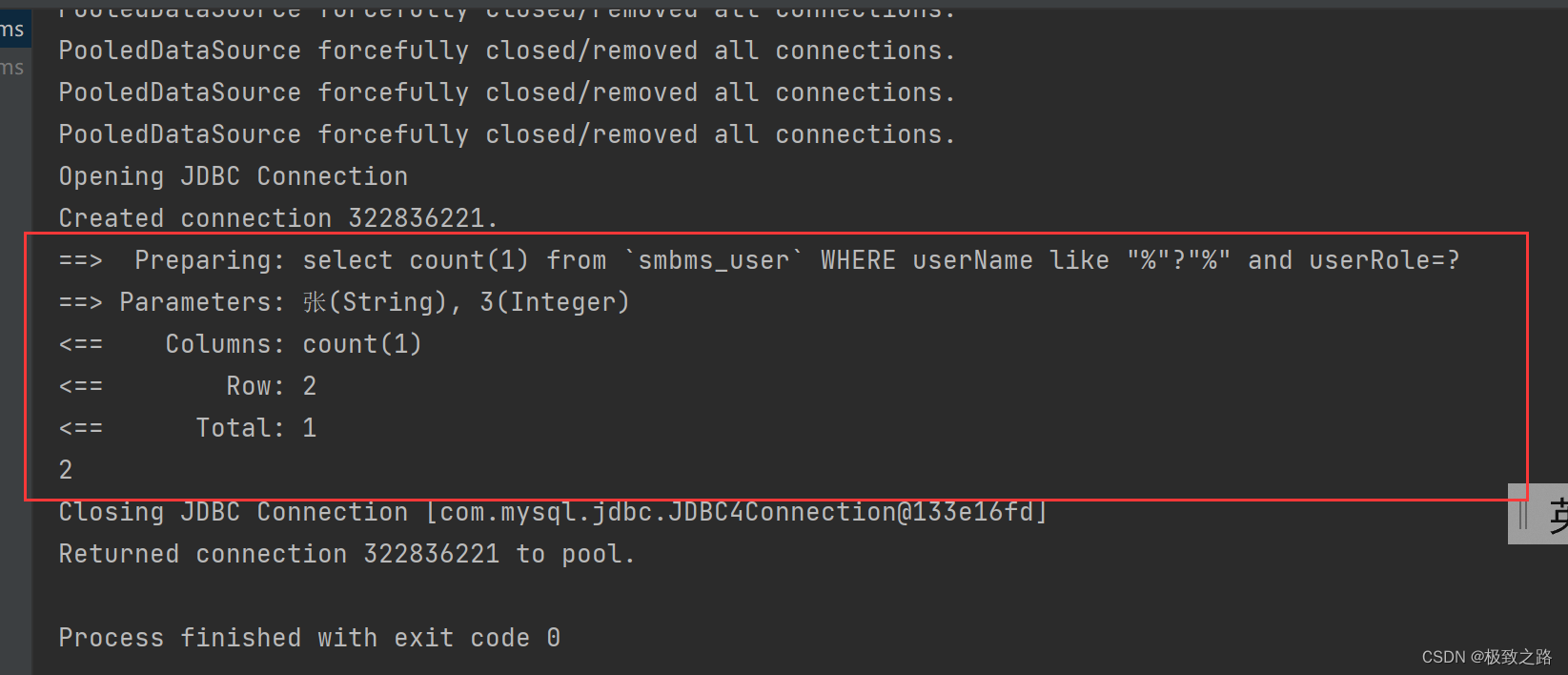
mapper向mapper.xml传参中文时的乱码问题
1.起因: 在idea中进行模糊查询传参时,发现在idea中查中文查不出记录,在navicate中可以查出来。 2.猜测: 1.idea中的编码问题导致的乱码。 2.idea和navicate的编码一致性导致的乱码。 3.mapper向mapper.xml传参后出现乱码。 3.解…...

基于Docker官方php:7.1.33-fpm镜像构建支持67个常见模组的php7.1.33镜像
实践说明:基于RHEL7(CentOS7.9)部署docker环境(23.0.1、24.0.2),所构建的php7.1.33镜像应用于RHEL7-9(如AlmaLinux9.1),但因为docker的特性,适用场景是不限于此的。 文档形成时期:2017-2023年 因系统或软件版本不同&am…...

Type-C PD充电器受电端sink诱骗取电汇总:小家电应用5V9V12V15V20V28V
小家电产品、美容产品、电动产品等升级采用Type-C接口,在Type-C接口上使用Type-C取电芯片,即可使用快速充电器的5V、9V、12V、15V、20V供电,无需再配充电器,各类品牌的充电器都可以支持。目前充电器常见的USB-PD功率为:…...
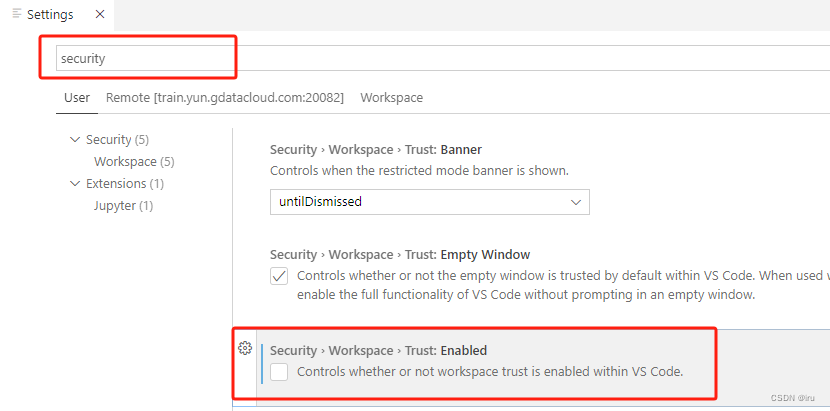
禁用code server docker容器中的工作区信任提示
VSCode 添加受限模式,主要是防止自动运行代码的,比如在vscode配置的task和launch参数是可以运行自定义代码的。如果用VScode打开未知的工程文件就有可能直接运行恶意代码。 但是当我们的实验基础模板文件可控的情况下,要想禁用code server do…...

JSON格式插件-VUE
JsonEditor 安装: npm i bin-code-editor -S引入: import Vue from vue; import CodeEditor from bin-code-editor; import bin-code-editor/lib/style/index.css; import App from ./App.vue; Vue.use(CodeEditor); new Vue({el: #app,render: h > …...
dubbo的springboot集成
1.什么是dubbo? Apache Dubbo 是一款 RPC 服务开发框架,用于解决微服务架构下的服务治理与通信问题,官方提供了 Java、Golang 等多语言 SDK 实现。使用 Dubbo 开发的微服务原生具备相互之间的远程地址发现与通信能力, 利用 Dubbo …...

【人工智能】智能电网:未来能源的革命
未来能源的革命 智能电网革命的意义在于将电力行业从传统的集中式发电和集中式输配电模式转变为智能化、分布式、互动式的能源网络。 现在我们从以下方面详细认真的了解一下智能电网: 智能变电站,智能配电网,智能电能表,智能交互…...

【AIGC】一组精美动物AI智能画法秘诀
如何使用AI绘画,从以下角度,依据表格内容梳理,表格如下: 外貌特征物种姿势特征描述场景风格技术描述小巧可爱幼小浣熊倚在桌子上具有人形特征中世纪酒馆电影风格照明8k分辨率细节精致毛茸茸手持咖啡杯Jean-Baptiste Monge的风格蓝…...
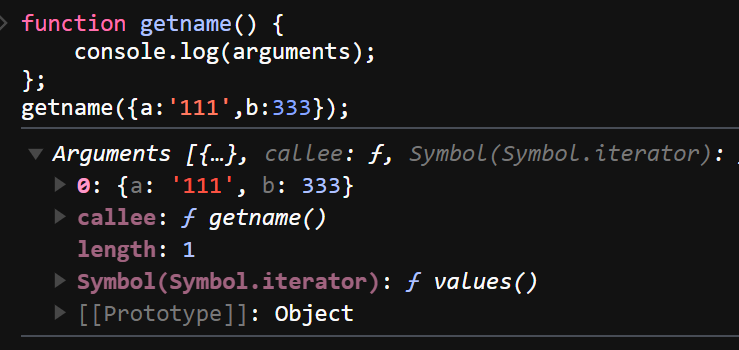
JS 高频面试题
JS 的数据类型有哪些,有什么区别 基本数据类型(Undefined、Null、Boolean、Number、String、Symbol) 引用数据类型(对象、数组和函数) 区别: 原始数据类型直接存储在栈(stack)中的简…...

linux—多服务免密登录
文档结构 概念简介配置操作 概念简介 配置操作 场景:在部署gp集群时,希望 master 节点可以使用gpadmin用户可以实现免密登录 slave1和 slave2 节点; step_1: IP映射 xx.xx.xx.101 server-slave1 xx.xx.xx.102 server-slave2说明&#x…...
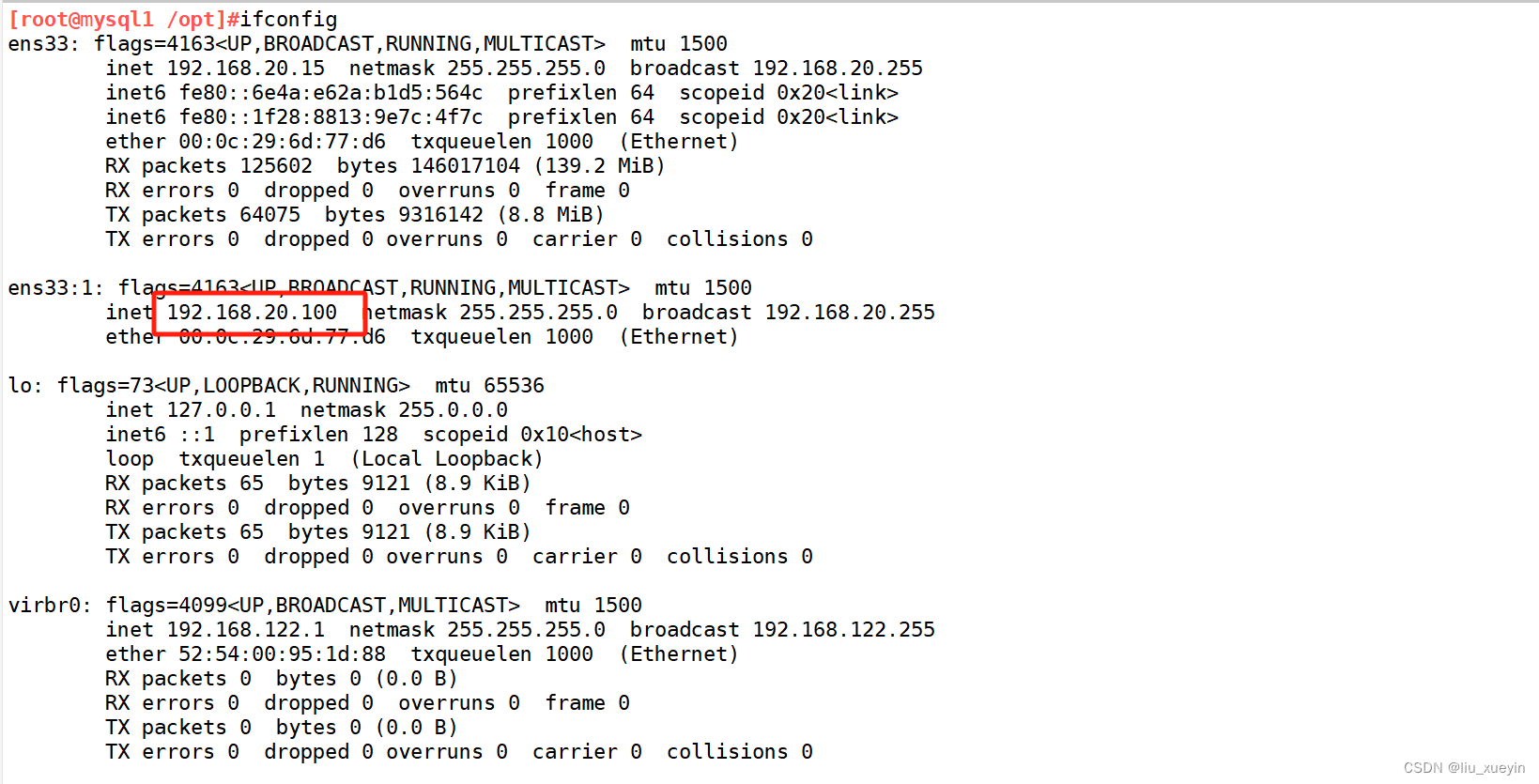
【MySQL】数据库之MHA高可用
目录 一、MHA 1、什么是MHA 2、MHA 的组成 3、MHA的特点 4、MHA的工作原理 二、有哪些数据库集群高可用方案 三、实操:一主两从部署MHA 1、完成主从复制 步骤一:完成所有MySQL的配置文件修改 步骤二:完成所有MySQL的主从授权&#x…...

ffmpeg 改变帧率,分辨率,时长等命令
ffmpeg -i elva.mp4 -ss 00:00:20 -t 00:00:30 -c:v copy -c:a copy output1.mp4 视频截取,开始时间和时长,-ss 00:00:20 -t 00:00:30 ffmpeg -i output1.mp4 -c:v libx265 output265.mp4 -c:v libx265,264转265 ffmpeg -i output1.mp4 -c:v libx264 output264.mp4 …...

烟火检测AI边缘计算智能分析网关V4在安防项目中的应用及特点
一、行业背景 随着社会和经济的发展,公共安全和私人安全的需求都在不断增长。人们需要更高效、更准确的安防手段来保障生命财产安全,而人工智能技术正好可以提供这种可能性,通过智能监控、人脸识别、行为分析等手段,大大提高了安防…...

有效的回文
常用方法就是双指针。使用两个指针从字符串的两端向中间移动,同时比较对应位置的字符,直到两个指针相遇。由于题目忽略非字母和非数字的字符且忽略大小写,所以跳过那些字符,并将字母转换为小写(或大写)进行…...

Electron快速上手
Electron 目录 简介 打包简单的html/css/javascript项目 打包Vue2项目 打包Vue3项目 简介 Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 嵌入 Chromium 和 Node.js 到 二进制的 Electron 允许您保持一个 JavaScript 代码代码库并创建 在Windows…...
华为“纯血”鸿蒙加速进场 高校、企业瞄准生态开发新风口
近日,华为终端BG CEO、智能汽车解决方案BU董事长余承东在2024年新年信中提出,开启华为终端未来大发展的新十年。 他特别提到,未来要构建强大的鸿蒙生态,2024年是原生鸿蒙的关键一年,将加快推进各类鸿蒙原生应用的开发…...

抖音百科怎么创建?头条百科的规则和技巧
在玩抖音的时候,不知道注意到抖音的搜索结果没有,有时候会去搜索框搜索一个品牌或人物名称,搜索框下面翻几下大概率就会出现百科词条,这个词条就是抖音百科。抖音的百科属于头条百科,因为这两个平台都属于字节跳动旗下…...

Kubernetes部署Valheim游戏服务器:云原生架构实践指南
1. 项目概述:当维京英灵殿遇上Kubernetes如果你和我一样,既沉迷于《英灵神殿》(Valheim)里那种与三五好友一起伐木、采矿、建造长屋,然后被巨魔追得满地图跑的原始乐趣,又恰好是一名整天和容器、编排系统打…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼
LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼 【免费下载链接】LrcHelper 从网易云音乐下载带翻译的歌词 Walkman 适配 项目地址: https://gitcode.com/gh_mirrors/lr/LrcHelper 你是否曾为找不到心爱歌曲的歌词而烦恼?或…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...
)
低多边形≠简陋!掌握这7个结构化Prompt技巧,3分钟产出可商用IP形象(附Figma网格对齐校验表)
更多请点击: https://intelliparadigm.com 第一章:低多边形设计的认知革命:从“简陋感”到“结构化美学” 低多边形(Low-Poly)设计曾长期被误读为建模能力不足的妥协产物,但其本质是一场对数字视觉语法的系…...

基于Docker部署OpenOffice无头服务实现文档自动化处理
1. 项目概述与核心价值最近在折腾文档处理自动化流程,发现很多老项目或者特定场景下,对Office文档的兼容性要求极高,尤其是那些需要处理.doc、.xls、.ppt等老格式的场景。直接用现代办公套件(比如LibreOffice)去处理&a…...

从零构建可定制对话系统:架构设计、RAG与智能体实战
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“customized-chat”。这名字听起来可能有点泛,但它的核心目标非常明确:打造一个完全由你自己掌控、能深度融入你特定业务逻辑或知识体系的对话…...
)
尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表)
更多请点击: https://intelliparadigm.com 第一章:尼泊尔语语音合成落地难?ElevenLabs官方未公开的3个语言模型限制(附2024年Q2实测延迟/错误率/重音支持对比表) 尼泊尔语(नेपाली)作为IS…...

手把手教你用Matlab搞定镜像电荷法仿真:从平面到半球导体的电场可视化
手把手教你用Matlab实现镜像电荷法仿真:从平面到半球导体的电场可视化 在电磁场理论的学习中,镜像电荷法是一个既经典又实用的计算方法。它通过引入虚拟电荷来简化复杂边界条件下的电场计算问题。本文将带你从零开始,用Matlab实现从简单平面到…...

Veil-Evasion核心模块深度解析:从控制器到Payload生成
Veil-Evasion核心模块深度解析:从控制器到Payload生成 【免费下载链接】Veil-Evasion Veil Evasion is no longer supported, use Veil 3.0! 项目地址: https://gitcode.com/gh_mirrors/ve/Veil-Evasion Veil-Evasion是一款专业的免杀payload生成工具&#x…...