2024.1.8 Day04_SparkCore_homeWork
目录
1. 简述Spark持久化中缓存和checkpoint检查点的区别
2 . 如何使用缓存和检查点?
3 . 代码题
浏览器Nginx案例
先进行数据清洗,做后续需求用
1、需求一:点击最多的前10个网站域名
2、需求二:用户最喜欢点击的页面排序TOP10
3、需求三:统计每分钟用户搜索次数
学生系统案例
4. RDD依赖的分类
5. 简述DAG与Stage 形成过程
DAG :
Stage :
1. 简述Spark持久化中缓存和checkpoint检查点的区别
1- 数据存储位置不同
缓存: 存储在内存或者磁盘 或者 堆外内存中
checkpoint检查点: 可以将数据存储在磁盘或者HDFS上, 在集群模式下, 仅能保存到HDFS上
2- 数据生命周期:
缓存: 当程序执行完成后, 或者手动调用unpersist 缓存都会被删除
checkpoint检查点: 即使程序退出后, checkpoint检查点的数据依然是存在的, 不会删除, 需要手动删除
3- 血缘关系:
缓存: 不会截断RDD之间的血缘关系, 因为缓存数据有可能是失效, 当失效后, 需要重新回溯计算操作
checkpoint检查点: 会截断掉依赖关系, 因为checkpoint将数据保存到更加安全可靠的位置, 不会发生数据丢失的问题, 当执行失败的时候, 也不需要重新回溯执行
4- 主要作用不同:
缓存: 提高Spark程序的运行效率
checkpoint检查点: 提高Spark程序的容错性
2 . 如何使用缓存和检查点?
将两种方案同时用在一个项目中, 先设置缓存,再设置检查点 , 最后一同使用Action算子进行触发, 这样程序只会有一次IO操作, 如果先设置检查点的话,就会有2次IO操作;
当在后续工程中读取数据的时候,优先从缓存中读取,如果缓存中没有数据, 再从检查点读取数据,并且会将数据缓存一份到内存中 ,后续直接从缓存中读取数据
3 . 代码题
浏览器Nginx案例

先进行数据清洗,做后续需求用
import os
from pyspark import SparkConf, SparkContext,StorageLevel
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 绑定指定的Python解释器
from pyspark.sql.types import StructType, IntegerType, StringType, StructFieldif __name__ == '__main__':
# 1- 创建SparkSession对象conf = SparkConf().setAppName('需求1').setMaster('local[*]')sc = SparkContext(conf=conf)
# 2- 数据输入init_rdd = sc.textFile('file:///export/data/2024.1.2_Spark/1.6_day04/SogouQ.sample')# 3- 数据处理filter_tmp_rdd = init_rdd.filter(lambda line:line.strip()!='')print('过滤空行的数据',filter_tmp_rdd.take(10))map_rdd = filter_tmp_rdd.map(lambda line:line.split())print('map出来的数据',map_rdd.take(10))len6_rdd = map_rdd.filter(lambda line:len(line)==6)print('字段数为6个的字段',len6_rdd.take(10))etl_rdd = len6_rdd.map(lambda list:(list[0],list[1],list[2][1:-1],list[3],list[4],list[5]) )print('转换成元组后的数据',etl_rdd.take(10))# 设置缓存etl_rdd.persist(storageLevel=StorageLevel.MEMORY_AND_DISK).count()
1、需求一:点击最多的前10个网站域名
print('点击最多的前10个网站域名','-'*50)website_map_rdd = etl_rdd.map(lambda tup:(tup[5].split('/')[0],1))print('把网站域名切出来,变成(hello,1)的格式',website_map_rdd.take(10))website_reducekey_rdd = website_map_rdd.reduceByKey(lambda agg,curr:agg+curr)print('进行聚合',website_reducekey_rdd.take(10))sort_rdd =website_reducekey_rdd.sortBy(lambda tup:tup[1],ascending=False)print('进行降序排序',sort_rdd.take(10))
# 4- 数据输出
# 5- 释放资源sc.stop()2、需求二:用户最喜欢点击的页面排序TOP10
print('用户最喜欢点击的页面排序TOP10','-'*100)top_10_order = etl_rdd.map(lambda tup:(tup[4],1))print('点击量排行',top_10_order.take(10))top_10_reducebykey = top_10_order.reduceByKey(lambda agg,curr:agg+curr)print('进行聚合',top_10_reducebykey.take(10))sortby_top10 = top_10_reducebykey.sortBy(lambda line:line[1],ascending=False)print('进行排序',sortby_top10.take(10))
# 4- 数据输出
# 5- 释放资源sc.stop()3、需求三:统计每分钟用户搜索次数
print('统计每分钟用户搜索次数','-'*50)search_map_rdd = etl_rdd.map(lambda tup:(tup[0][0:5],1))print('把网站域名切出来,变成(hello,1)的格式',search_map_rdd.take(10))search_reducekey_rdd = search_map_rdd.reduceByKey(lambda agg,curr:agg+curr)print('进行聚合',search_reducekey_rdd.take(10))sort_rdd =search_reducekey_rdd.sortBy(lambda tup:tup)print('按照时间进行排序',sort_rdd.take(10))
# 4- 数据输出
# 5- 释放资源sc.stop()学生系统案例

数据准备
import os
from pyspark import SparkConf, SparkContext, StorageLevel
from pyspark.sql import SparkSession
import pyspark.sql.functions as F# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 绑定指定的Python解释器
from pyspark.sql.types import StructType, IntegerType, StringType, StructFieldif __name__ == '__main__':
# 1- 创建SparkSession对象conf = SparkConf().setAppName('学生案例').setMaster('local[*]')sc = SparkContext(conf=conf)
# 2- 数据输入init_rdd= sc.textFile('hdfs://node1:8020/input/day04_home_work.txt')# 3- 数据处理stu_rdd = init_rdd.map(lambda line:line.split(',')).cache()print('切分后的数据为',stu_rdd.collect())# 1、需求一:该系总共有多少学生stu_cnt = stu_rdd.map(lambda line:line[0]).distinct().count()print(f'该系总共有{stu_cnt}个学生')
# 2、需求二:该系共开设了多少门课程subject_cnt = stu_rdd.map(lambda line:line[1]).distinct().count()print(f'该系共开设了{subject_cnt}门课程')
# 3、需求三:Tom同学的总成绩平均分是多少tom_score_sum = stu_rdd.filter(lambda line:line[0]=='Tom').map(lambda line:int(line[2])).sum()tom_subject_num = stu_rdd.filter(lambda line:line[0]=='Tom').map(lambda line:line[1]).distinct().count()tom_score_avg = tom_score_sum/tom_subject_numprint(f'Tom同学的总成绩平均分是{round(tom_score_avg,2)}')# 4、需求四:求每名同学的选修的课程门数
# every_student_course_num = stu_rdd.map(lambda x: (x[0], x[1])).distinct().map(lambda tup: (tup[0], 1))\
# .reduceByKey(lambda agg, curr: agg + curr).collect()every_student_course_num = stu_rdd.map(lambda x: (x[0], x[1])).distinct()print('学生与选修课,把一个学生重修一门选修课的情况去掉',every_student_course_num.collect())every_student_course_num2 = every_student_course_num\.map(lambda tup:(tup[0],1))\.reduceByKey(lambda agg,curr:agg+curr).collect()print('每个同学的选修课数',every_student_course_num2)
# 5、需求五:该系DataBase课程共有多少人选修subject_database = stu_rdd.filter(lambda line:line[1]=='DataBase').map(lambda line:line[0]).distinct().count()print(f'数据库有{subject_database}人选修')
# 6、需求六:各门课程的平均分是多少total_score = stu_rdd.map(lambda x:(x[1],int(x[2]))).groupByKey().map(lambda x:(x[0],sum(x[1])))print('各科总分为',total_score.collect())total_num = stu_rdd.map(lambda x: (x[1], 1)).groupByKey().map(lambda x: (x[0], sum(x[1])))print('各科的数量为',total_num.collect())#total_join =total_score.join(total_num)print('join后结果',total_join.collect())
# 各科总分为 [('DataBase', 170), ('Algorithm', 110), ('DataStructure', 140)]
# 各科的数量为 [('DataBase', 2), ('Algorithm', 2), ('DataStructure', 2)]
# 合表后为 [('DataBase', (170, 2)), ('DataStructure', (140, 2)), ('Algorithm', (110, 2))]total_avg =total_score.join(total_num).map(lambda x: (x[0], round(x[1][0] / x[1][1], 2))).collect()print('各科目的平均分为',total_avg)
# 4- 数据输出# 5- 释放资源sc.stop()4. RDD依赖的分类
窄依赖: 父RDD分区与子RDD分区是一对一关系
宽依赖: 父RDD分区与子RDD分区是一对多关系
5. 简述DAG与Stage 形成过程
DAG :
1-Spark应用程序,遇到了Action算子以后,就会触发一个Job任务的产生。Job任务首先将它所依赖的全部算子加载到内存中,形成一个完整Stage
2-会根据算子间的依赖关系,从Action算子开始,从后往前进行回溯,如果算子间是窄依赖,就放到同一个Stage中;如果是宽依赖,就形成新的Stage。一直回溯完成。
Stage :
1-Driver进程启动成功以后,底层基于PY4J创建SparkContext对象,在创建SparkContext对象的过程中,还会同时创建DAGScheduler(DAG调度器)和TaskScheduler(Task调度器)
DAGScheduler: 对Job任务形成DAG有向无环图和划分Stage阶段
TaskScheduler: 调度Task线程给到Executor进程进行执行
2-Spark应用程序遇到了一个Action算子以后,就会触发一个Job任务的产生。SparkContext对象将Job任务提交DAG调度器,对Job形成DAG有向无环图和划分Stage阶段。并且确定每个Stage阶段需要有多少个Task线程,将这些Task线程放置在TaskSet集合中。再将TaskSet集合给到Task调度器。
3-Task调度器接收到DAG调度器传递过来的TaskSet集合以后,将Task线程分配给到具体的Executor进行执行,底层是基于调度队列SchedulerBackend。Stage阶段是一个一个按顺序执行的,不能并行执行。
4-Executor进程开始执行具体的Task线程。后续过程就是Driver监控多个Executor的执行状态,直到Job任务执行完成。
相关文章:
2024.1.8 Day04_SparkCore_homeWork
目录 1. 简述Spark持久化中缓存和checkpoint检查点的区别 2 . 如何使用缓存和检查点? 3 . 代码题 浏览器Nginx案例 先进行数据清洗,做后续需求用 1、需求一:点击最多的前10个网站域名 2、需求二:用户最喜欢点击的页面排序TOP10 3、需求三&#x…...
09.简单工厂模式与工厂方法模式
道生一,一生二,二生三,三生万物。——《道德经》 最近小米新车亮相的消息可以说引起了不小的轰动,我们在感慨SU7充满土豪气息的保时捷设计的同时,也深深的被本土品牌的野心和干劲所鼓舞。 今天我们就接着这个背景&…...
DHCP,怎么在Linux和Windows中获得ip
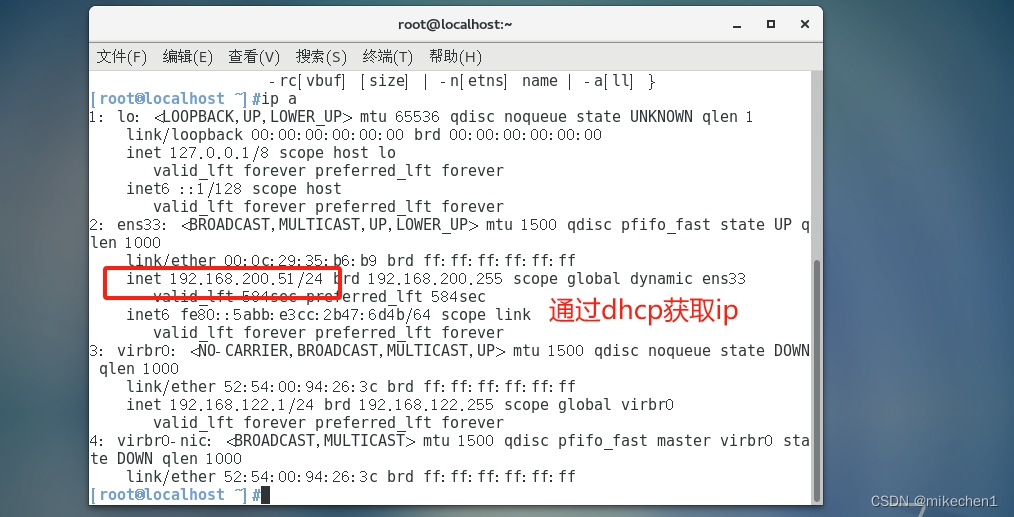
一、DHCP 1.1 什么是dhcp DHCP动态主机配置协议,通常被应用在大型的局域网络环境中,主要作用是集中地管理、分配IP地址,使网络环境中的主机动态的获得IP地址、DNS服务器地址等信息,并能够提升地址的使用率。 DHCP作为用应用层协…...
读写锁(arm)
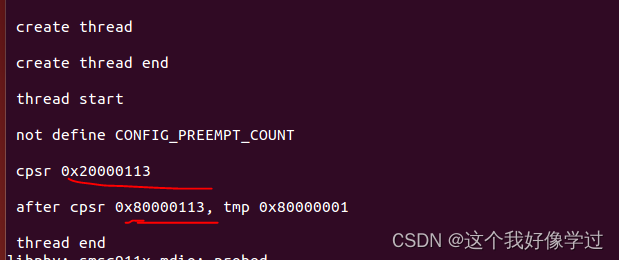
参考文章读写锁 - ARM汇编同步机制实例(四)_汇编 prefetchw-CSDN博客 读写锁允许多个执行流并发访问临界区。但是写访问是独占的。适用于读多写少的场景 另外好像有些还区分了读优先和写优先 读写锁定义 typedef struct {arch_rwlock_t raw_lock; #if…...

【第33例】IPD体系进阶:市场细分
目录 内容简介 市场细分原因 市场细分主要活动 市场细分流程 作者简介 内容简介 这节内容主要来谈谈 IPD 市场管理篇的市场细分步骤。 其中,市场管理(Market Management)是一套系统的方法。 用于对广泛的机会进行选择性收缩,...

response 拦截器返回的二进制文档(同步下载excel)如何配置
response 拦截器返回的二进制文档(同步下载excel)如何配置 一、返回效果图二、response如何配置 一、返回效果图 二、response如何配置 service.interceptors.response.use(response > {// 导出excel接口if (response.config.isExport) {return resp…...
为什么要使用云原生数据库?云原生数据库具体有哪些功能?
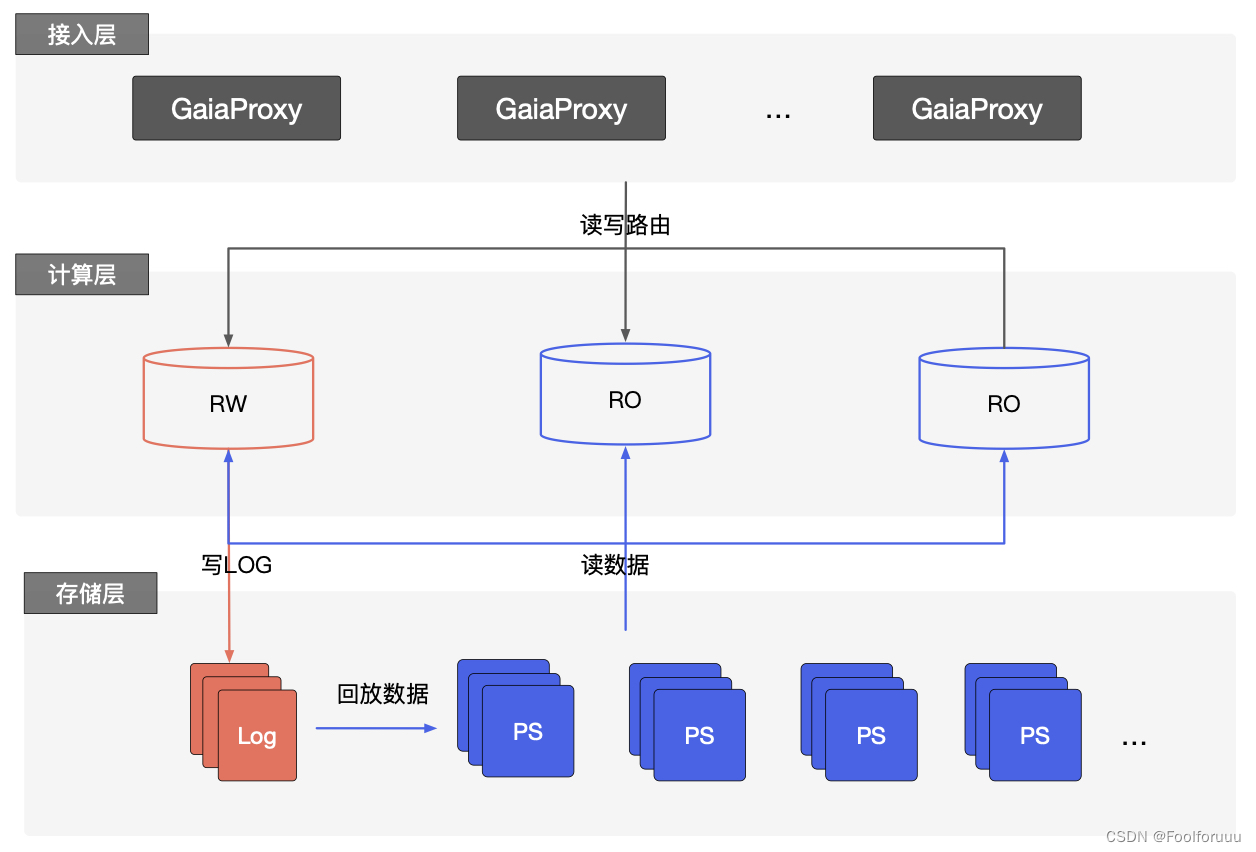
相比于托管型关系型数据库,云原生数据库极大地提高了MySQL数据库的上限能力,是云数据库划代的产品;云原生数据库最早的产品是AWS的 Aurora。AWS Aurora提出来的 The log is the database的理念,实现存储计算分离,把大量…...

05- OpenCV:图像操作和图像混合
目录 一、图像操作 1、读写图像 2、读写像素 3、修改像素值 4、Vec3b与Vec3F 5、相关的代码演示 二、图像混合 1、理论-线性混合操作 2、相关API(addWeighted) 3、代码演示(完整的例子) 一、图像操作 1、读写图像 (1)…...

人脸识别(Java实现的)
虹软人脸识别: 虹软人脸识别的地址:虹软视觉开放平台—以免费人脸识别技术为核心的人脸识别算法开放平台 依赖包: 依赖包是从虹软开发平台下载的 在项目中引入这个依赖包 pom.xml <!-- 人脸识别 --><dependency><gr…...

Maven 依赖管理项目构建工具 教程
Maven依赖管理项目构建工具 此文档为 尚硅谷 B站maven视频学习文档,由官方文档搬运而来,仅用来当作学习笔记用途,侵删。 另:原maven教程短而精,值得推荐,下附教程链接。 atguigu 23年Maven教程 目录 文章目…...
供应链+低代码,实现数字化【共赢链】转型新策略
在深入探讨之前,让我们首先明确供应链的基本定义。供应链可以被理解为一个由采购、生产、物流配送等环节组成的网状系统,它始于原材料的采购,经过生产加工,最终通过分销和零售环节到达消费者手中。 而数字化供应链,则是…...

[力扣 Hot100]Day3 最长连续序列
题目描述 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 出处 思路 此题可用带排序的哈希表,先构建哈希表࿰…...
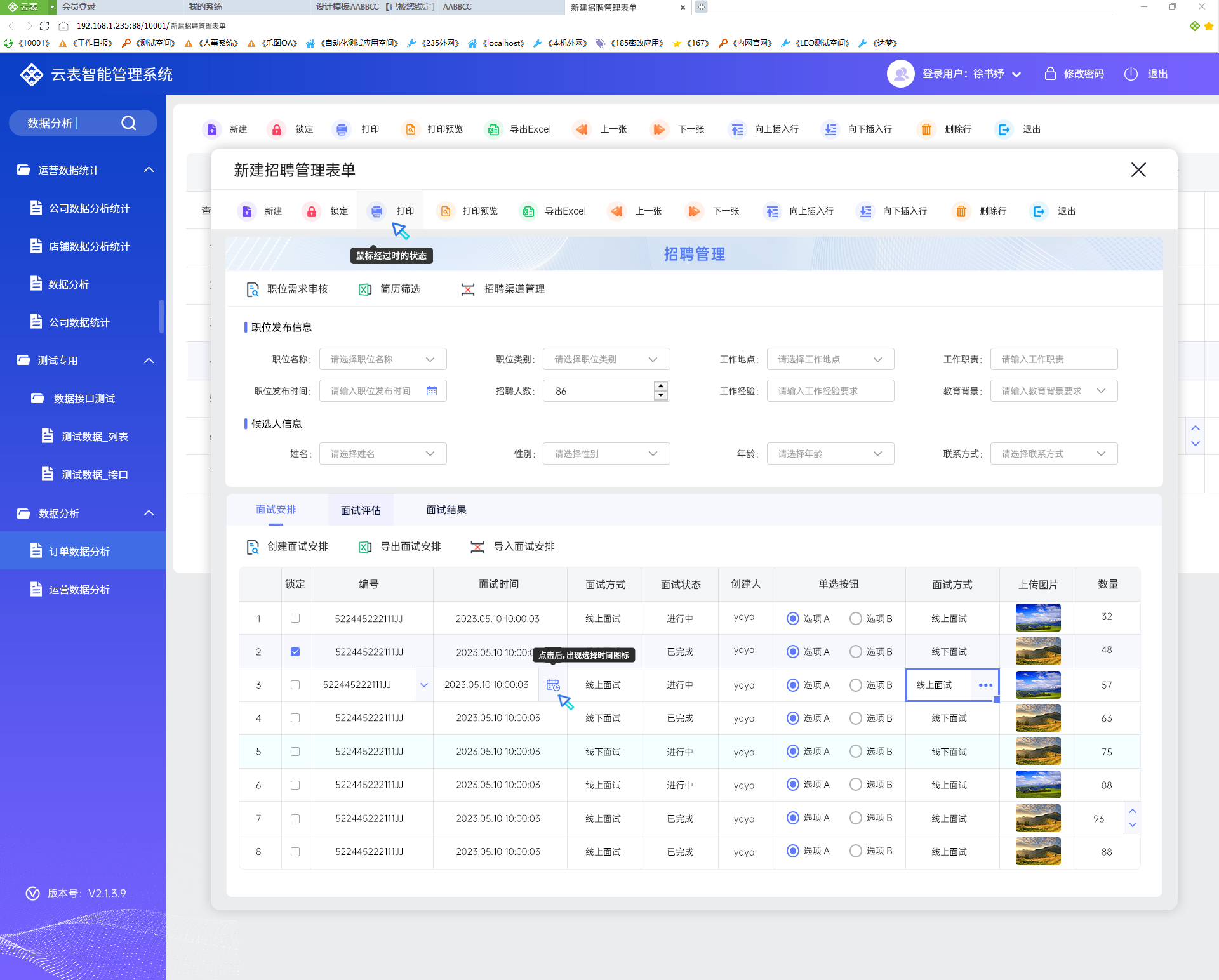
【办公技巧】Word功能区灰色显示不能编辑,怎么破?
Word文档可以设置加密来保护文件禁止修改,但是在word文档中设置限制编辑功能时对它的作用是否有详细的了解呢?今天为大家介绍word限制编辑功能的作用以及忘记了限制编辑密码该如何解决。 设置限制大家应该都清楚,就是点击工具栏中的审阅 – …...
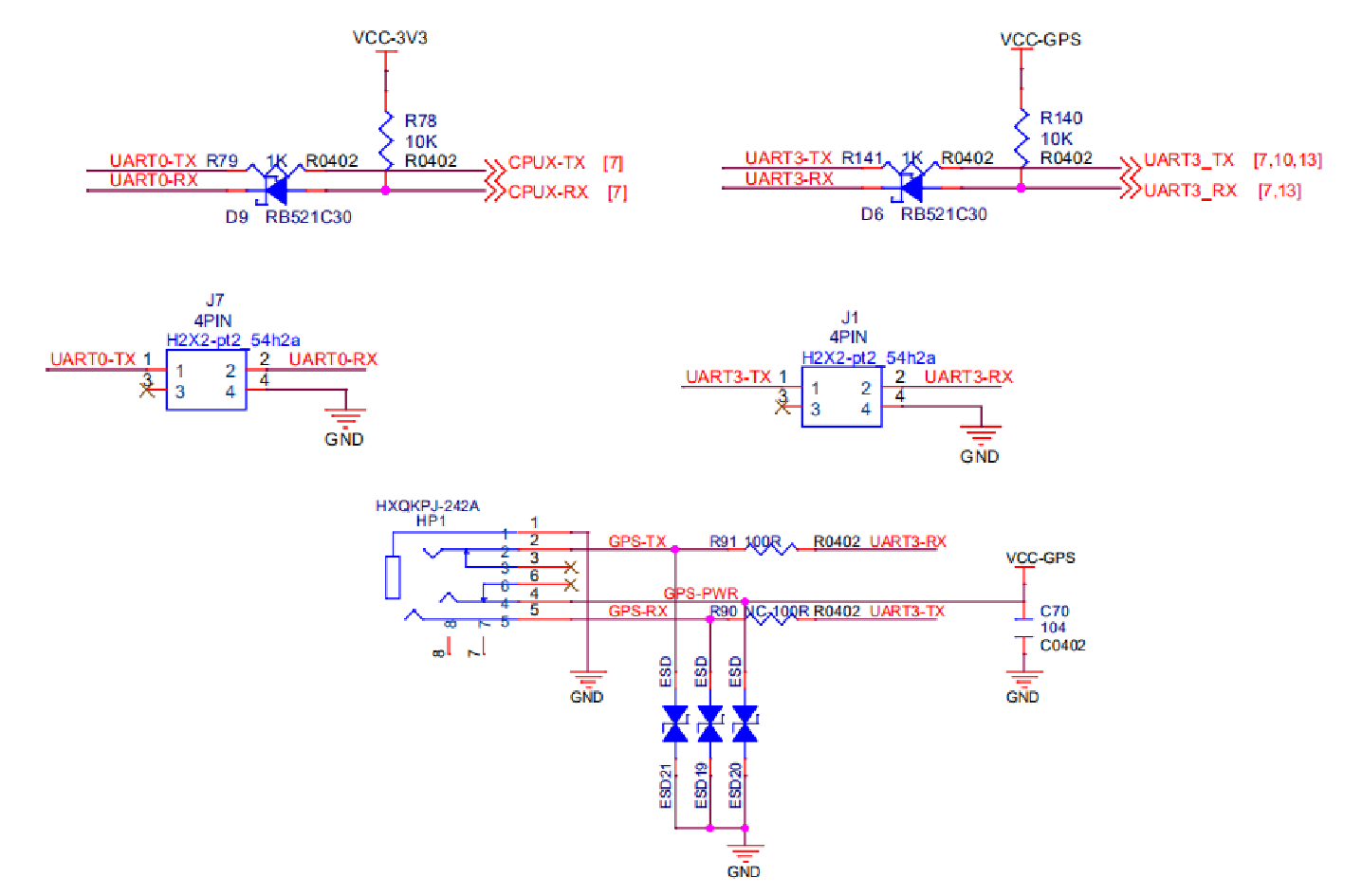
全志V853开发板原理图
本章节将对开发板几个主要的部件的原理图进行说明,方便快速上手开发板的硬件资料。 开发板硬件框图如下: 模块介绍 GPIO 分配 此表格为 V853 部分重要的 GPIO 的分配表,> 表示对IO的另外一个复用,完整的 GPIO 分配请参阅原理…...
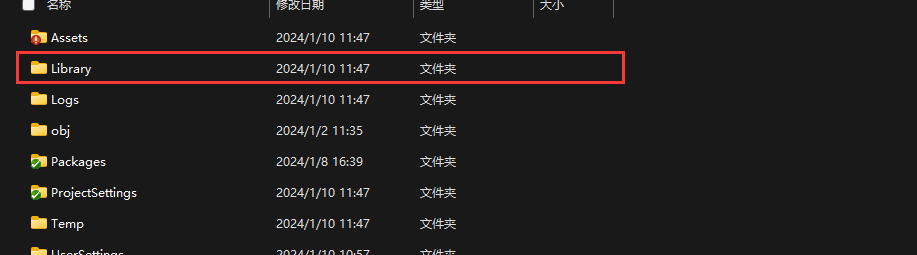
【解决】Unity Project 面板资源显示丢失的异常问题处理
开发平台:Unity 2021.3.7f1c1 一、问题描述 在开发过程中,遭遇 Project 面板资源显示丢失、不全的问题。但 Unity Console 并未发出错误提示。 二、解决方案:删除 Library 目录 前往 “工程目录/Library” 删除内部所有文件并重打开该…...

Hyperledger Fabric Docker 方式多机部署生产网络
规划网络拓扑 3 个 orderer 节点;组织 org1 , org1 下有两个 peer 节点, peer0 和 peer1; 组织 org2 , org2 下有两个 peer 节点, peer0 和 peer1; 因为我只有 3 台虚拟机资源所以没法实现完全的多机部署,资源使用规划如下&#…...
高效降压控制器FP7132XR:为高亮度LED提供稳定可靠的电源
目录 一. FP7132概述 二. 驱动电路:FP7132 三. FP7132应用 高亮度LED作为新一代照明技术的代表,已经广泛应用于各种领域。然而,高亮度LED的工作电压较低,需要一个高效降压控制器来为其提供稳定可靠的电源。在众多降压控制器…...

Spring Boot - Application Events 的发布顺序_ApplicationEnvironmentPreparedEvent
文章目录 Pre概述Code源码分析 Pre Spring Boot - Application Events 的发布顺序_ApplicationEnvironmentPreparedEvent 概述 Spring Boot 的广播机制是基于观察者模式实现的,它允许在 Spring 应用程序中发布和监听事件。这种机制的主要目的是为了实现解耦&#…...

华为HCIE课堂笔记第十三章 IPv6地址配置
目录 第十三章 IPv6地址配置 13.1 IPv6地址无状态自动配置 13.1.1 RS和RA报文格式 13.1.2 RA的Flags字段 13.1.3 地址的生存周期 13.1.4 RA报文中前缀中的Flags 13.2 DHCPv6 13.2.1 DHCPV6的概念 13.2.2 DCHPv6的报文 第十三章 IPv6地址配置 13.1 IPv6地址无状态自动…...
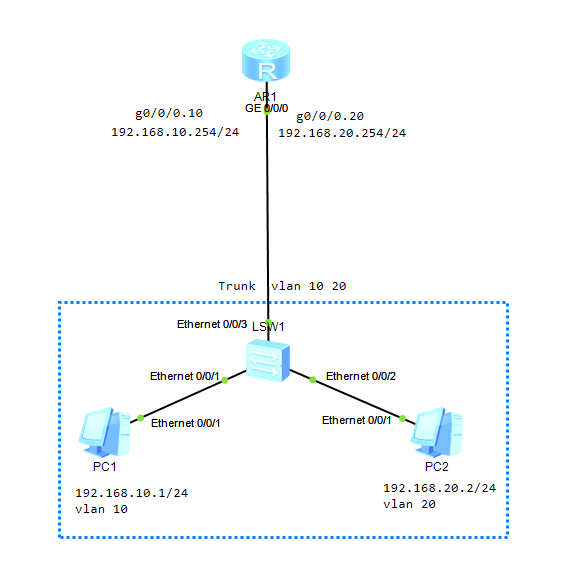
计算机网络-VLAN间通信
之前复习了VLAN的概念以及几个接口类型。VLAN在二层可以实现广播域的划分,VLAN间可以实现二层通信,但是不能实现三层通信,需要借助其它方式。 一、概述 实际网络部署中一般会将不同IP地址段划分到不同的VLAN。同VLAN且同网段的PC之间可直接进…...

安全聚合技术:原理、实现与多场景应用
1. 安全聚合技术概述安全聚合(Secure Aggregation)是一种多方安全计算技术,它允许多个互不信任的参与方在不泄露各自私有数据的前提下,共同计算出一个聚合结果。这项技术的核心价值在于解决了数据隐私与数据共享之间的矛盾&#x…...

LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼
LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼 【免费下载链接】LrcHelper 从网易云音乐下载带翻译的歌词 Walkman 适配 项目地址: https://gitcode.com/gh_mirrors/lr/LrcHelper 你是否曾为找不到心爱歌曲的歌词而烦恼?或…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

VS Code光标主题定制指南:提升开发效率与视觉舒适度
1. 项目概述:一个为开发者量身定制的光标主题集合如果你和我一样,每天有超过8个小时的时间是在代码编辑器里度过的,那么你一定对那个在屏幕上闪烁的光标再熟悉不过了。它不仅仅是文本插入点,更是我们思维在数字世界中的延伸。然而…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...

基于Helm Chart的JupyterHub生产级部署与运维实战指南
1. 项目概述:为什么我们需要一个可扩展的JupyterHub部署方案?如果你在团队里负责过数据科学或机器学习平台的搭建,大概率会为Jupyter Notebook的部署和管理头疼过。单个Jupyter Notebook服务给一两个人用还行,一旦团队规模扩大到十…...

Grad-CAM实战:用热力图透视神经网络的决策焦点
1. Grad-CAM技术初探:为什么我们需要热力图? 当你训练了一个图像分类模型,准确率高达95%,但你真的了解它是如何做出判断的吗?我曾在项目中遇到过这样的尴尬:模型把一只坐在草地上的哈士奇误判为"狼&qu…...