Hive 的 安装与使用
目录
- 1 安装 MySql
- 2 安装 Hive
- 3 Hive 元数据配置到 MySql
- 4 启动 Hive
- 5 Hive 常用交互命令
- 6 Hive 常见属性配置
Hive 官网
1 安装 MySql
为什么需要安装 MySql?
- 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。以我们需要将Hive 的元数据地址改为 MySql,可支持多窗口操作。
(1)检查当前系统是否安装过 Mysql,如果有,则删除
[huwei@hadoop101 ~]$ rpm -qa|grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64
[huwei@hadoop101 ~]$ sudo rpm -e --nodeps mariadb-libs
rpm -qa用于列出系统中已安装的所有软件包的名称,CentOS 6系统自带的数据库 MySql,CentOS 7系统自带的数据库是 mariadb(本质上就是 MySQL),根据自己的系统来确定。
(2)将 MySql 安装包拷贝到 /opt/software 目录下
(3)解压 MySql 安装包
新建 mysql_rpm 文件夹,并将MySQL 安装包中的文件解压在此处
[huwei@hadoop101 software]$ mkdir mysql_rpm
[huwei@hadoop101 software]$ tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C ./mysql_rpm/
注意,
mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar没有以gz结尾,不是压缩文件
(4)在安装目录下执行 rpm 安装
注意:按照 顺序 依次执行
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
[huwei@hadoop101 mysql_rpm]$ sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
(5)初始化数据库
[huwei@hadoop101 mysql_rpm]$ sudo mysqld --initialize --user=mysql
(6)查看临时生成的 root 用户的密码
[huwei@hadoop101 mysql_rpm]$ sudo cat /var/log/mysqld.log
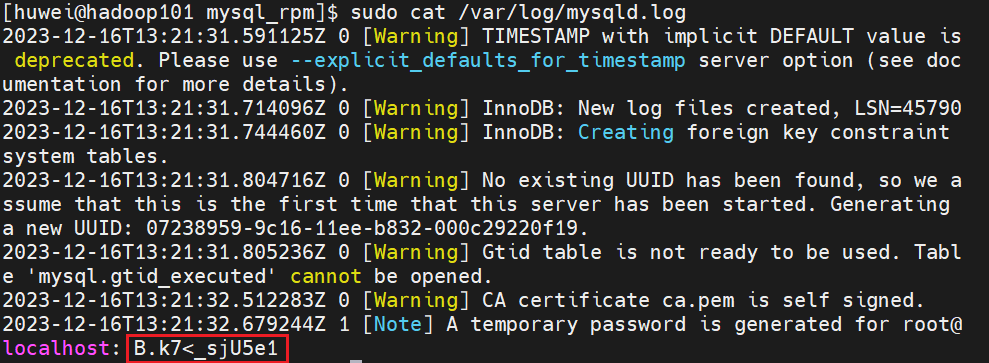
复制保存临时密码
(7)启动 MySql 服务
[huwei@hadoop101 mysql_rpm]$ sudo systemctl start mysqld
(8)登录 MySql 数据库
[huwei@hadoop101 mysql_rpm]$ mysql -uroot -p
不建议直接在
-p后直接输入密码,因为临时密码中可能含有一些特殊字符,shell 可能会把这些特殊字符解析导致出问题
(9)必须先修改 root 用户的密码,否则执行其他的操作会报错
这里我将 root 用户的密码改为 root
mysql> set password = password("root");
(10)修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
此时我是在主机 hadoop101 上安装的 MySQL,如果我想在主机 hadoop102 上登录MySQL,是登录不上的
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
退出 MySQL 数据库
mysql> exit;
2 安装 Hive
(1)把 apache-hive-3.1.2-bin.tar.gz上传到 linux 的 /opt/software 目录下
(2)解压 apache-hive-3.1.2-bin.tar.gz 到 /opt/module/ 目录下面
[huwei@hadoop101 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
(3)修改 apache-hive-3.1.2-bin 的名称为 hive-3.1.2
[huwei@hadoop101 software]$ cd ../module/
[huwei@hadoop101 module]$ mv apache-hive-3.1.2-bin/ hive-3.1.2
(4)修改 /etc/profile.d/my_env.sh,添加环境变量
[huwei@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
使环境变量生效
[huwei@hadoop101 module]$ source /etc/profile
(5)解决日志Jar包冲突
[huwei@hadoop101 module]$ cd hive-3.1.2/lib/
[huwei@hadoop101 module]$ ll
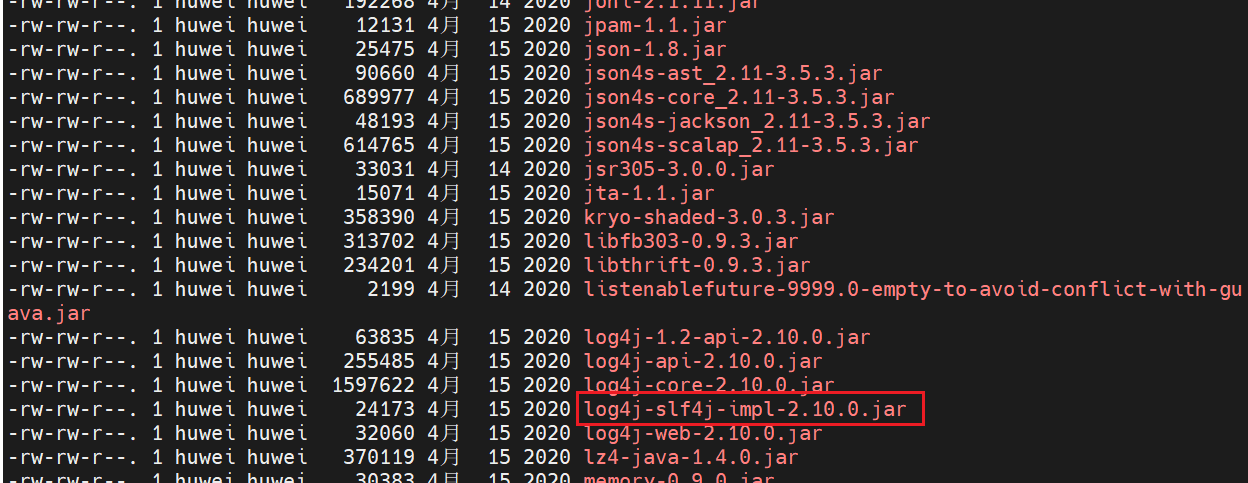
hive 工作时底层是基于 hadoop 的,hadoop 里也有日志的 jar 包,二者可能会有冲突,将 hive 中的
log4j-slf4j-impl-2.10.0.jar删除,在hive运行时直接使用 hadoop 提供的日志 jar 包。
[huwei@hadoop101 lib]$ rm -rf log4j-slf4j-impl-2.10.0.jar
3 Hive 元数据配置到 MySql
(1)在 $HIVE_HOME/conf目录下新建 hive-site.xml 文件
[huwei@hadoop101 ~]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false</value>
</property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value>
</property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- Hive元数据存储的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property>
</configuration>
(2)拷贝驱动
上传 JDBC 驱动至/opt/software/ ,然后将 MySql 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
[huwei@hadoop101 software]$ cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
(3)初始化元数据库
登录 mysql
[huwei@hadoop101 ~]$ mysql -uroot -proot
由于在 hive-site.xml 文件中指定了存放元数据的数据库 metastore
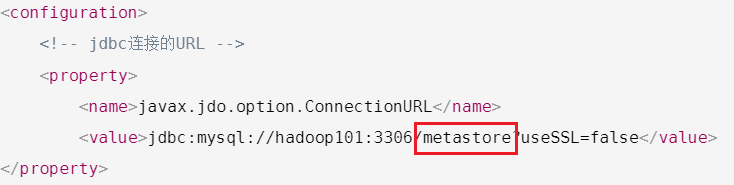
所以新建 Hive 元数据库 metastore
mysql> create database metastore;
Query OK, 1 row affected (0.01 sec)mysql> quit;
Bye
初始化 Hive 元数据库
[huwei@hadoop101 ~]$ schematool -initSchema -dbType mysql -verbose
4 启动 Hive
(1)启动 hadoop 集群
[huwei@hadoop101 ~]$ hdp_cluster.sh start
从下面三种启动方式中选择一种即可
(3)普通方式启动 hive
[huwei@hadoop101 ~]$ hive
(4)元数据服务方式启动 hive
hive的元数据是存在 MySql 里的,如果不使用元数据服务的话,hive直接会操作MySql里的元数据,使用元数据服务的话,hive会操作元数据服务,元数据服务再去操作 MySql 里的元数据
① 在 hive-site.xml 文件中添加如下配置信息
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/conf
[huwei@hadoop101 conf]$ vim hive-site.xml
<!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://hadoop101:9083</value></property>
② 启动 metastore
[huwei@hadoop101 ~]$ hive --service metastore
③ 新开启一个窗口,启动 hive
[huwei@hadoop101 ~]$ hive
(5)JDBC 方式启动 hive
普通方式启动 hive是直连的,而该方式则是通过 hiveserver2 再去连接 hive 的
① 在 hive-site.xml 文件中添加如下配置信息
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/conf
[huwei@hadoop101 conf]$ vim hive-site.xml
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop101</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
② 启动 hiveserver2
[huwei@hadoop101 ~]$ hive --service hiveserver2
③ 新开启一个窗口,启动 beeline 客户端
[huwei@hadoop101 conf]$ beeline -u jdbc:hive2://hadoop101:10000 -n huwei
注意:
-n后跟的是当前的用户名

(6)使用 hive
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test;
(7)编写启动 metastore 和 hiveserver2 脚本
前面第2、3种启动的方式导致需要打开多个 shell 窗口,编写启动 metastore 和 hiveserver2 脚本
[huwei@hadoop101 ~]$ cd bin
[huwei@hadoop101 bin]$ vim hiveservice.sh
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
thenmkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)echo $pid[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}function hive_start()
{metapid=$(check_process HiveMetastore 9083)cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"server2pid=$(check_process HiveServer2 10000)cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}function hive_stop()
{metapid=$(check_process HiveMetastore 9083)[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"server2pid=$(check_process HiveServer2 10000)[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}case $1 in
"start")hive_start;;
"stop")hive_stop;;
"restart")hive_stopsleep 2hive_start;;
"status")check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常";;
*)echo Invalid Args!echo 'Usage: '$(basename $0)' start|stop|restart|status';;
esac
添加执行权限
[huwei@hadoop101 bin]$ chmod u+x hiveservice.sh
启动服务
[huwei@hadoop101 bin]$ hiveservice.sh start
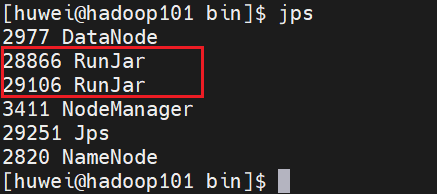
此时,我们发现有两个 RunJar 进程,就是hive服务进程了
5 Hive 常用交互命令
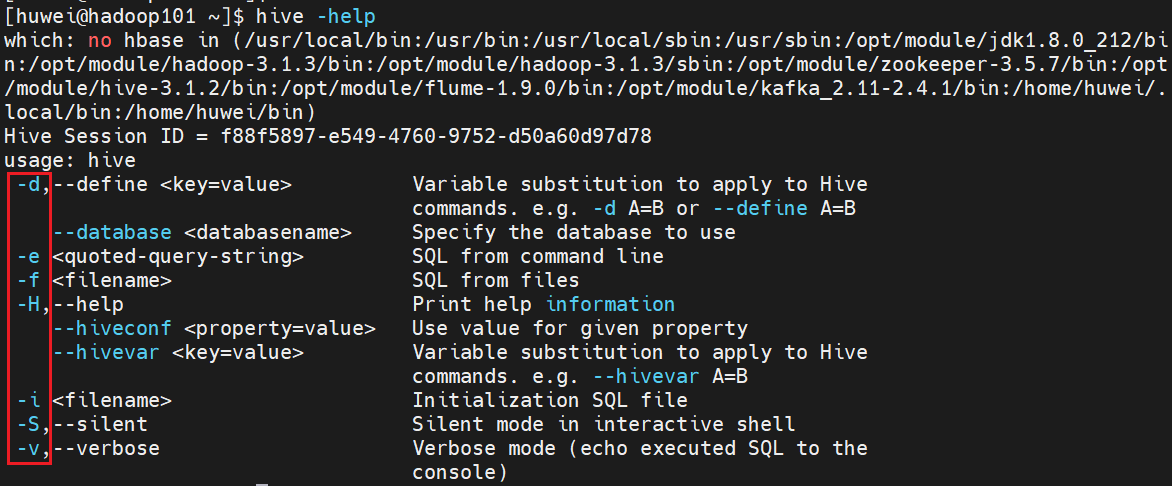
(1)-e:进入 hive 的交互窗口执行 sql 语句
首先进入hive 的交互窗口,新建表并插入内容
hive> create table mytbl (id int,name string);
hive> insert into mytbl values(1001,'zhangsan');
退出hive 的交互窗口
[huwei@hadoop101 ~]$ hive -e "select * from mytbl;"
(2)-f:执行脚本中 sql 语句
在 /opt/module/hive/下创建 datas 目录并在该目录下创建 hivef.sql 文件
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/
[huwei@hadoop101 hive-3.1.2]$ mkdir datas
[huwei@hadoop101 hive-3.1.2]$ cd datas/
[huwei@hadoop101 datas]$ touch hivef.sql
[huwei@hadoop101 datas]$ vim hivef.sql
在文件中编写 sql 语句
select * from mytbl;
执行脚本文件中的 sql 语句
[huwei@hadoop101 datas]$ hive -f /opt/module/hive-3.1.2/datas/hivef.sql
(3)退出 hive 窗口
hive> quit;
hive> exit;
如果是以 jdbc 方式开启 hive,则
!quit;退出
(4)在 hive 命令窗口中查看 hdfs文件系统
hive> dfs -ls /;
还可以在 hive 命令窗口中查看 linux 文件系统,
!ls /;,但这都很少用
(5)查看在 hive 中输入的所有历史命令
[huwei@hadoop101 datas]$ cd ~
[huwei@hadoop101 ~]$ cat .hivehistory
6 Hive 常见属性配置
(1)Hive 窗口打印默认库和表头
[huwei@hadoop101 ~]$ cd /opt/module/hive-3.1.2/conf/
[huwei@hadoop101 conf]$ vim hive-site.xml
添加如下内容
<property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property>
(2)Hive 运行日志信息配置
Hive 的 log 默认存放在
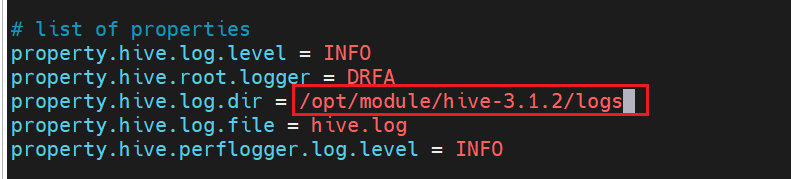
/tmp/atguigu/hive.log目录下(当前用户名下),修改 hive 的 log存放日志到/opt/module/hive-3.1.2/logs下
修改 /opt/module/hive-3.1.2/conf/hive-log4j2.properties.template文件名称为 hive-log4j2.properties
[huwei@hadoop101 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
在 hive-log4j.properties 文件中修改 log 存放位置
[huwei@hadoop101 conf]$ vim hive-log4j2.properties
(3)参数配置方式
查看当前所有的配置信息
hive (default)> set;
① 配置文件方式
- 默认配置文件:
hive-default.xml - 用户自定义配置文件:
hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
② 命令行参数方式
启动 Hive 时,可以在命令行添加 -hiveconf param=value 来设定参数。
[huwei@hadoop101 ~]$ hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
③ 参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
相关文章:
Hive 的 安装与使用
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive5 Hive 常用交互命令6 Hive 常见属性配置 Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户…...
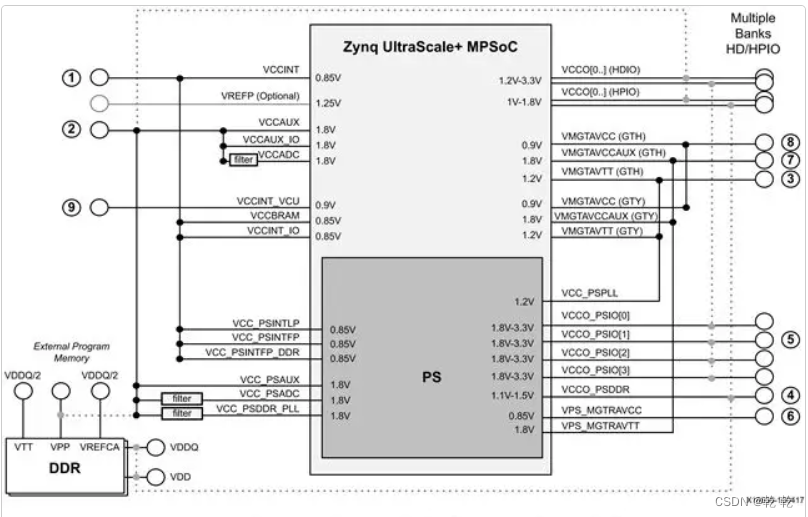
Zynq 电源
ZYNQ芯片的电源分PS系统部分和PL逻辑部分,两部分的电源分别是独立工作。PS系统部分的电源和PL逻辑部分的电源都有上电顺序,不正常的上电顺序可能会导致ARM系统和FPGA系统无法正常工作。 PS部分的电源有VCCPINT、VCCPAUX、VCCPLL和PS VCCO。 VCCPINT为PS内…...

DevOps系列之 Python操作数据库
pymysql操作mysql数据库 安装pymysql pip install pymysql pymysql操作数据库 1.连接数据库 使用Connect方法连接数据库 pymysql.Connections.Connection(hostNone, userNone, password, databaseNone, port0, charset) 参数说明: host – 数据库服务器所在的主机…...

【AI视野·今日NLP 自然语言处理论文速览 第七十四期】Wed, 10 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 10 Jan 2024 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Model Editing Can Hurt General Abilities of Large Language Models Authors Jia Chen Gu, Hao Xiang Xu, J…...

TDengine 签约积成电子
随着电力系统的复杂性和数据量不断增加,电力负荷、电压、频率等庞大的时序数据需要更高效的存储和处理能力,才能确保数据的可靠性和实时性。此外,电力系统还需要对实时数据进行快速分析和决策,以确保电网的稳定运行。然而…...
C++ 数组分页,经常有用到分页,索性做一个简单封装 已解决
在项目设计中, 有鼠标滑动需求,但是只能说能力有限,索性使用 php版本的数组分页,解决问题。 经常有用到分页,索性做一个简单封装、 测试用例 QTime curtime QTime::currentTime();nHour curtime.hour();nMin curtim…...

Redis管道操作
文章目录 1. 问题提出2. 解决方案3. 案例演示4. 总结 1. 问题提出 如何优化频繁命令往返造成的性能瓶颈? Redis是一种基于C/S一级请求响应协议的TCP服务,一个请求会遵循一下步骤: 客户端向服务端发送命令分四步(发送命令-> …...

新一代通信协议 - Socket.D
一、简介 Socket.D 是一种二进制字节流传输协议,位于 OSI 模型中的5~6层,底层可以依赖 TCP、UDP、KCP、WebSocket 等传输层协议。由 Noear 开发。支持异步流处理。其开发背后的动机是用开销更少的协议取代超文本传输协议(HTTP),HTTP 协议对于…...

国产系统-银河麒麟桌面版安装wps
0安装版本 系统版本 版本名称:银河麒麟桌面版操作系统V10(SP1) 软件版本 wps个人版2019 1双击安装 1.1卸载自带wps 为什么要卸载没有序列号,授权过期,不是免费的,通过先安装/在升级个人版跳过输入序列号问题等等原因 1.1.1当前自带的wps版本 1.1.2卸载 不卸载无法安装在…...
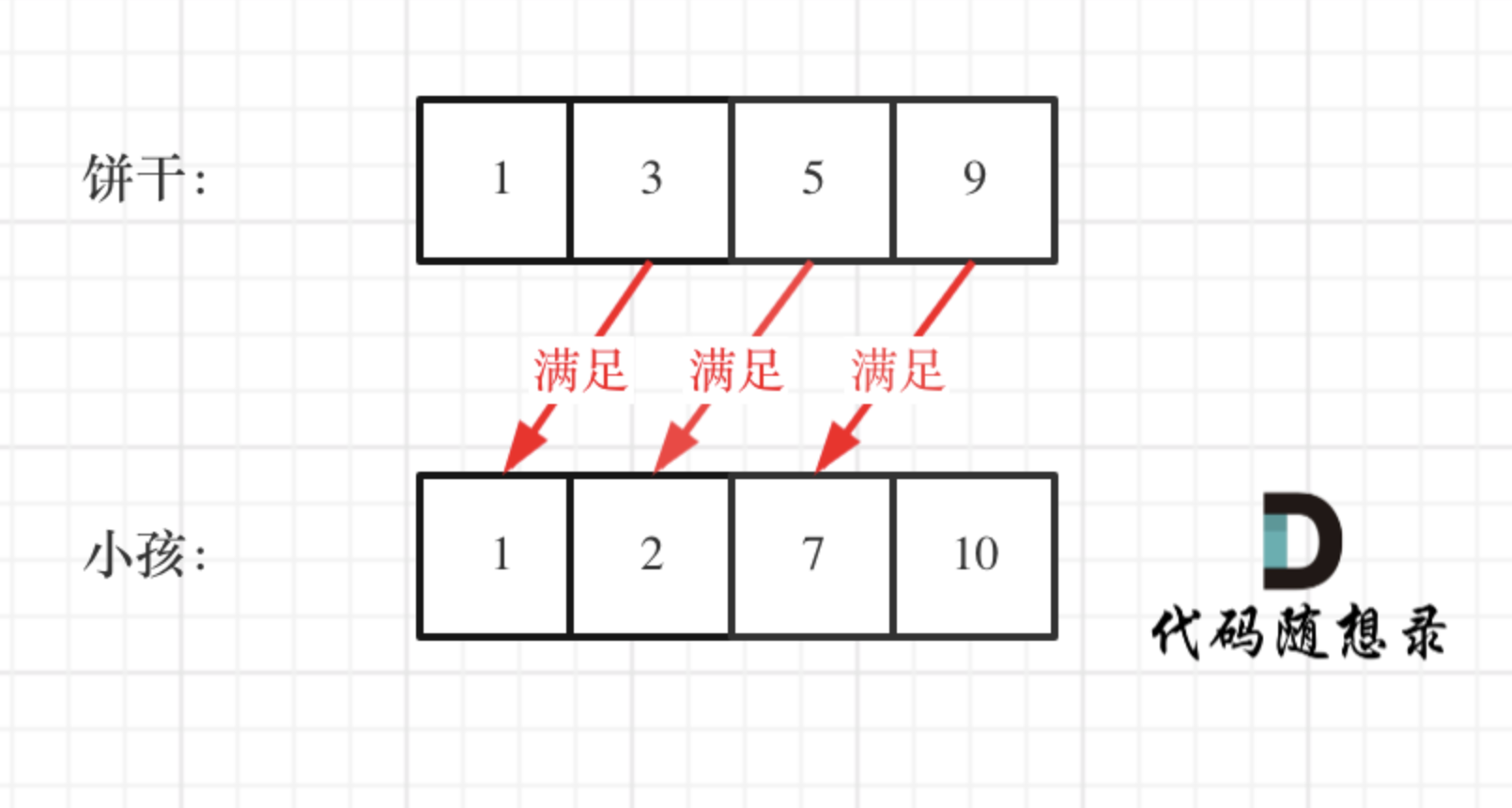
Day31 贪心算法 part01 理论基础 455.分发饼干 376.摆动序列 53.最大子序和
贪心算法 part01 理论基础 455.分发饼干 376.摆动序列 53.最大子序和 理论基础(转载自代码随想录) 什么是贪心 贪心的本质是选择每一阶段的局部最优,从而达到全局最优。 这么说有点抽象,来举一个例子: 例如&#…...
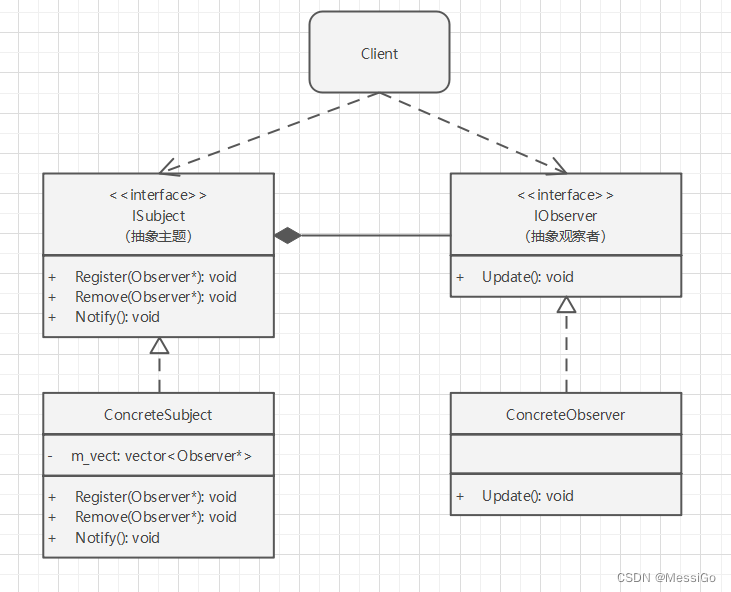
行为型模式 | 观察者模式
一、观察者模式 1、原理 观察者模式又叫做发布-订阅(Publish/Subscribe)模式,定义了一种一对多的依赖关系。让多个观察者对象同时监听某一个主题对象,这个主题对象在状态上发生变化时,会通知所有观察者对象࿰…...
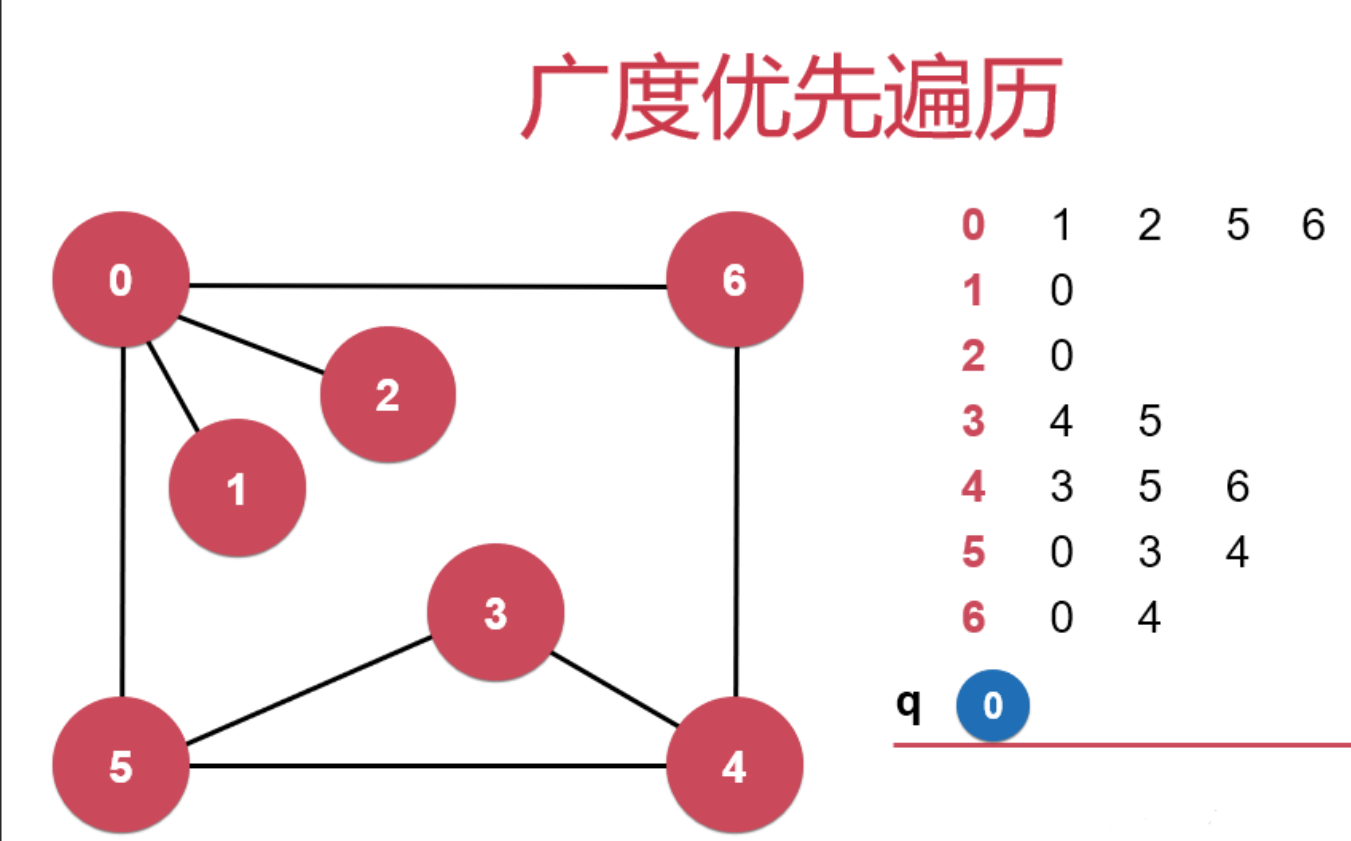
Python面向对象之继承
【 一 】什么是继承(Inheritance) 继承允许创建一个新类(称为子类或派生类),从已存在的类(称为父类或基类)继承属性和方法。子类可以继承父类的特性,并可以通过添加新的属性和方法来…...
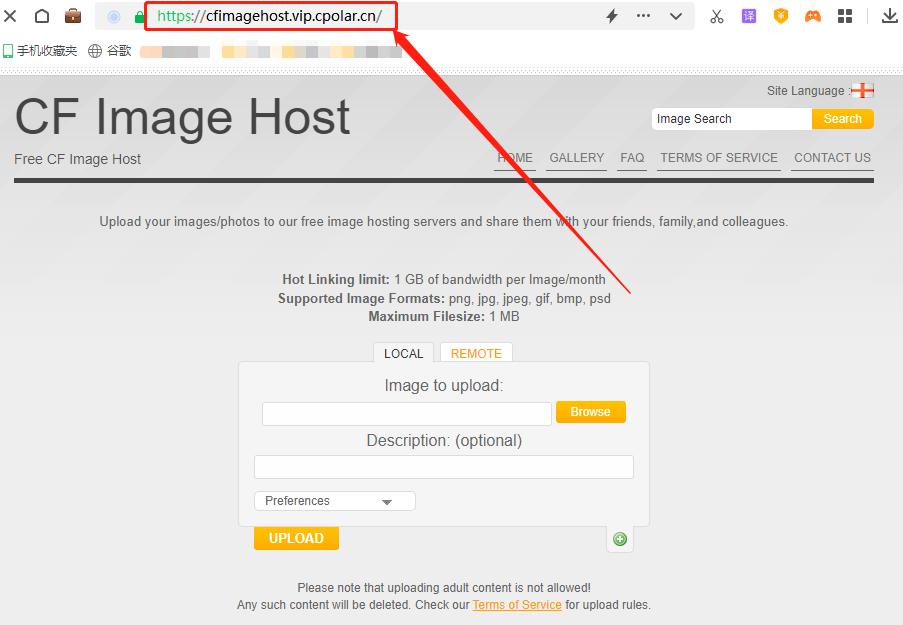
如何使用CFImagehost结合内网穿透搭建私人图床并无公网ip远程访问
[TOC] 推荐一个人工智能学习网站点击跳转 1.前言 图片服务器也称作图床,可以说是互联网存储中最重要的应用之一,不仅网站需要图床提供的外链调取图片,个人或企业也用图床存储各种图片,方便随时访问查看。不过由于图床很不挣钱&a…...

Wargames与bash知识14
Wargames与bash知识13 Bandit22 基于时间的作业调度程序cron会定期自动运行一个程序。在/etc/cron.d/中查找配置,并查看正在执行的命令。 注意:查看其他人编写的shell脚本是一项非常有用的技能。此级别的脚本有意使其易于阅读。如果您在理解它的作用时…...

2020年认证杯SPSSPRO杯数学建模C题(第二阶段)抗击疫情,我们能做什么全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 C题 抗击疫情,我们能做什么 原题再现: 2020 年 3 月 12 日,世界卫生组织(WHO)宣布,席卷全球的冠状病毒引发的病毒性肺炎(COVID-19)是一种大流行病。…...

JAVA基础学习笔记-day17-反射
JAVA基础学习笔记-day17-反射 1. 反射(Reflection)的概念1.1 反射的出现背景1.2 反射概述1.3 Java反射机制研究及应用1.4 反射相关的主要API1.5 反射的优缺点 2. 理解Class类并获取Class实例2.1 理解Class2.1.1 理论上2.1.2 内存结构上 2.2 获取Class类的实例(四种方法)2.3 哪些…...

经典算法-模拟退火算法的python实现
经典算法-模拟退火算法的python实现 模拟退火算法基本思想 模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却。加温时,固体内部粒子随温度升高变为无序状,内能增大,而缓慢冷却时粒子又逐渐趋有序。…...

谷粒学院项目redirect_uri 参数错误微信二维码登录
谷粒学院项目redirect_uri 参数错误_redirect_uri": "http%3a%2f%2fguli.shop%2fapi%2fuce-CSDN博客 修改本地配置 # ����˿� server.port8160 # ����&#x…...
Jenkins+nexus
jiekins安装完成 1、安装java环境 [rootnexus ~]# tar -xf jdk-8u211-linux-x64.tar.gz -C /usr/local [rootnexus ~]# vim /etc/profile.d/java.sh JAVA_HOME/usr/local/jdk1.8.0_211 PATH$PATH:$JAVA_HOME/bin [rootnexus ~]# source /etc/profile.d/java.sh 必须要选择与n…...
「JavaSE」类和对象1
🎇个人主页:Ice_Sugar_7 🎇所属专栏:快来卷Java啦 🎇欢迎点赞收藏加关注哦! 类和对象 🍉类的定义🍌类的实例化 🍉this引用🍉对象的构造及初始化🍌…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

Altium Designer实战:用xSignals搞定DDR4内存的等长布线,告别时序烦恼
Altium Designer实战:用xSignals实现DDR4内存精准等长布线 在高速PCB设计中,DDR4内存接口的布线一直是硬件工程师面临的技术高地。当信号速率突破2400MHz时,地址、命令与数据线之间哪怕几个ps的时序偏差都可能导致系统不稳定。传统手工计算网…...

当Windows 11 LTSC失去应用商店时,如何轻松找回完整的应用生态?
当Windows 11 LTSC失去应用商店时,如何轻松找回完整的应用生态? 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否曾经为W…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...