2. Presto应用
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。
文章目录
- 1、Presto安装使用
- 2、事件分析
- 3、漏斗分析
- 4、漏斗分析UDAF开发
- 开发UDF插件
- 开发UDAF插件
- 5、漏斗测试
1、Presto安装使用
参考官方文档:https://prestodb.io/docs/current/
Presto是一个高效的查询分析引擎,支持多种数据源,例如(Hive、MySQL、MD、Kafka等),内部查询是基于内存操作的,相比较Spark效率更高,而且更大的特点在于可以自定义内存空间,设置内存使用大小。
安装部署
# 创建目录
mkdir -p /opt1/soft/presto
# 下载presto-server
wget -P /opt1/soft/presto http://doc.yihongyeyan.com/qf/project/soft/presto/presto-server-0.236.tar.gz
# 解压
tar -zxvf presto-server-0.236.tar.gz
# 创建软连
ln -s /opt1/soft/presto/presto-server-0.236 /opt1/soft/presto/presto-server
# 安装目录下创建etc目录
cd /opt1/soft/presto/presto-server/ && mkdir etc
# 创建节点数据目录
mkdir -p /data1/presto/data
# 接下来创建配置文件
cd /opt/soft/presto/presto-server/etc/
# config.properties persto server的配置
cat << EOF > config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
# 单个查询在整个集群上够使用的最大用户内存
query.max-memory=3GB
# 单个查询在每个节点上可以使用的最大用户内存
query.max-memory-per-node=1GB
# 单个查询在每个节点上可以使用的最大用户内存+系统内存(user memory: hash join,agg等,system memory:input/output/exchange buffers等)
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://0.0.0.0:8080
EOF# node.properties 节点配置
cat << EOF > node.properties
node.environment=production
node.id=node01
node.data-dir=/data1/presto/data
EOF#jvm.config 配置,注意-DHADOOP_USER_NAME配置,替换为你需要访问hdfs的用户
cat << EOF > jvm.config
-server
-Xmx3G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-DHADOOP_USER_NAME=root
EOF#log.properties
#default level is INFO. `ERROR`,`WARN`,`DEBUG`
cat << EOF > log.properties
com.facebook.presto=INFO
EOF# catalog配置,就是各种数据源的配置,我们使用hive,注意替换为你自己的thrift地址
mkdir /opt1/soft/presto/presto-server/etc/catalog
cat <<EOF > catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.10.99:9083
hive.parquet.use-column-names=true
hive.allow-rename-column=true
hive.allow-rename-table=true
hive.allow-drop-table=true
EOF# 添加hudi支持
wget -P /opt1/soft/presto/presto-server/plugin/hive-hadoop2 http://doc.yihongyeyan.com/qf/project/soft/hudi/hudi-presto-bundle-0.5.2-incubating.jar# 客户端安装
wget -P /opt1/soft/presto/ http://doc.yihongyeyan.com/qf/project/soft/presto/presto-cli-0.236-executable.jar
cd /opt1/soft/presto/
mv presto-cli-0.236-executable.jar presto
chmod u+x presto
ln -s /opt1/soft/presto/presto /usr/bin/presto
# 至此presto 安装完毕
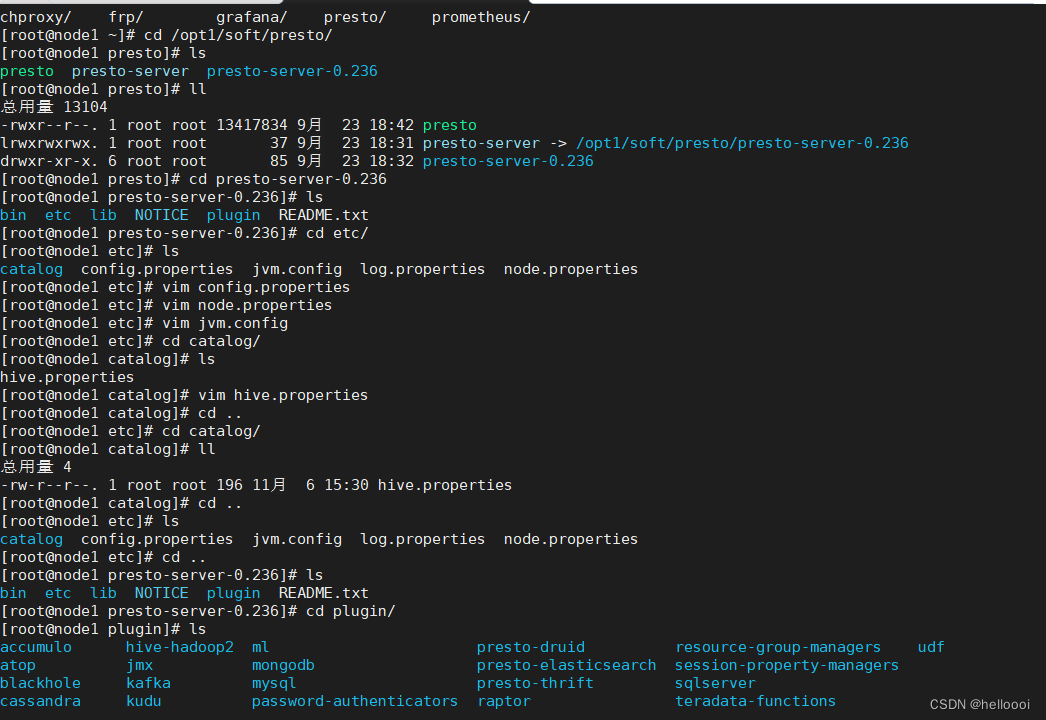
测试
# 启动persto-server, 注意下方命令是在后台启动,日志文件在node.properties中配置的 /data2/presto/data/var/log/ 目录下
/opt1/soft/presto/presto-server/bin/launcher start
# presot 连接hive metastore
presto --server 192.168.10.99:8080 --catalog hive --schema ods_news1
# 执行查询你会看到我们hive中的表
show tables;
进入客户端后,查询数据很多,需要用end键查看下拉,如果想退出按q键退出查看
2、事件分析
在这里我们先确定实施方案,也就是我们接下来开发的各种模型要怎么使用,给你大家提供了三种方案,第一种就是使用可视化工具superset,第二种就是使用hue、第三种使用自研Web平台,我们选择的是第三种方式,这种方式需要编写JDBC连接操作Presto,然后根据每个模型查询出来的不同结果集,提供不同的接口,客户端可以用过访问HTTP请求来调用接口拿到每个不同模型的不同数据。
-- 2. 分版本各APP页面访问次数(PV)的TOP-3, [当日准实时数据,当下时间延迟5分钟]with t1 as(selectlogday,app_version,element_page,count(1) as pvfrom ods_news1.eventwhere logday='20201227' and app_version!=''group by 1,2,3
),
t2 as(select logday,app_version,element_page,pv,row_number() over(partition by app_version order by pv desc) as rankfrom t1
)
select * from t2 where t2.rank<=3 order by app_version desc;/*类似结果如下:logday | app_version | element_page | pv | rank
----------+-------------+--------------+----+------20200619 | 2.3 | 我的 | 48 | 120200619 | 2.3 | 活动页 | 40 | 220200619 | 2.3 | 新闻列表页 | 39 | 320200619 | 2.2 | 搜索页 | 40 | 120200619 | 2.2 | 新闻列表页 | 38 | 220200619 | 2.2 | 活动页 | 37 | 320200619 | 2.1 | 首页 | 41 | 120200619 | 2.1 | 活动页 | 37 | 220200619 | 2.1 | 注册登录页 | 35 | 3
*/
-- 3. 天,小时,分钟 级别的APP页面点击的UV数,并保证每一列降序输出 [注意使用上卷函数,当日准实时数据,当下时间延迟5分钟]
--上卷(汇总数据)
上卷就是乘坐电梯上升观测人的过程。数据的汇总聚合,细粒度到粗粒度的过程,会无视某些维度
按城市汇总的人口数据上卷,观察按国家人口的数据。就是由细粒度到粗粒度观测数据的过程,应该还会记录相应变化。--下钻(明细数据)
上卷的反向操作,数据明细,粗粒度到细粒度的过程,会细化某些维度
可以按照城市汇总的人口数据下钻,观察按城镇人口汇总的数据。由粗粒度变为细粒度。--例
select * from table group by A;
select * from table group by A,B;
select * from table group by A,B,C;
自上而下粒度变细,为下钻;
自下而上粒度变粗,为上卷with t1 as(
select
format_datetime(from_unixtime(ctime/1000),'yyyy-MM-dd') as log_day,
format_datetime(from_unixtime(ctime/1000),'yyyy-MM-dd HH') as log_hour,
format_datetime(from_unixtime(ctime/1000),'yyyy-MM-dd HH:mm') as log_minute,
distinct_id
from ods_news1.event
where logday='20201227' and event='AppClick'
)
select
log_day,log_hour,log_minute,
count(distinct distinct_id) uv,
grouping(log_day,log_hour,log_minute) group_id
from t1
group by
rollup(log_day,log_hour,log_minute)
order by group_id desc,log_day desc ,log_hour desc ,log_minute desc
/*类似结果如下:log_day | log_hour | log_minute | uv | group_id
------------+---------------+------------------+------+----------NULL | NULL | NULL | 2341 | 72020-06-19 | NULL | NULL | 2341 | 32020-06-19 | 2020-06-19 18 | NULL | 584 | 12020-06-19 | 2020-06-19 17 | NULL | 585 | 12020-06-19 | 2020-06-19 16 | NULL | 562 | 12020-06-19 | 2020-06-19 15 | NULL | 571 | 12020-06-19 | 2020-06-19 14 | NULL | 298 | 12020-06-19 | 2020-06-19 18 | 2020-06-19 18:59 | 7 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:58 | 13 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:57 | 11 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:56 | 8 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:55 | 14 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:54 | 12 | 02020-06-19 | 2020-06-19 18 | 2020-06-19 18:53 | 10 | 0
*/
3、漏斗分析
sql实现
# 我们漏斗分析中定义的需求如下
注册-> 点击新闻-> 进入详情页-> 发布评论
# 转换成事件
SignUp -> AppClick[element_page='新闻列表页'] -> AppClick[element_page='内容详情页']->NewsAction[action_type='评论']# 接下来我们用SQL实现这个需求
# 我们来查询 20201227到20201230 事件范围内,并且窗口时间是3天的漏斗
注意:我们这里数据就三天,所以窗口期也就是不用判断,但是我们以后可能会拿到N天数据,所以要加窗口期判断
-- 分析sql,首先我们可以先把每一个事件的数据按照条件查询出来,然后在将每一个事件中的时间拿到,进行关联查询,通过时间进行判断该事件是否在窗口期以内,并且还要和上一个事件判断,一定要大于它
-- 拿到三天内每一个事件数据
with t1 as(selectdistinct_id,ctime,eventfrom ods_news1.eventwhere event='SignUp'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') >='20200923'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') <='20200925'
),
t2 as(selectdistinct_id,ctime,eventfrom ods_news1.eventwhere event='AppClick' and element_page='新闻列表页'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') >='20200923'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') <='20200925'
),
t3 as(selectdistinct_id,ctime,eventfrom ods_news1.eventwhere event='NewsAction' and element_page='评论'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') >='20200923'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') <='20200925'
),
t4 as(selectdistinct_id,ctime,eventfrom ods_news1.eventwhere event='SignIn'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') >='20200923'and format_datetime(from_unixtime(ctime/1000),'yyyyMMdd') <='20200925'
)
select
count(distinct t1.distinct_id) step1,
count(t2.event) step2,
count(t3.event) step3,
count(t4.event) step4
from t1
left join t2
on t1.distinct_id=t2.distinct_id
and t1.ctime<t2.ctime and t2.ctime-t1.ctime<86400*3*1000
left join t3
on t2.distinct_id=t3.distinct_id
and t2.ctime<t3.ctime and t3.ctime-t1.ctime<86400*3*1000
left join t4
on t3.distinct_id=t4.distinct_id
and t3.ctime<t4.ctime and t4.ctime-t1.ctime<86400*3*1000
# 执行上述查询可以看到如下类似结果step1 | step2 | step3 | step4
-------+-------+-------+-------3154 | 79 | 2 | 1
# 代表着我们的漏斗的每一步的人数
4、漏斗分析UDAF开发
分析:UDAF开发我们分为两步处理,第一步处理数据,求出用户深度即可,第二步根据每一个用户的深度将其转换成数组,集合每一个数组中对应下标值,然后求sum。
Presto使用操作:
需要掌握内容:
1、开辟内存空间大小
2、合理设置存入数据大小,保证别越界,超出内存
3、内存地址结合使用
开发UDF插件
开发完成代码后,然后将插件要部署到Presto上面,前提先打Jar,然后上传到Presto,最后重启,使用函数
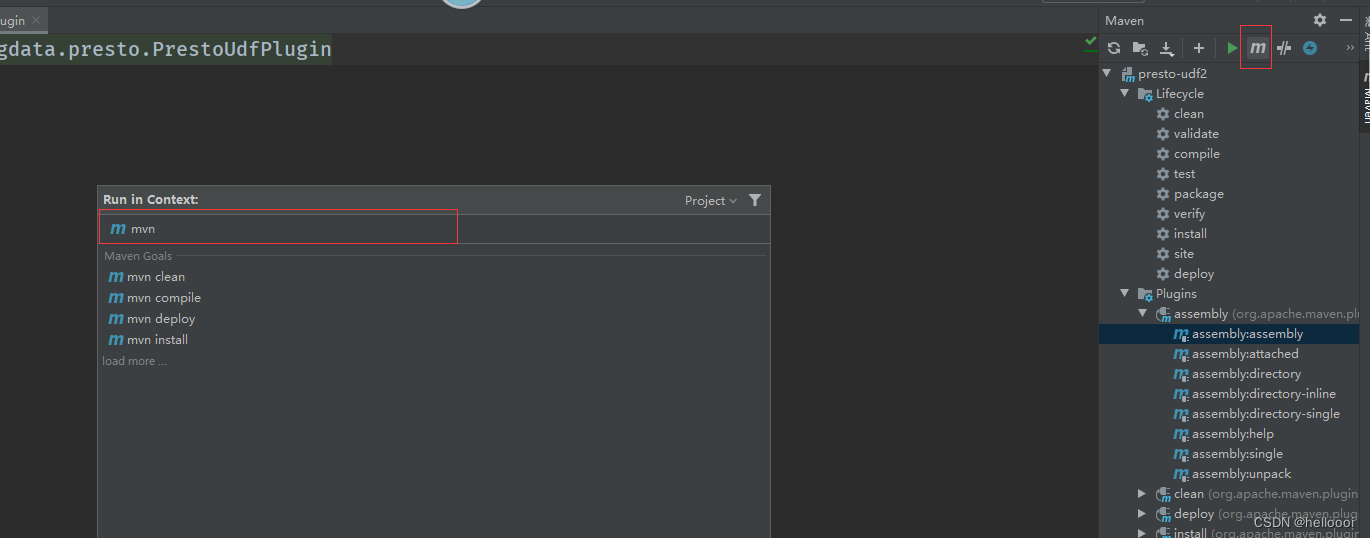
@ScalarFunction("my_upper") // 固定参数,这里面表示函数名的意思,也就我们在使用Presto的时候用的函数名
@Description("我的大小写转换函数") // 函数的注释
@SqlType(StandardTypes.VARCHAR) // 表示数据类型
开发UDAF插件
@AggregationFunction("sumDouble") // 函数名
@Description("this is a sum double") // 注释
@InputFunction 输入的方法注释
@CombineFunction 合并方法注释
@OutputFunction() 输出方法注释
同理,打包上传即可,然后重启Presto就可以使用。
5、漏斗测试
用户深度
select funnel(ctime, 86400*1000*3, event, 'SignUp,AppClick,AppClick,NewsAction') as user_depth
from ods_news1.event
where (
event in ('SignUp')
or (event='AppClick' and element_page='新闻列表页' )
or (event='AppClick' and element_page='内容详情页' )
or (event='NewsAction' and action_type='评论' )
)
and logday>='20201227' and logday<'20201230'
group by distinct_id
完整sql
select funnel_merger(user_depth, 4) as funnel_array from(
select funnel(ctime, 86400*1000*3, event, 'SignUp,AppClick,NewsAction,SignIn') as user_depth
from ods_news1.event
where (
event in ('SignUp')
or (event='AppClick' and element_page='新闻列表页' )
or (event='NewsAction' and action_type='评论' )
or (event='SignIn')
)
and logday>='20200923' and logday<'20200925'
group by distinct_id
);
注意:我的数据里面没有AppPageView数据,所以我在执行的时候没有添加它,但是我添加了两个AppClick就不对了,因为我们在开发UDAF的时候里面设置的是Map类型结构,我们获取Event名称的时候,发现相同Key了,而Map的Key是唯一的,所以你写入Key值得时候,会被覆盖,那么数据就乱了,所以这里我选择了一个SignIn,这个字段也没有的,只是代替一下,所以大家在操作的时候要看一下你的数据是否有这几个事件,不然结果就有可能不对。
相关文章:
2. Presto应用
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 1、Presto安装使用2、事件分析3、漏斗分析4、漏斗分析UDAF开发开发UDF插件开发UDAF插件 5、漏斗测试 1、Presto安装使用 参考官方文档:https://prestodb.io/docs/current/ P…...

工业级安卓PDA超高频读写器手持掌上电脑,RFID电子标签读写器
掌上电脑,又称为PDA。工业级PDA的特点就是坚固,耐用,可以用在很多环境比较恶劣的地方。 随着技术的不断发展,加快了数字化发展趋势,RFID技术就是RFID射频识别及技术,作为一种新兴的非接触式的自动识别技术&…...

Prompt提示工程上手指南:基础原理及实践(一)
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜…...

Redis如何保证缓存和数据库一致性?
背景 现在我们在面向增删改查开发时,数据库数据量大时或者对响应要求较快,我们就需要用到Redis来拿取数据。 Redis:是一种高性能的内存数据库,它将数据以键值对的形式存储在内存中,具有读写速度快、支持多种数据类型…...

学完C/C++,再学Python是一种什么体验?
你好,我是安然无虞。 文章目录 变量及类型变量类型动态类型特性 注释输入输出通过控制台输出通过控制台输入 运算符算术运算符关系运算符逻辑运算符赋值运算符 条件循环语句条件语句语法格式代码案例缩进和代码块空语句pass 循环语句while循环语法格式代码案例 for…...
ssm基于Java的壁纸网站设计与实现论文
目 录 目 录 I 摘 要 III ABSTRACT IV 1 绪论 1 1.1 课题背景 1 1.2 研究现状 1 1.3 研究内容 2 2 系统开发环境 3 2.1 vue技术 3 2.2 JAVA技术 3 2.3 MYSQL数据库 3 2.4 B/S结构 4 2.5 SSM框架技术 4 3 系统分析 5 3.1 可行性分析 5 3.1.1 技术可行性 5 3.1.2 操作可行性 5 3…...

零基础也可以探索 PyTorch 中的上采样与下采样技术
目录 torch.nn子模块Vision Layers详解 nn.PixelShuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.PixelUnshuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.Upsample 用法与用途 使用技巧 注意事项 参数 示例代码 nn.UpsamplingNearest2d …...

代码随想录算法训练营Day23|669. 修剪二叉搜索树、108.将有序数组转换为二叉搜索树、538.把二叉搜索树转换为累加树
目录 669. 修剪二叉搜索树 前言 思路 递归法 108.将有序数组转换为二叉搜索树 前言 递归法 538.把二叉搜索树转换为累加树 前言 递归法 总结 669. 修剪二叉搜索树 题目链接 文章链接 前言 本题承接昨天二叉搜索树的插入和删除操作题目,要对整棵二叉搜索树…...

乱 弹 篇(一)
题记 对于“乱弹”这个词汇的释义,《辞海》上仅有“ 戏曲剧种,亦指声腔 ”8个字。而由于“乱弹 ”的“ 弹”谐音谈”,这就容易让人联想到“乱谈”。不过从文体上看,“乱谈”也非乱七八糟之谈,反倒是“东西南北&#x…...
)
《JVM由浅入深学习【八】 2024-01-12》JVM由简入深学习提升分(JVM的垃圾回收算法)
目录 JVM的垃圾回收算法1. 标记-清除算法(Mark-Sweep)原理步骤优点缺点 2. 复制算法(Copying)原理步骤优点缺点 3. 标记-整理算法(Mark-Compact)原理步骤优点缺点 4. 分代收集算法(Generational…...

在矩阵回溯中进行累加和比较的注意点
1 总结 在回溯时,如果递归函数采用void返回,在入口处使用了sum变量,那么一般在初次调用dfs的地方,这个sum的初始值可能不是0,而是数组的对应指针的值,在比较操作的时候,需要在for循环开始之前进行…...
AI语音机器人的发展
第一代AI语音机器人具体投入研发的开始时间不太清楚,只记得2017年的下半年就已经开始接触到成型的AI语音机器人,并且正式商用。语音识别效果还不多,大多都是接入的科大讯飞或者百度的ASR。 2018年算是AI语音机器人的“青春期”吧,…...
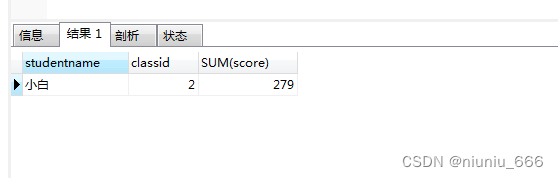
SQL语句错误this is incompatible with sql_mode=only_full_group_by解决方法
一、原理层面 这个错误发生在mysql 5.7.5 版本及以上版本会出现的问题: mysql 5.7.5版本以上默认的sql配置是:sql_mode“ONLY_FULL_GROUP_BY”,这个配置严格执行了"SQL92标准"。 很多从5.6升级到5.7时,为了语法兼容,大部…...

静态长效代理IP和动态短效代理IP有哪些用途?分别适用场景是什么?
静态长效代理IP和动态短效代理IP是两种常见的代理IP类型,它们在用途和适用场景上存在一定的差异。了解它们的特性以及使用场景有助于我们更好地利用代理IP,提高网络访问的效率和安全性。 一、静态长效代理IP 1. 用途 静态长效代理IP是指长期保持稳定的代…...
基于Spring Boot+Vue的课堂管理系统(前后端分离)
该项目完全免费 介绍 基于Spring BootVue的课堂管理系统。前后端分离。包含教师授课管理、学生选退课、聊天室、签到、笔记管理模块等。 技术架构 SpringBoot MyBatis Redis WebSocket VueCLI Axios Element UI 项目特点: 1、后台使用MyBatis连接数据库&…...

供排水管网管理信息化的必要性
供排水管网是城市供水系统的大动脉,它负担者将优质水源输送到最终用户的重要职责,对供水系统有着极其重要的作用。城市供排水管网埋设在地下,规模庞大,仅靠人工难以管理。同时,由于城市的发展,管网连接结构…...

统一格式,无限创意:高效管理不同格式图片批量转换
在数字时代,图片格式的多样性带来了管理上的不便。为了满足不同的需求,我们经常需要将大量图片转换为统一的格式。那么,有没有一种简单、高效的方法来解决这个问题呢?答案是肯定的!今天,我们将为您介绍一款…...
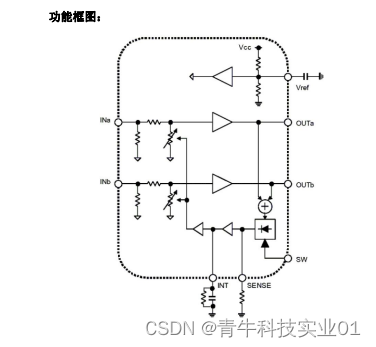
工作电压范围宽的国产音频限幅器D2761用于蓝牙音箱,输出噪声最大仅-90dBV
近年来随着相关技术的不断提升,音箱也逐渐从传统的音箱向智能音箱、无线音箱升级。同时在消费升级的背景下,智能音箱成为人们提升生活品质的方式之一。智能音箱是智能化和语音交互技术的产物,具有点歌、购物、控制智能家居设备等功能…...

中国智造闪耀CES | 木牛科技在美国CES展亮相多领域毫米波雷达尖端方案
素有全球科技潮流“风向标”之称的2024国际消费类电子产品展(CES),于1月9-12日在美国拉斯维加斯会议中心举办。CES是全球最大的消费电子和消费技术展览会之一,汇集了世界各地优秀的消费电子和科技公司,带着最好的产品来…...

亚马逊衣物收纳 梳妆台 收纳柜CPC认证ASTM F2057-23 报告分析
衣物收纳商品是指带有抽屉或铰链门的家具商品,通常是卧室家具,用于存放衣物。该政策适用于独立式服装收纳商品 包括但不限于箱子、五斗橱、抽屉柜、大橱柜、衣橱柜、衣橱、门柜和梳妆台,并且满足以下要求: 衣物收纳商品是指带有抽…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...
)
Midjourney Ash印相参数白皮书(含Adobe RGB/ProPhoto RGB双色域适配矩阵及ICC Profile嵌入规范)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Ash印相技术演进与核心定位 Midjourney Ash印相(Ash Toning)并非传统暗房化学工艺的简单复刻,而是基于生成式AI图像合成模型的一套语义化风格映射机制。它…...

AI攻防时间差:当漏洞发现速度碾压修复速度— 聚焦技术核心
AI攻防时间差:当漏洞发现速度碾压修复速度 — 聚焦技术核心 引言:当两个世界碰撞 2026年5月,对于网络安全领域而言,是一个具有分水岭意义的月份。 一边是360人工智能安全研究院在5月12日发布的重磅报告,首次提出**“AI…...

OPAL:基于OPA的实时策略数据分发与权限治理实践
1. 项目概述:什么是OPAL,以及它解决了什么核心痛点?如果你在负责一个微服务架构或者分布式系统的权限管理,大概率遇到过这样的场景:每次权限策略有更新,都需要重启服务、重新部署,或者等待一个漫…...
:实测137组prompt,仅3组达成真实暗角衰减与中心锐度坍缩)
Midjourney针孔摄影风格实战手册(含--s 120+--stylize微调对照表):实测137组prompt,仅3组达成真实暗角衰减与中心锐度坍缩
更多请点击: https://intelliparadigm.com 第一章:Midjourney针孔摄影风格的本质解构 针孔摄影(Pinhole Photography)并非一种后期滤镜,而是一种基于光学物理原理的成像范式——无镜头、小孔成像、无限景深、软焦边缘…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...

3步打造专业预印本:arxiv.sty LaTeX排版方案实战指南
3步打造专业预印本:arxiv.sty LaTeX排版方案实战指南 【免费下载链接】arxiv-style A Latex style and template for paper preprints (based on NIPS style) 项目地址: https://gitcode.com/gh_mirrors/ar/arxiv-style 在学术研究领域,预印本排版…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...