PyTorch简单理解ChannelShuffle与数据并行技术解析
目录
torch.nn子模块详解
nn.ChannelShuffle
用法与用途
使用技巧
注意事项
参数
示例代码
nn.DataParallel
用法与用途
使用技巧
注意事项
参数
示例
nn.parallel.DistributedDataParallel
用法与用途
使用技巧
注意事项
参数
示例
总结
torch.nn子模块详解
nn.ChannelShuffle
torch.nn.ChannelShuffle 是 PyTorch 深度学习框架中的一个子模块,它用于对输入张量的通道进行重排列。这种操作在某些网络架构中,如ShuffleNet,被用来提高模型的性能和效率。
用法与用途
- 用法:
ChannelShuffle接收一个输入张量,并将其通道划分为多个组(由groups参数指定数量),然后在这些组内部重新排列通道。 - 用途: 主要用于改进卷积神经网络的性能,通过重新排列通道来促进不同组之间的信息交流,增强模型的表达能力。
使用技巧
- 确定组数: 选择
groups参数是关键,它决定了通道划分的方式。通常,这个值需要根据网络的总通道数和特定的应用场景来确定。 - 与分组卷积结合使用:
ChannelShuffle通常与分组卷积(grouped convolution)结合使用,以提高网络的计算效率。
注意事项
- 输入通道数: 输入张量的通道数必须能被
groups整除,以确保通道可以均匀分组。 - 输出形状: 输出张量的形状与输入张量保持一致,但通道的排列顺序不同。
参数
groups(int): 用于在通道中进行分组的组数。
示例代码
import torch
import torch.nn as nn# 初始化 ChannelShuffle 模块
channel_shuffle = nn.ChannelShuffle(2)# 创建一个随机张量作为输入
# 输入张量的形状为 (批大小, 通道数, 高, 宽)
input = torch.randn(1, 4, 2, 2)
print("Input:\n", input)# 应用 ChannelShuffle
output = channel_shuffle(input)
print("Output after Channel Shuffle:\n", output)
这段代码展示了如何使用 ChannelShuffle 模块。首先,创建一个形状为 (1, 4, 2, 2) 的输入张量,然后通过 ChannelShuffle 对其进行处理。这里,通道数为 4,被分为 2 组进行重排列。输出张量的通道顺序与输入有所不同,但形状保持不变。
nn.DataParallel
torch.nn.DataParallel 是 PyTorch 中用于实现模块级数据并行的一个容器。通过在多个设备(如GPU)上分割输入数据来并行化指定模块的应用,这种方式主要用于加速大型模型的训练。
用法与用途
- 用法:
DataParallel将输入数据在批次维度上分割,并在每个设备上复制模型。在前向传播中,每个设备上的模型副本处理输入数据的一部分。在反向传播中,每个副本的梯度被汇总到原始模块中。 - 用途: 主要用于训练时的模型加速,特别是在处理大规模数据集和复杂模型时。
使用技巧
- 批次大小: 批次大小应该大于使用的GPU数量。
- 设备选择: 可以指定要使用的GPU设备,通过
device_ids参数设置。
注意事项
- 推荐使用
DistributedDataParallel: 尽管DataParallel在单节点多GPU训练中有效,但推荐使用DistributedDataParallel,因为它更加高效。 - 模块的参数和缓冲区位置: 在使用
DataParallel前,确保模块的参数和缓冲区位于device_ids[0]指定的设备上。 - 前向传播中的更新将丢失: 在
DataParallel的每次前向传播中,模块都会在每个设备上复制,因此在前向传播中对运行模块的任何更新都将丢失。 - 钩子函数的执行: 模块及其子模块上定义的前向和后向钩子函数将在每个设备上执行多次。
参数
module(Module): 要并行化的模块。device_ids(列表): 要使用的CUDA设备,默认为所有设备。output_device(int or torch.device): 输出的设备位置,默认为device_ids[0]。
示例
import torch
import torch.nn as nn# 假设 model 是一个已经定义的模型
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
input_var = torch.randn(...) # 输入数据
output = net(input_var) # input_var 可以在任何设备上,包括CPU
这个示例代码展示了如何使用 DataParallel 来在多个GPU上并行处理模型。需要注意的是,尽管 DataParallel 在某些场景下依然有效,但在可能的情况下,应优先考虑使用 DistributedDataParallel。
nn.parallel.DistributedDataParallel
torch.nn.parallel.DistributedDataParallel (DDP) 是 PyTorch 中用于实现基于 torch.distributed 包的模块级分布式数据并行性的容器。此容器通过在每个模型副本上同步梯度来提供数据并行性,使用的设备由输入的 process_group 指定,该组默认为整个世界(所有进程)。
用法与用途
- 用法: DDP 将模型副本放置在不同的设备(如GPU)上,并在每个设备上独立地进行前向和反向传播。然后,它同步所有设备上的梯度,以确保每个模型副本的更新是一致的。
- 用途: 主要用于大规模分布式训练,特别是在单节点多GPU或多节点环境中。
使用技巧
- 初始化: 使用 DDP 之前,需要初始化
torch.distributed,通常是通过调用torch.distributed.init_process_group()。 - 多进程: 在具有 N 个GPU的主机上使用 DDP 时,应该生成 N 个进程,每个进程专门在一个 GPU 上工作。
注意事项
- 速度优势: 与
torch.nn.DataParallel相比,DDP 在单节点多GPU数据并行训练中速度更快。 - 输入数据分配: DDP 不会自动分割或分片输入数据;用户负责定义如何进行此操作,例如通过使用
DistributedSampler。 - 梯度约减: DDP 在每个设备上独立计算梯度,然后将这些梯度在所有设备上进行约减(reduce)操作,以保持模型的一致性。
- Backend: 当使用 GPU 时,推荐使用
ncclbackend,这是目前最快的并且在单节点和多节点分布式训练中都推荐使用的。
参数
module(Module): 要并行化的模块。device_ids(列表): CUDA 设备。output_device(int or torch.device): 单设备 CUDA 模块的输出设备。- 其他参数控制如何同步模型和数据。
示例
import torch
import torch.nn as nn
import torch.distributed as dist# 初始化分布式环境
dist.init_process_group(backend='nccl', world_size=4, init_method='...')# 构造模型
model = nn.Linear(10, 10)
ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])# 训练循环
for data, target in dataset:output = ddp_model(data)loss = loss_function(output, target)loss.backward()optimizer.step()
此代码演示了如何使用 DDP 在多个 GPU 上进行模型的并行训练。需要注意的是,使用 DDP 时,每个进程应该独立运行相同的代码,但每个进程会在其指定的 GPU 上处理数据的不同部分。
总结
本文探讨了 PyTorch 框架中的几个关键的神经网络子模块:nn.ChannelShuffle、nn.DataParallel 和 nn.parallel.DistributedDataParallel。nn.ChannelShuffle 通过重排通道来提高网络性能,尤其在 ShuffleNet 架构中显著。nn.DataParallel 和 nn.parallel.DistributedDataParallel 分别提供了模块级数据并行的实现。nn.DataParallel 适用于单节点多GPU训练,而 nn.parallel.DistributedDataParallel 不仅在单节点多GPU训练中表现更佳,也支持大规模的分布式训练。这些模块共同使 PyTorch 成为处理复杂、大规模深度学习任务的强大工具。
相关文章:

PyTorch简单理解ChannelShuffle与数据并行技术解析
目录 torch.nn子模块详解 nn.ChannelShuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.DataParallel 用法与用途 使用技巧 注意事项 参数 示例 nn.parallel.DistributedDataParallel 用法与用途 使用技巧 注意事项 参数 示例 总结 torch.nn子模块详…...
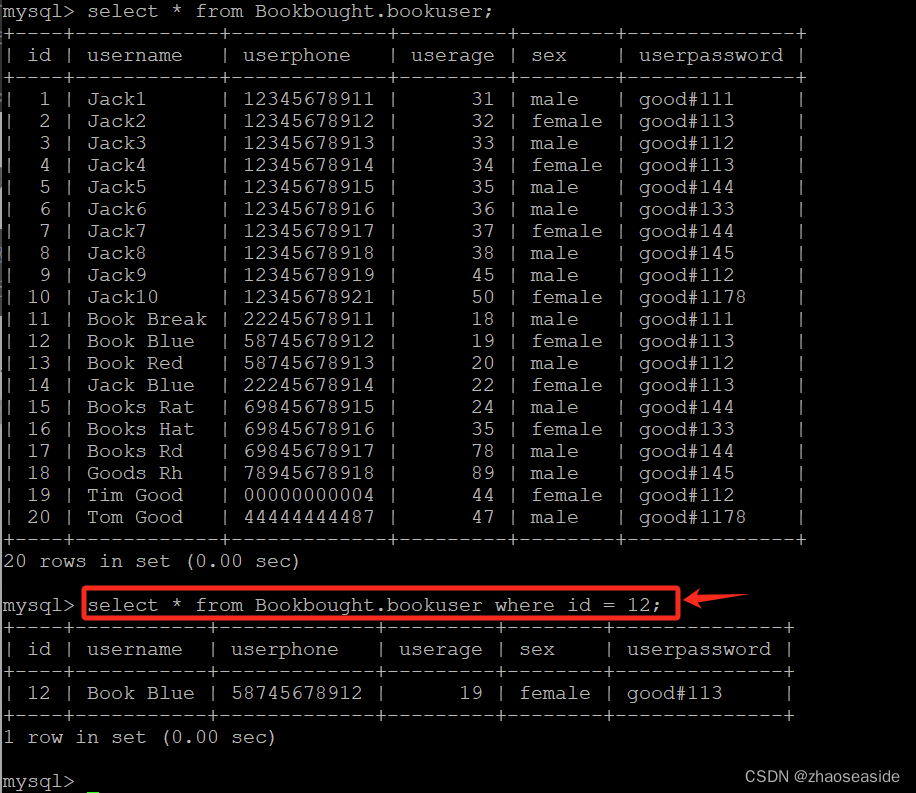
MySQL 8查询语句之查询所有字段、特定字段、去除重复字段、Where判断条件
《MySQL 8创建数据库、数据表、插入数据并且查询数据》里边有我使用到的数据。 再使用下方的语句补充一些数据: insert into Bookbought.bookuser(id,username,userphone,userage,sex,userpassword) values (11,Book Break,22245678911,18,male,good#111); insert…...

LLaMA-Factory添加adalora
感谢https://github.com/tsingcoo/LLaMA-Efficient-Tuning/commit/f3a532f56b4aa7d4200f24d93fade4b2c9042736和https://github.com/huggingface/peft/issues/432的帮助。 在LLaMA-Factory中添加adalora 1. 修改src/llmtuner/hparams/finetuning_args.py代码 在FinetuningArg…...
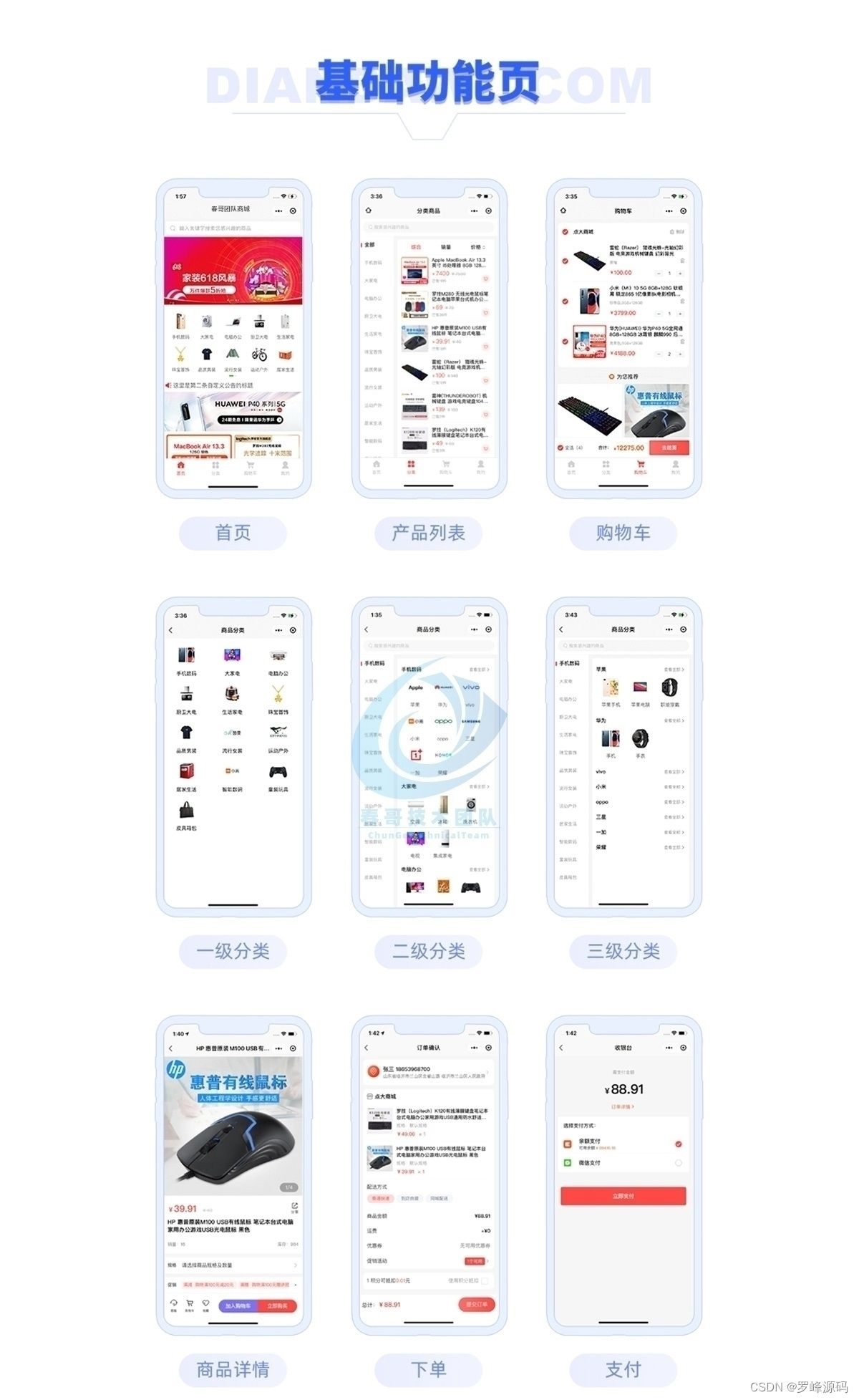
多端多用户万能DIY商城系统源码:自营+多商户入驻商城系统 独立部署 带完整的安装代码包以及搭建教程
电子商务行业日新月异,许多企业希望能够通过线上商城拓展业务。但是,传统商城系统往往无法满足多样化、个性化的需求,而且开发周期长、成本高。罗峰就来给大家分享一款多端多用户万能DIY商城系统源码,搭建简单。 以下是部分代码示…...

Qt 6之七:学习资源
Qt 6之七:学习资源 Qt是一种跨平台的C应用程序开发框架,它提供了一套丰富的工具和库,可以帮助开发者快速构建跨平台的应用程序,用于开发图形用户界面(GUI)和非GUI应用程序。 Qt 6之一:简介、安…...

解决大模型的幻觉问题:一种全新的视角
在人工智能领域,大模型已经成为了一个重要的研究方向。然而,随着模型规模的不断扩大,一种新的问题开始浮出水面,那就是“幻觉”问题。这种问题的出现,不仅影响了模型的性能,也对人工智能的发展带来了新的挑…...

mysql进阶-重构表
目录 1. 原因 2. 如何重构表呢? 2.1 命令1: 2.2 命令2: 2.3 命令3: 1. 原因 正常的业务开发,为什么需要重构表呢? 原因1:某张表存在大量的新增和删除操作,导致表经历过大量的…...

Element-ui图片懒加载
核心代码 <el-image src"https://img-blog.csdnimg.cn/direct/2236deb5c315474884599d90a85d761d.png" alt"我是图片" lazy><img slot"error" src"https://img-blog.csdnimg.cn/direct/81bf096a0dff4e5fa58e5f43fd44dcc6.png&quo…...

Linux系统——DNS解析详解
目录 一、DNS域名解析 1.DNS的作用 2.域名的组成 2.1域名层级结构关系特点 2.2域名空间构成 2.3域名的四种不同类型 2.3.1延伸 2.3.2总结 3.DNS域名解析过程 3.1递归查询 3.2迭代查询 3.3一次DNS解析的过程 4.DNS系统类型 4.1缓存域名服务器 4.2主域名服务器 4…...
初识Ubuntu
其实还是linux操作系统 命令都一样 但是在学习初级阶段,我还是将其分开有便于我的学习和稳固。 cat 查看文件 命令 Ubuntu工作中经常是用普通用户,在需要时才进行登录管理员用户 sudn -i 切换成管理用户 我们远程连接时 如果出现 hostname -I没有出现…...

Casper Network (CSPR)2024 年愿景:通过投资促进增长
Casper Network (CSPR)是行业领先的 Layer-1 区块链网络之一,通过推出了一系列值得关注的技术改进和倡议,已经为 2024 年做好了准备。 在过去的一年里,Casper Network (CSPR)不断取得里程碑式的进展,例如推…...

《MySQL系列-InnoDB引擎06》MySQL锁介绍
文章目录 第六章 锁1 什么是锁2 lock与latch3 InnoDB存储引擎中的锁3.1 锁的类型3.2 一致性非锁定读3.3 一致性锁定读3.4 自增长与锁3.5 外键和锁 4 锁的算法4.1 行锁的三种算法4.2 解决Phantom Problem 5 锁问题5.1 脏读5.2 不可重复读5.3 丢失更新 6 阻塞7 死锁 第六章 锁 开…...

获取多个PDF文件的内容并保存到excel上
# shuang # 开发时间:2023/12/9 22:03import pdfplumber import re import os import pandas as pd import datetimedef re_text(bt, text):# re 搜索正则匹配 包含re.compile包含的文字内容m1 re.search(bt, text)if m1 is not None:return re_block(m1[0])return…...

深入了解网络流量清洗--使用免费的雷池社区版进行防护
随着网络攻击日益复杂,企业面临的网络安全挑战也在不断增加。在这个背景下,网络流量清洗成为了确保企业网络安全的关键技术。本文将探讨雷池社区版如何通过网络流量清洗技术,帮助企业有效应对网络威胁。 ![] 网络流量清洗的重要性&#x…...
)
【FFMPEG应用篇】基于FFmpeg的转码应用(FLV MP4)
方法声明 extern "C" //ffmpeg使用c语言实现的,引入用c写的代码就要用extern { #include <libavcodec/avcodec.h> //注册 #include <libavdevice/avdevice.h> //设备 #include <libavformat/avformat.h> #include <libavutil/…...
LInux初学之路linux的磁盘分区/远程控制/以及关闭图形界面/查看个人身份
虚拟机磁盘分配 hostname -I 查看ip地址 ssh root虚拟就ip 远程连接 win10之后才有 远程控制重新启动 reboot xshell 使用(个人和家庭版 免费去官方下载) init 3 关闭界面 减小内存使用空间 init 5 回复图形界面 runlevel显示的是状态 此时和上…...
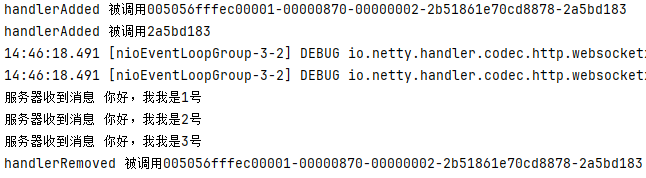
Netty 介绍、使用场景及案例
Netty 介绍、使用场景及案例 1、Netty 介绍 https://github.com/netty/netty Netty是一个高性能、异步事件驱动的网络应用程序框架,用于快速开发可扩展的网络服务器和客户端。它是一个开源项目,最初由JBoss公司开发,现在由社区维护。Netty的…...

小游戏选型(一):游戏化设计助力直播间互动和营收
一、社交直播间小游戏火爆 大家好,作为一个技术宅和游戏迷,今天来聊聊近期爆火的社交直播间小游戏的潮流。喜欢冲浪玩社交产品的小伙伴会发现,近期各大平台都推出了直播间社交小游戏,直播间氛围火爆,小游戏玩法简单&a…...

社区嵌入式服务设施建设为社区居家养老服务供给增加赋能
近年来,沈阳市浑南区委、区政府牢记在辽宁考察时的重要指示精神,认真践行以人民为中心的发展思想,聚集“一老一小”民生关切,统筹推进以社区为骨干结点的养老服务探索实践。围绕“品质养老”民生服务理念,针对社区老年…...
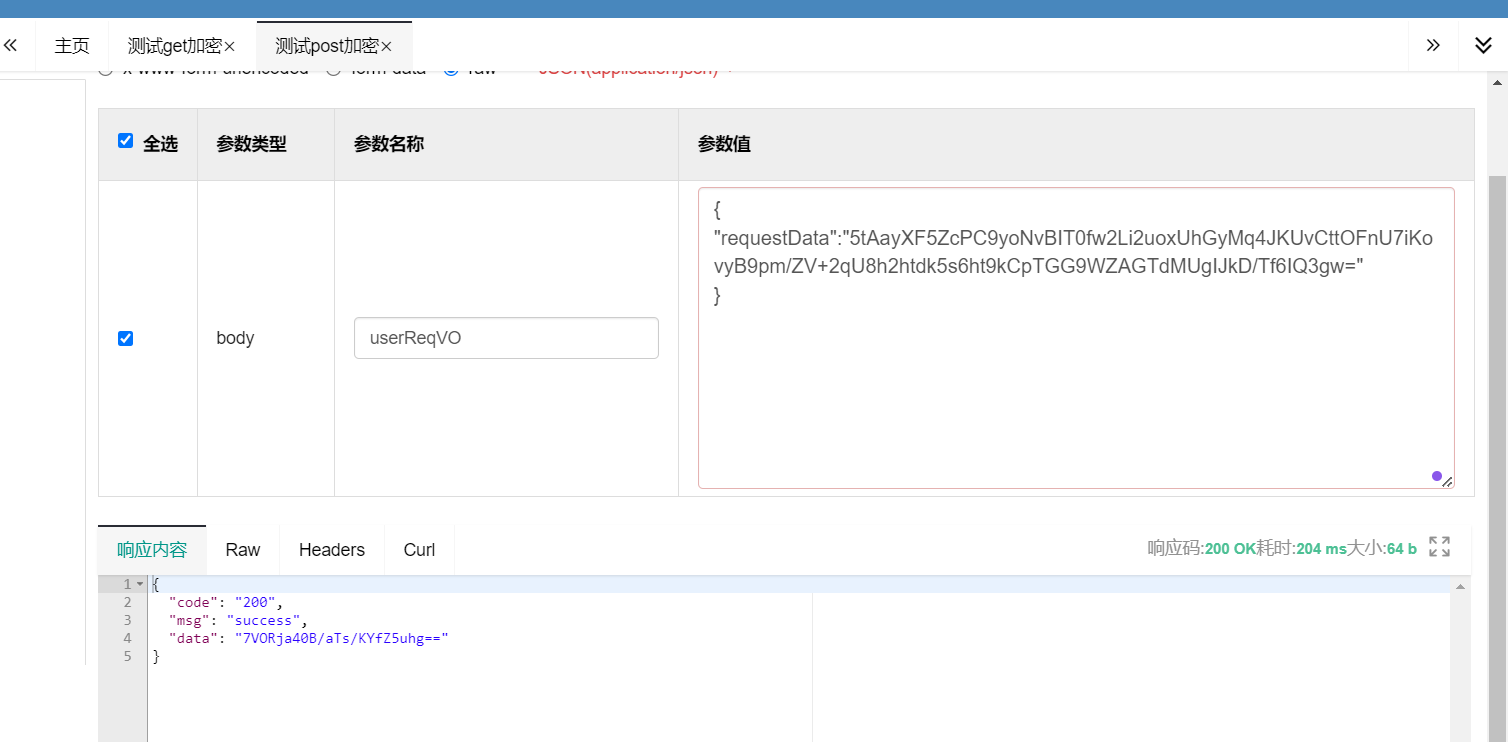
SpringBoot请求参数加密、响应参数解密
SpringBoot请求参数加密、响应参数解密 1.说明 在项目开发工程中,有的项目可能对参数安全要求比较高,在整个http数据传输的过程中都需要对请求参数、响应参数进行加密,也就是说整个请求响应的过程都是加密处理的,不在浏览器上暴…...

STM32嵌入式开发入门:从硬件配置到项目实战的完整学习路径
1. 项目概述:从零到一,如何构建你的STM32知识体系很多刚接触嵌入式开发的朋友,拿到一块STM32开发板,看着满屏的英文手册和复杂的库函数,第一反应往往是“从哪开始?”。这感觉就像面对一座零件齐全但没图纸的…...
)
类与对象(三)
再谈构造函数构造函数体赋值在创建对象时,编译器会通过调用构造函数,给对象中的各个成员变量一个合适的初始值:调用该构造函数后,对象中的每个成员变量都有了一个初始值,但是构造函数中的语句只能将其称作为赋初值&…...
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案
Point Transformer V3 牙齿语义分割测试结果为0问题:完整调试与修复方案 摘要 Point Transformer V3(PTv3)是CVPR 2024发布的高效点云处理模型,在语义分割任务中表现出色。然而,在16类牙齿语义分割任务的测试阶段,模型输出全部为0的问题却常常困扰开发者。本文将从数据…...

告别apt install:手把手教你为Ubuntu 20.04上的ROS2 Humble手动编译安装serial串口库
从ROS1到ROS2:深入解析串口库手动编译安装的技术内幕 在机器人操作系统(ROS)的演进历程中,ROS2的诞生标志着整个生态系统的重大升级。对于刚从ROS1迁移到ROS2的中级开发者而言,最直观的冲击莫过于包管理方式的变化。当你习惯性地输入apt inst…...

别再只盯着PageRank了!用Python实战特征向量、Katz和PageRank三大中心性算法
用Python实战三大中心性算法:特征向量、Katz与PageRank的深度对比 当我们需要识别社交网络中最有影响力的用户,或是优化网页排序结果时,图论中的中心性算法往往能提供关键洞见。本文将带您用Python实现三种经典的中心性算法——特征向量中心性…...
)
开关电源传导EMI超标?手把手教你用π型滤波器搞定(附SCT2450实测数据)
开关电源传导EMI超标?手把手教你用π型滤波器搞定(附SCT2450实测数据) 在电源设计领域,传导EMI超标是工程师们经常遇到的棘手问题。当你的产品在EMC实验室测试失败时,那种挫败感相信每个硬件工程师都深有体会。传导噪声…...

3mux常见问题解决:10个用户最常遇到的错误及其修复方法
3mux常见问题解决:10个用户最常遇到的错误及其修复方法 【免费下载链接】3mux Terminal multiplexer inspired by i3 项目地址: https://gitcode.com/gh_mirrors/3m/3mux 3mux是一款受i3启发的终端复用器,为用户提供高效的终端窗口管理体验。然而…...

Steam-Economy-Enhancer多货币支持:全球交易定价策略
Steam-Economy-Enhancer多货币支持:全球交易定价策略 【免费下载链接】Steam-Economy-Enhancer Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/st/Steam-Economy-Enhancer Steam-Economy-Enhancer是一款强大的S…...


ElevenLabs语音克隆失败率骤降63%的关键:训练集音频信噪比阈值、时长分布与语速归一化黄金公式
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的底层架构演进 ElevenLabs 的语音合成系统并非基于传统拼接或参数化 TTS 框架,而是构建在端到端神经声码器与自监督语音表征联合优化的混合架构之上。其核心演进路径…...