sqoop的安装与使用
Sqoop是一个用于在hadoop与mysql之间传输数据的工具
Sqoop 环境搭建
(1)上传安装包:sqoop-1.4.6-cdh5.14.2.tar.gz到/opt/software
(2)解压安装包:tar -zxf sqoop-1.4.6-cdh5.14.2.tar.gz -C /opt/install/
(3)创建软连接:ln -s /opt/install/sqoop-1.4.6-cdh5.14.2/ /opt/install/sqoop
(4)配置环境变量:vi /etc/profile
export SQOOP_HOME=/opt/install/sqoop
export PATH=$SQOOP_HOME/bin:$PATH
(5)让配置文件生效:source /etc/profile
(6)切换到sqoop根目录下的conf目录,复制并改名配置文件:cp sqoop-env-template.sh sqoop-env.sh
(7)修改配置文件sqoop-env.sh,在文件末尾追加以下内容:
export HADOOP_COMMON_HOME=/opt/install/hadoop
export HADOOP_MAPRED_HOME=/opt/install/hadoop
export HIVE_HOME=/opt/install/hive
export ZOOCFGDIR=/opt/install/zookeeper
export HBASE_HOME=/opt/install/hbase
(8)复制以下文件到 sqoop 的 lib 目录下
mysql-connector-java-5.1.27-bin.jar
java-json.jar
hive-common-1.1.0-cdh5.14.2.jar
hive-exec-1.1.0-cdh5.14.2.jar
(9)验证 sqoop 配置是否正确:sqoop help
(10)测试 Sqoop 是否能够成功连接数据库:
sqoop list-databases --connect jdbc:mysql://hadoop101:3306/ --username root --password 123
(11)做快照
连接数据库获取可用的数据库名称
sqoop list-databases \
--connect jdbc:mysql://hadoop101:3306 \
--username root \
--password 123
连接数据库获取指定数据库中的所有数据表
sqoop list-tables \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--userrname root \
--password 123
执行导入命令
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table customers \
--target-dir /data/retail_db/customers \
--num-mappers 1
从mysql导入指定表中带条件的数据到hdfs 1
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table orders \
--where 'order_id<500' \
--delete-target-dir \
--target-dir /data/retail_db/orders \
--num-mappers 1
从mysql导入指定表中字段且带条件的数据到hdfs 2
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table orders \
--where 'order_id<500' \
--columns order_id,order_data,order_customer_id \
--delete-target-dir \
--target-dir /data/retail_db/orders \
--num-mappers 1
从mysql导入指定查询语句的数据到hdfs【注:单双引号的区别,必须有where且以and $CONDITIONS结尾】
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--query 'select * from orders where order_status!="CLOSED" and $CONDITIONS' \
--delete-target-dir \
--target-dir /data/retail_db/orders \
--num-mappers 1
或
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--query "select * from orders where order_status!='CLOSED' and \$CONDITIONS" \
--delete-target-dir \
--target-dir /data/retail_db/orders \
--num-mappers 3 \
--split-by order_id
在sqoop中第二次增量导入【其中last-value是大于的关系】
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/test \
--username root \
--password 123 \
--table student \
--target-dir /data/retail_db/student \
--incremental append \
--check-column id \
--last-value 2 \
--num-mappers 1
# 查看数据
hdfs dfs -cat /data/retail_db/student/*
# 结果
# 增加数据
insert into student values(5,'tim','male'),(6,'jim','male');
# PPT 演示
# 第一次全量导入
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--query "select * from orders where order_date between '2013-07-01' and '2014-04-15' and \$CONDITIONS" \
--delete-target-dir \
--target-dir /data/retail_db/orders \
--num-mappers 3 \
--split-by order_id
# 第二次增量导入
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table orders \
--incremental append \
--check-column order_date \
--last-value 2014-04-15 \
--target-dir /data/retail_db/orders \
--num-mappers 3 \
--split-by order_id
# 导入mysql数据到hive中
# 启动hive
hiveserver2 &
# 进入客户端
beeline -ujdbc:hive2://hadoop101:10000 -nroot
# 创建数据库
create database retail_db;
# 导入数据
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table orders \
--where 'order_id<=10' \
--target-dir /data/retail_db/orders \
--delete-target-dir \
--hive-import \
--hive-database retail_db \
--hive-table orders \
--hive-overwrite \
--num-mappers 1
# 在hvie中查看表名称
show tables;
+-----------+--+
| tab_name |
+-----------+--+
| orders |
+-----------+--+
# 在hive中查看表结构
desc orders;
+--------------------+------------+----------+--+
| col_name | data_type | comment |
+--------------------+------------+----------+--+
| order_id | int | |
| order_date | string | |
| order_customer_id | int | |
| order_status | string | |
+--------------------+------------+----------+--+
# 在hive中查看表数据
select * from orders;
+------------------+------------------------+---------------------------+----------------------+--+
| orders.order_id | orders.order_date | orders.order_customer_id | orders.order_status |
+------------------+------------------------+---------------------------+----------------------+--+
| 1 | 2013-07-25 00:00:00.0 | 11599 | CLOSED |
| 2 | 2013-07-25 00:00:00.0 | 256 | PENDING_PAYMENT |
| 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE |
| 4 | 2013-07-25 00:00:00.0 | 8827 | CLOSED |
| 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE |
| 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE |
| 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE |
| 8 | 2013-07-25 00:00:00.0 | 2911 | PROCESSING |
| 9 | 2013-07-25 00:00:00.0 | 5657 | PENDING_PAYMENT |
| 10 | 2013-07-25 00:00:00.0 | 5648 | PENDING_PAYMENT |
+------------------+------------------------+---------------------------+----------------------+--+
# 导入mysql数据到hive分区
# 删除存在的表
drop table if exists orders;
# 执行导入
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--query 'select order_id,order_customer_id,order_status from orders where order_date="2014-07-24" and $CONDITIONS' \
--target-dir /data/retail_db/orders/order_date=2014-07-24 \
--delete-target-dir \
--hive-import \
--create-hive-table \
--hive-table retail_db.orders \
--hive-partition-key order_date \
--hive-partition-value 2014-07-24 \
--num-mappers 1
# 查看是否创建表
show tables;
# 查看表结构
desc orders;
# 查看数据
select * from orders;
# 查看分区
show partitions orders;
+------------------------+--+
| partition |
+------------------------+--+
| order_date=2014-07-24 |
+------------------------+--+
# 通过sqoop job实现“自动”增量导入功能
# 创建密码文件
echo -n 123 > mysqlpwd
# 创建新的job
sqoop job \
--create job01 \
-- import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/test \
--username root \
--password-file 'file:///root/mysqlpwd' \
--table student \
--target-dir /data/retail_db/student \
--hive-import \
--hive-database retail_db \
--hive-table student \
--incremental append \
--check-column id \
--last-value 0 \
--num-mappers 1
# 查看job
sqoop job --list
# 执行job,此时为全量导入
sqoop job --exec job01
# 测试在mysql中添加一条新数据
insert into student values(7,'rose','female');
# 执行job,此时为增量导入
sqoop job --exec job01
# 在hive中查看数据
select * from student;
# 导入mysql数据到hbase
# 启到hbase服务
zkServer.sh start
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
# 执行sqoop
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/retail_db \
--username root \
--password 123 \
--table products \
--hbase-create-table \
--hbase-table products \
--hbase-row-key product_id \
--column-family data \
--num-mappers 1
# 打开hbase客户端
hbase shell
# 查看数据
scan 'products'
# 导出hdfs数据到mysql
# 创建mysql表
use test;
create table student2 like student;
# 执行sqoop导入mysql中的student表中数据到hdfs的student表
sqoop import \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/test \
--username root \
--password 123 \
--table student \
--target-dir /data/retail_db/student \
--delete-target-dir \
--num-mappers 1
# 执行sqoop导出hdfs中student表中的数据到mysql的student2表
sqoop export \
--driver com.mysql.jdbc.Driver \
--connect jdbc:mysql://hadoop101:3306/test \
--username root \
--password 123 \
--table student2 \
--export-dir '/data/retail_db/student' \
--num-mappers 1
# 查看数据
select * from student2;
相关文章:

sqoop的安装与使用
Sqoop是一个用于在hadoop与mysql之间传输数据的工具 Sqoop 环境搭建 (1)上传安装包:sqoop-1.4.6-cdh5.14.2.tar.gz到/opt/software (2)解压安装包:tar -zxf sqoop-1.4.6-cdh5.14.2.tar.gz -C /opt/install/ (3)创建软连接:ln -s /opt/install/sqoop-1.4.6-cdh5.14.2/ /opt/ins…...

【docker】Docker Stack 详细使用及注意事项
一、什么是 Docker Stack Docker Stack 是 Docker Swarm 环境中用于管理一组相关服务的工具。它使得在 Swarm 集群中部署、管理和扩展一组相互关联的服务变得简单。主要用于定义和编排容器化应用的多个服务。以下是 Docker Stack 的一些关键特点: 服务集合…...

Android开发基础(四)
Android开发基础(四) 本篇将从Android数据存储方式去理解Android开发。 Android数据存储方式 Android提供了多种数据存储方式。 一、SharedPreferences存储 主要用于存储一些简单的配置信息,如登录账号密码等; 这种存储方式采…...

HTML5+CSS3+JS小实例:音频可视化
实例:音频可视化 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><m…...

【写作】短篇《相遇与相守》
文章目录 前言背景角色故事梗概 第一章 缘分的邂逅第二章 心动的瞬间第三章 甜蜜的日子第四章 误会与和解第五章 共度风雨 前言 背景 时代背景 现代,一个充满忙碌和喧嚣的都市。这个都市是许多年轻人追求梦想和奋斗的地方,但也是许多人渴望寻找真挚感情…...
2024年最新软件测试面试题
Part1 1、你的测试职业发展是什么?【文末有面试文档免费领取】 测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前3年积累测试经验,按如何做…...
instanceof、对象类型转化、static关键字
instanceof 与 对象类型转换 instanceof是判断一个对象是否与一个类有关系的关键字 先看引用类型,再看实际类型 *例子:obj instanceof A 先看obj的类型是否与A有关联,无关联则报错,有关联则判断obj的实际类型 因为obj的实际类…...

学习笔记-python文件基本操作
1.文件的基本操作 open()打开函数 语法 : open(name,mode) name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。 mode:设置打开文件的模式(访问模式):只读、写入、追加等。 # 打开文件open(): 如果报FileNotFoundError,文件路…...

【Scala】——流程控制
1 if-else 分支控制 让程序有选择的的执行,分支控制有三种:单分支、双分支、多分支 1.1单分支 if (条件表达式) {执行代码块 }1.2 双分支 if (条件表达式) {执行代码块 1 } else {执行代码块 2 }1.3 多分支 if (条件表达式1) {执行代码块 1 } else …...
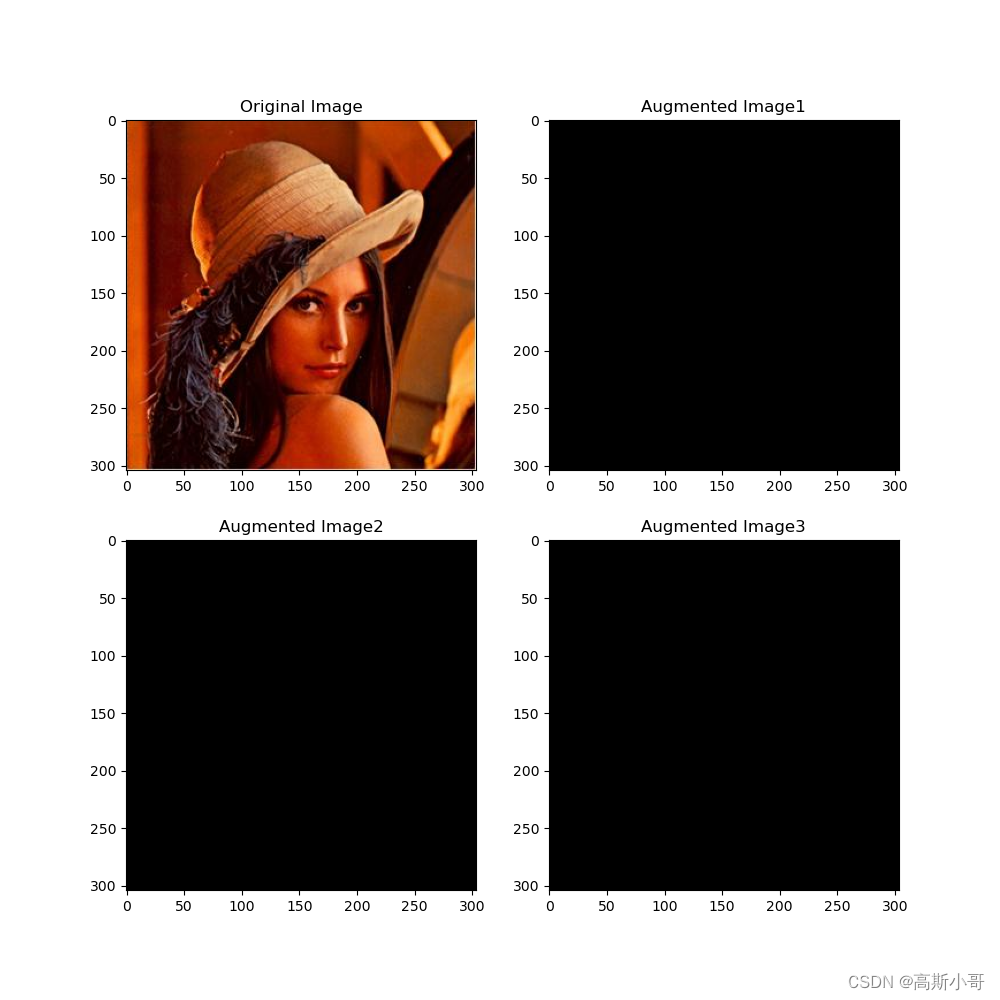
imgaug库指南(20):从入门到精通的【图像增强】之旅
引言 在深度学习和计算机视觉的世界里,数据是模型训练的基石,其质量与数量直接影响着模型的性能。然而,获取大量高质量的标注数据往往需要耗费大量的时间和资源。正因如此,数据增强技术应运而生,成为了解决这一问题的…...

最新AI绘画Midjourney绘画提示词Prompt大全
一、Midjourney绘画工具 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭…...
)
编写一个简单的服务和客户端(C++)
背景 当节点使用服务进行通信时,发送数据请求的节点称为客户端节点,响应请求的节点称为服务节点。请求和响应的结构由.srv文件确定。 这里使用的例子是一个简单的整数加法系统;一个节点请求两个整数之和,另一个节点响应结果。 …...

InseRF: 文字驱动的神经3D场景中的生成对象插入
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

类厂,变长参数,序列化
目的 在记录nav2中的各类信息,保存到文件中,以便后面回放来分析算法的编程中发现。 各种信息记录的数据不同,可能还会有变化,所以决定采用类厂模式,参见C++设计模式入门 记录的基类 有个信息记录的基类,不同的记录对应不同的子类。 enum rcdType{RT_NA,RT_nav2Info,R…...

LLK的2023年度总结
文章目录 一月二月三月四月五月六月七月八月九月十月十一月十二月 一月 此时的俺还在沉浸在蓝桥杯的练习和女朋友的甜蜜期,感觉没啥大长进。然后荣幸地知道了自己C语言实验因为某种非技术原因而挂科了。此时自己地目标由保研自然地转换到考研比赛就业的方向了。接着…...
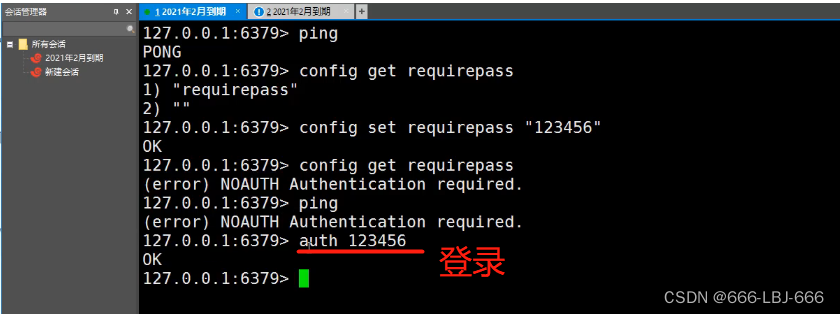
Redis-浅谈redis.conf配置文件
Redis.conf Redis.conf是Redis的配置文件,它包含了一系列用于配置Redis服务器行为和功能的选项。 以下是Redis.conf中常见的一些选项配置: bind: 指定Redis服务器监听的IP地址,默认为127.0.0.1,表示只能本地访问,可以…...

【liunx】线程池+单例模式+STL,智能指针和线程安全+其他常见的各种锁+读者写者问题
线程池单例模式STL,智能指针和线程安全其他常见的各种锁读者写者问题 1.线程池2.线程安全的单例模式3.STL,智能指针和线程安全4.其他常见的各种锁4.读者写者问题 喜欢的点赞,收藏,关注一下把! 1.线程池 目前我们学了挂起等待锁、条件变量、信…...

Golang的API项目快速开始
开启一个简单的API服务。 golang的教程网上一大堆,官网也有非常详细的教程,这里不在赘述这些基础语法教程,我们意在快速进入项目开发阶段。 golang好用语法教程传送门: m.runoob.com/go/ 编写第一个API 前提:按照上一…...
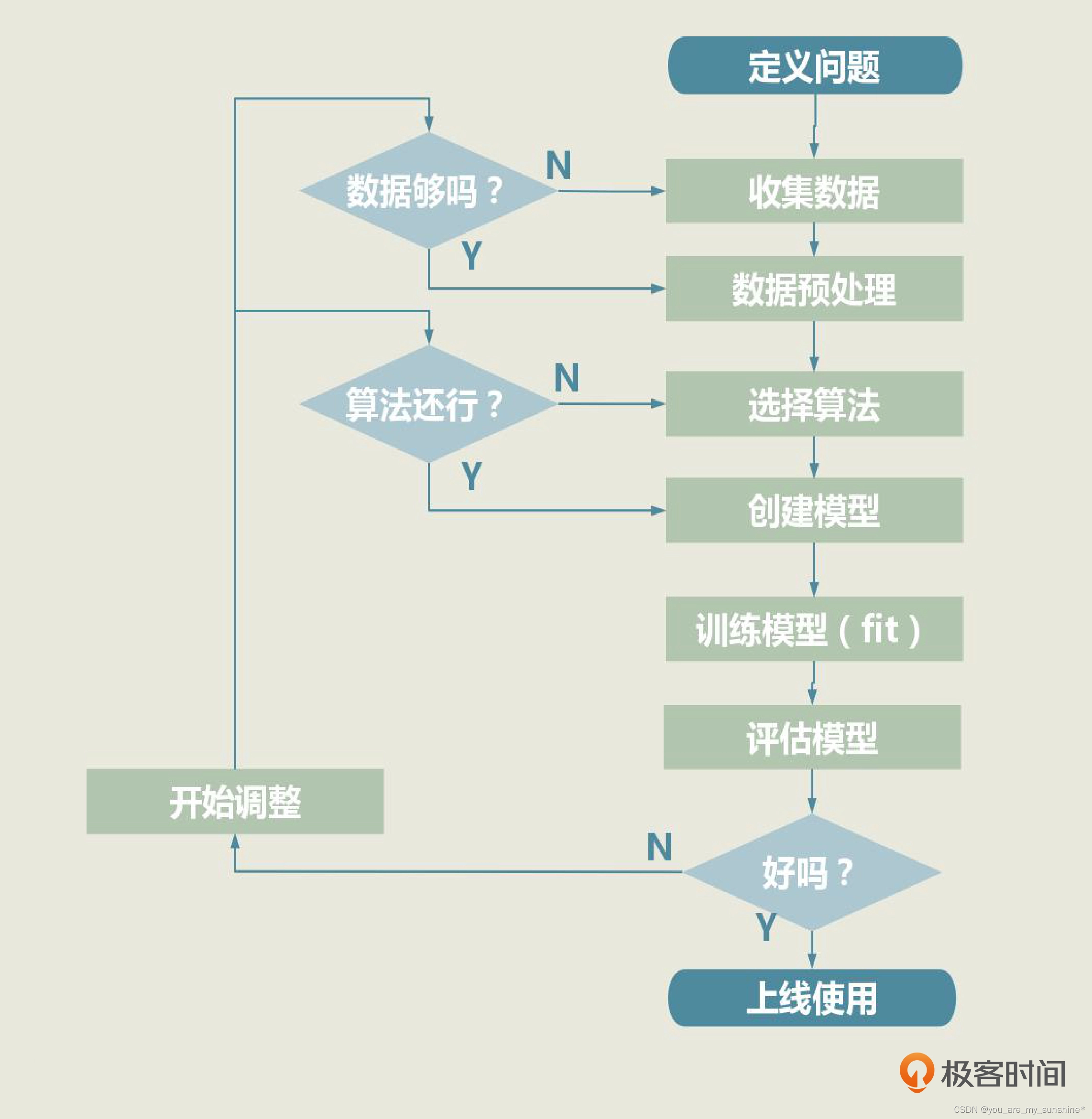
机器学习_实战框架
文章目录 介绍机器学习的实战框架1.定义问题2.收集数据和预处理(1).收集数据(2).数据可视化(3).数据清洗(4).特征工程(5).构建特征集和标签集(6).拆分训练集、验证集和测试集。 3.选择算法并建立模型4.训练模型5.模型的评估和优化 介绍机器学习的实战框架 一个机器学习项目从开…...
Java8常用新特性
目录 简介 1.默认方法 2..Lambda表达式 3.Stream API 4.方法引用 5.Optional类 简介 Java 8是Java编程语言的一个重要版本,引入了许多令人兴奋和强大的新特性。这些特性使得Java程序更加现代化、灵活和高效。让我们一起来探索一些Java 8的常用新特性吧&#…...

158页精品PPT | 某大型研发制造集团信息化IT规划整体方案
许多公司在数字化转型过程中会遇到一些共同的挑战,比如数据孤岛、技术更新慢、员工技能不足等。这些问题会导致企业效率低下,难以适应市场变化。针对这些问题,我们提出了一套解决方案,核心目标是帮助企业提升数字化水平࿰…...
)
像素皇城灵蛇贺岁:5分钟部署你的赛博春联生成器(保姆级教程)
像素皇城灵蛇贺岁:5分钟部署你的赛博春联生成器(保姆级教程) 1. 前言:当传统春节遇上赛博美学 春节贴春联是延续千年的传统习俗,但你是否想过用AI技术为这个传统注入新的活力?今天我们要介绍的"像素…...

公交客流统计摄像机系统,能替代监控摄像头吗?
公交车内乘客流量大,安全隐患较多,多年来监控摄像头已经成为车内的标配。随着科技技术的进步,如今公交客流统计摄像机系统,也逐渐部署到了各地公交上。那么公交客流统计摄像机系统,能替代监控摄像头吗?如今…...

Chandra AI在教育领域的应用:智能学习助手开发
Chandra AI在教育领域的应用:智能学习助手开发 1. 引言 想象一下这样的场景:一个学生在深夜复习功课,遇到一道数学难题却找不到老师请教;一个上班族想学习新技能,但时间碎片化难以系统学习;一个老师面对几…...

灵毓秀-牧神-造相Z-Turbo进阶玩法:结合提示词生成不同风格的灵毓秀
灵毓秀-牧神-造相Z-Turbo进阶玩法:结合提示词生成不同风格的灵毓秀 1. 认识灵毓秀-牧神-造相Z-Turbo 1.1 模型特点概述 灵毓秀-牧神-造相Z-Turbo是一款基于Xinference部署的专用文生图模型,专注于生成《牧神记》中灵毓秀这一角色的高质量图像。相比通…...
)
告别台式机没麦克风的尴尬:用SonoBus+VB-Cable把手机秒变无线麦(保姆级配置)
台式机零成本无线麦克风方案:SonoBus与VB-Cable实战指南 你是否遇到过这样的尴尬时刻——台式电脑突然需要语音沟通,却发现没有麦克风?无论是紧急会议、游戏开黑还是直播互动,这种硬件缺失带来的困扰可能让你措手不及。本文将介绍…...

**发散创新:基于微应用架构的轻量级权限控制实战设计**在现代前端开
发散创新:基于微应用架构的轻量级权限控制实战设计 在现代前端开发中,**微应用(Micro Frontend)*8 已成为构建复杂单页应用(SPA)的标准方案之一。它允许团队独立开发、部署和维护各自的功能模块,…...

Phi-4-mini-reasoning案例分享:用逻辑题测试模型对‘必要条件’的理解深度
Phi-4-mini-reasoning案例分享:用逻辑题测试模型对必要条件的理解深度 1. 模型能力定位 Phi-4-mini-reasoning是专为推理任务优化的文本生成模型,其核心优势在于处理需要多步逻辑推导的问题。与通用对话模型不同,它更擅长处理以下类型任务&…...

如何用Wi-Fi信号实现非接触检测:ESP-CSI完整指南
如何用Wi-Fi信号实现非接触检测:ESP-CSI完整指南 【免费下载链接】esp-csi Applications based on Wi-Fi CSI (Channel state information), such as indoor positioning, human detection 项目地址: https://gitcode.com/GitHub_Trending/es/esp-csi 想要让…...

AzurLaneAutoScript:碧蓝航线全自动游戏助手,释放您的双手与时间
AzurLaneAutoScript:碧蓝航线全自动游戏助手,释放您的双手与时间 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAuto…...