LightGBM原理和调参
背景知识
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,具有支持高效率的并行训练、更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以处理海量数据等优点。
普通的GBDT算法不支持用mini-batch的方式训练,在每一次迭代的时候,都需要多次遍历整个训练数据。这样如果把整个训练数据装进内存则会限制训练集的大小,如果不装进内存,反复的读写数据又会大量消耗时间,特别不适合工业级海量数据的应用。LGBM的提出就是为了解决这些问题。
XGBoost
在LGBM提出之前,应用最广泛的GBDT工具就是XGBoost了,它是基于预排序的决策树算法。这种构建决策树的算法基本思想是:
- 首先,对所有特征都按特征的数值进行预排序;
- 其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最佳分割点;
- 最后,在找到一个特征的最佳分割点后,将数据分裂成左右子节点。
这样预排序算法的优点是能精确地找到分割点,但是缺点也很明显:
- 空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。
- 时间开销大。在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- 对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层生成树的时候 ,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
LGBM的优化
为了弥补XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,LGBM在传统的GBDT算法上进行了如下优化:
- 基于Histogram的决策树算法。
- 单边梯度采样(Gradient-based One-side Sampling, GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征节省了不少时间和空间上的开销。
- 互斥特征捆绑(Exclusive Feature Bundling, EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
- 带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长(level-wise)的决策树生长策略,因为它不加区分的对待同一层叶子,带来了很多没必要的开销,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LGBM使用了带有深度限制的按叶子生长(leaf-wise)算法。
- 直接支持类别特征(Categorical Feature)。
- 支持高效并行。
- Cache命中率优化。
LGBM基本原理
LGBM是基于Histogram的决策树算法。直方图算法的基本思想是:先将连续的浮点特征值离散成K个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
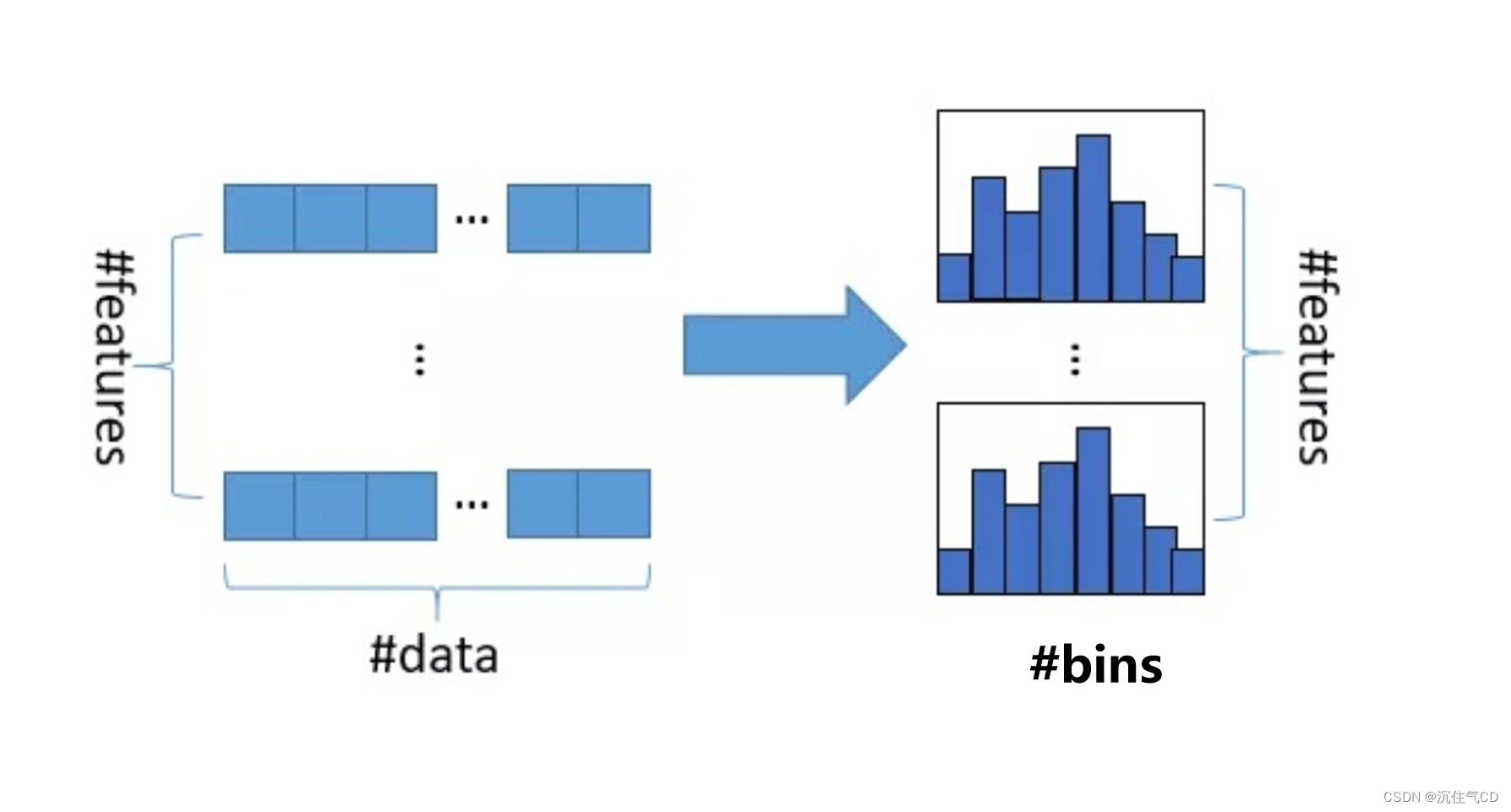
直方图算法的简单理解为:首先确定对于每个特征需要多少个箱子(bin)并为每个箱子分配一个整数;然后将浮点数的范围均分成若干区间,区间个数与箱子个数相等,将属于该箱子的样本数据更新为箱子的值;最后用直方图(#bins)表示。该算法本质上很简单,就是将大规模的数据放在了直方图中,就是直方图统计。
特征离散化具有很多优点,如存储方便、运算更快、鲁棒性强、模型更加稳定等。对直方图算法来说最直接的有以下两个优点:
- 内存占用更小。直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。也就是说XGBoost需要用32位的浮点数去存储特征值,并用32位的整形去存储索引,而LGBM只需要用8位整型去存储直方图,内存相当于减少了1/8。
- 计算代价更小:预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LGBM只需要计算k次(k可以认为是常数),直接将时间复杂度从 O ( # d a t a × # f e a t u r e ) O(\#data\times \#feature) O(#data×#feature)降低到 O ( k × # f e a t u r e ) O(k \times \#feature) O(k×#feature)。
缺点:
直方图算法并不是完美的。由于特征被离散化后,找到的并不是精确的分割点,所以会对结果产生影响。但在不同数据集上的测试结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时会好一些。这是由于决策树本身就是弱学习器,分割点是不是精确并不太重要,较粗糙的分割点也有正则化的效果,可以有效地防止过拟合,这样即使单个树的训练误差比精确分割的算法稍大,但在梯度提升的框架下并没有太大的影响。
LGBM调参
建议根据经验确定的参数
learning_rate:通常来说,学习率越小模型的最终表现越容易获得比较好的结果,但是过小的学习率往往会导致模型的过拟合以及影响模型训练的时间。一般来说,在调参的过程中会预设一个固定的值如0.1或者0.05,再在其他参数确定后在[0.05-0.2]之间搜索一个不错的值作为最终模型的参数。通常在学习率较小时,n_estimators的数值会大,而学习率大的时候,n_estimators会比较小,它们是一对此消彼长的参数对。n_estimators:- 一般情况下迭代次数越多模型表现越好,但是过大的迭代次往往会导致模型的过拟合以及影响模型训练的时间。一般我们选择的值在100-1000之间,训练时需要时刻关注过拟合的情况以便及时调整迭代次数。通常通过
lgb.plot_metrics(model,metrics='auc')来观察学习曲线的变化,如果在测试集表现趋于下降的时候模型还没有停止训练就说明出现过拟合了。 - 通常为了防止过拟合,都会选一个比较大的
n_estimators,然后设置early_stop_round为[20,50,100]来让模型停止在测试集效果还不错的地方,但如果模型过早的停止训练,比如只迭代了20次,那可能这样的结果是有问题的,需要再仔细研究下原因。 - 还有个通过交叉验证确定
n_estimators的办法,但已有的实验结果表明没有加early_stop_round来的稳定,但也是可以尝试的,具体做法是:进行3-5折交叉检验,训练时加上early_stop_round,记录下每折模型停止时的n_estimators数值,然后n_estimators取交叉检验模型停止的迭代次数的平均值的1.1倍,然后确定这个数值后调整其他参数,最终模型再通过early_stop_round得到最终的n_estimators数值。
- 一般情况下迭代次数越多模型表现越好,但是过大的迭代次往往会导致模型的过拟合以及影响模型训练的时间。一般我们选择的值在100-1000之间,训练时需要时刻关注过拟合的情况以便及时调整迭代次数。通常通过
min_split_gain:不建议调整。增大这个数值会得到相对浅的树深,可通过调整其他参数得到类似的效果。如果实在要调整,可以画出第一棵树和最后一棵树,把每次决策分叉的gain的数值画出来看一下大致范围,然后确定一个下限。但往往设置后模型性能会下降不少,所以如果不是过拟合很严重且没有其他办法缓解才建议调整这个参数。min_child_sample:这个参数需要根据数据集来确定,一般小数据集用默认的20就足够了,但大数据集用20的话会使得生成的叶子结点上数据量过少,会导致出现数据集没有代表性的问题,所以建议按树深为4共16个叶子时平均的训练数据个数的25%的数值来确定这个参数或者在这个范围稍微搜索下,这样模型的稳定性会有所保障。min_child_weight和min_child_sample的作用类似,但这个参数本身对模型的性能影响并不大,而且影响的方式不容易被人脑所理解,不建议过多的进行调整。
需要通过算法来搜索的参数
max_depth:一般在[3,4,5]这三个数里挑一个就好了,设置过大的数值过拟合会比较严重。num_leaves:在LGBM里,叶子节点数设置要和max_depth配合,要小于 2 m a x d e p t h − 1 2^max_depth-1 2maxdepth−1。一般max_depth取3时,叶子数要小于7。在参数搜索时,需要用max_depth去限制num_leaves的取值范围。subsample:不建议过度的精细细节,比如用搜索算法搜一个0.816386328这样的结果就不是很好。一般给出大致的搜索范围[0.7,0.8,0.9,1]这样几个比较整的数值就足够了。colsample_bytree:和subsample同理,一般给出大致的搜索范围[0.7,0.8,0.9,1]这样几个比较整的数值就足够了。reg_alpha:此参数用于L1正则化,一般在[0-1000]之间去进行调参。如果优化出来的数值过大,则说明有一些不必要的特征可以剔除,可以先做特征筛选后再进行调参,然后调节出来模型效果好的时候reg_alpha是个相对小的数值,那么我们对这个模型的信心会大很多。reg_lambda:此参数用于L2正则化,一般也在[0-1000]之间去进行调参。如果有非常强势的特征,可以人为加大一些使得整体特征效果平均一些,一般比reg_alpha略大一些,但如果大的夸张也需要查看一遍特征是否合理。
总结
在进行调参之前应该做好特征工程,确定特征后,根据数据规模和几个模型尝试的结果初步敲定learning_rate、n_estimators、min_split_gain、min_child_sample、min_child_weight这几个参数,然后使用grid_search、Bayesian optimization或random search来调整max_depth、 num_leaves、 subsample、 colsample_bytree、 reg_alpha、 reg_lambda。其中重点要调节max_depth和num_leaves,并注意两者的关系,其次subsample和 colsample_bytree在[0-1000]之间去进行粗略的调整下即可,reg_alpha和reg_lambda在[0,1000]范围调整,最后比较好的模型这两个参数值不应过大,尤其是reg_alpha,过大需要查看特征。
参考:
- Guolin Ke et al.(2017). Lightgbm: A highly efficient gradient boosting decision tree
- LightGBM(lgb)介绍
- LightGBM参数设置,看这篇就够了
相关文章:
LightGBM原理和调参
背景知识 LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,具有支持高效率的并行训练、更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以处理海量数据等优点。 普通的GBDT算法不支持用mini-batch的方式训练,在每一次…...

ROS无人机开发常见错误
飞控部分 一、解锁时飞控不闪红灯,无任何反应,地面站也无报错 解决办法: 打开地面站的遥控器一栏 首先检查右下角Channel Monitor是否有识别出遥控各通道的值,如果没有,检查遥控器是否打开,遥控器和接收…...
)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为AVI视频格式(C#)
Baumer工业相机堡盟工业相机如何联合NEOAPI SDK和OpenCV实现相机图像转换为视频格式(C#) Baumer工业相机Baumer工业相机的图像转换为OpenCV的图像的技术背景在NEOAPI SDK里实现相机图像转换为视频格式 工业相机通过OpenCV实现相机图像转换为视频格式的优…...

第一次面试总结 - 迈瑞医疗 - 软件测试
🧸欢迎来到dream_ready的博客,📜相信您对专栏 “本人真实面经” 很感兴趣o (ˉ▽ˉ;) 专栏 —— 本人真实面经,更多真实面试经验,中大厂面试总结等您挖掘 注:此次面经全靠小嘴八八,没…...

利用Qt输出XML文件
使用Qt输出xml文件 void PixelConversionLibrary::generateXML() {QFile file("D:/TEST.xml");//创建xml文件if (!file.open(QIODevice::WriteOnly | QIODevice::Text))//以只写方式,文本模式打开文件{qDebug() << "generateXML:Failed to op…...
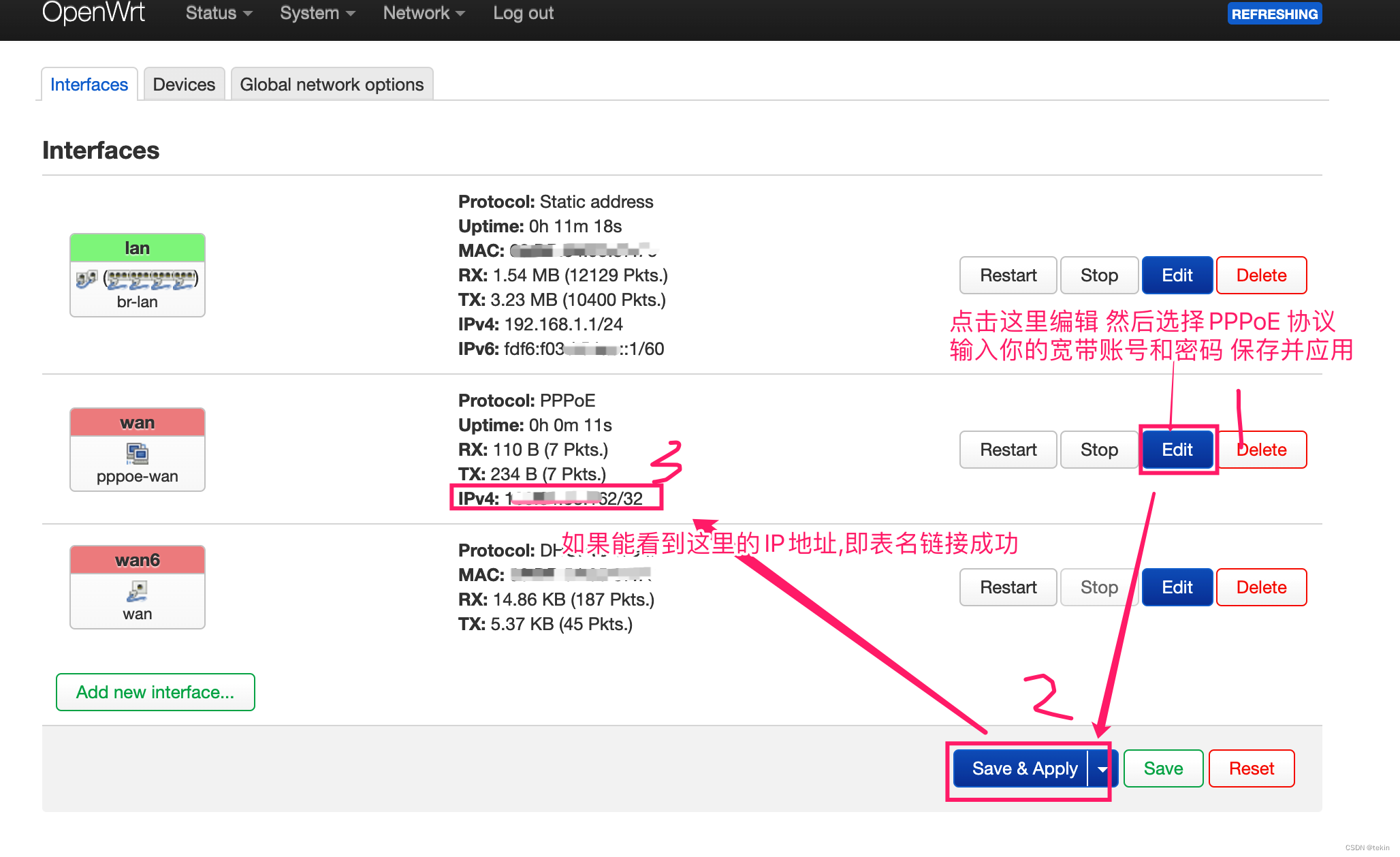
OpenWrt智能路由器Wan PPPoE拨号配置方法
OpenWrt智能路由器的wan PPPoE拨号配置方法和我们常见的不太一样, 需要先找到wan网卡,然后将协议切换为 PPPoE然后才能看到输入上网账号和密码的地方. 首先登录路由器 http://openwrt.lan/ 然后找到 Network --> Interfaces 这里会显示你当前的路由器的所有接口, 选择 …...

(十一)IIC总线-AT24C02-EEPROM
文章目录 IIC总线篇AT24C02-EEPROM篇主要特性引脚说明AT24Cxx用几位数据地址随机寻址的(存储器组织)AT24C02设备操作AT24CXX设备寻址EEPROM写操作的种类EEPROM读操作的种类实现单字节写实现任意读读写应用 IIC总线篇 前面介绍过了,请参考 (十)IIC总线-PCF8591-ADC/…...

现在做电商还有发展空间吗?哪个平台的盈利比较大?
我是电商珠珠 对于部分人来说,实体店的投入太大,一上来就是十几w,有时候还看不到结果。 所以有的人就瞄准了电商这个圈子,做线上平台。 大家都知道,近年来直播电商很火,所以很多商家都会去找达人带货&am…...

多节点 docker 部署 elastic 集群
参考 Install Elasticsearch with Docker Images 环境 docker # docker version Client: Docker Engine - CommunityVersion: 24.0.7API version: 1.43Go version: go1.20.10Git commit: afdd53bBuilt: Thu Oct 26 09:08:01 202…...
2023年全国职业院校技能大赛软件测试赛题—单元测试卷⑨
单元测试 一、任务要求 题目1:根据下列流程图编写程序实现相应分析处理并显示结果。返回文字“xa*a*b的值:”和x的值;返回文字“xa-b的值:”和x的值;返回文字“xab的值:”和x的值。其中变量a、b均须为整型…...
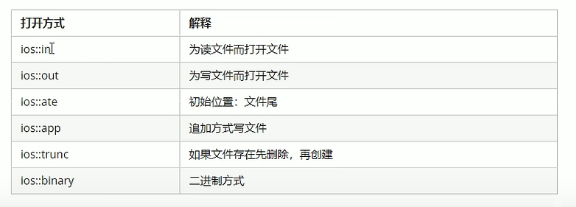
C++核心编程——文件操作
本专栏记录C学习过程包括C基础以及数据结构和算法,其中第一部分计划时间一个月,主要跟着黑马视频教程,学习路线如下,不定时更新,欢迎关注。 当前章节处于: ---------第1阶段-C基础入门 ---------第2阶段实战…...

【REST2SQL】05 GO 操作 达梦 数据库
【REST2SQL】01RDB关系型数据库REST初设计 【REST2SQL】02 GO连接Oracle数据库 【REST2SQL】03 GO读取JSON文件 【REST2SQL】04 REST2SQL第一版Oracle版实现 信创要求用国产数据库,刚好有项目用的达梦,研究一下go如何操作达梦数据库 1 准备工作 1.1 安…...

GitLab 502 Whoops, GitLab is taking too much time to respond. 解决
1、先通过gitlab-ctl restart进行重启,2分钟后看是否可以正常访问,为什么要2分钟,因为gitlab启动会有很多配套的服务启动,包括postgresql等 2、如果上面不行,再看gitlab日志,通过gitlab-ctl tail命令查看&…...

vi ~/.bashrc 后如何编辑并退出
在使用 vi 编辑器打开 ~/.bashrc 文件后,可以按照以下步骤编辑并保存退出: vi ~/.bashrc 按 i 进入插入模式: 在 vi 编辑器中,按 i 键将进入插入模式。在插入模式中,您可以编辑文本。 编辑文件: 在插入模…...

KVM Vcpu概述
KVM Vcpu概述 Intel VTSMP系统CPU过载使用CPU模型CPU绑定和亲和性CPU优化 Intel VT Intel的硬件虚拟化技术大致分为3类: 1、VT-x技术:是指Intel处理器中的一些虚拟化技术支持,包括CPU中最基础的VMX技术,也包括内存虚拟化的硬件支…...

linux服务器ftp部署
1、ftp服务安装 # 检查是否安装 1、查询安装列表 sudo systemctl list-unit-files --typeservice | grep ftp 2、查询ftp服务状态 sudo service vsftpd status 或者 sudo systemctl status vsftpd # yum安装,一般yum仓库都有ftp安装包 sudo yum install vsftpd # 启…...
)
NSIS 安装windows 安装包(包括QT和MFC)
NSIS(Nullsoft Scriptable Install System)是一个开源的 Windows 系统下安装程序制作程序。它提供了安装、卸载、系统设置、文件解压缩等功能。 基本概念 区段 是对应某种安装/卸载选项的处理逻辑,该段代码仅当用户选择相应的选项才被执行…...

K8S----PVPVCSC
一、简介 1、PV(persistent volume)–持久卷 PV是集群中的一块存储,可以由管理员事先静态(static)制备, 也可以使用存储类(Storage Class)来动态(dynamic)制备。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样, 也是使用卷插件(volume p…...

RSIC-V“一芯”学习笔记(一)——概述
考研的文章和资料之后想写的时候再写怕趴 文章目录 一、阶段设计二、环境、开发语言和工具三、最重要的两个观念四、处理器芯片设计五、处理器芯片设计包含很多软件问题六、处理器芯片的评价指标七、复杂系统的构建和维护八、专业世界观九,提问的艺术(提问模板)十、…...
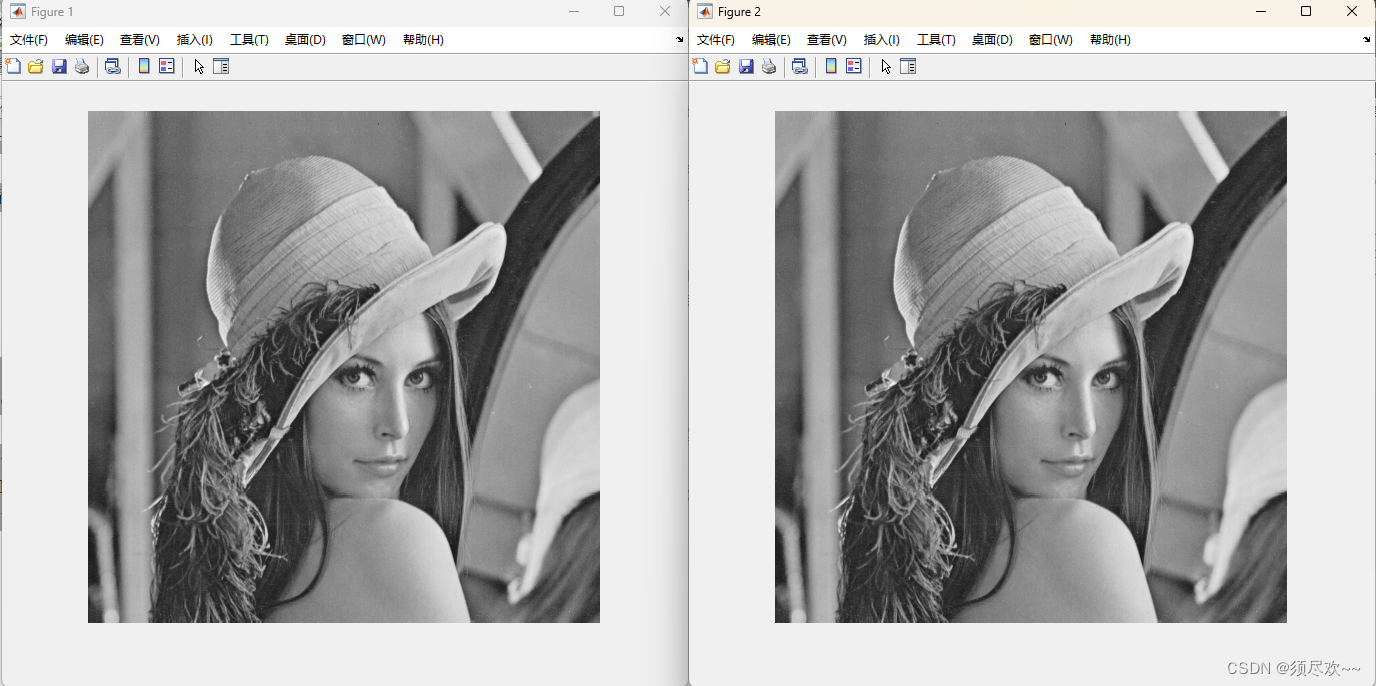
MATLAB读取图片并转换为二进制数据格式
文章目录 前言一、MATLAB 文件读取方法1、文本文件读取2、二进制文件读取3、 图像文件读取4、其他文件读取 二、常用的图像处理标准图片链接三、MATLAB读取图片并转换为二进制数据格式1、matlab 源码2、运行结果 前言 本文记录使用 MATLAB 读取图片并转换为二进制数据格式的方…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...