shardingsphere5.1.1分表分库yaml配置 自定义策略
前言
通过阅读官方稳定给出示例 https://shardingsphere.apache.org/document
一、基本配置示例
spring:sharding:datasource:names: ds0, ds1ds0:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db0username: rootpassword: rootds1:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db1username: rootpassword: rootsharding:default-database-strategy:inline:sharding-column: user_idalgorithm-expression: ds$->{user_id % 2}tables:user:actual-data-nodes: ds$->{0..1}.user_$->{0..1}database-strategy:inline:sharding-column: user_idalgorithm-expression: ds$->{user_id % 2}table-strategy:inline:sharding-column: idalgorithm-expression: user_$->{id % 2}
在该配置中,有两个数据源ds0和ds1,分别对应两个数据库db0和db1。在ShardingSphere中,通过配置actual-data-nodes属性来指定数据分片的具体情况。在这里,我们指定了user表在ds0和ds1这两个数据源中的分片情况。其中,actual-data-nodes中的$->{0..1}表示分片,即分为两个分片。
在分片策略中,我们采用了取模算法。对于user表,我们根据user_id字段的值对数据进行分片,具体的算法表达式为ds$->{user_id % 2}。这样就将user表的数据分为了两个数据源。
对于具体的分片表,我们还需要设置table-strategy,以实现分表的功能。在这里,我们根据id字段的值对数据进行分表,具体的算法表达式为user_$->{id % 2}。
二、自定义策略
官网策略规则(混合规则)
rules:
- !SHARDINGtables: # 数据分片规则配置<logic_table_name> (+): # 逻辑表名称actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一standard: # 用于单分片键的标准分片场景shardingColumn: # 分片列名称shardingAlgorithmName: # 分片算法名称complex: # 用于多分片键的复合分片场景shardingColumns: # 分片列名称,多个列以逗号分隔shardingAlgorithmName: # 分片算法名称hint: # Hint 分片策略shardingAlgorithmName: # 分片算法名称none: # 不分片tableStrategy: # 分表策略,同分库策略keyGenerateStrategy: # 分布式序列策略column: # 自增列名称,缺省表示不使用自增主键生成器keyGeneratorName: # 分布式序列算法名称auditStrategy: # 分片审计策略auditorNames: # 分片审计算法名称- <auditor_name>- <auditor_name>allowHintDisable: true # 是否禁用分片审计hintdefaultDatabaseStrategy:standard:shardingColumn: # 分片列名称shardingAlgorithmName: # 分片算法名称# 分片算法配置shardingAlgorithms:<sharding_algorithm_name> (+): # 分片算法名称type: # 分片算法类型props: # 分片算法属性配置# ...https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/builtin-algorithm/sharding/keyGenerators:<key_generate_algorithm_name> (+): # 分布式序列算法名称type: # 分布式序列算法类型props: # 分布式序列算法属性配置
- !READWRITE_SPLITTINGdataSources:<data_source_name>: # 读写分离逻辑数据源名称dynamicStrategy: # 读写分离类型autoAwareDataSourceName: # 数据库发现逻辑数据源名称<data_source_name>: # 读写分离逻辑数据源名称dynamicStrategy: # 读写分离类型autoAwareDataSourceName: # 数据库发现逻辑数据源名称
- !DB_DISCOVERYdataSources:<data_source_name>:dataSourceNames: # 数据源名称列表- ds_0- ds_1- ds_2discoveryHeartbeatName: # 检测心跳名称discoveryTypeName: # 数据库发现类型名称<data_source_name>:dataSourceNames: # 数据源名称列表- ds_3- ds_4- ds_5discoveryHeartbeatName: # 检测心跳名称discoveryTypeName: # 数据库发现类型名称discoveryHeartbeats:<discovery_heartbeat_name>: # 心跳名称props:keep-alive-cron: # cron 表达式,如:'0/5 * * * * ?'discoveryTypes:<discovery_type_name>: # 数据库发现类型名称type: # 数据库发现类型,如:MySQL.MGR props:group-name: # 数据库发现类型必要参数,如 MGR 的 group-name
- !ENCRYPTencryptors:<encrypt_algorithm_name> (+): # 加解密算法名称type: # 加解密算法类型props: # 加解密算法属性配置<encrypt_algorithm_name> (+): # 加解密算法名称type: # 加解密算法类型tables:<table_name>: # 加密表名称columns:<column_name> (+): # 加密列名称plainColumn (?): # 原文列名称cipherColumn: # 密文列名称encryptorName: # 密文列加密算法名称assistedQueryColumn (?): # 查询辅助列名称assistedQueryEncryptorName: # 查询辅助列加密算法名称likeQueryColumn (?): # 模糊查询列名称likeQueryEncryptorName: # 模糊查询列加密算法名称queryWithCipherColumn(?): # 该表是否使用加密列进行查询
spring:shardingsphere:mode:# 运行模式类型。可选配置:内存模式 Memory、单机模式 Standalone、集群模式 Clustertype: Memoryprops:#是否在日志中打印 SQL。#打印 SQL 可以帮助开发者快速定位系统问题。日志内容包含:逻辑 SQL,真实 SQL 和 SQL 解析结果。#如果开启配置,日志将使用 Topic ShardingSphere-SQL,日志级别是 INFO。 falsesql-show: true#是否在日志中打印简单风格的 SQL。falsesql-simple: false#用于设置任务处理线程池的大小。每个 ShardingSphereDataSource 使用一个独立的线程池,同一个 JVM 的不同数据源不共享线程池。executor-size: 20#次查询请求在每个数据库实例中所能使用的最大连接数。1max-connections-size-per-query: 1#在程序启动和更新时,是否检查分片元数据的结构一致性。check-table-metadata-enabled: false#在程序启动和更新时,是否检查重复表。falsecheck-duplicate-table-enabled: falsedatasource:names: ds0, ds1ds0:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db0username: rootpassword: rootds1:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db1username: rootpassword: rootrules:sharding:key-generators:# shardingsphere-jdbc-core-spring-boot-starter需要加载此项配置 snowflake:type: SNOWFLAKEprops:worker-id: 123#分片算法配置sharding-algorithms:## 分片算法名称fenpian-db-1:#对应 Override getTypetype: UserDatabaseAlgorithm# 分片算法属性配置props:strategy: STANDARDalgorithm-class-name: xxxx.xxx.xxx.UserDatabaseAlgorithmfenpian-table-1:#对应 Override getTypetype: UserDataTableAlgorithmprops:strategy: STANDARDalgorithm-class-name: xxxxx.xxxx.xxx.UserDataTableAlgorithmtables:# 逻辑表名称sys_user:# 由数据源名 + 表名组成(参考 Inline 语法规则)actual-data-nodes: ds${0..3}.sys_user${0..255}# 分表策略,缺省表示使用默认分库策略,以下的分片策略只能选其一table-strategy:#standard: # 用于单分片键的标准分片场景standard:#数据库的键shardingColumn: xxxxsharding-algorithm-name: fenpian-table-1# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一database-strategy:#standard: # 用于单分片键的标准分片场景standard:shardingColumn: xxxx# 此处使用的就是我们在sharding-algorithms里面定义的规则sharding-algorithm-name: fenpian-db-1
public class UserDatabaseAlgorithm implements StandardShardingAlgorithm<Long> {@Overridepublic String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {for (String databaseName : databaseNames) {if (databaseName.endsWith(String.valueOf(shardingValue.getValue() % 2))) {return databaseName;}}throw new IllegalArgumentException();}@Overridepublic String getType() {return "UserDatabaseAlgorithm";}
}
public class UserDataTableAlgorithm implements StandardShardingAlgorithm<Long> {@Overridepublic String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {for (String databaseName : databaseNames) {if (databaseName.endsWith(String.valueOf(shardingValue.getValue() % 2))) {return databaseName;}}throw new IllegalArgumentException();}@Overridepublic String getType() {return "UserDataTableAlgorithm";}
}SPI机制注入
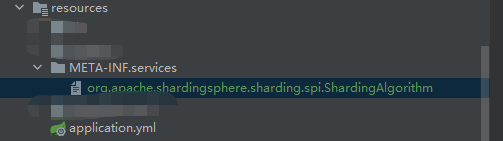
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm
xxxx.xxx.xxx.UserDatabaseAlgorithm
xxxxx.xxxx.xxx.UserDataTableAlgorithm
搞完收工!!!!!
三、ShardingAlgorithm实现类扩展
在ShardingSphere中,ShardingAlgorithm是一个非常重要的概念,是分片规则中实现分片算法的核心接口。ShardingAlgorithm接口定义了如何根据分片键的值计算分片后的数据所在位置。ShardingSphere提供了多种ShardingAlgorithm的实现类,下面是常见的几种实现类及其区别:
PreciseShardingAlgorithm
PreciseShardingAlgorithm是ShardingSphere提供的最基本的分片算法接口,用于实现基于精确值的分片算法。PreciseShardingAlgorithm只能用于处理精确的分片键,即单个值,无法处理范围查询。使用PreciseShardingAlgorithm进行分片时,只需要在规则配置中指定算法名称,即可实现数据的分片。
用于将数据按照一定规则分散到不同的数据库和表中。它的实现可以用于以下场景:
数据库扩展:当一个单一数据库无法满足应用程序的性能需求时,可以使用分库分表技术,将数据分散到多个数据库和表中,以提高性能。
数据隔离:某些业务需要数据隔离,例如多租户应用程序中,每个租户的数据需要独立存储,这时可以使用分库分表技术。
数据容错:当某个数据库或表发生故障时,分库分表可以通过备份或者替换该节点,从而提高应用程序的容错性。
数据负载均衡:使用分库分表可以将数据分散到不同的节点上,从而实现数据的负载均衡,提高应用程序的性能和稳定性。
RangeShardingAlgorithm
RangeShardingAlgorithm是ShardingSphere提供的另一种常见的分片算法接口,用于实现基于范围的分片算法。RangeShardingAlgorithm能够处理范围查询,支持处理>、>=、<、<=、BETWEEN AND等操作符。使用RangeShardingAlgorithm进行分片时,需要指定范围查询的最小值和最大值,以及需要查询的具体分片键范围,从而计算出符合要求的分片结果。
它可以根据一定的范围规则,将数据按照分片键的范围进行分散到不同的数据库和表中。通过 RangeShardingAlgorithm,可以实现数据的按范围划分,从而更好地控制数据的分布和负载均衡。
实现 RangeShardingAlgorithm 有以下用途:
数据分片更加灵活:通过 RangeShardingAlgorithm,可以根据分片键的范围规则,将数据按照一定的范围进行分片,从而更加灵活地控制数据的分布和负载均衡。
数据查询更加高效:由于 RangeShardingAlgorithm 可以将数据按照分片键的范围进行划分,因此在查询数据时可以更加高效地进行范围查询,从而提高查询性能。
数据备份和恢复更加容易:使用 RangeShardingAlgorithm 可以将数据按照范围进行备份和恢复,从而提高数据的可用性和容错能力。
数据库扩展更加灵活:通过 RangeShardingAlgorithm,可以将新的数据库或表添加到分片规则中,从而实现动态扩展。
总的来说,RangeShardingAlgorithm 可以为应用程序提供更加灵活、更加高效的数据分片方式,满足不同的业务需求。但是需要注意的是,在使用 RangeShardingAlgorithm 时需要对分片规则进行更加严格的管理,以确保数据分散均匀且查询性能高效。同时,需要考虑范围划分的复杂度和性能,以确保系统的性能和可扩展性。
HintShardingAlgorithm
HintShardingAlgorithm是一种比较特殊的分片算法,它不需要分片键,而是通过ShardingHint对象中携带的分片信息进行数据的分片。使用HintShardingAlgorithm进行分片时,需要在SQL语句中加入hint信息,例如/*+ sharding(shardingValue=xxx) */,其中shardingValue为hint的名称,xxx为具体的分片信息。这种算法相对于其他算法来说,可以灵活地指定分片信息,但需要在代码中显式地添加hint信息。
以根据用户指定的分片键,将数据按照一定规则分散到不同的数据库和表中。与 PreciseShardingAlgorithm 不同,HintShardingAlgorithm 不需要通过计算分片键的哈希值来进行分片,而是通过应用程序显式指定分片路由信息,从而实现数据的分片。
实现 HintShardingAlgorithm 有以下用途:
灵活性更高:通过 HintShardingAlgorithm,应用程序可以显式指定数据的分片路由信息,从而可以更灵活地进行分片。
特殊业务需求:某些业务需要将数据存储到指定的数据库或表中,例如某些敏感数据需要存储到特定的数据库或表中,此时可以使用 HintShardingAlgorithm 实现数据的分片。
数据库扩展:当应用程序需要进行数据库扩展时,通过 HintShardingAlgorithm 可以将新的数据库或表添加到分片规则中,从而实现动态扩展。
数据备份和恢复:通过 HintShardingAlgorithm,可以将数据备份到指定的数据库或表中,从而方便进行数据恢复和灾备。
总的来说,HintShardingAlgorithm 可以为应用程序提供更灵活、更精细的数据分片方式,满足不同的业务需求。但是需要注意的是,由于需要应用程序显式指定分片路由信息,因此在使用 HintShardingAlgorithm 时需要进行更为严格的分片规划和管理,否则可能会出现数据分散不均或者数据丢失等问题。
ComplexKeysShardingAlgorithm
ComplexKeysShardingAlgorithm是一种用于处理多分片键的复合分片算法,它能够根据多个分片键计算出分片后的数据所在位置。使用ComplexKeysShardingAlgorithm进行分片时,需要指定多个分片键,以及如何计算这些分片键的值。相比于单一分片键的分片算法,ComplexKeysShardingAlgorithm可以提供更为灵活的分片策略。
总的来说,ShardingSphere提供了多种ShardingAlgorithm的实现类,每种实现类都有其特点和适用场景。开发人员需要根据具体业务需求,选择适合的分片算法,以实现高效、灵活、可靠的数据分片。
它可以根据多个分片键,将数据按照一定规则分散到不同的数据库和表中。相比于单一的分片键,使用多个分片键可以更加精细地控制数据的分片方式,从而实现更好的负载均衡和容错能力。
实现 ComplexKeysShardingAlgorithm 有以下用途:
数据分片更加精细:通过使用多个分片键,可以将数据按照更为复杂的规则进行分片,从而更加精细地控制数据的分布和负载均衡。
业务逻辑更加复杂:某些业务需要根据多个分片键来进行数据分片,例如一个订单系统需要根据订单创建时间和订单状态来进行分片,此时可以使用 ComplexKeysShardingAlgorithm 实现数据分片。
数据库扩展更加灵活:通过使用多个分片键,可以将新的数据库或表添加到分片规则中,从而实现动态扩展。
数据备份和恢复更加容易:使用多个分片键可以更加精细地控制数据的备份和恢复,从而提高数据的可用性和容错能力。
总的来说,ComplexKeysShardingAlgorithm 可以为应用程序提供更加灵活、更加精细的数据分片方式,满足不同的业务需求。但是需要注意的是,由于需要考虑多个分片键之间的关系,因此在使用 ComplexKeysShardingAlgorithm 时需要进行更为严格的分片规划和管理,否则可能会出现数据分散不均或者数据丢失等问题。同时,实现 ComplexKeysShardingAlgorithm 也需要考虑算法的复杂度和性能,以确保系统的性能和可扩展性。
StandardShardingAlgorithm
StandardShardingAlgorithm是ShardingSphere提供的一种分片算法接口实现,它是基于分片键进行分片的一种标准分片算法。使用StandardShardingAlgorithm进行分片时,需要指定分片键的值、分片表的数量以及分片后的数据表名称,从而计算出分片后的数据所在位置。
标准化
由于StandardShardingAlgorithm是ShardingSphere提供的标准分片算法之一,因此开发人员可以基于该算法进行二次开发,快速实现自己的分片算法,同时也可以避免重复造轮子。
灵活性
StandardShardingAlgorithm支持自定义分片策略,可以根据不同的业务需求,制定不同的分片策略。开发人员可以通过修改StandardShardingAlgorithm的实现来适应不同的分片场景,如按时间、按地域、按用户等。
易用性
StandardShardingAlgorithm接口定义简单明了,易于使用和理解。开发人员只需要实现该接口中的doSharding方法,就可以实现自己的分片算法。此外,由于StandardShardingAlgorithm是ShardingSphere提供的标准分片算法,因此可以直接在ShardingSphere中配置,无需进行额外的代码开发。
总的来说,StandardShardingAlgorithm提供了一种通用的分片算法实现方式,能够帮助开发人员快速实现分布式系统的数据分片,提高系统的可扩展性和性能。开发人员可以根据具体业务需求,选择合适的分片算法,以实现高效、灵活、可靠的数据分片。
相关文章:
shardingsphere5.1.1分表分库yaml配置 自定义策略
前言通过阅读官方稳定给出示例 https://shardingsphere.apache.org/document一、基本配置示例spring:sharding:datasource:names: ds0, ds1ds0:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db0username: rootpassword: rootds1:driver-class-na…...

“探索未来:VR全景直播技术引领新媒体时代”
随着虚拟现实技术的不断发展,VR全景直播已经成为了越来越受欢迎的直播形式。VR全景直播可以让观众通过虚拟现实设备亲临直播现场,享受身临其境的观看体验。VR全景直播是什么? VR全景直播是虚拟现实技术和直播的结合。相对于传统直播ÿ…...

Spring Cloud(微服务)学习篇(六)
Spring Cloud(微服务)学习篇(六) 2 Sentinel实现流量规则(控制台版) 2.1 变更pom.xml(shop-user-server项目)代码 2.1.1 加入如下依赖 <!--熔断限流--> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-…...
MATLAB-Scatter3-三维散点图投影至XYZ三个平面
MATLAB-Scatter3函数可以绘制立体的三维散点图,但有时候需要在该立体图中分析X-Y-Z三者的关系,即1副图呈现出4个信息,XYZ综合信息、XY信息、XZ信息、YZ信息。现有的Scatter3无法实现该功能,本文可实现Scatter3三维立体散点图在三个…...
Unity/C#------委托与事件(一篇文章彻底搞懂...)
一:委托 所有的代码语言创造者母语都是英语,我们从英语翻译到中文的过程中难免会存在一些不太能还原本意的词,比如我之前一直不理解构造函数和析构函数,只知道这俩货作用相反,直到我看到了它的英文意思,Con…...
别再为 Jenkins 安装烦恼,Docker 帮你轻松解决
前言 大家好,又见面了,我是沐风晓月,本文收录与云原生相关的专栏,以下是我的简介: 🏠个人主页:我是沐风晓月 🧑个人简介:大家好,我是沐风晓月,双…...

汇编语言程序设计(一)
前言 在学习汇编语言之前,我们应该要知道汇编语言他是一门怎么样的语言。汇编语言是直接工作在硬件上的一门编程语言,学习汇编语言之前最好先了解一下计算机硬件系统的结构和工作原理。学习汇编语言的重点是学习如何利用硬件系统的编程结构和指令集进而…...

【uni-app教程】四、UniAPP 路由配置及页面跳转
四、UniAPP 路由配置及页面跳转 (1) 路由配置 uni-app页面路由为框架统一管理,开发者需要在pages.json里配置每个路由页面的路径及页面样式。类似小程序在 app.json 中配置页面路由一样。所以 uni-app 的路由用法与 Vue Router 不同,如仍希望采用 Vue …...
-- ROS控制器图形化界面开发)
ROS从入门到精通系列(二十八)-- ROS控制器图形化界面开发
ROS (Robot Operating System, 机器人操作系统) 作为机器人软件中的通信及控制中间件,提供一系列程序库和工具以帮助软件开发者创建机器人应用软件。它提供了硬件抽象、设备驱动、函数库、可视化工具、消息传递和软件包管理等诸多功能。ROS遵循BSD开源许可协议。 随着机器人智…...
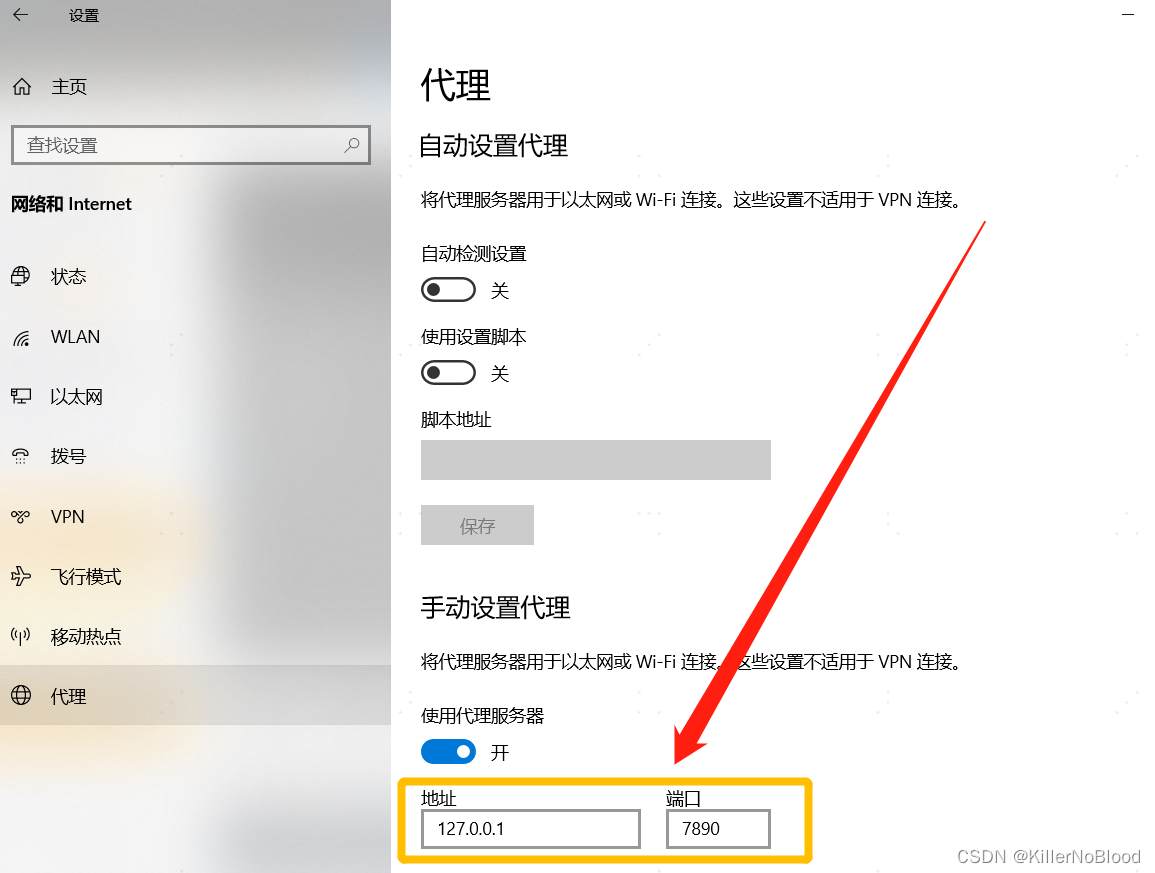
Submodule命令:android如何将自己项目中的某个Module作为gitlab中第三方公共库
一、创建远程公共库 1、Android Studio创建本地仓库 创建一个新的module 在新建module中添加代码(此处示例代码) 右击新建的module,打开新建module的命令行界面, 因为我们只上传这个module的代码,而不是整个项目的代码 命令行中输入以下命令…...

MySQL索引事务
1.索引1.1概念索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结果实现。(这里只用通俗的语言和图片进行介绍)1.2作用数据库中的表…...

ISO27001信息安全管理体系认证
ISO信息安全管理体系认证 一、什么是ISO信息安全管理体系认证? ISO是信息安全管理体系认证,是由国际标准化组织(ISO)采纳英国标准协会BS-2标准后实施的管理体系,成为了“信息安全管理”的国际通用语言,企…...
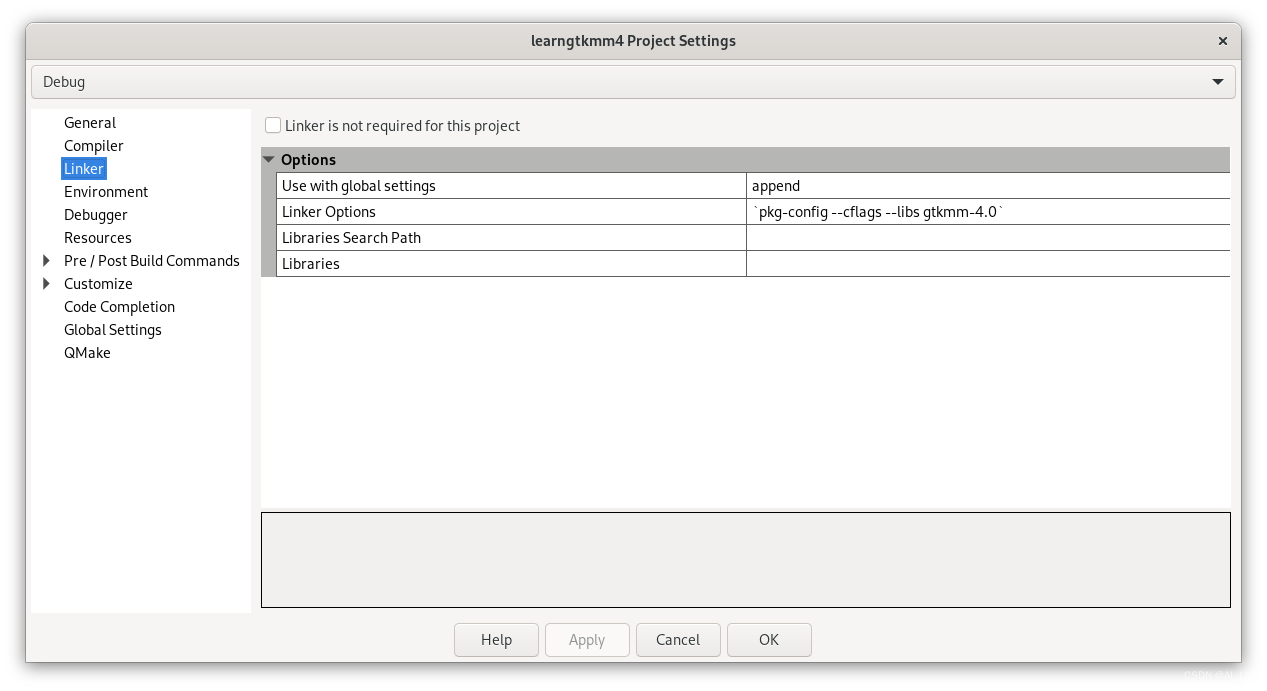
Linux应用GUI开发C++ 之gtkmm4(1)
目录概述GTKgtkmm安装gtkmm4hello,worldcodelite配置代码解释概述 GTK GTK是一个小部件工具包。GTK创建的每个用户界面都由小部件组成。这是在C语言中使用GObject实现的,GObject是一个面向对象的C语言框架。窗口小部件是主容器。然后通过向窗口中添加按钮、下拉菜…...
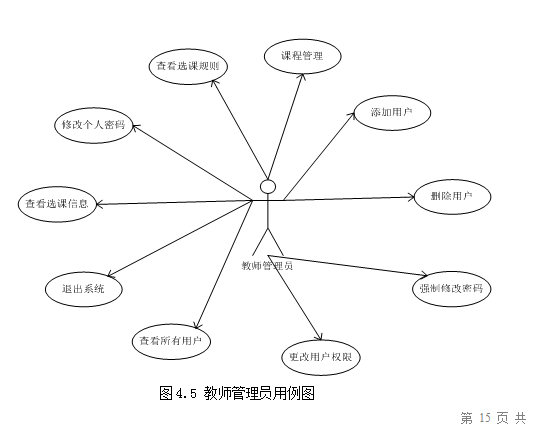
选课系统的设计与实现
技术:Java等摘要:目前国内各高校的规模越来越大,进而造成教师教学管理等工作量日趋加大。然而,现代教育的信息化、网络化已经成为教育发展的一个重要方向,同时也为解决高校教学管理效率低下的现状,使管理突…...

关于安卓的一些残缺笔记
安卓笔记Android应用项目的开发过程Android的调试Android项目文档结构Intent的显式/隐式调用Activity的生命周期1个Activity界面涉及到生命周期的情况2个Activity界面涉及到生命周期的情况Android布局的理论讲解Activity界面布局ContentProvider是如何实现数据共享Android整体架…...
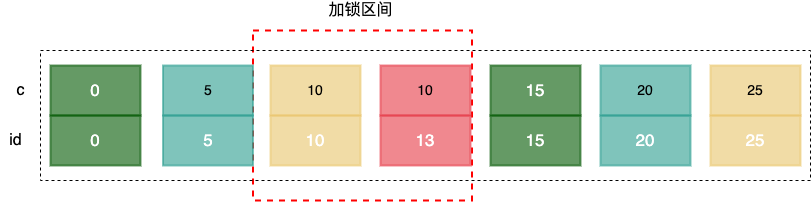
MySQL 中的锁有哪些类型,MySQL 中加锁的原则
锁的类型MySQL 找那个根据加锁的范围,大致可以分成全局锁,表级锁和行级锁。全局锁全局锁,就是对整个数据库加锁。加锁flush tables with read lock解锁unlock tables全局锁会让整个库处于只读状态,之后所有的更新操作都会被阻塞&a…...
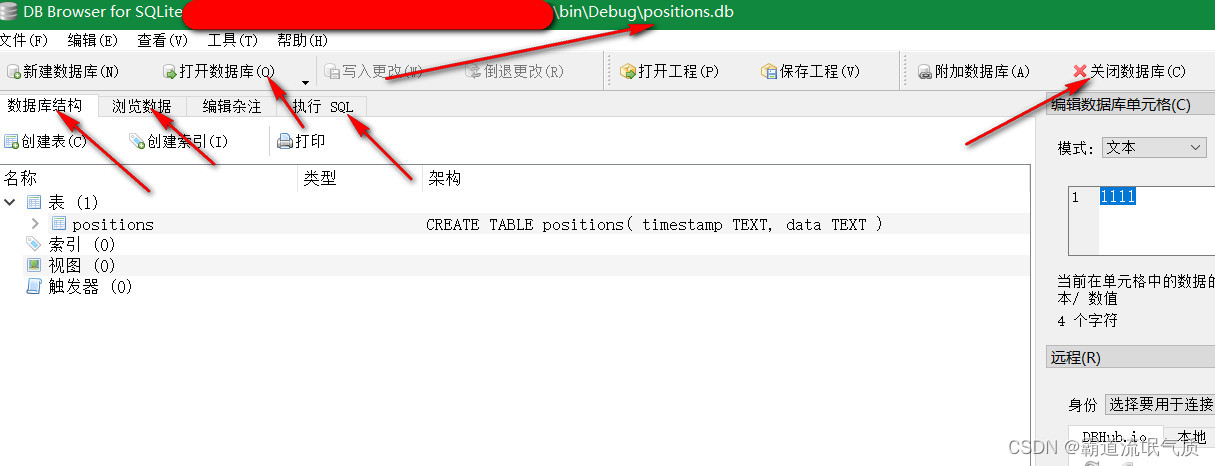
Winform中操作Sqlite数据增删改查、程序启动时执行创建表初始化操作
场景 Sqlite数据库 SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。 它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。 就像其他数据库,SQLite 引擎不…...
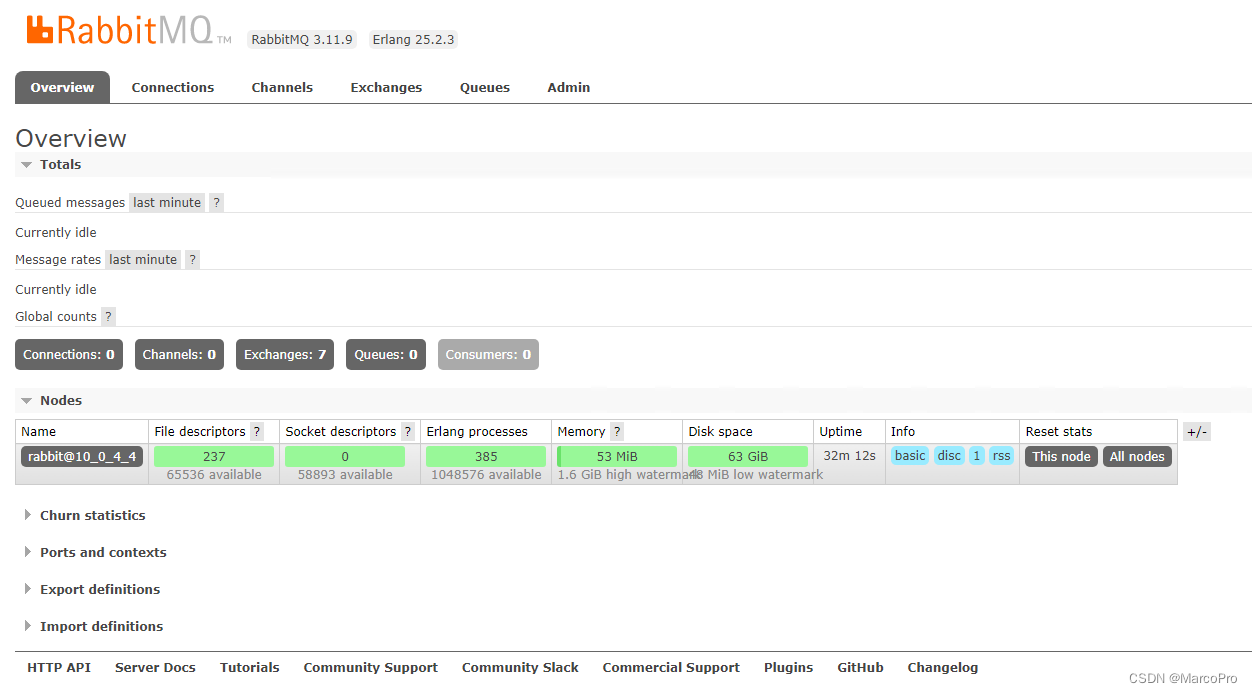
2023最新版本RabbitMQ下载安装教程
一、RabbitMQ简介 RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。主要用于在进程、应用程序和服务器之间交换数据,可以通过插件支持进行扩展,支持许多协议,并提供高性能、可靠性、集群和高可用队列。 AMQP :Advanced Me…...

如何使用码匠连接 Elasticsearch
目录 在码匠中集成 Elasticsearch 在码匠中使用 Elasticsearch 关于码匠 Elasticsearch 是一个开源的分布式搜索和分析引擎,常用于处理大规模数据集的搜索、实时数据分析和数据挖掘任务。它支持多种数据源,包括关系型数据库(如 MySQL、Pos…...

jmeter学习笔记二(jmeter函数与后置处理器)
Jmeter重要的函数 ${__counter(,)} 计数器 ${__counter(TRUE,)} 默认加1; TRUE,每个用户有自己的计数器;FALSE,使用全局计数器 计数器元件,可以设置起始值,间隔值,最大值。运行结果超过最大值时&a…...

Clawforce:开源AI智能体团队基础设施,实现持久化与安全协作
1. 项目概述:Clawforce,一个为持久化AI智能体团队构建的基础设施最近在AI智能体领域,一个词被反复提及:“Agentic AI”,即智能体驱动的AI。这不再是让单个AI模型回答一个问题那么简单,而是构建一个能够自主…...
)
【开盘预测】2026年5月13日(周三)
生成时间:2026-05-12 20:30 | 数据来源:金融市场数据 核心预测:市场震荡整理,关注4200-4250区间,量能变化是关键一、今日收盘总结指数收盘点涨跌幅关键技术位上证指数4214.49-0.25%失守4220,守在4200上方深…...

练了半年演讲口才,汇报时还是结巴,说说我的真实感受
小林坐在会议室的角落,手心微微出汗。轮到他汇报季度项目进展时,他深吸一口气站起来——结果,开场白磕磕绊绊,PPT翻到第三页才找回节奏。散会后他苦笑着跟同事说:“演讲口才课我上了半年了,怎么还是这副德行…...

限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流
限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流 项目地址:interview-agent 技术栈:Java 21 / Spring Boot 4.0 / Redis 7 (Redisson) / PostgreSQL 问题:单维度限流挡不住真实场景 简历上传接口,你加了一个&q…...

AI写作净化器:识别与消除AI文本痕迹的实用指南
1. 项目概述:为什么我们需要一个“AI写作净化器”? 如果你和我一样,每天都要和AI助手打交道,无论是用它写邮件、生成报告,还是草拟技术文档,那你一定对那种“AI味儿”深有体会。那种感觉就像喝了一杯过度调…...
)
别再想当然!用AD628/INA等差分放大器做单端采集,必须搞懂的共模电压计算(附Excel工具)
差分放大器单端采集实战指南:共模电压计算与设计避坑 在工业传感器接口和医疗设备信号链设计中,差分放大器常被用于单端信号采集的场景。许多工程师习惯性地认为,只要将差分放大器的负输入端接地,就能轻松实现单端转差分功能。但实…...
)
CES效用函数保姆级解析:从公式推导到Python代码实现(附替代弹性计算)
CES效用函数实战指南:从数学本质到Python可视化 在经济学建模和金融工程领域,CES(Constant Elasticity of Substitution)效用函数就像一把瑞士军刀——它不仅能描述消费者偏好,还能通过调整参数δ来模拟完全替代、Cobb…...
)
保姆级教程:用GATK4从玉米B73参考基因组中提取SNP和Indel(附完整代码)
玉米基因组变异检测实战指南:从测序数据到SNP/Indel分析全流程 在植物遗传学研究领域,玉米作为重要的模式作物和粮食作物,其基因组变异分析对品种改良和功能基因挖掘具有重要意义。本文将带领生物信息学初学者逐步完成从原始测序数据到变异检…...

Tailark部署指南:从开发到生产环境的完整流程
Tailark部署指南:从开发到生产环境的完整流程 【免费下载链接】cnblocks Shadcn marketing blocks 项目地址: https://gitcode.com/gh_mirrors/cn/cnblocks Tailark是一个专为现代营销网站打造的响应式组件库,基于shadcn/ui、Tailwind CSS和Next.…...

Midjourney Basic计划真实体验:7天高强度测试+37组对比图,揭示隐藏限制与生产力断层
更多请点击: https://intelliparadigm.com 第一章:Midjourney Basic计划真实体验:7天高强度测试37组对比图,揭示隐藏限制与生产力断层 过去一周,我以全职创作者身份深度使用 Midjourney Basic 计划($10/月…...