Hadoop 实战 | 词频统计WordCount
词频统计
通过分析大量文本数据中的词频,可以识别常见词汇和短语,从而抽取文本的关键信息和概要,有助于识别文本中频繁出现的关键词,这对于理解文本内容和主题非常关键。同时,通过分析词在文本中的相对频率,可以帮助理解词在不同上下文中的含义和语境。
"纽约时报"评论数据集记录了有关《纽约时报》2017年1月至5月和2018年1月至4月发表的文章上的评论的信息。月度数据分为两个csv文件:一个用于包含发表评论的文章,另一个用于评论本身。评论的csv文件总共包含超过200万条评论,有34个特征,而文章的csv文件包含超过9000篇文章,有16个特征。
本实验需要提取其中的 articleID 和 snippet 字段进行词频统计
MapReduce
在Hadoop中,输入文件通常会通过InputFormat被分成一系列的逻辑分片,分片是输入文件的逻辑划分,每个分片由一个Mapper处理。
本实验中,WordCount通过MapReduce统计snippet 字段中每个单词出现的总次数。程序主要包括Mapper, Reducer, Driver三个部分。
自定义的Mapper和Reducer都要继承各自的父类。Mapper中的业务逻辑写在map()方法中,Reducer的业务逻辑写在reduce()方法中。整个程序还需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。
程序总体流程如下图所示。
Mapper
Mapper的主要任务是处理输入分片并生成中间键值对,这些键值对将被传递给Reducer进行进一步处理,也就是对应的Map的过程。
在本实验中,Mapper需要将这行文本中的单词提取出来,针对每个单词输出一个<word, 1>的<Key, Value>对。之后MapReduce会对这些<word,1>进行排序重组,将相同的word放在一起,形成<word, [1,1,1,1,1,1,1…]>的<Key,Value >结构并传递给Reducer。
Reducer
Reducer则以中间键值对为输入,将其按照键进行分组,并将每个组的值按一定规则合并成最终的输出。
注意在此阶段前,Hadoop框架会自行将中间键值对经过默认的排序分区分组,Key相同的单词会作为一组数据构成新的<Key, Value>对。
在本实验中,Reducer将集合里的1求和,再将单词(word)与这个和(sum)组成一个<Key, Value>,也就是<word, sum>输出。每一个输出就是一个单词和它的词频统计总和了。
Driver
Driver是一个程序的主入口,负责配置和启动整个MapReduce任务。Driver类通常包含了整个MapReduce作业的配置信息、作业的输入路径、输出路径等信息,并启动MapReduce作业的执行。
总结
该程序基于Hadoop MapReduce框架实现了简单的单词计数功能,适用于大规模文本数据的并行处理。
PSEUDO-CODE 2 WordCount(词频统计)
/* Map函数,处理每一行的文本 */
1:input <Key,Value>; //Value使用Text类型表示文本行
2:从文本中提取文档ID和实际文本内容snippet;
3:使用空格、单引号和破折号作为分隔符,将文本snippet分词;
4:for 文本snippet中的每个单词:
5: 去除特殊字符后将<word,1>写入context,发射给Reducer;
6:end for
/* Reduce函数,处理相同键的所有值 */
1:input <Key,Value>,sum←0; //来自Map的<word,[1,1,1…]>
2:for Value的每个1:
3: 累加计数sum += 1;
代码
import java.io.IOException;
import java.util.regex.*;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {public WordCount() {}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(WordCount.TokenizerMapper.class);job.setCombinerClass(WordCount.IntSumReducer.class);job.setReducerClass(WordCount.IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true)?0:1);}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private static final IntWritable one = new IntWritable(1);private Text word = new Text();public TokenizerMapper() {}public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)throws IOException, InterruptedException {// Split DocID and the actual textString DocId = value.toString().substring(0, value.toString().indexOf("\t"));String value_raw = value.toString().substring(value.toString().indexOf("\t") + 1);// Reading input one line at a time and tokenizing by using space, "'", and "-" characters as tokenizers.StringTokenizer itr = new StringTokenizer(value_raw, " '-");// Iterating through all the words available in that line and forming the key/value pair.while (itr.hasMoreTokens()) {// Remove special charactersword.set(itr.nextToken().replaceAll("[^a-zA-Z]", ""));if(word.toString() != "" && !word.toString().isEmpty()){context.write(word, one);}}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public IntSumReducer() {}public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;IntWritable val;for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {val = (IntWritable)i$.next();}this.result.set(sum);context.write(key, this.result);}}}相关文章:

Hadoop 实战 | 词频统计WordCount
词频统计 通过分析大量文本数据中的词频,可以识别常见词汇和短语,从而抽取文本的关键信息和概要,有助于识别文本中频繁出现的关键词,这对于理解文本内容和主题非常关键。同时,通过分析词在文本中的相对频率࿰…...

SpringCloud.04.熔断器Hystrix( Spring Cloud Alibaba 熔断(Sentinel))
目录 熔断器概述 使用Sentinel工具 什么是Sentinel 微服务集成Sentinel 配置provider文件,在里面加入有关控制台的配置 实现一个接口的限流 基本概念 重要功能 Sentinel规则 流控规则 简单配置 配置流控模式 配置流控效果 降级规则 SentinelResource…...

python 八大排序_python-打基础-八大排序
## 排序篇 #### 二路归并排序 - 介绍 - 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列…...

运维知识点-Sqlite
Sqlite 引入 依赖 引入 依赖 <dependency><groupId>org.xerial</groupId><artifactId>sqlite-jdbc</artifactId><version>3.36.0.3</version></dependency>import javafx.scene.control.Alert; import java.sql.*;public clas…...

我为什么要写RocketMQ消息中间件实战派上下册这本书?
我与RocketMQ结识于2018年,那个时候RocketMQ还不是Apache的顶级项目,并且我还在自己的公司做过RocketMQ的技术分享,并且它的布道和推广,还是在之前的首席架构师的带领下去做的,并且之前有一个技术神经质的人࿰…...

24校招,Moka测试开发工程师一面
前言 大家好,今天回顾一下楼主当时参加moka测试开发工程师的面试 对其中一些重要问题,我也给出了相应的答案 过程 自我介绍挑一个项目,详细介绍你在其中担任的职责如何安排工作的,有什么成果?回归测试如何设计&…...
)
Docker(网络,网络通信,资源控制,数据管理,CPU优化,端口映射,容器互联)
目录 docker网络 网络实现原理 网络实现实例 网络模式 查看Docker中的网络列表: 指定容器网络模式 模式详解 Host模式(主机模式): Container模式(容器模式): None模式(无网…...
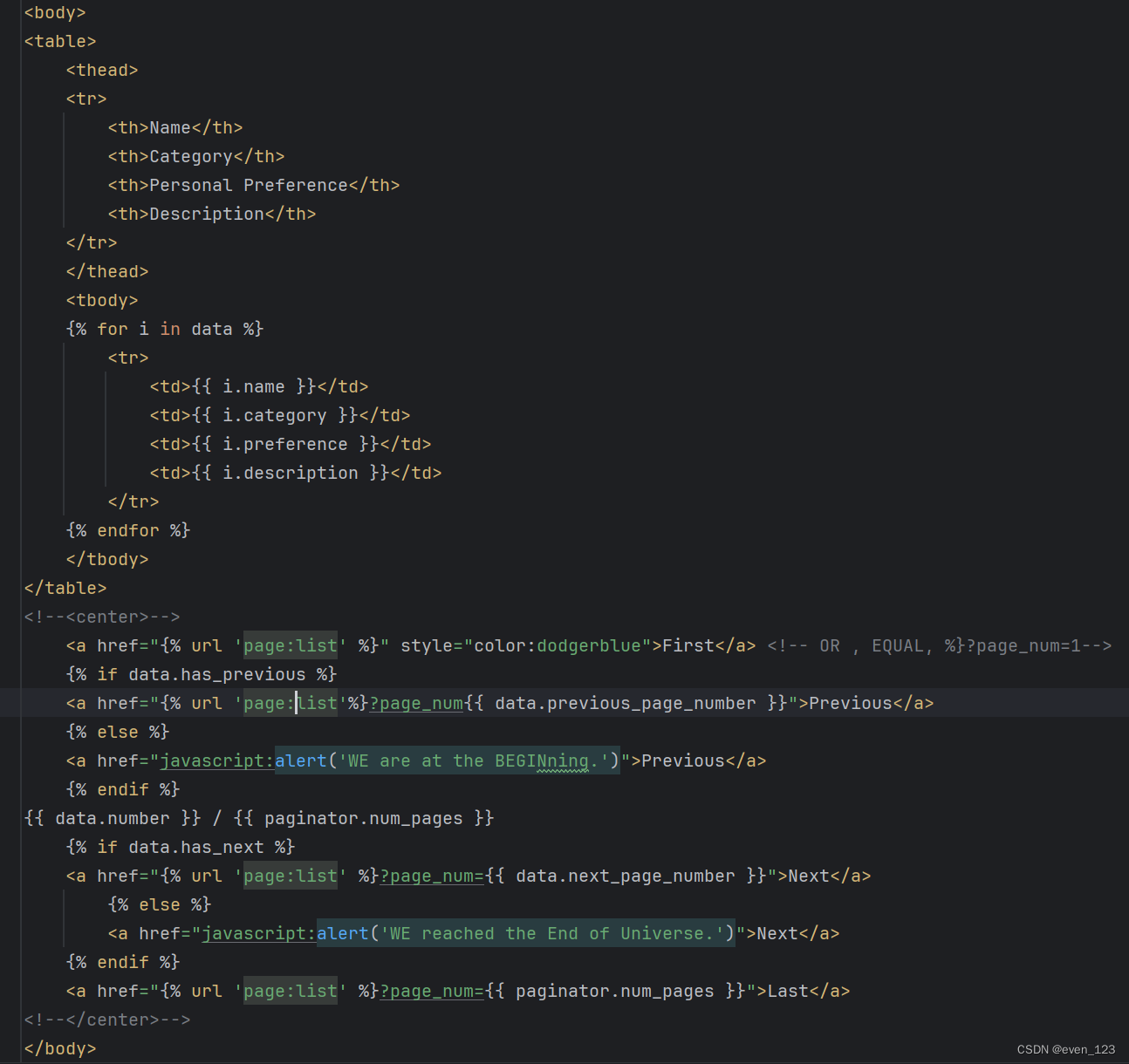
开发实践5_project
要求: (对作业要求的"Student"稍作了变换,表单名称为“Index”。)获得后台 Index 数据,作展示,要求使用分页器,包含上一页、下一页、当前页/总页。 结果: ① preparatio…...
蓝桥杯准备
书籍获取:Z-Library – 世界上最大的电子图书馆。自由访问知识和文化。 (zlibrary-east.se) 书评:(豆瓣) (douban.com) 一、观千曲而后晓声 别人常说蓝桥杯拿奖很简单,但是拿奖是一回事,拿什么奖又是一回事。况且,如果…...

AtCoder Beginner Contest 336 A-E 题解
比赛链接:https://atcoder.jp/contests/abc336比赛时间:2024 年 1 月 14 日 20:00-21:40 A题:Long Loong 标签:模拟题意:给定一个 n n n,输出 L L L、 n n n个 o o o和 n g ng ng。题解:按题意…...
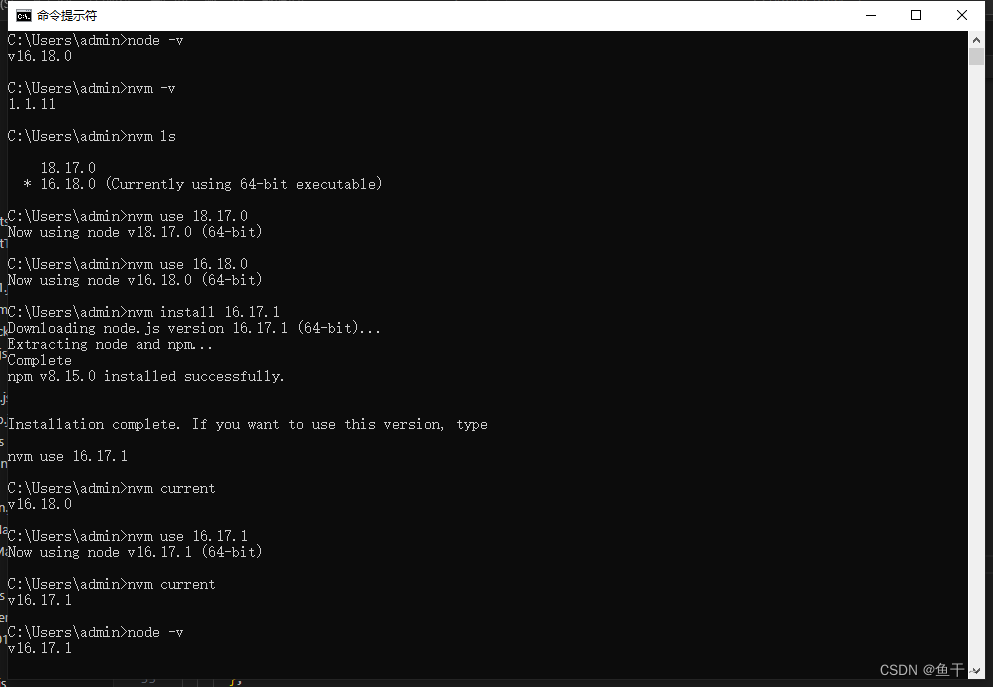
node各个版本的下载地址
下载地址: https://nodejs.org/dist/ 可以下载多个版本,使用nvm控制切换(需要先安装nvm再安装node) nvm下载地址(访问的是github,请科学上网,下载后解压安装exe即可):h…...
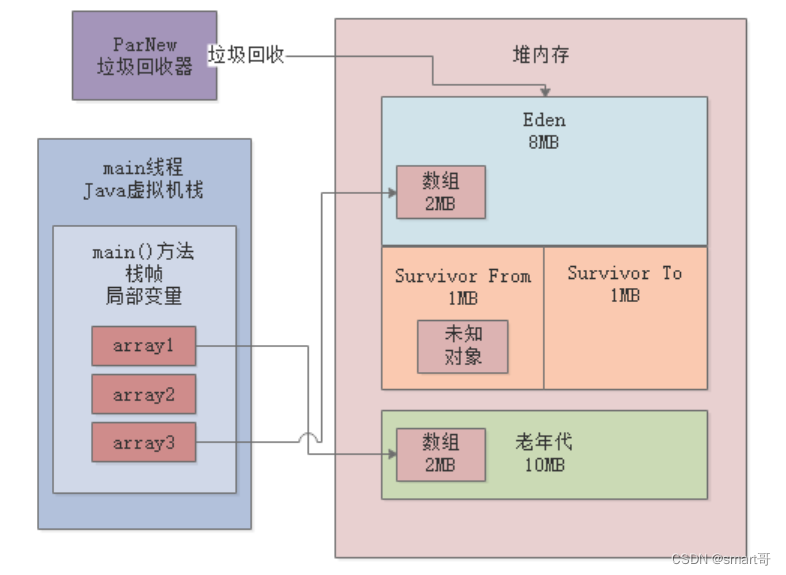
JVM实战(17)——模拟对象晋升
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 学习必须往深处挖&…...
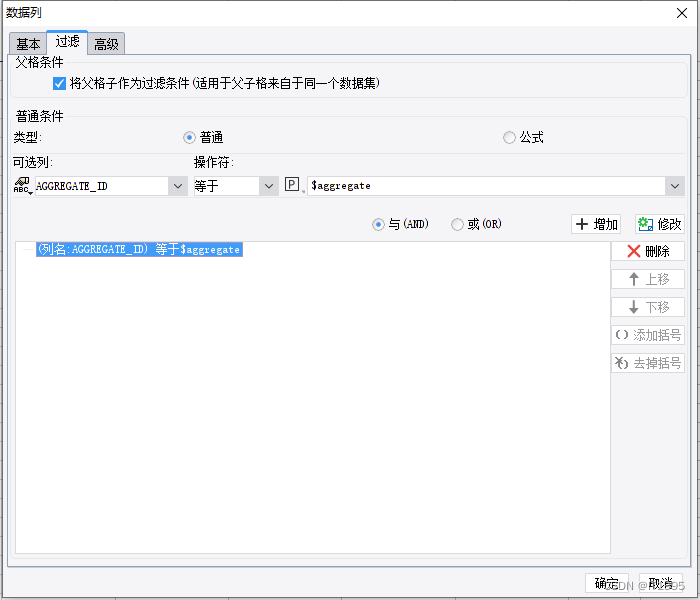
帆软笔记-决策表报对象使用(两表格联动)
效果描述如下: 数据库中有个聚合商表,和一个储能表,储能属于聚合商,桩表中有个字段是所属聚合商。 要求帆软有2个表格,点击某个聚合商,展示指定的储能数据。 操作: 帆软选中表格单元…...

DataGear专业版 1.0.0 发布,数据可视化分析平台
DataGear专业版 1.0.0 正式发布,欢迎大家试用! http://datagear.tech/pro/ DataGear专业版 基于 开源版 开发,新增了诸多企业级特性,包括: MySQL、PostgreSQL、Oracle、SQL Server以及更多兼容部署数据库支持OAuth2…...

AS,android SDK
android sdk中包含什么? Android平台工具(Android Platform Tools): 这包括 adb(Android Debug Bridge)等工具,用于在计算机和 Android 设备之间进行通信、调试和数据传输。 Android命令行工具…...

LeetCode第155题 - 最小栈
题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 push(x) —— 将元素 x 推入栈中。 pop() —— 删除栈顶的元素。 top() —— 获取栈顶元素。 getMin() —— 检索栈中的最小元素。 示例: 输入: [&q…...

Java微服务系列之 ShardingSphere - ShardingSphere-JDBC
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列专栏目录 [Java项…...
)
Unity中URP下实现能量罩(外发光)
文章目录 前言一、实现菲涅尔效果1、求 N ⃗ \vec{N} N 2、求 V ⃗ \vec{V} V 3、得出菲涅尔效果4、得出菲涅尔相反效果5、增加菲涅尔颜色二、能量罩 交接处高亮 和 外发光效果结合1、修改混合模式,使能量罩透明2、限制 0 ≤ H i g h L i g h t C o l o r ≤ 1 0\leq HighL…...

Golang 中哪些类型可以作为 map 类型的 key?
目录 可以作为 map 键的类型 不能作为 map 键的类型 最佳实践 小结 在 Go 语言中,map 是一种内置的关联数据结构类型,由一组无序的键值对组成,每个键都是唯一的,并与一个对应的值相关联。本文将详细介绍哪些类型的变量可以作为…...
C# 导出EXCEL 和 导入
使用winfrom简单做个界面 选择导出路径 XLSX起名字 打开导出是XLSX文件 // 创建Excel应用程序对象Excel.Application excelApp new Excel.Application();excelApp.Visible false;// 创建工作簿Excel.Workbook workbook excelApp.Workbooks.Add(Type.Missing);Excel.Works…...

轻量级负载均衡器Codex-lb:云原生场景下的部署与调优实践
1. 项目概述:一个轻量级的负载均衡解决方案 最近在折腾一些个人项目和小型服务部署时,我遇到了一个挺实际的问题:如何在不引入复杂架构和运维负担的前提下,为多个后端服务实例提供一个统一的、可靠的入口。你可能也遇到过类似场景…...

极域电子教室破解终极指南:如何快速解除课堂控制实现学习自由
极域电子教室破解终极指南:如何快速解除课堂控制实现学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为极域电子教室的全屏控制而烦恼吗?你是…...
)
用户NPS提升2.8倍的秘密:Lovable SaaS的3层共鸣架构,含Figma可复用组件库(限时开源)
更多请点击: https://intelliparadigm.com 第一章:Lovable SaaS产品开发指南 打造真正“可爱”(Lovable)的SaaS产品,核心在于将技术实现与人类情感体验深度耦合——用户不仅愿意使用,更主动分享、期待更新…...

诺云定制APP:赋能社区团购商家私域长效盈利
如今社区团购行业早已告别野蛮烧钱补贴的粗放发展阶段,迈入精细化私域运营、低成本稳复购的深耕时代。不管是深耕社区多年的本地团购实体店家、社区团长创业者,还是手握生鲜、日用刚需货源的供应链商家,都面临着共同经营难题:依赖…...

SK海力士晶圆代工战略:特色工艺如何重塑半导体产业格局
1. 韩国半导体雄心:从存储巨头到晶圆代工的野望最近几年,全球半导体产业的新闻头条几乎被台积电、英特尔和三星的千亿美元级投资计划所占据。然而,在2021年5月,一则来自韩国的消息,虽然声量相对较小,却揭示…...

5分钟免费激活Windows和Office:KMS_VL_ALL_AIO完整使用指南
5分钟免费激活Windows和Office:KMS_VL_ALL_AIO完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统未激活的烦恼而困扰吗?想要免费使用完整功能…...

Windows APK安装器完整指南:无需安卓手机直接安装应用
Windows APK安装器完整指南:无需安卓手机直接安装应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想要在Windows电脑上直接安装Android应用吗ÿ…...

【claude code agent 实践7】后台任务机制深度解析: 从S02到S08的演进
后台任务机制深度解析 文章目录后台任务机制深度解析🔄 s02 vs s08 核心变化对比🔍 新增核心逻辑详解1. BackgroundManager类(后台任务管理器)2. agent_loop关键变化 - 每次LLM调用前排空队列📊 后台任务完整工作流程图…...

JavaScript中隐藏类HiddenClasses对对象访问的加速
JavaScript引擎通过隐藏类机制优化对象属性访问,按固定顺序初始化属性可复用内存布局,乱序或动态增删会导致降级为慢字典模式,构造函数中预声明所有属性是保持性能的关键。JavaScript引擎(如V8)通过隐藏类(…...
)
老笔记本焕发第二春:微星GT60升级GTX1060保姆级避坑指南(含硬件ID修改)
微星GT60笔记本升级GTX1060全流程实战:从硬件改造到驱动破解 当手头的微星GT60笔记本逐渐跟不上现代游戏需求时,许多玩家会考虑升级显卡来延续它的使用寿命。MXM接口的GTX1060显卡因其性价比和性能表现成为热门选择,但整个升级过程充满技术陷…...