C++ 后端面试 - 题目汇总
文章目录
- 🍺 非技术问题
- 🍻 基本问题
- 🥂 请自我介绍?
- 🥂 你有什么问题需要问我的?
- 🍻 加班薪资
- 🥂 你对加班有什么看法?
- 🥂 你的薪资期望是多少?【待回答】
- 🍻 规划前景
- 🥂 你对自己的职业有什么规划吗?
- 🥂 你有对象没?在哪个城市?
- 🍺 项目经历
- 🍻 极简抖音服务器
- 🥂 用户密码是用明文存储的吗?
- 🍺 C++基础
- 🍻 新特性
- 🥂 C++11 的新特性有哪些?
- 🥂 你对 lambda 了解多少?
- 🥂 move 的作用是什么?
- 🥂 智能指针的原理是什么?如何实现智能指针?
- 🥂 实现智能指针需要哪些函数?【待回答】
- 🥂 智能指针出现循环引用如何解决?【待回答】
- 🍻 关键字 / 函数
- 🥂 volatile 关键字是干什么的?
- 🥂 sort 函数是基于快速排序还是插入排序的?
- 🥂 strcpy 和 strncpy 的区别?
- 🥂 static 的作用?【待回答】
- 🍻 继承 / 封装 / 多态
- 🥂 多态是如何实现的?
- 🥂 析构函数为什么一般为虚函数?
- 🍻 内存管理
- 🥂 程序的内存分区是怎么样的?
- 🥂 堆和栈的区别?
- 🥂 为什么要内存对齐?对齐原则是什么?
- 🥂 内存泄漏是什么?如何避免?
- 🥂 程序从开始编译到生成可执行文件的过程?【待回答】
- 🍻 语言对比
- 🥂 C++ 和 Python 的区别?【待回答】
- 🍻 STL
- 🥂 unordered_set、set、unordered_map、map 的区别?应用场景?
- 🍻 设计模式
- 🥂 常见的设计模式有哪些?【待回答】
- 🥂 单例模式是什么?请实现一下单例模式?
- 🥂 哲学家进餐问题?【待回答】
- 🍺 计算机网络
- 🍻 HTTP / HTTPS
- 🥂 在浏览器地址栏输入 URL 会涉及的技术步骤?
- 🥂 HTTP 和 HTTPS 的区别?
- 🥂 HTTP 1.0 / 1.1 / 2 / 3 的区别?
- 🥂 HTTP 的状态码有哪些?
- 🥂 HTTP 的请求和响应报文有哪些字段?
- 🥂 HTTP 长连接如何维持?
- 🍻 TCP / UDP
- 🥂 TCP 是如何保证可靠传输的?
- 🥂 TCP 和 UDP 的区别?
- 🥂 三次握手的过程是怎样的?
- 🥂 四次挥手的过程是怎样的?
- 🥂 四次挥手中 ACK 报文和 FIN 报文可以合并发送吗?
- 🥂 封包、拆包是什么?是基于 TCP 还是 UDP 的概念?
- 🍻 DNS
- 🥂 DNS 负载均衡是什么?【待回答】
- 🍺 操作系统
- 🍻 进程 / 进程
- 🥂 进程与线程的区别?
- 🥂 进程间通信方法有哪些?
- 🥂 线程间通信方法有哪些?
- 🥂 回收线程有哪些方法?【待回答】
- 🥂 线程切换状态有哪些?【待回答】
- 🍻 锁
- 🥂 在并发任务中,不加锁可能会出现哪些问题?
- 🥂 死锁是什么?产生原因是什么?如何避免?
- 🥂 介绍下几种典型的锁?
- 🍻 多路复用
- 🥂 IO 多路复用是什么?
- 🥂 IO 模型有哪些?
- 🥂 select、poll、epoll 的区别?
- 🍻 Linux
- 🥂 Linux 中异常和中断的区别?
- 🥂 Linux 中常用的命令有哪些?
- 🥂 Linux 如何查看用到的端口?【待回答】
- 🍻 其他
- 🥂 内核态和用户态的区别?【待回答】
- 🍺 MySQL
- 🍻 引擎
- 🥂 InnoDB、MylSAM 的区别?
- 🍻 锁
- 🥂 MySQL 的行级锁有哪些?
- 🍻 慢查询
- 🥂 如何排查一条慢 SQL?如何优化?
- 🍻 事务
- 🥂 事务的四大特性是什么?
- 🥂 事务的隔离级别有哪些?
- 🥂 脏读、幻读、丢弃更改、不可重复读是什么?
- 🍻 索引
- 🥂 为什么 MySQL 索引使用 B+ 树?为什么不用 B 树,红黑树,hash 表?
- 🥂 MySQL 中有哪些索引?
- 🥂 使用索引的好处有哪些?【待回答】
- 🥂 使用索引的注意事项有哪些?【待回答】
- 🍻 备份
- 🥂数据库的备份和灾备你有了解吗?
- 🍺 Redis
- 🍻 概念
- 🥂 Redis 是什么?
- 🍻 数据结构
- 🥂 Redis 的底层数据结构有哪些?
- 🍻 锁
- 🥂 Redis 如何实现分布式锁?
- 🍻 缓存
- 🥂 如何保证缓存与数据库的数据一致性?
- 🥂 Redis 的数据优化方案有哪些?【待回答】
- 🥂 热点数据和冷数据是什么?【待回答】
- 🍻 持久化
- 🥂 Redis 有哪些持久化机制?
- 🍺 面试算法
- 🍻 双指针
- 🥂 11. 盛最多水的容器 [数组] [面积] (双指针)
- 🥂 31. 下一个排列 [数组] [排列] (双指针) (推导)
- 🥂 42. 接雨水 [数组] [面积] (双指针)
- 🥂 160. 相交链表 [链表] [相交] (双指针)
- 🥂 LCR 139. 训练计划 I [数组] [元素交换] (双指针)
- 🍻 三指针
- 🥂 215. 数组中的第K个最大元素 [数组] [第K大元素] (三指针) (快速排序)
- 🍻 滑动窗口
- 🥂 3. 无重复字符的最长子串 [字符串] [子串] (滑动窗口)
- 🍻 二分法
- 🥂 153. 寻找旋转排序数组中的最小值 [旋转数组] [最小值] (二分法)
- 🥂 162. 寻找峰值 [数组] [峰值] (二分法)
- 🍻 DFS
- 🥂 200. 岛屿数量 [矩阵] [岛屿] (DFS)
- 🍻 贪心
- 🥂 452. 用最少数量的箭引爆气球 [数组] [区域重合] (贪心) (排序)
- 🍻 其他
- 🥂 8. 字符串转换整数 [字符串] [转换] (遍历)
- 🍻【待做】【199】
🍺 非技术问题
🍻 基本问题
🥂 请自我介绍?
🔶 面试官您好,我是深圳大学信息与通信工程的研三在校生,我叫XXX。下面我将从求职动机和过往经历介绍下我自己。
🔶 对于求职动机,虽然我本科和研究生阶段都是通信类专业,但是我在校期间接触的项目大多都是和软件相关的,比如本科接触过智能车的赛道识别,硕士期间接触的深度学习图像压缩,还有自己参与过的小组项目也都是软件相关的,自己对编程类的工作也更感兴趣。
🔶 对于过往经历,我在研三期间有一段实习经历,在深圳的中科鼎创公司作为一个后端实习生实习了四个月,主要工作是基于 C++ 实现对VMWare 虚拟机的灾备工作,后期对相关功能进行 go 的实现。我的在校项目有两个,第一个是参加的字节青训营的活动,官方会提供一个编写好的抖音前端界面,我们的任务就是对软件的后端功能进行实现,比如像用户登录,注册,发布视频,点赞搜藏等。第二个项目是一个webserver 服务器,当用户在浏览器上输入对应网址时,可以获取远程数据库中的文字,图片,视频等信息。我们科研工作的化主要集中于深度学习图像压缩,科研中使用语言大多是 python,目前已经发表了专利和小论文。我的性格的话比较外向,在工作和生活中也可以和别人很好的沟通交流,希望自己能够胜任这份工作。
🔶 以上是我的介绍,谢谢。
🥂 你有什么问题需要问我的?
🔶 请问你们在部门的主要业是什么?如果自己进入贵部门会负责什么?
🔶 请问面试官觉得我还存在着哪些不足的地方?
🔶 我如果能够应聘上这个岗位,还需要具备哪些知识或能力呢?
🔶 请问面试官对我的职业规划有什么建议?
🍻 加班薪资
🥂 你对加班有什么看法?
🔶 我觉得加班来赶工期或者赶进度是很正常的,特别是在互联网这个行业。业务肯定有比较忙,比较紧急的时候,对于加班我觉得是挺必要的。而且多把自己的精力放在工作中,自己能力提升的也更快些。
🥂 你的薪资期望是多少?【待回答】
🍻 规划前景
🥂 你对自己的职业有什么规划吗?
🔶 首先希望进到公司后,能够对新人有一定的培养,自己尽快的适应当前的工作。
🔶 在最初的两年脚踏实地的干好自己的本职工作,熟练掌握开发中需要用到的技术,为公司带来更多的价值。平时的工作生活中多向前辈请教,学习新的知识提高自己的水平。
🔶 在自己成为具备一定能力的工程师后,希望能熟悉部分项目的框架,原理,碰到问题可以快速定位解决。以后向着架构师或者别的方向发展,更多的提供自己的价值。
🥂 你有对象没?在哪个城市?
🔶 有的,我女朋友找到也是深圳的工作,所以我首要考虑的也是在深圳发展。
🍺 项目经历
🍻 极简抖音服务器
🥂 用户密码是用明文存储的吗?
🔶 不是,存储的是加密后的数据,比如我在项目中就用的是 md5 加密,存储的是 128 位的哈希值。
🔶 如果直接明文存储密码就十分的不安全,登录或者其他操作时验证密码,也是验证的加密值。
🍺 C++基础
🍻 新特性
🥂 C++11 的新特性有哪些?
🔶 在关键字上用 nullptr 代替了 NULL,引入了 auto 和 decltype 实现类型推导,引入了 final 和 override 继承关键字,引入了基于范围的 for 循环等。
🔶 引入了匿名函数 lambda 表达式,用来替代独立的函数或函数对象。
🔶 支持自定义类型的列表初始化,初始化代码更加简洁。
🔶 引入了智能指针,自动释放动态内存,避免忘记释放内存导致的内存泄漏。
🔶 引入了右值引用和 move 语义,减少了不必要的资源拷贝。
🥂 你对 lambda 了解多少?
🔶 lambda 表达式可以编写内嵌的匿名函数,用来替换独立的函数、匿名对象,增加代码的可读性。
🔶 每当定义一个 lambda 表达式,编辑器会自动生成一个匿名类,也成为闭包。在运行时,lambda 表达式会创建一个闭包实例,它可以通过传值或引用的方式获取作用域内的变量,也就是前面的 [],也可以通过参数列表获取参数,也就是后面的 ()。
🔶 lambda 表达式的语法定义为: [捕捉列表] (参数列表) mutable 是否可修改捕捉列表 -> 返回类型 {函数体}。其中捕获列表和函数体是必须有的,其他的可以省略。
🥂 move 的作用是什么?
🔶 move 是一种高效的资源转移机制,相当于转移了资源的所有权,这样可以让待销毁对象的资源原地转移到其他变量,避免不必要的内存拷贝操作,提高程序的性能。
🔶 move 本身不能移动任何东西,它的唯一作用是将一个左值引用强制转化为右值引用,编辑器只能对右值引用的对象调用移动构造 / 拷贝函数,实现移动语义。
🥂 智能指针的原理是什么?如何实现智能指针?
🔶 智能指针:本质上是一个类,它用来存储指向动态分配对象的指针,并负责该动态分配对象的释放,避免内存泄漏。当智能指针对象的生命周期结束后,会自动调用析构函数来释放动态分配的资源。
🔶 shared_ptr:多个该智能指针可以指向同一个对象。每当增加一个智能指针指向该对象时,所有的智能指针内部的计数器都会加一,每当减少一个智能指针指向该对象时,所有的智能指针内部计数器都会减一。因此当智能指针内部的引用计数器为零时,则会自动释放动态分配的内存资源。
🔶 unique_ptr:该智能指针独享所指向对象的所有资源。当资源进行转移时,原来的智能指针将被置空,因此 unique_ptr 不支持普通的拷贝和赋值操作,因为此时有两个智能智能指向同一个资源,导致同一内存多次释放。
🔶 weak_ptr:该智能指针主要是为了解决循环引用的问题,此时两个指针指向的内存都无法释放。weak_ptr 是一个弱引用,它指向 shared_ptr 管理的对象而不影响对象的计数。当访问对象时,可以使用 lock 函数来获取指向该对象的 shared_ptr。
🔷 智能指针的实现:
template<typename T>
class Shared_Ptr {
private:T* _ptr; // 指向资源的指针int* _pcount; // 指向引用计数的指针
public:// 构造函数,初始化智能指针Shared_Ptr(T* ptr = nullptr): _ptr(ptr), _pcount(new int(1)) {}// 拷贝构造函数,共享同一块内存,引用计数 +1Shared_Ptr(const SharedPtr& s): _ptr(s._ptr), _pcount(s._pcount) {(*_pcount)++;}// 赋值运算符重载SharedPtr<T>& operator=(const SharedPtr& s) {if (this != &s) {// 复制前,检查自己是否是最后一个指向先前某区域的指针,是的话释放之前指向的资源if (--(*(this->_pcount)) == 0) {delete this->_ptr;delete this->_pcount;}// 复制其他的智能指针,现在指向一个新的对象_ptr = s._ptr;_pcount = s._count;(*_pcount)++;}return *this;}// 解引用操作符重载T& operator*() {return *(this->_ptr);}// 成员访问操作符重载T* operator->() {return this->_ptr;}// 析构函数,处理引用计数,当为 0 时,释放资源。~ SharedPtr() {--(*(this->_pcount));if (*(this->_pcount) == 0) {delete _ptr;_ptr = nullptr;delete _pcount;_pcount = nullptr;}}
};
🥂 实现智能指针需要哪些函数?【待回答】
🥂 智能指针出现循环引用如何解决?【待回答】
🍻 关键字 / 函数
🥂 volatile 关键字是干什么的?
🔶 内存可见性:CPU 内核有自己的缓存,彼此之间不可见,使用 volatile 会强制将缓存写入主内存中,从主内存中加载数据。
🔶 禁止指令重排:指令重排是编译器为了优化程序的执行性能,而对指令重新排序的一种手段,在多线程环境下可能会出现问题。当一个变量被 volatile 修饰时,编译器会禁止对齐进行指令重排,从而确保程序的正确性。
🥂 sort 函数是基于快速排序还是插入排序的?
🔶 sort 中采用的是一种 IntroSort 内省式排序的混合排序算法。
🔶 首先判断排序的元素个数是否大于阈值,通常这个阈值为 16,如果元素个数小于阈值则直接使用插入排序。因为当序列中大多元素有序时,采用插入排序会更快。
🔶 如果元素个数大于阈值时,判断序列递归的深度会不会超过 2*log(n),如果递归深度没有超过阈值时就使用快速排序。
🔶 如果递归深度超过阈值时,那么快排的复杂度就退化了,这时候就采用堆排序,因为堆排序的复杂度是 nlog(n),比较稳定。
🥂 strcpy 和 strncpy 的区别?
🔶 这两个都是复制字符串的函数,不过 strncpy 可以指定复制的长度。
🔶 如果指定长大于目标长,则报错无法复制。
🔶 如果指定长大于源长,那么可以正常拷贝,自动加上结束符。
🔶 如果指定长小于源长,那么只能拷贝部分字符串,并且不会加上结束符。
🥂 static 的作用?【待回答】
🍻 继承 / 封装 / 多态
🥂 多态是如何实现的?
🔶 多态是指让不同的对象在使用相同的方法时,可以表现出不同的响应。
🔶 编辑器在发现基类中有 virtual 修饰的虚函数时,会为每个含有虚函数的类生成一份虚表,其中存放着一系列的虚函数地址。
🔶 编辑器会在对象中保存一个虚表指针指向这个虚表,从而在实际调用中找到对应的函数。
🔶 当派生类创建对象时,会自动调用构造函数,在构造函数中创建虚表,初始化虚表指针。
🔶 当派生类的虚函数没有重写时,派生类的虚表指针指向的是基类的虚表,当派生类对基类的虚函数进行重写时,派生类的虚表指针将指向自身重写的虚表。因此可以根据当前对象的虚表指针进行相应函数的调用,实现多态。
🥂 析构函数为什么一般为虚函数?
🔶 如果析构函数为虚函数,当基类指针可以指向派生类的对象,如果删除基类的指针,就会调用所指派生类对象的析构函数,而派生类的析构函数又会调用基类的析构函数,整个派生类的对象被完全释放。
🔶 如果析构函数不为虚函数,则编辑器实施静态绑定,当删除基类指针时,只会调用基类的析构函数而不会调用派生类的析构函数,造成派生类析构不完全,导致内存泄漏。
🍻 内存管理
🥂 程序的内存分区是怎么样的?
🔶 程序的内存分区主要分为 5 个部分,从高到低分别是栈区,堆区,全局数据区,常量区和代码区。
🔶 栈区:程序运行时,函数中局部变量的存储空间在栈上创建,函数执行结束时,这些变量的存储空间会被自动释放。栈的内存分配由操作系统负责,效率高,但是分配的内存空间有限。
🔶 堆区:由 new 操作符所分配的动态内存,都存放于堆中,但是这些内存的释放需要手动控制,一个 new 对应一个 delete 释放。堆的内存分配效率低,但是可分配的内存空间大。
🔶 全局数据区:里面存放着全局变量和静态变量,如果有些变量没有初始化,那么在这里会进行自动的初始化。
🔶 常量区:里面存放着常量,不允许修改。
🔶 代码区:里面存放的是二进制的代码。
🥂 堆和栈的区别?
🔶 申请方式不同:栈是由系统自动分配的,堆是程序员手动分配的。
🔶 申请大小不同:栈是一片连续的内存区域,大小是操作系统预定义好的。堆是一片不连续的内存区域,大小可以灵活调整。
🔶 申请效率不同:栈由系统分配,速度快,且不会有碎片,堆由程序员分配,速度慢,而且会产生内存碎片。
🔶 生长方向不同:栈的内存分配是由高到低的,堆的内存分配是由低到高的。
🥂 为什么要内存对齐?对齐原则是什么?
🔶 CPU 访问数据时,并不是逐字节的访问,而是以字长为单位进行访问,比如在 32 位系统中,字长为 4 字节。这样设计可以提高 CPU 访问内存的效率,比如同样是访问 8 字节的数据,以字长为单位读取仅需要两次即可,而逐字节访问需要 8 次。
🔷 结构体中的成员,会按照声明的顺序进行存储,而且第一个成员的地址就是结构体的地址。
🔷 结构体中的成员,一定会存放在整数倍自身大小的偏移量上,比如 int 只会方在 4 的倍数上。
🔷 结构体的总大小为最大对齐数的整数倍,而最大对齐数与最大的成员大小有关。
🔷 可以通过 alignof 查看当前对齐数,alignas 指定对齐数,或通过 pragma back 指定对齐数。
🥂 内存泄漏是什么?如何避免?
🔶 内存泄漏通常是指堆中内存的泄漏,应用程序在使用如 malloc,realloc,new 等函数分配到堆中内存时,使用完毕后应该立即使用 free,delete 释放该内存,否则这块内存就无法被再次使用,造成内存泄漏。
🔷 可以采用记数法,当使用 new 或 malloc 时,让计数加一,delete 或 free 时,让计数减一,程序执行完毕后打印计数,如果计数不为 0 则存在内存泄漏。
🔷 虚构函数需要声明为虚函数,防止父类指针指向子类对象时,编辑器实施静态绑定只会调用父类的析构函数,而造成子类的析构不完全,造成内存泄漏。
🔷 养成 new,delete 和 malloc,free 配对的习惯。
🔷 通过 new 构造的对象数组,需要使用 delete[] 删除。
🥂 程序从开始编译到生成可执行文件的过程?【待回答】
🍻 语言对比
🥂 C++ 和 Python 的区别?【待回答】
🍻 STL
🥂 unordered_set、set、unordered_map、map 的区别?应用场景?
🔶 map 是一种键值对的数据结构,支持自动排序,底层基于红黑树实现,查询复杂度为 OlogN,但是占用空间比较大,需要存放父子节点,染色等信息。
🔶 set 和 map 类似,支持自动排序,底层基于红黑树实现,它是一种只有键的数据结构。
🔶 unordered_map 不支持排序,底层是通过哈希表来实现,通过哈希函数计算元素的位置,因此查询复杂度为 O(1)。
🔶 unordered_set 和 unordered_map 类似,不支持排序,基于哈希表实现,是一种只有键的数据结构。
🔷 map、set 主要用于元素有序的场景,unordered_map、unordered_set 主要用于需要高效查询的场景。
🍻 设计模式
🥂 常见的设计模式有哪些?【待回答】
🥂 单例模式是什么?请实现一下单例模式?
🔶 单例模式是一种创建型设计模式,能够保证一个类只有一个实例,并提供一个访问该实例的全局节点。它可以解决一个全局使用的类,被频繁的创建与销毁的问题(比如首页页面刷新),使用单例模式可以有效减少内存开销。
class Single {
private:// 防止外界构造和删除对象Single() = default; // 构造函数~Single() = default; // 析构函数Single(const Single&) = default; // 拷贝构造函数Single& operator=(const Single&) = default; // 运算符重载// 静态析构函数,用于在程序结束时销毁实例static void Destructor*() {if (instance != nullptr) {delete instance;instance = nullptr;}}// 静态指针,指向Single的唯一实例static Single *instance;// 静态互斥锁,用于同步多线程访问static mutex mutex_;
public:// 公共静态方法,提供全局访问点static Single* GetInstance() {// 第一次检查,查看实例是否已经被创建,如果没有则进入同步块if (instance == nullptr) {// 使用互斥锁确保同时只有一个线程可以执行实例创建的代码lock_guard<mutex> lock(mutex_);// 第二次检查,确保实例在当前线程等待锁期间未被创建if (instance == nullptr) {// 创建Single的新实例instance = new Single();// 注册析构函数,以便在程序退出时销毁实例atexit(Destuctor);}}return instance;}
};
// 新建实例
Single single::instance = nullptr;
🥂 哲学家进餐问题?【待回答】
🍺 计算机网络
🍻 HTTP / HTTPS
🥂 在浏览器地址栏输入 URL 会涉及的技术步骤?
🔶 浏览器首先会对 URL 进行解析,生成发送给服务器的请求报文。
🔶 查询服务器域名对应的 IP 地址,浏览器会先查询本地缓存,本地没有的话就从通过 DNS 服务器进行查询。
🔶 查询到服务器的 IP 地址后,向服务器三次握手建立 TCP 连接,并保持通信。
🔶 期间浏览器可以向服务器发送 GET,POST 等请求,比如获取数据库资源,修改数据信息等。
🔶 服务器会对请求进行处理,并发送响应报文给浏览器。
🔶 浏览器根据返回的响应解析内容并渲染网页,呈现在屏幕上。
🥂 HTTP 和 HTTPS 的区别?
🔶 HTTP 是超文本传输协议,信息是明文传输的,因此存在安全风险;HTTPS 在 TCP 和 HTTP 之间加入了 SSL/TLS 协议,使得报文可以加密传输,更加的安全。
🔶 HTTP 建立连接比较简单,仅需要 TCP 三次握手;HTTPS 不仅需要 TCP 三次握手,还需要经历 SSL/TLS 的握手过程。
🔶 HTTP 的默认端口是 80;HTTPS 的默认端口为 443。
🔶 HTTP 不需要数字证书;HTTPS 需要申请数字证书,来确保服务端的身份是可信的。
🥂 HTTP 1.0 / 1.1 / 2 / 3 的区别?
🔶 HTTP 1.0 是一种无状态,无连接的应用层协议,浏览器每次请求都需要与服务器建立一个 TCP 连接,处理完请求之后立即断开连接,不记录过去的状态。
🔶 HTTP 1.1 支持长连接,在一个 TCP 连接上可以同时传输多个 HTTP 请求和响应,减少了网络延迟。
🔶 HTTP 2 是基于二进制流的,可以分解为独立的帧交错发送,提高网络的传输效率。
🔶 HTTP3 是最新的版本,它使用了 QUIC 协议来提高网络的传输效率。
🥂 HTTP 的状态码有哪些?
🔶 1xx:信息状态码,表示接收的请求正在处理,比如 100 代表一切正常。
🔶 2xx:成功状态码,表示请求被正常处理,比如 200 代表成功。
🔶 3xx:重定向状态码,表示需要附加的操作来完成请求,比如 301 代表永久重定向,访问的资源已经被转移到其他位置。
🔶 4xx:客户端错误码,代表客户端发送的请求中存在错误,比如 404 代表访问资源不存在。
🔶 5xx:服务端错误码,代表服务端处理请求时出现错误,比如 503 代表服务器繁忙,无法处理请求。
🥂 HTTP 的请求和响应报文有哪些字段?
🔶 请求报文的第一行包含了请求方法,URL,协议类型。
🔶 接下来的多行的请求头信息,主要包含 Accept 接收类型,Connection 连接类型,Host 等信息。
🔶 请求头和请求体之间用空格区分开,最后是请求体的具体内容。
🔷 响应报文的第一行包含了协议版本,状态码,状态描述。
🔷 接下来是多行的响应头信息,主要包含 Content-length 响应长度,Content-type 响应格式 等信息。
🔷 响应头和响应体之间同样用空格区分开,最后是响应体的具体内容。
🥂 HTTP 长连接如何维持?
🔶 可以在服务端设置一个保活定时器,当定时器开始工作的时候就向客户端发送探测报文,如果对方收到探测报文并返回 ACK,则代表连接还维持,否则就已经断开。
🔶 可以在服务端设置 keep-alive 参数来保持长连接,它可以指定长连接超时时间,超时后如何没有数据传输就会自动连接,如果有数据传输则超时时间重制。
🍻 TCP / UDP
🥂 TCP 是如何保证可靠传输的?
🔶 超时重传:接收到收到消息后,会发送一个响应报文,如果发送方一段时间内没有收到响应报文,就会触发超时重传机制。
🔶 数据校验:TCP 头部有校验和,用来校验报文是否损坏。
🔶 分片排序:TCP 会按照最大传输单元 MTU 合理分片发送数据,接受方会缓存未按序到达的数据,重新排序后发送给应用层。
🔶 流量控制:当接收方来不及处理发送的数据时,会使用滑动窗口提醒发送方降低发送速率。
🔶 拥塞控制:当网络拥塞时,通过拥塞窗口减少发送方的发送速率,避免丢包。
🥂 TCP 和 UDP 的区别?
🔶 连接:TCP 是面向连接的协议,传输前需要先建立连接;UDP 可以不建立连接直接传输。
🔶 可靠性:TCP 是可靠的,数据可以无差错,有序,完整的传输;UDP 是尽最大可能的交付,并不可靠。
🔶 服务对象:TCP 是一对一的点到点服务;UDP 支持一对一,一对多,多对一的服务。
🔶 拥塞控制:TCP 有拥塞控制;UDP 没有。
🔶 首部开销:TCP 首部长,开销较大;UDP 首部开销固定只有 8 字节,较小。
🔶 传输方式:TCP 是基于字节流的传输,无边界但是有序;UDP 是基于包的传输,有边界但是无序。
🔶 应用场景:TCP 是面向连接且可靠的,因此主要用于类似文件传输这样的场景;UDP 是无连接不可靠的,但因为其传输较快可以用于类似音视频通话这样的场景。
🥂 三次握手的过程是怎样的?
🔶 最开始,客户端和服务端都处于 CLOSE 状态,服务端主动监听端口,处于 LISTEN 状态。
🔶 此时客户端请求连接,发送 SYN 报文,进入 SYN_SEND 状态。
🔶 服务端收到 SYN 报文后,发送 SYN+ACK 报文表示已已经收到消息,同意连接,随后进入 SYN_RECV 状态。
🔶 最后当客户端收到 SYN+ACK 报文后,发送最后的 ACK 报文并进入 ESTABLISH 状态,服务端收到 ACK 报文后也进入 ESTABLISH 状态。
🥂 四次挥手的过程是怎样的?
🔶 最开始,客户端和服务端处于 ESTABLISH 状态,当客户端想要断开时,会发送 FIN 报文给服务端,并进入 FIN_WAIT_1 状态。
🔶 服务端收到 FIN 报文后,发送 ACK 报文给客户端,表示收到信息,随后进入 CLOSE_WAIT 状态。
🔶 客户端收到 ACK 报文后,进入 FIN_WAIT_2 状态。
🔶 服务端将待处理数据处理完毕后,向客户端发送 FIN 报文表示同意断开,随后进入 LAST_ACK 状态。
🔶 客户端收到 FIN 报文后,回应 ACK 给服务端,进入 TIME_WAIT 阶段。
🔶 服务端收到 ACK 报文后,直接进入 CLOSE 状态,此时服务端已经关闭连接。
🔶 而客户端需要等待 2MSL 时间,等待完后自动进入 CLOSE_WAIT 状态,关闭连接。
🥂 四次挥手中 ACK 报文和 FIN 报文可以合并发送吗?
🔶 在四次挥手中,服务端收到了来自于客户端的 FIN 报文,会先发送 ACK 报文告知已经收到消息,之后在处理完自己的数据之后,才会发送 FIN 报文。
🔶 如果在收到客户端的 FIN 时没有数据需要处理,并且开启了 TCP 延迟确认机制,那么二三次握手是可以合并的,也就是 ACK 包和 FIN 包合并发送。
🥂 封包、拆包是什么?是基于 TCP 还是 UDP 的概念?
🔶 封包和拆包都是基于 TCP 的概念,因为 TCP 是无边界的二进制的流传输,所以需要对 TCP 进行封包和拆包,确保发送和接收数据的不粘连。
🔶 封包:在发送数据包的时候,为每个 TCP 数据包加上一个包头,将数据报文分为包头和包体两个部分,其中包头中包含数据包的长度信息。
🔶 拆包:接收方在收到报文后,根据包头中数据的长度信息来截取包体。
🍻 DNS
🥂 DNS 负载均衡是什么?【待回答】
🍺 操作系统
🍻 进程 / 进程
🥂 进程与线程的区别?
🔶 调度:进程是资源分配的基本单位;线程是 CPU 调度的基本单位。
🔶 拥有资源:进程拥有内存资源、CPU 资源、文件资源等;线程只拥有自己的寄存器和栈资源,其他资源彼此共享。
🔶 切换效率:进程的切换内容包含虚拟空间地址、页表、硬件上下文等,切换内容保存在内核中,会涉及用户态到内核态的切换,因此切换效率低;线程的切换内容也保存在内核中,但因为其切换内容仅包含部分寄存器资源,因此切换效率更好些。
🔶 并发性:多个进程之间可以并发运行;一个进程中的多个线程之间也可以并发运行。
🥂 进程间通信方法有哪些?
🔶 管道:管道允许一个进程和拥有共同祖先的另一个进程间进行通信。但是管道通信的效率较低,不适合频繁的数据交换。
🔶 命名管道:命名管道允许任意两个进程之间进行通信,通过 mkdifo 来创建命名管道。
🔶 消息队列:消息队列是一种存储在内核中的消息链表,有写权限的进程可以向队列中添加消息,有读权限的进程可以从队列中取出消息。消息队列中消息体的大小有长度限制,不能传输过大的数据,在通信过程中,存在用户态和内核态之间的数据拷贝开销。
🔶 共享内存:共享内存把多个进程中的虚拟地址空间映射到相同的物理地址空间中去。这样一个进程写入数据,其他进程立马可以看到,不需要数据拷贝的过程,大大提高了通信效率。但如果多个进程同时修改共享内存,那么可以会发生冲突。
🔶 信号量:信号量是一个整形的计数器,主要用于实现进程间的互斥和同步。信号量的值代表资源的数量,控制信号量的方式有 P 操作和 V 操作,分别发生在进入共享资源,离开共享资源时。
🔶 信号:信号是进程间的一种异步通信机制,可以在任何时候发送信号给某一进程。信号的来源有硬件来源(ctrl+c 终止进程)和软件来源(kill 命令)等。
🔶 socket:socket 可以实现跨网络不同主机间进程的通信,也可以实现同主机间不同进程间的通信。
🥂 线程间通信方法有哪些?
🔶 线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的数据交换相关的机制。
🔶 锁机制:锁机制包含互斥锁,读写锁,条件变量等。互斥锁以排他的方式防止同共享数据同一时间被多个线程修改。读写锁允许多个线程同时读数据,但是同一时间只能有一个线程写数据。条件变量可以阻塞线程,直到某个特定的条件为真则让线程继续执行,通常和互斥锁配合使用。
🔶 wait / notify 等待:当一个线程调用锁对象的 wait 方式时,线程会放弃同步锁进入等待队列,直到其他线程进入同步锁调用 notify 唤醒该线程。
🔶 volatile 共享内存:volatile 具有可见性和有序性,其中可见性就是确保线程间可以进行通信。实现可见性需要两个原则保证,当 volatile 修饰的变量被线程修改时,必须立即刷新到主内存;当线程读取 volatile 修饰的数据时,需要从主内存中读取新值。
🔶 信号量:信号量是一个整形的计数器,主要用于实现进程间的互斥和同步。信号量的值代表资源的数量,控制信号量的方式有 P 操作和 V 操作,分别发生在进入共享资源,离开共享资源时。
🔶 信号:信号是进程间的一种异步通信机制,可以在任何时候发送信号给某一进程。信号的来源有硬件来源(ctrl+c 终止进程)和软件来源(kill 命令)等。
🥂 回收线程有哪些方法?【待回答】
🥂 线程切换状态有哪些?【待回答】
🍻 锁
🥂 在并发任务中,不加锁可能会出现哪些问题?
🔶 当两个线程使用同一个全局变量时,可能会导致数据不一致的问题。
🔶 比如 A 线程修改了数据,但是 B 线程还是从缓存中读取未更新的数据,导致数据不一致。
🥂 死锁是什么?产生原因是什么?如何避免?
🔶 死锁:在并发编程中,线程访问共享资源前会加上互斥锁,只有成功持有锁时才能操作共享资源。当两个线程为了访问两个不同的共享资源时,会使用两个互斥锁,如果这两个互斥锁之间存在着循环依赖,则会同时等待对方释放锁,导致死锁。
🔷 死锁的产生需要同时满足四个条件:
🔷 互斥条件:线程 A 已持有的资源,不能被线程 B 持有。
🔷 持有并等待条件:线程 A 已持有资源 1,想要资源 2,则需要等待其他线程释放资源 2,在此期间资源 1 不会被释放。
🔷 不可剥夺条件:线程 A 已持有资源 1,在使用完毕之前,不可以被其他线程剥夺。
🔷 环路等待条件:线程间获取资源的顺序构成了环路,比如线程 A 持有资源 1,想要资源 2,线程 B 持有资源 2,想要资源 1。
🔶 避免方法:采用资源有序分配法来破坏环路等待条件。当多个线程都需要部分相同资源时,应该保证获取资源的顺序是一致的,比如线程 A 和线程 B 都是先获取资源 1,再获取资源 2。
🥂 介绍下几种典型的锁?
🔶 在多线程环境中,为了避免多个线程同时修改同一资源,造成资源混乱,因此需要在访问共享资源前加锁。
🔶 互斥锁:互斥锁是为了在任意时间内,仅有一个线程可以访问共享资源。当线程A加锁成功时,只要线程A没有释放锁,那么线程B就会加锁失败,并释放CPU让给其他线程。随后线程B进入阻塞睡眠状态,等待锁被释放后,被内核唤醒继续执行业务。
🔶 自旋锁:自旋锁也是为了在任意时间内,仅有一个线程可以访问共享资源。但是当自旋锁被持有而导致锁获取失败时,线程不会立即释放CPU,而是一直循环尝试获取锁,直到获取锁成功。因此自旋锁一般用于加锁时间很短的场景,较少了线程上下文切换的开销,效率更高。
🔶 读写锁:读写锁由读锁和写锁两部分构成,如果只读取共享资源用读锁加锁,如果需要修改共享资源则需要用写锁加锁,它主要用于可以明确区分读操作和写操作的场景,在读多写少的场景下可以发挥出优势。
🔶 条件变量:条件变量是一种同步机制,可能使线程在阻塞等待到某个条件发生后,继续执行业务。比如在生产者消费者模型中,希望在生产 N 个产品后进行庆祝。假设线程 A 是生产线程,线程 B 是查询线程。如果使用互斥锁,线程 B 需要不断地轮询查看是否满足条件,每次查询都需要加锁解锁,非常浪费资源。而使用条件变量可以高效解决,当线程 B 发现不满足条件时,直接进入阻塞等待状态。接着在线程 A 中判断是否满足条件,当满足条件时由线程 A 发送信号唤醒线程 B 继续查询,避免了无效的加锁解锁操作。
🍻 多路复用
🥂 IO 多路复用是什么?
🔶 IO 多路复用是一种处理多个 IO 流的技术。它允许单个进程同时监听多个文件描述符,当一个或多个文件描述符准备读写时,可以立即响应。这种技术可以提高系统的并发能力和响应能力,减少系统资源的浪费。
🔶 在 linux 中,select、poll、epoll 都是 IO 多路复用的实现方式,它们都可以同时监听多个文件描述符,一旦某个文件描述符就绪,就能通知程序进行对应的读写操作。
🥂 IO 模型有哪些?
🔶 阻塞 IO:当进程 A 发起数据请求时,如果内核数据没有准备好,A 会一直处于等待状态,直到内核数据准备才会通知 A。优点是阻塞期间,不会占用 CPU 的资源。缺点是如果长时间处于阻塞状态,比较占用连接资源。
🔶 非阻塞 IO:当进程 A 发起数据请求时,如果内核没有准备好数据,会立即告诉应用 A,不会让 A 等待。之后 A 会进行多次的询问,直到内核准备好数据告知 A。优点是用户线程不用阻塞,实时性好。缺点是用户线程轮询,比较占用 CPU 的资源。
🔶 IO 多路复用:提供一种工具如 select、poll、epoll 来同时监听多个 fd 的操作,比如 select 函数可以让内核检查是否有 fd 可读或可写。如果没有准备就绪,则进入阻塞状态,只要有一个 fd 准备就绪,select 会调用进程进行相应的处理。优点是只需要少量的线程就可以监听大量的连接,大大减少系统开销。
🔶 信号驱动 IO:当进程发起一个 IO 操作时,会向内核注册一个信号处理函数,进程返回不阻塞。当内核准备就绪时,会发送信号给进程,进程在信号处理函数中调用 IO 读取数据。
🔶 异步 IO:当进程发起一个 IO 操作时,进程返回不阻塞。当内核把整个 IO 处理完毕后,才会告知进程,如果 IO 操作成功则进程可以直接获取数据。
🥂 select、poll、epoll 的区别?
🔶 连接数不同:select 的最大连接数有限制,通过 FD_SETSIZE 宏定义,大小是 32 的整数倍;poll 和 select 本质上没有区别,只是最大连接数没有限制,因为它通过链表来存储连接信息;epoll 虽然有连接数限制,但这个数很大,1G 内存可以打开近 10 万的连接。
🔶 IO 效率不同:select 和 poll 都采用轮询的机制,会对 socket 进行线性遍历,在 socket 过多时效率会很低;epoll 是事件驱动的,只有活跃的 socket 才会主动调用 callback 函数,因此 epoll 的效率与 socket 的数量无关,而仅与活跃的 socket 数量有关。
🔶 消息传递方式:select 和 poll 中的消息传递需要将内核态中的消息传递到用户态,涉及内核拷贝动作;epoll 中的消息传递是通过内核用户空间共享同一块内存来实现的。
🍻 Linux
🥂 Linux 中异常和中断的区别?
🔶 发送源不同,中断是由硬件设备产生的,异常是由 CPU 产生的,但都是发送到内核,内核调用不同的程序进行处理。
🔶 当处理中断时,处于中断上下文中,当处理异常时,处于进程上下文中。
🔶 中断不是时钟同步的,因此随时可能到来,但异常是 CPU 产生的,具有时钟同步的特点。
🥂 Linux 中常用的命令有哪些?
🔶 文件:mv 移动文件,cp 拷贝文件,mkdir 创建目录,cd 切换目录,ls 显示目录中的文件。
🔶 权限:chmod 修改权限,chown 修改所有者,useradd 添加新用户。
🔶 资源:netstat 显示网络状况,ping 测试网络连通性,ps -ef 查看进程信息,top 查看系统资源占用。
🔶 压缩:tar -zxvf 压缩文件。
🥂 Linux 如何查看用到的端口?【待回答】
🍻 其他
🥂 内核态和用户态的区别?【待回答】
🍺 MySQL
🍻 引擎
🥂 InnoDB、MylSAM 的区别?
🔶 事务支持:InnoDB 支持事务,具有 ACID 属性;MyISAM 不支持事务,适用于读多写少的场景。
🔶 锁支持:InnoDB 支持行级锁,仅锁定实际需要的数据;MyISAM 只支持表级锁。
🔶 外键支持:InnoDB 支持外键,保证了数据的完整性;MyISAM 不支持外键。
🔶 崩溃恢复:InnoDB 在崩溃后可以自动恢复;MyISAM 崩溃后需要手动恢复或使用备份恢复。
🔶 备份:InnoDB 支持热备份,即在数据库运行的时候进行备份;MyISAM 不支持热备份,需要保证备份期间没有写操作。
🍻 锁
🥂 MySQL 的行级锁有哪些?
🔶 记录锁:仅仅锁定一条记录。
🔶 间隙锁:锁定一个范围,但是不包括记录本身。
🔶 临键锁:锁定一个范围,同时也锁定记录本身。
🔶 在读提交隔离级别下,行级锁的种类只有记录锁。
🔶 在可重复读隔离级别下,行级锁的种类有记录锁,间隙锁,临键锁。
🍻 慢查询
🥂 如何排查一条慢 SQL?如何优化?
🔶 慢查询是记录在 MySQL 中响应时间超过阈值的语句,这些语句被记录在慢查询日志中。慢查询日志可以通过设置 slow_query_log 属性来开启。
🔶 可以通过 explain 指令去查询 SQL 语句的执行计划,看 SQL 语句是否使用索引,全表扫描等。
🔷 如果是因为没有使用索引,那么就使用合适的索引。
🔷 如果是因为数据表过大,即使使用索引也慢,那么需要考虑分表。
🍻 事务
🥂 事务的四大特性是什么?
🔶 原子性:一个事务中的操作,要么全部完成,要么全部不满成,不存在只完成部分的情况。如果中间发生错误会进行回滚操作。
🔶 一致性:事务开始前和结束后,数据库的完整性没有遭到破坏。
🔶 隔离性:当多个事务访问数据库时,多个事务之间相互隔离,互不干扰。
🔶 持久性:事务结束后,对数据库的修改应该是永久的,即使遇到故障也不会丢失。
🥂 事务的隔离级别有哪些?
🔶 读未提交:一个事务还没有提交时,它做出的修改可以被其他事务读到。可能会出现脏读、不可重复读、幻读等情况。
🔶 读提交:一个事务在提交后,它做出的修改才能被其他事务读到。可能会出现不可重复读,幻读等情况。
🔶 可重复读:当前执行的事务对数据的修改对外是不可见的,因此其他事务多次执行相同查询操作时,结果应该是相同的。可能会出现幻读情况。
🔶 可串行化读:当多个事务对同一个记录进行读写时,会加上读写锁,一个事务处理完毕后才会轮到下一个事务。
🥂 脏读、幻读、丢弃更改、不可重复读是什么?
🔶 脏读:事务 A 读取到了事务 B 未提交并修改过的数据,那么当事务 B 发生错误并回滚时,事务 A 读取的数据和实际的数据不一致,发生脏读现象。
🔶 幻读:事务 A 多次查询符合某个条件的记录数量,但同时事务 B 进行一些插入删除操作,使得事务 A 多次查询的结果不一致,发生幻读现象。
🔶 丢弃修改:事务 A 和事务 B 同时对一个数据进行操作,但最终事务 B 的结果把事务 A 的结果覆盖,发生丢弃修改现象。
🔶 不可重复读:事务 A 读取了一个数据,但随后事务 B 对数据进行了修改,事务 B 再次读取发现数据不一样,发生了不可重复读现象。
🍻 索引
🥂 为什么 MySQL 索引使用 B+ 树?为什么不用 B 树,红黑树,hash 表?
🔶 Mysql 中的数据是放在磁盘的,读取数据会有访问磁盘的操作,而访问磁盘的 IO 操作效率很低。
🔶 二分查找树可以快速地查找到数据,但是极端情况下,比如依次插入递增的元素,那么查询数据的复杂度会从 O(logn) 退化为 O(n)。
🔶 自平衡二叉树是高度平衡的,确保复杂度为 O(log n),但是当数据量过大时,树的高度依然很高,磁盘 IO 次数也更多。
🔶 B 树和 B+ 树中,一个节点有多个子节点,因此树的高度会变低,磁盘 IO 次数也会降低,查询效率更高。
🔷 B+ 树中的叶子节点存放数据,非叶子节点仅存放索引,在相同数据量下,B+ 数的非叶子节点可以存放更多的索引,因此高度比 B 树更低,查询效率也更高。
🔷 B+ 树中有着大量的冗余索引,这些冗余索引可以让 B+ 树在插入删除时的效率更高,树的结构也不会发生太复杂的变化;
🔷 B+ 树的叶子节点之间用链表连接了起来,有利于范围查询,而 B 树只能通过前序遍历来范围查询。
🔶 红黑树属于一种平衡二叉树,它没有实现绝对平衡而是选择实现局部平衡,使得查找,删除,插入的复杂度都为 O(log2 n)。但它本质上还是二叉树,当数据量过大时高度还是会很高,磁盘 IO 次数会增加导致效率变低。
🔶 当进行连续数据查询时,红黑树也需要通过前序遍历来范围查询,效率不如 B+ 树。
🔷 采用哈希表的查询复杂度为 O(1),速度确实更快,但数据库中可能查询多条连续数据,由于 B+ 树的有序性,进行范围查询时会比 hash 表更快。
🔷 hash 表需要把数据全部加载到内存中,非常消耗内存,而采用 B+ 树可以按节点分段加载,内存消耗更少。
🥂 MySQL 中有哪些索引?
🔶 普通索引:仅可以加速查询。
🔶 唯一索引:可以加速查询,并且列值唯一可以为空。
🔶 主键索引:可以加速查询,并且列值唯一不可以为空,表中只能有一个主键。
🔶 组合索引:多列组成的一个索引,专门用于组合搜索,效率高于索引合并。
🔶 全文索引:对文本的内容进行分词,搜索。
🔶 索引合并:使用多个单列索引,组合搜索。
🔶 覆盖索引:使用多字段的联合索引,使得从非主键中就能查询到的记录,而不需要查询主键,避免了回表,可以减少树的搜索次数。
🔶 聚簇索引:它的表数据和索引是放在一起存储的,存放在叶子节点中,找到索引就相当于找到了数据。
🔶 非聚簇索引:它的表数据和索引分为两部分存储,它的叶子节点只存放对应的主键值,根据主键值二次查找数据。
🥂 使用索引的好处有哪些?【待回答】
🥂 使用索引的注意事项有哪些?【待回答】
🍻 备份
🥂数据库的备份和灾备你有了解吗?
🔶 数据库的备份和灾备主要是为了保护数据库中的数据不因为意外情况而丢失。
🔶 数据库的备份:是指定期为数据库创建副本到另一个位置,当发生数据丢失或数据库崩溃时进行恢复。
🔶 数据库的容灾:是指当数据库主服务器发生故障或不可用时,确保备用服务器可以接管数据库系统并提供相应服务。
🔷 数据库的备份可以分为完全备份和增量备份,其中完全备份是指备份数据中的所有数据,因此比较耗时和占用内存。增量备份是指仅备份距离上次备份后修改过的数据,因此这种备份方式速度更快,占用内存更少。
🔷 数据库的备份还可以分为冷备份和热备份,其中冷备份是指只有当数据库停止运行,没有发生数据修改时才可以进行备份,而热备份可以在数据库运行的过程中进行备份。
🔷 数据库的容灾可以分为数据库复制和数据库镜像,其中数据库复制把数据库的副本移动到另一个服务器,使其可以独立运行,数据库镜像是创建数据库的实时副本,可以提供几乎无中断的故障转移,但更耗费网络资源。
🍺 Redis
🍻 概念
🥂 Redis 是什么?
🔶 Redis 是一种非关系型的数据库,与传统的数据库不同,Redis 中的数据是存储在内存中的,所以读写速度非常的快,因此 Redis 被广泛应用于缓存方向。
🔶 Redis 提供了多种数据类型来支持不同的业务场景,比如字符串、哈希表、列表、集合、bitmap、geo、hyperloglog 等。
🍻 数据结构
🥂 Redis 的底层数据结构有哪些?
🔶 简单动态字符串 SDS:SDS 的结构中包含参数 len,用来记录字符串的长度,因此查询字符串长度的复杂度仅为 O(1),速度快。SDS 还是二进制安全的,它不像 C 字符串一样用 ‘\0’ 标识字符串末尾,而是使用 len 来记录,因此可以存放任意的二进制数据。SDS 中参数 alloc 用于计算字符串的剩余空间,在拼接字符串时如果空间不够会自动扩容,避免缓存区溢出,更加的安全。
🔶 链表:链表的每个节点中都有一个前向和后向指针,因此是双向链表。链表结构中的 head 和 tail 可以获取头尾元素节点,dup,free 和 match 函数可以复制,释放和比较元素节点。参数 len 可以用来获取链表长度,查询链表长度的复杂度仅为 0(1)。链表节点由于使用的是 void* 指针,因此可以存放不同类型的数据。它的缺点是内存不连续,数据查找效率不高,以及创建节点内存开销大。
🔶 压缩列表:压缩列表类似于数组,使用连续的内存块来存放数据。当前元素节点会记录前一节点的长度,因此可以实现双向遍历。压缩列表在存储数据时会根据数据的大小分配合适的内存,可以很好的节省了内存空间。但是当插入一个较大元素时,可能出现记录前一节点长度所需空间不够的情况,导致连锁更新使压缩列表的性能下降。
🔶 哈希表:哈希表是一种 key-value 的数据结构,可以使用 O(1) 的复杂度进行快速查询。然而,随着数据的不断增加,可能会发生哈希冲突。redis 采用链式哈希结构来解决哈希冲突,就是将拥有相同哈希值的数据用链表串起,确保数据仍可以被查询到。另一种解决方法就是 rehash,当发生哈希冲突时,新建一个哈希表并扩增哈希桶的大小为两倍,迁移旧哈希表中的数据到新哈希表中。
🔶 整数集合:整数集合是一块连续的内存空间,类似于数组。其中元素的存放类型取决于参数 encoding 的属性,比如 8,16,32 位的 int。此外当插入的新数据类型超过当前最大类型时,会进行类型的升级操作。
🔶 跳表:跳表在链表的基础上进行改进的,实现了一种多层的有序链表,可以快速定位数据。它的查询步骤是从头节点的顶层开始,查找第一个大于指定元素的节点,再退回上一节点,在下一层节点继续查找,使得查找的复杂度为 O(log n)。
🍻 锁
🥂 Redis 如何实现分布式锁?
🔶 使用 setnx + expire 实现。首先利用 setnx 将 key 设为 value,当 key 不存在时加锁成功,而当 key 存在时什么也不做。因为分布式锁需要超时机制,因此使用 expire 来设置过期时间。但存在问题,因为 setnx 和 expire 是两步操作,不具有原子性,如果执行第一条语句后发生异常,锁将无法过期。
🔶 可以采用 lua 脚本,将 setnx 和 expire 写在脚本中,由于 lua 脚本在 redis 中的实现是原子性的,因此加锁和设置过期具有原子性。
🔶 使用 set 及 nx 可选参数实现。例如 EX 代表设置过期时间,NX 代表 key 不存在时设置过期时间。其中设置的 value 必须具有唯一性,以便区分来自不同客户端的加锁操作。释放锁时,需要根据 value 值判断是不是自己的锁,再进行释放锁操作。
🍻 缓存
🥂 如何保证缓存与数据库的数据一致性?
🔶 使用缓存就会涉及到数据库和缓存的存储双写,会导致数据不一致的问题。数据一致性分为:强一致性,即用户写入什么,读取的立刻就是什么,用户体验好但是对系统性能影响大。弱一致性:写入数据后,不保证数据立即一致,而是某个时间级别后能够一致。
🔶 旁路缓存模式:适用于请求比较多的场景,服务端会以数据库的结果为准。读请求时,先读取缓存,如果命中的话直接返回数据,未命中的话从数据库中获取数据,并添加到缓存中。写请求时,先更新数据库,再删除缓存。
🔶 读写穿透模式:服务端会以缓存的结果为准。读请求时,先读取缓存,如果命中的话直接返回数据,未命中的话从数据库中获取数据,并添加到缓存中。当进行写请求时,先检查缓存,缓存未存在则直接更新数据库,如果缓存存在,则先更新缓存,再更新数据库。读写穿透在旁路缓存的基础上提供了 cache-provider 层并进行了封装,在旁路缓存中缓存未命中客户端自己负责写入数据到缓存,而读写穿透中是由 cache 服务自动将数据写入缓存的。
🔶 异步缓存写入模式:该模式和缓存穿透类似,都是通过 cache 服务负责缓存和数据库的读写。不同的是读写穿透同时更新数据库和缓存,而该模式是先更新缓存数据,之后通过异步的方式批量更新数据库。这种同步方式的缺点是缓存还没有来得及更新到数据库,就已经失效。适合用在对写入数据需要高但对一致性需求不高的情况,比如网页的浏览量,点赞量等场景。
🥂 Redis 的数据优化方案有哪些?【待回答】
🥂 热点数据和冷数据是什么?【待回答】
🍻 持久化
🥂 Redis 有哪些持久化机制?
🔶 Redis 有两种持久化方式,分别为 RDB 持久化和 AOF 持久化技术。
🔶 通过持久化机制,将内存中的数据同步到硬盘中,当 Redis 重启后,将持久化数据从硬盘数据加载到内存,达到恢复数据的目的。Redis 默认使用 RDB 持久化。
🔷 RDB:Redis 可以通过创建快照来获取某个时刻的内存数据副本,创建的快照是二进制文件。创建快照完成后对快照进行备份,发送给其他服务器创建数据副本,也可以在重启时用快照恢复自身的服务器数据。
🔷 Redis 有两个命令来生成快照,分别是 save 和 bgsave。其中 save 会在主线程中生成文件,而 bgsave 会创建子线程来生成文件,避免主线程的阻塞。RDB 的备份是全量备份,如果备份频繁的话会影响 Redis 的性能,但不频繁可能会丢失较长时间的数据。
🔶 AOF:Redis 在执行一条写操作命令时,会把命令以追加到形式写入到磁盘中的日志里。当 Redis 重启的时候,读取并执行日志中的命令,就可以恢复内存数据。AOF 有三种策略:
🔶 写回策略:Redis 在执行完写操作后,会将命令写入缓冲区,系统调用 write() 函数将缓冲区命令写入 AOF 日志,由内核决定何时将日志写入到磁盘。其中参数为 always,可以让内核在每次执行写操作后将日志写入到磁盘,everysec,可以让内核每秒将日志写入到磁盘,参数为 no,意味着将日志写入磁盘的时机由内核决定。
🔶 重写机制:随着写操作的越来越多,AOF 日志文件的大小也会越来越大,这会导致性能的问题。于是 redis 给 AOF 文件大小设置阈值,当超过后会启用 AOF 重写机制。当出现了多条命令修改同一个 key 时,只会记录最后一条更新 key 的命令。然后将重写后的 AOF 文件覆盖掉现有的 AOF 文件,AOF 文件的大小也得到了压缩。
🔶 后台重写:当触发 AOF 重写机制时,如果 AOF 文件太大的话,主线程的重写是很耗时的,因此 AOF 重写可以由后台的子进程完成,在此期间主进程一直是非阻塞的。
🔷 Redis 也支持 RDB 和 AOF 的混合持久化。使用混合持久化时,AOF 重写会将内存数据以快照的形式全量写入 AOF 文件,之后将新增命令以 AOF 的形式增量写入到 AOF 文件,实现混合持久化。
🍺 面试算法
🍻 双指针
🥂 11. 盛最多水的容器 [数组] [面积] (双指针)
class Solution {
public:int maxArea(vector<int>& height) {// 双指针int left = 0, right = height.size() - 1;// 最大面积, 当前面积int res = 0, cur = 0;// 缩小区域while (left < right) {cur = min(height[left], height[right]) * (right - left);res = max(res, cur);// 哪一边比较短, 移动哪一边if (height[left] < height[right]) {left++;} else {right--;}}return res;}
};
🥂 31. 下一个排列 [数组] [排列] (双指针) (推导)
class Solution {
private:int flag = 0; // 设置一个标志位, 代表找到当前排列了
public:void nextPermutation(vector<int>& nums) {int n = nums.size();// 从后往前找, 找到第一个 nums[i] < nums[j] 的地方int i = n - 2, j = n - 1;while (i >= 0 && nums[i] >= nums[i + 1]) {i--;}// 此时不是最后一个排列if (i >= 0) {// 找到一个比 nums[i] 大的第一个元素while (j > i && nums[j] <= nums[i]) {j--;}// 交换两者swap(nums[i], nums[j]);// 再将剩余部分逆转, 把降序变为升序reverse(nums.begin() + i + 1, nums.end());} else {// 如果是最后一个排列reverse(nums.begin(), nums.end());}return;}
};
🥂 42. 接雨水 [数组] [面积] (双指针)
class Solution {
public:int trap(vector<int>& height) {// 左边边界, 右边边界, 最边上存不了水int left = 0, right = height.size() - 1;// 左边最大值, 右边最大值int left_max = height[left], right_max = height[right];// 当前装水量, 总装水量int cur = 0, res = 0;while (left <= right) {left_max = max(left_max, height[left]);right_max = max(right_max, height[right]);if (left_max < right_max) {// 左指针的leftMax比右指针的rightMax矮// 说明:左指针的右边至少有一个板子 > 左指针左边所有板子// 那么可以计算左指针当前列的水量:左边最大高度-当前列高度res += left_max - height[left];left++;} else {res += right_max - height[right];right--;}}return res;}
};
🥂 160. 相交链表 [链表] [相交] (双指针)
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {// 双指针ListNode *p1 = headA, *p2 = headB;// A 走到 nullptr 后接着走 B, B 走到 nullptr 后接着走 A// 当 p1 == p2 的地方就是相交的地方while (p1 != p2) {if (p1 == nullptr) p1 = headB;else p1 = p1->next;if (p2 == nullptr) p2 = headA;else p2 = p2->next;}return p1;}
};
🥂 LCR 139. 训练计划 I [数组] [元素交换] (双指针)
class Solution {
public:vector<int> trainingPlan(vector<int>& actions) {int n = actions.size();if (n <= 1) return actions;// 定义双指针,一个指向头,一个指向尾int left = 0, right = n - 1; while (left < right) {// 依次移动,找到数时暂停while (left < right && actions[left] % 2 == 1) {left++;}while (left < right && actions[right] % 2 == 0) {right--;}std::swap(actions[left], actions[right]);}return actions;}
};
🍻 三指针
🥂 215. 数组中的第K个最大元素 [数组] [第K大元素] (三指针) (快速排序)
class Solution {
private:int target; // 目标索引, 第 n-k 小int res; // 目标值
public:int findKthLargest(vector<int>& nums, int k) {// 快速排序, 每次可以确定好一个元素的位置, 当索引为 k 时, 代表找到int n = nums.size();// 第 k 大就是第 n - k 小target = n - k;// 开始快排quickSort(nums, 0, n - 1);return res;}// 快排 [left, right]void quickSort(vector<int>& nums, int left, int right) {if (left > right) return;// 只剩一个元素if (left == right && left == target) {res = nums[target];return;}// 先获取一个哨兵, 将数组分为小于它的部分和大于它的部分vector<int> edge = part(nums, left, right);// 如果 target 在左右边界之间, 则找到if (edge[0] <= target && target <= edge[1]) {res = nums[target];return;}// 继续递归quickSort(nums, left, edge[0] - 1);quickSort(nums, edge[1] + 1, right);}// 分隔, 三指针, 这里返回相同元素的左右边界是为了去重vector<int> part(vector<int>& nums, int left, int right) {int pivot_idx = rand() % (right - left + 1) + left;int pivot = nums[pivot_idx];// [pivot] [1] [2] [3] [4]// L/LP CP RP swap(nums[pivot_idx], nums[left]);// 设置三个指针, 分别指向小于 pivot 的元素, 当前元素, 大于 pivot 的元素int curp = left + 1, leftp = left, rightp = right + 1;// 还没走到尽头, rightp 始终是指向大于 pivot 元素的while (curp < rightp) {if (nums[curp] < pivot) { // 小于哨兵leftp++;swap(nums[curp], nums[leftp]);curp++;} else if (nums[curp] > pivot) { // 大于哨兵rightp--;swap(nums[curp], nums[rightp]);} else { // 相等, 什么也不做curp++;}}// 最后 leftp 指向的内容肯定是最后一个小于 pivot 的, 它与 pivot 交换swap(nums[left], nums[leftp]);// 返回等于 pivot 的左边界和右边界 [小于] [pivot] [大于]return {leftp, rightp - 1};}
};
🍻 滑动窗口
🥂 3. 无重复字符的最长子串 [字符串] [子串] (滑动窗口)
class Solution {
private:unordered_map<char, int> window; // 窗口内的字符
public:int lengthOfLongestSubstring(string s) {int left = 0, right = 0;int res = 0;// 开始滑动while (right < s.size()) {char cur_r = s[right];right++;window[cur_r]++;// 如果出现次数为第二次, 则缩小窗口, 直到出现次数为一次while (window[cur_r] > 1) {char cur_l = s[left];left++;window[cur_l]--;}// 此时更新下符合条件的当前字符长度 [left, right-1]res = max(res, right - left);}return res;}
};
🍻 二分法
🥂 153. 寻找旋转排序数组中的最小值 [旋转数组] [最小值] (二分法)
class Solution {
public:int findMin(vector<int>& nums) {int left = 0, right = nums.size() - 1;// 二分法 [0, n-1]while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] < nums[right]) {right = mid;} else if (nums[mid] > nums[right]) {left = mid + 1;} else {right--;}}return nums[left];}
};
🥂 162. 寻找峰值 [数组] [峰值] (二分法)
class Solution {
public:int findPeakElement(vector<int>& nums) {int left = 0, right = nums.size() - 1;// [0, n-1]while (left < right) {// [left, mid] [mid+1 right]int mid = left + (right - left) / 2;if (nums[mid] > nums[mid + 1]) {// [left, mid]right = mid;} else {// [mid+1, right], 相等的时候左右移动都一样left = mid + 1;}}return left;}
};
🍻 DFS
🥂 200. 岛屿数量 [矩阵] [岛屿] (DFS)
class Solution {
private:int m, n; // 地图的宽高int res = 0; // 岛屿数量vector<vector<int>> dirts = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}}; // 方向
public:int numIslands(vector<vector<char>>& grid) {m = grid.size(), n = grid[0].size();// 从每个点都出发找一遍for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) {if (grid[i][j] == '1') {DFS(grid, i, j);res++;}}}return res;}// DFS 算法void DFS(vector<vector<char>>& grid, int i, int j) {// 终止条件if (i < 0 || i >= m || j < 0 || j >= n) return;if (grid[i][j] == '0') return;// 将已遍历岛屿沉默grid[i][j] = '0';// 遍历四周的元素for (auto& dirt : dirts) {DFS(grid, i + dirt[0], j + dirt[1]);}}
};
🍻 贪心
🥂 452. 用最少数量的箭引爆气球 [数组] [区域重合] (贪心) (排序)
// 找非重叠区域最多有几个, 就是需要射多少箭
class Solution {
private:int res = 0; // 需要射的最少的箭数long cur_end = LONG_MIN; // 上一个区间的 end [-wq, INT_MIN]
public:int findMinArrowShots(vector<vector<int>>& points) {// 按 end 排序sort (points.begin(), points.end(), [](vector<int>& a, vector<int>& b) {return a[1] < b[1];});// 开始遍历一个个区间for (auto& point : points) {int start = point[0], end = point[1];// 碰到重叠区域, 这题擦边也可以射气球if (start <= cur_end) continue;// 没碰到重叠区域res++;cur_end = end;}return res;}
};
🍻 其他
🥂 8. 字符串转换整数 [字符串] [转换] (遍历)
class Solution {
public:int myAtoi(string s) {long res = 0; // 最终的结果int flag = 1; // 正负标志位int i = 0; // 元素下标while (s[i] == ' ') i++; // 去掉前面的空格if (s[i] == '-') flag = -1; // 标志为负数if (s[i] == '+' || s[i] == '-') i++; // 移动到数字处// 开始转换while (i < s.size()) {if (s[i] < '0' || s[i] > '9') break;int cur = s[i] - '0';cout << cur;// 如果是负数 -2147483648if (flag == -1 && (res > INT_MAX / 10 || (res == INT_MAX / 10 && cur > 8))) {return INT_MIN;}// 如果是正数 2147483647if (flag == 1 && (res > INT_MAX / 10 || (res == INT_MAX / 10 && cur > 7))) {return INT_MAX;}res = res * 10 + cur;i++;}return flag * res;}
};
🍻【待做】【199】
相关文章:

C++ 后端面试 - 题目汇总
文章目录 🍺 非技术问题🍻 基本问题🥂 请自我介绍?🥂 你有什么问题需要问我的? 🍻 加班薪资🥂 你对加班有什么看法?🥂 你的薪资期望是多少?【待回…...

zds1104示波器使用指南
1、设置语言 2、功能检测验证示波器是否正常工作 3、示波器面板按钮详解 3.1、软键 3.2、运行控制与操作区 3.3、水平控制区 3.4、垂直控制区 3.5、多功能控制区 3.6、断电启动恢复,auto setup,default setup,恢复出厂设置详细解释 3.7、触…...
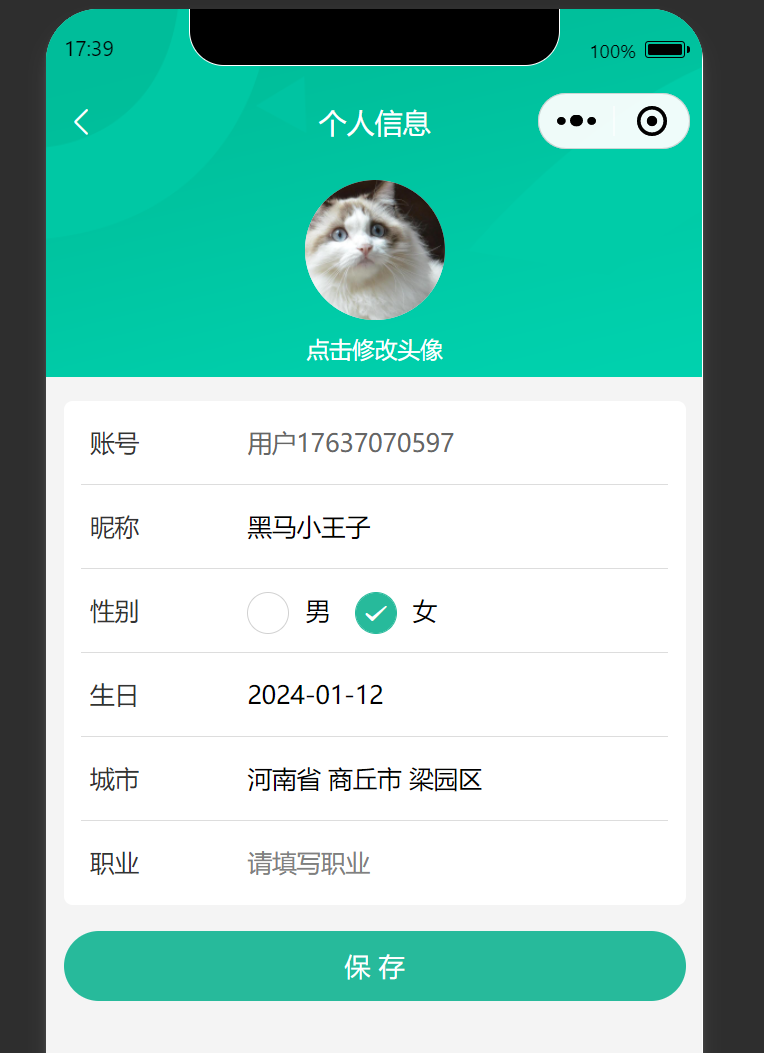
uni-app修改头像和个人信息
效果图 代码(总) <script setup lang"ts"> import { reqMember, reqMemberProfile } from /services/member/member import type { MemberResult, Gender } from /services/member/type import { onLoad } from dcloudio/uni-app impor…...
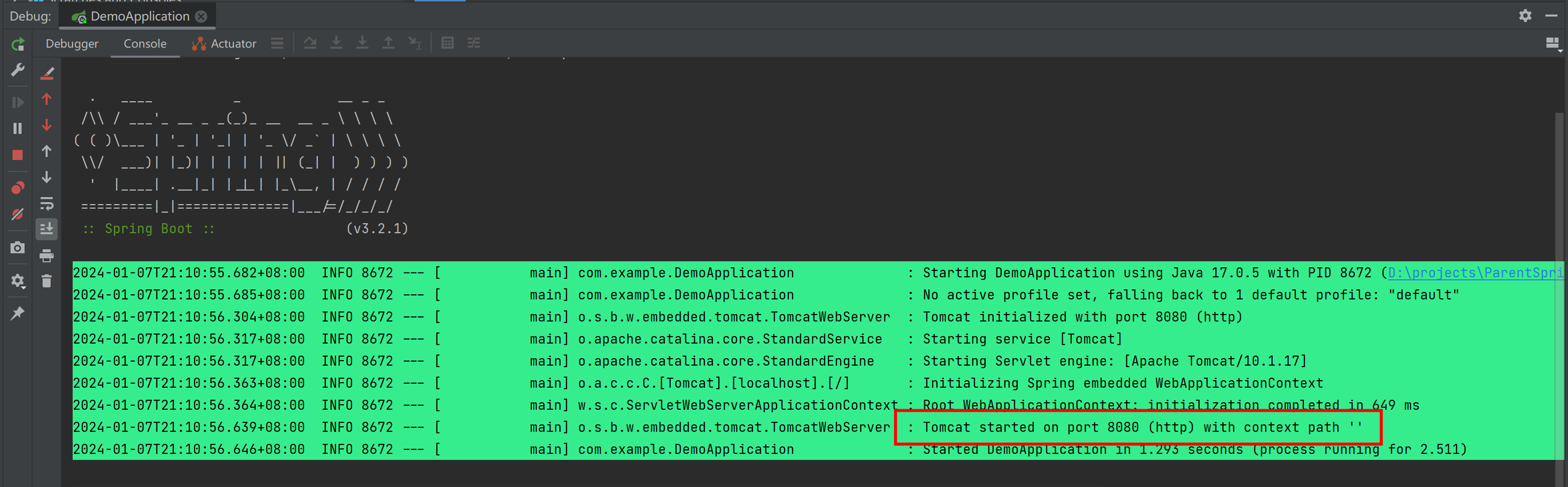
IDEA 中搭建 Spring Boot Maven 多模块项目 (父SpringBoot+子Maven)
第1步:新建一个SpringBoot 项目 作为 父工程 [Ref] 新建一个SpringBoot项目 删除无用的 .mvn 目录、 src 目录、 mvnw 及 mvnw.cmd 文件,最终只留 .gitignore 和 pom.xml 第2步:创建 子maven模块 第3步:整理 父 pom 文件 ① …...
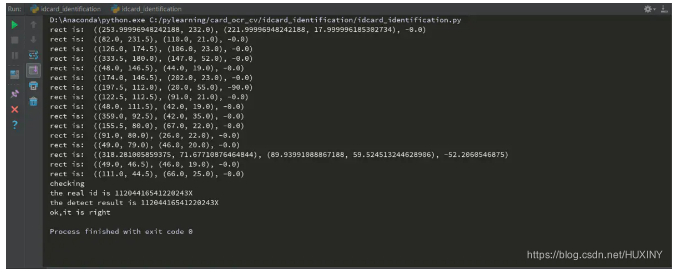
竞赛保研 基于计算机视觉的身份证识别系统
0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于机器视觉的身份证识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-sen…...
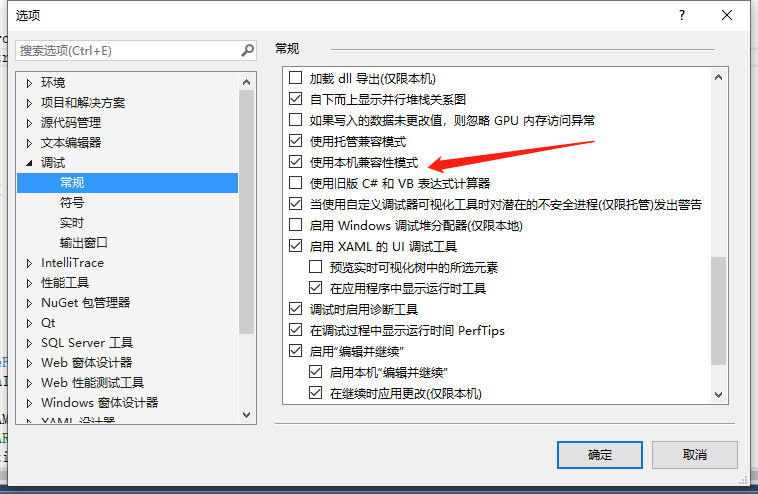
在visual studio中调试时无法查看std::wstring
1.问题 在调试的时候发现std::wstring类型的变量查看不了,会显示(error)|0,百思不得其解。 2.解决方法 参考的:vs2015调试时无法显示QString变量的值,只显示地址_vs调试qstring的时候如何查看字符串-CSDN博客 在工具/选项/调试…...

2023年全国职业院校技能大赛高职组应用软件系统开发正式赛题—模块三:系统部署测试
模块三:系统部署测试(3 小时) 一、模块考核点 模块时长:3 小时模块分值:20 分本模块重点考查参赛选手的系统部署、功能测试、Bug 排查修复及文档编写能力,具体包括:系统部署。将给定项目发布到…...

微信小程序上传并显示图片
实现效果: 上传前显示: 点击后可上传,上传后显示: 源代码: .wxml <view class"{{company_logo_src?blank-area:}}" style"position:absolute;top:30rpx;right:30rpx;height:100rpx;width:100rp…...
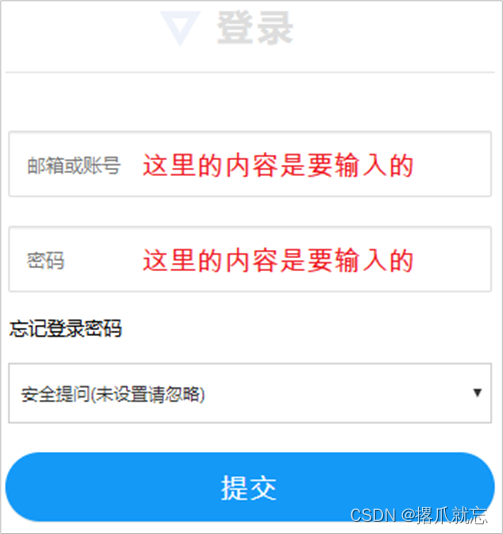
java基础知识点系列——数据输入(五)
java基础知识点系列——数据输入(五) 数据输入概述 Scanner使用步骤 (1)导包 import java.util.Scanner(2)创建对象 Scanner sc new Scanner(System.in)(3)接收数据 int i sc…...

MySQL面试题 | 07.精选MySQL面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

C语言中关于指针的理解及用法
关于指针意思的参考:https://baike.baidu.com/item/%e6%8c%87%e9%92%88/2878304 指针 指针变量 地址 野指针 野指针就是指针指向的位置是不可知的(随机的,不正确的,没有明确限制的) 以下是导致野指针的原因 1.指针…...

软件测试|深入理解Python中的re.search()和re.findall()区别
前言 在Python中,正则表达式是一种强大的工具,用于在文本中查找、匹配和处理模式。re 模块提供了许多函数来处理正则表达式,其中 re.search()和 re.findall() 是常用的两个函数,用于在字符串中查找匹配的模式。本文将深入介绍这两…...

❤ Vue3 完整项目太白搭建 Vue3+Pinia+Vant3/ElementPlus+typerscript(一)yarn 版本控制 ltb (太白)
❤ 项目搭建 一、项目信息 Vue3 完整项目搭建 Vue3PiniaVant3/ElementPlustyperscript(一)yarn 版本控制 项目地址: 二、项目搭建 (1)创建项目 yarn create vite <ProjectName> --template vueyarn install …...

linux搭建SRS服务器
linux搭建SRS服务器 文章目录 linux搭建SRS服务器SRS说明实验说明搭建步骤推流步骤查看web端服务器拉流步骤final SRS说明 SRS(simple Rtmp Server),是一个简单高效的实时视频服务器,支持RTMP/WebRTC/HLS/HTTP-FLV/SRT, 是国人自己开发的一款…...
系列六、Spring Security中的认证 授权 角色继承
一、Spring Security中的认证 & 授权 & 角色继承 1.1、概述 关于Spring Security中的授权,请参考【系列一、认证 & 授权】,这里不再赘述。 1.2、资源类 /*** Author : 一叶浮萍归大海* Date: 2024/1/11 20:58* Description: 测试资源*/ Re…...

云原生周刊:OpenTofu 宣布正式发布 | 2023.1.15
开源项目推荐 kubeaudit kubeaudit 是一个开源项目,旨在帮助用户对其 Kubernetes 集群进行常见安全控制的审计。该项目提供了工具和检查规则,可以帮助用户发现潜在的安全漏洞和配置问题。 Chronos Chronos 是一款综合性开发人员工具,可监…...
【如何在 GitHub上面找项目】【转载】
很多的小伙伴,经常会有这样的困惑,我看了很多技术的学习文档、书籍、甚至视频,我想动手实践,于是我打开了GitHub,想找个开源项目,进行学习,获取项目实战经验。这个时候很多小伙伴就会面临这样的…...

java每日一题——ATM系统编写(答案及编程思路)
前言: 基础语句学完,也可以编写一些像样的程序了,现在要做的是多加练习,巩固下知识点,打好基础,daydayup! 题目:模仿银行ATM系统,可以创建用户,存钱,转账&…...

《TrollStore巨魔商店》TrollStore2安装使用教程支持IOS14.0-16.6.1
TrollStore(巨魔商店) 简单的说就相当于一个永久的免费证书,它可以给你的iPhone和iPad安装任何你想要安装的App软件,而且不需要越狱,不用担心证书签名过期的问题,不需要个人签名和企业签名。 支持的版本: TrollStore安装和使用教…...

鸿鹄电子招投标系统源码实现与立项流程:基于Spring Boot、Mybatis、Redis和Layui的企业电子招采平台
随着企业的快速发展,招采管理逐渐成为企业运营中的重要环节。为了满足公司对内部招采管理提升的要求,建立一个公平、公开、公正的采购环境至关重要。在这个背景下,我们开发了一款电子招标采购软件,以最大限度地控制采购成本&#…...

AI企业参与国防采购的挑战、机遇与实操路线图
1. 项目概述:当AI遇见国防采购,一场静默的“双向奔赴”在硅谷的咖啡厅和五角大楼的简报室之间,正上演着一场深刻而复杂的对话。话题的核心,是人工智能这项被誉为“新时代电力”的技术,如何融入世界上最庞大、最严谨的采…...

洛谷 B4361:[GESP202506 四级] 排序
【题目来源】 https://www.luogu.com.cn/problem/B4361 【题目描述】 体育课上有 n 名同学排成一队,从前往后数第 i 位同学的身高为 hi,体重为 wi。目前排成的队伍看起来参差不齐,老师希望同学们能按照身高从高到低的顺序排队,…...

大模型从0训练LLaMA全流程实战——基于昇腾910B集群
用昇腾集群从零训练一个 LLaMA-7B,走完数据准备、代码修改、分布式配置、启动训练、监控调优的全流程。中间踩过的坑都标注在对应步骤里。 1. 硬件与环境确认(训练前必做) 训练大模型对环境的稳定性要求极高,任何一项不达标都可能导致训练中途崩溃。 #!/bin/bash # 训练前…...

CANN-ATB量化推理-昇腾NPU上W8A8量化为什么比W4A16更实用
Llama2-70B 权重 140GB,8 卡 TP 刚好放得下但没什么余量给 KV Cache。W8A8 量化把权重从 fp16 压到 int8,权重体积减半,4 卡就能跑 70B。W4A16 理论上压得更狠(4 倍压缩),但精度损失在实际业务里往往不可接…...

深度学习安全帽佩戴检测系统
1 前言 今天学长向大家介绍一个机器视觉的毕设项目,深度学习安全帽佩戴检测系统 项目运行效果: 毕业设计 深度学习安全帽佩戴检测系统🧿 项目分享:见主页简介 1 课题背景 建筑工人头部伤害是造成建筑伤亡事故的重要原因。佩戴安全帽是防止…...

终极AMD Ryzen调试工具:SMUDebugTool完全使用指南
终极AMD Ryzen调试工具:SMUDebugTool完全使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...
解读 第七章)
UE5官方文档(第一人称射击游戏教程)解读 第七章
好了,今天来到我们的第七章,今天将承上启下,延伸输入部分的工作。 配置角色移动 Coder 03 Configure Character Movement with C in Unreal Engine | Unreal Engine 5.7 Documentation | Epic Developer Community // Copyright Epic Games…...

ShiroAttack2实战指南:从漏洞检测到内存马注入的完整揭秘
ShiroAttack2实战指南:从漏洞检测到内存马注入的完整揭秘 【免费下载链接】ShiroAttack2 shiro反序列化漏洞综合利用,包含(回显执行命令/注入内存马)修复原版中NoCC的问题 https://github.com/j1anFen/shiro_attack 项目地址: https://gitc…...

不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变
不会 CSS 也能做出惊艳 PPT!Frontend Slides这个开源 Claude Code 技能让 AI 帮你生成 12 种风格演示文稿,告别千篇一律的紫渐变 💡 每次做 PPT 都在 Powerpoint 里拖来拖去,最后做出来还是那个味儿?Frontend Slides 让…...

SpringBoot-Scan:面向红队的SpringBoot资产指纹与测绘工作流
1. 这不是又一个“SpringBoot漏洞扫描器”教程,而是一份真实红队队员的资产测绘工作流你有没有遇到过这样的情况:手头刚拿到一个目标域名,技术栈标注着“SpringBoot 2.7.x”,但连它到底跑在哪个端口、是否启用了Actuator、有没有暴…...