Flink定制化功能开发,demo代码
前言:
这是一个Flink自定义开发的基础教学。本文将通过flink的DataStream模块API,以kafka为数据源,构建一个基础测试环境;包含一个kafka生产者线程工具,一个自定义FilterFunction算子,一个自定义MapFunction算子,用一个flink任务的代码逻辑,将实时读kafka并多层处理串起来;让读者体会通过Flink构建自定义函数的技巧。
一、Flink的开发模块分析
Flink提供四个基础模块:核心SDK开发API分别是处理实时计算的DataStream和处理离线计算的DataSet;基于这两个SDK,在其上包装了TableAPI开发模块的SDK;在Table API之上,定义了高度抽象可用SQL开发任务的FlinkSQL。在核心开发API之下,还有基础API的接口,可用于对时间,状态,算子等最细粒度的特性对象做操作,如包装自定义算子的ProcessWindowFunction和ProcessFunction等基础函数以及内置的对象状态StateTtlConfig;
FLINK开发API关系结构如下:

二、定制化开发Demo演示
2.1 场景介绍
Flink实时任务的的通用技术架构是消息队列中间件+Flink任务:
将数据采集到Kafka或pulser这类队列中间件的Topic,然后使用Flink内置的kafkaSource,监控Topic的数据情况,做实时处理。
- 这里提供一个kafka的生产者线程,可以自定义构建需要的数据和上传时间,用于控制写入kafka的数据源;
- 重写两个DataStream的基础算子:FilterFunction和MapFunction,用于让读者体会,如何对FLINK函数的重新包装,后续更基础的函数原理一样;我这里用String数据对象做处理,减少对象转换的SDK引入,通常要基于业务做数据polo的加工,这个自己处理,将对象换成业务对象;
- 然后使用Flink将整个业务串起来,从kafka读数据,经过两层处理,最终输出需要的结果;
2.2 本地demo演示
2.2.1 pom文件
这里以flink1.14.6+scala1.12版本为例:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.example</groupId><artifactId>flinkCDC</artifactId><version>1.0-SNAPSHOT</version></parent><artifactId>flinkStream</artifactId><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink-version>1.14.6</flink-version><scala-version>2.12</scala-version><hadop-common-version>2.9.1</hadop-common-version><elasticsearch.version>7.6.2</elasticsearch.version><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target><log4j.version>2.17.1</log4j.version></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots></snapshots></repository></repositories><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink-version}</version><!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-core</artifactId><version>${flink-version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala-version}</artifactId><version>${flink-version}</version><!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala-version}</artifactId><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions><version>${flink-version}</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>myflinkml.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration></plugin></plugins></pluginManagement></build>
</project>
2.2.2 kafka生产者线程方法
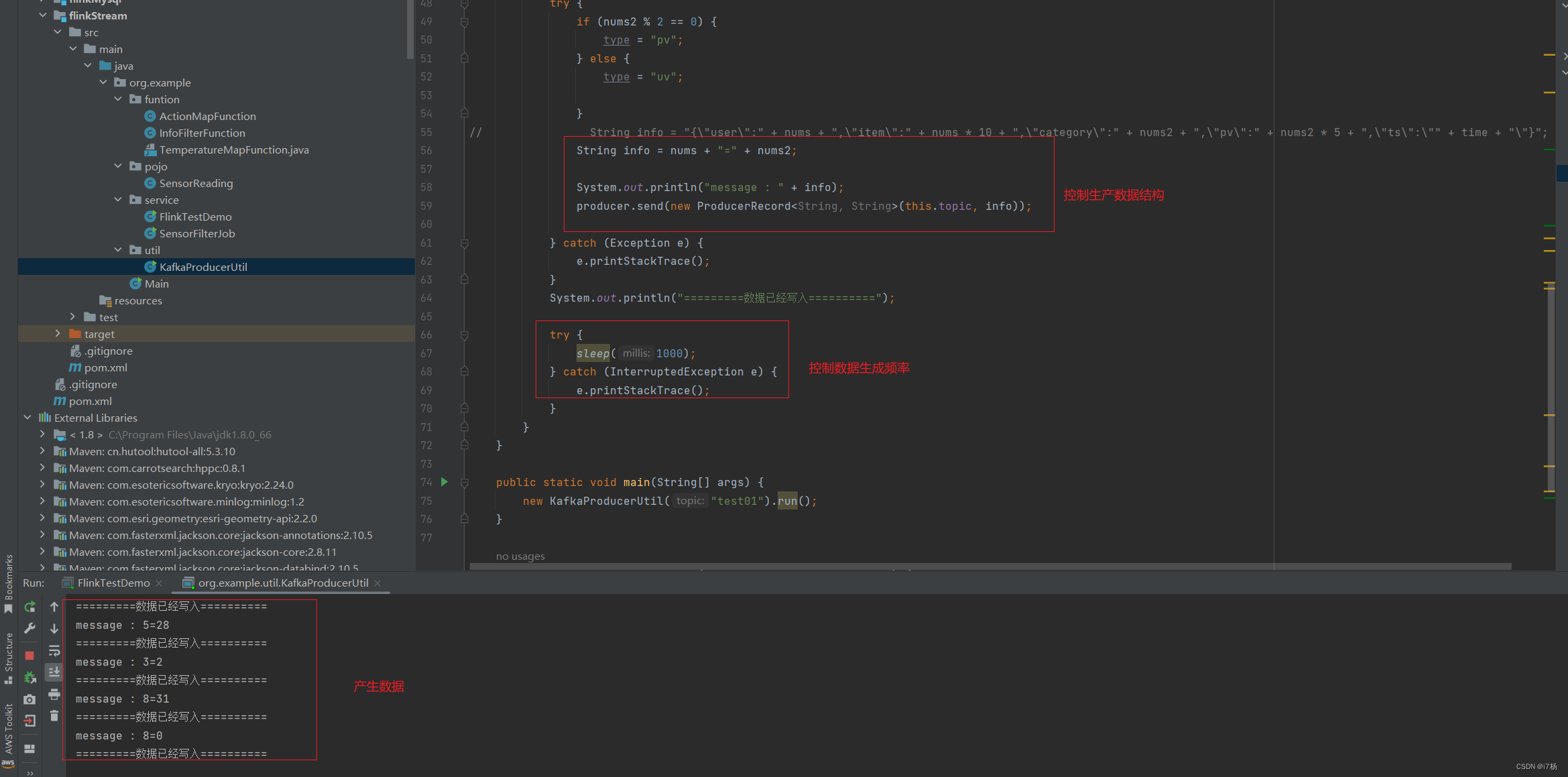
package org.example.util;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.*;/*** 向kafka生产数据** @author i7杨* @date 2024/01/12 13:02:29*/public class KafkaProducerUtil extends Thread {private String topic;public KafkaProducerUtil(String topic) {super();this.topic = topic;}private static Producer<String, String> createProducer() {// 通过Properties类设置Producer的属性Properties properties = new Properties();
// 测试环境 kafka 配置properties.put("bootstrap.servers", "ip2:9092,ip:9092,ip3:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");return new KafkaProducer<String, String>(properties);}@Overridepublic void run() {Producer<String, String> producer = createProducer();Random random = new Random();Random random2 = new Random();while (true) {int nums = random.nextInt(10);int nums2 = random.nextInt(50);
// double nums2 = random2.nextDouble();String time = new Date().getTime() / 1000 + 5 + "";String type = "pv";try {if (nums2 % 2 == 0) {type = "pv";} else {type = "uv";}
// String info = "{\"user\":" + nums + ",\"item\":" + nums * 10 + ",\"category\":" + nums2 + ",\"pv\":" + nums2 * 5 + ",\"ts\":\"" + time + "\"}";String info = nums + "=" + nums2;System.out.println("message : " + info);producer.send(new ProducerRecord<String, String>(this.topic, info));} catch (Exception e) {e.printStackTrace();}System.out.println("=========数据已经写入==========");try {sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) {new KafkaProducerUtil("test01").run();}public static void sendMessage(String topic, String message) {Producer<String, String> producer = createProducer();producer.send(new ProducerRecord<String, String>(topic, message));}}
2.2.3 自定义基础函数
这里自定义了filter和map两个算子函数,测试逻辑按照数据结构变化:
自定义FilterFunction函数算子:阈值小于40的过滤掉
package org.example.funtion;import org.apache.flink.api.common.functions.FilterFunction;/*** FilterFunction重构** @author i7杨* @date 2024/01/12 13:02:29*/public class InfoFilterFunction implements FilterFunction<String> {private double threshold;public InfoFilterFunction(double threshold) {this.threshold = threshold;}@Overridepublic boolean filter(String value) throws Exception {if (value.split("=").length == 2)// 阈值过滤return Double.valueOf(value.split("=")[1]) > threshold;else return false;}
}
自定义MapFunction函数:后缀为2的,添加上特殊信息
package org.example.funtion;import org.apache.flink.api.common.functions.MapFunction;public class ActionMapFunction implements MapFunction<String, String> {@Overridepublic String map(String value) throws Exception {System.out.println("value:" + value);if (value.endsWith("2"))return value.concat(":Special processing information");else return value;}
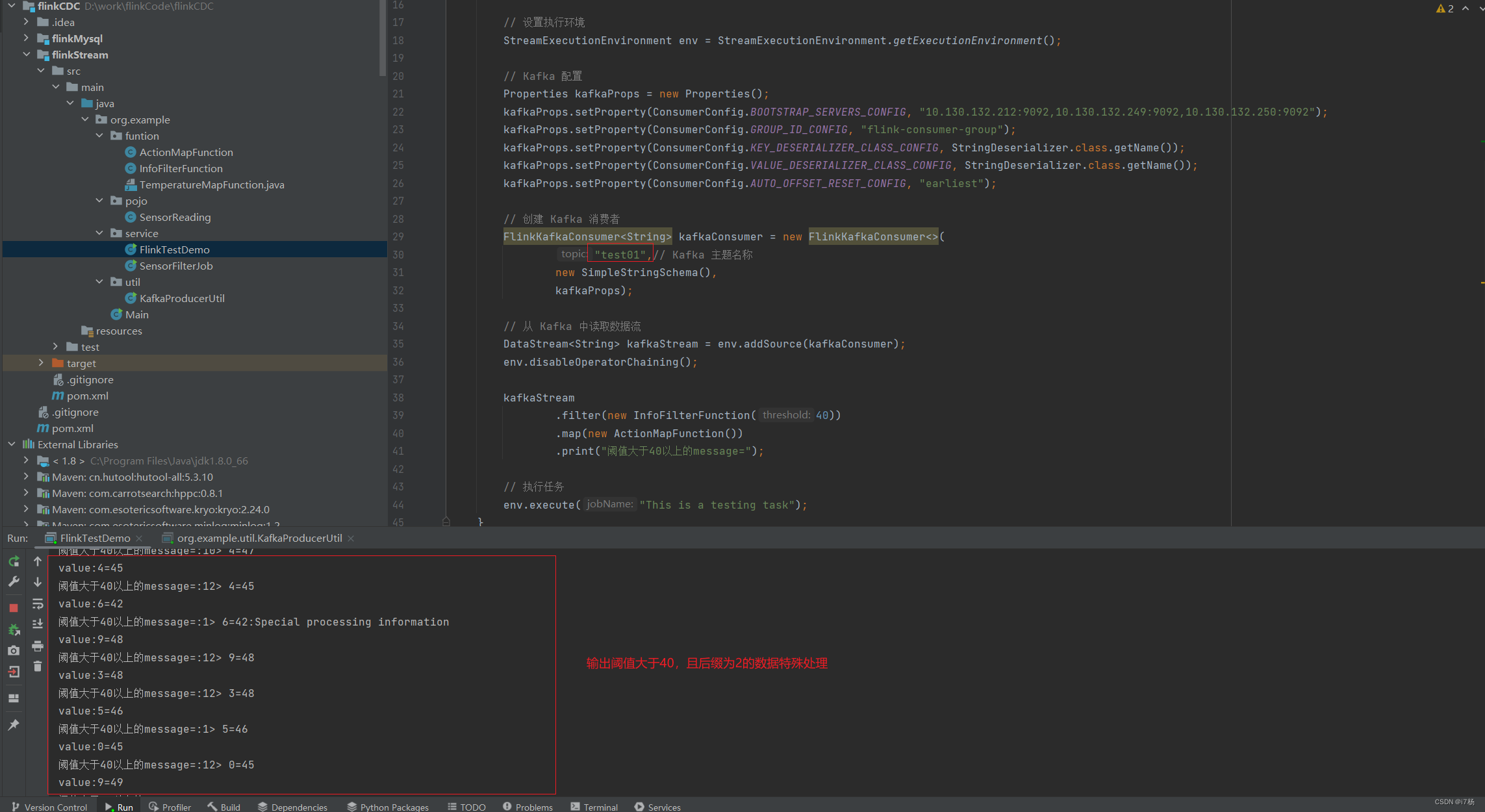
}2.2.4 flink任务代码
任务逻辑:使用kafka工具产生数据,然后监控kafka的topic,讲几个函数串起来,输出结果;
package org.example.service;import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.example.funtion.ActionMapFunction;
import org.example.funtion.InfoFilterFunction;import java.util.*;public class FlinkTestDemo {public static void main(String[] args) throws Exception {// 设置执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// Kafka 配置Properties kafkaProps = new Properties();kafkaProps.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip1:9092,ip2:9092,ip3:9092");kafkaProps.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-consumer-group");kafkaProps.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());kafkaProps.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());kafkaProps.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 创建 Kafka 消费者FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("test01",// Kafka 主题名称new SimpleStringSchema(),kafkaProps);// 从 Kafka 中读取数据流DataStream<String> kafkaStream = env.addSource(kafkaConsumer);env.disableOperatorChaining();kafkaStream.filter(new InfoFilterFunction(40)).map(new ActionMapFunction()).print("阈值大于40以上的message=");// 执行任务env.execute("This is a testing task");}}
运行结果:
相关文章:
Flink定制化功能开发,demo代码
前言: 这是一个Flink自定义开发的基础教学。本文将通过flink的DataStream模块API,以kafka为数据源,构建一个基础测试环境;包含一个kafka生产者线程工具,一个自定义FilterFunction算子,一个自定义MapFunctio…...

Edge浏览器入门
关于作者: CSDN内容合伙人、技术专家, 从零开始做日活千万级APP,带领团队单日营收超千万。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业化变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览…...

Go语言的调度器
简介 Go语言的调度器是一个非常强大的工具,它可以帮助我们轻松地实现并发编程。调度器的工作原理是将多个协程映射到多个操作系统线程上,并根据协程的状态来决定哪个协程应该在哪个线程上运行。 调度器有两种主要策略: 协作式调度…...
Linux系统使用超详细(十)~vi/vim命令①
vi/vim命令有很多,其实只有少数的用法对于我们日常工作中起到了很大帮助,但是既然我选择梳理Linux的学习笔记,那么一定全力把自己的理解和学习笔记的内容认真整理汇总,内容或许有错误,还请发现的C友们发现了及时指出。…...

C语言实现双向链表
1.版本一 由于节点之间的连接变多 所以我们最好提前将前驱节点和后继节点用变量保存下来 以免等下在进行节点之间的指向时出错 #include <stdio.h> #include <stdlib.h> #include <stdbool.h> // 节点类 typedef struct Node {// 数据域int data;// 指针域…...
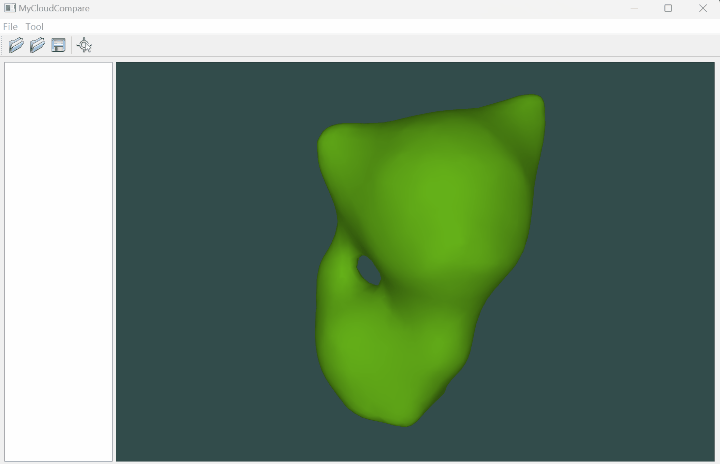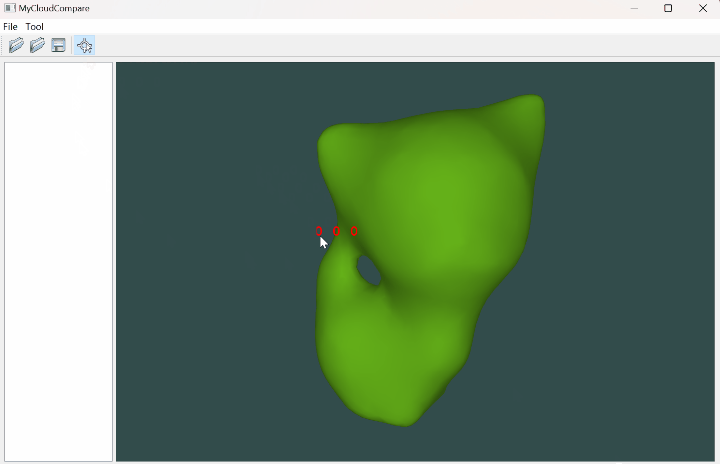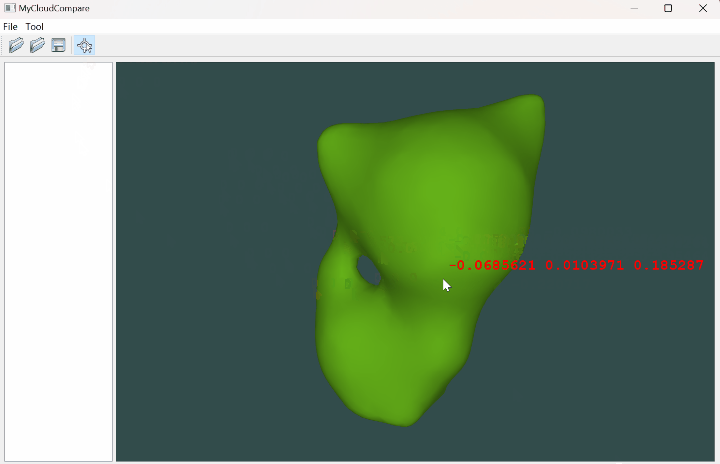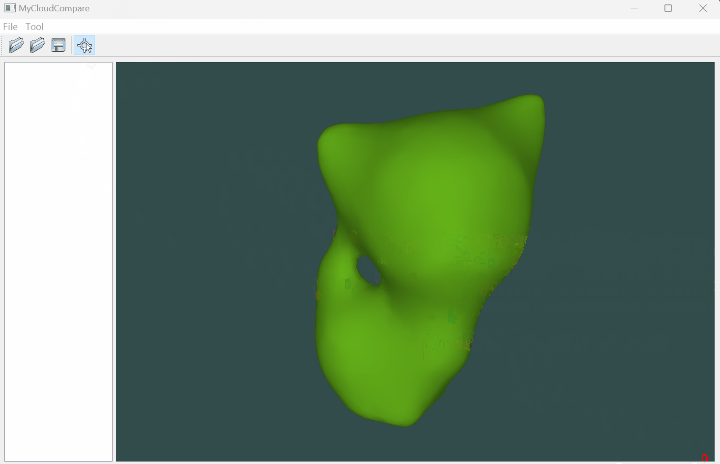
OpenGL 网格拾取坐标(Qt)
文章目录 一、简介二、代码实现三、实现效果参考资料一、简介 有时候我们希望通过鼠标来拾取某个网格中的坐标,这就涉及到一个很有趣的场景:光线投射,也就是求取一条射线与网格的交点,这里如果我们采用普通遍历网格中的每个面片的方式,当网格的面片数据量很大时计算效率就…...

GitHub高级搜索技巧
GitHub高级搜索技巧 in:name <关键字> 仓库名称带关键字查询 in:description <关键字> 仓库描述带关键字查询 in:readme <关键字> README文件带关键字查询 stars(fork): >() <数字> <关键字> star或fork数大于(或等于)指定数字的带关键字查…...
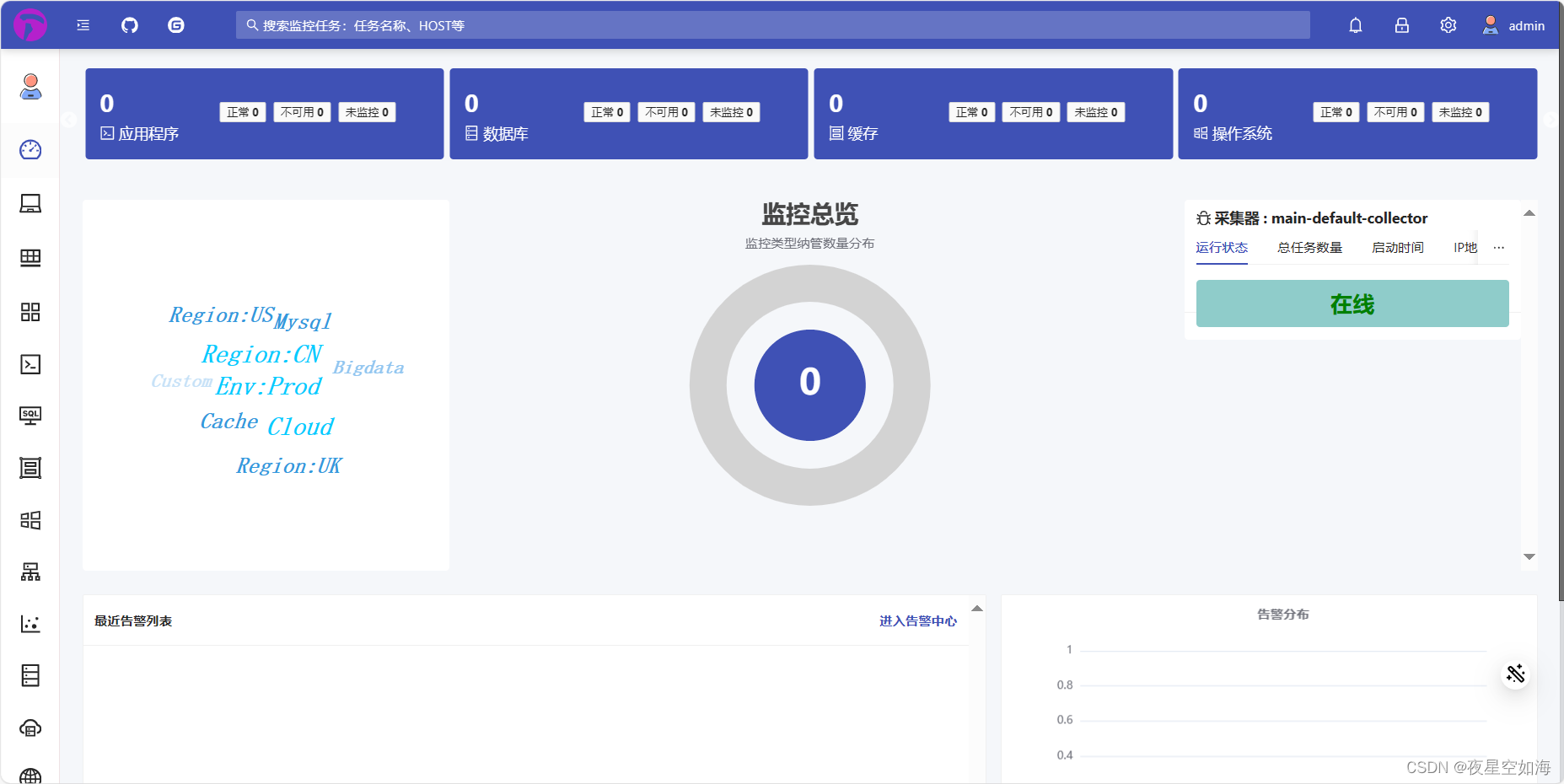
docker-compose安装HertzBeat赫兹跳动监控H3C交换机
前面我们用docker方式安装了HertzBeat,现在我们自己写个docker-compose.yml文件、创建文件直接docker-compose up -d直接启动运行 使用docker-compose需要先安装docker和docker-compose1、输入以下两段命令 mkdir 123 && cd 123 && mkdir data &a…...

NetSuite学习笔记 - 中心
一、什么是中心? 对于每个用户,NetSuite 会根据用户的指定角色显示一组可变的标签页面,称为中心。通俗来讲呢,NetSuite的中心其实就是我们常说的“导航菜单”。 只是在我过去常见的系统中,导航菜单一般都是固定的&am…...
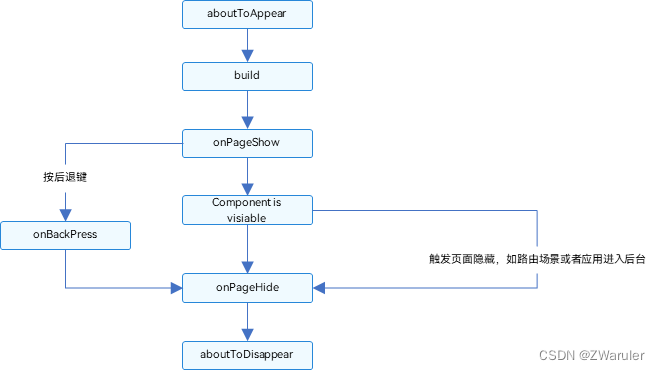
鸿蒙开发笔记(三):页面和自定义组件生命周期
先明确自定义组件和页面的关系: 自定义组件:Component装饰的UI单元,可以组合多个系统组件实现UI的复用。 页面:即应用的UI页面。可以由一个或者多个自定义组件组成,Entry装饰的自定义组件为页面的入口组件,…...
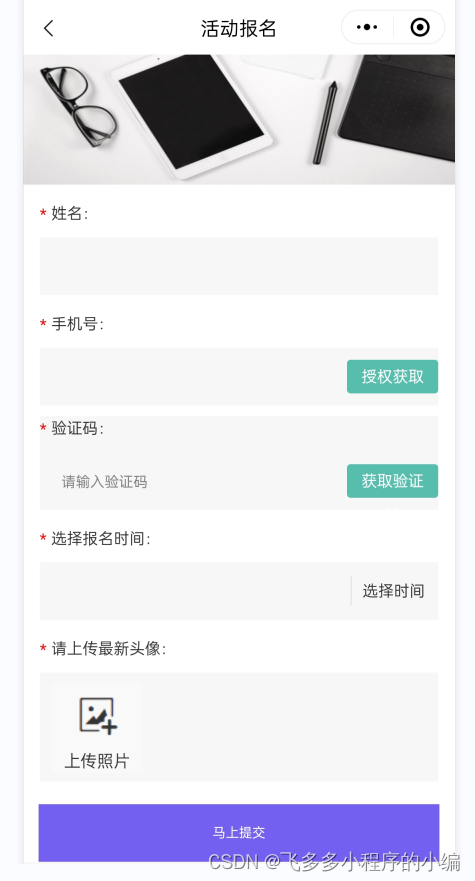
报名活动怎么做_小程序创建线上报名活动最详细攻略
报名活动怎么做:一篇让你掌握活动策划与营销的秘籍 在当今社会,无论是线上还是线下,活动已经成为企业营销和品牌推广的重要手段。但是,如何策划一场成功的活动呢?这篇文章将为你揭示活动策划与营销的秘籍,…...
Apache POI 导出Excel报表
大家好我是苏麟 , 今天聊聊Apache POI . Apache POI 介绍 Apache POI 是一个处理Miscrosoft Office各种文件格式的开源项目。简单来说就是,我们可以使用 POI 在 Java 程序中对Miscrosoft Office各种文件进行读写操作。 一般情况下,POI 都是用于操作 E…...
使用Qt连接scrcpy-server控制手机
Qt连接scrcpy-server 测试环境如何启动scrcpy-server1. 连接设备2. 推送scrcpy-server到手机上3. 建立Adb隧道连接4. 启动服务5. 关闭服务 使用QTcpServer与scrcpy-server建立连接建立连接并视频推流完整流程1. 开启视频推流过程2. 关闭视频推流过程 视频流的解码1. 数据包协议…...

debian12部署Gitea服务之二——部署git-lfs
Debian安装gitlfs: 先更新下软件包版本 sudo apt update 安装 sudo apt install git-lfs 验证是否安装成功 git lfs version cd到Gitea仓库目录下 cd /mnt/HuHDD/Git/Gitea/Repo/hu/testrepo.git 执行lfs的初始化命令 git lfs install客户机Windows端在官网下载并安装Git-Lfs 再…...

leetcode 1两数之和
题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺…...
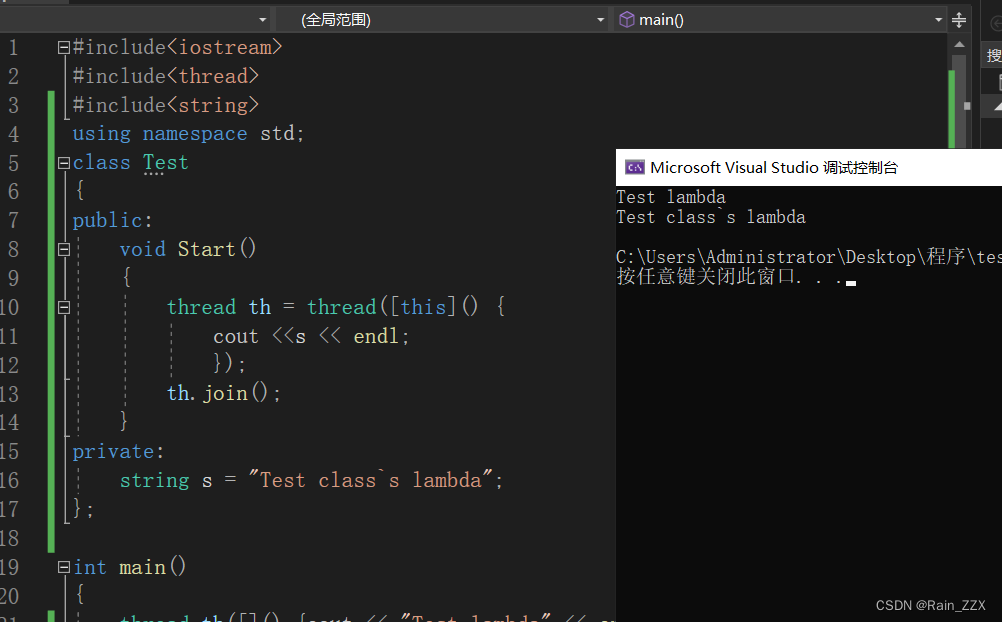
C++多线程学习[三]:成员函数作为线程入口
一、成员函数作为线程入口 #include<iostream> #include<thread> #include<string>using namespace std;class Mythread { public:string str;void Test(){cout << str << endl;} }; int main() {Mythread test;test.str "Test";thr…...
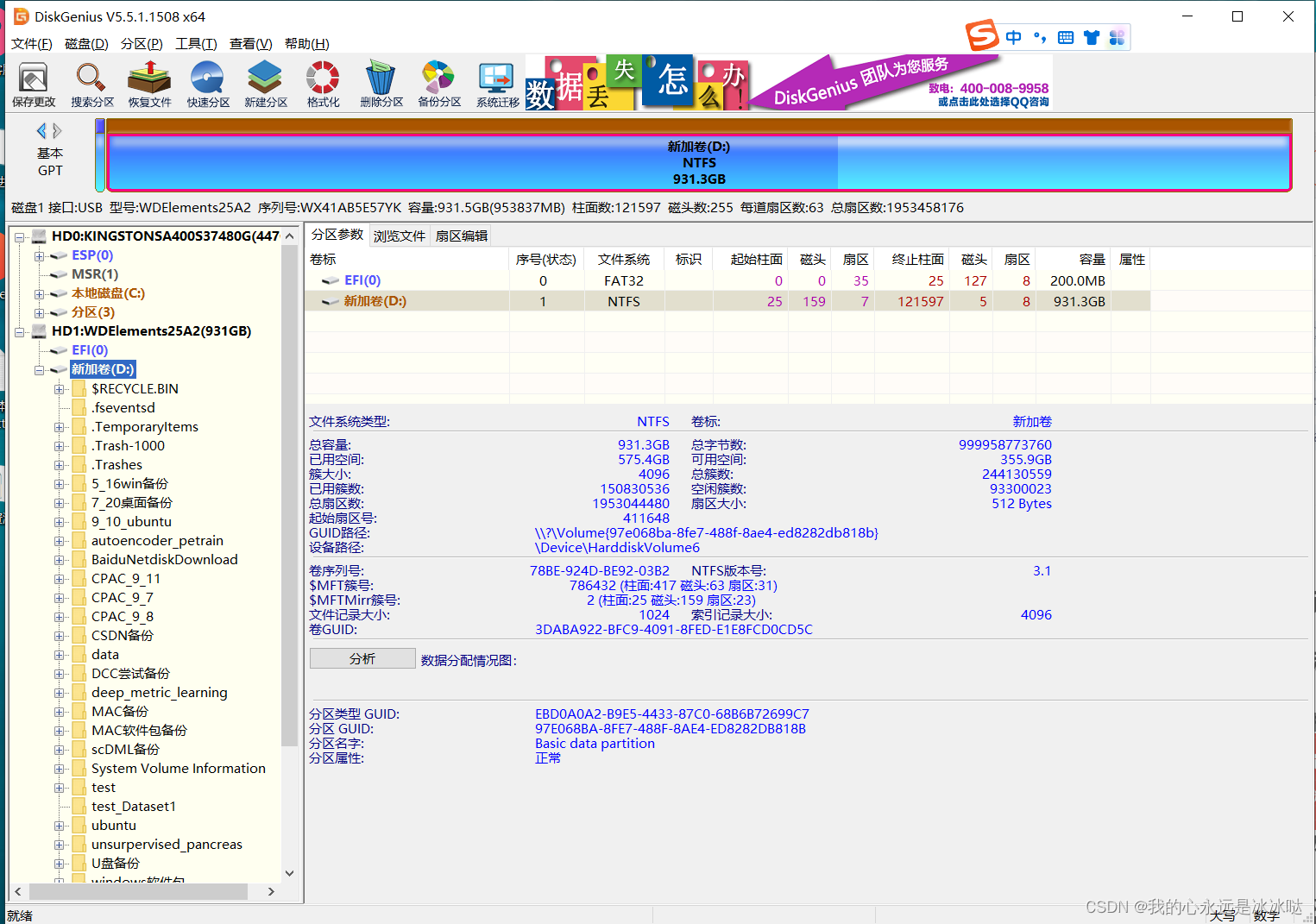
移动硬盘无法识别处理办法
今天这里做一下总结,我现在手上有一个移动硬盘,插入win10电脑是有盘号的,但是 但是点击就出问题 解决办法 安装DiskGenius 下载网址在https://www.diskgenius.cn/download.php 下载之后解压安装就行,非常简单,然后…...

【Spring Cloud】Sentinel流量限流和熔断降级的讲解
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《Spring Cloud》。🎯🎯 &am…...

前端浮点和16进制互转
一、浮点转16进制数据 //浮点数转16进制 function singleToHex(t) {if (t "") {return "";}t parseFloat(t.substr(0, 4));if (isNaN(t) true) {return "Error";}if (t 0) {return "00000000";}var s,e,m;if (t > 0) {s 0;}e…...
与equals()的相关规定)
Java中hashCode()与equals()的相关规定
API文件有对对象的状态制定出必须遵循的规则。hashCode()和equals()是object中定义的两个方法,它们都与对象的相等性有关。 通常情况下我们需要同时使用这两个方法来判断两个对象是否相等,只有两个对象的equals()方法返回true,并且它们的has…...

生产环境最佳实践
生产环境最佳实践 前言 本文将介绍Spring Cloud Alibaba在生产环境中的最佳实践,包括配置优化、监控告警、高可用设计等方面。 一、高可用设计 1.1 服务端高可用 # Nacos集群配置 # 至少3个节点 # 推荐使用外部数据库spring:cloud:nacos:server-addr: nacos-1:8848,…...

HTML应用指南:利用GET请求获取智己汽车门店位置信息
智己汽车作为高端智能电动汽车品牌,深度融合先锋设计美学、纯电驱动技术、高阶智能驾驶与全场景出行服务,依托L7、LS7、LS6、L6等产品矩阵,打造兼具科技感与驾控乐趣的高端出行体验。在营销推广层面,智己摒弃传统4S店模式…...

Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究|附代码数据
全文链接:https://tecdat.cn/?p45916原文出处:拓端数据部落公众号封面:关于分析师在此对 Haoyang Ke 对本文所作的贡献表示诚挚感谢。他在浙江财经大学完成了数理统计专业的学习,专注机器学习、数据采集领域。他擅长 Python、R 语…...

Claude Mythos:AI驱动的自动化漏洞挖掘与攻防范式跃迁
1. 项目概述:一场静默却震耳欲聋的AI能力跃迁这周,整个AI安全圈没有爆炸性新闻稿,没有铺天盖地的发布会直播,只有一份措辞克制、数据密集的系统卡片(System Card)和一份由英国AI安全研究所(AISI…...

GPT-4稀疏激活机制解析:1.8万亿参数为何仅用2%
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区被反复引用、误读、放大,甚至成为AI算力焦虑的具象化符号。但作为从2017年就开始部署LSTM语音模型、2019年…...

Java 零基础全套教程,数据结构与集合源码,笔记 168-174
Java 零基础全套教程,数据结构与集合源码,笔记 168-174 一、参考资料 【Java视频教程,java入门神器(附300道Java面试题剖析)】 https://www.bilibili.com/video/BV1PY411e7J6/?p168&share_sourcecopy_web&vd_…...

深度学习的缺失数据革命:使用MIDAS实现高效多重插补
深度学习的缺失数据革命:使用MIDAS实现高效多重插补 【免费下载链接】MIDAS Multiple imputation utilising denoising autoencoder for approximate Bayesian inference 项目地址: https://gitcode.com/gh_mirrors/midas3/MIDAS 在数据科学和机器学习领域&a…...


西门子S7-1200 PLC编程避坑指南:从振荡电路到浮点数计算,新手最易犯的5个错误
西门子S7-1200 PLC编程实战避坑手册:从逻辑陷阱到数据精度的深度解析 在工业自动化领域,PLC编程就像是在钢丝上跳舞——一步错可能导致整个产线瘫痪。作为西门子S7-1200的资深用户,我见过太多初学者在相同的地方跌倒。这篇文章不会给你教科书…...

如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程
如何用knitAYABInterface创建复杂图案:从JSON文件到针织成品的完整流程 【免费下载链接】knitAYABInterface A Python library with the interface to the AYAB shield. 项目地址: https://gitcode.com/gh_mirrors/ay/knitAYABInterface 想要将数字图案转化为…...