大语言模型系列-word2vec
文章目录
- 前言
- 一、word2vec的网络结构和流程
- 1.Skip-Gram模型
- 2.CBOW模型
- 二、word2vec的训练机制
- 1. Hierarchical softmax
- 2. Negative Sampling
- 总结
前言
在前文大语言模型系列-总述已经提到传统NLP的一般流程:
创建语料库 => 数据预处理 => 分词向量化 => 特征选择 => 建模(RNN、LSTM等)
传统的分词向量化的手段是进行简单编码(如one-hot),存在如下缺点:
- 如果词库过大, one-hot编码生成的向量会造成维度灾难
- one-hot编码生成的向量是稀疏的,它们之间的距离相等,无法捕捉单词之间的语义关系。
- one-hot编码是固定的,无法在训练过程中进行调整。
因此,出现了词嵌入(word embedding)的概念,通过word embedding模型生成的向量是密集的,具有相似含义的单词在向量空间中距离较近,可以捕捉单词之间的语义关系。并且Word Embedding模型的权重可以在训练过程中进行调整,以便更好地捕捉词汇之间的语义关系。
word2vec就是一种经典的词嵌入(word embedding)模型,由Tomas Mikolov等人在2013年提出,它通过学习将单词映射到连续向量空间中的表示,以捕捉单词之间的语义关系。
提示:以下是本篇文章正文内容,下面内容可供参考
一、word2vec的网络结构和流程
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,根据学习思路的不同,分为两种训练方式:Skip-Gram和CBOW(Continuous Bag of Words)。其中,Skip-gram是已知当前词的情况下预测上下文的表示,CBOW则是在已知上下文的情况下预测当前词的表示。通过这种表示学习,学得映射矩阵,将原始离散数据空间映射到新的连续向量空间(实际上起到了降维的作用)。
- 将单词使用one-hot编码
- 输入网络进行训练,获得参数矩阵 W V × N W_{V×N} WV×N
- 输入层的每个单词one-hot编码x(V-dim)与矩阵W相乘,即 x ⋅ W V × N x \cdot W_{V×N} x⋅WV×N,得到其word embedding(N-dim)
1.Skip-Gram模型
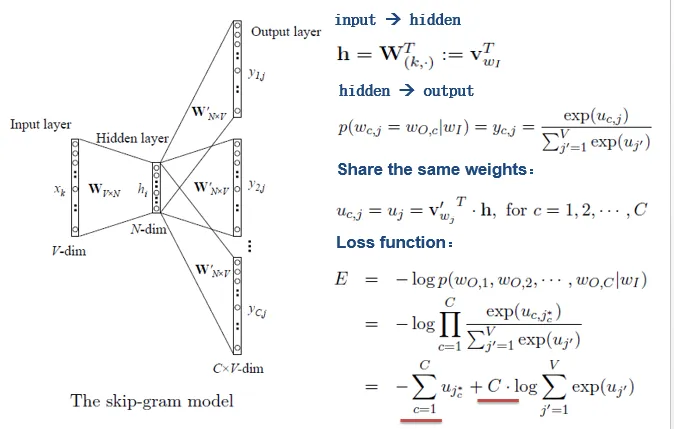
2.CBOW模型
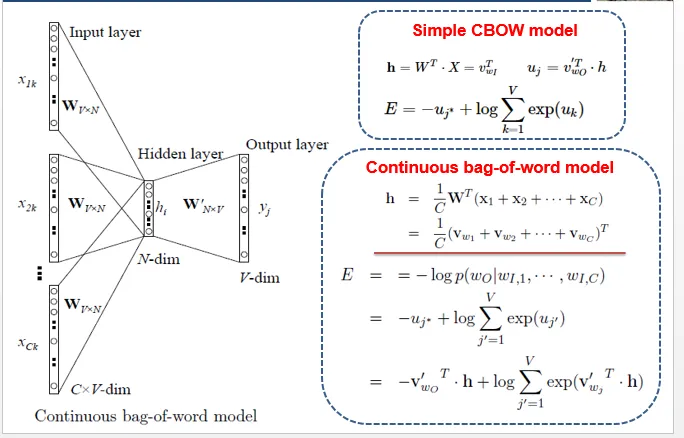
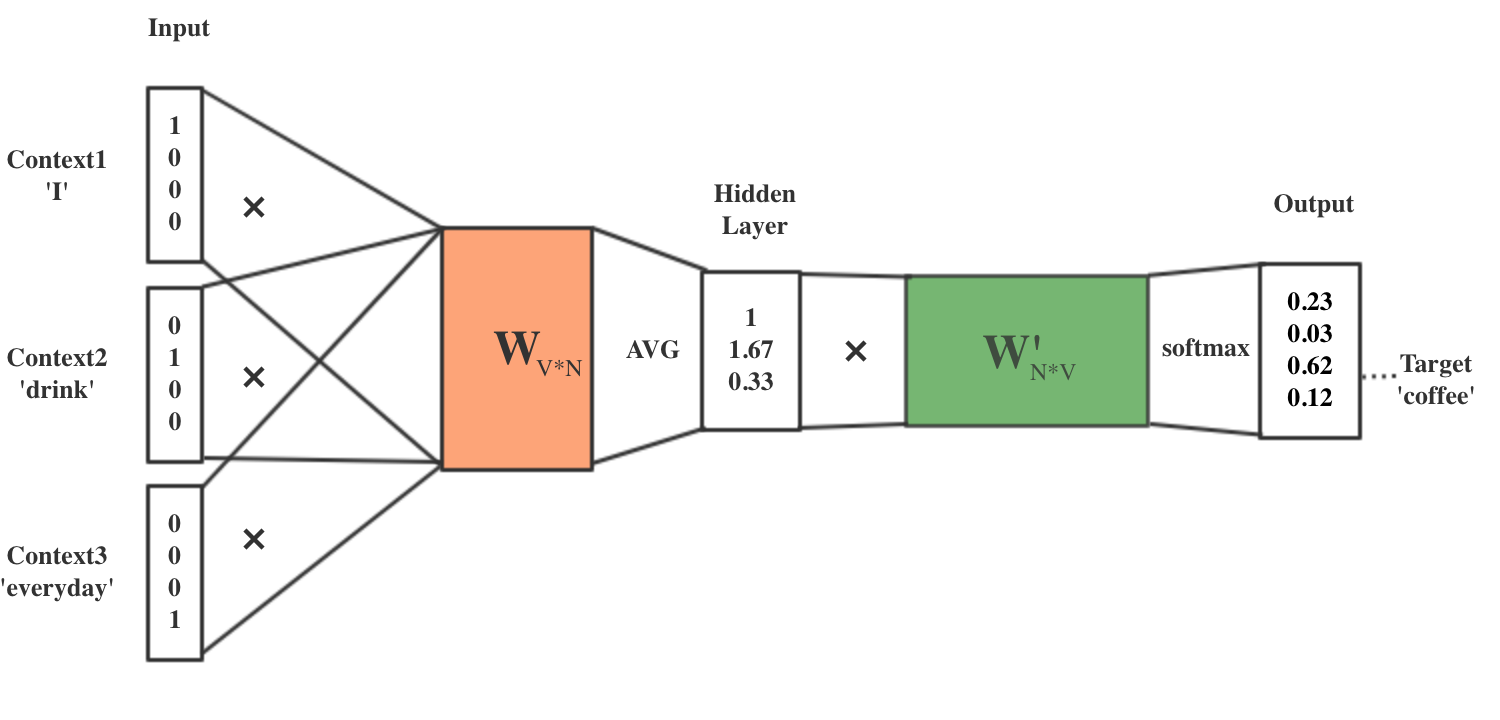
二、word2vec的训练机制
假设语料库中有V个不同的单词,hidden layer取128,则word2vec两个权值矩阵维度都是[V,128],我们使用的语料库往往十分庞大,这也会导致权值矩阵的庞大,即神经网络的参数规模的庞大,在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。
word2vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling。
1. Hierarchical softmax
和传统的神经网络输出不同的是,word2vec的hierarchical softmax结构是把输出层改成了一颗哈夫曼树,其中图中白色的叶子节点表示词汇表中所有的V个词,黑色节点表示非叶子节点,每一个叶子节点也就是每一个单词,都对应唯一的一条从root节点出发的路径。我们的目的是使的 w = w 0 w=w_0 w=w0这条路径的概率最大,即: P ( w = w 0 ∣ w I ) P(w=w_0|w_I) P(w=w0∣wI)最大,假设最后输出的条件概率是 P ( w = w 0 ∣ w 2 ) P(w=w_0|w_2) P(w=w0∣w2)最大,那么只需要去更新从根结点到 w 2 w_2 w2这一个叶子结点的路径上面节点的向量即可,而不需要更新所有的词的出现概率,这样大大的缩小了模型训练更新的时间。
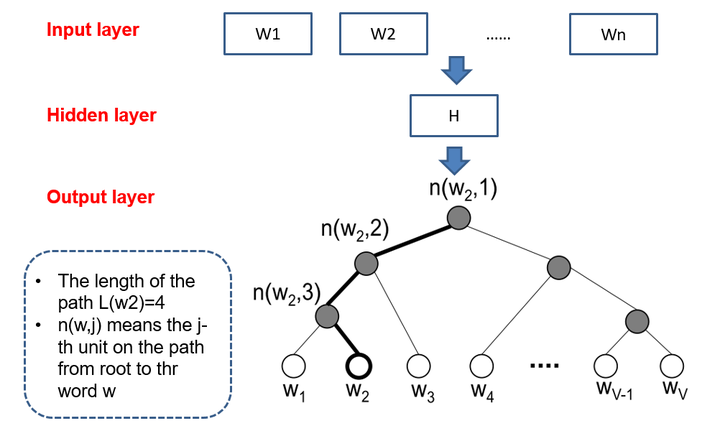
ps:
- 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
- 我们知道在输入softmax之前,可以简单认为神经网络输出的大体含义为每个单词的频率,可以将其视为权值,然后通过哈夫曼树编码。这样在训练时,如果我们要计算Leaf2(观看)的概率,只需计算从Root到Leaf2路径上的节点的概率即可,而不需要考虑其他叶子节点,从而大大降低计算复杂度。
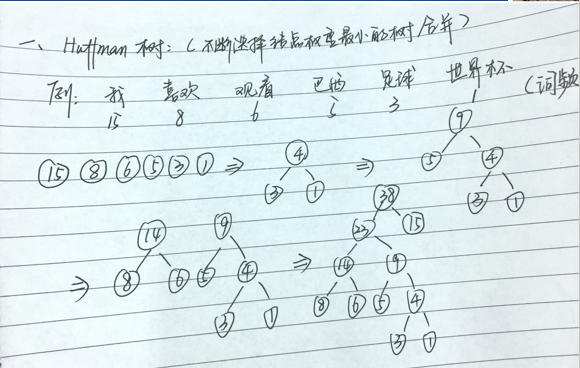

Hierarchical softmax的优点如下:
1)从利用softmax计算概率值改为利用Huffman树计算概率值,计算复杂度从O(V)变成了O(logV)
2)由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到(贪心优化思想)
2. Negative Sampling
我们已经知道,对于每个训练样本,word2vec都需要计算并更新所有词汇表中的词的权重。这在大规模的词汇表上会变得非常昂贵,尤其是当词汇表非常大时。
Hierarchical softmax通过哈夫曼树,使得对于每个训练样本,只需要更新路径节点权重即可,大大减少了参数量和计算成本。Negative Sampling则通过只更新与当前训练样本相关的一小部分词的权重,以此来降低计算成本。具体步骤如下:
- 对于输入的中心词 w c w_c wc,设置窗口大小m,该窗口大小内的词为正样本(即 w c − m , . . . , w c + m w_{c-m},...,w_{c+m} wc−m,...,wc+m,不包括 w c w_c wc)
- 按照一定的概率分布 P ( w ~ ) P(\tilde w) P(w~)从词典中抽取K个负样本 w ~ 1 , w ~ 2 , . . . , w ~ k \tilde w_1, \tilde w_2,..., \tilde w_k w~1,w~2,...,w~k,那么{ w c , w ~ k w_c,\tilde w_k wc,w~k}为负样本,其中k=1,2,…,K
- 则给定中心词 w c w_c wc,预测 w j w_j wj( j ∈ [ c − m , c + m ] j∈[c-m,c+m] j∈[c−m,c+m])由如下事件集构成: w c w_c wc和 w j w_j wj共同出现,以及 w c w_c wc不和 w ~ k \tilde w_k w~k共同出现
Negative Sampling的优点如下:
1)将多分类问题转换成K+1个二分类问题,从而减少计算量,计算复杂度由O(V)变成了O(K),加快了训练速度。
2)保证模型训练效果,因为目标词只跟相近的词有关,没有必要使用全部的单词作为负例来更新它们的权重。
总结
和之前的方法相比,word2vec能够考虑上下文并获得低维的词向量表示,但word2vec无法解决多义词问题,没有语境信息,原因是word embedding是静态的(词和向量是一对一的关系),并且词嵌入和实际任务模型分开,使得整个训练过程不是端到端的。

相关文章:
大语言模型系列-word2vec
文章目录 前言一、word2vec的网络结构和流程1.Skip-Gram模型2.CBOW模型 二、word2vec的训练机制1. Hierarchical softmax2. Negative Sampling 总结 前言 在前文大语言模型系列-总述已经提到传统NLP的一般流程: 创建语料库 > 数据预处理 > 分词向量化 > …...

vue项目运行报错this[kHandle] = new _Hash(algorithm, xofLen)
自从昨天分盘重装了最新版本的Node之后,项目是一启一个报错 出现这个报错时,需要在package.json文件中 dev命令行 增加:set NODE_OPTIONS–openssl-legacy-provider 出现该问题的原因: node.js V17开始版本中发布的是OpenSSL3.0,…...

APP兼容性测试,这几个面试硬技能,包教包会
兼容性测试主要通过人工或自动化的方式,在需要覆盖的终端设备上进行功能用例执行,查看软件性能、稳定性等是否正常。 对于需要覆盖的终端设备,大型互联网公司,像 BAT,基本都有自己的测试实验室,拥有大量终…...

【学习iOS高质量开发】——熟悉Objective-C
文章目录 一、Objective-C的起源1.OC和其它面向对象语言2.OC和C语言3.要点 二、在类的头文件中尽量少引用其他头文件1.OC的文件2.向前声明的好处3.如何正确引入头文件4.要点 三、多用字面量语法,少用与之等价的方法1.何为字面量语法2.字面数值3.字面量数组4.字面量字…...
Qt/QML编程之路:Grid、GridLayout、GridView、Repeater(33)
GRID网格用处非常大,不仅在excel中,在GUI中,也是非常重要的一种控件。 Grid 网格是一种以网格形式定位其子项的类型。网格创建一个足够大的单元格网格,以容纳其所有子项,并将这些项从左到右、从上到下放置在单元格中。每个项目都位于其单元格的左上角,位置为(0,0)。…...
mac pro “RESP.app”意外退出 redis desktop manager
文章目录 redis desktop manager下载地址提示程序含有恶意代码“RESP.app”意外退出解决办法:下载python3.10.并安装重新打开RESP如果还是不行,那么需要替换错误路径(我的没用)外传 最近在研究redis的消息,看到了strea…...
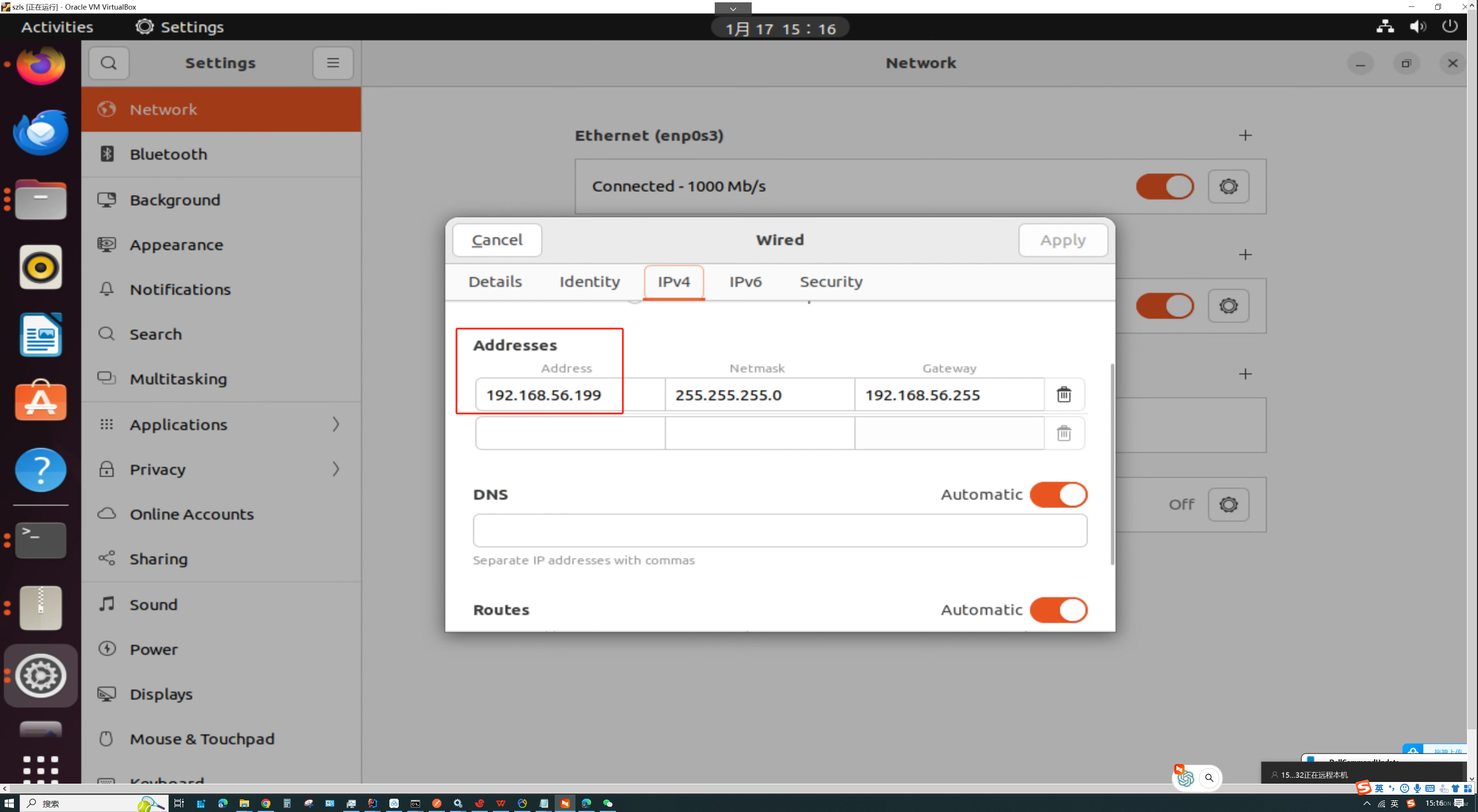
VirtualBox 如何让虚拟机和主机互相通信
首先建立一张虚拟网卡 在这里进行网络设置 设置成固定ip,这张网卡专门用来通信,上面的网卡用来上网的...
【Java】源码文件开头添加注释
需求 应公司质量部要求,需要对代码做静态检查。质量部要求,源码文件必须在起始行起设置一些注释,然而项目已经开发了一年之久,且没有维护这个注释。 此时,面对好几千个源码文件,我们如何快速添加相应的注…...

GitHub 异常 - 无法连接22端口 Connection timed out
GitHub 异常 - 无法连接22端口 Connection timed out 问题描述 错误信息: 今天突然用ssh方式 pull GitHub的项目报:ssh: connect to host xx.xx.xx.xx port 22: Connection timed out 表明 SSH 连接在尝试通过 22 端口连接到远程服务器时超时。这可能是由于网络环…...

python基础学习
缩⼩图像(或称为下采样(subsampled)或降采样(downsampled))的主要⽬的有两个:1、使得图像符合显⽰区域的⼤⼩;2、⽣成对应图像的缩略图。 放⼤图像(或称为上采样…...
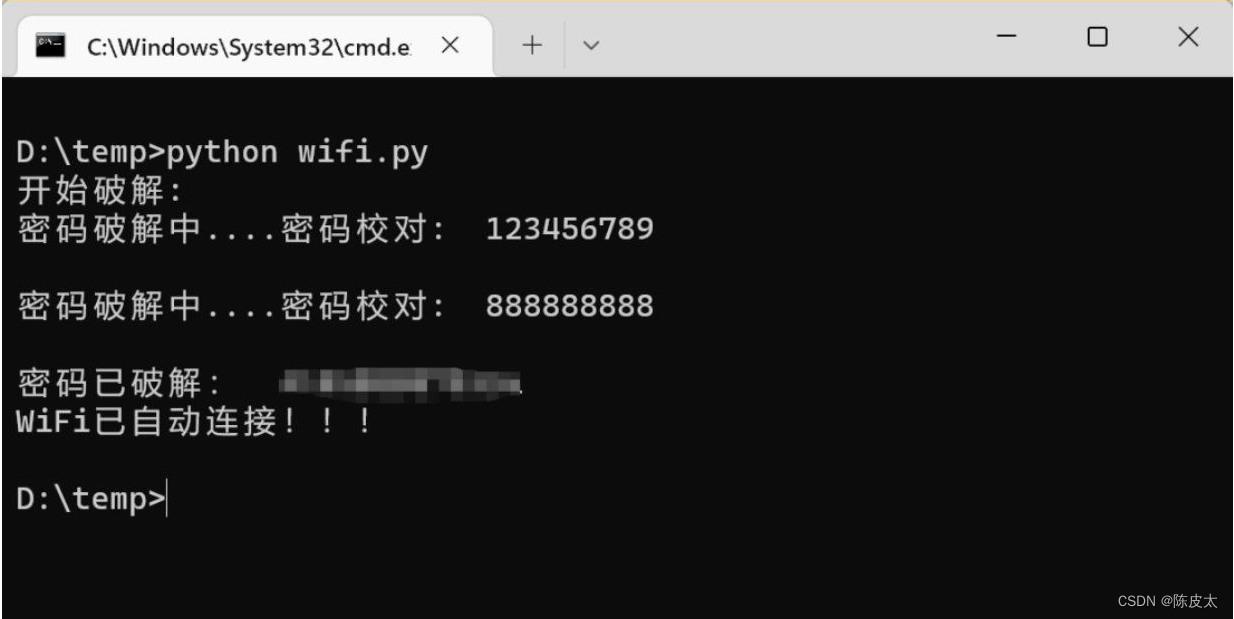
Python密码本连接wifi
有时候我们会忘记自己的Wi-Fi密码,或者需要连接某个Wi-Fi网络以满足合法需求。本文将介绍如何使用Python编程语言编写一个简单的连接Wi-Fi的程序。 一、密码本准备 在进行wifi猜测时,其实就是列出各种可能的密码,用来尝试去访问目标wifi&…...

Docker 设置 Redis 的密码失效
在网上找了设置Docker里的设置Redis密码,一段时间就失效了 1. 进入redis的容器 docker exec -it 容器ID redis-cli2. config set requirepass 密码 解决方法 1. 创建 redis.conf 配置文件 # Redis configuration file example. # # Note that in order to read the configu…...
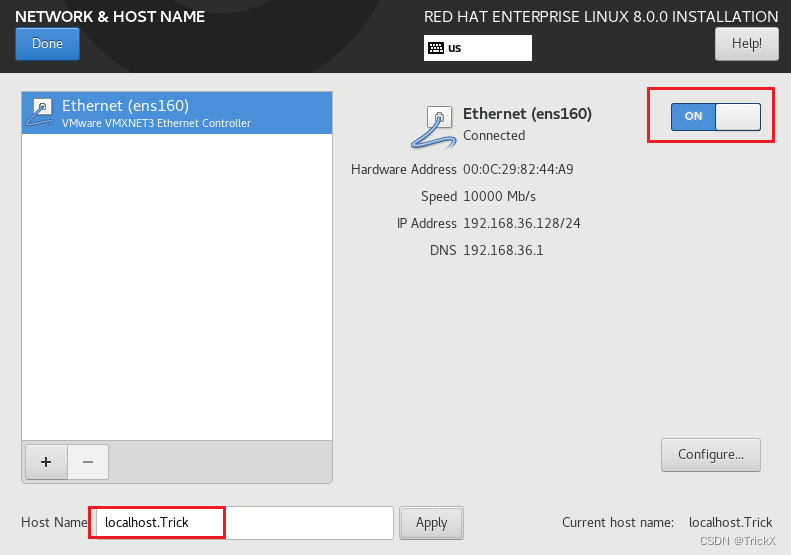
1.环境部署
1.虚拟机安装redhat8系统 这个其实很简单,但是有一点小细节需要注意。 因为我的电脑是 16核心的,所以选择内核16,可以最大发挥虚拟机的性能 磁盘选择SATA,便于后期学习 将一些没用的设备移除 选择安装redhat 8 时间选择上海 选择…...

2024年第二届“华数杯”国际大学生数学建模竞赛 (A题 MCM)| 废水扩散分析 |数学建模完整代码+建模过程全解全析
当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。 让我们来看看华数杯的A题! 完整内容可以在文章末…...

深度学习基础知识整理
自动编码器 Auto-encoders是一种人工神经网络,用于学习未标记数据的有效编码。它由两个部分组成:编码器和解码器。编码器将输入数据转换为一种更紧凑的表示形式,而解码器则将该表示形式转换回原始数据。这种方法可以用于降维,去噪,特征提取和生成模型。 自编码器的训练过…...

go语言GMP模式介绍以及协程案例展示
一. MPG模式 Go语言的调度模型被称为GMP,这是一个高效且复杂的调度系统,用于在可用的物理线程上调度goroutines(Go的轻量级线程)。GMP模型由三个主要组件构成:Goroutine、M(机器)和P࿰…...
码牛课堂首推——鸿蒙南北双向开发学习路线图标准版~
鸿蒙!鸿蒙!鸿蒙! 要说2023-2024年IT圈最火爆的名词,一定是鸿蒙! 2023年9月25日,华为发布会正式宣布2024年第一季度将推出HarmonyOS NEXT版本,这意味着鸿蒙原生应用开发将彻底摆脱Android手机系…...
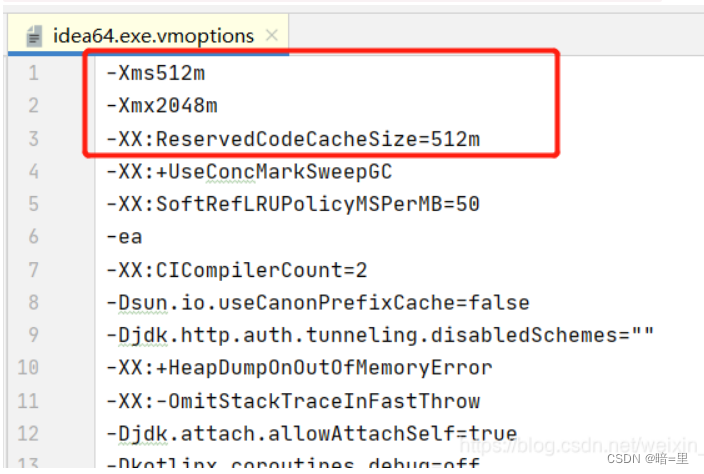
(亲测可行)关于提高IDEA运行速度的方案
1.作者IDEA软件版本和计算机内存 Ultimate 2022.1.2版IDEA,计算机内存为12GB 2.修改配置以提高IDEA运行速度的误区-调高堆内存 很多文章会教调配置的内存,但大多是让你调高堆内存,比如会让你调高-Xms -Xmx ,这两种对应的是最…...

框架基础-Maven+SpringBoot入门
框架基础 Maven基础 Maven概述 Maven是为Java项目提供项目构建和依赖管理的工具 Maven三大功能 - 项目构建构建:是一个将代码从开发阶段到生产阶段的一个过程:清理,编译,测试,打包,安装,部署…...
uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -投票帖子排行实现
锋哥原创的uniapp微信小程序投票系统实战: uniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )_哔哩哔哩_bilibiliuniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )共计21条视频…...

80C166/C167芯片内部RAM执行代码技术详解
1. 80C166/C167芯片内部RAM执行代码的技术解析在嵌入式系统开发中,有时我们需要将特定代码从ROM复制到芯片内部RAM执行。这种需求常见于需要改变总线模式的场景,比如在Siemens 80C166/C167微控制器上切换8位/16位模式或改变总线复用配置。根据Siemens官方…...

DPO vs PPO:两种AI对齐技术到底选哪个?我全试了一遍
整整一个月的实验,四块4090烧了不知道多少电费。这不算什么,真正让我崩溃的是——跑了三天的PPO训练,在最后一刻因为reward model打分偏差炸了。 那一刻我真的很想摔键盘。 但后来换上DPO重新跑,12小时搞定,效果还更…...

UCD9081 GUI实战:电源时序管理与故障记录配置详解
1. 项目概述:为什么我们需要一个智能的电源监控与序列管理器?在复杂的多轨电源系统设计中,比如服务器主板、通信基站或者高端测试仪器,工程师们常常面临一个共同的挑战:如何确保十几路甚至几十路电源在上电、下电以及运…...

原神祈愿数据分析终极方案:genshin-wish-export架构革命与效能倍增
原神祈愿数据分析终极方案:genshin-wish-export架构革命与效能倍增 【免费下载链接】genshin-wish-export Easily export the Genshin Impact wish record. 项目地址: https://gitcode.com/GitHub_Trending/ge/genshin-wish-export 你是否曾在多设备间苦苦同…...

转行简历不会衔接?AI一键生成,自然过渡无违和感,邀约率飙升3倍!
“我以前是做销售的,想转行产品经理,简历上怎么写才能不让HR觉得我风马牛不相及?” “干了几年运营,现在想尝试开发,简历里除了写熟悉Word、Excel,还能写啥?” “裸辞转行,简历一片…...

终极窗口置顶解决方案:AlwaysOnTop完整使用指南
终极窗口置顶解决方案:AlwaysOnTop完整使用指南 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 在Windows多任务处理中,窗口遮挡是影响工作效率的主要痛点…...
)
ElevenLabs广西话语音定制全链路指南(含南宁/柳州/玉林三方言音色对比数据)
更多请点击: https://codechina.net 第一章:ElevenLabs广西话语音定制的背景与技术定位 随着语音合成技术从通用语种向方言及小众语言纵深演进,区域性语音能力成为人机交互本地化落地的关键瓶颈。广西话(以南宁白话为代表&#x…...
)
告别OnlyOffice限制!用Alist+KkFileView搭建全能文件预览中心(支持CAD/PSD/ZIP)
突破文件预览瓶颈:AlistKkFileView全格式支持实战指南 你是否曾因AlistOnlyOffice无法预览CAD图纸而焦头烂额?或是面对团队发来的PSD设计稿只能干瞪眼?这套组合方案虽能解决基础办公文档需求,但遇到专业格式就束手无策。本文将带你…...
,3大未公开API接口实测报告)
别再手动复制粘贴了!ChatGPT原生PPT导出功能已上线(仅限Enterprise Tier),3大未公开API接口实测报告
更多请点击: https://intelliparadigm.com 第一章:ChatGPT原生PPT导出功能的架构演进与企业级定位 ChatGPT原生PPT导出功能并非简单集成第三方渲染库,而是OpenAI在模型服务层、内容生成中间件与文档编排引擎三者深度协同下构建的端到端能力。…...

Nodejs开发者三步搞定Taotoken接入并实现异步聊天对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs开发者三步搞定Taotoken接入并实现异步聊天对话功能 对于Node.js开发者而言,将大模型能力集成到应用中的第一步&…...