2024年1月16日Arxiv热门NLP大模型论文:Multi-Candidate Speculative Decoding
大幅提速NLP任务,无需牺牲准确性!南京大学提出新算法,大幅提升AI文本生成效率飞跃
引言:探索大型语言模型的高效文本生成
在自然语言处理(NLP)的领域中,大型语言模型(LLMs)已经证明了它们在各种任务上的卓越能力,从语言理解到文本生成,再到跨多种NLP任务和开放领域的泛化能力。然而,这些模型在自回归地生成文本时往往耗时较长。为了加快它们的速度,研究者们提出了一种名为“推测性解码”(speculative decoding)的策略,该策略通过快速草稿模型生成候选段落(一系列令牌),然后由目标模型并行验证。尽管这种方法在提高大型自回归模型的端到端延迟方面非常有效,但候选令牌的接受率受到多种因素的限制,包括模型、数据集和解码设置。本文将探讨一种新策略,即通过从草稿模型中采样多个候选项,然后将它们批量组织起来进行验证,以提高大型语言模型的效率。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」 智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人
神奇口令: 小瑶读者 (前100位有效)
论文概览:提升大型语言模型效率的新策略
1. 论文标题、作者、机构和链接
- 论文标题:Multi-Candidate Speculative Decoding
- 作者:Sen Yang, Shujian Huang, Xinyu Dai, Jiajun Chen
- 机构:National Key Laboratory for Novel Software Technology, Nanjing University
- 链接:https://arxiv.org/pdf/2401.06706.pdf
2. 大型语言模型的挑战与现有解决方案
大型语言模型如GPT系列和LLaMA在NLP任务中展现出了卓越的能力,但它们在生成文本时的高延迟和计算开销成为了部署LLM服务的一大障碍。目前流行的基于Transformer的LLMs通常采用自回归范式生成文本,这需要模型多次迭代解码单个文本片段,进一步加剧了延迟问题。为了解决这一问题,研究者们提出了推测性解码(SD),它通过一个比目标模型小得多的额外草稿模型以低计算成本生成几个候选令牌,然后在目标模型上并行验证这些候选项。
SD的主要目的是通过在验证阶段接受尽可能多的令牌来最小化对目标模型的调用。因此,加速性能在很大程度上取决于目标模型接受候选令牌的比率,即在给定上下文下草稿和目标模型输出分布之间的一致性。然而,研究表明,当处理涉及更长提示的复杂任务时,目标和草稿模型之间的分布差异变得更加明显。此外,社区中流行的对LLMs进行额外数据微调以提高其在特定方面的性能的做法,也可能在目标和草稿模型之间引入显著的分布差异,即使它们最初是对齐的。
本工作旨在提高目标模型在验证阶段的接受率。我们的动机是在草稿生成的每个位置采样多个候选令牌。这些候选项被组织成一批,以便在目标模型上并行验证。尽管这种方法直观且简单,但它遇到了一个挑战,即SD无法直接使用多个候选项来提高接受率,同时保持目标模型的输出分布。为了解决这个问题,我们提出了一种多候选验证算法。此外,从草稿模型中采样的多个候选项有可能发生碰撞。因此,我们还引入了一个更高效的无重复采样候选项的版本。
多候选推测解码(MCSD)的核心思想
1. 传统推测解码(SD)的工作流程
传统的推测解码(Speculative Decoding, SD)是一种提高大型自回归语言模型生成文本速度的方法。在SD中,首先由一个较小的草稿模型(draft model)生成一系列候选的词元(tokens),然后这些候选词元并行地被目标模型(target model)验证。验证过程是顺序进行的,从第一个候选词元开始,每个词元都会经过一个推测采样算法来决定是否被接受。如果一个词元被拒绝,后续的验证就会终止,并且算法会返回一个新的词元作为终点。如果所有词元都被接受,目标模型会额外采样一个词元作为终点。因此,这个过程至少生成1个,最多生成γ+1个被接受的词元。
2. MCSD的创新之处
多候选推测解码(Multi-Candidate Speculative Decoding, MCSD)的创新之处在于,它不仅仅在每个位置上生成一个候选词元,而是生成多个候选词元,并将它们组织成批量进行并行验证。这种方法直观上看似乎简单,但它面临的挑战是,传统的推测采样算法不能直接用于多候选词元的验证,同时还要保持目标模型的输出分布。为了解决这个问题,MCSD提出了一种多候选验证算法。此外,由于多候选词元采样可能会有重复,MCSD还引入了一种无替换采样的更高效版本。
多候选推测采样算法
1. 多候选推测采样的挑战
多候选推测采样面临的挑战是如何在不改变目标模型输出分布的前提下,提高候选词元的接受率。传统的推测采样算法在处理多个候选词元时不能直接使用,因为它们是独立同分布的,随着候选词元数量的增加,词元之间的碰撞(即重复)概率增加。一旦一个词元被拒绝,它在剩余分布中的概率就会变为0,因此不会再次被接受。
2. 无替换采样的多候选推测采样算法
为了避免词元碰撞,MCSD采用了无替换采样的方法。在无替换采样中,假设词元序列是顺序从分布q中采样的,即每个词元的采样都考虑到了之前已经采样的词元。MCSD提出了一种新的推测采样算法,并在附录中证明了这种算法能够保持目标模型的输出分布。这种方法类似于从一棵树的根部走到叶节点,每一步都可以从k个分支中选择一条路径,或者提前终止。通过这种方式,MCSD能够在保持输出分布的同时,提高了候选词元的接受率。
树状注意力机制的引入
1. 传统注意力机制的局限
在自然语言处理(NLP)领域,大型语言模型(LLMs)如GPT系列和LLaMA展现了卓越的语言理解和生成能力。然而,这些模型在生成文本时通常采用自回归方式,需要多次迭代解码单个文本,导致较高的延迟。为了加快生成速度,研究者提出了推测性解码(speculative decoding, SD),该方法使用一个快速的草稿模型生成候选片段,然后由目标模型并行验证。尽管SD在提升端到端延迟方面有效,但候选令牌的接受率受到模型、数据集和解码设置等多个因素的限制。
2. 树状注意力机制的优势
为了提高目标模型在验证阶段的接受率,本文提出了多候选推测性解码(multi-candidate speculative decoding, MCSD)。MCSD的核心思想是在草稿生成阶段对每个位置采样多个候选令牌,并将这些候选令牌组织成批量进行并行验证。这种方法虽直观,但面临一个挑战:如何在保持目标模型输出分布的同时,利用多个候选令牌提高接受率。为此,我们提出了一种多候选验证算法,并引入了树状注意力(Tree Attention)机制,以减少由于缓存复制而产生的通信开销。树状注意力机制通过设计精巧的注意力掩码,允许多个候选序列共享生成令牌的缓存,同时防止候选之间的信息污染,保持令牌之间的因果关系。这种机制使得在单个序列中并行处理多个候选成为可能,从而在增加了极少的计算开销的同时,显著减少了通信开销。
实验设置与效率评估
1. 模型与数据集的选择
实验基于公开可用的LLaMA套件及其经过指令数据微调的版本Vicuna进行评估。选择了13B和33B版本的模型作为目标模型,而作为快速草稿生成的小模型,采用了LLaMA-68M和LLaMA-160M。在数据集方面,我们使用了对话数据集Alpaca和翻译数据集WMT EnDe进行评估,这两个数据集在之前的研究中已被用于评估LLM的解码加速。
2. 接受率和块效率的定义
接受率(α)用于评估候选令牌在每一步被接受的概率,基本上反映了草稿模型和目标模型之间的分布一致性。块效率(τ)作为每个块生成的预期令牌数量的常用度量,其在最坏情况下为1(至少返回一个作为端点的令牌),如果所有候选令牌都被接受,则目标模型在末尾追加一个额外的令牌,因此τ = γ + 1。在实际部署中,调用草稿模型和执行我们的算法会产生额外的开销,因此我们除了块效率外,还报告了平均墙钟速度提升。
接受率提升的实验结果
1. 不同因素对接受率的影响
实验结果表明,接受率受多种因素影响,包括模型、数据集和解码设置。在未经微调的目标模型(如LLaMA)上,如果使用argmax采样在Alpaca数据集上进行推理,草稿模型生成的候选项具有较高的接受率。然而,对目标模型进行微调(如Vicuna版本的LLaMA)、更换数据集或采样方法都可能导致接受率下降。在大多数情况下,改变目标模型的大小对接受率的影响不大,而增加草稿模型的大小对接受率的提升作用有限。
2. 不同模型和数据集的接受率提升
通过使用LLaMA-68M作为草稿模型,我们观察到随着k值的增加,在不同模型和数据集上接受率都有一致的提升。当k值超过32时,接受率曲线趋于收敛,此时进一步增加k值变得困难且不经济。这些结果证明了我们的方法在提高接受率方面的有效性,即使k值较小。
主要结果:速度提升与块效率
1. 不同超参数配置下的性能
我们的方法在每个步骤中采样多个候选词,假设它们分别为k1, k1, …, kγ,总共生成K = Σγi=1 ki个候选词。这构成了一个巨大的超参数搜索空间。为了效率考虑,我们将总预算K限制在最多32个,ki ∈ {1, 2, 4, 8, 16, 32}。对于我们方法在不同超参数下的性能,请参见第4.4节。对于每种设置,我们报告了我们方法在最佳ks组合下的性能,以及具有相同γ值的SD和最佳γ值的SD的性能。
2. MCSD与传统SD的对比
总体而言,与SD基线相比,我们的方法始终实现了更高的速度提升和块效率,证明了该方法在提高目标模型效率方面的有效性。
方法在不同模型间的泛化能力
1. 微调草稿模型的影响
在探索不同模型间的泛化能力时,微调草稿模型对于提高目标模型的接受率具有显著影响。实验表明,即使在同一套模型内,当处理复杂任务涉及较长提示时,目标和草稿模型之间的分布差异会变得更加明显。此外,通过使用额外数据对大型语言模型(LLMs)进行微调以增强特定方面的性能已成为一种流行做法。然而,微调也可能引入目标和草稿模型之间的显著分布差异,即使它们最初是很好对齐的。
为了改善目标模型在验证阶段的接受率,本研究提出了在草稿生成中对每个位置采样多个候选标记,并将这些候选标记组织成批量进行并行验证。通过这种方法,我们不仅能够显著提高接受率,还能在保持目标模型分布的同时,有效地利用多候选验证算法。在多个数据集和模型上的实验结果表明,我们的方法在接受率上取得了显著改进,一致性地超过了标准的推测性解码(SD)。
2. 不同目标模型的兼容性
我们的方法在不同目标模型间展现出良好的泛化能力。通过将方法应用于LLaMA套件,包括其微调版本Vicuna,以及使用argmax和标准采样,我们的方法在Alpaca和WMT数据集上都取得了显著的接受率提升。此外,我们还将方法扩展到LLaMA2和OPT套件,验证了方法的泛化能力。值得注意的是,通过对草稿模型进行微调,我们可以进一步提高接受率,我们的方法可以叠加在这种微调之上。
相关工作:提升深度神经网络推理效率的研究
在提升深度神经网络推理效率的研究领域,已经开发了多种策略,包括蒸馏(distillation)、量化(quantisation)、稀疏化(sparcification)等。这些技术通常会引入一定程度的性能损失。与之相反,推测性解码(speculative decoding)有效地减少了LLMs的推理延迟,同时不影响模型性能。在推测性解码之前,块并行解码(blockwise parallel decoding)已经用于加速自回归模型的推理。
针对草稿和目标模型之间的分布一致性,研究者们专注于通过额外训练来对齐草稿模型和目标模型。然而,我们的实证发现表明,这种对齐在分布外数据(如WMT)上的鲁棒性不如分布内数据(如Alpaca)。与我们的研究相似,一些研究利用多个候选标记来提高接受率。例如,Miao等人利用多个草稿模型生成多样化的候选标记,而Cai等人训练额外的预测头部来达到同样的目的。他们的工作还包括树状注意力(Tree Attention)来减少与多候选标记相关的通信开销。与我们的方法类似,Sun等人也从草稿模型中采样多个候选标记。不同之处在于,他们从最优运输的角度推导出多候选验证算法,其实现需要线性规划。
结论:多候选推测解码的优势与未来展望
在本文中,我们介绍了一种新颖的多候选推测解码(MCSD)方法,旨在提高大型语言模型(LLM)在文本生成任务中的效率。通过在草稿模型中采样多个候选词,并将它们批量提交给目标模型进行并行验证,我们的方法显著提高了候选词的接受率,并在多个数据集和模型上一致超越了标准推测解码(SD)。
1. 多候选推测解码的优势
我们的实验结果表明,MCSD方法在接受率上取得了显著的提升。例如,在使用LLaMA-68M作为草稿模型时,随着候选数k的增加,接受率α在不同的模型和数据集上均有一致的提升(如图3所示)。此外,我们的方法在接受率上的改进并不依赖于草稿模型的大小,即使是较小的草稿模型也能产生良好的效果。
2. 树状注意力(Tree Attention)的应用
为了减少在处理多候选词时的通信开销,我们采用了树状注意力机制。这种机制允许多个候选词共享已生成词的缓存,从而减少了复制和传输的需要(如图2所示)。这一设计不仅优化了计算资源的使用,还保持了生成过程中的因果关系。
3. 方法的泛化能力
我们的方法不仅在LLaMA模型套件上表现出色,还在LLaMA2和OPT套件上验证了其泛化能力。通过对草稿模型进行微调,我们进一步提高了与目标模型的分布一致性,这表明我们的方法可以与微调过程无缝结合,以适应特定的任务或领域。
4. 未来展望
尽管我们的方法已经取得了显著的成果,但仍有进一步的优化空间。例如,我们可以探索更高效的候选词采样策略,以减少候选词之间的冲突。此外,我们还可以研究如何进一步减少通信开销,以及如何将我们的方法应用于更大规模的模型和更复杂的任务。
总之,多候选推测解码方法通过有效利用并行计算资源,显著提高了大型自回归语言模型的解码效率,同时保持了生成文本的质量。未来的研究将继续探索这一方法的潜力,以实现更快、更高效的语言模型服务。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」 智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人
神奇口令: 小瑶读者 (前100位有效)
相关文章:

2024年1月16日Arxiv热门NLP大模型论文:Multi-Candidate Speculative Decoding
大幅提速NLP任务,无需牺牲准确性!南京大学提出新算法,大幅提升AI文本生成效率飞跃 引言:探索大型语言模型的高效文本生成 在自然语言处理(NLP)的领域中,大型语言模型(LLMs…...

AI对决:ChatGPT与文心一言的比较
文章目录 引言ChatGPT与文心一言的比较Chatgpt的看法文心一言的看法Copilot的观点chatgpt4.0的回答 模型的自我评价自我评价 ChatGPT的优势在这里插入图片描述 文心一言的优势AI技术发展趋势总结 引言 在过去的几年里,人工智能(AI)技术取得了…...

uni-app引用矢量库图标
矢量库引用 导入黑色图标 1.生成连接,下载样式 2.导入项目(字体样式) 3.引入css样式 4.替换font-face 5.使用图标(字体图标,只有黑色) 导入彩色图标 1.安装插件 npm install -g iconfont-tools2.…...

Android的setContentView流程
一.Activity里面的mWindow是啥 在ActivityThread的performLaunchActivity方法里面: private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {ActivityInfo aInfo r.activityInfo;if (r.packageInfo null) {r.packageInfo getP…...

【加速排坑】docker设置国内image镜像源
第零步,查看阿里最新的镜像源:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors 第一步:在/etc/docker/daemon.json中添加镜像源 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-EOF {"registry-m…...

el-table嵌套两层el-dropdown-menu导致样式错乱
问题: 解决方式: <el-table-column label"操作" fixed"right" width"132" align"center"><template slot-scope"scope"><div v-if"scope.row._index ! 合计"><el-d…...
自动化测试:fixture学得好,Pytest测试框架用到老
在pytest中,fixture是一种非常有用的特性,它允许我们在测试函数中注入数据或状态,以便进行测试。而参数化则是fixture的一个特性,它允许我们将不同的数据传递给fixture,从而进行多次测试。 本文将介绍如何在pytest中使…...

Linux上常用网络操作
主机名配置 hostname 查看主机名 hostname xxx 修改主机名 重启后无效 如果想要永久生效,可以修改/etc/sysconfig/network文件 IP地址配置 ifconfig 查看(修改)ip地址(重启后无效) ifconfig eth0 192.168.12.22 修改ip地址 如果想要永久生效,修改 /etc/sysco…...
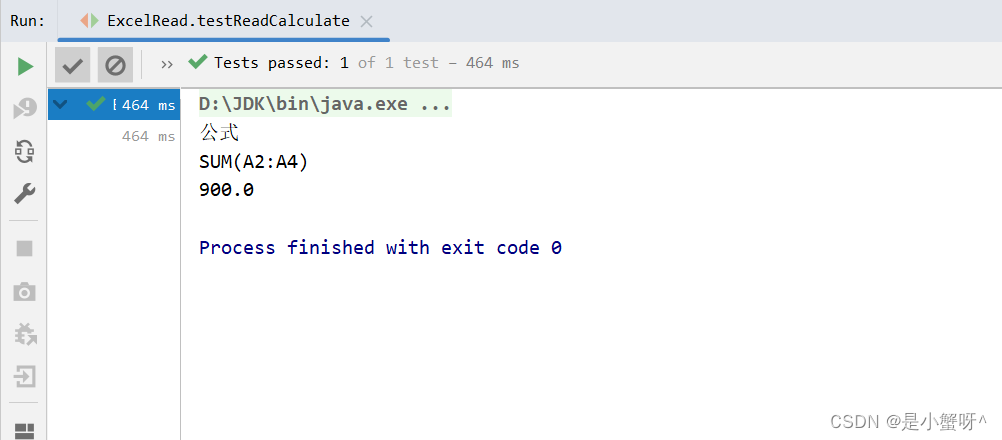
POI:对Excel的基本读操作 整理2
1 简单读取操作 public class ExcelRead {String PATH "D:\\Idea-projects\\POI\\POI_projects";// 读取的一系列方法// ...... } 因为07版本和03版本操作流程大差不差,所以这边就以03版本为例 Testpublic void testRead03() throws IOException {//获取…...

LeetCode每周五题_2024/01/15~01/19
文章目录 82. 删除排序链表中的重复元素 II题目题解 2744. 最大字符串配对数目题目题解 82. 删除排序链表中的重复元素 II 82. 删除排序链表中的重复元素 II 题目 给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字…...

免费chartGPT网站汇总
https://s.suolj.com - (支持文心、科大讯飞、智谱等国内大语言模型,Midjourney绘画、语音对讲、聊天插件)国内可以直连,响应速度很快 很稳定 https://seboai.github.io - 国内可以直连,响应速度很快 很稳定 http://gp…...
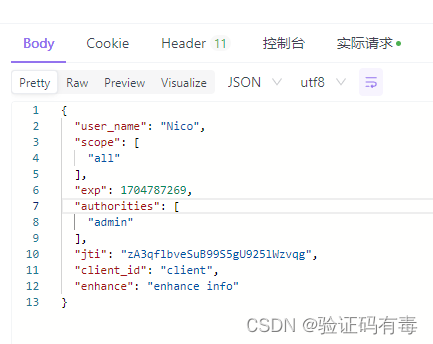
【分布式微服务专题】SpringSecurity OAuth2快速入门
目录 前言阅读对象阅读导航前置知识笔记正文一、OAuth2 介绍1.1 使用场景*1.2 基本概念(角色)1.3 优缺点 二、OAuth2的设计思路2.1 客户端授权模式2.1.0 基本参数说明2.1.1 授权码模式2.1.2 简化(隐式)模式2.1.3 密码模式2.1.4 客…...

Spring Boot实现国际化
src\main\resources\i18n\messages_zh_CN.properties message.hello你好,世界! message.welcome欢迎! src/main/resources/i18n/messages_en_US.properties message.helloHello World! message.welcomeWelcome! 默认语言 src\main\resources\…...

面试题之ElasticSearch
面试题之ElasticSearch 1.es的基础知识2. es的集群、节点、分片、副本分片的定义?3. es为什么快?4. 倒排索引的原理是什么?5. es的segment是什么?6. es的分段存储和分段索引的概念及区别?7. 索引相关的问题?…...
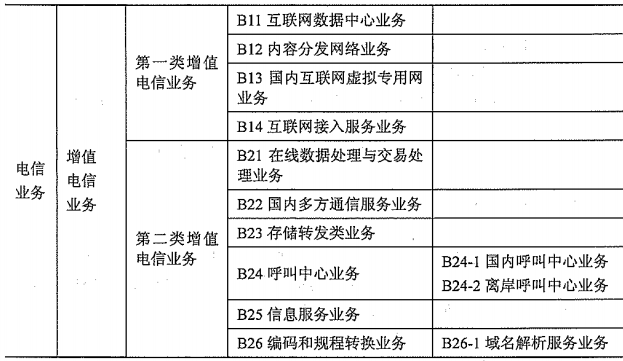
第10章 通信业务
文章目录 10.1.1 通信行业1、通信行业的界定2、通信行业的特点 10.1.2 通信企业10.1.3 通信终端1、通信终端的分类2、终端发展趋势 10.2.1 通信业务的定义及分类10.2.2 基础电信业务1、第一类基础电信业务A11 固定通信业务A12 蜂窝移动通信业务A13 第一类卫星通信业务A14 第一类…...

c++ 指针的安全问题
指针是一个强大的工具,但它们可能导致多种安全问题。接下来我们一起研究一下会出现的安全问题。欢迎大家补充说明!!! 悬挂指针(也称为悬空指针或迷途指针) 是指向一块已经释放或无效内存的指针。悬挂指针…...

高质量训练数据助力大语言模型摆脱数据困境 | 景联文科技
目前,大语言模型的发展已经取得了显著的成果,如OpenAI的GPT系列模型、谷歌的BERT模型、百度的文心一言模型等。这些模型在文本生成、问答系统、对话生成、情感分析、摘要生成等方面都表现出了强大的能力,为自然语言处理领域带来了新的突破。 …...

elasticsearch查询
(1)简单查询 curl -XGET http://127.0.0.1:9201/_search curl -XGET http://127.0.0.1:9201/test231208/_search curl -XGET http://127.0.0.1:9201/test231208/_doc/_search curl -XGET http://127.0.0.1:9201/test231208/_doc/id (2&…...

Vue + JS + tauri 开发一个简单的PC端桌面应用程序
Vue JS tauri 开发一个简单的PC端桌面应用程序 文章目录 Vue JS tauri 开发一个简单的PC端桌面应用程序1. 环境准备1.1 安装 Microsoft Visual Studio C 生成工具[^2]1.2 安装 Rust[^3] 2. 使用 vite 打包工具创建一个 vue 应用2.1 使用Vite创建前端Vue项目2.2 更改Vite打包…...

7.5 MySQL对数据的增改删操作(❤❤❤)
7.5 MySQL对数据的基本操作 1. 提要2. 数据添加2.1 insert语法2.2 insert 子查询2.3 ignore关键字 3. 数据修改3.1 update语句3.2 update表连接 4. 数据删除4.1 delete语句4.2 delete表连接4.3 快速删除数据表全部数据 1. 提要 2. 数据添加 2.1 insert语法 2.2 insert 子查询 …...

UVA12822 Extraordinarily large LED 题解
UVA12822 Extraordinarily large LED 题目描述 Link: https://uva.onlinejudge.org/index.php?optioncom_onlinejudge&Itemid8&category861&pageshow_problem&problem4687 PDF 输入格式 输出格式 输入输出样例 #1 输入 #1 START 09:00:00 SCORE 09:01:05…...

AI时代的“新文盲”:不会用提示词的技术人正在掉队
2026年的软件测试领域,正在经历一场前所未有的认知分化。这种分化不再是手工测试与自动化测试的界限,也不是代码能力的高低之别,而是在AI辅助工具全面渗透到测试工作流的今天,能否通过“提示词”(Prompt)精…...

CyberChef:浏览器端数据处理的模块化架构解析
CyberChef:浏览器端数据处理的模块化架构解析 【免费下载链接】CyberChef The Cyber Swiss Army Knife - a web app for encryption, encoding, compression and data analysis 项目地址: https://gitcode.com/GitHub_Trending/cy/CyberChef CyberChef 是一款…...

AI——LangChain 三大核心概念
LangChain 三大核心概念一、LangChain 三大核心概念1. 提示词模板 PromptTemplate2. 模型调用 ChatOpenAI / ChatZhipuAI3. 链 Chain二、完整可运行代码(带角色设定)功能三、如果你想用 **智谱 GLM**四、总结一、LangChain 三大核心概念 1. 提示词模板 …...

Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案
Source Sans 3:让数字界面阅读体验焕然一新的开源字体解决方案 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans 你是否曾经在设计网页或应用时,…...

全栈开发的核心技能:掌握这4个技术,成为全栈工程师
对于很多深耕测试领域多年的软件测试从业者来说,“转全栈开发”早已不是一个陌生的方向——无论是为了突破职业瓶颈,还是为了打通测试到开发的链路,提升自己的端到端交付能力,抑或是拓展职业选择的边界,全栈工程师都是…...
)
非科班本科,3年从零基础到AI工程师,我的真实转行之路(附避坑指南)
大家好,我是一名普通的非科班本科生,专业是机械制造及自动化,如今已经在AI行业深耕3年,成为了一名能独当一面的AI工程师,还参与过OpenClaw、DeerFlow等国际开源项目,算是真正从“AI小白”逆袭成了行业从业者。 写这篇文章,不是为了炫耀,而是因为我太懂那种“想转行AI却…...

【ElevenLabs云南话语音落地实战】:20年语音AI专家亲授3步适配方言模型,避开92%开发者踩过的声学对齐陷阱
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs云南话语音落地实战导论 云南话作为西南官话的重要分支,具有声调丰富、语流连贯、地域变体多样等特点,为语音合成技术带来独特挑战。ElevenLabs 提供的多语言、高保真…...

ArcGIS Pro 基础:县级人口图斑分级设色显示
首先确定图斑数据和属性数据,如下:对图层名称进行修改。右键图层属性,对常规里的名称进行修改。右键图层,打开【符号系统】。【主符号系统】选择【分级色彩】;【归一化】选择【无】;【方法】选择【自然间断…...

医用超声图像灰阶图算法:原理、实现与应用
引言 医用超声成像作为一种无创、实时、无辐射的影像学检查手段,在临床诊断中扮演着至关重要的角色。超声设备采集到的原始信号是射频(RF)信号,而最终呈现在医生面前的,是经过一系列复杂算法处理后的灰阶图像(B-mode图像)。灰阶图算法正是将原始超声回波信号转换为可视…...