MySQL-多表连接查询

🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
✨博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注! ❤️

目录
📣多表查询
📣多表查询概述
📣笛卡尔积
📣如何消除无效的笛卡尔积
📣分类
📣内连接
📣外连接
📣自连接
📣总结
📣多表查询
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结 构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
✨一对多 (多对一)
✨多对多
✨一对一
一对多
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 通常在多的一方建立外键,关联一的一方的主键 (左边为n,右边为1)

多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 维护多对多的关系,需要建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

可以由下表看出,学生表和课程表是通过中间表取得关联

准备脚本:
create table student(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',no varchar(10) comment '学号'
) comment '学生表';insert into student values (null, '沈立聪', '2106030322'),(null, '李佳成', '2106030101'),(null, '陈治辉', '2106030407'),(null, '刘小金', '2106030608');create table course(id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';insert into course values (null, 'math'), (null, 'chinese'), (null , 'english') , (null, 'good');create table student_course(id int auto_increment comment '主键' primary key,studentid int not null comment '学生ID',courseid int not null comment '课程ID',constraint fk_courseid foreign key (courseid) references course (id),constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2), (null,2,3),(null,3,4);
一对一
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 如何维护一对一的关系?在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE),从而保证我们一条记录,只能对应一个用户的基本信息
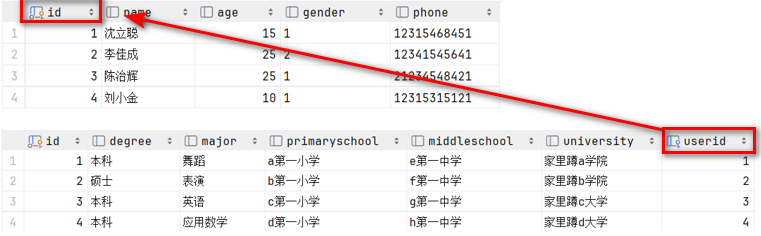
准备脚本
create table tb_user(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '1: 男 , 2: 女',phone char(11) comment '手机号'
) comment '用户基本信息表';create table tb_user_edu(id int auto_increment primary key comment '主键ID',degree varchar(20) comment '学历',major varchar(50) comment '专业',primaryschool varchar(50) comment '小学',middleschool varchar(50) comment '中学',university varchar(50) comment '大学',userid int unique comment '用户ID',constraint fk_userid foreign key (userid) references tb_user(id)
) comment '用户教育信息表';insert into tb_user(id, name, age, gender, phone) values
(null,'沈立聪',15,'1','12315468451'),
(null,'李佳成',25,'2','12341545641'),
(null,'陈治辉',25,'1','21234548421'),
(null,'刘小金',10,'1','12315315121');insert into tb_user_edu(id, degree, major, primaryschool, middleschool, university, userid) values
(null,'本科','舞蹈','a第一小学','e第一中学','家里蹲a学院',1),
(null,'硕士','表演','b第一小学','f第一中学','家里蹲b学院',2),
(null,'本科','英语','c第一小学','g第一中学','家里蹲c大学',3),
(null,'本科','应用数学','d第一小学','h第一中学','家里蹲d大学',4);
📣多表查询概述
概念:多表查询就是指从多张表中查询数据
删除之前 empcp, dept表的测试数据
执行如下脚本,创建empcp表与dept表并插入测试数据
-- 创建dept表,并插入数据
create table dept(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '部门名称'
)comment '部门表';INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'), (6, '人事部');-- 创建empcp表,并插入数据
create table empcp(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '姓名',age int comment '年龄',job varchar(20) comment '职位',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment '直属领导ID',dept_id int comment '部门ID'
)comment '员工表';-- 添加外键
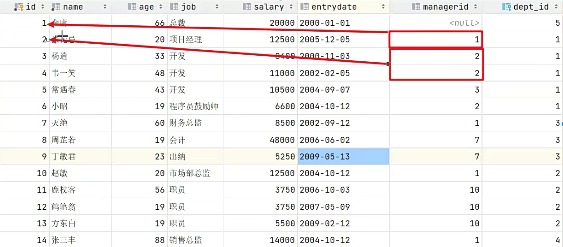
alter table empcp add constraint fk_empcp_dept_id foreign key (dept_id) references dept(id);INSERT INTO empcp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES
(1, 'a', 66, '总裁',20000, '2000-01-01', null,5),
(2, 'b', 20, '项目经理',12500, '2005-12-05', 1,1),
(3, 'c', 33, '开发', 8400,'2000-11-03', 2,1),
(4, 'd', 48, '开发',11000, '2002-02-05', 2,1),
(5, 'e', 43, '开发',10500, '2004-09-07', 3,1),
(6, 'f', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),
(7, 'g', 60, '财务总监',8500, '2002-09-12', 1,3),
(8, 'h', 19, '会计',48000, '2006-06-02', 7,3),
(9, 'i', 23, '出纳',5250, '2009-05-13', 7,3),
(10, 'j', 20, '市场部总监',12500, '2004-10-12', 1,2),
(11, 'k', 56, '职员',3750, '2006-10-03', 10,2),
(12, 'l', 19, '职员',3750, '2007-05-09', 10,2),
(13, 'm', 19, '职员',5500, '2009-02-12', 10,2),
(14, 'n', 88, '销售总监',14000, '2004-10-12', 1,4),
(15, 'o', 38, '销售',4600, '2004-10-12', 14,4),
(16, 'p', 40, '销售',4600, '2004-10-12', 14,4),
(17, 'q', 42, null,2000, '2011-10-12', 1,null);
执行:
原来查询单表数据,执行的SQL形式为:select * from empcp;
那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,代码如下
select * from empcp , dept ;
执行:

此时,我们看到查询结果中包含了大量的结果集,总共102条记录,而这其实就是员工表emp所有的记录
17条与部门表dept所有记录6条的所有组合情况,这种现象称之为笛卡尔积。接下来,就来简单介绍下笛卡尔积。
📣笛卡尔积
笛卡尔积: 笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。
举个例子:
集合A={a,b}, B={0,1,2},笛卡尔积结果为:
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
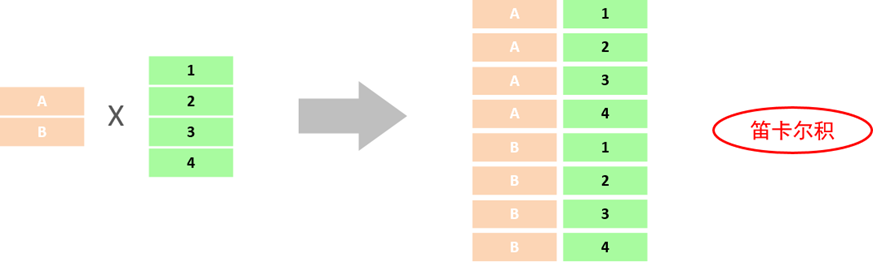
而在多表查询中,我们是需要消除无效的笛卡尔积的,只保留两张表关联部分的数据。

如图我们只需要dept_id与dept.id相同的数据,即 dept_id = dept.id,其他对应关系不需要

📣如何消除无效的笛卡尔积
给多表查询加上连接查询条件就可以解决了
select * from empcp , dept where empcp.dept_id = dept.id;
此时可以发现无效的笛卡尔积被清除了,但是我们有17个人,按逻辑应该有17条数据,那么第17条数据呢?
实际上我们仔细观察到,第17条数据没有dept_id字段,所以在多表查询时,根据连接查询的条件并没有查询到![]()
📣分类
连接查询
✨内连接:相当于查询A、B交集部分数据
✨外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据
右外连接:查询右表所有数据,以及两张表交集部分数据
✨自连接:当前表与自身的连接查询,自连接必须使用表别名
子查询
📣内连接

查询两张表之间交集的数据(也就是绿色部分的数据)
内连接的语法分为两种:
✨隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;✨显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;案例:
查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: empcp , dept
连接条件: empcp.dept_id = dept.id (其实这个连接条件就是用于消除无效的笛卡尔积的那个外键)
这里empcp.name,dept.name,前面加上表名,是通过表名来限定,是哪一个表的哪个字段
这里查询出来依旧是16条,因为有一个人是没有部门的,也就不属于两张表的交集部分,所以这条数据查询不到
select empcp.name 员工姓名 , dept.name 部门名 from empcp , dept where empcp.dept_id = dept.id ; 有时如果表名比较长,取名比较繁琐,我们就会起别名,通常在多表查询中我们都会起别名
注意:我们一旦给表起了别名之后,我们还能不能通过表名来限定字段,不可以,如果我们为表起了别名,此时我们就不能再通过表名来限定字段,此时只能够使用别名来指定字段。
因为对于DQL语句执行顺序,先执行的是from,执行完from,这表就已经起名为别名了,我们只能去使用别名了
select e.name , d.name from emp e , dept d where e.dept_id = d.id ;执行:
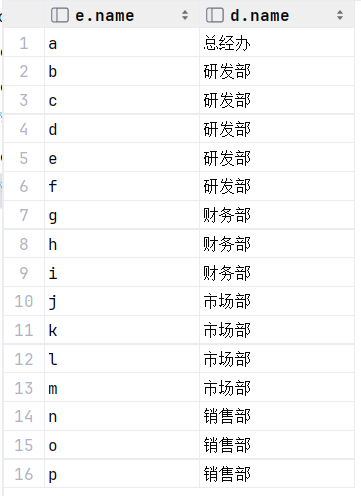
查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) --- INNER JOIN ... ON ...
表结构: empcp , dept
连接条件: empcp.dept_id = dept.id
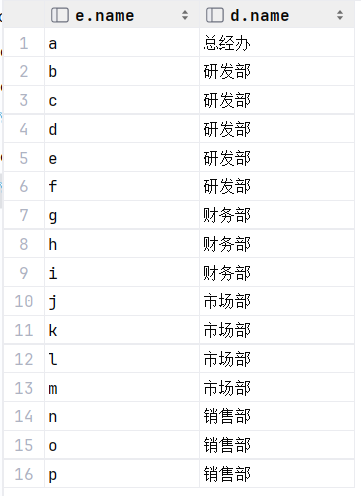
select e.name, d.name from empcp e inner join dept d on e.dept_id = d.id; -- 为每一张表起别名,简化SQL编写select e.name, d.name from empcp e join dept d on e.dept_id = d.id; --在显示内连接中inner关键字可以省略
表的别名:
①. tablea as 别名1 , tableb as 别名2 ;
②. tablea 别名1 , tableb 别名2 ;
📣外连接
外连接分为两种,分别是:左外连接 和 右外连接。
左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ; --outer可有可无右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
案例:
查询empcp表的所有数据, 和对应的部门信息
由于需求中提到,要查询empcp的所有数据,因为内连接有一条数据查询不出来,17号它没有关联的数据,所以查询不出来,要查到所有数据是不能用内连接查询的,需要考虑使用外连接查询。
表结构: empcp, dept
连接条件: empcp.dept_id = dept.id (empcp表的外键关联dept表的主键)
select e.*, d.name from empcp e left outer join dept d on e.dept_id = d.id; select e.*, d.name from empcp e left join dept d on e.dept_id = d.id;
执行:

17条记录,第17条即使没有部门id,依然查询出,因为左外连接会完全包含左表数据
查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查 询。
表结构: empcp, dept
连接条件: empcp.dept_id = dept.id
select d.*, e.* from empcp e right outer join dept d on e.dept_id = d.id; select d.*, e.* from dept d left outer join empcp e on e.dept_id = d.id;
--此时左外会完全包含左表的数据,此时左表不就是dept表嘛,这就是左右外连接互换
执行:

人事部没有数据,依然可以查询出,因为右外连接会把表2的数据全部显示,右外连接完全包含右表
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺 序就可以了。而我们在日常开发使用时,更偏向于左外连接。
📣自连接
自己连接自己,也就是把一张表连接查询多次
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条 件 ... ;自连接查询,可以是内连接查询,也可以是外连接查询,可以是左外,也可以是右外。
案例:
查询员工及其所属领导的名字
表结构: empcp
员工表是empcp这个我们知道,但是这个里面要查询的是所属领导的名字,在empcp中并没有去记录直属领导的是谁?但是empcp表中有一个字段managerid,指的就是所属领导的id,在企业中,领导是不是也是员工,所以这个managerid指代的就是当前表的主键,员工的id
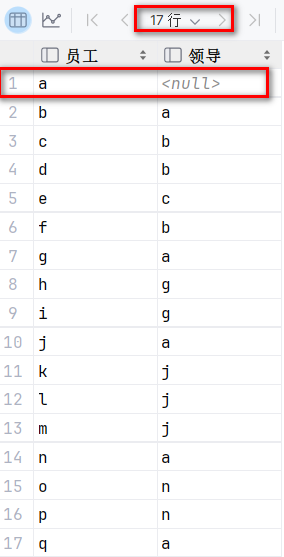
例如这样的关系
id为1的managerid为null,说明他没有直属领导
id为2的人是id为3和4的直属领导,因为id3和4的人的managerid是2
此时涉及到的表结构只有一张表empcp表,所以我们的思路肯定是去查询empcp表,但是我们的单表查询是完不成这项问题的,我们要通过多表查询,连接empcp表两次,运用自连接
也就是把一张表看成两张表,一张员工表,一张领导表,用员工表的managerid关联领导表的id

select a.name as '员工' , b.name as '领导' from empcp a , empcp b where a.managerid = b.id;执行:

查询所有员工 empcp表 及其领导的名字 empcp表 , 如果员工没有领导, 也需要查询出来
表结构: empcp a , empcp b
员工没有领导也要查询,意思就是这个员工的managerid是null我们也要把他查询出来,此时要用到外连接,因为内连接只查询两张表交集的部分,外连接才会完全包含左表或右表的数据,这里我们使用左外,一定一定看成两张表去做,a表是员工表,b表是领导表
select a.name '员工', b.name '领导' from empcp a left join empcp b on a.managerid = b.id;注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段,谁的managerid=谁的id?对吧。
执行:
📣总结
谢谢你这么好看还来看我!
相关文章:
MySQL-多表连接查询
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:重拾MySQL 🍹文章作者技术和水平很有限,如果文中出现错误&am…...

Qt第二周周二作业
代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr);~Widget();void paintEvent(…...

docker 学习命令整理
文章目录 docker 学习命令整理(积累中...)0. 启动/停止1. 运行2. 查看运行中docker3. 删除指定container4. 查看本地镜像5. 拉取指定镜像6. 新起终端进入同一container7. 取消sudo8. 查看docker状态9. 查看docker存储10.删除镜像11.删除容器12. qemu12.1 安装12.2 卸载qemu 附&…...
windows安装RabbitMq,修改数据保存位置
1、先安装Erlang, Erlang和RabbitMQ有版本对应关系。 官网RabbitMQ与Erlang版本对应RabbitMQ Erlang Version Requirements — RabbitMQ 2、安装RabbitMQ。 3、修改数据保存地址。找到安装目录下的sbin文件夹,找到rabbitmq-env.bat,编辑文件…...

Redis面试题18
Redis 支持集群模式吗?如何实现 Redis 的集群? 答:是的,Redis 支持集群模式,并提供了 Redis Cluster 来实现分布式数据存储和高可用性。 Redis Cluster 是通过将数据分散到多个节点上来实现的,每个节点都拥…...

python实现文件批量分发
在Python中实现文件的批量分发通常涉及到文件的读取、网络通信以及目标系统上的文件写入。这里有几种方法来实现这一功能,但最常见的方法之一是使用FTP(文件传输协议)或SSH(安全外壳协议)。以下是使用Python通过SSH进行文件批量分发的一个基本示例。这里使用了paramiko库,…...
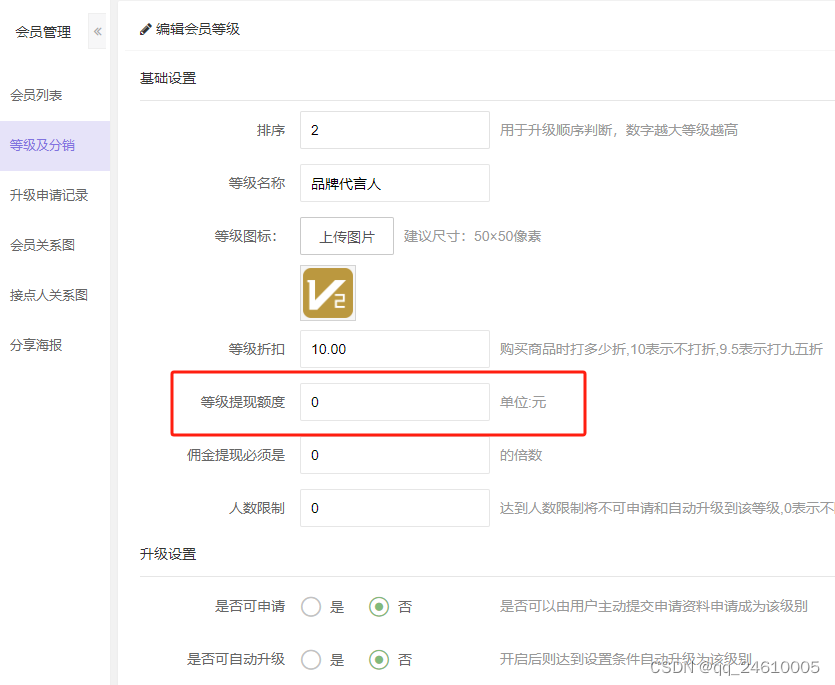
分销商城多端uniapp 可编译5端 - 等级提现额度
等级提现额度 等级提现额度是一种常见的财务管理策略,通常用于在线平台、金融服务或游戏中,用于控制不同等级用户的提现限额。这样的机制有助于平台管理资金流动性,防范欺诈,并鼓励用户提升他们的活跃度或忠诚度。以下是一个简单的…...
)
蓝桥杯基础知识5 unique()
蓝桥杯基础知识5 unique() #include <bits/stdc.h>int main(){std::vector<int> vec {1,1,2,2,3,3,3,4,4,5};auto it std::unique(vec.begin(), vec.end());vec.erase(it, vec.end());//vec.erase(unique(vec.begin(),vec.end()),vec.end(…...

设计一个抽奖系统
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术🔥如果感觉博主的文章还不错的…...
IntelliJ IDEA使用学习
一、安装教程 网上自行下载,CSDN不然过审二、使用教程 2.1 快捷键操作与设置 设置 Setting——>按键映射——>选择顺手的系统快捷键 编写代码 CtrlShift Enter,语句完成。 “!”,否定完成,输入表达式时按 …...
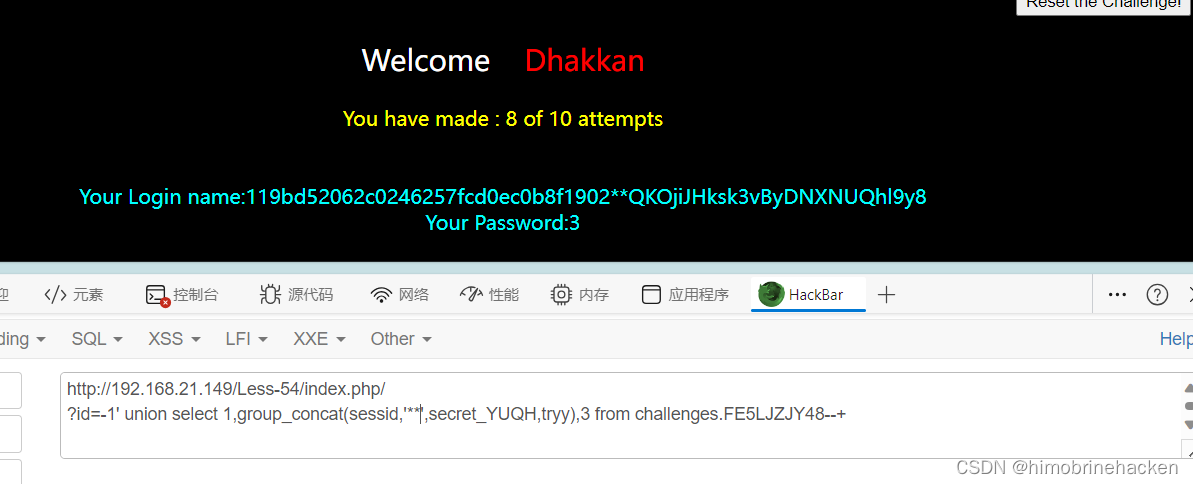
sqlilabs第五十三五十四关
Less-53(GET - GET - Error based - ORDER BY CLAUSE-String- Stacked injection) 手工注入 单引号闭合,和上一关一样堆叠注入解决 自动注入 和上一关一样 Less-54(GET - challenge - Union- 10 queries allowed -Variation 1) 手工注入 这一关开始后面的可以看…...
❤ Uniapp使用三( 打包和发布上线)
❤ Uniapp使用三( 打包和发布上线) 一、介绍 什么是 uniapp? uniapp 是一种基于 Vue.js 的多平台开发框架,它可以同时用于开发安卓、iOS、H5 等多个平台。因此,只需要写一次代码就可以在多个平台上运行,提高了开发效率。 打包…...
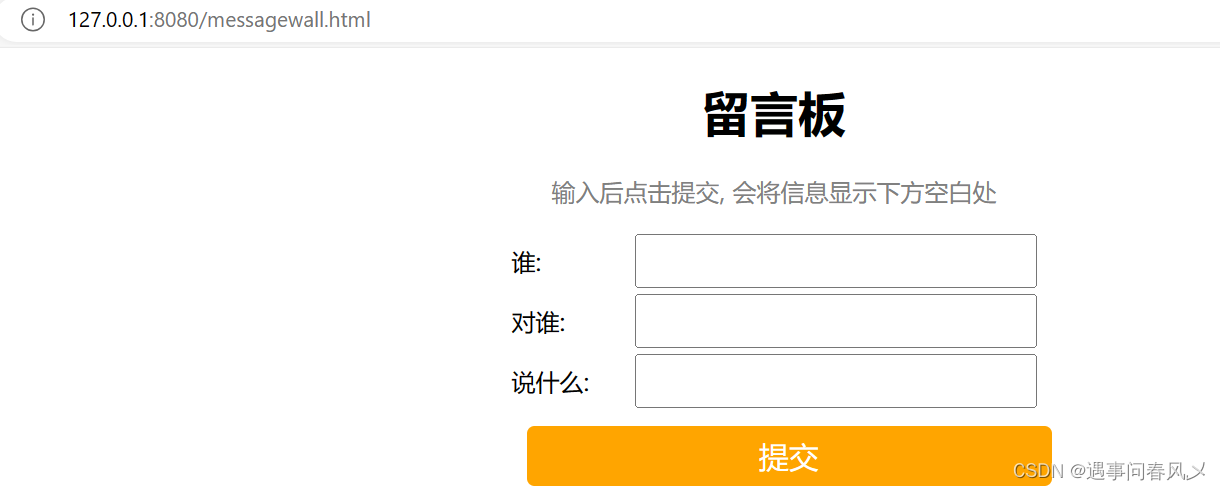
【JavaEEj进阶】 Spring实现留言板
文章目录 🎍预期结果🍀前端代码🎄约定前后端交互接⼝🚩需求分析🚩接⼝定义 🌳实现服务器端代码🚩lombok 🌲服务器代码实现🌴运⾏测试 🎍预期结果 可以发布并…...
react、Vue打包直接运行index.html不空白方法
react vue 在根目录下创建 vue.config.js 文件,写入 module.exports {publicPath: ./, }...

SpringBoot-01
Spring Boot是一个开源的Java框架,用于快速构建独立的、可执行的、生产级的Spring应用程序。它基于Spring框架,简化了Spring应用程序的配置和部署过程,使开发者能够更快速地创建高效、可扩展的应用。 Spring Boot具有以下特点: 简…...

「解析」Jetson配置 git服务
这两天感冒了在家休养,想着把之前买的 Jetson 开发板用起来,买Jetson的初衷就是用来学习Linux系统,顺道可以部署算法,以及一些其他需求,相比树莓派而言,Jetson开发相对更贵,但是其配备了英伟达的…...
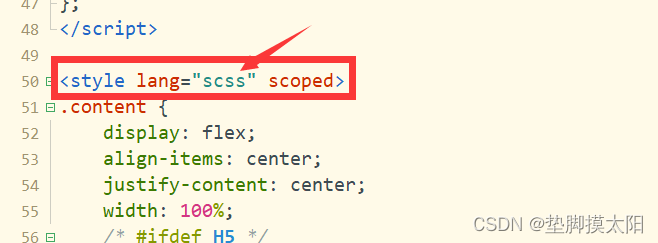
uniapp使用安装sass
1.首先你要安装node-sass npm install node-sass --save-dev2.安装sass-loader npm install sass-loader --save-dev3.修改style标签,声明使用sass <style lang"scss" scoped>...

ClickHouse学习笔记(六):ClickHouse物化视图使用
文章目录 1、ClickHouse 物化视图2、物化视图 vs 普通视图3、物化视图的优缺点4、物化视图的用法4.1、基本语法4.2、准备表结构4.3、准备数据4.3、查询结果 1、ClickHouse 物化视图 ClickHouse 的物化视图是一种查询结果的持久化,它的存在是为了带来查询效率的提升…...
)
华为OD机试真题-最小矩阵宽度-2023年OD统一考试(C卷)
题目描述: 给定一个矩阵,包含N*M个整数,和一个包含K个整数的数组。 现在要求在这个矩阵中找一个宽度最小的子矩阵,要求子矩阵包含数组中所有的整数。 输入描述: 第一行输入两个正整数N,M,表示矩阵大小。 接下来N行M列表示矩阵内容。 下一行包含一个正整数K。 下一行包含…...

java stream distinct根据list某个字段去重
项目场景: java stream distinct根据list某个字段去重,普通List简单去重: import java.util.Arrays; import java.util.List; import java.util.stream.Collectors;public class TestMain {public static void main(String[] args) {List&l…...

对比官方价Taotoken活动价在长期使用中的成本优势感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价,Taotoken活动价在长期使用中的成本优势感受 效果展示类,基于一段时间的实际使用数据࿰…...

B站视频下载终极方案:DownKyi全功能解析与高效使用指南
B站视频下载终极方案:DownKyi全功能解析与高效使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...
: 对象引用、可变性和垃圾回收 - Python深复制如何处理循环引用)
《流畅的Python》读书笔记07(补充02): 对象引用、可变性和垃圾回收 - Python深复制如何处理循环引用
在Python中,copy.deepcopy()处理自定义类中的循环引用时,主要通过备忘录(memo)机制和递归复制策略来避免无限递归,确保复制过程能正确完成。下面我将从算法原理、实现机制、应用场景和性能影响四个方面进行深度拆解。 …...

解决RTL8821CU无线网卡在Linux下的3大痛点:从识别到稳定连接的全攻略
解决RTL8821CU无线网卡在Linux下的3大痛点:从识别到稳定连接的全攻略 【免费下载链接】rtl8821CU Realtek RTL8811CU/RTL8821CU USB Wi-Fi adapter driver for Linux 项目地址: https://gitcode.com/gh_mirrors/rt/rtl8821CU 你是否曾经在Linux系统上连接RTL…...

终极QQ空间备份指南:用GetQzonehistory永久保存你的青春记忆
终极QQ空间备份指南:用GetQzonehistory永久保存你的青春记忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否也曾担心多年积累的QQ空间说说会随着时间消失?…...

信贷系统压测:用JMeter实现状态流并发与资金流仿真
1. 为什么信贷业务压测不能只跑个登录接口就交差?我第一次接手某城商行信贷系统压测时,信心满满地用JMeter搭了个500线程的“高并发”脚本,模拟用户登录查看额度。结果压测报告一出来,TPS稳定在320,平均响应时间180ms&…...

DataRoom:企业级数据可视化大屏设计器的架构创新与实践价值
DataRoom:企业级数据可视化大屏设计器的架构创新与实践价值 【免费下载链接】DataRoom 🔥基于SpringBoot、MyBatisPlus、ElementUI、G2Plot、Echarts等技术栈的大屏设计器,具备目录管理、DashBoard设计、预览能力,支持MySQL、Orac…...

easyPoi使用
一、核心定位区别 EasyPoi:全能型,支持 Excel、Word、PDF 导出,注解极简,适合小数据、快速开发EasyExcel:高性能型,只专注 Excel,主打低内存、大数据量,适合海量数据导出 二、Easy…...

Windows平台苹果USB网络共享驱动自动化部署方案
Windows平台苹果USB网络共享驱动自动化部署方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/gh_mirrors/ap/Apple-Mob…...

微信好友关系检测:如何发现那些悄悄离开的“单向好友“
微信好友关系检测:如何发现那些悄悄离开的"单向好友" 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFr…...