设计一个抽奖系统
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- 抽奖系统
- 需求概述
- 设计思路
- 总库表梳理
- 核心领域开发之抽奖领域
- 库表梳理
- 结构梳理
- 核心介绍
- 核心领域开发之发放奖品领域
- 结构梳理
- 核心领域开发之活动领域
- 流程梳理
- 结构梳理
- ID生成与分库分表
- 应用层编排
- 规则引擎设计
- MQ解耦发货流程
- 定时任务扫描
- 扫描库表补偿发货单MQ消息
- 分布式锁扣减
- 总体思路
- 优化思路
- 机器环境配置:
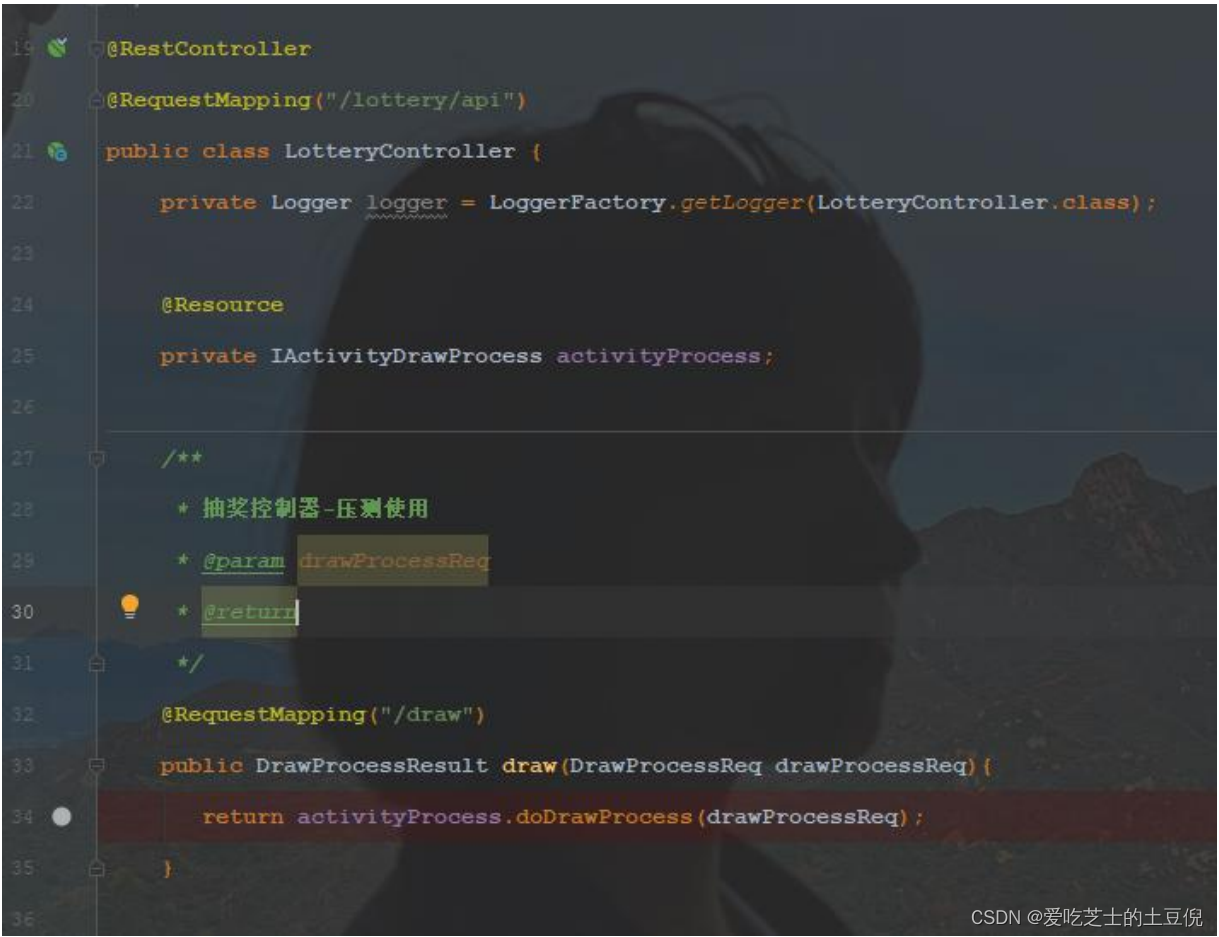
- 一、定义 REST 接口进行压测使用
- 二、Postmain 模拟调用
- 三、梯度压测
- 四、数据库连接异常
- 五、引入 Druid 数据源
- 六、分布式锁和抽奖的后续流程
- 七、添加索引
- 八、Arthas 分析接口响应时长并将查库操作存入 Redis
- 九、磁盘和网络带宽导致负载增加
- 十、增加 Tomcat 线程数
抽奖系统
需求概述
如果设计一个抽奖系统,如何设计一个高并发的秒杀系统?
这类项目在网上其实很多,但是实际的工作流到底是什么呢?难不成只有简单的数据库操作和逻辑判断吗?实际的工作流都有哪些呢?站在整体上来看都需要哪些呢?下面就以一个项目来讲解下都有什么?
设计思路
总库表梳理
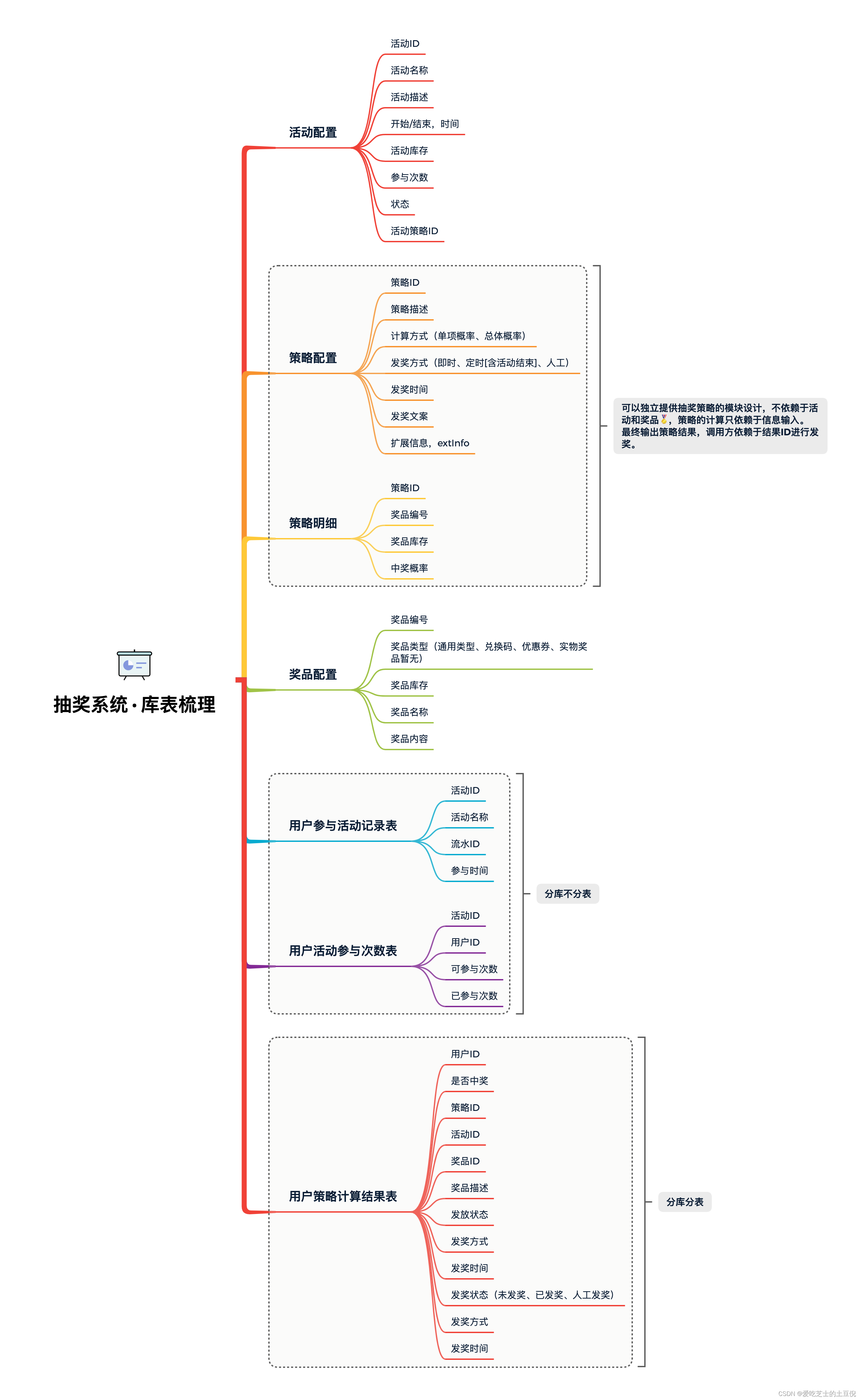
核心领域开发之抽奖领域
库表梳理

结构梳理
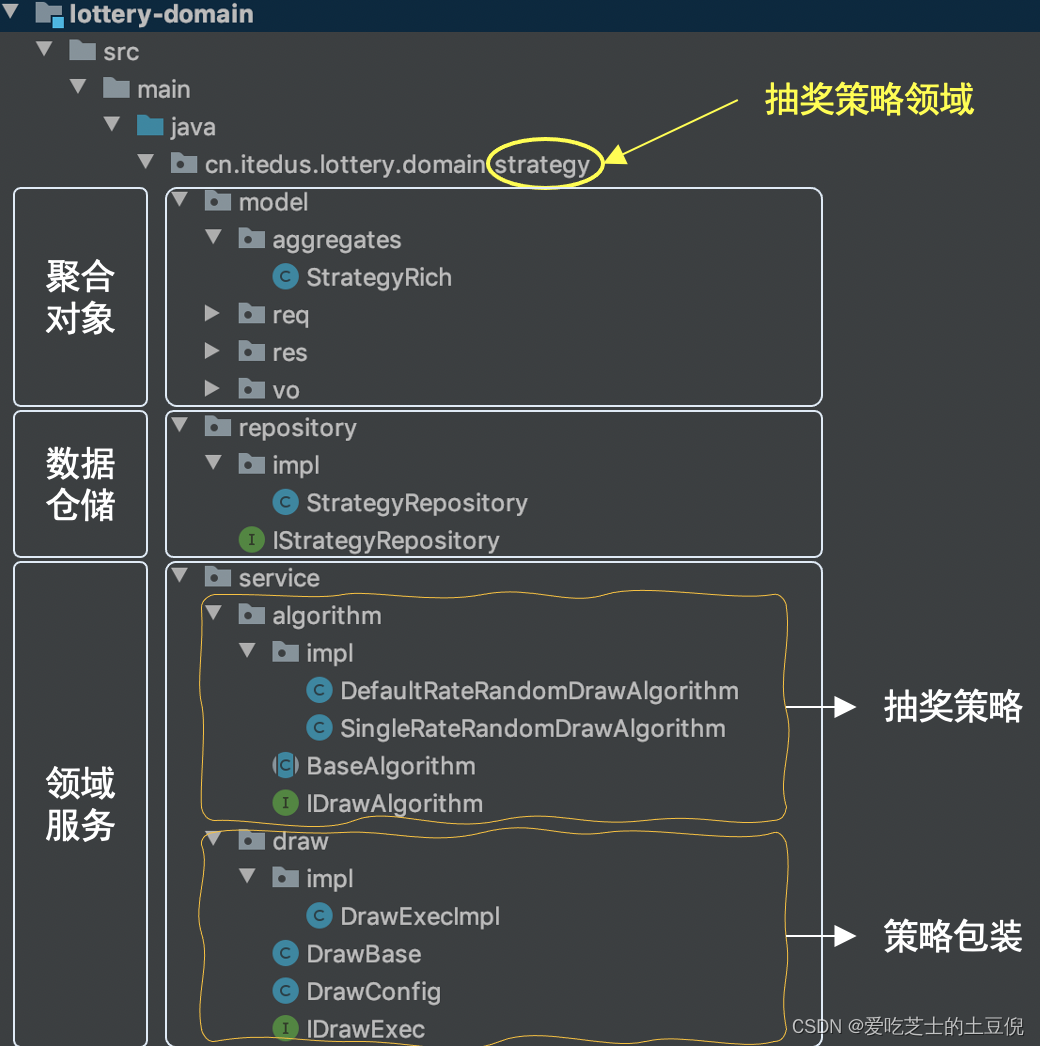
核心介绍
其实可以看到,该部分其实是DDD结构中的一个单独的领域,主要是用来走抽奖逻辑。那么实际上仅仅对于抽奖这件事来说,其实就是抽奖策略的设计。通过策略包装里面的doDraw方法选择合适的策略进行抽奖。那么核心流就是策略都有哪些?
实际上关于这方面的策略主要有 总体策略 和 单项策略。
单项策略就是说加入某个奖品抽完了,我们不需要重新计算概率,如果刚好抽到了没有的奖品,那么就相当于没抽到
而总体概率加入说没有商品了,需要重新计算现有商品的概率。
核心领域开发之发放奖品领域
这一步算的上是,抽出奖品后以什么样的规则进行发放了。
结构梳理
lottery-domain
└── src└── main└── java└── cn.itedus.lottery.domain.award├── model├── repository│ ├── impl│ │ └── AwardRepository│ └── IAwardRepository└── service├── factory│ ├── DistributionGoodsFactory.java│ └── GoodsConfig.java└── goods├── impl│ ├── CouponGoods.java│ ├── DescGoods.java│ ├── PhysicalGoods.java│ └── RedeemCodeGoods.java├── DistributionBase.java└── IDistributionGoodsc.java关于 award 发奖领域中主要的核心实现在于 service 中的两块功能逻辑实现,分别是:goods 商品处理、factory 工厂
goods:包装适配各类奖品的发放逻辑,虽然我们目前的抽奖系统仅是给用户返回一个中奖描述,但在实际的业务场景中,是真实的调用优惠券、兑换码、物流发货等操作,而这些内容经过封装后就可以在自己的商品类下实现了。
factory:工厂模式通过调用方提供发奖类型,返回对应的发奖服务。通过这样由具体的子类决定返回结果,并做相应的业务处理。从而不至于让领域层包装太多的频繁变化的业务属性,因为如果你的核心功能域是在做业务逻辑封装,就会就会变得非常庞大且混乱。
核心领域开发之活动领域
流程梳理
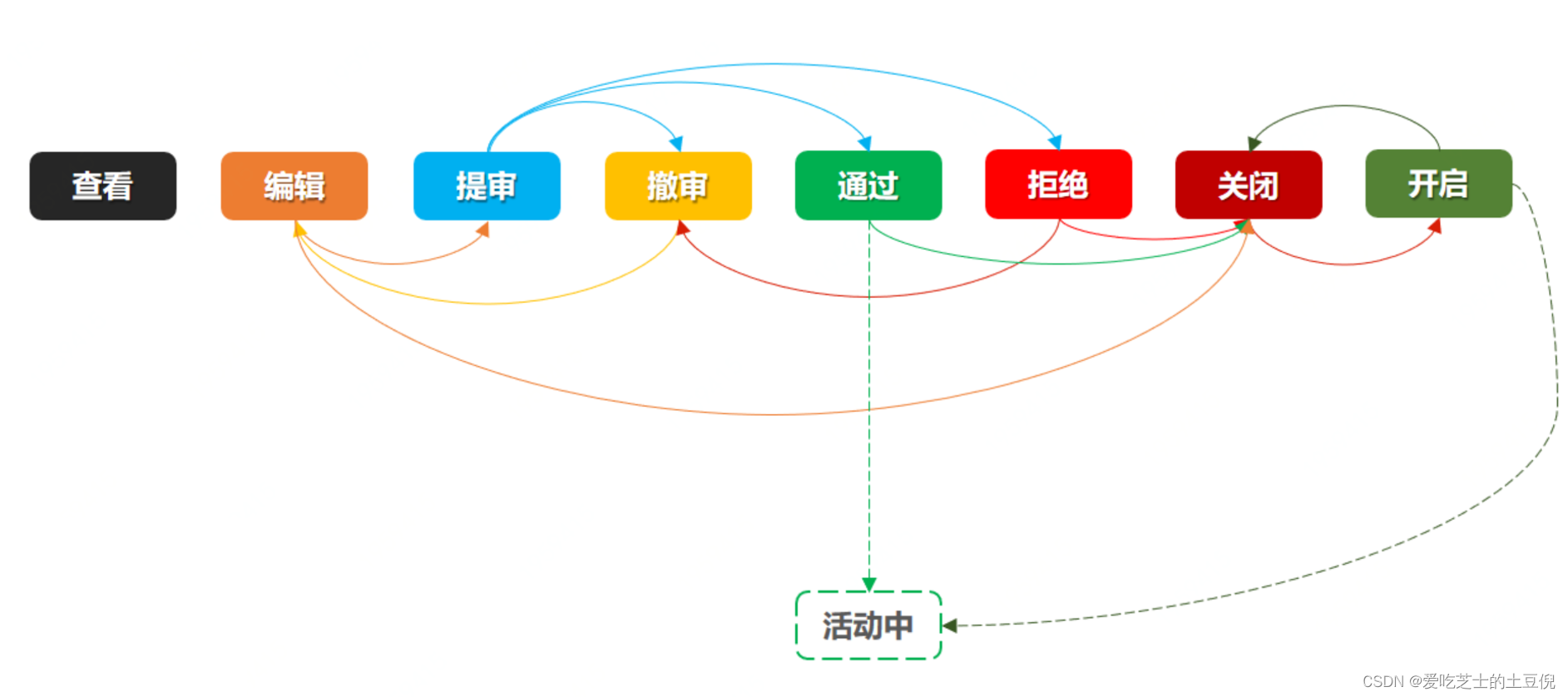
实际上活动的创建在实际的工作流中必须涉及到这些步骤,那么基于这些步骤就可以设计具体的代码结构
结构梳理
lottery-domain
└── src└── main└── java└── cn.itedus.lottery.domain.activity├── model├── repository│ └── IActivityRepository└── service├── deploy├── partake [待开发]└── stateflow├── event│ ├── ArraignmentState.java│ ├── CloseState.java│ ├── DoingState.java│ ├── EditingState.java│ ├── OpenState.java│ ├── PassState.java│ └── RefuseState.java├── impl│ └── StateHandlerImpl.java├── AbstractState.java├── IStateHandler.java└── StateConfig.javaID生成与分库分表
关于 ID 的生成因为有三种不同 ID 用于在不同的场景下;
- 订单号:唯一、大量、订单创建时使用、分库分表
- 活动号:唯一、少量、活动创建时使用、单库单表
- 策略号:唯一、少量、活动创建时使用、单库单表
所以针对订单号的这种情况,需要考虑分库分表的实现思路
综合来说具体的实现思路如下:设计一个简易版的数据库路由-CSDN博客
应用层编排
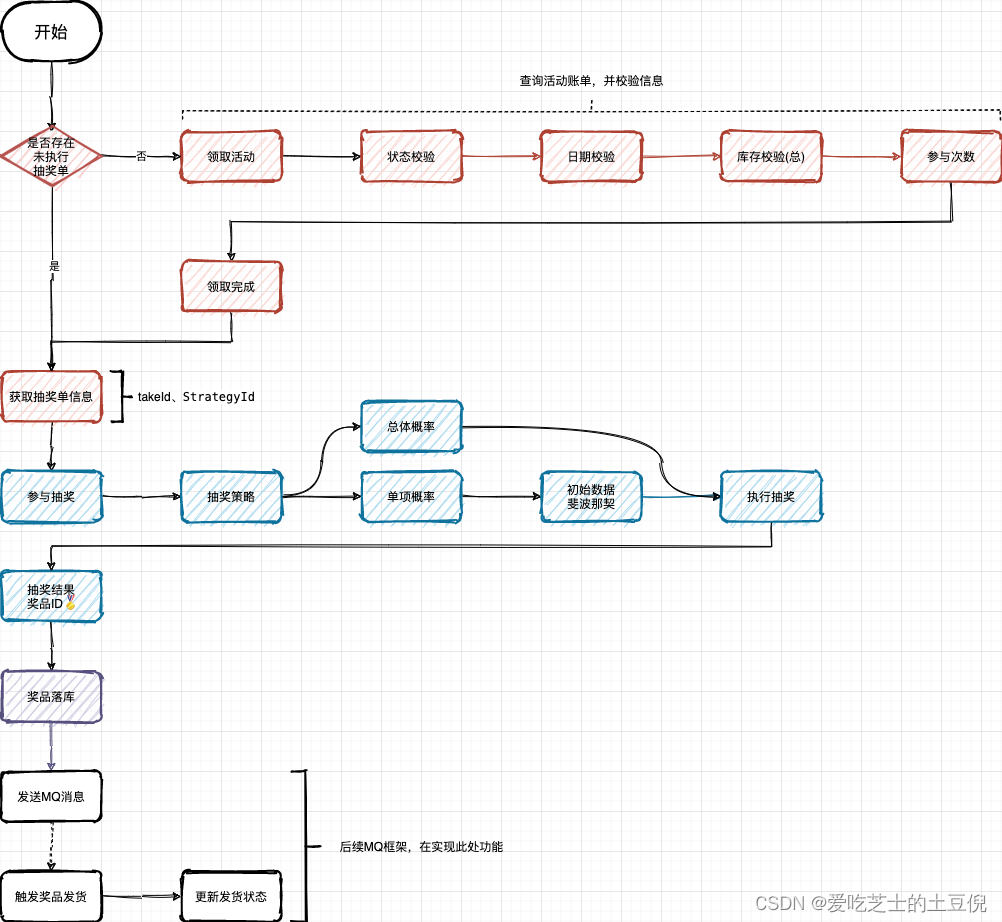
这个图其实就简单的将主题的思路都囊括出来了,当有了各种活动以后,需要对当前用户能否参与活动进行检验,如状态、日期、库存、参与次数等。然后进入抽奖部分,按照不同的策略进行抽奖,最终做到落库,在这里后续的设计打算使用MQ进行解耦分离。
规则引擎设计
应用层编排的设计的具体思路其实还是需要知道一开始的活动才行的,但是假如说活动有很多,怎么知道要参加什么活动呢?
所以需要一种规则引擎
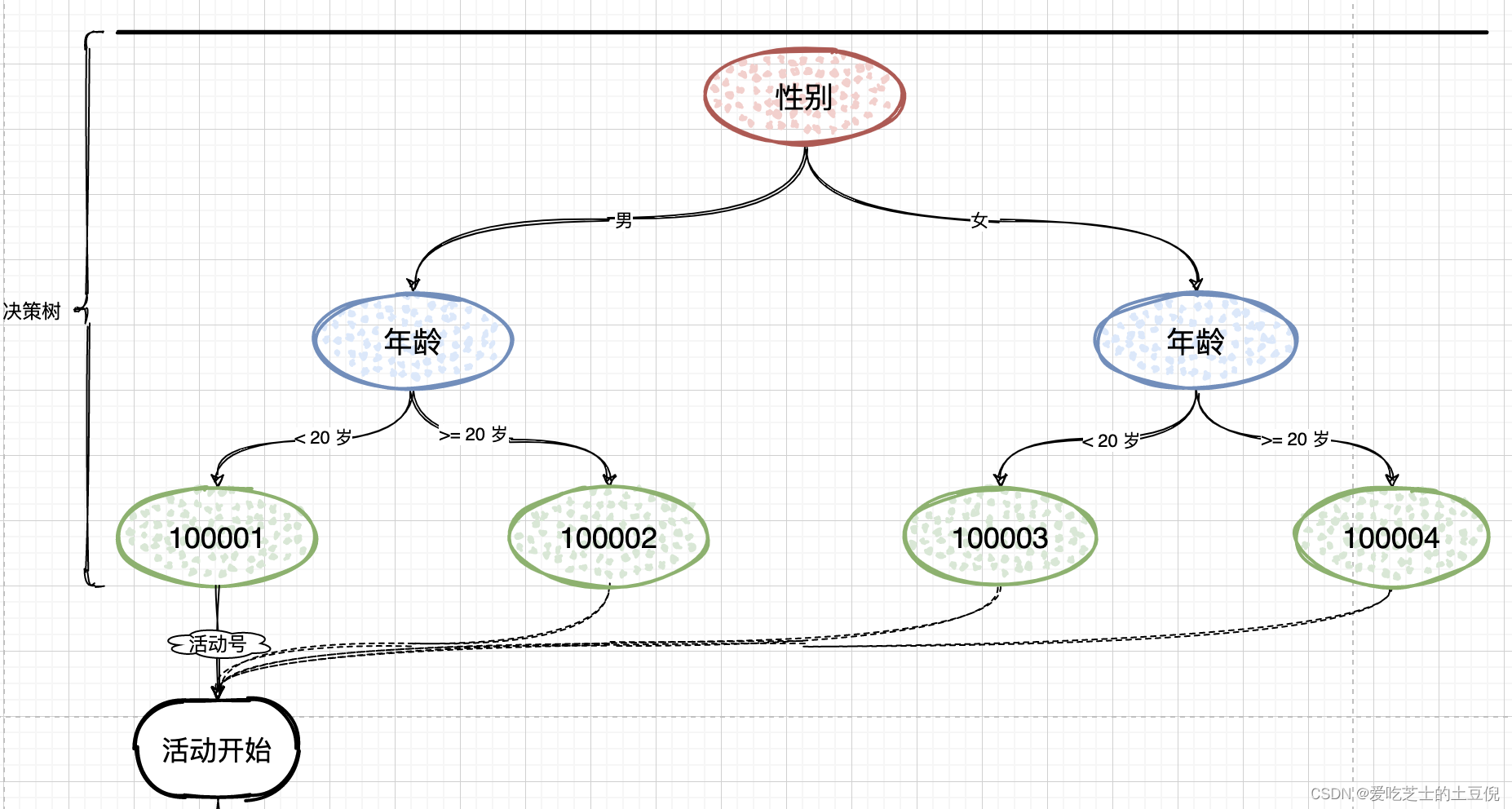
通过这种规则引擎的方式来选取不同的活动,然后在执行后续的逻辑。
MQ解耦发货流程
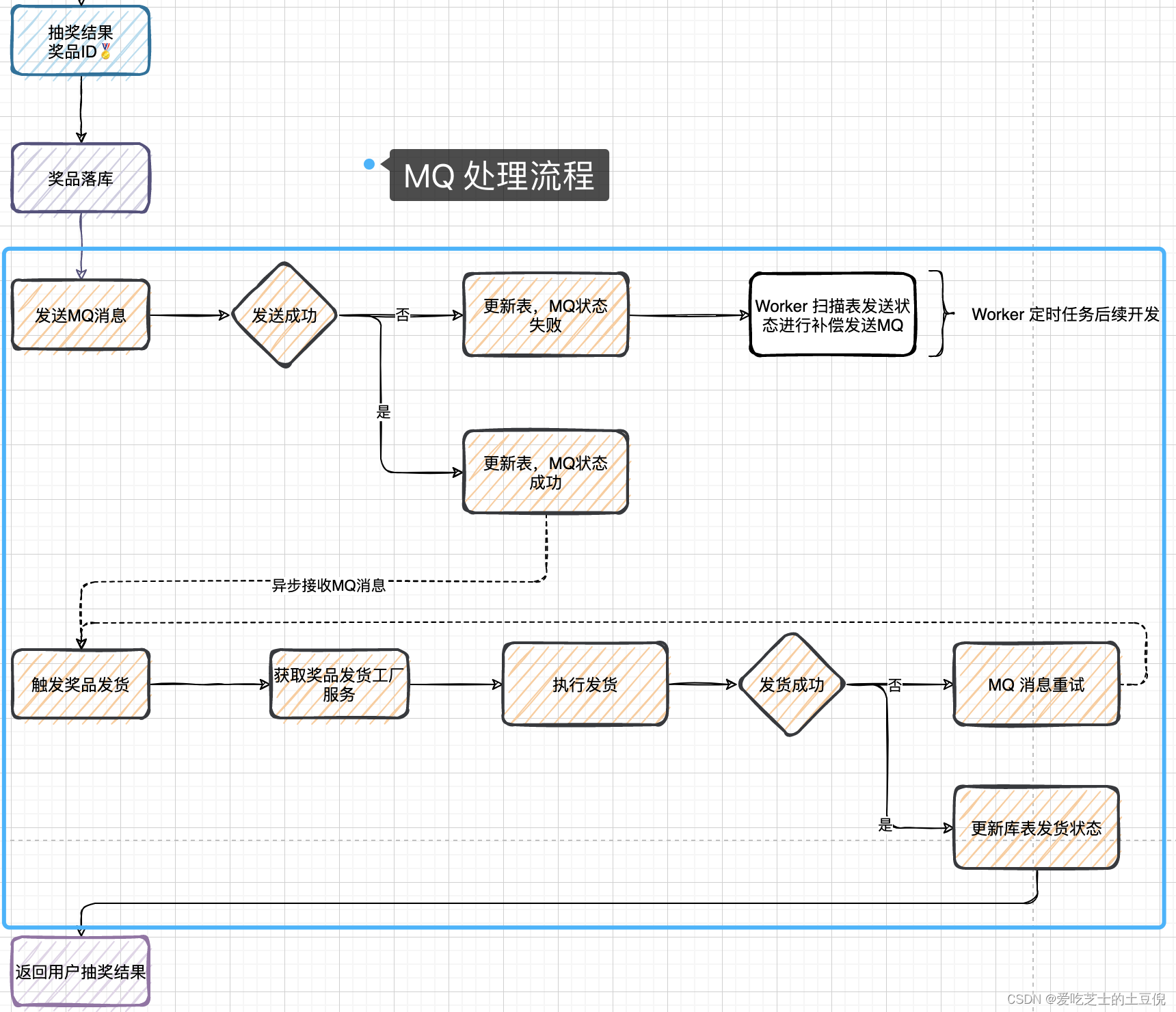
使用消息队列必须要考虑的是发送成功或者失败,以后重复消费的问题。
首先需要开启幂等。然后发送端如果发送失败的话,更新表,这个表中存储的是发送成功或者失败的状态。如果发送失败的话,将来需要使用定时任务进行回调,而图中下半部分的MQ是否消费成功,则是手动开启了消费确认。
定时任务扫描
按照上面说的,如果任务发送MQ失败了,需要用定时任务进行回调,就是使用这个,现在比较常见的有xxl-job,这里我们使用自研的一个:设计一个简易版本的分布式任务调度系统-CSDN博客
扫描库表补偿发货单MQ消息
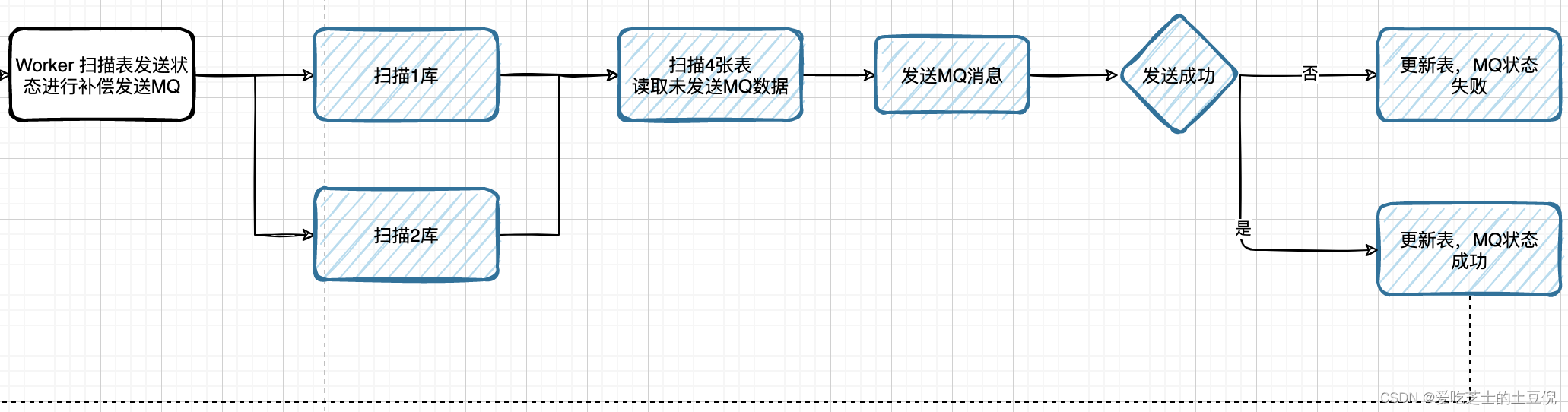
按照定时任务扫描,如果成功了就发送MQ,没有成功的话,就继续等待下一次定时任务扫描即可。
分布式锁扣减

- 在抽奖系统中引入 Redis 模块,优化用户参与抽奖活动。因为只要有大量的用户参与抽奖,那么这个就属于秒杀场景。所以需要使用 Redis 分布式锁的方式来处理集中化库存扣减的问题,否则在 TPS 达到1k-2k,就会把数据库拖垮。
- 在设计秒杀流程时,优化锁的颗粒度力度,不要把锁直接放到活动编号上,这样在极端临界情况下会出现秒杀解锁失败,导致库存有剩余但不能下单的情况。所以需要增加锁的颗粒度,以滑动库存剩余编号的方式进行加锁,例如 100001_1、100001_2、100001_3,以此类推,具体看代码实现。
- 增加缓存扣减库存后,发送 MQ 消息进行异步更新数据库中活动库存,做最终数据一致性处理。这一部分如果你的系统并发体量较大,还需要把 MQ 的数据不要直接对库更新,而是更新到缓存中,再由任务最阶段同步,以此减少对数据库表的操作
即使是使用 Redis 分布式锁,我们也不希望把锁的颗粒度放的太粗,否则还是会出现活动有库存但不能秒杀,提示“活动过于火爆”。那么我们就需要按照活动编号把库存锁的颗粒度缩小,实际操作也并不复杂,只是把活动ID+库存扣减后的值一起作为分布式锁的Key,这样就缩小了锁的颗粒度。
其中有一个比较关键的就是扣减库存后,在各个以下的流程节点中,如果有流程失败则进行缓存库存的恢复操作。
总体思路
优化思路
前置知识:项目压测优化实践思路-CSDN博客
机器环境配置:
1、阿里云服务器三台 4c8G 100mbps 带宽
2、一台中间件机器

3、一台监控机器 prometheus、influxdb 、grafana

4、一台应用机器 jdk 、lottery 、arthas、 nedo_export

一、定义 REST 接口进行压测使用
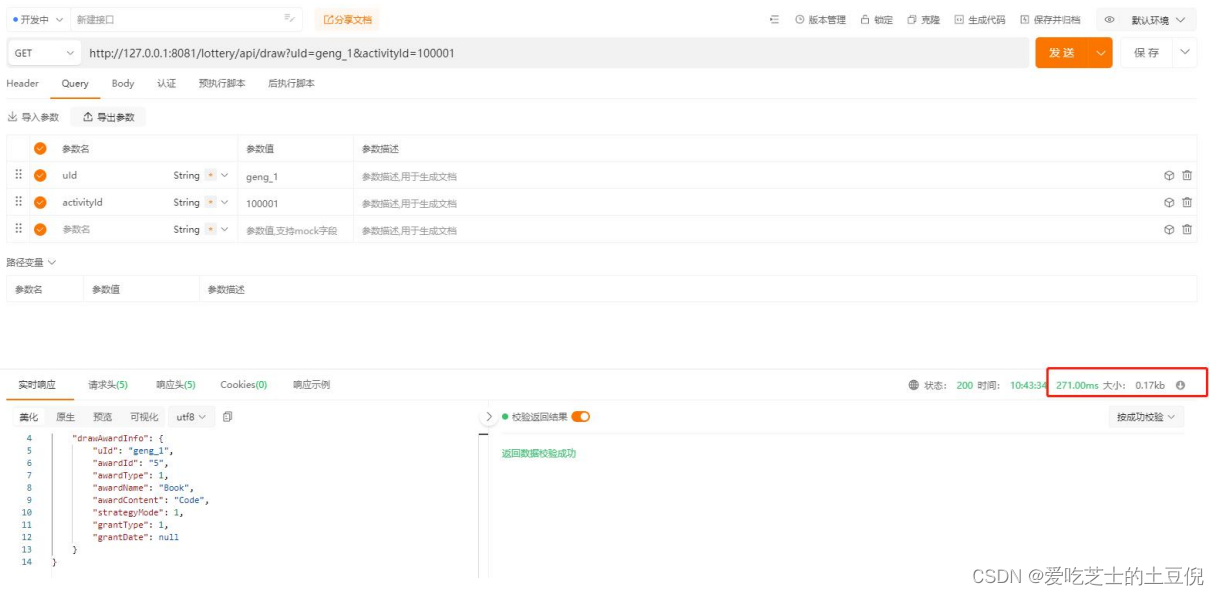
二、Postmain 模拟调用
Postmain 模拟调用 RESTFUL 接口 需关注响应时长和返回数据包大小,因为数据包大小会影响到带宽占用。根据响应时长可以算出压测中线程组的执行总时长
三、梯度压测
梯度压测(逐渐增加并发,观察系统的负载,找到系统的临界点)
线程数:根据接口的响应时间来决定 如果很短 就可以用很少的线程 反之更多的线程循环次数:接口响应时间 * 循环次数 = 执行样本的时间(s) 可以控制所有线程组在多久的时间内执行完成
| 线程数 | 循环次数 | 样本数 |
|---|---|---|
| 5 | 4000 | 20000 |
| 10 | 4000 | 40000 |
| 20 | 4000 | 80000 |
| 25 | 4000 | 100000 |
| 30 | 4000 | 120000 |
| 35 | 4000 | 140000 |
| 40 | 4000 | 160000 |
| 45 | 4000 | 180000 |
| 50 | 4000 | 200000 |
总线程总数:275
总循环次数:40000 次
总样本数:1,040,000
四、数据库连接异常
开始压测:MySQL 直接报错
问题 1:数据库连接异常

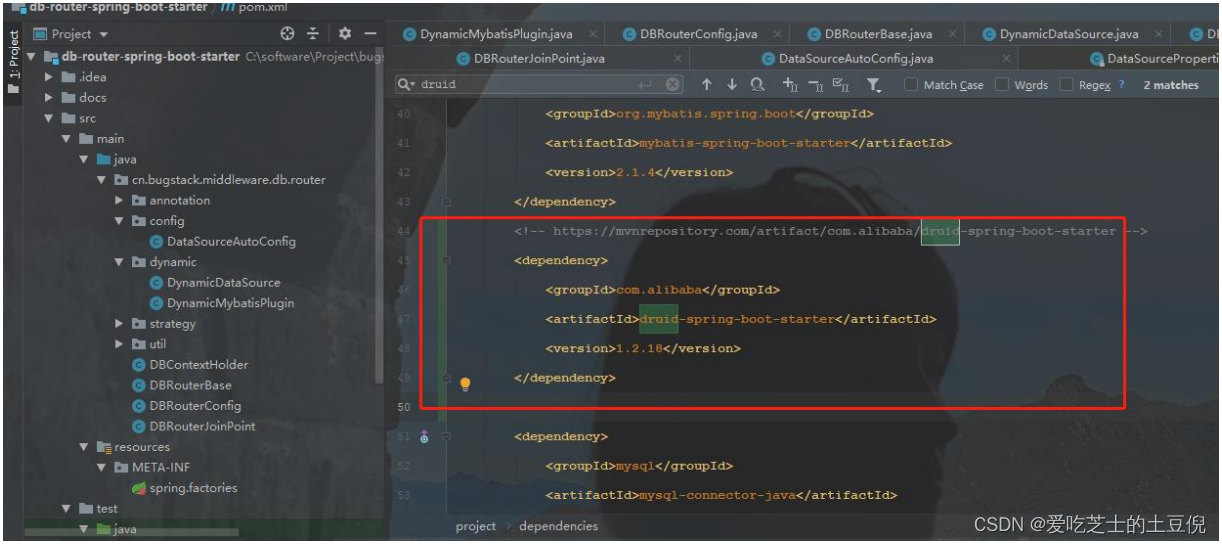
引入 DBRouter 待数据源配置的 用 master 分支的代码(需要在 dbrouter 的 master 分支加一个 druid 依赖否则会报如下错误)
Caused by: java.lang.ClassNotFoundException: com.alibaba.druid.pool.DruidDataSource
at java.net.URLClassLoader.findClass(URLClassLoader.java:387) ~[na:1.8.0_371]
at java.lang.ClassLoader.loadClass(ClassLoader.java:418) ~[na:1.8.0_371]
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355) ~[na:1.8.0_371]
at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ~[na:1.8.0_371]
at java.lang.Class.forName0(Native Method) ~[na:1.8.0_371]
at java.lang.Class.forName(Class.java:264) ~[na:1.8.0_371]
at
cn.bugstack.middleware.db.router.config.DataSourceAutoConfig.createDataSource(DataSourceAu
toConfig.java:103) ~[db-router-spring-boot-starter-1.0.2-SNAPSHOT.jar:1.0.2-SNAPSHOT]
加入 Druid 依赖,用的是 Master 分支代码 需要加一个 Druid 数据源 否则启动
在 Lottery 的父依赖中排除指定依赖
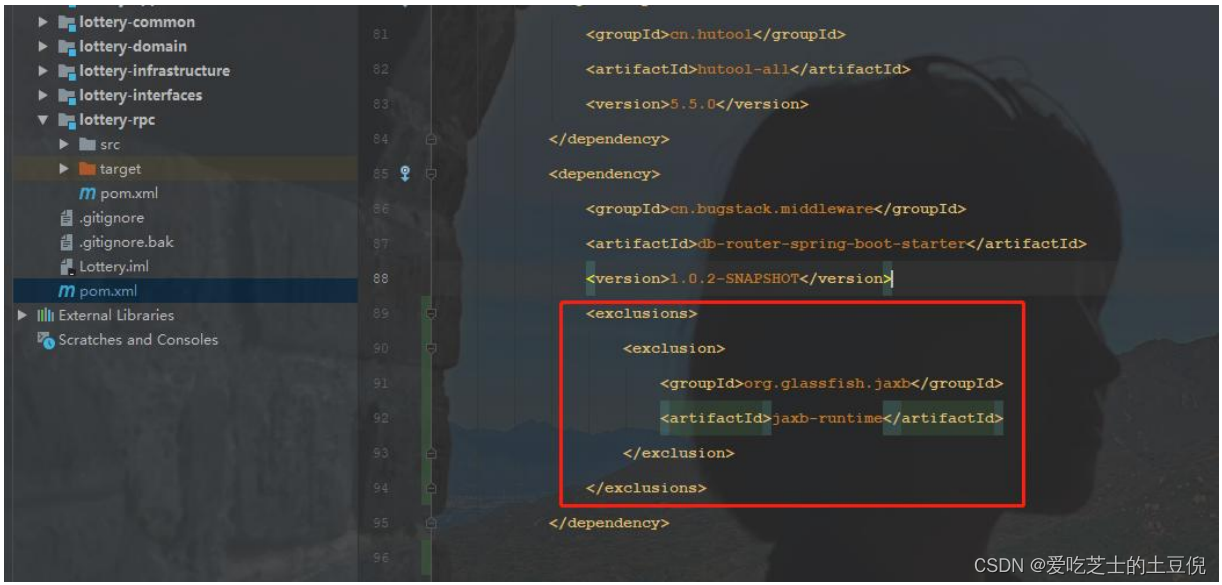
五、引入 Druid 数据源
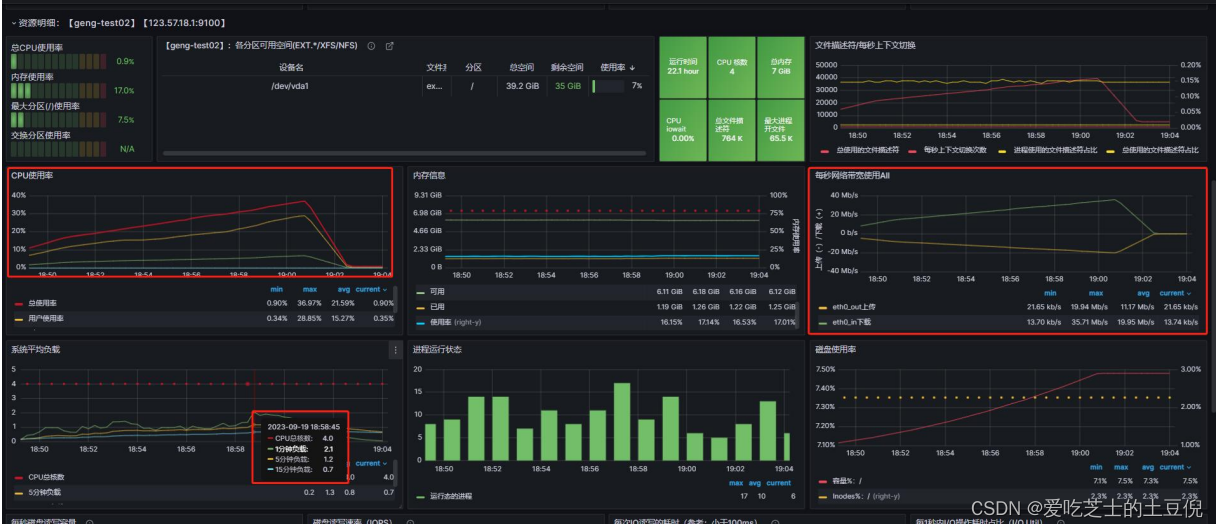
压测 2:修改 Druid 数据源后直接压测
系统负载:1 分钟负载 2.1 5 分钟负载 1.3 15 分钟负载 0.7;说明系统可以处理过来系统的负载和 CPU 的核数有关,对于 4 核 CPU 来说 当负载大于 4 就需要介入查看。CPU 使用和内存占用不高
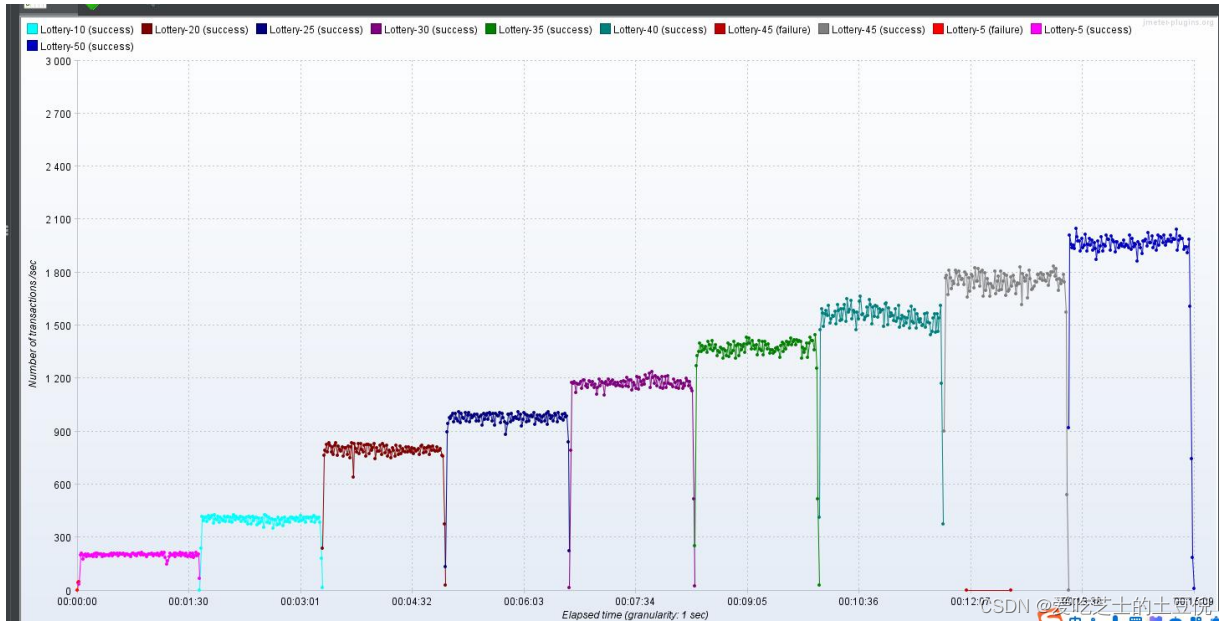
每个样本的汇总报告:系统的 TPS 持续增加

RT:最开始响应时间长 后来持续平稳,应该是最开始的样本 完成了抽奖的整个流程,后续的请求返回的都是系统无库存,在 Redis 层拦截
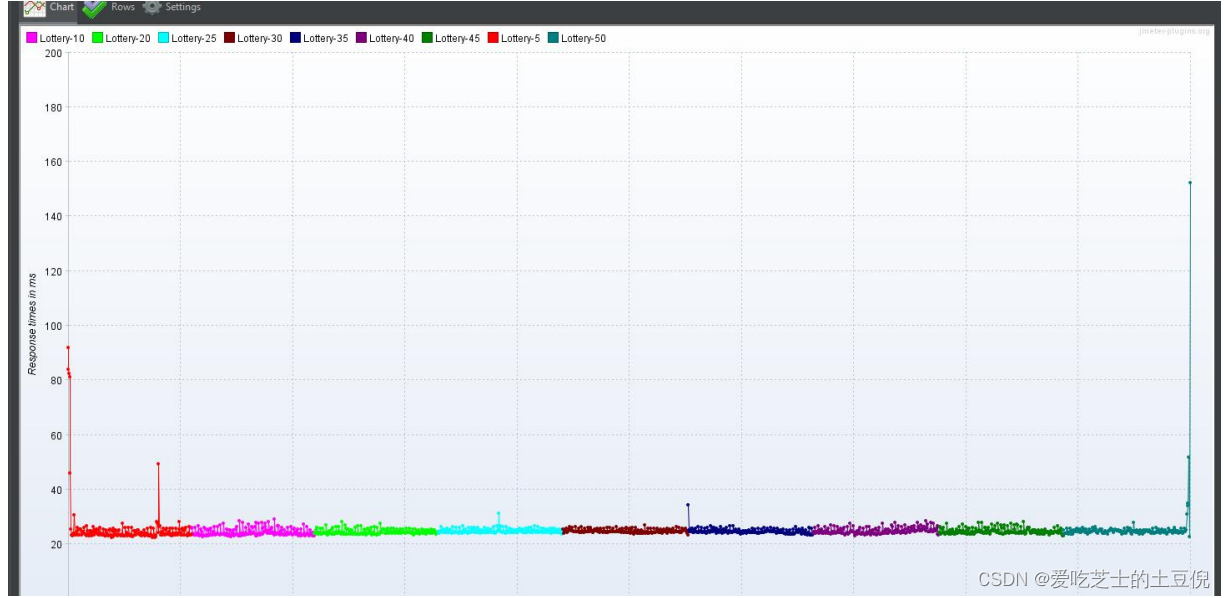
TPS
活动线程数
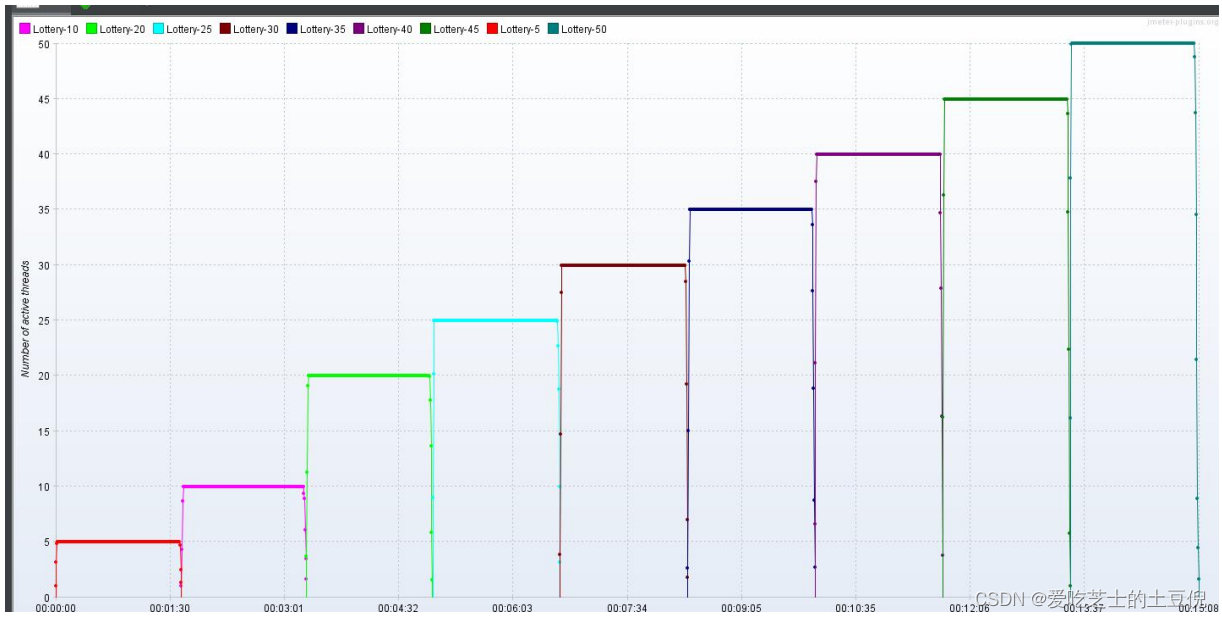
总结:看监控信息显示,负载不高,响应时间在最开始的时候稍长 后续逐渐平稳,TPS 持续增加,异常率很低。推测是在 Redis 层库存校验时进行了拦截返回,几乎后面所有的请求响应结果都是无库存。
{"code":"0001","info":"活动剩余库存非可用","drawAwardInfo":null}
六、分布式锁和抽奖的后续流程
压测三:基于压测二的总结,接下来压测 获取分布式锁和抽奖的后续流程,【建议先跑两个线程组看看,接口的响应时间,在决定启动多个线程执行多少次,尽量避免直接启动压测二的样本】
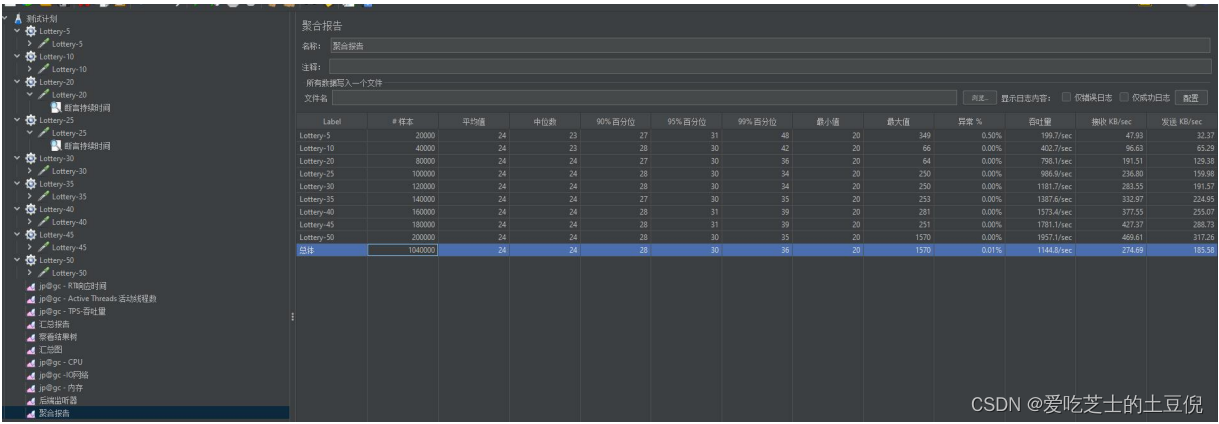
(1)Jmeter 测试计划
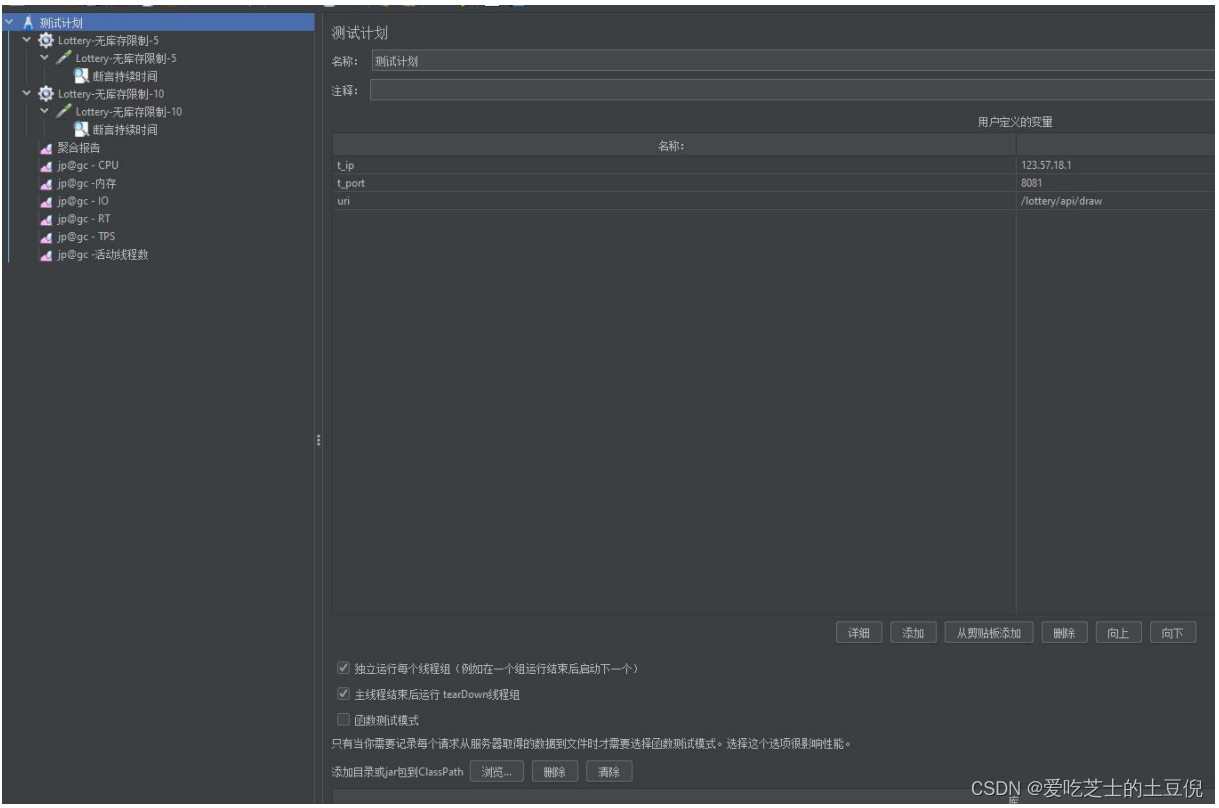
(2)样本和线程数
| 线程数 | 循环数 | 样本数 |
|---|---|---|
| 5 | 1000 | 5000 |
| 10 | 1000 | 10000 |
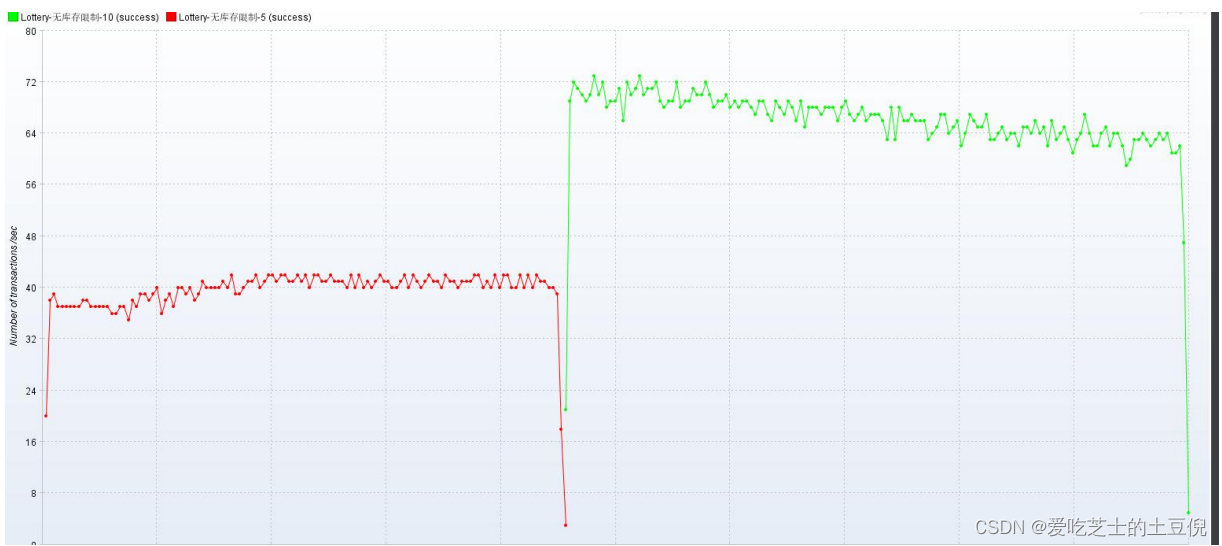
(3)聚合报告
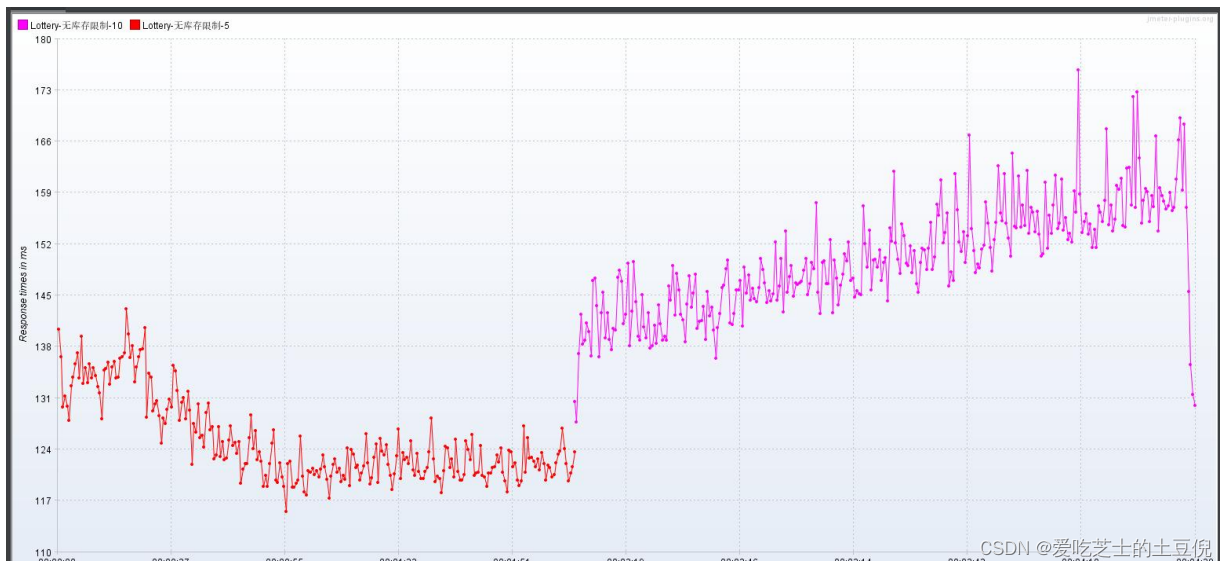
看聚合报告 RT 的相应时间都在 100ms 以上,所以适合用 少线程 多循环的方式执行(原因是因为低时延)

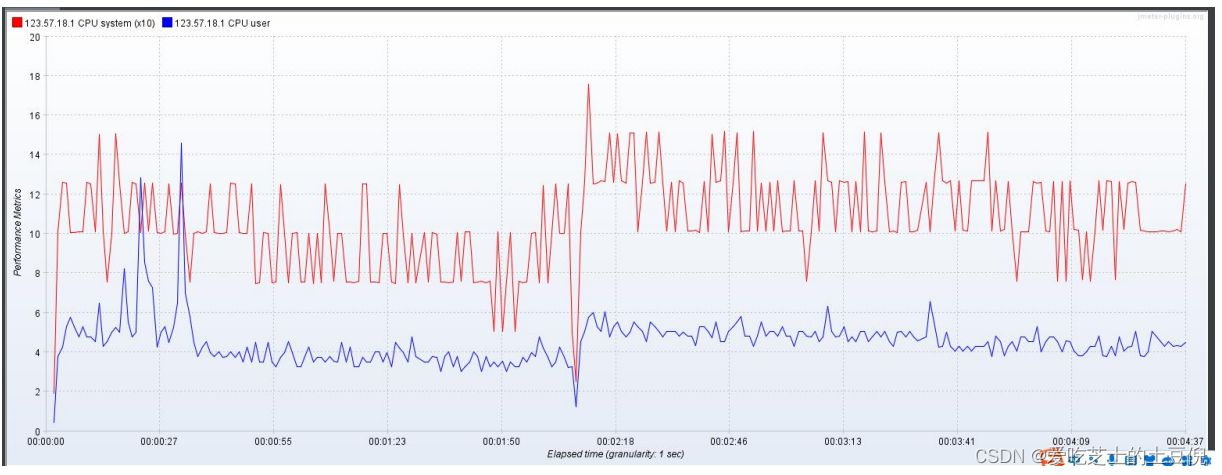
prometheus 监控,整个系统资源使用率 不高 ,负载不高 IO 也不高
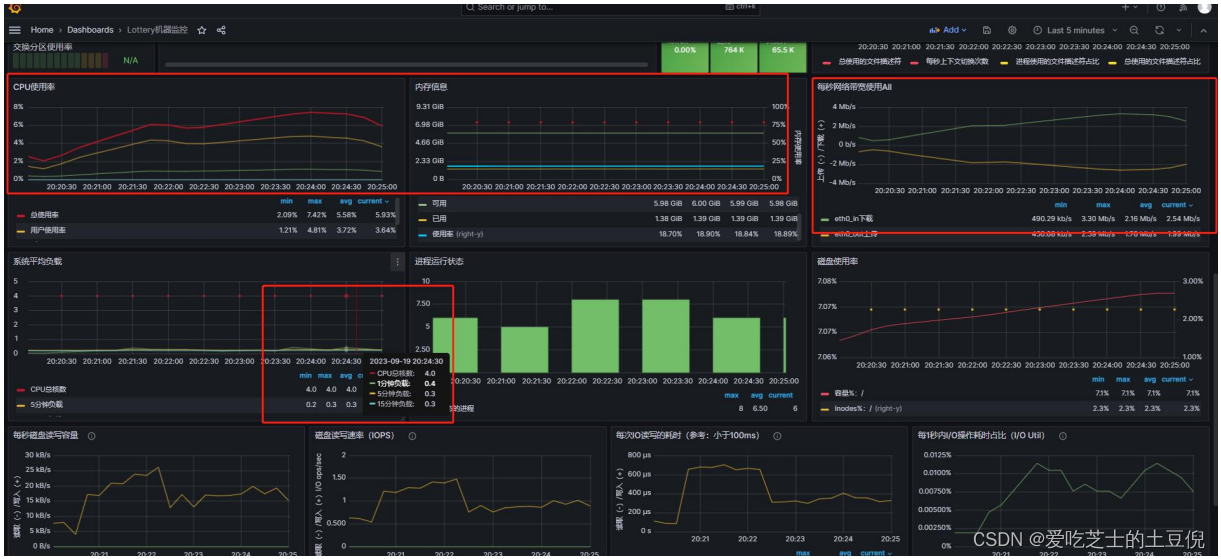
TPS:
RT:响应时间越来越长
CPU:利用率很低
七、添加索引
压测三改进:
(1)对应响应时间长的接口,压测的时候可以增加多个线程数 ,循环次数减
(2)由于操作数据库比较多查询较多,建立字段索引列,加快查询效率
创建联合索引,user_take_activity 和 user_take_activity_count 添加联合索引,activity 表可以给 activity_id 加一个单列索引(数据量较少,暂时看不出效果)
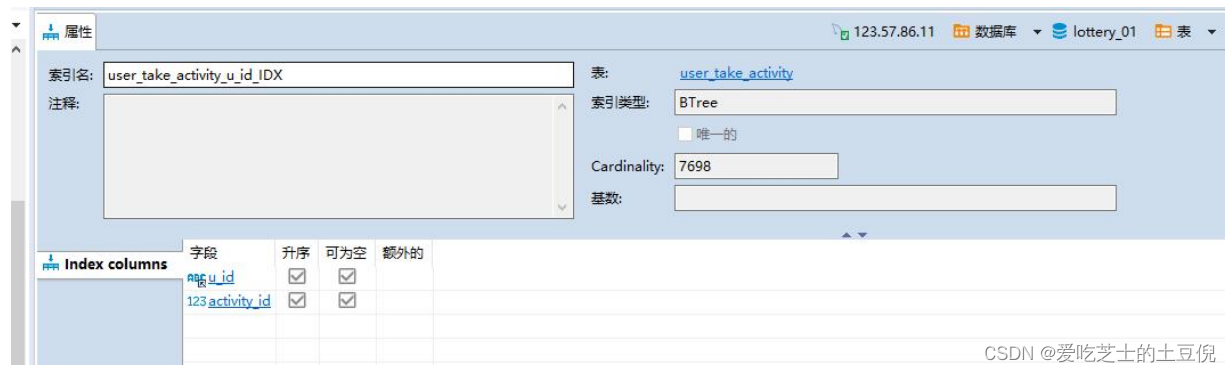
索引执行效果

样本:
| 线程数 | 循环次数 | 样本数 |
|---|---|---|
| 200 | 20 | 4000 |
| 300 | 20 | 6000 |
聚合报告:吞吐量上来了是上一轮压测的 8 倍多 但是执行响应时间还是很长,平均值还在708ms 左右 是上一轮的 7 倍左右

RT:
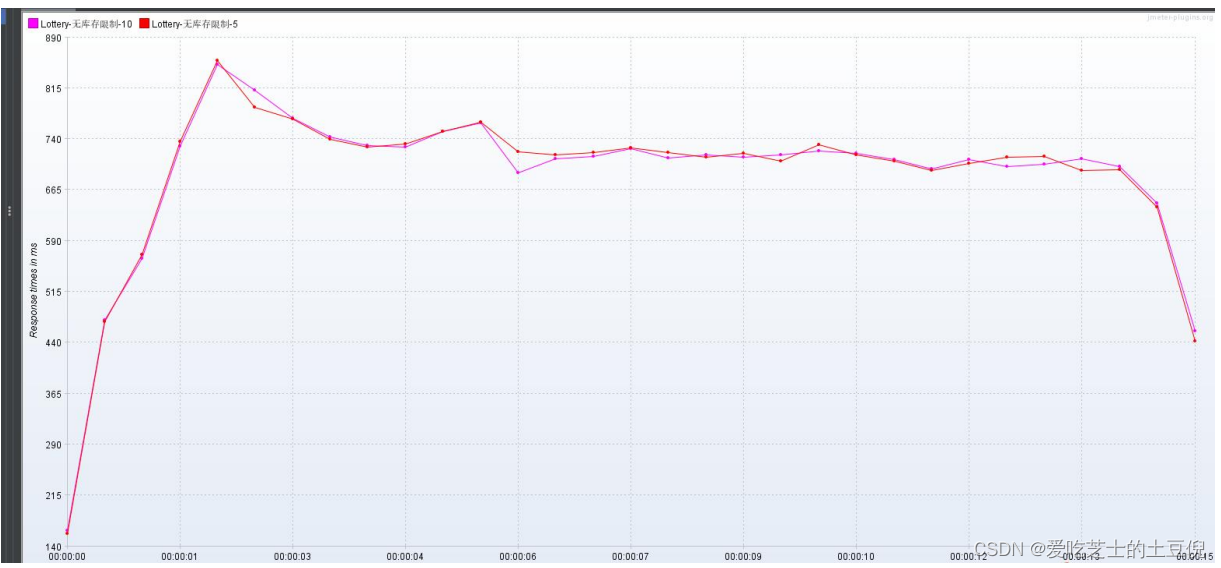
总结:
通过响应时间 可以确定是采用多线程 少循环次数 还是 少线程 多循环次数
增加索引值 ,提高查询效率,TPS 有所回升,所以我们需要确定代码中那块的执行时间比较长,进而优化,借助阿里的 arthas 性能分析
八、Arthas 分析接口响应时长并将查库操作存入 Redis
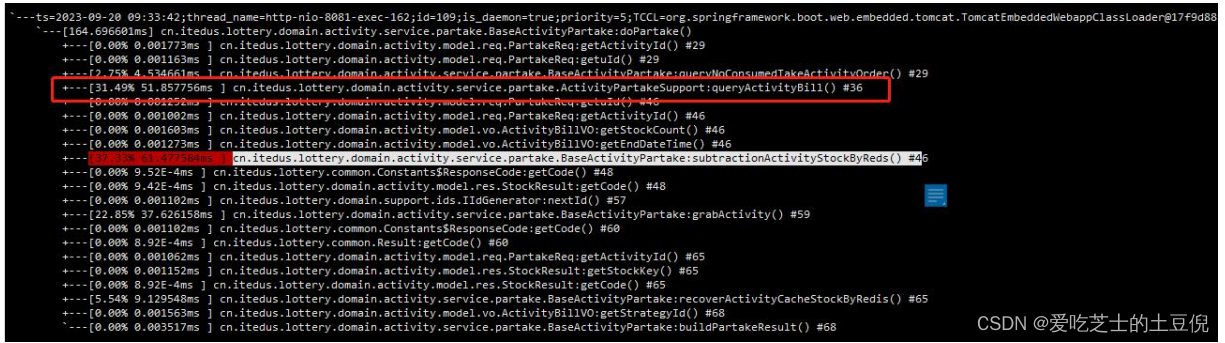
监控 doDrawProcess 找到耗时的 doPartake 方法
trace cn/itedus/lottery/application/process/draw/impl/ActivityDrawProcessImpl doDrawProcess
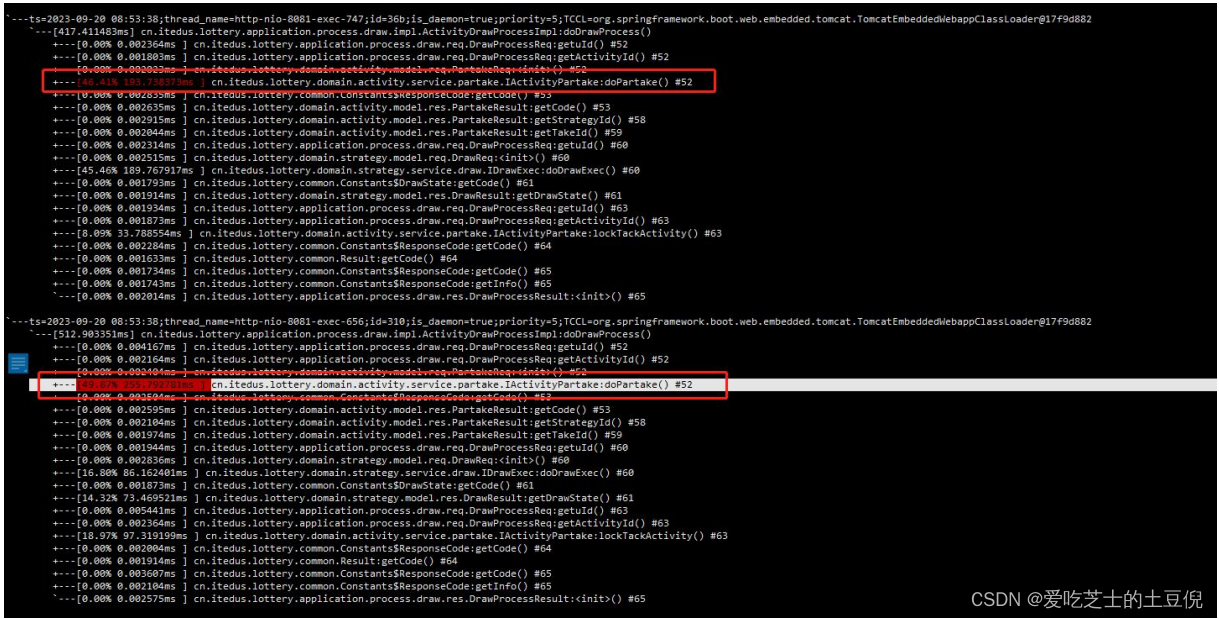
监控 doPartake 方法
trace cn/itedus/lottery/domain/activity/service/partake/IActivityPartake doPartak
查询账单接口响应时间 100MS 左右 生成领取记录接口在 224ms 左右
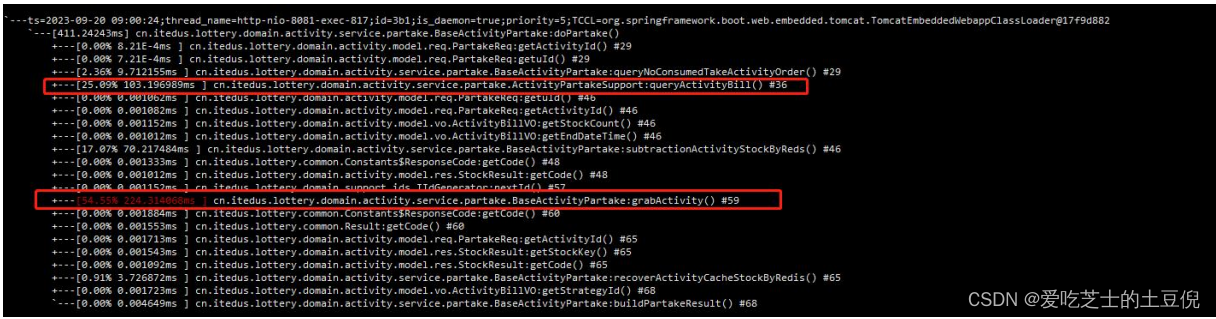
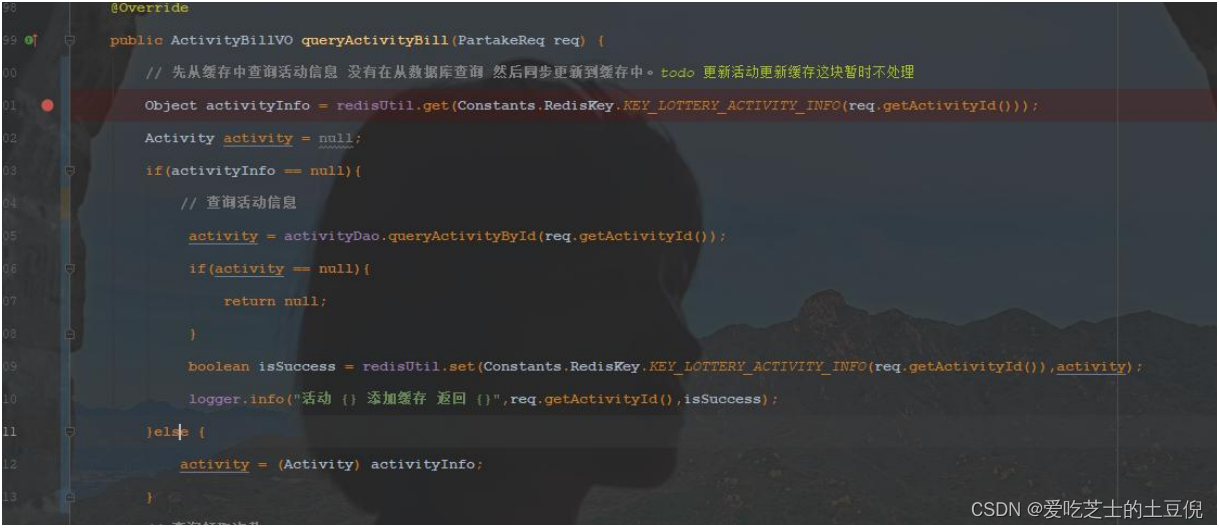
优化查询账单接口:将查库操作改为查 Redis
修改后的代码:
压测后的结果:RT 有所减少 TPS 有所增加

Arthas 返回结果:查询账单接口减少 50ms
九、磁盘和网络带宽导致负载增加
增加线程数压测
样本数:
| 线程数 | 循环次数 | 样本数 |
|---|---|---|
| 200 | 200 | 40000 |
| 400 | 200 | 80000 |
| 600 | 200 | 120000 |
| 800 | 200 | 160000 |
| 1000 | 200 | 200000 |
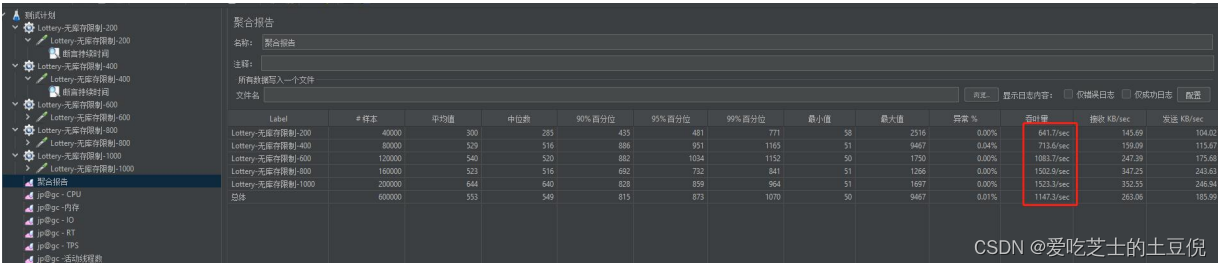
聚合报告: TPS 平均在 1500 左右 RT 平均在 472
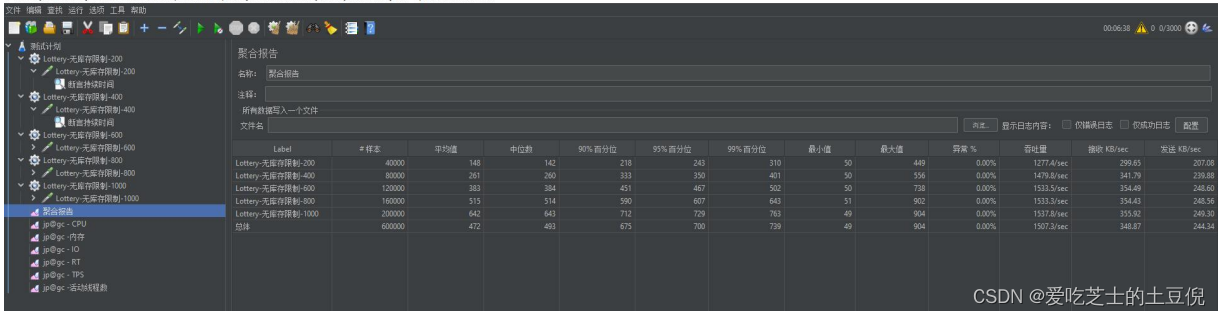
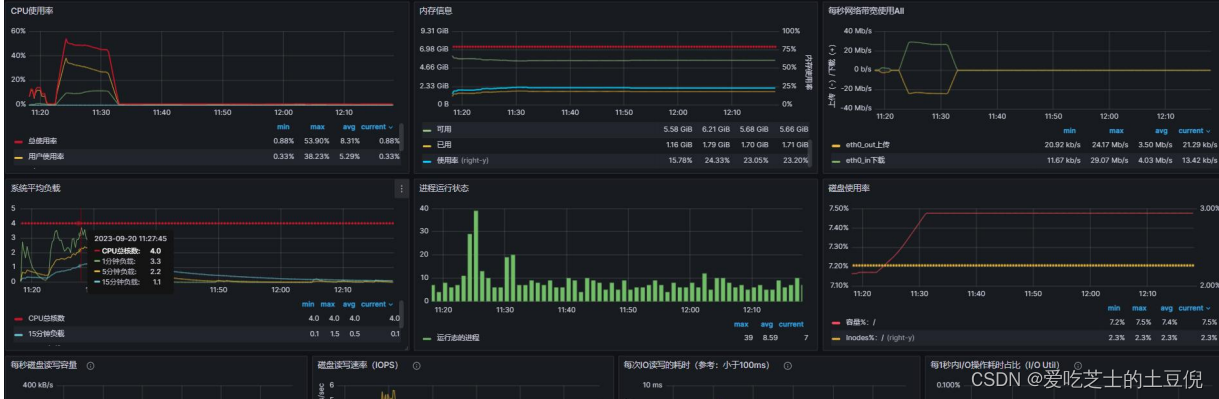
prometheus 监控显示 系统 1 分钟负载已达到 5.4 说明系统中有大量的排队请求,系统已经请求不过来了,这个时候就需要优化了,因为已经达到系统的瓶颈了,带宽也达到最大值,说明带宽也影响了系统的处理能力,CPU 和内存正常

磁盘 IO 使用率很高、网络带宽不足或延迟 造成系统的负载很高 但是 CPU 和内存正常

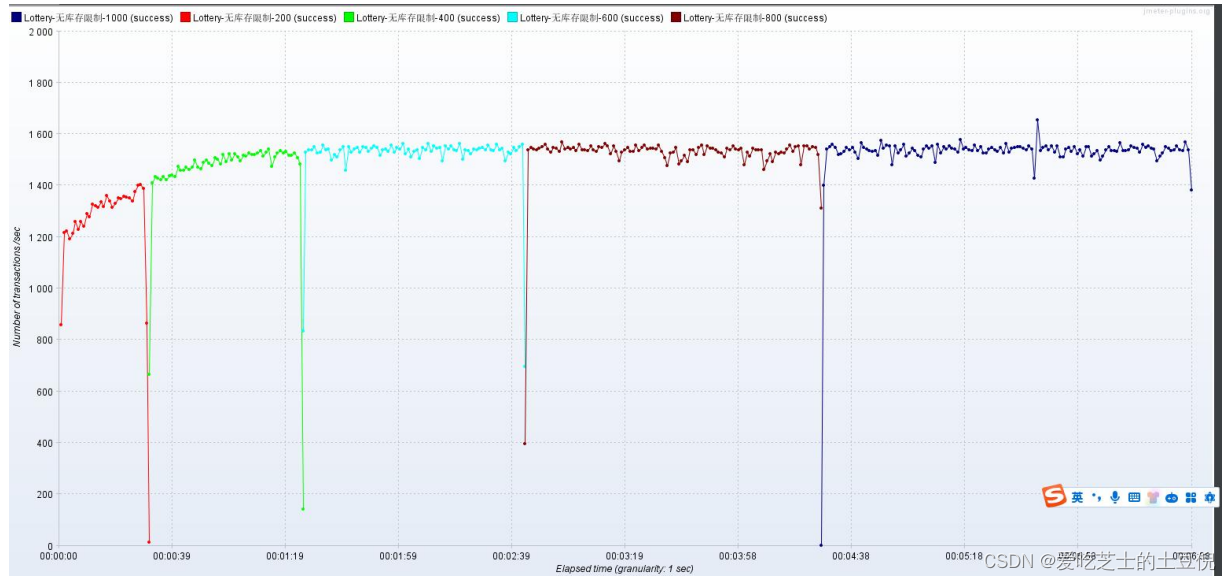
TPS: 很稳定
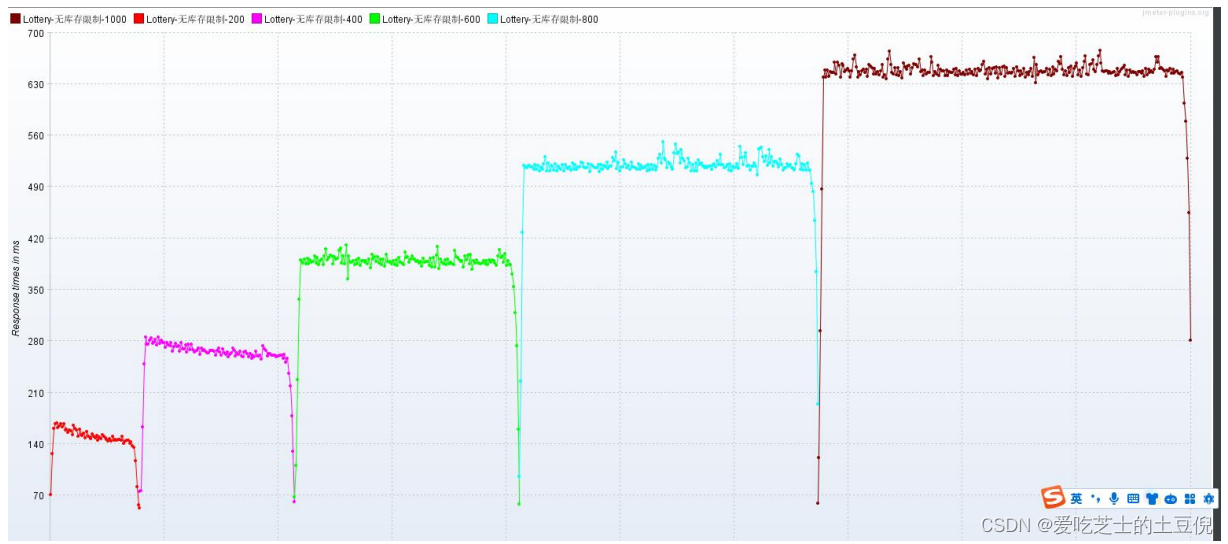
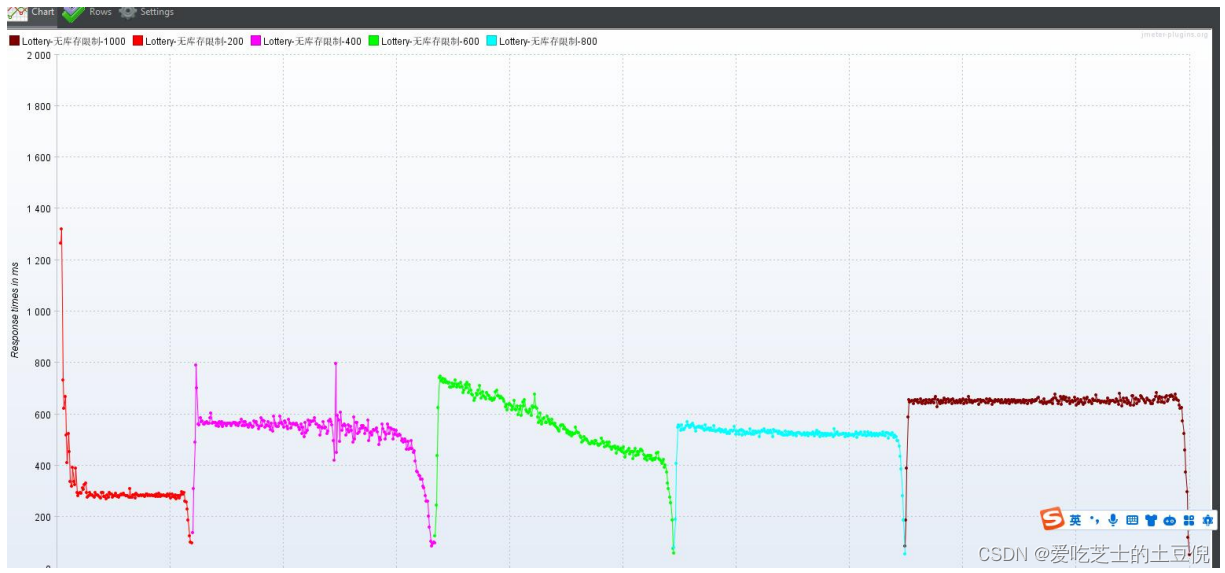
RT:响应时间在增加
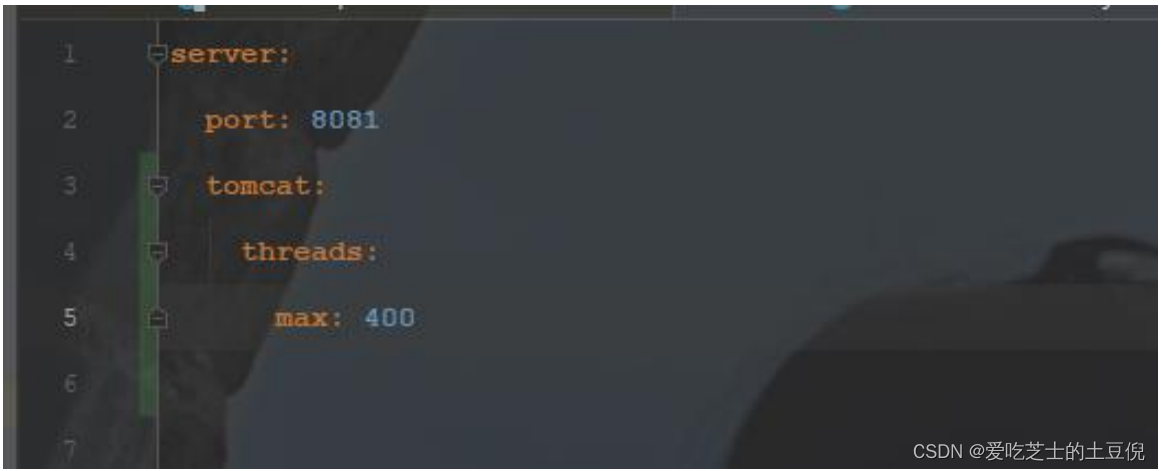
十、增加 Tomcat 线程数
Tomcat 线程数为 400 默认 200
prometheus 监控显示 负载有所降低
聚合报告:
RT:
TPS:

相关文章:
设计一个抽奖系统
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术🔥如果感觉博主的文章还不错的…...
IntelliJ IDEA使用学习
一、安装教程 网上自行下载,CSDN不然过审二、使用教程 2.1 快捷键操作与设置 设置 Setting——>按键映射——>选择顺手的系统快捷键 编写代码 CtrlShift Enter,语句完成。 “!”,否定完成,输入表达式时按 …...
sqlilabs第五十三五十四关
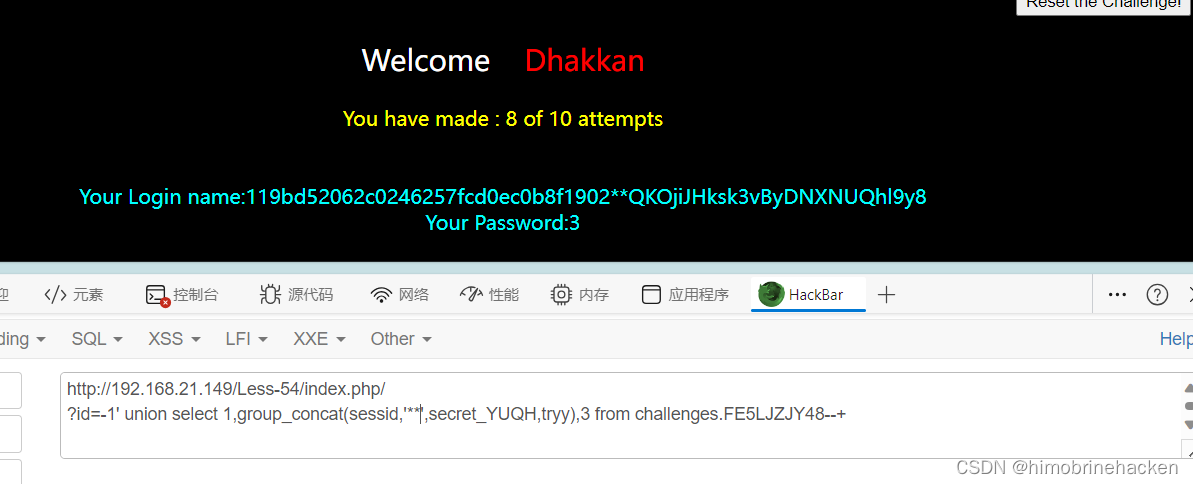
Less-53(GET - GET - Error based - ORDER BY CLAUSE-String- Stacked injection) 手工注入 单引号闭合,和上一关一样堆叠注入解决 自动注入 和上一关一样 Less-54(GET - challenge - Union- 10 queries allowed -Variation 1) 手工注入 这一关开始后面的可以看…...
❤ Uniapp使用三( 打包和发布上线)
❤ Uniapp使用三( 打包和发布上线) 一、介绍 什么是 uniapp? uniapp 是一种基于 Vue.js 的多平台开发框架,它可以同时用于开发安卓、iOS、H5 等多个平台。因此,只需要写一次代码就可以在多个平台上运行,提高了开发效率。 打包…...
【JavaEEj进阶】 Spring实现留言板
文章目录 🎍预期结果🍀前端代码🎄约定前后端交互接⼝🚩需求分析🚩接⼝定义 🌳实现服务器端代码🚩lombok 🌲服务器代码实现🌴运⾏测试 🎍预期结果 可以发布并…...
react、Vue打包直接运行index.html不空白方法
react vue 在根目录下创建 vue.config.js 文件,写入 module.exports {publicPath: ./, }...

SpringBoot-01
Spring Boot是一个开源的Java框架,用于快速构建独立的、可执行的、生产级的Spring应用程序。它基于Spring框架,简化了Spring应用程序的配置和部署过程,使开发者能够更快速地创建高效、可扩展的应用。 Spring Boot具有以下特点: 简…...

「解析」Jetson配置 git服务
这两天感冒了在家休养,想着把之前买的 Jetson 开发板用起来,买Jetson的初衷就是用来学习Linux系统,顺道可以部署算法,以及一些其他需求,相比树莓派而言,Jetson开发相对更贵,但是其配备了英伟达的…...
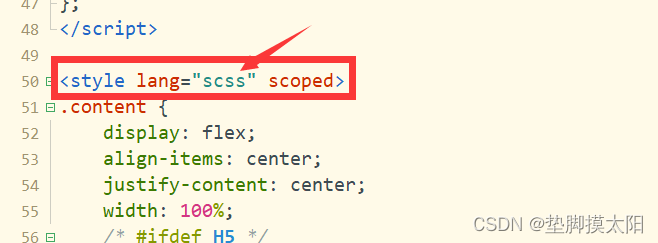
uniapp使用安装sass
1.首先你要安装node-sass npm install node-sass --save-dev2.安装sass-loader npm install sass-loader --save-dev3.修改style标签,声明使用sass <style lang"scss" scoped>...

ClickHouse学习笔记(六):ClickHouse物化视图使用
文章目录 1、ClickHouse 物化视图2、物化视图 vs 普通视图3、物化视图的优缺点4、物化视图的用法4.1、基本语法4.2、准备表结构4.3、准备数据4.3、查询结果 1、ClickHouse 物化视图 ClickHouse 的物化视图是一种查询结果的持久化,它的存在是为了带来查询效率的提升…...
)
华为OD机试真题-最小矩阵宽度-2023年OD统一考试(C卷)
题目描述: 给定一个矩阵,包含N*M个整数,和一个包含K个整数的数组。 现在要求在这个矩阵中找一个宽度最小的子矩阵,要求子矩阵包含数组中所有的整数。 输入描述: 第一行输入两个正整数N,M,表示矩阵大小。 接下来N行M列表示矩阵内容。 下一行包含一个正整数K。 下一行包含…...

java stream distinct根据list某个字段去重
项目场景: java stream distinct根据list某个字段去重,普通List简单去重: import java.util.Arrays; import java.util.List; import java.util.stream.Collectors;public class TestMain {public static void main(String[] args) {List&l…...
超精简虚拟机镜像
前经常有人问我要极度精简的win 7 虚拟机镜像,开个贴直接发吧,这次包括 win10 和 win7 镜像,另有一个 win 8 win7 镜像压缩包只有 300Mb, win 10 镜像 有 800Mb, win 8 有 700Mb 系统极度精简,可以运行 qq 微信&#…...

【JVM】常用命令
一、前言 Java虚拟机(JVM)是Java程序运行的基础设施,它负责将Java字节码转换为本地机器代码并执行。在开发过程中,我们经常需要使用一些命令来监控和管理JVM的性能和状态。本文将详细介绍6个常用的JVM命令:jps、jstat…...
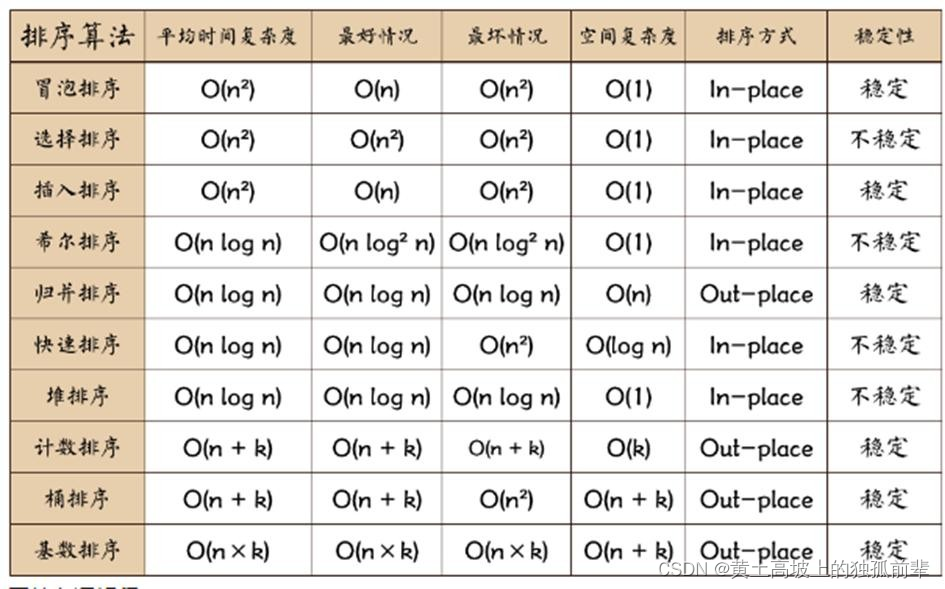
第 7 章 排序算法
文章目录 7.1 排序算法的介绍7.3 算法的时间复杂度7.3.1 度量一个程序(算法)执行时间的两种方法7.3.2 时间频度7.3.3 时间复杂度7.3.4 常见的时间复杂度7.3.5 平均时间复杂度和最坏时间复杂度 7.4 算法的空间复杂度简介7.4.1 基本介绍 7.5 冒泡排序7.5.1 基本介绍7.5.2 演示冒泡…...

机器人持续学习基准LIBERO系列7——计算并可视化点云
0.前置 机器人持续学习基准LIBERO系列1——基本介绍与安装测试机器人持续学习基准LIBERO系列2——路径与基准基本信息机器人持续学习基准LIBERO系列3——相机画面可视化及单步移动更新机器人持续学习基准LIBERO系列4——robosuite最基本demo机器人持续学习基准LIBERO系列5——…...

基于 Level set 方法的医学图像分割
摘 要 医学图像分割是计算机辅助诊断系统设计中的关键技术。对于医学图像分割问题,它一般可分为两部分:(l)图像中特定目标区域(器官或组织)的识别;(2)目标区域完整性的描述与提取。相比于其他图像,医学图像的复杂性和多样性,使得传统的基于底层图像信息的分割方法很难取得好的…...
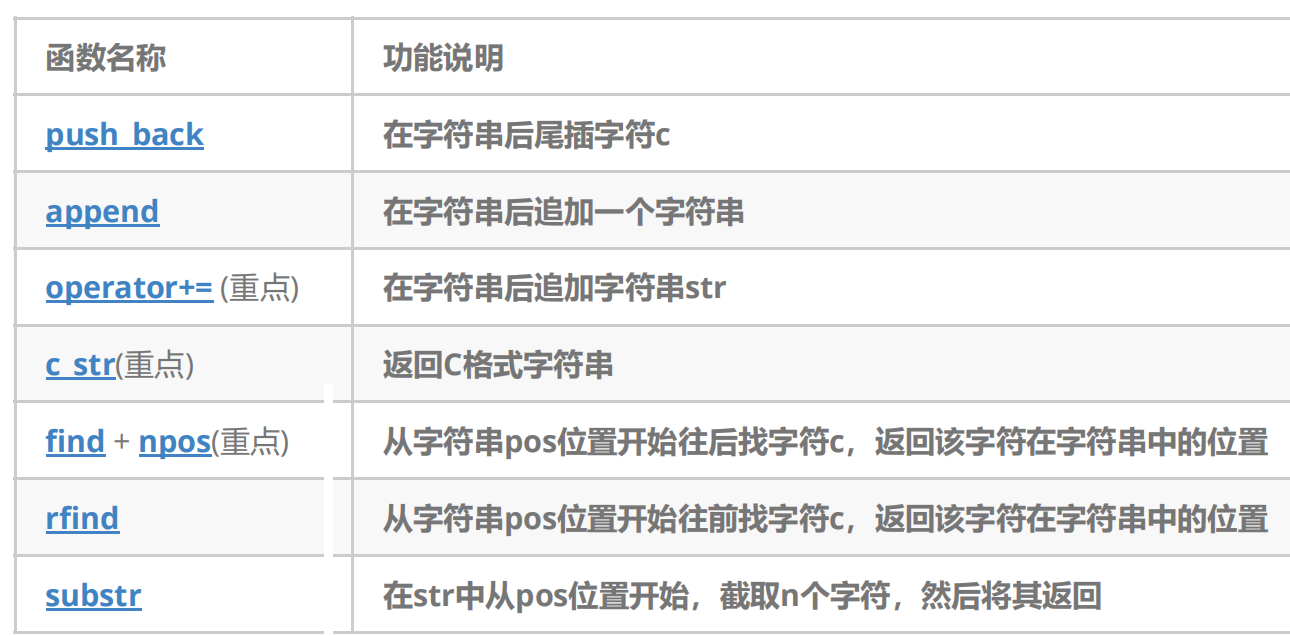
【C++入门】C++ STL中string常用函数用法总结
目录 前言 1. string使用 2. string的常见构造 3. string类对象的访问及遍历 迭代器遍历: 访问: 4. string类对象的容量操作 4.1 size和length 4.2 clear、empty和capacity 4.3 reserve和resize reserve resize 5. string类对象的修改操作 push_back o…...

Rust变量、常量声明与基本数据类型
Rust是一门系统级别的编程语言,注重安全性、性能和并发。在这篇博客中,我们将介绍Rust中的变量、常量声明以及基本数据类型,并通过示例说明每一种类型的用法。 变量声明 在Rust中,使用 let 关键字声明变量。变量默认是不可变的&…...
【MATLAB】 SSA奇异谱分析信号分解算法
有意向获取代码,请转文末观看代码获取方式~ 1 基本定义 SSA奇异谱分析(Singular Spectrum Analysis)是一种处理非线性时间序列数据的方法,可以对时间序列进行分析和预测。 它基于构造在时间序列上的特定矩阵的奇异值分解&#…...
,3大未公开API接口实测报告)
别再手动复制粘贴了!ChatGPT原生PPT导出功能已上线(仅限Enterprise Tier),3大未公开API接口实测报告
更多请点击: https://intelliparadigm.com 第一章:ChatGPT原生PPT导出功能的架构演进与企业级定位 ChatGPT原生PPT导出功能并非简单集成第三方渲染库,而是OpenAI在模型服务层、内容生成中间件与文档编排引擎三者深度协同下构建的端到端能力。…...
)
ESP32连接阿里云物联网平台实战:从设备创建到APP控制,一个教程全搞定(避坑指南)
ESP32连接阿里云物联网平台实战:从设备创建到APP控制全流程解析 在智能硬件产品开发中,物联网平台的选择与集成往往是决定项目成败的关键环节。阿里云物联网平台凭借其稳定的服务、丰富的功能生态和本土化优势,已成为国内物联网开发者的首选。…...

AI-auth-toolkit社区贡献指南:从入门到核心开发者
AI-auth-toolkit社区贡献指南:从入门到核心开发者 【免费下载链接】genai-compliance-bench GenAI compliance benchmark is a evaluation benchmarks for generative AI in regulated industries. 项目地址: https://gitcode.com/gh_mirrors/ai/genai-compliance…...

副本机制与 ISR 设计:为什么 Kafka 这么快又这么可靠
几年前我接手过一个"慢到不能忍"的消息系统。Kafka 集群,日处理 500 亿条消息,QPS 峰值 120 万。但是隔三差五出现"数据延迟积压",有时候一条消息从生产到消费,竟然要等几十秒。查了一周,发现跟 K…...

Windows Server TLS安全加固:注册表三步禁用Sweet32漏洞
1. 这不是“打补丁”,而是给Windows Server的SSL/TLS协议栈做一次外科手术你有没有遇到过这样的情况:安全扫描工具突然报出一堆红色高危漏洞,CVE-2016-2183(Sweet32)、CVE-2015-2808(Logjam)、C…...

Foobar2000终极歌词体验:三平台逐字歌词完整配置指南
Foobar2000终极歌词体验:三平台逐字歌词完整配置指南 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource 还在为Foobar2000找不到高质量的逐字歌词…...

如何在RK35XX设备上部署稳定高效的Ubuntu系统?
如何在RK35XX设备上部署稳定高效的Ubuntu系统? 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 想要在Rockchip RK35XX系列开发板上获得接近原生Ubuntu的体验吗…...

easyPoi使用
一、核心定位区别 EasyPoi:全能型,支持 Excel、Word、PDF 导出,注解极简,适合小数据、快速开发EasyExcel:高性能型,只专注 Excel,主打低内存、大数据量,适合海量数据导出 二、Easy…...

边缘AI语音交互实战:从唤醒词识别到MCP外设控制的嵌入式实现
1. 项目概述:当边缘计算遇见语音交互 最近在折腾一个挺有意思的项目,核心是把语音交互的能力从云端“拽”下来,直接部署到边缘设备上,然后让它去控制各种MCP(Microcontroller Peripheral)外设。听起来像是智…...

TwicketSegmentedControl性能优化终极指南:内存管理与渲染技巧深度解析
TwicketSegmentedControl性能优化终极指南:内存管理与渲染技巧深度解析 【免费下载链接】TwicketSegmentedControl Custom UISegmentedControl replacement for iOS, written in Swift 项目地址: https://gitcode.com/gh_mirrors/tw/TwicketSegmentedControl …...