2024年1月17日Arxiv热门NLP大模型论文:THE FAISS LIBRARY
Meta革新搜索技术!提出Faiss库引领向量数据库性能飞跃
引言:向量数据库的兴起与发展
随着人工智能应用的迅速增长,需要存储和索引的嵌入向量(embeddings)数量也在急剧增加。嵌入向量是由神经网络生成的向量表示,其主要目的是将输入媒体项映射(嵌入)到向量空间中,空间中的局部性编码了输入的语义。这些嵌入向量从各种媒体形式中提取,包括文字、图像、用户和推荐项目等。它们甚至可以编码对象关系,例如多模态文本-图像或文本-音频关系。
嵌入向量在工业环境中非常受欢迎,用于端到端学习成本效益不高的任务。例如,k最近邻分类器比深度神经网络分类更高效。在这种情况下,嵌入向量作为可以重复用于多个目的的紧凑中间表示特别有用。这解释了为什么提供向量存储和搜索功能的工业数据库管理系统(DBMS)在过去几年中获得了采用。这些DBMS位于传统数据库和近似最近邻搜索(ANNS)算法的交汇处。直到最近,后者主要被认为是特定用例或研究中的算法。
从实际角度来看,保持嵌入提取和向量搜索算法之间角色的清晰分离有多种优势。两者都受“嵌入合同”约束,该合同规定了嵌入距离:嵌入提取器(通常是现代系统中的神经网络)经过训练,使得嵌入之间的距离与要执行的任务对齐;向量索引旨在尽可能准确地执行嵌入向量之间的邻居搜索,以便在给定的距离度量下获得精确搜索结果。
Faiss是一个用于ANNS的工业级库。它旨在从简单脚本中使用,也可以作为DBMS的构建模块。与其他只关注单一索引方法的库不同,Faiss是一个工具箱,包含通常涉及一系列组件(预处理、压缩、非穷尽搜索等)的索引方法。这是必要的:根据使用约束,最有效的索引方法是不同的。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人
论文概览:Faiss库的核心功能与应用
Faiss库专门用于向量相似性搜索,是向量数据库的核心功能。Faiss是一套索引方法和相关原语的工具包,用于搜索、聚类、压缩和转换向量。本文首先描述了向量搜索的权衡空间,然后是Faiss的设计原则,包括结构、优化方法和接口。我们对库的关键特性进行了基准测试,并讨论了几个选定的应用案例,以突出其广泛的适用性。
Faiss是一个包含多种索引方法的工具箱,这些方法通常涉及一系列组件(如预处理、压缩、非穷尽搜索等)。这是必要的,因为根据使用约束,最有效的索引方法是不同的。Faiss不提取特征——它只索引由不同机制提取的嵌入;Faiss不是一个服务——它只提供在本地机器上作为调用过程的一部分运行的函数;Faiss也不是数据库——它不提供并发写访问、负载平衡、分片或一致性。库的范围有意限制,以专注于精心实现的算法。
Faiss的基本结构是索引。索引可以存储一定数量的数据库向量,这些向量逐渐添加到其中。在搜索时,提交一个查询向量到索引。索引返回与查询向量在欧几里得距离上最接近的数据库向量。有许多这种基本功能的变体:可以返回最近的邻居而不是仅仅一个;可以返回固定数量的邻居而不是一定范围内的向量;可以并行搜索多个向量,在批处理模式下;支持除欧几里得距离以外的其他度量;可以为速度或内存交换搜索的准确性。搜索可以使用CPU或GPU。
本文的目标是展示Faiss的设计原则。相似性搜索库必须在不同约束之间取得平衡,这在Faiss中通过两个主要工具解决:向量压缩和非穷尽搜索。Faiss被设计为灵活且可用的工具。我们还回顾了Faiss在万亿级索引、文本检索、数据挖掘和内容审核等几个应用中的应用。
论文标题:THE FAISS LIBRARY
机构:FAIR, Meta; Zilliz; Zhejiang University
论文链接:https://arxiv.org/pdf/2401.08281.pdf
项目地址:暂无提供
向量搜索的权衡空间:速度、准确性与资源消耗
在向量搜索的领域,我们面临速度、准确性和资源消耗之间的权衡。这些因素通常是相互制约的,优化其中一个往往会牺牲另一个。例如,为了提高搜索速度,我们可能会接受较低的准确性或更高的资源消耗。反之,为了提高准确性,我们可能需要更多的时间和资源来处理数据。
1. 速度
速度是衡量搜索算法性能的关键指标之一。在实际应用中,快速响应用户的查询请求是至关重要的。然而,提高速度往往需要牺牲准确性或增加资源消耗。
2. 准确性
准确性指的是搜索结果与理想结果的接近程度。在某些应用场景中,如内容推荐或医疗诊断,高准确性是必不可少的。然而,提高准确性可能会导致搜索速度降低,或需要更多的计算资源。
3. 资源消耗
资源消耗包括内存使用、计算能力和存储空间等。在资源有限的环境中,如移动设备或嵌入式系统,资源消耗成为一个重要的考虑因素。优化资源消耗可以降低成本并提高系统的可扩展性。
在设计搜索算法时,我们需要根据具体的应用场景和需求来平衡这三个因素,以达到最佳的性能。
Faiss设计原则:结构、优化方法和接口设计
Faiss是一个专注于向量相似性搜索的工具库,其设计遵循了一些核心原则,以确保其在不同的应用场景中都能提供高效且灵活的搜索能力。
1. 结构设计
Faiss的基本结构是索引(index),它可以存储数据库向量,并在查询时返回与查询向量最接近的数据库向量。Faiss支持多种索引变体,如返回k个最近邻、只返回一定范围内的向量等。索引的设计允许在CPU和GPU上使用,以适应不同的硬件环境。
2. 优化方法
Faiss通过向量压缩和非穷尽搜索来优化搜索过程。向量压缩可以减少内存使用,而非穷尽搜索则通过聚类或图探索等方法,减少需要计算距离的向量数量,从而提高搜索速度。
3. 接口设计
Faiss旨在提供灵活的接口,使其可以轻松地嵌入到其他工具或数据库管理系统中。所有的类成员都是公开的,以便用户可以访问和修改实现细节。此外,Faiss提供了Python绑定,使得它可以方便地在脚本中使用。
Faiss的关键特性:索引方法与基准测试
Faiss提供了多种索引方法,以支持不同的搜索需求和优化目标。
1. 索引方法
Faiss的索引方法包括基于量化的近似最近邻搜索(ANN),如乘积量化(Product Quantization,PQ)和残差量化(Residual Quantization,RQ)。这些方法通过将向量压缩成紧凑的代码,来减少存储和计算需求。
2. 基准测试
为了评估不同索引方法的性能,Faiss进行了基准测试。这些测试使用了不同规模的数据集,如百万级别的数据集和包含10亿向量的数据集。基准测试结果显示,Faiss在处理大规模数据集时能够提供快速且准确的搜索结果。
通过这些特性,Faiss能够在保持高准确性的同时,有效地处理大规模的向量搜索任务。
向量压缩与非穷尽搜索:Faiss的两大工具
在处理大规模嵌入向量集合的向量数据库中,向量压缩和非穷尽搜索是Faiss库的两大核心工具。Faiss专注于向量相似性搜索,这是向量数据库的核心功能。向量压缩旨在减少向量所需的存储空间,而非穷尽搜索则试图在不检查数据库中的每个向量的情况下找到与查询向量最相似的向量。
1. 向量压缩
向量压缩通过减少每个向量的表示大小来减少整体存储需求。Faiss支持多种向量编解码器,或称为量化器,这些量化器将连续的多维向量转换为整数或等效的固定大小比特串。量化器的解码器部分负责从整数重建向量的近似表示。由于整数的数量是有限的,解码器只能重建有限数量的不同向量。
2. 非穷尽搜索
非穷尽搜索方法旨在提高搜索效率,通过避免对数据库中的每个向量进行距离计算来加速查询。Faiss实现了多种非穷尽搜索方法,包括基于聚类的方法和基于图的方法。这些方法通常涉及在搜索时只访问数据库的一个子集,这个子集由与查询向量最近的一组向量组成。
非穷尽搜索方法:IVF与基于图的索引
1. IVF索引
倒排文件(IVF)索引是一种在索引时对数据库向量进行聚类的技术。这种聚类使用向量量化器(粗量化器)产生一定数量的不同索引,这些索引的重建值称为质心。在搜索时,只访问部分质心对应的聚类。这种方法的关键参数是聚类的数量,它直接影响搜索的准确性和速度。
2. 基于图的索引
基于图的索引通过构建一个有向图来实现,图的节点是要索引的向量。在搜索时,通过跟随指向查询向量最近的节点的边来探索图。Faiss实现了两种基于图的算法:HNSW和NSG,分别对应于 IndexHNSW和 IndexNSG类。
数据库操作:向量的动态添加、删除与过滤搜索
1. 动态操作
Faiss索引支持动态添加(add和 add_with_ids)和删除向量(remove_ids)。这些操作允许数据库随时间变化,向量可以根据需要添加或删除。Faiss不存储任何与向量相关的元数据,只使用63位整数作为标识符。
2. 过滤搜索
向量过滤是在搜索时基于某些标准返回数据库向量的过程。Faiss对向量过滤有基本的支持,用户可以提供一个谓词(IDSelector回调),如果谓词对向量标识符返回 False,则忽略该向量。这种方法适用于需要根据元数据过滤向量的情况。
通过这些工具和方法,Faiss提供了一种灵活且高效的方式来处理大规模向量搜索任务,无论是在内存中还是在磁盘上。它支持各种操作,包括向量的动态添加和删除,以及基于用户定义的标准过滤搜索结果。
Faiss的工程实践:代码结构与优化策略
3.1 Brute force search
在Faiss中,实现高效的暴力搜索并不是一件简单的事情。它需要(1)一种高效计算距离的方法,以及(2)对于k近邻搜索,一种高效追踪k个最小距离的方法。
距离计算在Faiss中要么通过直接距离计算完成,要么当查询向量以足够大的批量提供时,使用矩阵乘法分解。Faiss的函数在CPU和GPU上分别通过 knn和 knn_gpu暴露。在CPU上,最小距离的追踪使用二进制堆或GPU上的排序网络。对于较大的k值,使用一个大小为k’ > k的未排序的结果缓冲区(reservoir)更为高效,当它溢出时将其调整为k。
尽管暴力搜索可以给出准确结果,但对于大型、高维数据集来说,这种方法变得缓慢。在低维度中,存在精确搜索结果的分支限界方法,但在高维度中,它们并不比暴力搜索更快。
3.2 Metrics
在近似最近邻搜索(ANNS)中,用户接受不完美的结果,这为新的解决方案设计空间打开了大门。数据库可以预处理成索引结构,而不仅仅是存储为普通矩阵。
准确性指标。在ANNS中,准确性是与精确搜索结果的差异来衡量的。这是一个中间目标:端到端的准确性取决于(1)距离度量与项目匹配目标的相关性,以及(2)我们在此处测量的ANNS的质量。
资源指标。交易的其他轴与计算资源相关。在搜索期间,搜索时间和内存使用是主要约束。内存使用可以小于原始向量的内存,如果使用了压缩的话。
3.3 Tradeoffs
通常只有一部分指标是重要的。例如,当在固定索引上执行大量搜索时,索引构建时间并不重要。或者,当向量数量如此之小以至于原始数据库可以多次完全适合RAM时,内存使用就不重要了。我们称我们关心的指标为活跃约束。请注意,准确性始终是一个活跃的约束,因为它可以与每一个其他约束进行交易。
3.4 Exploring search-time settings
对于固定索引,通常有一个或多个搜索时超参数,可以在速度和准确性之间进行权衡。例如,对于 IndexIVF,请参见第5节。一般来说,我们将超参数定义为标量值,这样当值更高时,速度会降低,准确性会提高。然后,我们可以只保留Pareto最优设置,这些设置是对于给定准确性来说最快的,或者等效地,对于给定时间预算来说具有最高准确性。
3.5 Exploring the index space
Faiss包括一个基准测试框架,用于探索索引设计空间,以找到最佳地权衡准确性、内存使用和搜索时间的参数。基准测试生成候选索引配置进行评估,扫描构建时和搜索时的参数,并测量这些指标。准确性指标根据适用情况选择,例如k近邻搜索的n-recall@m,范围搜索的平均精度,以及向量编解码器的均方误差,可以进一步自定义。
实际应用案例:从文本检索到内容审核
8.2 Text retrieval
Faiss常用于自然语言处理任务。特别是,近似最近邻搜索(ANNS)对于信息检索很重要,应用包括事实核查、实体链接、槽填充或开放域问答:这些通常依赖于在大规模语料库中检索相关内容。为此,嵌入模型已针对文本检索进行了优化。
8.4 Content Moderation
Faiss的主要应用之一是大规模检测和补救有害内容。人工标记的违反政策的图像和视频示例使用模型(如SSCD)进行嵌入,并存储在Faiss索引中。为了决定新图像或视频是否会违反某些政策,多阶段分类管道首先嵌入内容并搜索Faiss索引以查找相似的标记示例,通常使用范围查询。结果聚合并通过额外的机器分类或人工验证进行处理。由于错误的影响很大,良好的表示应该区分感知上相似和不同的内容,即使在数十亿到万亿规模上,也需要准确的相似性搜索。
总结与展望:Faiss的未来发展方向
Faiss是一个专注于向量相似性搜索的工具库,它通过一系列方法实现了不同的权衡,包括训练时间、吞吐量、内存使用和准确性。本文提到的大多数用例和实验在Faiss的wiki页面中有更详细的介绍和相应的代码。Faiss的未来发展将继续关注优化和扩展其功能,以满足不断增长的工业和研究需求,特别是在处理大规模数据集和复杂查询方面。随着深度学习和人工智能应用的不断增长,Faiss将继续在高效、可扩展的相似性搜索领域发挥关键作用。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人
相关文章:

2024年1月17日Arxiv热门NLP大模型论文:THE FAISS LIBRARY
Meta革新搜索技术!提出Faiss库引领向量数据库性能飞跃 引言:向量数据库的兴起与发展 随着人工智能应用的迅速增长,需要存储和索引的嵌入向量(embeddings)数量也在急剧增加。嵌入向量是由神经网络生成的向量表示&…...
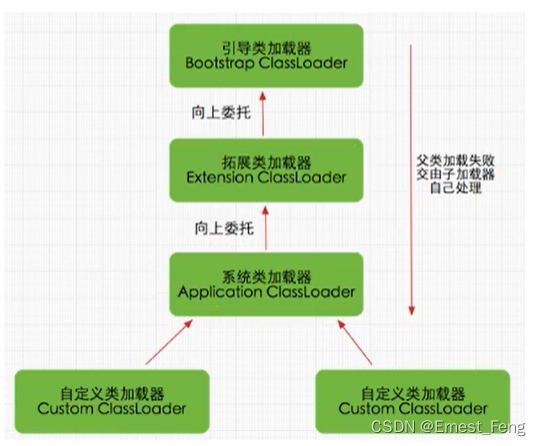
深度解析JVM类加载器与双亲委派模型
概述 Java虚拟机(JVM)是Java程序运行的核心,其中类加载器和双亲委派模型是JVM的重要组成部分。本文将深入讨论这两个概念,并解释它们在实际开发中的应用。 1. 什么是类加载器? 类加载器是JVM的一部分,负…...
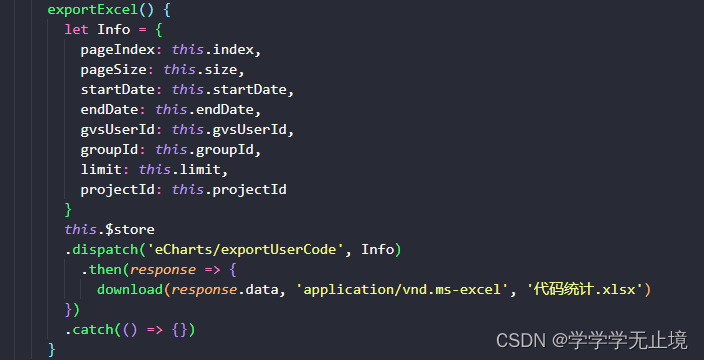
前端下载文件流,设置返回值类型responseType:‘blob‘无效的问题
前言: 本是一个非常简单的请求,即是下载文件。通常的做法如下: 1.前端通过Vue Axios向后端请求,同时在请求中设置响应体为Blob格式。 2.后端相应前端的请求,同时返回Blob格式的文件给到前端(如果没有步骤…...
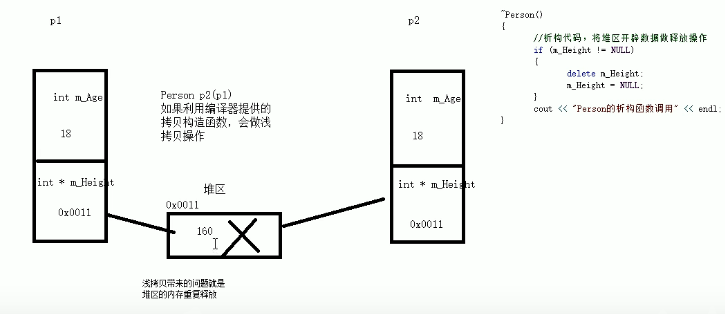
C++核心编程——类和对象(一)
本专栏记录C学习过程包括C基础以及数据结构和算法,其中第一部分计划时间一个月,主要跟着黑马视频教程,学习路线如下,不定时更新,欢迎关注。 当前章节处于: ---------第1阶段-C基础入门 ---------第2阶段实战…...

脱模斜度是什么意思,为什么要有脱模斜度,没有斜度不行吗?
问题描述:脱模斜度是什么意思,为什么要有脱模斜度,没有斜度不行吗? 问题解答: 脱模斜度是指在模具中的零件在脱模(从模具中取出)过程中相对于模具开合方向的倾斜程度。在模具设计和制造中&…...

【现代密码学】笔记9-10.3-- 公钥(非对称加密)、混合加密理论《introduction to modern cryphtography》
【现代密码学】笔记9-10.3-- 公钥(非对称加密)、混合加密理论《introduction to modern cryphtography》 写在最前面8.1 公钥加密理论随机预言机模型(Random Oracle Model,ROM) 写在最前面 主要在 哈工大密码学课程 张…...
牛客-寻找第K大、LeetCode215. 数组中的第K个最大元素【中等】
文章目录 前言牛客-寻找第K大、LeetCode215. 数组中的第K个最大元素【中等】题目及类型思路思路1:大顶堆思路2:快排二分随机基准点 前言 博主所有博客文件目录索引:博客目录索引(持续更新) 牛客-寻找第K大、LeetCode215. 数组中的第K个最大元…...
MySQL的各种日志
目录 一、错误日志 二、二进制日志 1、介绍 2、作用 3、相关信息 4、日志格式 5、查看二进制文件 6、二进制日志文件删除 三、查询日志 四、慢日志 一、错误日志 记录MySQL在启动和停止时,以及服务器运行过程中发生的严重错误的相关信息,当数据库…...
rust跟我学六:虚拟机检测
图为RUST吉祥物 大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info是怎么检测是否在虚拟机里运行的。 首先,先要了解get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址:…...

测试bug分析
项目场景: 提示:这里简述项目相关背景: 例如:项目场景:示例:通过蓝牙芯片(HC-05)与手机 APP 通信,每隔 5s 传输一批传感器数据(不是很大) 问题描述 提示:这里描述项目中遇到的问题࿱…...
css-盒子等样式学习
盒子居中,继承外层盒子的宽高 兼容性(border-box)将边框收到盒子内部 初始化div 不用管box-setting content-box 还原 创建为一个类 ,让所有需要还原的类 进行继承 padding 用法表示margin上下左右边距 body 外边距&…...

数据库系统概论 第1章绪论 1.1数据库的四个基本概念
1.1.1 数据库的4个基本概念 - 数据(Data) - 数据库(Database, DB) - 数据库管理系统(DataBase Management System, DBMS) - 数据库系统(DataBase System, DMS) 1. 数据 - 数据(Data)是数据库中存储…...

使用Linux搭建svn
1.安装 Apache 和 Subversion 软件包 sudo yum install httpd subversion mod_dav_svn2.启动 Apache 服务 sudo systemctl start httpd3.设置 Apache 服务开机自启动 sudo systemctl enable httpd4.创建/svn 目录 sudo mkdir /svn5.设置 /svn 目录的权限: sudo…...

Kafka的安装、管理和配置
Kafka的安装、管理和配置 1.Kafka安装 官网: https://kafka.apache.org/downloads 下载安装包,我这里下载的是https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz Kafka是Java生态圈下的一员,用Scala编写,运行在Java虚拟机上…...
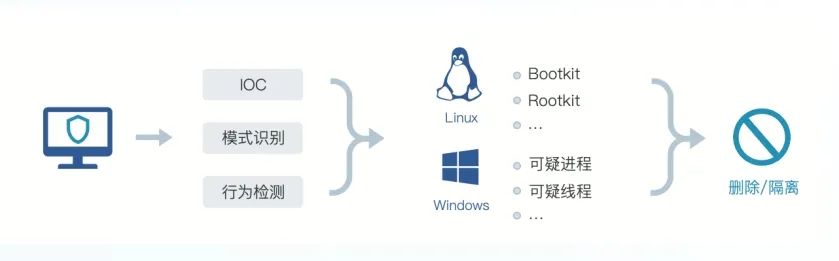
某银行主机安全运营体系建设实践
随着商业银行业务的发展,主机规模持续增长,给安全团队运营工作带来极大挑战,传统的运营手段已经无法适应业务规模的快速发展,主要体现在主机资产数量多、类型复杂,安全团队难以对全量资产进行及时有效的梳理、管理&…...

虚拟化技术、Docker、K8s笔记总结
一、虚拟化技术 是一种将物理资源(如服务器、存储设备、网络设备等)抽象、转换和分割成多个逻辑资源的技术。通过虚拟化技术,用户可以在单个物理设备上运行多个相互独立的虚拟环境,从而提高资源的利用率、降低运维成本和提高系统…...
基于springboot+vue的在线拍卖系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目背景…...

【征服redis3】一文征服redis的jedis客户端
使用数据库的时候,我们可以用JDBC来实现mysql数据库与java程序之间的通信,为了提高通信效率,我们有了数据库连接池比如druid等等。而我们想通过Java程序控制redis,同样可以借助一些工具来实现,这就是redis客户端&#…...

Python如何操作RabbitMQ实现direct关键字发布订阅模式?有录播直播私教课视频教程
direct关键字发布订阅模式 基本用法 发布者 import json from rabbitmq import pika import rabbitmq# 建立连接 credentials rabbitmq.PlainCredentials(zhangdapeng,zhangdapeng520, ) # mq用户名和密码 connection_target rabbitmq.ConnectionParameters(host127.0.0.…...

如何应用数据图表了解家里的 Unifi 网络状况?
1. 前言 自从之前写了《【让 IT 更简单】使用 Ubiquiti 全家桶对朋友家进行网络改造》 《【Rethinking IT】如何结合 Unifi 和 MikroTik 设备打造家庭网络》两篇文章后,相信给各位正在用 Unifi 或者打算使用 Unifi 的朋友应该有所帮助。 那么,今天我就…...

XRF导向的土壤重金属定量分析方法与应用【附模型】
✨ 长期致力于X射线荧光、土壤重金属、本底扣除、重叠峰解析、光谱联用研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)非对称加权惩罚最小二乘本底扣…...

软件架构分析方法SAAM、ATAM与CBAM
一、SAAM(软件架构分析方法) 1. 核心思路 基于场景,评估架构对可修改性(以及可移植性、可扩充性)的支持程度。 关键是区分 直接场景(现有架构直接支持)和 间接场景(需要修改架构)。 通过分析间接场景的数量与修改代价,定位高风险、高耦合的模块。 2. 典型案例:内…...

SQL出现filesort 一定慢吗
前言:filesort 出现在当无法使用索引排序时,MySQL 必须自己计算排序顺序,这个过程称为 filesort。EXPLAIN 的 Extra 字段会出现 Using filesort。常见触发场景:排序列不在索引中,或顺序/方向与索引不一致ORDER BY 包含…...

UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案
UxPlay应用场景:从家庭娱乐到企业演示的全面解决方案 【免费下载链接】UxPlay AirPlay Unix mirroring server 项目地址: https://gitcode.com/gh_mirrors/uxp/UxPlay UxPlay是一款功能强大的AirPlay Unix镜像服务器,它让Linux、macOS和Unix系统能…...
)
LeetCode--112. 路径总和(二叉树)
题目描述 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。 叶子节点 是指没…...
GANsformer:用Transformer重构GAN判别与生成机制
1. 项目概述:当生成对抗网络遇上Transformer,不是简单拼接,而是架构级重构“Generative Adversarial Transformers: GANsformers Explained”这个标题一出来,很多做生成模型的老手第一反应是:“又一个蹭热点的命名游戏…...

Redis分布式锁进阶第一十一篇
一、本篇前置衔接 第一十一篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争…...

NY382固态MT29F32T08GSLBHL8-24QM:B
NY382固态MT29F32T08GSLBHL8-24QM:B当工业设备在极端环境下稳定运行,其核心存储的每一次数据读写,都决定着生产线的效率与安全。一颗看似平凡的存储芯片,背后是无数工程师在稳定性、耐久性与环境适应性之间的精妙权衡。今天,我们聚…...

什么是换根DP及第一步操作说明
第一步 以任意一点统计我们规定任意一个点作为根 root,进行树形 DP 的操作。获取以确定 root 为根的状态下,所有子树的深度 deep[]。具体的,设当前 dfs 的点为 cur,孩子节点是 nex:对每个进入 dfs 的 deep[cur] 初始化…...

告别演讲焦虑:PPTTimer如何让时间管理变得简单智能
告别演讲焦虑:PPTTimer如何让时间管理变得简单智能 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 你是否曾在重要演讲时频繁看表,担心时间不够用?是否在PPT演示中因时间控制…...