Kafka的安装、管理和配置
Kafka的安装、管理和配置
1.Kafka安装
官网: https://kafka.apache.org/downloads 下载安装包,我这里下载的是https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
Kafka是Java生态圈下的一员,用Scala编写,运行在Java虚拟机上,所以安装运行和普通的Java程序并没有什么区别(需要配置java环境)。
在Kafka 2.8之后,引入了基于Raft协议的KRaft模式,支持取消对Zookeeper的依赖。
支持两种启动方式:
- Kafka with ZooKeeper
启动Zookeeper
进入Kafka目录下的bin\windows,编辑启动、停止脚本,注意最好不要将解压的安装包放在桌面,否则可能会由于目录层级太深或者是目录名字太长导致无法正确启动zookeeper,Linux下与此类似,进入bin后,执行对应的sh文件即可
start_ZK.bat
zookeeper-server-start.bat ../../config/zookeeper.properties
start_Kafka.bat
kafka-server-start.bat ../../config/server.properties
stop_Kafka.bat
kafka-server-stop.bat ../../config/server.properties
- Kafka with KRaft
1.生产集群id
./kafka-storage.sh random-uuid

2.格式化存储目录
# vAB7_ADZTc6vsKrBLI1qmA上面指令生成的集群id
./kafka-storage.sh format -t vAB7_ADZTc6vsKrBLI1qmA -c ../config/kraft/server.properties

3.启动服务
./kafka-server-start.sh ../config/kraft/server.properties
2.kafka基本的操作和管理
- 列出所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list

- 列出所有主题的详细信息
./kafka-topics.sh --bootstrap-server localhost:9092 --describe

- 创建主题主题名 my-topic ,1副本,8分区
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --replication-factor 1 --partitions 8
- 增加分区,注意:分区无法被删除
./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic my-topic --partitions 16
- 创建生产者(控制台)
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic

- 创建消费者(控制台)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning --consumer.config ../config/consumer.properties

- kafka终止命令
./kafka-server-stop.sh
3.Kafka broker配置
配置文件放在Kafka目录下的config目录中,主要是server.properties文件
3.1常规配置
broker.id
在单机时无需修改,但在集群下部署时往往需要修改。它是个每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
listeners
监听列表(以逗号分隔 不同的协议(如plaintext,trace,ssl、不同的IP和端口)),hostname如果设置为0.0.0.0则绑定所有的网卡地址;如果hostname为空则绑定默认的网卡。如果没有配置则默认为java.net.InetAddress.getCanonicalHostName()。
如:PLAINTEXT://myhost:9092,TRACE://:9091或 PLAINTEXT://0.0.0.0:9092,
zookeeper.connect
zookeeper集群的地址,可以是多个,多个之间用逗号分割。(一组hostname:port/path列表,hostname是zk的机器名或IP、port是zk的端口、/path是可选zk的路径,如果不指定,默认使用根路径)
log.dirs
Kafka把所有的消息都保存在磁盘上,存放这些数据的目录通过log.dirs指定。可以使用多路径,使用逗号分隔。如果是多路径,Kafka会根据“最少使用”原则,把同一个分区的日志片段保存到同一路径下。会往拥有最少数据分区的路径新增分区。
num.recovery.threads.per.data.dir
每数据目录用于日志恢复启动和关闭时的线程数量。因为这些线程只是服务器启动(正常启动和崩溃后重启)和关闭时会用到。所以完全可以设置大量的线程来达到并行操作的目的。注意,这个参数指的是每个日志目录的线程数,比如本参数设置为8,而log.dirs设置为了三个路径,则总共会启动24个线程。
auto.create.topics.enable
是否允许自动创建主题。如果设为true,那么produce(生产者往主题写消息),consume(消费者从主题读消息)或者fetch
metadata(任意客户端向主题发送元数据请求时)一个不存在的主题时,就会自动创建。缺省为true。
delete.topic.enable=true
删除主题配置,默认未开启
3.2 主题配置
新建主题的默认参数
num.partitions
每个新建主题的分区个数(分区个数只能增加,不能减少 )。这个参数一般要评估,比如,每秒钟要写入和读取1000M数据,如果现在每个消费者每秒钟可以处理50MB的数据,那么需要20个分区,这样就可以让20个消费者同时读取这些分区,从而达到设计目标。(一般经验,把分区大小限制在25G之内比较理想)
log.retention.hours
日志保存时间,默认为7天(168小时)。超过这个时间会清理数据。bytes和minutes无论哪个先达到都会触发。与此类似还有log.retention.minutes和log.retention.ms,都设置的话,优先使用具有最小值的那个。(提示:时间保留数据是通过检查磁盘上日志片段文件的最后修改时间来实现的。也就是最后修改时间是指日志片段的关闭时间,也就是文件里最后一个消息的时间戳)
log.retention.bytes
topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限制。log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除。(注意如果是log.retention.bytes先达到了,则是删除多出来的部分数据),一般不推荐使用最大文件删除策略,而是推荐使用文件过期删除策略。
log.segment.bytes
分区的日志存放在某个目录下诸多文件中,这些文件将分区的日志切分成一段一段的,我们称为日志片段。这个属性就是每个文件的最大尺寸;当尺寸达到这个数值时,就会关闭当前文件,并创建新文件。被关闭的文件就开始等待过期。默认为1G。
如果一个主题每天只接受100MB的消息,那么根据默认设置,需要10天才能填满一个文件。而且因为日志片段在关闭之前,消息是不会过期的,所以如果log.retention.hours保持默认值的话,那么这个日志片段需要17天才过期。因为关闭日志片段需要10天,等待过期又需要7天。

log.segment.ms
作用和log.segment.bytes类似,只不过判断依据是时间。同样的,两个参数,以先到的为准。这个参数默认是不开启的。
message.max.bytes
表示一个服务器能够接收处理的消息的最大字节数,注意这个值producer和consumer必须设置一致,且不要大于fetch.message.max.bytes属性的值(消费者能读取的最大消息,这个值应该大于或等于message.max.bytes)。该值默认是1000000字节,大概900KB~1MB。如果启动压缩,判断压缩后的值。这个值的大小对性能影响很大,值越大,网络和IO的时间越长,还会增加磁盘写入的大小。
Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好(LinkedIn的kafka性能测试)
4.硬件配置对Kafka性能的影响
为Kafka选择合适的硬件更像是一门艺术,就跟它的名字一样,我们分别从磁盘、内存、网络和CPU上来分析,确定了这些关注点,就可以在预算范围之内选择最优的硬件配置。
磁盘吞吐量/磁盘容量
磁盘吞吐量(IOPS 每秒的读写次数)会影响生产者的性能。因为生产者的消息必须被提交到服务器保存,大多数的客户端都会一直等待,直到至少有一个服务器确认消息已经成功提交为止。也就是说,磁盘写入速度越快,生成消息的延迟就越低。(SSD固态贵单个速度快,HDD机械偏移可以多买几个,设置多个目录加快速度,具体情况具体分析)
磁盘容量的大小,则主要看需要保存的消息数量。如果每天收到1TB的数据,并保留7天,那么磁盘就需要7TB的数据。
内存
Kafka本身并不需要太大内存,内存则主要是影响消费者性能。在大多数业务情况下,消费者消费的数据一般会从内存(页面缓存,从系统内存中分)中获取,这比在磁盘上读取肯定要快的多。一般来说运行Kafka的JVM不需要太多的内存,剩余的系统内存可以作为页面缓存,或者用来缓存正在使用的日志片段,所以我们一般Kafka不会同其他的重要应用系统部署在一台服务器上,因为他们需要共享页面缓存,这个会降低Kafka消费者的性能。

网络
网络吞吐量决定了Kafka能够处理的最大数据流量。它和磁盘是制约Kafka拓展规模的主要因素。对于生产者、消费者写入数据和读取数据都要瓜分网络流量。同时做集群复制也非常消耗网络。
CPU
Kafka对cpu的要求不高,主要是用在对消息解压和压缩上。所以cpu的性能不是在使用Kafka的首要考虑因素。
总结
我们要为Kafka选择合适的硬件时,优先考虑存储,包括存储的大小,然后考虑生产者的性能(也就是磁盘的吞吐量),选好存储以后,再来选择CPU和内存就容易得多。网络的选择要根据业务上的情况来定,也是非常重要的一环。
相关文章:
Kafka的安装、管理和配置
Kafka的安装、管理和配置 1.Kafka安装 官网: https://kafka.apache.org/downloads 下载安装包,我这里下载的是https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz Kafka是Java生态圈下的一员,用Scala编写,运行在Java虚拟机上…...
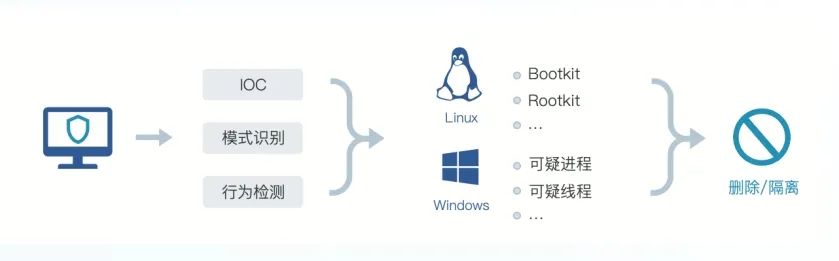
某银行主机安全运营体系建设实践
随着商业银行业务的发展,主机规模持续增长,给安全团队运营工作带来极大挑战,传统的运营手段已经无法适应业务规模的快速发展,主要体现在主机资产数量多、类型复杂,安全团队难以对全量资产进行及时有效的梳理、管理&…...

虚拟化技术、Docker、K8s笔记总结
一、虚拟化技术 是一种将物理资源(如服务器、存储设备、网络设备等)抽象、转换和分割成多个逻辑资源的技术。通过虚拟化技术,用户可以在单个物理设备上运行多个相互独立的虚拟环境,从而提高资源的利用率、降低运维成本和提高系统…...
基于springboot+vue的在线拍卖系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目背景…...

【征服redis3】一文征服redis的jedis客户端
使用数据库的时候,我们可以用JDBC来实现mysql数据库与java程序之间的通信,为了提高通信效率,我们有了数据库连接池比如druid等等。而我们想通过Java程序控制redis,同样可以借助一些工具来实现,这就是redis客户端&#…...

Python如何操作RabbitMQ实现direct关键字发布订阅模式?有录播直播私教课视频教程
direct关键字发布订阅模式 基本用法 发布者 import json from rabbitmq import pika import rabbitmq# 建立连接 credentials rabbitmq.PlainCredentials(zhangdapeng,zhangdapeng520, ) # mq用户名和密码 connection_target rabbitmq.ConnectionParameters(host127.0.0.…...

如何应用数据图表了解家里的 Unifi 网络状况?
1. 前言 自从之前写了《【让 IT 更简单】使用 Ubiquiti 全家桶对朋友家进行网络改造》 《【Rethinking IT】如何结合 Unifi 和 MikroTik 设备打造家庭网络》两篇文章后,相信给各位正在用 Unifi 或者打算使用 Unifi 的朋友应该有所帮助。 那么,今天我就…...
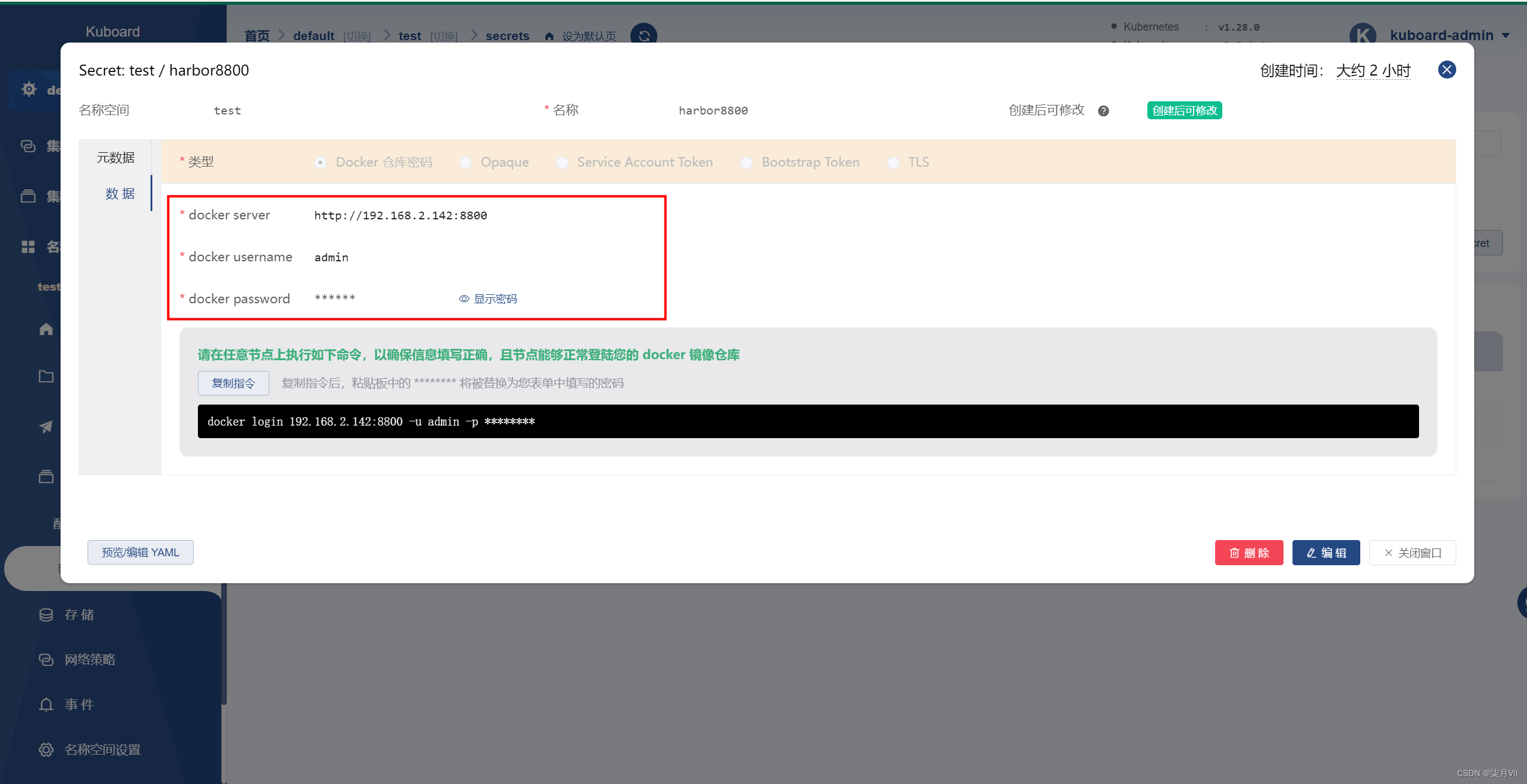
新版K8s:v1.28拉取Harbor仓库镜像以及本地镜像(docker弃用改用containerd,纯纯踩坑)
目录 一、项目概述二、环境三、项目样式Harborkuboard运行样式 四、核心点Harbor安装config.toml文件修改(containerd)ctr、nerdctl相关命令kuboard工作负载 五、总结 一、项目概述 使用Kuboard作为k8s集群的管理平台,Harbor作为镜像仓库,拉取Harbor镜像…...
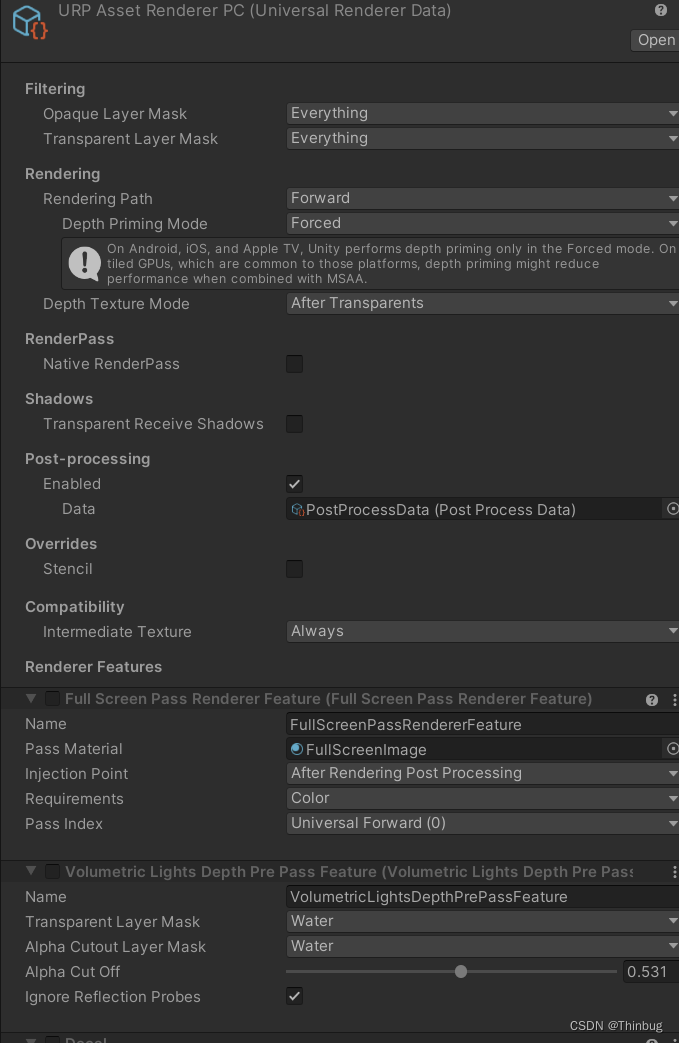
Unity URP切换品质和Feature开关的性能问题
现在对我的项目进行安卓端发布,需要切换品质和一些Feature开关。 我是这样做的。 划分品质 首先Renerer分为2个Android和PC,图中其他不用参考。 每个副本的URP Asset分为pc和android,例如图中的 hall和hall_android。 我们可以看到hall用的…...

jmeter解决返回unicode编辑
一般乱码有两种方法来解决: 1、修改配置文件jmeter.properties中默认编码格式ISO-8859-1(不支持中文),修改为utf-8 sampleresult.default.encoding utf-82、添加BeanShell PostProcessor加入 prev.setDataEncoding("utf-8")3、还有一种返回…...

C# 基础入门
第二章 C# 语法基础 2-1 C# 中的关键字 关键字,是一些被C#规定了用途的重要单词。 在Visual Studio的开发环境中,关键字被标识为蓝色,下图代码中,用红方框圈出的单词就是关键字。 关键字 class ,这个关键字的用途是…...
)
PHP 支付宝(单笔转账到银行账户接口)
alipay.fund.trans.tobank.transfer(单笔转账到银行账户接口) 小程序文档 - 支付宝文档中心 一、下载支付宝SDK,现有版本v1、v2、v3 https://github.com/alipay/alipay-sdk-php-all github 慢的话,DNS 直达即可 140.82.112.3 github.com 【host文…...

【Java万花筒】Java安全卫士:从密码学到Web应用攻击
Java安全锦囊:从Web应用攻击到加密算法,助你建立强固的开发堡垒 前言 在当今数字化时代,安全性至关重要,特别是对于Java开发者而言。本文将深入探讨Java安全与加密领域的关键库和技术,包括Bouncy Castle、Jasypt、Ke…...
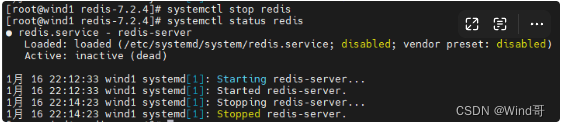
redis安装-Linux为例
可以下载一个Shell或者MobaXterm工具,便于操作 在redis官网下载压缩包 开始安装 安装依赖 yum install -y gcc tcl切换目录 切换目录后直接把redis安装包拖到/user/local/src/下 cd /user/local/src/解压然后安装 #解压 tar -zxvf redis-7.2.4.tar.gz #安装 …...

iOS长按时无法保存图片问题解决方案
在使用iOS设备的用户中,相信很多人都有过在浏览网页时遇到长按时无法保存图片的困扰。这主要是因为网页开发者为了保护版权或隐私,默认屏蔽掉了图片长按时保存的功能。 具体来说,问题出在-webkit-touch-callout这个CSS属性上。这个属性用于定…...
)
Datawhale 强化学习笔记(一)
参考 在线阅读文档 github 教程 开源框架 JoyRL datawhalechina/joyrl: An easier PyTorch deep reinforcement learning library. (github.com) 策略梯度算法的两种不同的推导版本。 强化学习中的一些核心问题,比如优化值的估计、解决探索与利用等问题。 从传统强…...
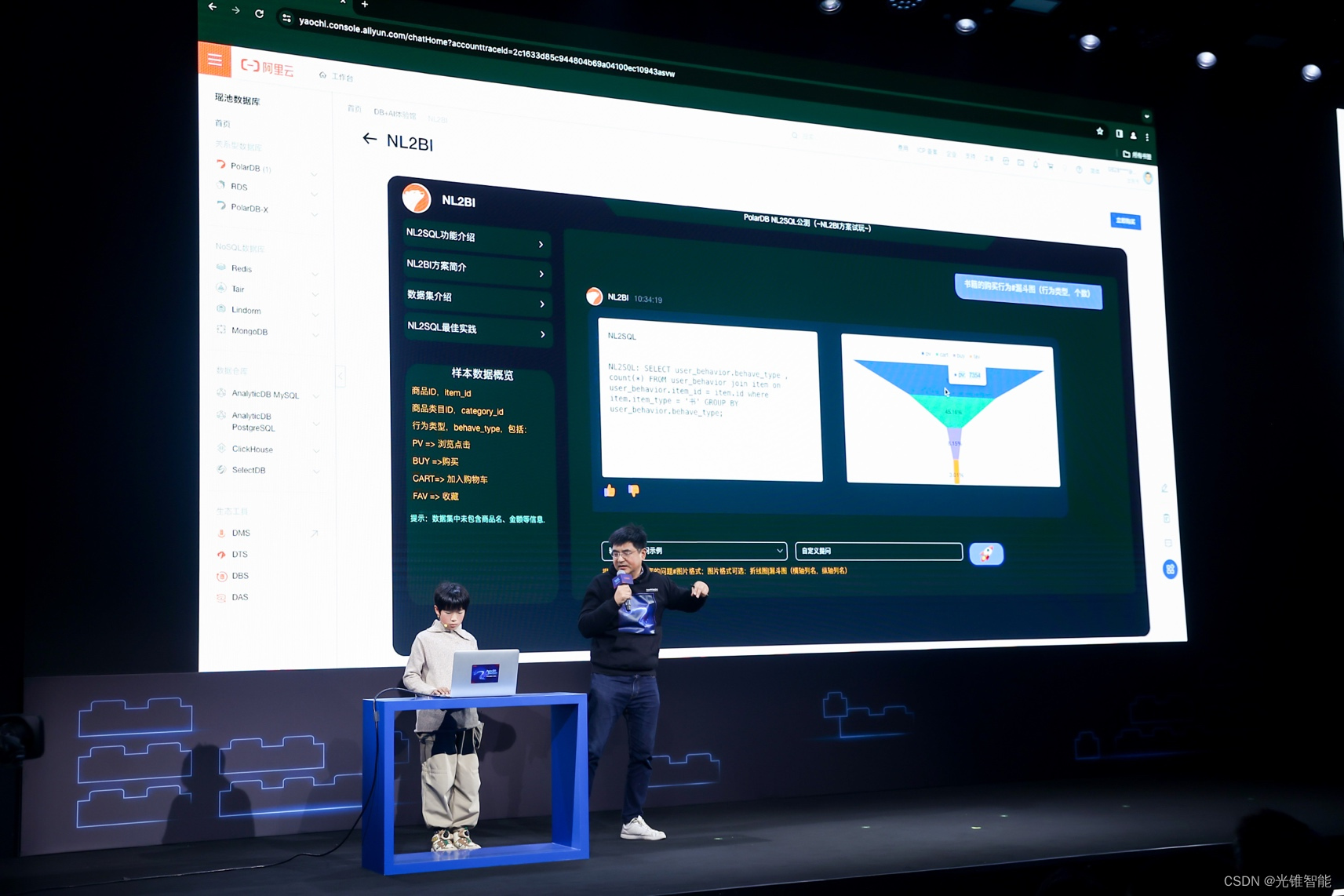
首届PolarDB开发者大会在京举办,阿里云李飞飞:云数据库加速迈向智能化
1月17日,阿里云PolarDB开发者大会在京举办,中国首款自研云原生数据库PolarDB发布“三层分离”新版本,基于智能决策实现查询性能10倍提升、节省50%成本。此外,阿里云全新推出数据库场景体验馆、训练营等系列新举措,广大…...

003-90-15【SparkSQLDFDS】慈航寺庙山脚下八卦田旁油菜花海深处人家王大爷家女儿用GPT学习DataSet的基本操作
003-90-14【SparkSQL&DF&DS】慈航寺庙山脚下八卦田旁油菜花海深处人家王大爷家女儿用GPT学习DataSet的基本操作 【SparkSQL&DF&DS】Dataset 的创建和使用 【SparkSQL&DF&DS】2,Dataset 的创建和使用1, 创建2, show3, map4, as5, select6 f…...
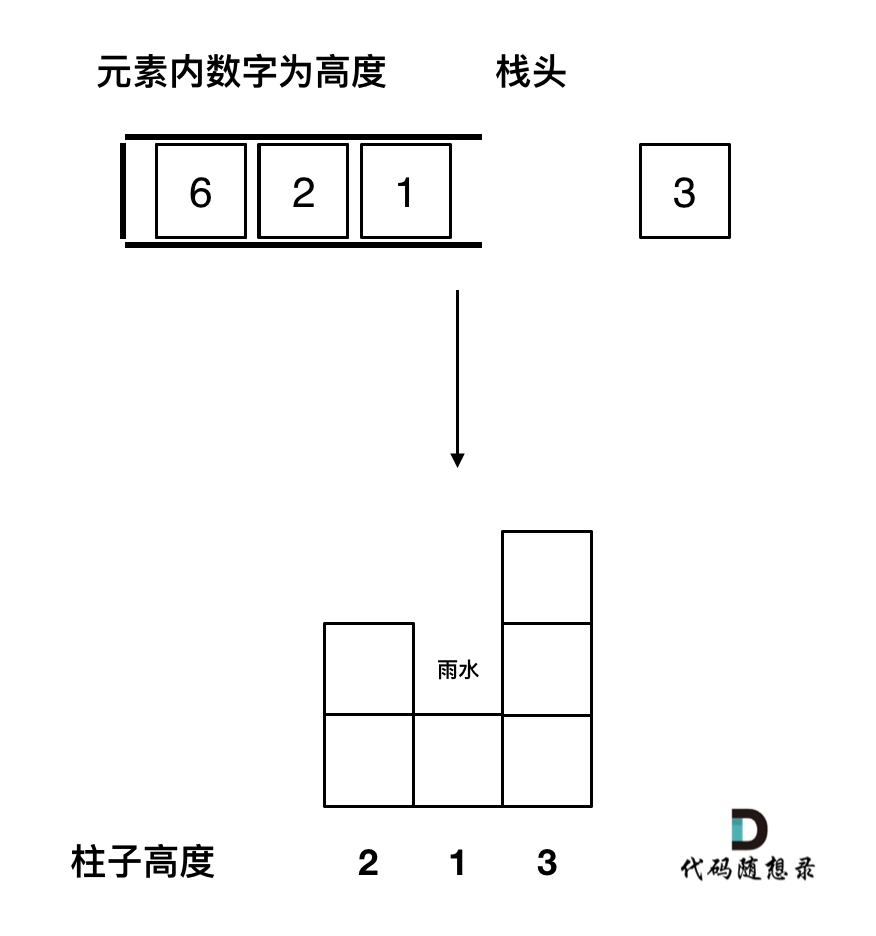
代码随想录-刷题第五十七天
42. 接雨水 题目链接:42. 接雨水 思路:本题十分经典,使用单调栈需要理解的几个问题: 首先单调栈是按照行方向来计算雨水,如图: 使用单调栈内元素的顺序 从大到小还是从小到大呢? 从栈头&…...

flutter 播放SVGA动图
SVGAPlayer-Flutter:这是一个轻量级的动画渲染库,可以通过Flutter CustomPainter原生渲染动画,为您带来高性能,低成本的动画体验123。 您可以按照以下步骤使用 SVGAPlayer-Flutter 插件: 1.在 pubspec.yaml 文件中添…...

龙芯LS2K PMON启动全解析:从内核到U盘识别的奥秘
【龙芯LS2K PMON终极干货】整机设备启动全景图:从 mainbus 开机到 U 盘识别全流程 一、整篇总纲(最强一句话) 内核启动 → 读 ioconf.c/cfdata 硬件族谱 → 从根总线 mainbus 开始遍历 → 逐级 attach 设备 → 启动 PCI → 扫描到 OTG 控制器 → 加载 dwc2 驱动 → 开启 U…...

一文讲清WMS软件是什么?企业为什么要用WMS软件?
在数字化供应链时代,WMS软件(仓储管理系统)已成为企业物流管理的核心。面对仓库混乱、库存不准,很多企业都在问:WMS软件到底是什么?它和Excel或进销存有什么区别?企业为什么要用WMS软件…...
)
手把手教你用高云FPGA的Video Frame Buffer IP搞定OV7725摄像头到HDMI显示(附源码)
高云FPGA视频处理实战:OV7725摄像头数据缓存与HDMI输出全解析 在嵌入式视觉系统开发中,FPGA因其并行处理能力和低延迟特性,成为实时视频处理的理想选择。高云FPGA作为国产芯片的代表,其Video Frame Buffer等硬核IP为开发者提供了高…...

健身房会员行为可视化涨点改进 | 全网独家复现,健康洞察实战篇 引入多维度可视化+用户分层分析,助力会员留存、课程优化、个性化指导有效涨点
目录 一、实战背景与核心目标(贴合健身房实际运营场景) 1.1 实战背景 1.2 核心目标 1.3 数据集说明(可直接获取,确保复现) 二、完整代码实现(全流程可复现,标注详细注释) 2.1 环境配置(明确版本,避免兼容问题) 2.2 数据加载与初步探索(补充异常值、冗余数据…...

机器视觉开发-使用YOLO8预训练模型检测目标
在计算机视觉领域,目标检测是一项基础而重要的任务。今天,我将介绍如何使用Ultralytics的YOLOv8库,仅用一行代码就能实现强大的目标检测功能。YOLOv8简介YOLO(You Only Look Once)是一种流行的实时目标检测算法&#x…...

几十万买的数字孪生低代码平台集体落灰?被隐瞒的落地真相,终于说透了
在政企数字化采购圈子里,一直有个特别讽刺、且年年重复上演的现象。很多企业、政府单位,手握专项数字化预算,毫不犹豫花几十万重金购入数字孪生、3D可视化低代码平台。采购前被厂商的宣传话术打动:零代码拖拽、人人上手、无需专业…...

ARMv8-A架构VDISR_EL3与VSESR_EL2寄存器解析
1. AArch64系统寄存器概述在ARMv8-A架构中,系统寄存器是处理器状态和功能控制的核心组件。它们分布在不同的异常级别(EL0-EL3),每个级别都有特定的访问权限和功能定位。作为芯片级开发者,理解这些寄存器的细节对构建稳定可靠的系统至关重要。…...

开源鸿蒙OpenHarmony在微纳卫星上的航天级改造与应用实践
1. 项目概述:当开源鸿蒙“遇见”微纳卫星最近在航天圈里有个挺有意思的事儿,开源鸿蒙OpenHarmony系统,就是咱们手机、平板上那个鸿蒙系统的开源版本,现在已经成功“上天”了。这事儿不是概念验证,而是实打实地应用在了…...

ElevenLabs支持闽南语吗?福建话语音合成实测:从API调用到音色克隆的7步通关手册
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs福建话语音支持现状与能力边界 ElevenLabs 目前尚未在官方语音模型库中提供对福建话(含闽南语、闽东语等分支)的原生支持。其公开文档与 API 文档均未列出任何以“Fuj…...

摆脱论文困扰!!2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...